卷积神经网络在图像(计算机视觉)中用的比较多
1. 图像在计算机中的本质

图像就是一个个像素(小方块)组成的,像素的范围是0~255。看右边那张图,即使没有颜色,我们也能够隐隐约约的看出8,因此可以理解,像素值越大,颜色更亮。
灰度图是单通道的,也就是说,只有一个矩阵
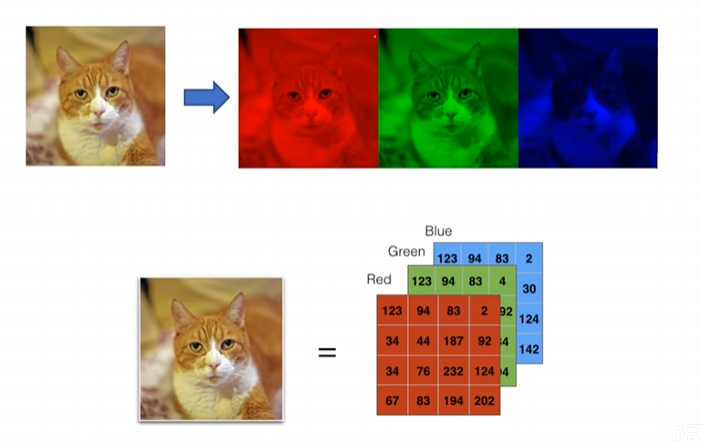
彩色图是三通道的,也就是我们说的RGB,三张图叠加起来,就是彩色图了
所以在计算机中,灰度图是【】一个矩阵,彩色图是【【】,【】,【】】三个矩阵,因此计算起来会更加复杂耗时
2. 卷积神经网络的整体结构
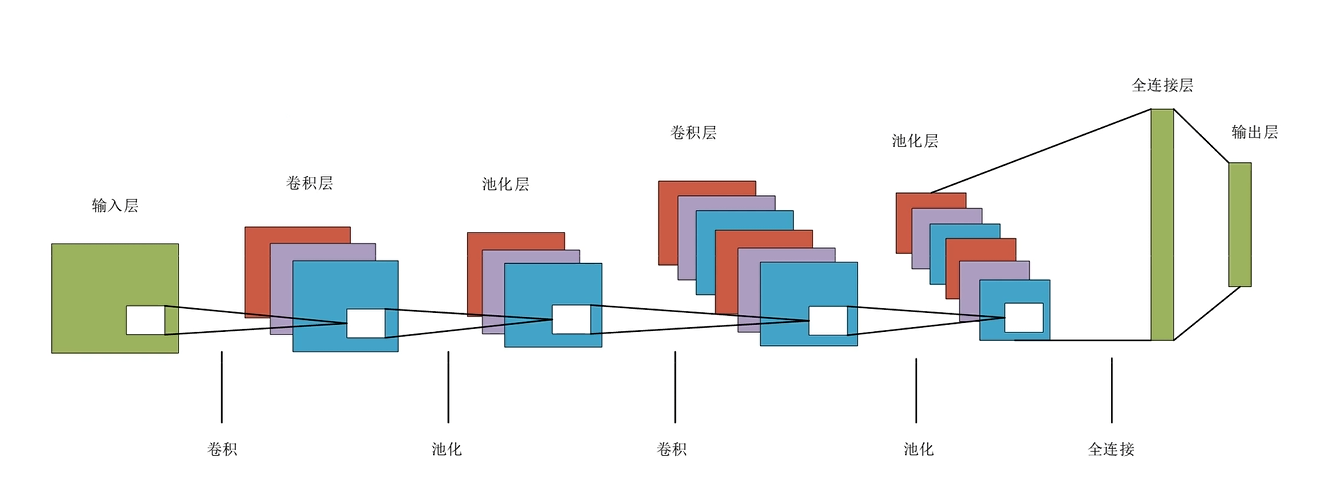
可以看到,卷积神经网络,有两种基本运算:卷积运算和池化运算。
1. 卷积运算
我们输入一张特征图(单通道的图),然后进入卷积层,卷积层会改变我们特征图的通道数,如图这里是三通道,但不是彩色图,而是说,有三个特征来表示我这一张单通道的图(彩色的三通道不也是红绿蓝三个特征来表示一张彩色图吗)。
并且卷积运算可以改变原来图片的W和H(长和高),(不是一定要改变)比如原来是30×30×1,变成24×24×3
2. 池化运算
如图,我们可以发现,它的通道数是不变的,但是可以改变W和H(长和高)(不是一定要改变)
然后不断的卷积运算、池化运算,随着通道数的增加,直到模型认为这样的一个网络结构,已经把这张特征图的信息提取完之后,最后再接一个全连接层(全连接神经网络)
3. 全连接神经网络存在的问题
为什么图片我们要用卷积神经网络,不直接用全连接神经网络呢?全连接神经网络不也能学习我们的特征吗?

我们将哈士奇分解为一块一块的特征,3 4是狗耳朵,9 10是狗头,如果是全连接神经网络,就会打乱图片之间的空间信息,空间之间的信息没有被利用,就会导致全连接神经网络的准确度不高。
但是卷积神经网络,不打乱空间信息,显然准确度很更高
还有一个问题
卷积神经网络有一个卷积核,是用来表示权重的 ,对于全连接神经网络来说,图片这么多像素,这么多特征,会导致每一层的神经元会多很多。
那么参数少一定好吗,不一定,但是你参数多也不一定好。你参数多,首先就是计算量大,其次就是容易过拟合。
4. 卷积层
1. 卷积运算和卷积核
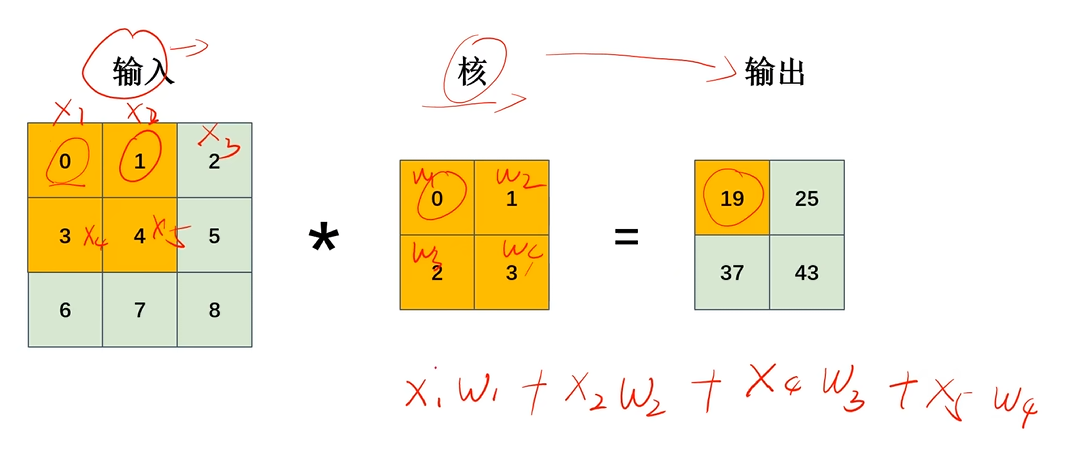
卷积核里面就是权重W ,输入就是X ,输出就是对应相乘相加
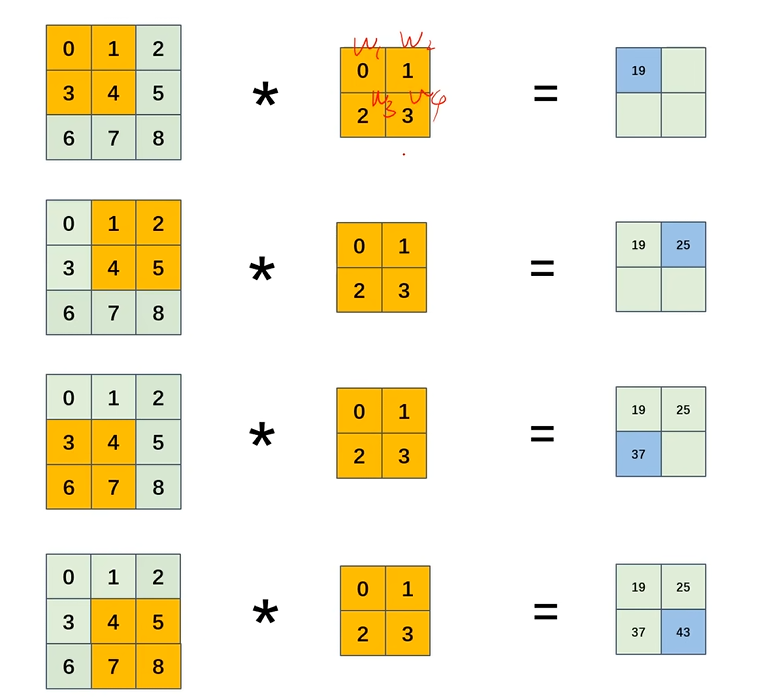
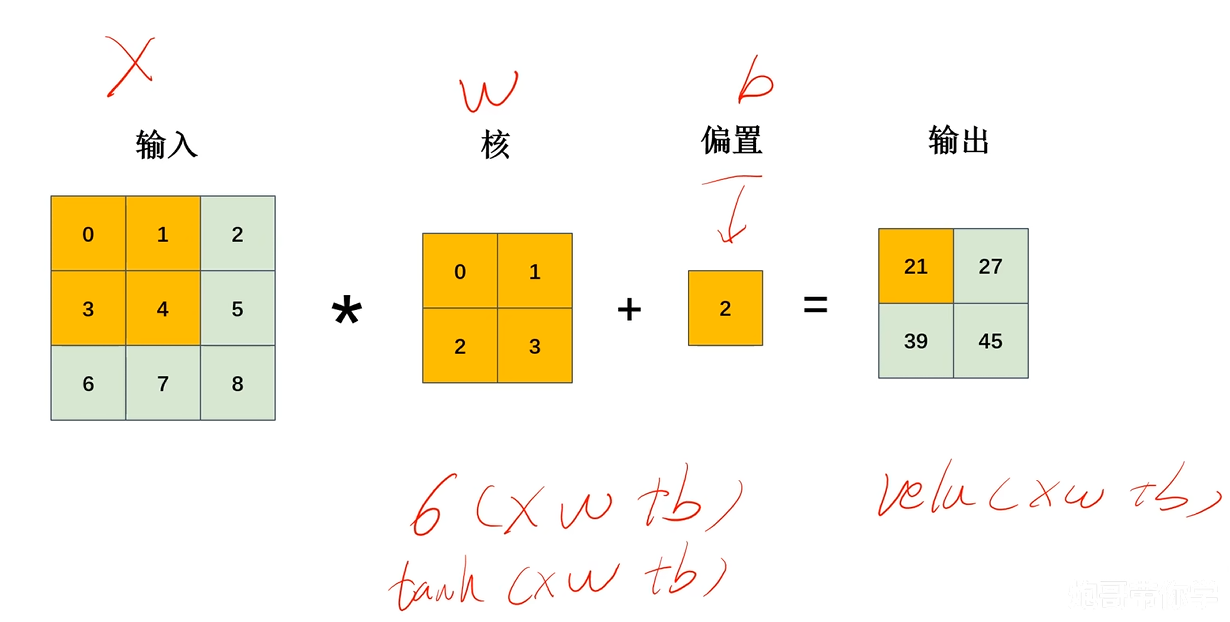
这就是整个计算过程,实际上不就是wx+b吗,计算完之后,还可以套一个激活函数
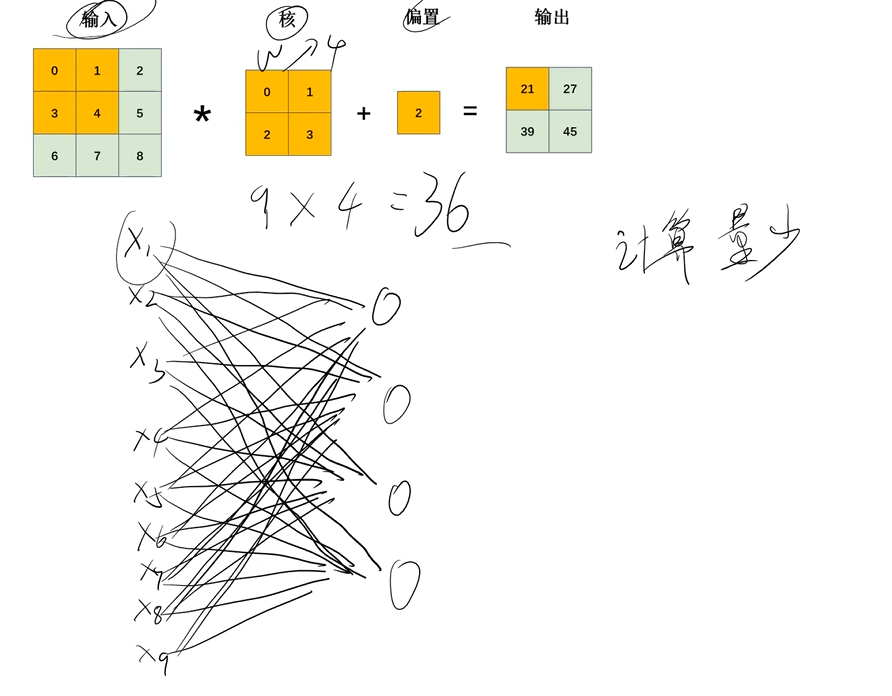
对比可以明显发现,全连接神经网络9×4=36,明显计算量要大很多,这还只是一层
2. 权重共享
看上面的过程,很明显会发现,全连接神经网络,每个输入都有自己专有的参数W,但卷积运算并不是每个参数都有自己专有的参数W ,这里有引出了一个新的概念:权重共享。
其实也就是因为权重共享,所以导致计算量减少了,并且帮我们解决了过拟合。
在我们调整权重参数的时候,当输入特征X=0、1,也就是说这一块信息少,因此对权重的调整影响就小一些,当输入特征X=8、9,也就是说这一块信息多,因此对权重调整影响就大一些。因此最后它更侧重图像中更加有用的信息,而不是没有什么用的信息也给它来一个专有的权重
3. 填充
其实就是一开始讲的,改变特征图的W和H
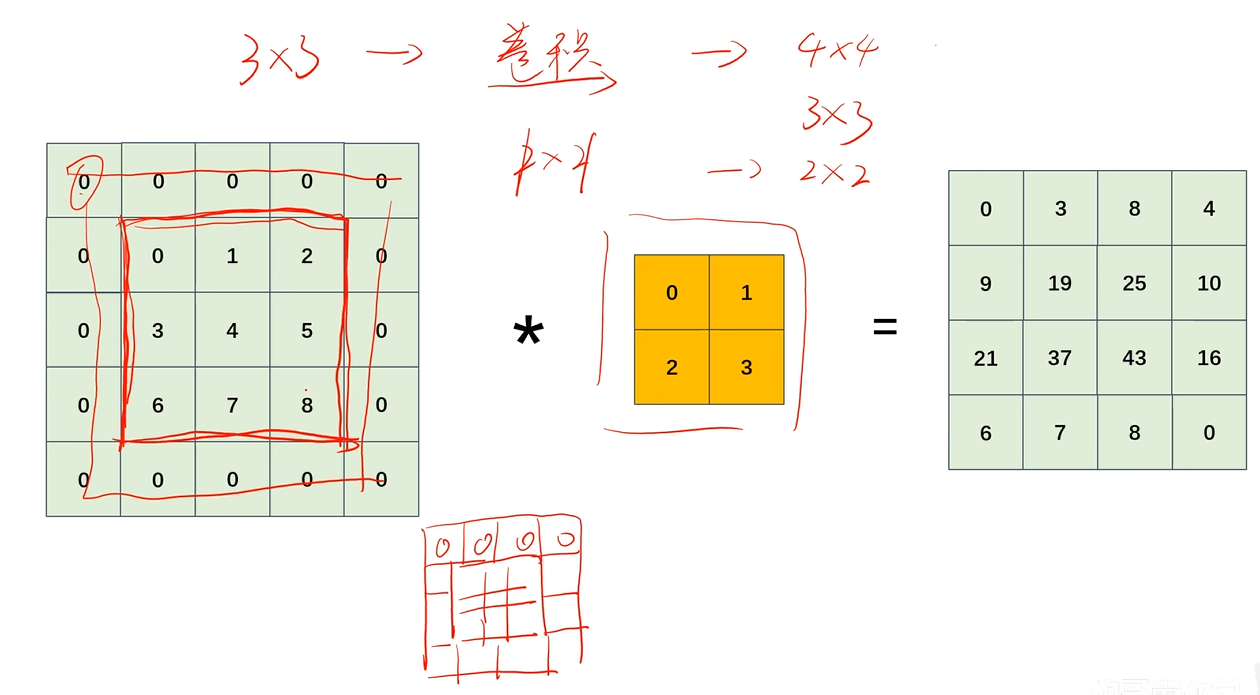
给特征图加一圈0,这样就不会影响原来图的信息,然后通过权重共享,将信息扩散出去
4. 步幅
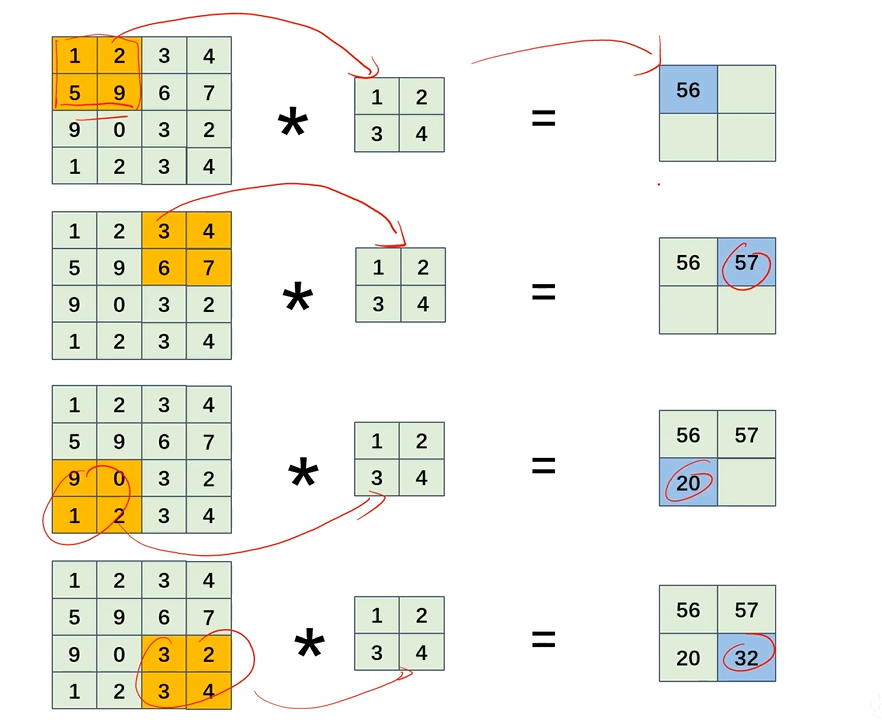
我们刚刚研究的都是步幅为1,也就是每次计算滑动一个,当步幅为2的时候,最后的结果特征图的W和H就会减少 4×4 ---> 2×2 (让我想到四阶魔方当二阶拧)
我们发现
如果步幅为1,4×4 * 2×2 最后得到 3*3
如果步幅为2,4×4 * 2×2 最后得到 2*2
我们隐隐约约感觉到,这里面应该有什么必要的关系,只是我们还没有发现
5. 经过卷积运算之后的特征图大小------计算公式
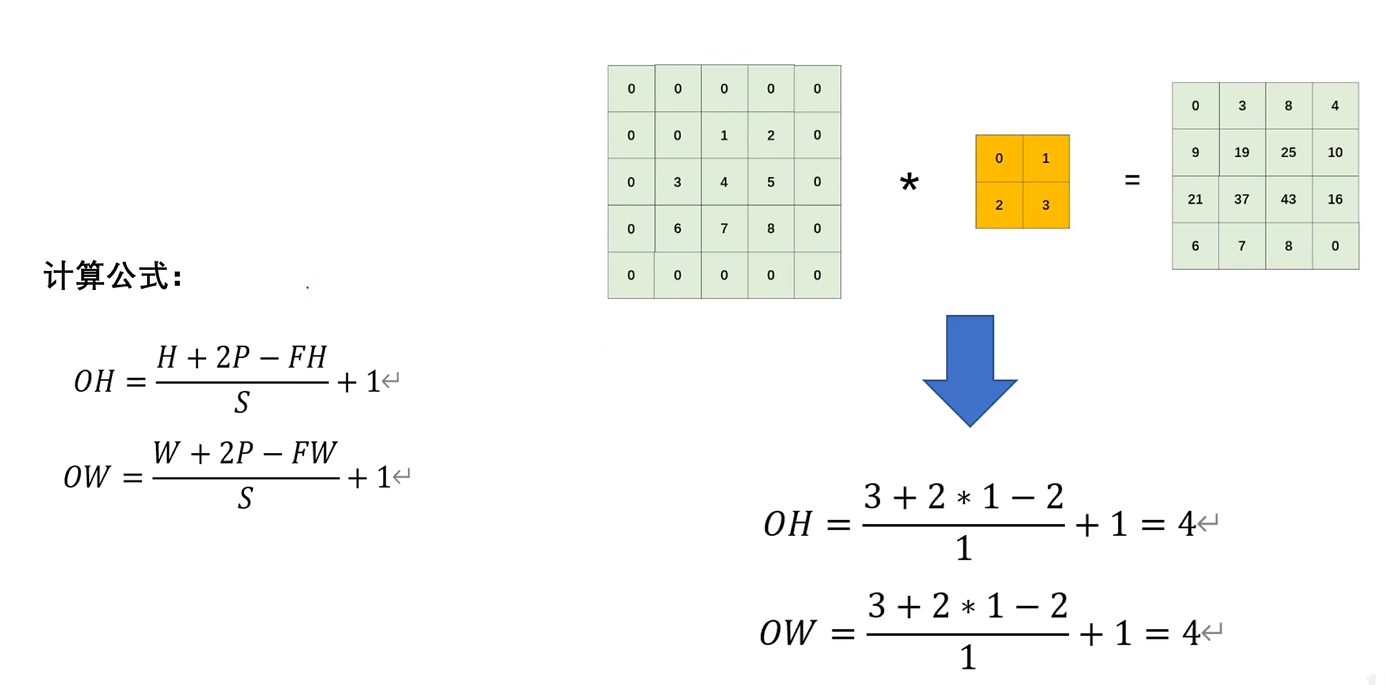
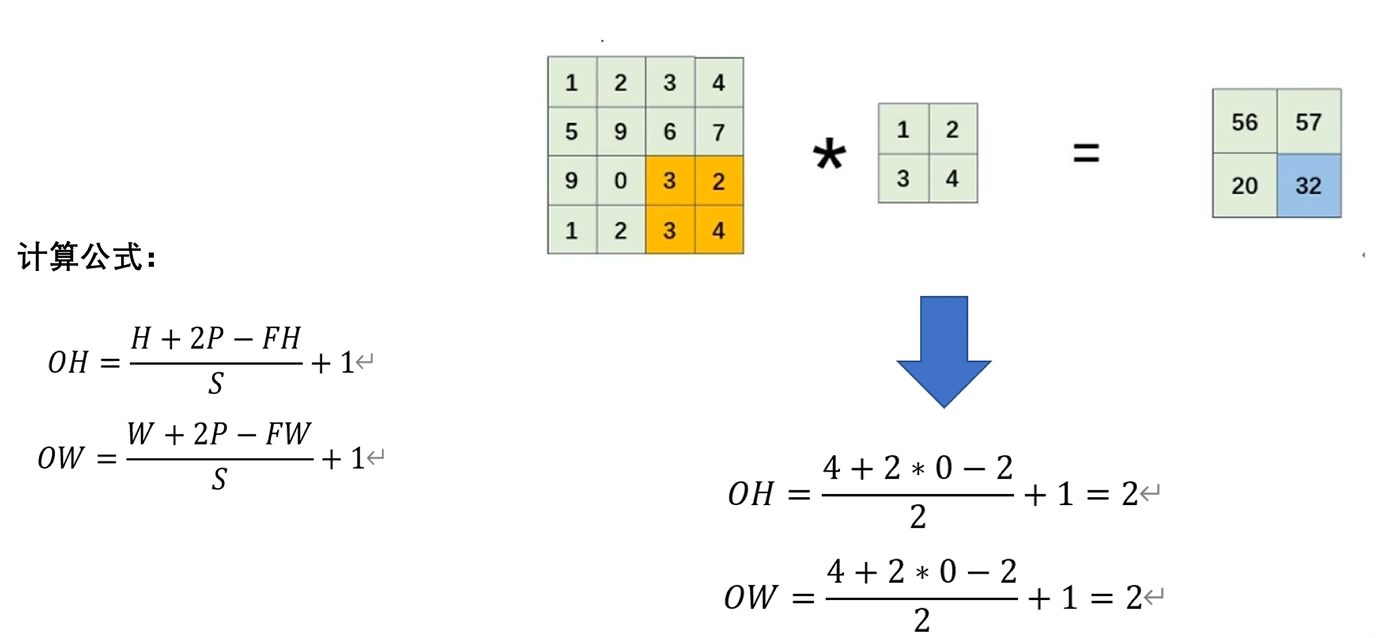
H:原图的高
P:填充的大小
FH:卷积核的高
S:步幅
6. 多通道数据卷积运算
刚刚讲的都是单通道的卷积运算,但是在我们卷积神经网络中,往往输入的特征图都是多通道的。
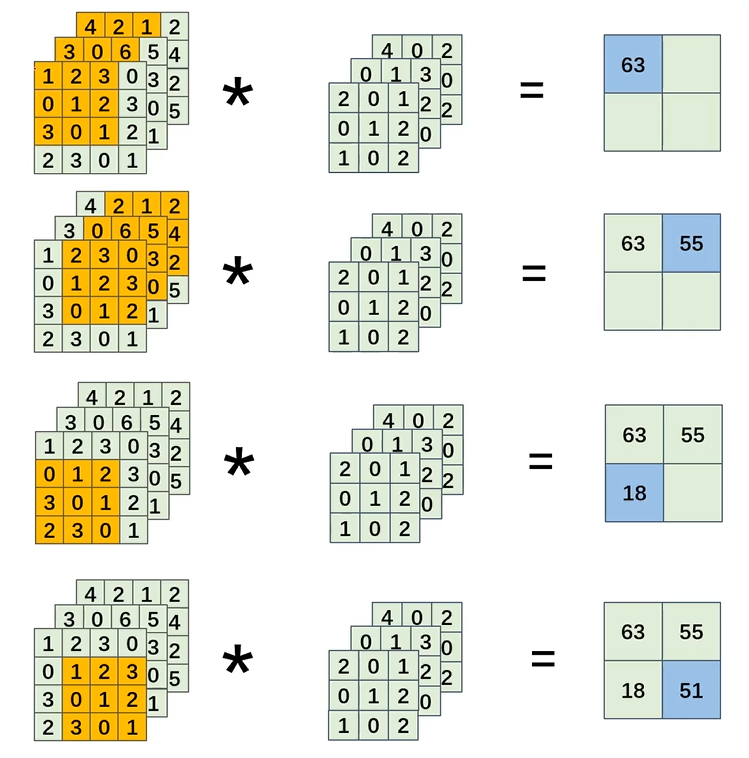
通道数和卷积核是一一对应的,3通道就有3个卷积核。
那么怎么计算呢?有些人会误以为,和单通道一样,每一个通道和一个卷积核相乘之后就好了,最后产生的通道数也是3,其实不是这样的。每一个通道的的计算结果,对应位置相加,因为一组卷积核,它所产生的特征图就是1。
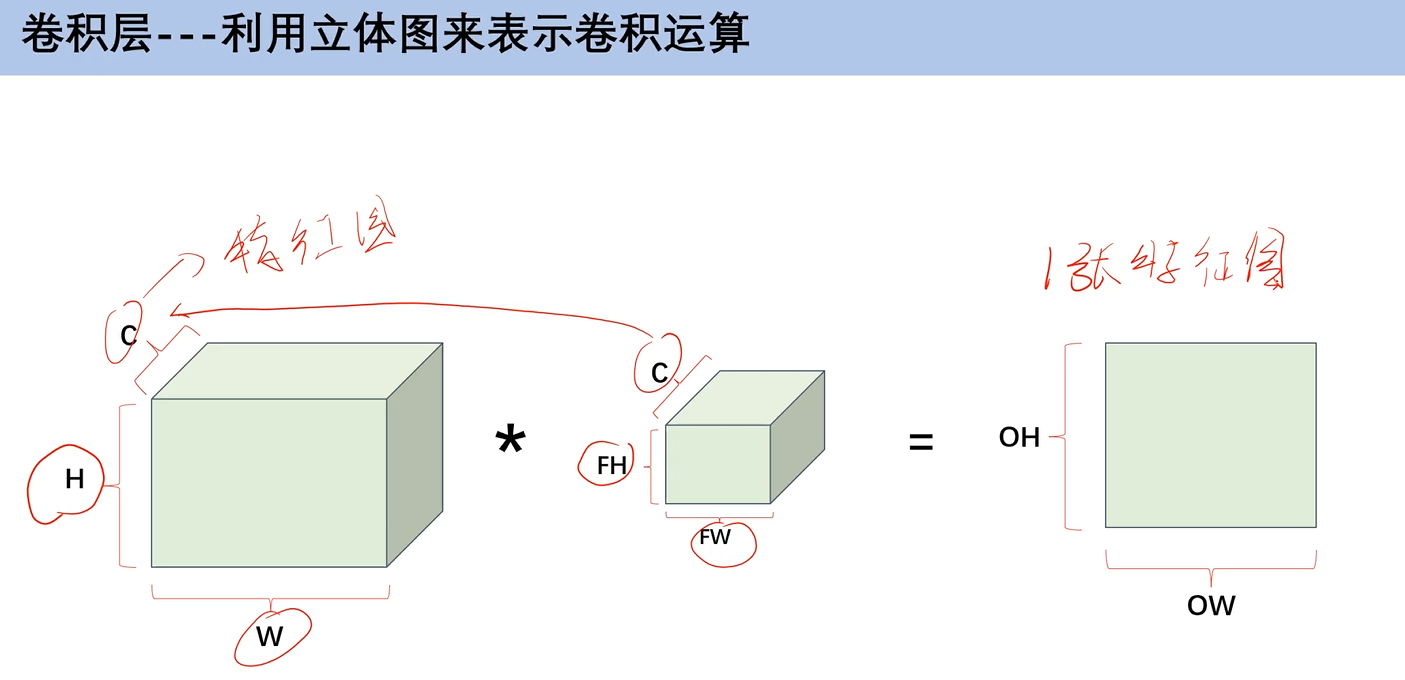
c就是通道数,通道数一定要相同,不相同不能进行卷积运算
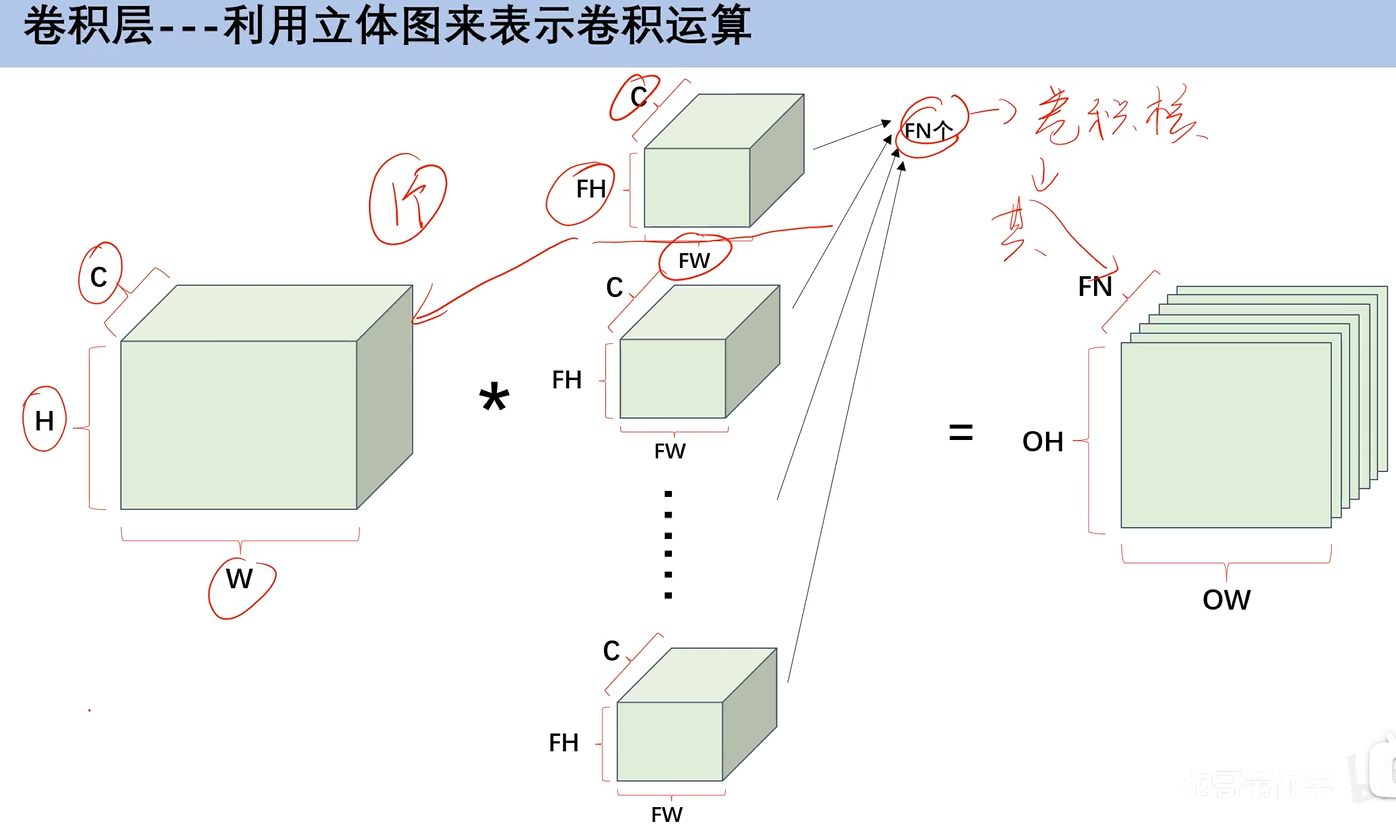
当有多组卷积核的时候,那么就会产生多通道的特征图,特征图的大小,依旧可以通过填充、步幅和卷积核大小来控制
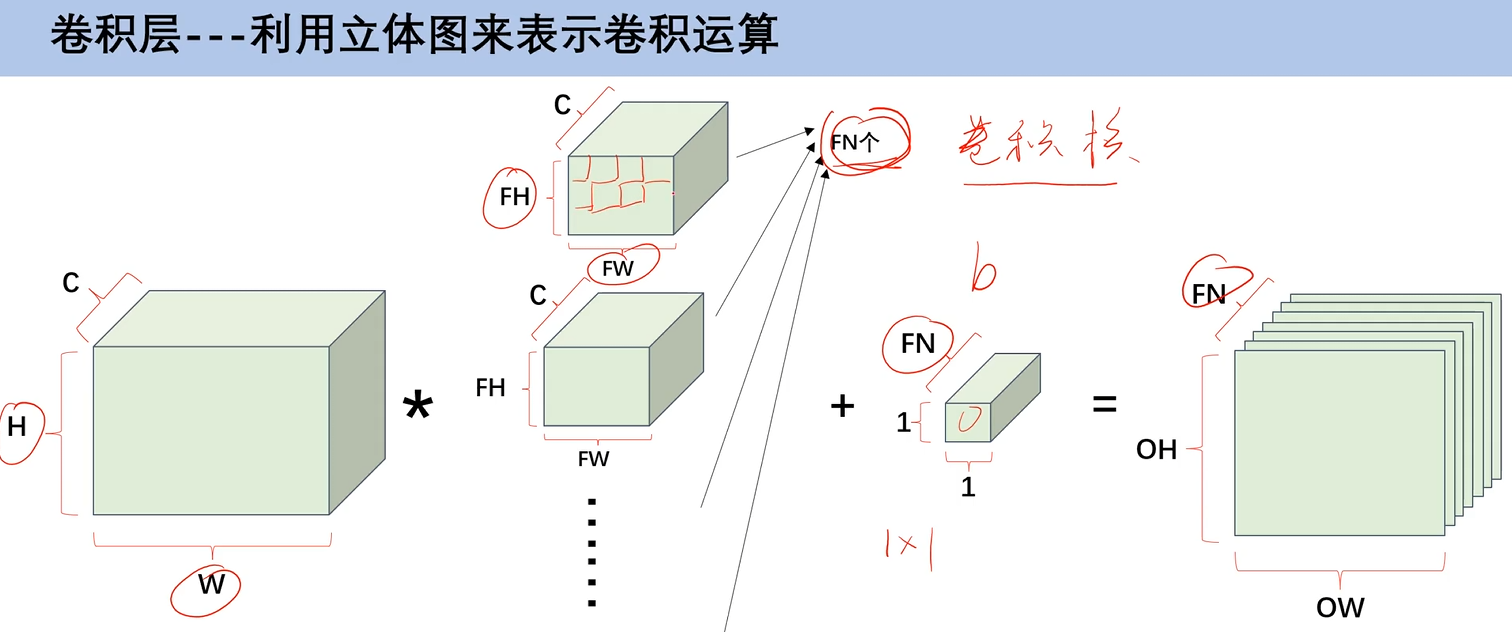
加上偏置b之后,因为b就是一个 1×1 的,所以就直接加进去就好了
5. 池化层
池化层中也有一个池化核的概念,池化核就是告诉它要在特征图中找多大的区域,池化核是不含W的,池化层里也有填充和步幅的概念
它不会改变通道数,这是和卷积层最大的区别
1. 最大池化运算
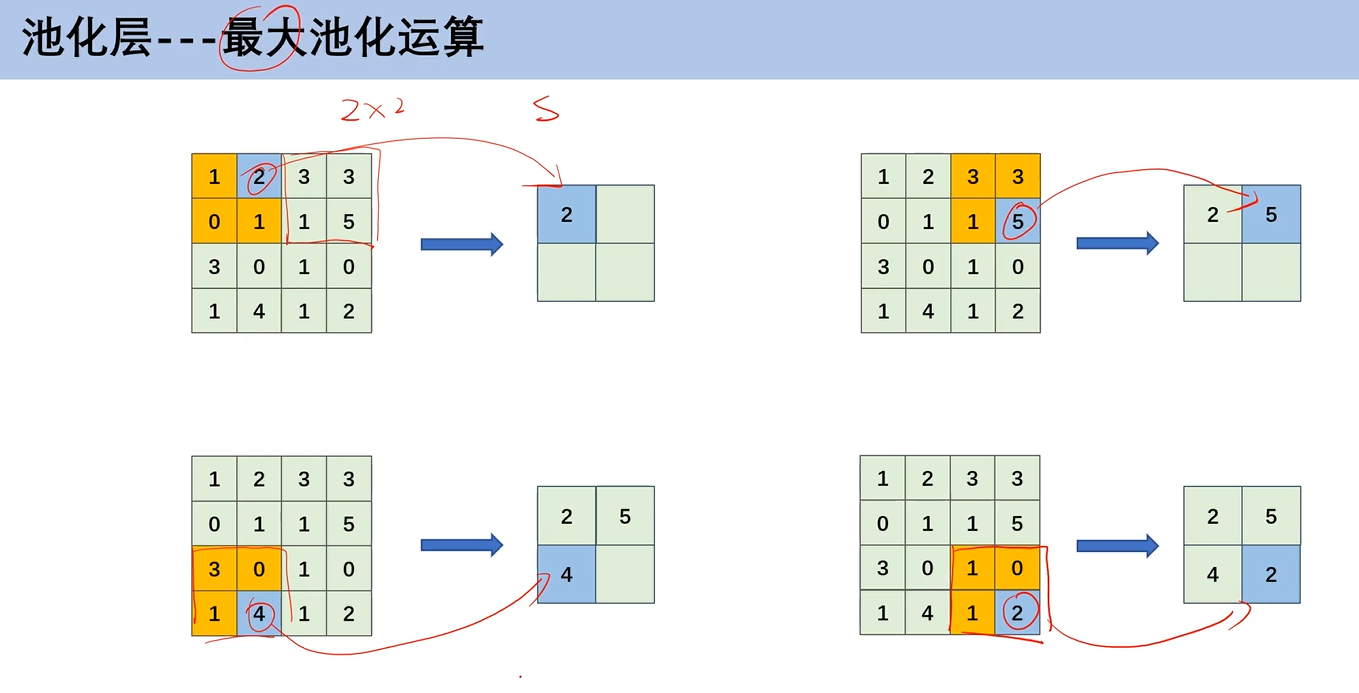
就是在2×2的区域,找到这个区域中特征值最大的,这里的步幅为2
2. 平均池化运算
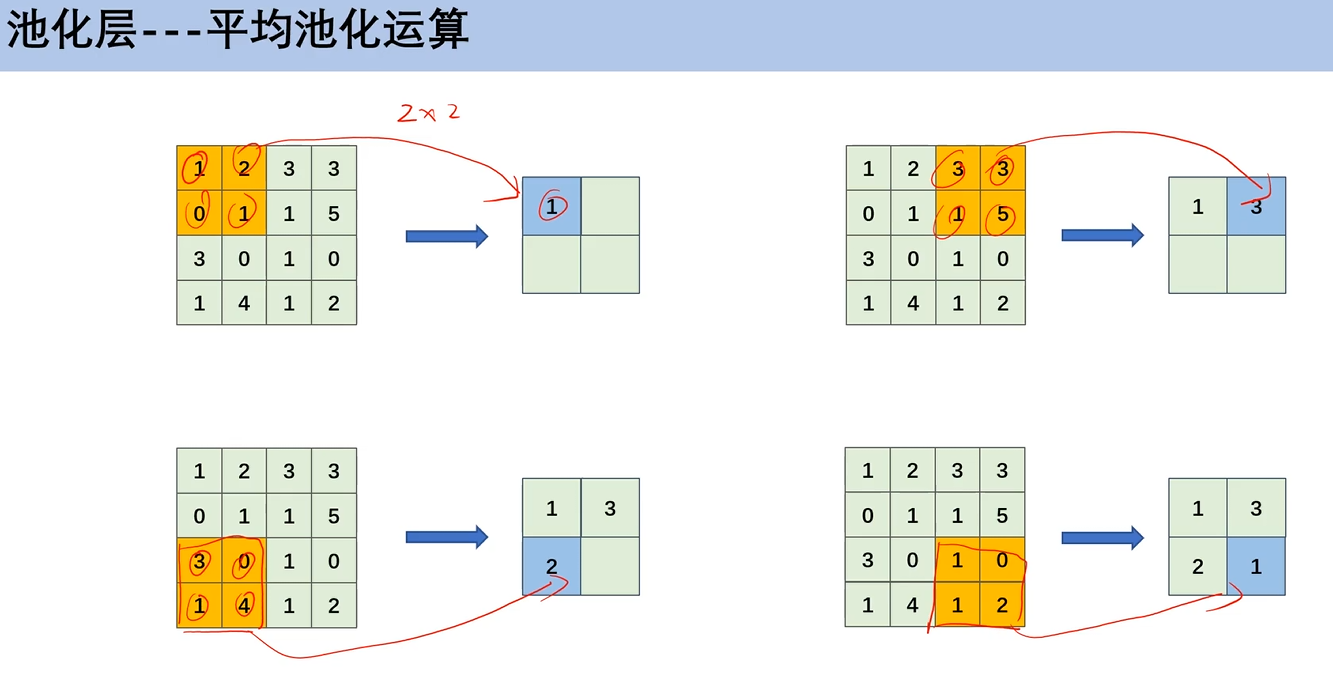
就是在2×2的区域,把这个区域中的特征值加起来,取平均值,这里的步幅为2
3. 池化运算的优点
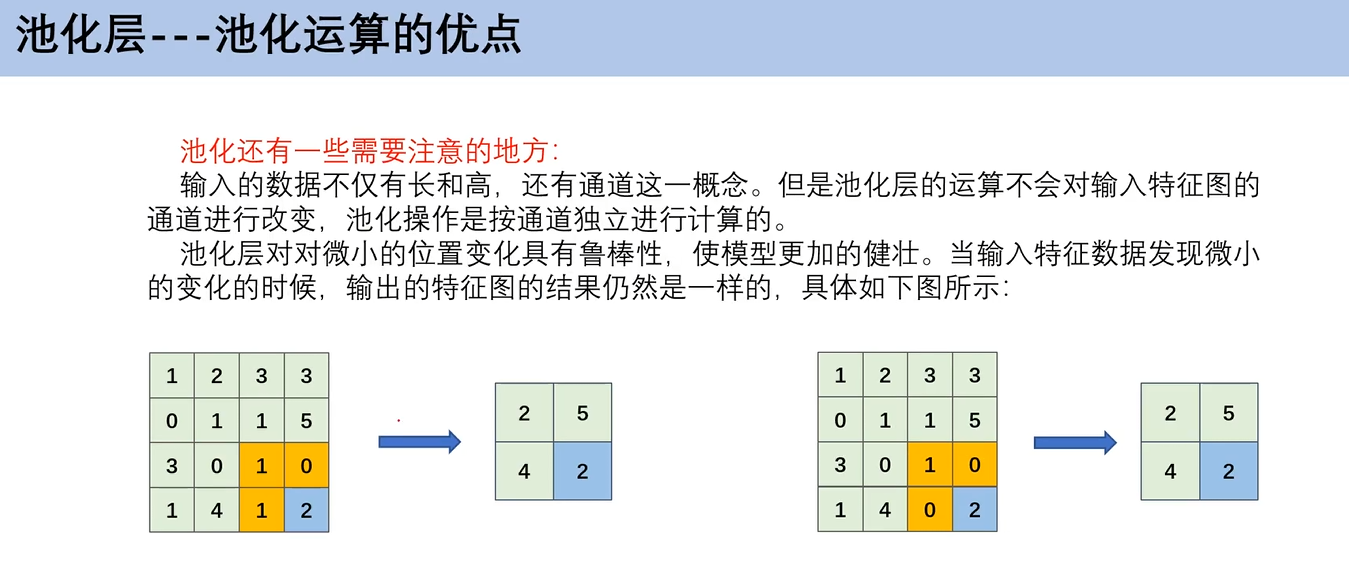
如左图,1 0 1 2,右图 1 0 0 2,特征图是有变化的,但是把2提取出来之后,不管其他怎么动,问题都不大。**也就是说,池化运算,使得你的图像即使有一些细微的变化,依旧不影响你的结果。**比如说,一只狗的图片,你锁定了狗头,然后又来一张狗的图片,它是没手没脚的,但当你锁定狗头之后,就不影响你判断它是狗。
我的理解其实就是,增强模型的泛化能力。
4. 经过池化层后的特征图大小------计算公式
经过池化层后的特征图大小也有对应的计算公式
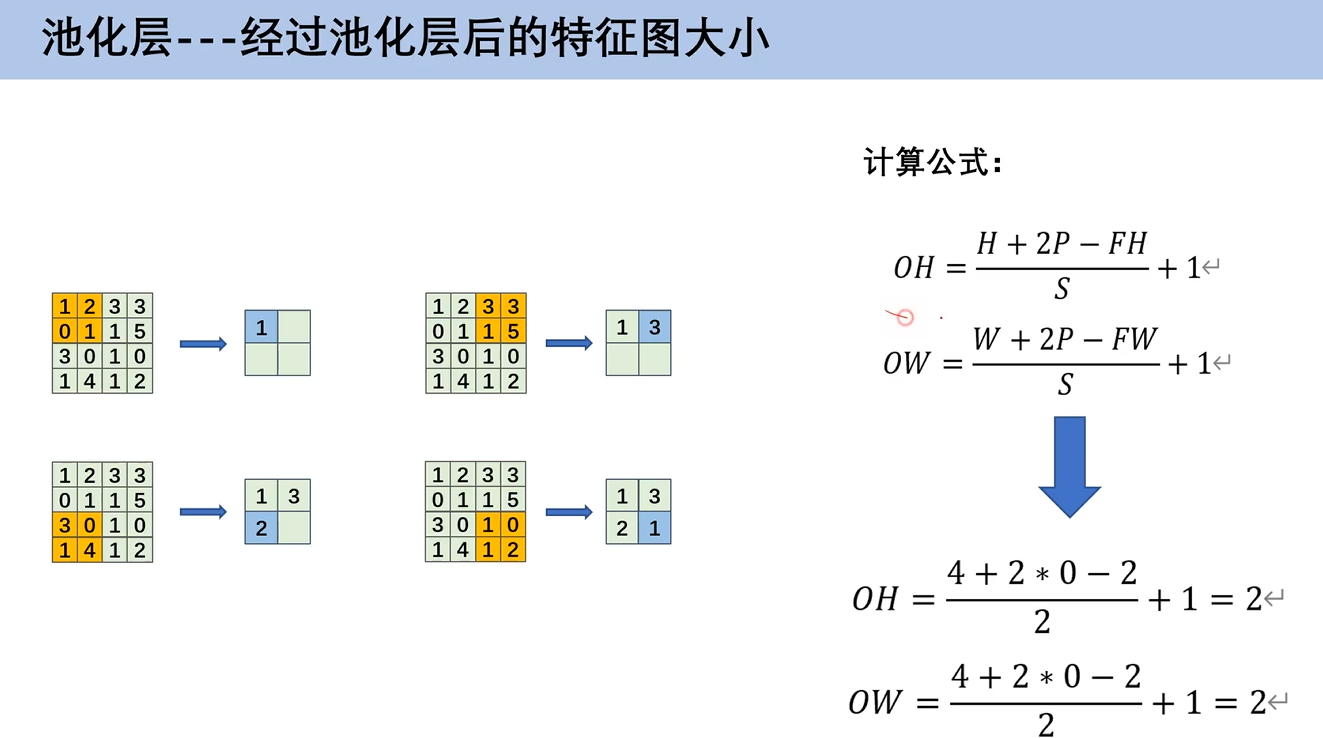
其实可以发现,和前面卷积运算的特征图大小计算公式是一样的