相关项目下载链接
项目介绍
本项目基于 SuperTuxKart 图像数据集(下载链接),从零训练一个自回归图像生成模型。该最终模型兼具两大功能------生成模型与图像压缩器。
首先下载并解压缩数据集
bash
wget https://utexas.box.com/shared/static/qubjm5isldqvyimfj9rsmbnvnbezwcv4.zip -O supertux_data.zip
unzip supertux_data.zip本项目data.py 文件中提供了该图像数据集的数据加载器(dataloaders),以及该数据集的令牌化版本。同时,在 train.py 文件中提供了一套完整的训练脚本,其中包含日志记录(logging)功能。若要训练你在 ae.py、autoregressive.py 或 bsq.py 中定义的任意模型,只需执行以下调用操作:
bash
python -m homework.train NameOfTheModel用户可根据需要(可选)指定 --epochs ... 参数(用于延长训练轮数),或 --batch_size 参数(用于控制显存 / 内存使用)。训练器(脚本)会生成两个文件 / 目录:
logs/{date}_{NameOfTheModel}:TensorBoard 日志文件(执行tensorboard --logdir logs命令即可查看所有日志)checkpoints/{date}_{NameOfTheModel}.pth:训练完成的实际模型权重文件
最后,本项目提供了令牌化脚本(tokenize.py),该脚本可将一组图像转换为令牌形式的 PyTorch 张量(torch tensor)。
自测作业评分
评分标准按作业各部分分别制定,并在下文详细说明。若实现 "基于自回归模型 + 熵编码的图像压缩" 功能,可获得 5 分的额外加分。
块级自编码器(30 分)
首先实现块级自编码器。
本部分目标是:接收一张宽(W)=150 像素、高(H)=100 像素的图像,将其切分为尺寸均为 P×P 的图像块(P 可取 5 至 25 之间任意值);对每个图像块,通过非线性函数计算得到 d 维嵌入向量,最终生成尺寸为 w×h×d 的特征张量(w、h 为切分后图像块在宽 / 高维度的数量);随后解码器会将这些特征映射回原始图像空间。
网络架构无严格限制,你可借助本部分熟悉训练代码、完成热身 ------ 即便是线性编码器 + 线性解码器也能满足要求。
执行以下命令训练你定义的网络:
bash
python -m homework.train PatchAutoEncoder块级量化器(30 分)
本部分需实现二进制球面量化(Binary Spherical Quantization, BSQ)的简化版本。BSQ 采用维度为 C 的二进制瓶颈层,其中每个特征值仅为 - 1 或 1;该二进制编码可直接映射为整数令牌,具体可参考BSQ._code_to_index和BSQ._index_to_code函数(实现二进制向量→整数特征的映射)。
本项目在bsq.py中提供了可微分二值化函数diff_sign:支持 - 1/1 量化,且采用直通梯度估计器(straight-through gradient estimator) 计算梯度。直接在二进制瓶颈层使用该函数可能效果不佳(可参考 BSQ 论文基线实验,或自行训练验证),但只需对二值化输入做 L2 范数归一化,即可得到易训练、高效率的量化器。
BSQ 完整流程:先将自编码器输出的特征投影至更低维度的瓶颈层(也叫码本维度(codebook dimension)),再对其归一化、量化,最后映射回原始维度空间。
除重构损失外,BSQ 原论文还优化熵损失、承诺损失、GAN 损失等,但本次作业可忽略这些,仅用可微分符号函数 + 归一化即可。
本部分需将第一部分的自编码器与 BSQ 量化器结合,强烈建议遵循初始代码超参数:patch_size=5、codebook_bits=10(能降低后续部分实现难度)。
执行以下命令训练网络:
bash
python -m homework.train BSQPatchAutoEncoder记得用这段指令激活tensorboard tensorboard --logdir logs 来监控你的训练过程。
训练良好的量化器效果如下:

上述结果由单 GPU 训练 1 小时得到 ------ 因训练时长有限且仅用 L2 损失,图像存在少量伪影,但效果接近该水平即可。即便量化器输出有块效应(blocky) 或模糊,也不影响完成作业;入门级 GPU 仅需 5 分钟即可训练出可用的量化器。
完成BSQPatchAutoEncoder训练后,执行以下命令生成令牌级数据集(供下一部分使用):
bash
python -m homework.tokenize checkpoints/YOUR_BSQPatchAutoEncoder.pth data/tokenized_train.pth data/train/*.jpg
python -m homework.tokenize checkpoints/YOUR_BSQPatchAutoEncoder.pth data/tokenized_valid.pth data/valid/*.jpg该命令会生成data/tokenized_train.pth和data/tokenized_valid.pth,分别存储完整的令牌化训练集 / 验证集。
若感兴趣,可查看令牌化文件大小:
python
du -hs data/tokenized_train.pth按上述超参数训练后,文件约 76MB(原始 JPG 数据集为 500MB)------ 这已是不错的压缩效果,后续还能进一步优化。
自回归模型(30 分)
最后训练自回归模型:接收一批令牌化图像作为输入,输出 "下一个令牌" 的概率分布。
在autoregressive.py中设计AutoregressiveModel类即可,多种结构均适用,仅解码器架构的 Transformer(decoder-only transformer)最易实现;无需搭建大型网络,建议使用torch.nn.TransformerEncoderLayer+因果掩码(causal mask) torch.nn.Transformer.generate_square_subsequent_mask。
实现要点:
- 先将输入图像展平为一维序列;
- 自回归预测需保证:位置 (i,j) 的输出仅能看到其之前的令牌,无法看到同位置 (i,j) 的输入令牌;
- 可选添加位置嵌入(positional embedding),非强制要求。
网络搭建完成后,用 "下一个令牌交叉熵损失(next-token cross-entropy loss)" 训练:
python
python -m homework.train AutoregressiveModel知识点:
该交叉熵损失值,等价于算术编码算法基于你的模型能达到的压缩率。
模型可轻松达到 "平均每幅图像 4500 比特(bits per image)" 的压缩水平;训练良好的模型可降至 4000 比特 / 图像(即 500 字节)------ 尽管画质不及 JPG,但体积比 JPG 小一个数量级。
图像生成(10 分)
最后实现AutoregressiveModel.generate函数,基于生成模型生成样本图像。因模型规模小、令牌化过程有信息损失,无需期望生成效果极佳。
以下是未使用位置嵌入的模型生成结果:
|----------------------------------------------------------------------------|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
|  |
| 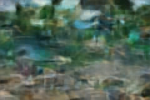 |
|  |
|
可见仅能捕捉图像块的共现统计特征(co-occurrence statistics)(同一关卡内)。
使用位置嵌入后效果略有提升,但仍远非理想:
|----------------------------------------------------------------------------|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
|  |
|  |
|  |
|
执行以下命令生成自定义样本:
python
python3 -m homework.generation checkpoints/YOUR_TOKENIZER checkpoints/YOUR_AUTOREGRESSIVE_MODEL N_IMAGES OUTPUT_PATH若模型仅训练少数轮次(甚至 1 轮),生成结果可能如下:
|----------------------------------------------------------------------------|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
|  |
|  |
|  |
|
提升生成效果需满足:
- 优化量化器(更小的图像块 / 更高比特率);
- 搭建更大的 Transformer;
- 延长训练时长。
额外加分:图像压缩(5分)
若想挑战自己,可在compress.py中实现Compressor.compress和Compressor.decompress函数。
模型检查点(Checkpoints)
训练过程中,模型检查点会自动保存至checkpoints/目录;最新训练的模型也会保存至homework/目录,作为评分依据。
若想提交指定检查点(而非最新版本),可手动将目标文件从checkpoints/复制到homework/并覆盖现有模型文件,确保评分系统使用该版本评估。
示例:若你在2025-02-27训练了AutoregressiveModel,并希望以此版本评分,执行:
bash
cp checkpoints/2025-02-27_AutoregressiveModel.pth homework/AutoregressiveModel.pth苹果芯片(MPS)与位运算Bug
实现BSQ时,我们发现PyTorch在苹果硅(MPS)设备上存在位运算Bug:位移操作(<< 和 >>)在启用MPS的设备上执行结果错误。
该问题已记录在PyTorch官方仓库:
PyTorch Issue #147889
为解决此问题,我们基于diff_sign实现了自定义位运算------该函数提供符号函数的可微分近似,效果与参考实现的位运算等价。
解决方案:
强烈建议用2的幂次运算(x * (2 ** n))替代位移运算(x << n),确保跨硬件兼容性。
示例:
避免使用:
python
index = (binary_code << torch.arange(codebook_bits))应使用:
python
index = (binary_code * (2 ** torch.arange(codebook_bits)))此修改可避免在苹果硅(M1/M2/M3)设备上运行BSQ模型时出现计算错误。
核心术语统一说明
| 英文术语 | 中文翻译 | 关键补充 |
|---|---|---|
| Straight-through gradient estimator | 直通梯度估计器 | 处理离散量化操作梯度的核心方法,让二值化等无梯度操作可参与反向传播 |
| Causal mask | 因果掩码 | 确保自回归模型仅访问当前位置之前的令牌,避免"未来信息泄露" |
| Bits per image | 每幅图像比特数 | 图像压缩率核心指标,数值越低压缩效果越好(需权衡画质) |
| Blocky | 块效应 | 分块处理导致的图像块状伪影,是量化/压缩中常见的视觉问题 |
| Codebook dimension | 码本维度 | 量化器中离散码本的维度,决定令牌的表达能力(codebook_bits为码本比特数) |
| Co-occurrence statistics | 共现统计特征 | 图像块在空间上共同出现的概率规律,是自回归模型学习的核心特征 |