目录
[attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys) 为什么最后一层:queries 再对图像做一次 attention,token到image,image到token双向注意力还不够吗](#attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys) 为什么最后一层:queries 再对图像做一次 attention,token到image,image到token双向注意力还不够吗)
[2.1 防止信息回流污染 + 最终精炼](#2.1 防止信息回流污染 + 最终精炼)
[2.2 信息提取与精炼](#2.2 信息提取与精炼)
[2.3 信息整合的最终聚合](#2.3 信息整合的最终聚合)
[2.4 精炼的、对齐到原始图像信息](#2.4 精炼的、对齐到原始图像信息)
[2.5 单向的特征聚合](#2.5 单向的特征聚合)
[2.6 特征融合的最终优化](#2.6 特征融合的最终优化)
一、前言
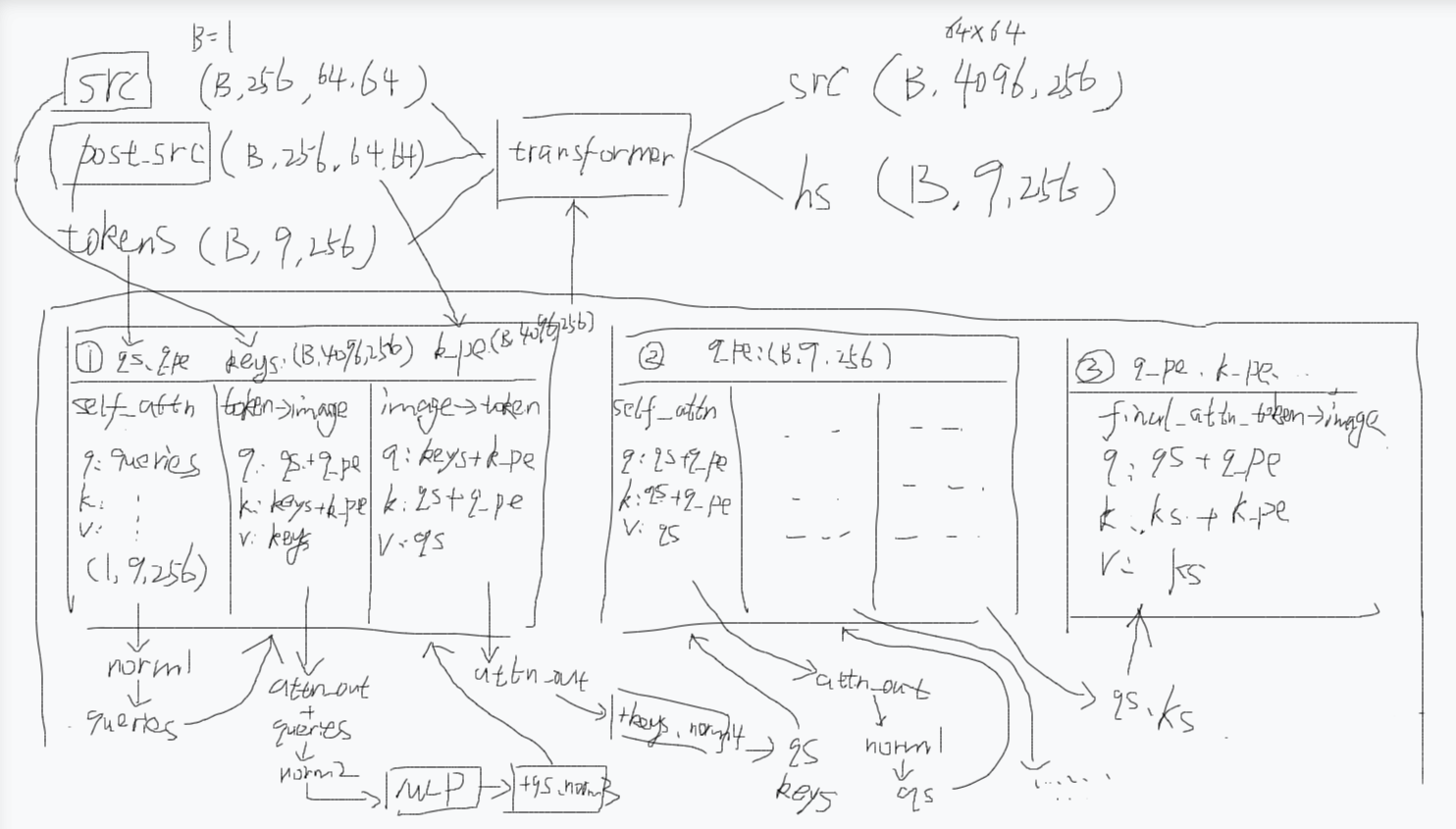
这一篇我们先休息一下。先回顾一下前面几篇在搞什么,然后处理一下上一篇的遗留问题。在前面的文章中,我们先说了调用transformer之前干了些什么,先弄了三个东西:src、post_src、tokens,其实这三个东西就是图像特征、图像位置编码、提示编码(包含提示的内容向量和位置向量),然后呢我们说了transformer(TwoWayTransformer)做了什么,其实就做了三个阶段(双向交互+最后精炼):
第一阶段 是双向交互。它包含了两层(都是做这些事:自注意力+残差+归一化、token->image的交叉注意力+残差+归一化、MLP+残差+归一化、image->token的交叉注意力+残差+归一化)
自注意力就是让点提示之间相互"沟通",用户可能输入多个点,自注意力用于理解这些点之间的空间和语义关系,例如,模型可以推断出"这些点共同构成了一个轮廓",或者"这个点在另一个点的内部"。这让每个点的 query 不再是孤立的,而是理解了它和其他"同伴"的关系。
token->image,就是点提示告诉图像,我关心你这里的这些区域,于是点提示知道了更多了,吸收了对应图像位置的上下文信息。
image->token,就是图像告诉点提示,在你关心的这些位置,我这里有这些具体的视觉特征(比如边缘、纹理、颜色),这些你关心的位置的视觉特征的重要性就被提高了。
第一层返回的queries和keys会给到第二层,然后又会跟第一层做一样的事情,除了第二层的自注意力之后会加残差(上一篇已经提到过),其他都是跟第一层一样的。关键就在这,就是因为第一层query->key,key->query,第二层又query->key,导致query给到key的信息又给回自己了,信息在循环,为了终止这个循环以及进行最后的精炼,所以这就是为什么要进行后面的第二个阶段。
第二个阶段,将第一个阶段输出的queries和keys做残差之后进行一个token->image的交叉注意力。就是点提示结合自己最初的怀疑(point_embedding,其实就是一开始输入transformer的tokens)和现场勘察的所有新发现(queries),对整个犯罪现场(keys + image_pe)进行最终的梳理和总结。它回答的问题是:"综合了所有交互信息之后,为了完成我的任务,我最需要从这幅图中提取什么?"
最后transformer输出的是一个queries和keys,对应下图的hs和src,hs就是点提示,src就是图像,不过都是增强后的。下图用qs表示queries,q_pe表示querie_pe(带pe的都是位置编码),ks表示keys,k_pe表示key_pe。然后transformer里面有三个表格,前两个是双向交互,最后一个是聚合。然后每个表格第一行是表示那些最初的提示、图像编码(因为经过一次注意力后,原始位置编码要重新加回来才可以继续做注意力,所以需要这些最初的东西)
这里说点题外话,为了回答为什么要增加最后这个聚合的token->image交叉注意力,我调用了6个AI回答同一个问题,最终发现Kimi2理解问题非常深刻,而且比喻也还可以。GLM4.6比喻非常好,很早就搞语言模型了,底子还是在且一直在进步。DeepSeekV3.2回答问题有点格式化,回答的内容中规中矩,可能是偏向于严谨地对待问题,是不是被幻觉搞怕了,感觉DeepSeek在语言理解方面有些懈怠了,可能精力投入到数学方面了吧,也是能理解。GPT5也是中规中矩,回答问题属于是懂的人会比较喜欢它的答案,不懂的人还得多问几句,属于懒惰性,不会主动打比喻,不过还是靠谱的。豆包也是中规中矩,千问回答问题也有点格式化,而且跟GPT5一样,回答得太简洁了。
(注:为什么tokens是(B,9,256)要看前面文章的解释,其实是1个objectness 打分,1个iou打分,4个mask原型,还有3个点提示,为什么是3个点提示,因为我给的是一个矩形提示,矩形提示因为矩形左上角点和矩形右下角点是两个点,再加上算法会加上一个padding的空点防止提示为空,所以总共是3个点,加起来总共是9个。如果你给的点提示数量跟我的不一致,你看到的tokens的形状是不一样的,这里解释一下说明这个形状不是固定的,而只是个例子)
二、遗留问题
attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys) 为什么最后一层:queries 再对图像做一次 attention,token到image,image到token双向注意力还不够吗
2.1 防止信息回流污染 + 最终精炼
这是一个非常深入且关键的架构设计问题,触及了SAM等模型中TwoWayTransformer的核心思想。最后一层单向注意力绝非冗余,而是精心设计的关键步骤。
核心原因:防止信息回流污染 + 最终精炼
让我们一步步拆解:
1. 双向Attention的"副作用":Image Token被污染
在
TwoWayAttentionBlock中(假设它实现了标准的双向交叉注意力):
# 伪代码示意每个block内部: queries ← queries + Attention(Q=queries+query_pe, K=keys+key_pe, V=keys) # Token→Image keys ← keys + Attention(Q=keys+key_pe, K=queries+query_pe, V=queries) # Image→Token问题 :经过多层双向交互后,
keys(图像token)已经被queries的信息污染了。它不再是纯粹的图像特征,而是混杂了点提示(query)信息的混合体。如果直接用被污染的
keys去和queries做双向交互,会形成一个 "信息回音壁" :queries的信息在image token里转了一圈又回到queries自身,削弱了模型从原始图像中重新校准的能力。2. 最后一层的使命:纯净的"查询-图像"对齐
最后一层单向注意力的设计是:
q = queries + point_embedding # queries + 原始PE k = keys + image_pe # 但keys是经过双向交互后的"污染"版本 v = keys # 值也是"污染"版本 attn_out = Attention(q, k, v) # 单向:只有Token→Image queries = queries + attn_out # 残差融合关键洞察:
Q (Query) :携带了原始点提示的绝对位置信息 + 经过双向交互精修后的queries
K (Key) :虽然是"被污染"的图像特征,但它承载了queries与图像多轮对话后的"共同理解"
V (Value):同上,提供多轮交互后最相关的图像上下文
这一步的本质是:用精炼后的query,向"已理解query意图"的图像特征做最后一次精准查询,提取最相关的信息来完成最终校准。
3. 为什么不用双向?
如果最后一层也用双向:
# 错误的设计(假设) queries ← queries + Token→Image(keys) keys ← keys + Image→Token(queries) # ❌ 问题:这会再次污染keys
Image→Token 方向会再把queries的信息写回
keys,导致最终输出的queries并非纯粹从原始图像提取的特征。在下游任务中(如SAM的mask解码器),我们只需要增强的queries来预测mask,不需要再次被污染的image tokens。
残差结构
queries = queries + attn_out要求attn_out必须是增量信息,而不是双向震荡的结果。4. 类比:面试 vs. 告别陈述
想象一个面试场景:
双向Attention:面试官和候选人来回多轮问答,互相调整理解(面试官被候选人的回答影响,候选人也根据面试官的追问调整表述)。
最后一层单向Attention :面试官在最后关头,基于之前所有对话的上下文 ,再向候选人提出一个最终确认问题 ,然后仅记录候选人的最终回答,不再让这个问题反过来影响自己对候选人的整体评价。
面试官需要的是一个经过多轮交互后、最终校准过的判断(queries),而不是一个被反复污染的中介状态。
5. 代码中的实际效果
来看张量维度:
# 经过2层双向block后: queries: [1, 9, 256] # 已融合图像信息 keys: [1, 4096, 256] # 已融合点提示信息(被污染) # 最后一层单向attention: attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys) # attn_out: [1, 9, 256] # 仅提取最相关的图像上下文 queries = queries + attn_out # 残差:在已有基础上做最终增强这里的
attn_out是纯粹的、从图像到查询的映射 ,没有反向回流,确保了queries的最终状态是稳定且信息最大化的。
总结
层类型 Q来源 K/V来源 目的 是否污染keys 双向Block 上一轮queries 上一轮keys 多轮交互、相互理解 ✅ 是(设计如此) 最终单向层 精炼queries+原始PE 被污染的keys 最终校准、无回流精炼 ❌ 否(刻意避免) 这个设计体现了分阶段信息融合 的哲学:双向交互阶段 负责建立共识,单向精炼阶段负责提取无干扰的最终表示。它是SAM在交互式分割任务中实关现高精度定位的键。
你说keys(图像token)已经被queries的信息污染了,我怎么感觉问题的关键在于queries的信息被keys污染了,因为第一步是queries->image,第二步是image->querie,有可能是因为第二步图像的信息污染了queries,所以最后一步才需要重新queries->image
你的质疑非常敏锐!你说到点子上了------问题的本质确实是queries被污染,但更精确地说,是"循环污染"。让我们重新梳理这个微妙的设计:
你是对的:queries确实被keys"污染"了
在双向block中,两个方向都在发生信息融合:
# 第一层 queries₁ = queries₀ + Attention(queries₀ → keys₀) # ✅ 我们想要的:queries被图像信息增强 keys₁ = keys₀ + Attention(keys₀ → queries₀) # ✅ 我们想要的:keys理解查询意图 # 第二层 queries₂ = queries₁ + Attention(queries₁ → keys₁) # ⚠️ 问题在这里!此时
keys₁已经包含了queries₀的信息 (来自第一层的反向attention)。所以当第二层做queries₁ → keys₁时,queries的信息通过keys间接流回了自己 ,形成了循环依赖。这不是"污染",而是"信息回声":queries的特征里混入了它自己之前的版本。
最后一层的核心作用:打破循环,做纯粹外部查询
# 最后一层:仅queries → image方向 attn_out = Attention(q=queries₂, k=keys₂, v=keys₂) queries_final = queries₂ + attn_out这层的巧妙之处在于:
Q是最终状态的queries(携带了多轮交互后的意图)
K/V是"共识空间"的keys₂(确实被queries污染过,但这正是它的价值------它代表了"图像与查询的共同理解")
单向操作 :确保这次attention的输出
attn_out纯粹是"共识空间对查询的响应",不会产生反向污染,打破循环
修正后的理解框架
阶段 操作 queries状态 keys状态 目的 双向Block queries→keys+keys→queries被图像信息增强 被查询意图引导 建立双向共识 循环后 多轮重复 混入自身回声 持续被更新 产生循环依赖 最后一层 仅 queries→keys打破循环,纯粹精炼 不再被更新 无回流最终校准
更精准的类比:调查案件
想象你在调查案件,与证人有多轮对话:
双向Block:你提问→证人回答→你追问→证人再答...(互相影响)
循环污染:你的某个假设影响了证人,证人的回答又强化了你的原假设,陷入确认偏误
最后一层单向 :你只读 所有笔录,不再提问,纯粹提炼最终结论,避免继续污染证人
最后一层是"只读"操作 :从共识空间读取信息,但不写入,因此不会产生循环。
结论
你抓住了关键:最后一层不是为了防止keys被污染,而是为了打破queries的"自我循环"。它确保:
attn_out是纯粹的外部增量信息queries的最终状态是稳定、无回声的精炼表示
下游任务拿到的是最真实的查询-图像对齐特征
这个 "先双向耦合建立共识,再单向解耦打破循环" 的设计,正是TwoWayTransformer的精妙所在!
2.2 信息提取与精炼
这是一个非常好的问题,它触及了这个模型设计的核心思想。你观察得很仔细,双向注意力确实已经做了大量的信息交换,那为什么最后还需要一次单向的注意力呢?
简单来说:双向注意力是"信息交换与融合",而最后的单向注意力是"信息提取与精炼"。
它们扮演的角色不同,目的也不同。让我们来详细拆解一下。
1. 双向注意力块 (
TwoWayAttentionBlock) 的作用:相互更新,信息融合在
TwoWayAttentionBlock中,发生了两件事:
- Queries (点) → Keys (图像) : 点提示告诉图像,我关心你这里的这些区域。这是一种自上而下的指导。
- Keys (图像) → Queries (点) : 图像告诉点提示,在你关心的这些位置,我这里有这些具体的视觉特征(比如边缘、纹理、颜色)。这是一种自下而上的信息提供。
这个过程是相互的、迭代 的。经过
depth层这样的操作后:
queries(点 token) 已经不再是孤立的点,它吸收了对应图像位置的上下文信息,变得更"知情"。keys(图像 token) 也被"污染"或"激活"了。那些被点提示关注的图像区域,其特征表示也融入了点的语义信息,变得更"重要"。所以,双向注意力的核心目的是让两种不同来源、不同粒度的信息(稀疏的点 vs. 稠密的图像)进行深度、双向的融合。
2. 最终单向注意力 (
final_attn_token_to_image) 的作用:最终提取,聚焦输出当双向融合完成后,我们得到了一个已经被点信息"调制"过的图像特征
keys,和一个已经被图像信息"丰富"过的点特征queries。现在,模型的目标是:为每一个点提示生成一个最终的、高度浓缩的、用于下游任务(如分割)的特征向量。
这就是最终单向注意力的用武之地。让我们看看它的输入和过程:
# 1. 残差连接:融合后的特征 + 原始特征(含位置编码) q = queries + point_embedding # [B, Np, C] k = keys + image_pe # [B, H*W, C] # 2. 单向 attention:用 q 去查询 k,从 v (keys) 中提取信息 attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys) # [B, Np, C] # 3. 残差连接并归一化 queries = queries + attn_out queries = self.norm_final_attn(queries)为什么必须要有这一步?
角色定位 :在这个模型中,
queries(点提示) 是主角 。整个 Transformer 的最终目的是为了得到更好的queries表示,而不是为了改变图像。图像keys只是一个信息库,一个供queries查询的"记忆库"。最终聚焦 :经过双向融合后,
keys包含了丰富的信息,但这些信息是分散在整个特征图上的。最后的单向 attention,相当于让每个query对整个信息库进行一次最终的、全局的扫描和总结 。它回答的问题是:"综合了所有交互信息之后,为了完成我的任务,我最需要从这幅图中提取什么?"残差连接的巧妙设计:
q = queries + point_embedding:这里的q不仅包含了多层交互后的queries,还加回了最原始的点提示信息。这确保了在最终提取时,模型不会"忘记"最初的指令(这个点在哪里,是什么类型的点)。k = keys + image_pe:这里的k不仅包含了被点"调制"后的图像特征,还加回了原始的图像位置编码 。这确保了queries在查询时,能准确定位到图像的空间结构。从"融合"到"提炼":
- 双向块像是把各种食材(点、图像)放进锅里一起翻炒,让味道相互渗透(融合)。
- 最终的单向 attention 像是厨师最后用勺子撇去浮沫,舀出最精华的汤汁(提炼),作为这道菜的最终成品。
一个生动的比喻
想象一下侦探破案:
- 图像 (
keys):是整个犯罪现场,充满了各种线索。- 点提示 (
queries):是侦探初步的怀疑点或关键证物(比如"门口的脚印"、"桌上的杯子")。
双向注意力 (
TwoWayAttentionBlock):
- 侦探拿着"脚印"的线索去勘察现场(
query → key),发现附近有泥土。- 现场的"泥土"线索也让侦探联想到"脚印"可能来自花园(
key → query)。- 这是一个信息来回交换、相互启发的过程。侦探对现场的理解加深了,现场也因为侦探的关注而显得"重点突出"。
最终单向注意力 (
final_attn_token_to_image):
- 经过一番勘察和思考后,侦探回到桌前,拿出笔记本。
- 他结合自己最初的怀疑(
point_embedding)和现场勘察的所有新发现(queries),对整个犯罪现场(keys + image_pe)进行最终的梳理和总结。- 他在笔记本上写下了关于"脚印"的最终结论(
attn_out),这个结论是高度浓缩的,可以直接用于指认嫌疑人。这个最终结论,就是我们模型输出的
queries,它融合了所有信息,并且是为最终任务量身定制的。总结
特性 双向注意力块 ( TwoWayAttentionBlock)最终单向注意力 ( final_attn_token_to_image)方向 双向 (Query↔Key) 单向 (Query → Key) 目的 信息融合:让点和图像特征相互渗透、更新。 信息提取:让点从融合后的信息中提取最终特征。 更新对象 queries和keys都被更新。只有 queries被更新。角色 "对话"与"交流" "总结"与"汇报" 最终产出 中间状态的、富含上下文的 queries和keys。最终的、可直接用于下游任务的 queries。所以,双向注意力还不够,因为它只是完成了信息的准备和融合工作。最后的单向注意力才是"临门一脚",负责将融合好的信息提炼成最终的、有价值的输出。
2.3 信息整合的最终聚合
1. 信息整合的最终聚合
在双向注意力中,每个点token都能看到整个图像,但这是通过多轮交互实现的。最后的单向注意力相当于一个最终的聚合层,确保所有点token基于它们前面交互得到的信息,做一次统一的最终整合。
2. 保持层级结构清晰
这种设计创建了一个清晰的层级:
双向阶段:token和图像token相互交换信息,互相增强
单向阶段:增强后的token做最终的信息提取
这类似于一些编码器-解码器结构中,解码器最后会有一个单独的注意力层来汇总所有信息。
3. 残差连接的完整性
注意最后一层的前后都有残差连接:
q = queries + point_embedding # 加回原始PE queries = queries + attn_out # 残差连接 queries = self.norm_final_attn(queries) # LayerNorm这形成了一个标准的Transformer块结构:
LayerNorm → Attention → Add → LayerNorm → ...4. 任务特性考虑
在SAM中,这个模块的最终目标是为每个点token产生一个增强的表示,用于后续的mask预测。最后的单向注意力可以:
专注于提取相关信息:让每个点token根据其当前位置和信息需求,从图像中选择性地提取最关键的信息
减少干扰:避免在最后阶段又被图像token反过来影响(这在双向注意力中会发生)
5. 与原始设计的对应
这种设计也对应了SAM原始论文中的架构图示,他们先做双向cross-attention,最后有一个单独的token-to-image attention。
实际意义
你可以这样理解:
双向阶段:像是"对话" - token和图像互相交流,互相理解
单向阶段:像是"做决定" - 每个token基于前面的对话,提取自己需要的信息做出最终判断
如果没有这最后一层,输出的token表示可能会:
包含太多来自图像token的反向影响
缺乏一个清晰的最终聚合步骤
可能没有充分利用双向阶段建立的信息通道
这种设计在实践中被证明是有效的,特别是在需要精确位置理解的分割任务中。
2.4 精炼的、对齐到原始图像信息
简短回答: 最后再做一次
queries→image的单向 attention 是为了给 queries 做一次"精炼的、对齐到原始图像信息"的最终融合与定位校正,弥补双向块中为效率或结构所做的近似/下采样与对称更新带来的信息损失或不确定性。详细解释
双向 block 的作用 是让 queries 和 image tokens 互相交换信息,形成联合表征。但这些 block 往往包含下采样/共享矩阵、对称更新或近似计算(例如内部 Q/K 下采样、共享 attention 矩阵用于双向更新),其目标偏向于高效地建立交互而不是做最终精确的像素级对齐。
最终单向 attention 的价值 在于:让 queries 以原始(或更精确)的 image keys/values 做一次直接查询,把之前交互中学到的 query 表征映射回图像的细粒度信息,从而完成定位、细节补偿与语义对齐。
残差 + LayerNorm 的组合保证这次融合是"增量且稳定"的:把新注意力输出作为补偿项加回原始 queries,再做归一化,避免破坏已学到的上下文。
另外,双向更新会同时修改 image tokens;若中间有信息混淆或下采样误差,最后一次针对原始 image_pe/keys 的 attention 能纠正或强化对关键像素的关注。
总结:双向块负责交互与信息传递,最后的 token→image attention 负责精炼、对齐与恢复细节,两者互补,缺一不可。
2.5 单向的特征聚合
你想知道在双向注意力层之后,为什么还要额外让 queries 对图像做一次单独的 attention,而不是仅依靠之前的双向注意力就完成特征增强。
一、先理解双向注意力与最终单独 attention 的本质区别
首先,你代码中的TwoWayAttentionBlock(双向注意力块) 是互逆的双向交互 (queries→keys 和 keys→queries 都会做),而最后的
final_attn_token_to_image是单向的特征聚合(仅 queries→keys,也就是稀疏点 token 对稠密图像 token 做 attention)。二者的设计目标和作用完全不同,我们可以从三个核心角度解释这个设计的必要性:1. 双向注意力的 "交互" 属性 vs 最终 attention 的 "聚合" 属性
- 双向注意力层 :核心是让稀疏点 token 和稠密图像 token 互相交流、互相更新 。在这个过程中,点 token 会吸收图像的信息,图像 token 也会吸收点 token 的信息,但这个过程是相互的、迭代的 ,目的是让两者的特征逐渐对齐。但由于图像 token 数量远大于点 token(比如 4096 vs 9),双向交互后,点 token 可能还没有充分聚合图像中与自身相关的关键信息(因为交互是相互的,图像 token 的更新会分散一部分计算资源)。
- 最终的单向 attention :核心是让点 token 专注于从图像 token 中聚合最相关的信息。此时没有了图像 token 的反向更新,计算资源全部集中在点 token 对图像的注意力上,相当于对之前双向交互的结果做一次 **"聚焦式总结"**,让点 token 的特征更凝练、更贴合任务需求(比如分割、检测中的点提示任务)。
2. 残差设计与原始 PE 的复用,弥补双向层的信息损失
在最终 attention 中,代码做了这两步关键操作:
q = queries + point_embedding # 残差加回原始PE k = keys + image_pe # 残差加回原始图像PE
- 双向注意力层在迭代更新中,可能会让 queries/keys 逐渐偏离原始的位置编码(PE)信息(位置编码对视觉任务至关重要)。而最终 attention 中,将原始 PE 残差加回后,再做 attention,相当于让点 token 在 "保留原始位置信息" 的基础上,重新聚焦图像的关键区域。
- 双向注意力层没有这个操作,而最终 attention 通过这个设计,能弥补双向层迭代过程中可能的位置信息损失,让输出的 queries 既包含双向交互的语义信息,又保留精准的位置信息。
3. 工程上的 "收尾" 作用,稳定训练与提升性能
从实际工程角度,这种 "双向交互 + 单向聚合" 的结构是 Transformer 类模型的常见设计技巧:
- 双向注意力层是特征交互的主体,但多次迭代后可能会出现特征的 "过平滑" 或 "噪声累积";
- 最后的单向 attention 相当于一个轻量级的收尾层,通过一次简单的 attention 操作,对特征做一次重新归一化和聚合,能有效稳定训练过程(比如减少梯度消失),并提升最终的任务性能。
二、类比理解
你可以把这个过程类比成 **"讨论 + 总结"** 的场景:
- 双向注意力层:就像你(稀疏点 token)和一群专家(稠密图像 token)围坐在一起讨论问题,你们互相交流观点(互相更新特征),这个过程中你会吸收专家的知识,专家也会理解你的问题。
- 最终的单向 attention:讨论结束后,你需要单独整理专家的观点,聚焦于和你的问题最相关的内容,形成一份最终的报告(增强后的 queries)。如果没有这一步,你可能只是记住了讨论的零散内容,而没有形成一个凝练的、针对问题的结论。
总结
- 功能互补 :双向注意力负责特征互作对齐 ,最终单向 attention 负责特征聚焦聚合,二者缺一不可。
- 信息弥补:最终 attention 通过复用原始位置编码(PE),弥补了双向层迭代中可能的位置信息损失。
- 工程优化:最终 attention 作为收尾层,能稳定训练过程,提升模型的最终性能。
简单来说,双向注意力是 "让两者互相了解",而最终的单向 attention 是 "让点 token 从图像中提炼出对自己最有用的信息",这一步是双向注意力无法替代的。
2.6 特征融合的最终优化
虽然前面的双向attention blocks已经进行了token-to-image和image-to-token的交互,但最后一层token-to-image attention有几个重要作用:
- 特征融合的最终优化:前面的双向attention层中,token-to-image和image-to-token attention是交替进行的,而最后一层专门让增强后的queries再次对图像特征做一次精确的注意力融合,确保点查询充分吸收图像信息。
- 残差连接的特殊设计 :注意代码中最后的处理:
q = queries + point_embedding和queries = queries + attn_out。这是将原始位置编码重新加入,并通过残差连接强化最终的特征表示,这种设计在SAM的MaskDecoder中是标准做法。- 任务导向的设计:对于分割任务来说,最终输出的是基于点查询(queries)生成的mask。最后一层专门的token-to-image attention确保这些点查询在输出前能够最后一次"阅读"完整的图像特征,这对于生成精确的分割结果至关重要。
- 架构一致性:这种设计借鉴了DETR和MaskFormer等先进模型的思想,在SAM中被证明是有效的标准架构。
简而言之,双向attention blocks负责中间特征的交互和增强,而最后一层专门的token-to-image attention则是为了确保最终的点查询特征能够充分融合图像信息,为下游的mask生成提供最优的特征表示。这不是冗余设计,而是SAM架构中经过验证的关键组件。