JVM执行引擎
一、JVM前后端编译
- 前端编译:使用编译器将Java文件编译成class字节码文件
- 后端编译:将class字节码文件编译成机器码指令
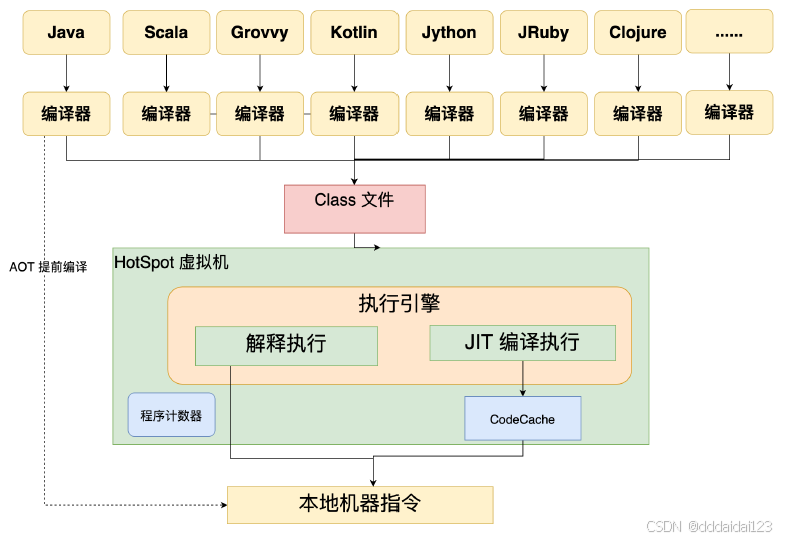
java 跨平台直接理解:前端编译将java文件编译成class文件,
然后使用jvm(后端编译(所以跨平台需要在多个平台上设计jvm将class文件编译成对应平台上的机器码指令))将class文件编译成机器码指令
二、解释执行 & 编译执行
2.1 解释执行
JVM中的**解释器(Interpreter)**读取字节码文件,逐行翻译成机器码(Native Code)并立即执行。翻译一句,执行一句。
-
优点:
启动快: 不需要等待编译过程,程序一启动就可以立即运行。
内存占用少: 不需要存储编译后的机器码。
-
缺点:
运行慢: 每次执行都需要重复"翻译"的过程(比如一个循环跑100万次,就要翻译100万次),效率低下。
3.1 编译执行
JVM通过热点探测(HotSpot Detection) 监控程序运行。当发现某段代码(如某个方法或循环)执行频率很高(被称为"热点代码")时,JIT会把这段字节码一次性编译成本地机器码,并缓存起来。下次再执行这段代码时,直接运行机器码,无需翻译。
-
优点:
运行极快: 执行的是优化后的本地机器码,速度接近C/C++。
深度优化: JIT在编译时会进行各种优化(如方法内联、死代码消除、逃逸分析等)。
-
缺点:
启动延迟: 编译过程需要消耗时间(编译耗时),可能导致程序刚启动时负载较高。
占用内存: 需要专门的内存(Code Cache)来存储编译后的机器码。
既然编译执行的速度比解释执行快,那么JVM为什么还是用解释执行呢?
虽然编译执⾏可以将越来越多的代码编译成本地代码,这样可以减少解释器的中间损耗,获得更⾼的执⾏效率。但是,这也意味着对内存有更多的资源限制,在很多资源⽐较紧张的场景,⽐如客户端应⽤,嵌⼊式系统等,使⽤解释执⾏就能更节约内存。
编译执行后的代码存储的位置是Code Cache,处于本地内存中(类似元空间)
三、识别热点代码
-
方法调用计数器: 记录方法的调用次数,如果超过阈值,则将方法存入code cache中,JVM的默认阈值为10000,可以使用-XX: CompileThreshold=N 来设置阈值
-
回边计数器:统计一个方法中循环体代码执行的次数。在class字节码文件中有例如goto等标志识别。服务端模式默认阈值为10700。
客户端编译器(C1)和服务端编译器(C2)
-
C1:相当于一个初级翻译。编译过程中,C1会对字节码进行简单和可靠的优化,耗时短,以达到更快的编译速度。启动快,占用内存小。但是翻译出来的机器码优化程度不高。适合小巧的桌面应用,所以称为客户端编译器。
-
C2:相当于是⼀个⾼级翻译。编译过程中,C2会对字节码进⾏更激进的优化,优化后的佮代码执⾏效率更⾼。但是相应的,⼯作量也变得更⼤了。C2的启动更慢,占⽤内存也更多。进⾏耗时较⻓的优化,以及激进优化,但优化的代码执⾏效率更⾼。启动慢,占⽤内存多,执⾏效率⾼。⽐较适合于⼀些资源充裕的服务级应⽤,因此也称为服务端编译器。
解释执行不会交给C1、C2进行分析,所以不会进行优化
四、后端热点代码优化
如果JVM识别到一段代码是热点代码,就会使用JIT编译器进行提前编译迁移,那么在这个过程中,会对编译后的代码进行额外优化。
内联技术
将方法的外部调用简化为在一个方法中调用,减少虚拟机栈的栈帧创建销毁的消耗。
例如:
java
public int calculate() {
int x = 10;
int y = 20;
return add(x, y); // 这里发生了方法调用
}
// 被调用的小方法
private int add(int a, int b) {
return a + b;
}优化为:
java
public int calculate() {
int x = 10;
int y = 20;
return x+ y;
}如果方法过于臃肿(行数太长),则JIT会拒绝内联。
如何从内联的角度理解阿里巴巴手册中规定的一个方法长度不能过长?
由于方法过于臃肿(行数太长)JIT会拒绝内联,如果这个方法是热点方法,其还是会被缓存,但是其没有被内联,使得其在执行其他方法(假设这个方法中调用了其他方法)的时候还是会去创建栈帧,销毁栈,使得执行效率低于内联之后的效率。
逃逸分析技术
标量替换+栈上分配
只有在使用C2编译器的时候(代码是热点代码),才会进行逃逸分析、标量替换等高级优化。
锁消除技术
对于加锁(synchronized),如果编译器发现锁本身只会被一个线程获取而不会被其他线程获取,那么JVM在编译的时候就会将锁去除,从而提高性能。