引言:我们正处在AI的「iPhone时刻」
我们正站在人工智能发展的历史拐点上。从2022年ChatGPT的横空出世,到如今各类大语言模型百花齐放,AI正从实验室走向千家万户,深刻改变着我们的工作与生活方式。本文将系统介绍AIGC与大模型的基础知识,帮助你理解这场技术革命背后的原理与演进脉络。
通过这篇博客,你将系统了解:
- AIGC与大模型的基本概念:它们是什么,又是如何演进而来的?
- 大模型的核心原理:了解驱动AI生成的"引擎"是如何工作的。
- 分析式AI与生成式AI的根本区别:看懂本次AI浪潮的独特之处。
- 生成式AI的训练过程:深入理解RLHF技术如何让AI更贴近人类意图。
- 丰富的应用场景:探索生成式AI正在如何改变各行各业。
- 延伸学习资源:获得进一步深入学习的资源推荐。
一、AIGC与大模型
1.1 AIGC 是什么
AIGC(AI Generated Content), 即人工智能生成内容。其核心在于「生成」二字。与传统的分析、判断不同,AIGC的输入是一个指令或提示(Prompt),输出则是全新的、连贯的、符合需求的内容,例如:
- 一段文章或邮件
- 一张图片或一段视频
- 一段可运行的代码
- 一个数据分析报告
1.2 AI的演进之路
理解AIGC需要先了解AI的发展脉络:
- 早期阶段:以规则为基础的专家系统,依赖预设的逻辑和规则。
- 机器学习时代:通过数据训练模型,使机器能够从数据中学习规律。
- 深度学习时代:利用神经网络模拟人脑的复杂结构,处理更复杂的任务。
- 大模型时代:以大规模数据和算力为基础,构建通用性强、性能卓越的AI模型。
二、从GPT-1到GPT-4:大模型的进化之路
大模型的能力飞跃并非一蹴而就,而是一个持续的演进过程。下表梳理了GPT系列的关键发展阶段:
| 模型 | 发布时间 | 参数量 | 预测数据量 | 关键能力与意义 |
|---|---|---|---|---|
| GPT-1 | 2018年6月 | 1.17亿 | 约5GB | 证明了Transformer架构在生成任务上的潜力,具有一定泛化能力。 |
| GPT-2 | 2019年2月 | 15亿 | 40GB | 展示了无监督多任务学习的潜力,在文本生成方面表现出强大天赋,但也引发了关于生成假新闻等伦理担忧。 |
| GPT-3 | 2020年5月 | 1750亿 | 45TB | 参数量实现巨大飞跃,展示了惊人的上下文学习(In-Context Learning) 和泛化能力,能完成写代码、创作、对话等绝大部分NLP任务。 |
| InstructGPT/ChatGPT | 2022年 | 基于GPT-3 | - | 引入了基于人类反馈的强化学习(RLHF),关键突破在于让模型的输出与人类意图对齐,更安全、有用、遵循指令。ChatGPT的"超能力"正源于此。 |
三、大模型:驱动AIGC的"引擎"
如果把AIGC比作一辆智能汽车,那么大模型就是它的"引擎"。当前我们使用的绝大多数AI生成应用,背后都离不开大语言模型的支持。
3.1 大模型:一个超级"文本预测器"
你可以这样理解大模型:它就像是一个阅读了几乎整个互联网的"超级学习者"。通过分析海量的文章、对话、代码等文本,它学会了在什么样的上下文中,接下来最可能出现什么词。
比如,当你输入"今天天气很好,我们一起去......"时,模型可能会预测"公园""散步""爬山"等词,而不是"睡觉"或"开会",因为它从训练数据中学会了这些常见的搭配模式。
3.2 Transformer:让AI真正"理解"上下文
在Transformer出现之前,AI处理文本就像是一个只能记住最近几句话的人,容易忘记前文的内容。
在 Transformer 出现之前,AI处理文本的主要方式是使用 循环神经网络(RNN) 及其升级版 长短时记忆网络(LSTM) 。
RNN就像是一个"记忆力很差"的读者,读一句话,从左到右,边读边努力记住前面说了什么。RNN也是这样,它按顺序处理每个词,并生成一个"记忆"(隐藏状态)传递给下一个词。
为了解决RNN的健忘问题,LSTM被发明出来。它像是RNN带上了一个可以选择性记笔记的笔记本。
它有三个"门"(输入门、遗忘门、输出门),用来决定:
- 记住什么(把重要信息写入笔记本)。
- 忘记什么(从笔记本上擦除不重要的旧信息)。
- 输出什么(根据当前输入和笔记本内容,给出回答)。
相比RNN,LSTM能记住更长的信息,因此在2010年代中后期成为处理文本(如翻译、情感分析)的主流技术。
为它必须一个字一个字按顺序处理,无法并行计算。同时,对于非常长的文本(比如整篇文章),它的"笔记本"仍然不够用,重要信息可能还是会被遗忘。
而Transformer架构的突破在于,它让AI能够同时"看到"并理解整段话中所有词之间的关系。
简单来说,它让AI具备了全局理解能力:
- 读句子时,知道每个词的重要性
- 理解"它"指代的是什么
- 把握长篇文章的核心脉络
3.3 注意力机制:AI的"高亮笔"
想象你在阅读一本教科书时,会用荧光笔标出重点内容。注意力机制就是AI的"智能高亮笔"------它让模型在处理信息时,知道应该重点关注哪些部分。
例如,当AI回答"苹果公司最新产品是什么?"时,它会更关注"苹果公司""最新""产品"这些关键词,而不是被"水果""吃""甜"这些无关含义干扰。
四、分析式AI vs. 生成式AI:本质区别
我们知道了大模型是强大的"智能引擎",那么,它主要驱动的是什么样的AI呢?这就引出了当前AI领域的核心分野:分析式AI与生成式AI。
4.1 本质区别
理解这两者的区别,是看懂本次AI浪潮的关键。简单来说:
- 分析式AI 是专家和侦探,擅长分析现有数据,告诉你"是什么"和"为什么"。
- 生成式AI 是作家和创造者,基于学到的东西,创造出全新的内容。
以我们前面讨论的大模型(如GPT)为核心的,正是生成式AI。下面我们通过一个清晰的对比
| 维度 | 分析式AI | 生成式AI |
|---|---|---|
| 核心目标 | 理解与分析现有数据,提炼洞察。 | 创造新的、与训练数据相似的内容。 |
| 它像什么 | 分析师/侦探 | 作家/设计师 |
| 典型任务 | 垃圾邮件识别、股价预测、商品推荐、人脸识别。 | 撰写邮件、智能对话、翻译、AI绘画、生成代码。 |
| 输出形式 | 一个标签、一个数值、一个是否的判断、一组列表。 | 一段文字、一张图片、一段代码、一个完整方案。 |
| 代表技术 | 逻辑回归、支持向量机、传统的推荐算法。 | 大语言模型 (GPT、文心一言)、扩散模型 (Stable Diffusion)。 |
| 与数据关系 | 从数据中发现隐藏的模式或边界。 | 学习数据的整体分布,并从中"想象"出新样本。 |
4.2 训练方式差异
-
分析式AI以监督学习为主,需标注大量数据。
-
生成式AI更多采用强化学习+奖励机制,鼓励模型自主探索最优解。
4.3 生成式AI是人类大脑的仿真或复制品吗?
这是一个非常深刻且常见的问题。简单直接的回答是:不,生成式AI并不是在仿真人类大脑,它只是受到了人脑基本结构的启发,但走了完全不同的技术路径。
灵感来源与基础结构
- 神经元网络灵感:人工神经网络(ANN)的概念确实源自对生物神经元(脑细胞)的简化模拟。一个"人工神经元"接收输入、进行加权计算、然后输出结果,这模仿了生物神经元通过突触接收和传递电信号的基本过程。
- 连接与学习:两者都通过调整"连接强度"(大脑是突触可塑性,AI是权重参数)来学习和记忆。
本质区别:从"仿形"到"数学模拟"
虽然灵感来自大脑,但现代生成式AI(尤其是大模型)已经发展成一套纯粹的数学和工程系统,与大脑的运行机制截然不同。
用一个经典比喻非常适合解释两者的关系:
- 鸟(大脑):通过生物进化而来,通过扇动翅膀利用空气动力学飞行。这是自然的、有机的方案。
- 飞机(生成式AI):受到鸟类飞行的启发,但并没有模仿扇动翅膀。它通过完全不同的原理(固定机翼和喷气发动机)来遵循相同的物理定律(空气动力学),最终实现了更高效、载重更大的飞行。
同样:
-
大脑:通过生物神经元和化学信号处理信息。
-
生成式AI:受到"神经元连接"的启发,但使用完全不同的方法(向量数学、梯度下降、注意力机制)来遵循相同的信息处理目标(从数据中学习模式并生成输出),最终在特定任务上实现了超越人类的表现。
五、生成式AI的训练过程
下面以ChatGPT为例,我们来看是如何训练出来的,在了解训练过程前,需要先了解下 RLHF 这个概念。
5.1 RLHF详解
RLHF (Reinforcement Learning from Human Feedback) ,中文译为基于人类反馈的强化学习。
它是一种用于训练人工智能系统,尤其是大语言模型的关键技术。它的核心思想是:让模型的优化目标与人类的真实偏好和价值观对齐,而不仅仅是完成一个预定义的、易于量化的技术任务。
5.2 为什么需要RLHF?
在RLHF之前,大型语言模型(如GPT-3)虽然能力强大,但存在明显问题:
- 不遵循指令:回答可能冗长、答非所问或包含无用信息。
- 生成有害内容:可能产生带有偏见、有毒或不真实的信息。
- "胡言乱语":在不确定时,倾向于编造看似合理但事实错误的答案(即"幻觉")。
传统的训练方式(预测下一个词)让模型学会了"语言的统计规律",但没能教会它"如何成为一个有用、诚实、无害的助手"。RLHF正是为了解决这个"对齐问题"而诞生的。
5.3 RLHF的工作流程详解(三步法)
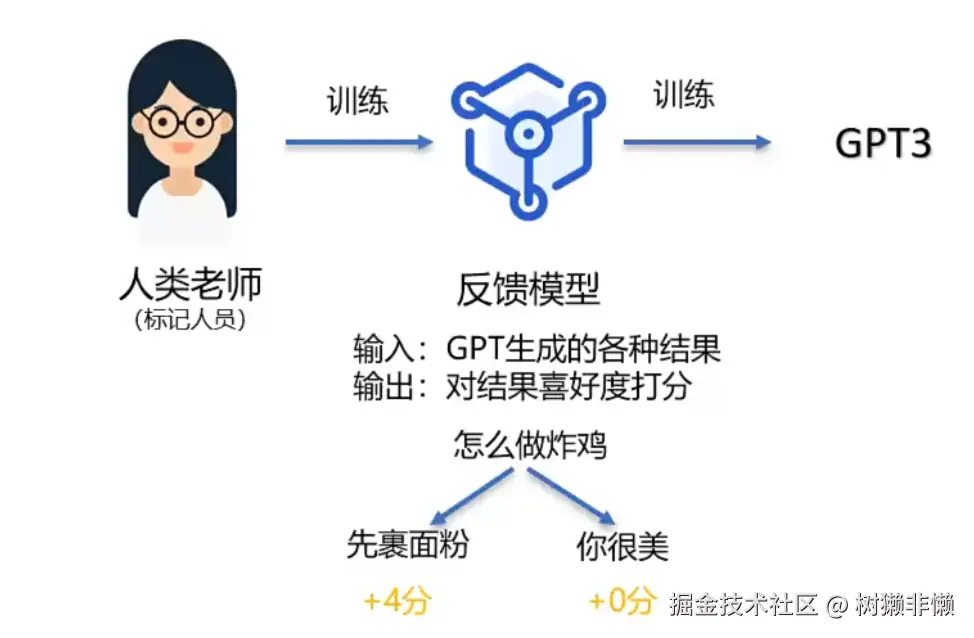
通常,RLHF过程分为三个核心步骤:
第一步:监督微调(Supervised Fine-Tuning, SFT)
-
目标: 教会模型"如何回答"。
-
过程:
- 聘请一批人类"老师"(标注员)。
- "老师"根据一批问题(Prompt),编写高质量、符合要求的答案。
- 用这些(问题,答案)配对数据,在预训练好的大模型(如GPT-3.5)上进行有监督的微调。
-
结果: 得到一个初步的、会遵循指令进行回答的模型,称为 SFT模型。但这个模型的质量还不稳定,答案可能时好时坏。
第二步:训练奖励模型(Training a Reward Model, RM)
-
目标: 建立一个能判断答案好坏的"AI裁判",量化人类偏好。
-
过程:
- 用SFT模型对同一个问题生成4-9个不同的答案。
- 将这批答案随机排列后,交给人类"老师"进行排序(从好到差)。排序比直接打分更可靠,因为人们更擅长做比较判断。
- 利用这些排序数据,训练一个独立的 "奖励模型" 。这个模型的输入是(问题,答案),输出是一个标量分数,用来预测人类对这个答案的偏好程度。
-
结果: 得到一个能模拟人类偏好的"奖励模型",它可以自动给任何回答打分。
第三步:通过强化学习优化模型(Reinforcement Learning Optimization, e.g., PPO)
-
目标: 让SFT模型在"AI裁判"的指导下,自我进化成终极助手。
-
过程:
- 将SFT模型作为需要被训练的"智能体"(Agent),将奖励模型作为环境提供的"奖励信号"。
- "智能体"针对一个新问题生成一个回答。
- 将这个回答输入"奖励模型",得到一个奖励分数。
- 使用强化学习算法(如近端策略优化,PPO),根据这个奖励分数来更新"智能体"(即SFT模型)的参数,目标是使模型生成的回答能获得尽可能高的奖励分数。
- 为了防止模型"作弊"(例如,生成一堆无意义但能讨好奖励模型的词),通常会加入一个约束项,确保优化后的模型不会偏离最初的SFT模型太远(即保持语言能力不退化)。
-
结果: 最终得到与人类偏好高度对齐的模型,例如 ChatGPT。
正是RLHF技术,让ChatGPT从"一个很会说话的学者"变成了"一个乐于助人且善于沟通的助手"。
六、生成式AI的应用场景
生成式AI正从一个"新奇的技术"转变为"基础的生产力工具"。它的核心价值在于:
- 处理海量信息,将无序数据变成结构化知识。
- 填补技能缺口,让不擅长写作、编程、设计的人也能产出合格成果。
- 激发创意灵感,提供更多可能性作为思考的起点。
6.1 内容创作与营销("你的全能创意助理")
- 新媒体运营:自动生成社交媒体文案、短视频脚本、博客初稿,保持日更不再是难题。
- 广告与营销:根据产品特点,快速生成多版广告语、营销邮件、产品描述,并进行A/B测试。
- 个性化推荐:不仅推荐商品,更能为不同用户生成个性化的商品描述和购买理由。
6.2 办公与效率提升("你的超级同事")
- 会议与邮件:自动生成会议纪要、提炼行动项;一键撰写或回复专业邮件。
- 报告与文档:输入数据和要点,自动生成结构完整、文笔流畅的分析报告、周报、方案书。
- 演示辅助:根据文档内容,自动生成PPT大纲、演讲稿,甚至设计建议。
6.3 编程与软件开发("你的外包程序员")
- 代码生成与补全:根据自然语言描述(如"写一个Python函数读取CSV文件并绘图")生成代码片段。
- 代码解释与调试:为复杂代码添加注释、解释其功能;帮助定位错误并提出修复建议。
- 不同语言间转换:将一种编程语言的代码转换成另一种。
6.4 教育与学习("你的私人导师")
- 个性化辅导:根据学生的学习水平和问题,生成定制的练习题、解析步骤和知识总结。
- 内容制作:帮助教师快速生成教案、测验题目、教学案例。
- 语言学习:提供沉浸式的对话练习伙伴,并即时纠正语法和用词。
6.5 客户服务与互动("你的永不疲倦的客服")
传统客服依赖关键词匹配,理解能力有限;而基于生成式AI的客服系统能更自然理解用户意图,实现流畅对话,已在营销、咨询等场景广泛应用。
- 智能问答与导购:7x24小时回答客户咨询,理解复杂问题,提供准确的产品建议和解决方案。
- 售后支持:引导用户完成故障排查、退货退款等流程,大幅降低人工客服压力。
6.6 创意与设计("你的灵感伙伴")
- 图像与视觉设计:根据文字描述生成Logo初稿、营销海报、产品概念图、插画等。
- 音乐与音效:生成背景音乐、广告配乐或特定情绪的音效。
- 游戏与影视:快速生成游戏剧情对话、角色设定、虚拟场景描述,辅助剧本创作。
6.7 数据分析与洞察("你的数据分析师")
- 自动报告:连接数据库后,可用自然语言提问(如"上月销量最好的三个产品是什么?"),AI自动查询并生成图文报告。
- 趋势预测与摘要:快速分析长篇市场报告、学术论文,提炼核心结论和趋势。
未来,随着技术的发展,生成式AI将会像电力或互联网一样,成为各行各业不可或缺的基础设施,嵌入到每一个工作流程中。
附录:学习资源推荐
想要更好的入门学习大模型,笔者推荐一些学习资源:
中文 LLM 教程全家桶
- 提示工程:prompt-engineering-for-developers(含吴恩达系列课程中文笔记) github.com/datawhalech...
- 应用开发:llm-universe(面向小白的大模型应用开发全流程) github.com/datawhalech...
Awesome-Chinese-LLM 导航仓库
- 汇总 100+ 中文开源大模型、微调工具、数据集、部署方案与教程,每月更新。 github.com/HqWu-HITCS/...
视频 & 报告资源
吴恩达 2025 春季《大模型系统实战》全套中文字幕