一、redis基础命令

1、KEYS的用法:
1. 基本语法
KEYS pattern- pattern:glob 风格的通配符模式。
2. 通配符速记
-
*:匹配任意数量的字符(包括零个)。 -
?:匹配单个任意字符。 -
[]:匹配括号内的任一字符(如user:[123])。
3. 常用示例
KEYS user:* # 查找所有以 "user:" 开头的键
KEYS *name # 查找所有以 "name" 结尾的键
KEYS * # 查找**所有**键 (**极度危险!**)4. 返回值
-
匹配的键名列表。
-
无匹配则返回空列表
(empty array)。
5. 严重警告
-
生产环境禁用!
KEYS会阻塞服务器,遍历所有键,可能导致服务瘫痪。 -
替代方案 :使用
SCAN命令进行增量、非阻塞的迭代查询。
6、一句话总结
KEYS pattern根据模式查找键,但因其阻塞性, 生产环境严禁使用**,请用 SCAN代替。**
2、DEL用法:
1. 基本语法
DEL key [key ...]- 可同时删除一个或多个键。
2. 返回值
- 被成功删除 的键的数量 (
integer)。
3. 常用示例
# 1. 删除单个键
127.0.0.1:6379> DEL mykey
(integer) 1 # 成功删除1个
# 2. 删除多个键
127.0.0.1:6379> DEL key1 key2 key3
(integer) 2 # 只删除了2个存在的键
# 3. 删除不存在的键
127.0.0.1:6379> DEL non_existent_key
(integer) 0 # 返回0,无键被删除4. 核心特点
-
无视数据类型:可删除任何类型的键(String, Hash, List...)。
-
不可逆:删除后数据无法恢复。
-
阻塞风险 :删除超大键(如百万级元素的集合)可能短暂阻塞服务器。
5. 大键删除建议
- 使用
UNLINK key [...]命令代替,它会异步释放内存,避免阻塞。
6、一句话总结
DEL key1 key2 ...删除一个或多个键,返回被删除的数量。生产环境删除大键时,优先使用 UNLINK。
3、EXISTS用法:
1. 基本语法
EXISTS key [key ...]- 可同时检查一个或多个键。
2. 返回值
-
存在的键的总数量 (
integer)。-
> 0:存在的键的数量。 -
0:所有指定的键都不存在。
-
3. 常用示例
# 1. 检查单个键
127.0.0.1:6379> EXISTS mykey
(integer) 1 # 键存在
# 2. 检查多个键
127.0.0.1:6379> EXISTS key1 key2 key3
(integer) 2 # key1 和 key2 存在,key3 不存在
# 3. 检查不存在的键
127.0.0.1:6379> EXISTS non_existent_key
(integer) 0 # 键不存在4. 核心特点
-
极高性能 :时间复杂度为 O(1),无论数据库多大,检查速度都恒定。
-
原子性:检查多个键的过程不会被其他命令打断。
-
常用作条件判断 :在
SET、GET、DEL等操作前,先判断键是否存在。
5、一句话总结
EXISTS key检查键是否存在,返回存在的键的数量 (integer),因 O(1) 的高性能而常用于程序中的条件判断。
4、EXPIRE用法:
1. 基本语法
EXPIRE key seconds- seconds :过期时间,单位为秒。
2. 返回值
-
1:设置成功。 -
0:设置失败(通常因为键不存在)。
3. 常用示例
# 1. 为已存在的键设置过期时间
127.0.0.1:6379> SET mykey "hello"
OK
127.0.0.1:6379> EXPIRE mykey 60
(integer) 1 # 60秒后过期
# 2. 使用 SETEX 原子性设置值和过期时间 (推荐)
127.0.0.1:6379> SETEX cache:page 300 "<html>...</html>"
OK # 等同于 SET + EXPIRE,但更安全高效4. 核心用途
-
为缓存、会话(Session)、验证码等设置生命周期。
-
防止数据永久驻留内存。
5. 配套命令
-
TTL key:查询剩余生存时间(秒)。 -
PERSIST key:移除过期时间,使键永久存在。
6、一句话总结
EXPIRE key seconds为键设置以秒为单位的生存时间,成功返回 1。设置缓存时,优先使用原子性的 SETEX命令。
5、TTL的用法:
1. 基本语法
TTL key- 查询键的剩余生存时间(秒)。
2. 返回值(核心)
-
> 0:键剩余的生存时间(秒)。 -
-1:键存在 ,且永不过期。 -
-2:键不存在或已过期。
3. 常用示例
127.0.0.1:6379> SETEX temp_key 60 "value"
OK
127.0.0.1:6379> TTL temp_key
(integer) 57 # 剩余57秒
127.0.0.1:6379> SET persistent_key "value"
OK
127.0.0.1:6379> TTL persistent_key
(integer) -1 # 永不过期
127.0.0.1:6379> TTL non_existent_key
(integer) -2 # 键不存在4. 核心用途
-
缓存管理:监控缓存新鲜度,决定何时刷新。
-
会话管理:实现滑动过期(Sliding Expiration)。
-
状态检查:区分键是永久的、临时的还是已消失。
5. 配套命令
-
EXPIRE key seconds:设置过期时间。 -
PERSIST key:移除过期时间。 -
PTTL key:查询剩余时间(毫秒精度)。
一句话总结
TTL key查询键的剩余生存时间,返回值 >0(秒)、-1(永不过期)、-2(不存在),是缓存和会话管理的核心诊断工具。
二、Redis命令-String类型

1、SET用法:
1. 基础设置
SET key value
# 例:SET name "Alice"
# => OK2. 设置并指定过期时间(原子操作,推荐)
SET key value EX seconds # 秒
SET key value PX milliseconds # 毫秒
# 例:SET cache "data" EX 60 # 60秒后过期3. 条件性设置(分布式锁核心)
SET key value NX # 仅当键【不存在】时设置
SET key value XX # 仅当键【存在】时设置
# 例:SET lock:order NX EX 10 # 获取锁,10秒自动释放
# => OK (成功) 或 (nil) (失败)4. 更新值但保留原过期时间 (Redis 6.0+)
SET key new_value KEEPTTL
# 例:SET api:data "new" KEEPTTL5. 返回值速记
-
成功 :
OK -
条件不满足 (NX/XX) :
(nil) -
失败: 错误
6、黄金法则
-
设置缓存 :用
SET ... EX -
创建锁 :用
SET ... NX EX -
更新缓存 :用
SET ... KEEPTTL(如需保留TTL) 或直接SET(重置TTL)。
记住这几个组合,足以应对 99% 的场景。
2、GET用法:
1. 基本语法
GET key2. 返回值(核心)
-
键存在且有值 :返回对应的字符串值。
-
键不存在 :返回
(nil)。 -
键存在但类型不是 String :返回错误
(error) WRONGTYPE ...。
3. 常用示例
# 1. 获取存在的键
127.0.0.1:6379> SET name "Bob"
OK
127.0.0.1:6379> GET name
"Bob" # 返回字符串值
# 2. 获取不存在的键
127.0.0.1:6379> GET non_existent_key
(nil) # 返回 nil
# 3. 错误示例:对非字符串键使用 GET
127.0.0.1:6379> LPUSH mylist "item"
(integer) 1
127.0.0.1:6379> GET mylist
(error) WRONGTYPE Operation against a key holding the wrong kind of value4. 核心用途
-
读取缓存数据。
-
检查会话信息。
-
作为
SET命令的"读取"搭档。
5、一句话总结
GET key要么返回键的字符串值,要么返回 (nil),如果类型不对就报错。
3、MSET用法:
好的,这里是 MSET命令用法的超精简核心指南。
1. 基本语法
MSET key1 value1 key2 value2 ...- 原子性 :所有键值对同时设置成功或失败。
2. 返回值
- 总是
OK。
3. 常用示例
# 1. 同时设置多个键值对
127.0.0.1:6379> MSET key1 "val1" key2 "val2" key3 "val3"
OK
# 2. 验证结果
127.0.0.1:6379> GET key1
"val1"
127.0.0.1:6379> GET key2
"val2"4. 与 MGET搭配使用
# 批量设置
127.0.0.1:6379> MSET a 1 b 2 c 3
OK
# 批量获取
127.0.0.1:6379> MGET a b c
1) "1"
2) "2"
3) "3"5. 核心用途
-
高效批量写入 :比多次调用
SET性能更好,且保证原子性。 -
一次性初始化多个配置项或用户属性。
6、一句话总结
MSET k1 v1 k2 v2 ...原子性地同时设置多个键值对,总是返回 OK,常与 MGET搭配进行批量操作。
4、MGET用法:
1. 基本语法
MGET key1 [key2 ...]- 可同时获取一个或多个键的值。
2. 返回值
-
一个列表,按请求的键的顺序返回对应的值。
-
如果某个键不存在,列表中对应位置返回
(nil)。
3. 常用示例
# 1. 批量获取存在的键
127.0.0.1:6379> MSET a "Apple" b "Banana" c "Cherry"
OK
127.0.0.1:6379> MGET a b c
1) "Apple"
2) "Banana"
3) "Cherry"
# 2. 批量获取(包含不存在的键)
127.0.0.1:6379> MGET a d b
1) "Apple" # a 的值
2) (nil) # d 不存在
3) "Banana" # b 的值4. 核心特点
-
原子性:所有键的值在一次调用中返回。
-
高效 :比循环调用多次
GET性能更高。 -
保持顺序:返回值列表的顺序与传入键的顺序一致。
5. 核心用途
- 批量读取:高效地一次性获取多个相关的缓存数据或配置项。
6、一句话总结
MGET key1 key2 ...原子性地批量获取多个键的值,按请求顺序返回列表,不存在的键对应位置为 (nil),性能远高于多次 GET。
5、INCR用法:
1. 基本语法
INCR key- 将键所存储的数字值 增加
1。
2. 返回值
- 增加后的新值 (
integer)。
3. 常用示例
# 1. 对不存在的键执行 INCR,会先将其初始化为 0 再 +1
127.0.0.1:6379> INCR counter
(integer) 1
# 2. 对已存在的数字键执行 INCR
127.0.0.1:6379> INCR counter
(integer) 24. 错误处理
- 如果键的值不是数字 ,会返回错误
(error) ERR value is not an integer or out of range。
5. 变种命令
-
INCRBY key increment:增加指定的整数。INCRBY page_view 5 # 增加 5 -
DECR key:减少1。 -
DECRBY key decrement:减少指定的整数。
6. 核心用途
-
计数器:文章阅读量、网站访客数、API调用次数。
-
生成唯一ID。
-
限流。
7、一句话总结
INCR key将键的值原子性地加 1 并返回新值,是构建高性能计数器的基石。
6、INCRBY用法:
1. 基本语法
INCRBY key increment- increment :要增加的整数数值。
2. 返回值
- 增加后的新值 (
integer)。
3. 常用示例
# 1. 对不存在的键执行 INCRBY,会先初始化为 0 再加上增量
127.0.0.1:6379> INCRBY points 10
(integer) 10
# 2. 对已存在的数字键增加指定值
127.0.0.1:6379> INCRBY points 5
(integer) 154. 错误处理
- 如果键的值不是数字 ,会返回错误
(error) ERR value is not an integer or out of range。
5. 变种命令
-
INCRBYFLOAT key increment:增加一个浮点数。INCRBYFLOAT salary 1500.50 # 增加 1500.50
6. 核心用途
-
精确计数器:增加指定数量的积分、库存、金额。
-
批量ID生成:一次性获取一段ID范围。
7、一句话总结
INCRBY key N将键的值原子性地增加指定的整数 N 并返回新值,是实现精确步长计数的核心命令。
7、INCRBYFLOAT用法:
1. 基本语法
INCRBYFLOAT key increment- increment :要增加的浮点数数值(支持正负数)。
2. 返回值
- 增加后的新值 (
bulk string reply),以字符串形式表示浮点数。
3. 常用示例
# 1. 对不存在的键执行 INCRBYFLOAT,会先初始化为 0 再加上增量
127.0.0.1:6379> INCRBYFLOAT balance 99.95
"99.95"
# 2. 对已存在的浮点数字键增加指定值
127.0.0.1:6379> INCRBYFLOAT balance 0.05
"100"
# 3. 支持负数(相当于减法)
127.0.0.1:6379> INCRBYFLOAT balance -20.50
"79.5"4. 核心特点
-
高精度 :处理浮点数运算,避免
INCRBY只能处理整数的限制。 -
原子性:保证在高并发下的计算准确性。
-
返回值:始终是字符串格式,以避免二进制浮点数的精度问题。
5. 核心用途
-
金融计算:处理金额、账户余额、股票持仓等需要小数的场景。
-
科学计量:记录重量、温度、百分比等浮点数指标。
6、一句话总结
INCRBYFLOAT key float_increment将键的值原子性地增加指定的浮点数并返回新值(字符串),是处理金额等高精度计算的必备命令。
8、SETNX用法:
重要提示 :
SETNX命令在现代 Redis 开发中已不推荐 使用。它的功能已被更强大的SET key value NX选项所取代。但了解它仍有历史意义。
1. 基本语法
SETNX key value- SET if Not eXists 的缩写。
2. 返回值
-
1:键不存在 ,设置成功。 -
0:键已存在 ,设置失败。
3. 常用示例
# 1. 键不存在,设置成功
127.0.0.1:6379> SETNX lock:order_123 "process_A"
(integer) 1
# 2. 键已存在,设置失败
127.0.0.1:6379> SETNX lock:order_123 "process_B"
(integer) 0
# 3. 验证结果
127.0.0.1:6379> GET lock:order_123
"process_A" # 仍然是 process_A4. 致命缺点 & 现代替代方案
-
非原子性 :
SETNX无法同时设置过期时间。在SETNX成功后,必须再调用EXPIRE,这两步操作之间存在竞态条件窗口,可能导致锁永远不会释放。# 不安全的做法! SETNX lock:order "me" EXPIRE lock:order 10 # 如果此时Redis崩溃,锁将永久存在! -
现代推荐 :使用
SET命令的NX和EX选项,它们是原子性的。# 安全且推荐的分布式锁写法 SET lock:order "me" NX EX 10
5、一句话总结
SETNX key value仅当键不存在时设置值,返回 1(成功)/0(失败)。因无法原子性设置过期时间,在 Redis 2.6.12+ 中已被 SET key value NX EX取代,不应在新代码中使用。
9、SETEX用法:
1. 基本语法
SETEX key seconds value-
SET + EXpire 的原子操作组合。
-
seconds :过期时间,单位为秒。
2. 返回值
- 总是
OK。
3. 常用示例
# 设置一个缓存,内容在 300 秒(5分钟)后自动过期
127.0.0.1:6379> SETEX cache:user:1001 300 "{...json data...}"
OK
# 验证
127.0.0.1:6379> TTL cache:user:1001
(integer) 297 # 剩余约297秒4. 核心优势
- 原子性 :
SET和EXPIRE两步操作合并为一步,避免了在中间环节 Redis 崩溃导致键永久存在的问题。
5. 现代等价写法
在 Redis 2.6.12+ 中,SETEX的功能完全可以被 SET命令的选项替代,且后者更灵活。
# SETEX 写法
SETEX key 60 "value"
# 等价的现代 SET 写法 (推荐,因为选项更清晰)
SET key "value" EX 606. 核心用途
- 缓存写入 :创建带有生存时间的缓存项是
SETEX最经典的应用。
7、一句话总结
SETEX key seconds value原子性地设置键值并指定过期时间(秒)。在 Redis 新版本中,其功能已被更灵活的 SET key value EX seconds取代,但仍可使用。
三、Redis命令- Key的层级格式

四、Redis命令- Hash类型

1、HSET key field value用法:
1. 基本语法
HSET key field value [field value ...]- 为哈希表(Hash)中的一个或多个字段(field)设置值。
2. 返回值
-
新添加的字段数量 (
integer)。-
如果设置单个字段且该字段是新的,返回
1。 -
如果设置单个字段但该字段已存在(覆盖),返回
0。 -
如果同时设置多个字段,返回新添加字段的总数。
-
3. 常用示例
# 1. 设置单个字段
127.0.0.1:6379> HSET user:1001 name "Alice"
(integer) 1 # 新字段,返回1
# 2. 更新已存在的字段
127.0.0.1:6379> HSET user:1001 name "Bob"
(integer) 0 # 字段已存在,被覆盖,返回0
# 3. 原子性地设置多个字段 (推荐)
127.0.0.1:6379> HSET user:1001 age 30 email "alice@example.com"
(integer) 2 # 假设 age 和 email 都是新字段4. 核心特点
-
数据结构:操作的是 Hash 类型,适合存储对象(如用户信息、商品属性)。
-
原子性:单次调用可设置多个字段,保证操作的原子性。
-
高效 :相比将整个对象序列化成 JSON 字符串再用
SET存储,HSET/HGET可以更精细地读写单个字段,节省带宽和CPU。
5. 核心用途
-
存储对象:最经典的用法,将一个对象的多个属性存储在同一个 Hash 键下。
-
部分更新:无需读取整个对象,即可更新其中的一两个字段。
6、一句话总结
HSET key field value为 Hash 表的字段设置值,返回新添加字段数。它是存储和操作对象属性的高效、原子性命令,支持同时设置多个字段。
2、HGET key field用法:
1. 基本语法
HGET key field- 获取哈希表(Hash)中指定字段(field)的值。
2. 返回值
-
字段存在 :返回对应的字符串值。
-
字段不存在 :返回
(nil)。 -
键不存在或非 Hash 类型 :返回
(nil)或错误。
3. 常用示例
# 1. 获取存在的字段
127.0.0.1:6379> HSET profile name "Alice" age "30"
(integer) 2
127.0.0.1:6379> HGET profile name
"Alice"
# 2. 获取不存在的字段
127.0.0.1:6379> HGET profile city
(nil)4. 核心特点
-
精准读取:只获取对象的一个属性,无需读取整个对象。
-
高效 :相比
GET一个大的 JSON 字符串再反序列化,性能更高。
5. 配套命令
-
HSET key field value:设置字段值。 -
HMGET key field1 [field2]:批量获取多个字段值。 -
HGETALL key:获取所有字段和值。
6、一句话总结
HGET key field获取 Hash 表中指定字段的值,返回字符串或 (nil),是读取对象单个属性的高效命令。
3、HMSET用法:
1. 基本语法
HMSET key field1 value1 [field2 value2 ...]- 为哈希表(Hash)中的多个字段(field)同时设置值。
2. 返回值
- 总是
OK。
3. 常用示例
# 一次性设置 user:1001 的多个属性
127.0.0.1:6379> HMSET user:1001 name "Alice" age 30 email "alice@example.com"
OK4. 核心特点与现状
-
原子性:所有字段的设置操作在一个原子步骤内完成。
-
已废弃 :在 Redis 4.0.0 及更高版本中,
HMSET被视为过时命令。 -
现代替代 :官方推荐使用功能更全面的
HSET命令来代替HMSET,因为HSET在新版本中也支持同时设置多个字段。
5. 推荐用法 (使用 HSET)
# 新版本中,应优先使用 HSET 来完成 HMSET 的工作
127.0.0.1:6379> HSET user:1001 name "Alice" age 30 email "alice@example.com"
(integer) 3 # 返回新添加的字段数量注意:HSET返回新字段的数量,而 HMSET只返回 OK。
6. 核心用途
- 批量更新对象属性:在需要一次性写入对象的多个字段时使用。
7、一句话总结
HMSET key f1 v1 ...用于批量设置 Hash 字段,但因已废弃,在新代码中应优先使用支持多字段的 HSET命令。
4、HMGET用法:
1. 基本语法
HMGET key field1 [field2 ...]- 从哈希表(Hash)中批量获取一个或多个指定字段的值。
2. 返回值
-
一个列表,按请求的字段顺序返回对应的值。
-
如果某个字段不存在,列表中对应位置返回
(nil)。
3. 常用示例
# 1. 先准备一个哈希数据
127.0.0.1:6379> HSET product:123 name "Laptop" price 999 stock 50
(integer) 3
# 2. 批量获取多个字段
127.0.0.1:6379> HMGET product:123 name price description
1) "Laptop" # name 的值
2) "999" # price 的值
3) (nil) # description 字段不存在4. 核心特点
-
原子性:所有字段的值在一次调用中返回,保证数据一致性。
-
保持顺序:返回值列表的顺序与传入字段的顺序严格一致。
-
高效 :比循环调用多次
HGET性能更高,减少了网络往返。
5. 核心用途
- 批量读取对象属性:一次性获取一个对象的多个字段,避免多次网络请求。
6. 配套命令
-
HGET key field:获取单个字段。 -
HGETALL key:获取所有字段和值(慎用,如果字段很多会影响性能)。 -
HSET/HMSET:设置字段值。
7、一句话总结
HMGET key f1 f2 ...原子性地批量获取 Hash 表中多个字段的值,按请求顺序返回列表,不存在的字段对应位置为 (nil),性能远高于多次 HGET。
5、HGETALL用法:
1. 基本语法
HGETALL key- 获取哈希表(Hash)中所有的字段(field)和值(value)。
2. 返回值
-
一个列表,其中奇数个元素 是字段名,偶数个元素是对应的值。
- 格式:
[field1, value1, field2, value2, ...]
- 格式:
3. 常用示例
# 1. 先准备一个哈希数据
127.0.0.1:6379> HSET profile name "Alice" age "30" city "Beijing"
(integer) 3
# 2. 获取所有字段和值
127.0.0.1:6379> HGETALL profile
1) "name" # 字段名
2) "Alice" # 字段值
3) "age"
4) "30"
5) "city"
6) "Beijing"4. 核心特点与警告
-
原子性:一次性返回所有数据。
-
性能风险 :如果哈希表包含成千上万个 字段,此命令会阻塞 Redis 服务器,并消耗大量网络带宽。
-
慎用场景 :绝对不要 对大型哈希表使用
HGETALL。
5. 安全替代方案
-
使用
HSCAN命令 :它可以像SCAN遍历键一样,渐进式、分批地迭代哈希表中的字段,避免阻塞。# 安全迭代 profile 中的所有字段 HSCAN profile 0 MATCH * COUNT 10
6. 核心用途
-
快速查看小型哈希表的内容(例如在调试或管理工具中)。
-
获取字段数量有限的对象的全部属性。
7、一句话总结
HGETALL key返回哈希表的所有字段和值,但对于大型哈希表会严重阻塞服务器,生产环境中应优先使用 HSCAN进行安全迭代。
6、HKEYS用法:
1. 基本语法
HKEYS key- 获取哈希表(Hash)中所有的字段(field)名。
2. 返回值
-
一个列表,包含哈希表中所有的字段名。
-
如果键不存在或哈希表为空,返回空列表
(empty list or set)。
3. 常用示例
# 1. 先准备一个哈希数据
127.0.0.1:6379> HSET config theme "dark" lang "zh-CN" timeout "30"
(integer) 3
# 2. 获取所有字段名
127.0.0.1:6379> HKEYS config
1) "theme"
2) "lang"
3) "timeout"4. 核心特点与警告
-
性能风险 :和
HGETALL一样,如果哈希表非常大,此命令会阻塞服务器。 -
慎用场景 :绝对不要 对包含大量字段的大型哈希表使用
HKEYS。
5. 安全替代方案
-
使用
HSCAN命令:进行渐进式、分批的字段名迭代,避免阻塞。# 安全迭代 config 中的所有字段名 HSCAN config 0 MATCH * COUNT 10
6. 核心用途
-
快速查看小型哈希表的结构(有哪些字段)。
-
在调试或管理工具中列出对象的属性名。
7、一句话总结
HKEYS key返回哈希表的所有字段名,但对大型哈希表有阻塞风险,生产环境中应优先使用 HSCAN进行安全迭代。
7、HVALS用法:
1. 基本语法
HVALS key- 获取哈希表(Hash)中所有的值(value)。
2. 返回值
-
一个列表,包含哈希表中所有的值。
-
如果键不存在或哈希表为空,返回空列表
(empty list or set)。
3. 常用示例
# 1. 先准备一个哈希数据
127.0.0.1:6379> HSET config theme "dark" lang "zh-CN" timeout "30"
(integer) 3
# 2. 获取所有值
127.0.0.1:6379> HVALS config
1) "dark"
2) "zh-CN"
3) "30"4. 核心特点与警告
-
性能风险 :和
HGETALL、HKEYS一样,如果哈希表非常大,此命令会阻塞服务器。 -
慎用场景 :绝对不要 对包含大量字段的大型哈希表使用
HVALS。
5. 安全替代方案
-
使用
HSCAN命令 :进行渐进式、分批的迭代,避免阻塞。虽然HSCAN默认返回字段和值,但可以只提取其中的值。# 安全迭代 config 中的所有字段和值,然后在客户端处理结果 HSCAN config 0 MATCH * COUNT 10
6. 核心用途
-
快速查看小型哈希表中存储了哪些数据(不关心字段名)。
-
在调试或管理工具中获取对象的所有属性值。
7、一句话总结
HVALS key返回哈希表的所有值,但对大型哈希表有阻塞风险,生产环境中应优先使用 HSCAN进行安全迭代。
8、HINCRBY用法:
1. 基本语法
HINCRBY key field increment- 为哈希表中指定字段的值增加指定的整数。
2. 返回值
- 增加后的新值 (
integer)。
3. 常用示例
# 1. 对不存在的字段执行 HINCRBY,会先将其初始化为 0 再 +increment
127.0.0.1:6379> HINCRBY product:123 stock 5
(integer) 5
# 2. 对已存在的数字字段增加指定值
127.0.0.1:6379> HINCRBY product:123 stock 3
(integer) 84. 错误处理
- 如果字段的值不是数字 ,会返回错误
(error) ERR hash value is not an integer。
5. 变种命令
-
HINCRBYFLOAT key field increment:增加一个浮点数。HINCRBYFLOAT product:123 price 1.99 # 价格增加 1.99
6. 核心用途
- 对象内计数器 :为商品的库存(
stock)、文章的阅读量(views)、用户的积分(points)等字段进行原子性增减。
7、一句话总结
HINCRBY key field N将哈希表指定字段的值原子性地增加指定的整数 N 并返回新值,是实现对象内部计数器的核心命令。
9、HSETNX用法:
1. 基本语法
HSETNX key field value-
H ash SET if N ot eXists 的缩写。
-
仅当哈希表中的指定字段不存在时,才设置其值。
2. 返回值
-
1:字段不存在 ,设置成功。 -
0:字段已存在 ,设置失败(值保持不变)。
3. 常用示例
# 1. 字段不存在,设置成功
127.0.0.1:6379> HSETNX user:1001 nickname "AliceInWonderland"
(integer) 1
# 2. 字段已存在,设置失败,原有值不会被覆盖
127.0.0.1:6379> HSETNX user:1001 nickname "BobTheBuilder"
(integer) 0
127.0.0.1:6379> HGET user:1001 nickname
"AliceInWonderland" # 值依然是 Alice4. 核心特点
-
原子性:检查字段是否存在和设置值是一个不可分割的操作。
-
条件性写入:保证字段的值只在第一次被设置,后续操作不会改变它。
5. 核心用途
-
初始化对象属性:确保一个对象的某个属性(如首次访问时间、默认配置)只被设置一次。
-
实现锁或标志位:在哈希表内部创建一个唯一的、不可覆盖的标志。
6. 配套命令
-
HSET key field value:无条件设置字段值(会覆盖)。 -
HEXISTS key field:检查字段是否存在。
7、一句话总结
HSETNX key field value仅当哈希表的字段不存在时才设置它,返回 1(成功)/0(失败),是保证属性只被初始化一次的原子性命令。
五、Redis命令-List类型
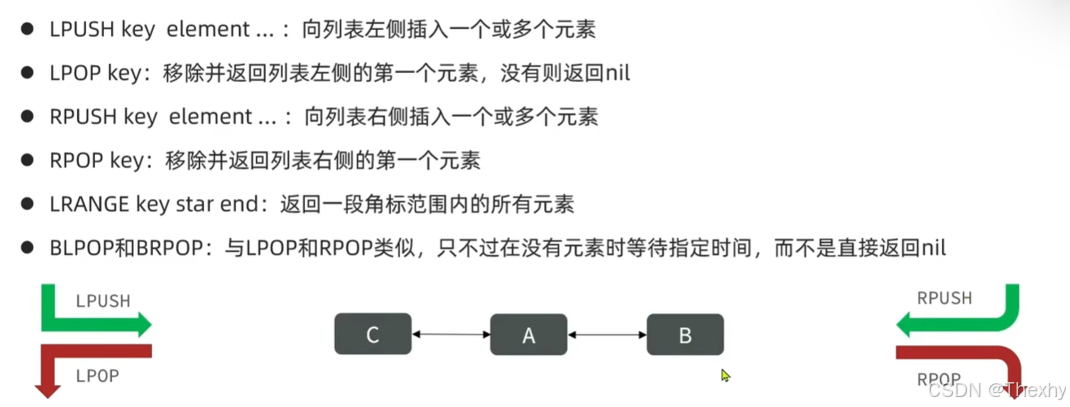
1、LPUSH key element用法:
好的,这里是 LPUSH key element命令用法的超精简核心指南。
1. 基本语法
LPUSH key element [element ...]- 将一个或多个元素插入到列表(List)的头部(左侧)。
2. 返回值
- 执行
LPUSH后,列表的新长度 (integer)。
3. 常用示例
# 1. 从左侧插入单个元素
127.0.0.1:6379> LPUSH tasks "buy milk"
(integer) 1
# 2. 从左侧插入多个元素(注意插入顺序)
127.0.0.1:6379> LPUSH tasks "write report" "check emails"
(integer) 3 # 列表现在有3个元素
# 3. 查看列表内容 (从左至右显示)
127.0.0.1:6379> LRANGE tasks 0 -1
1) "check emails" # 最后 LPUSH 的元素在列表最左边
2) "write report"
3) "buy milk" # 最先 LPUSH 的元素在列表最右边4. 核心特点
-
头部插入:新元素总是被添加到列表的最左端。
-
顺序反转 :当插入多个元素时,它们在列表中的顺序与输入参数的顺序是相反的。
-
创建列表:如果键不存在,会先创建一个空列表再执行推送。
5. 核心用途
-
消息队列:用作栈(Stack),实现后进先出(LIFO)的逻辑。最新的任务或消息排在最前面。
-
最新项目列表 :维护一个固定长度的最新帖子、日志或通知列表(常配合
LTRIM使用)。
6. 配套命令
-
RPUSH key element:从列表**尾部(右侧)**插入。 -
LPOP key:从列表头部移除并返回一个元素。 -
LRANGE key start stop:获取列表指定范围内的元素。
7、一句话总结
LPUSH key elem将一个或多个元素原子性地插入列表头部,返回新长度。新元素在列表最左,多元素时顺序反转,是实现栈结构的核心命令。
2、LPOP key用法:
1. 基本语法
LPOP key- 移除并返回列表(List)的**头部(左侧)**元素。
2. 返回值
-
列表的头部元素(字符串)。
-
如果键不存在或列表为空,返回
(nil)。
3. 常用示例
# 1. 从一个非空列表中弹出头部元素
127.0.0.1:6379> RPUSH mylist "one" "two" "three" # 先创建列表 ["one", "two", "three"]
(integer) 3
127.0.0.1:6379> LPOP mylist
"one" # 返回并移除了最左侧的元素
# 2. 查看弹出后的列表
127.0.0.1:6379> LRANGE mylist 0 -1
1) "two"
2) "three"
# 3. 从空列表中弹出
127.0.0.6379> LPOP empty_list
(nil)4. 核心特点
-
原子性操作:移除和返回是原子性的。
-
破坏性读取:读取后即删除该元素。
-
栈的出栈操作 :与
LPUSH配合,实现后进先出(LIFO)的栈。
5. 变种命令
-
LPOP key count(Redis 6.2+): 一次从列表头部弹出多个元素。LPOP mylist 2 # 一次弹出2个元素
6. 核心用途
-
消息队列/栈:作为消费者,从队列头部获取任务(如果是栈结构)。
-
遍历列表 :通过循环
LPOP来处理列表中的所有元素。
7. 配套命令
-
RPOP key:从列表尾部移除并返回元素。 -
LPUSH key element:向列表头部插入元素。 -
BLPOP key [key ...] timeout:阻塞版本的LPOP,列表为空时会等待。
8、一句话总结
LPOP key移除并返回列表头部的元素,返回该元素或 (nil),是与 LPUSH搭配实现栈结构的核心命令。
3、RPUSH key element用法:
1. 基本语法
RPUSH key element [element ...]- 将一个或多个元素插入到列表(List)的尾部(右侧)。
2. 返回值
- 执行
RPUSH后,列表的新长度 (integer)。
3. 常用示例
# 1. 从尾部插入单个元素
127.0.0.1:6379> RPUSH queue "task1"
(integer) 1
# 2. 从尾部插入多个元素(注意插入顺序)
127.0.0.1:6379> RPUSH queue "task2" "task3"
(integer) 3 # 列表现在有3个元素
# 3. 查看列表内容 (从左至右显示)
127.0.0.1:6379> LRANGE queue 0 -1
1) "task1" # 最先 RPUSH 的元素在列表最左边
2) "task2"
3) "task3" # 最后 RPUSH 的元素在列表最右边4. 核心特点
-
尾部插入:新元素总是被添加到列表的最右端。
-
顺序保持 :当插入多个元素时,它们在列表中的顺序与输入参数的顺序是一致的。
-
创建列表:如果键不存在,会先创建一个空列表再执行推送。
5. 核心用途
-
消息队列:用作标准队列(Queue),实现先进先出(FIFO)的逻辑。最早进入的任务排在最前面。
-
时间线/记录:维护按时间顺序排列的记录,如用户动态、操作日志等。
6. 配套命令
-
LPUSH key element:从列表**头部(左侧)**插入。 -
RPOP key:从列表尾部移除并返回一个元素。 -
LRANGE key start stop:获取列表指定范围内的元素。
7、一句话总结
RPUSH key elem将一个或多个元素原子性地插入列表尾部,返回新长度。新元素在列表最右,多元素时顺序不变,是实现队列结构的核心命令。
4、RPOP key用法:
1. 基本语法
RPOP key- 移除并返回列表(List)的**尾部(右侧)**元素。
2. 返回值
-
列表的尾部元素(字符串)。
-
如果键不存在或列表为空,返回
(nil)。
3. 常用示例
# 1. 从一个非空列表中弹出尾部元素
127.0.0.1:6379> RPUSH mylist "one" "two" "three" # 先创建列表 ["one", "two", "three"]
(integer) 3
127.0.0.1:6379> RPOP mylist
"three" # 返回并移除了最右侧的元素
# 2. 查看弹出后的列表
127.0.0.1:6379> LRANGE mylist 0 -1
1) "one"
2) "two"
# 3. 从空列表中弹出
127.0.0.1:6379> RPOP empty_list
(nil)4. 核心特点
-
原子性操作:移除和返回是原子性的。
-
破坏性读取:读取后即删除该元素。
-
队列的出队操作 :与
RPUSH配合,实现先进先出(FIFO)的队列。
5. 变种命令
-
RPOP key count(Redis 6.2+): 一次从列表尾部弹出多个元素。RPOP mylist 2 # 一次弹出2个元素
6. 核心用途
-
消息队列:作为消费者,从队列尾部获取任务(实现FIFO)。
-
遍历列表 :通过循环
RPOP来处理列表中的所有元素。
7. 配套命令
-
LPOP key:从列表头部移除并返回元素。 -
RPUSH key element:向列表尾部插入元素。 -
BRPOP key [key ...] timeout:阻塞版本的RPOP,列表为空时会等待。
8、一句话总结
RPOP key移除并返回列表尾部的元素,返回该元素或 (nil),是与 RPUSH搭配实现队列(FIFO)结构的核心命令。
5、LRANGE key star end用法:
1. 基本语法
LRANGE key start stop- 获取列表(List)中指定范围内的所有元素。
2. 参数含义
-
start: 起始索引(从 0 开始)。负数表示从尾部开始计数(-1 是最后一个元素)。 -
stop: 结束索引。负数表示从尾部开始计数(-1 是最后一个元素)。 -
闭区间 :返回的结果包含
start和stop索引处的元素。
3. 常用示例
# 准备一个列表: mylist -> ["a", "b", "c", "d", "e"]
127.0.0.1:6379> RPUSH mylist a b c d e
(integer) 5
# 1. 获取所有元素
127.0.0.1:6379> LRANGE mylist 0 -1
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
# 2. 获取前3个元素 (索引 0, 1, 2)
127.0.0.1:6379> LRANGE mylist 0 2
1) "a"
2) "b"
3) "c"
# 3. 获取最后2个元素 (索引 -2, -1)
127.0.0.1:6379> LRANGE mylist -2 -1
1) "d"
2) "e"4. 核心特点
-
只读:不会修改原始列表。
-
高性能 :对于大范围的查询(如
0 -1),如果列表很大,可能会。 -
索引越界 :如果
start超出列表范围,返回空列表。如果stop超出范围,则截取到列表末尾。
5. 核心用途
-
分页查询:获取列表的一部分数据。
-
查看列表内容:在调试或展示时获取全部或部分元素。
6、一句话总结
LRANGE key start stop获取列表中指定索引范围的所有元素,支持负索引,-1代表最后一个元素,是查看列表内容的只读命令。
6、BLPOP和BRPOP用法:
1. 基本语法
BLPOP key [key ...] timeout # 阻塞式从【头部】弹出
BRPOP key [key ...] timeout # 阻塞式从【尾部】弹出- timeout :超时时间(秒)。
0表示无限期阻塞。
2. 返回值
-
有元素可弹出 :返回一个包含两个元素的数组
[key, popped_element]。 -
超时 :如果在指定时间内所有列表都为空,则返回
(nil)。
3. 常用示例
# 场景:两个生产者,一个消费者
# 1. 客户端A:启动一个消费者,监听 task_queue1 和 task_queue2,无限期阻塞
127.0.0.1:6379> BLPOP task_queue1 task_queue2 0
# (阻塞中...)
# 2. 客户端B:向 task_queue1 推入一个任务
127.0.0.1:6379> LPUSH task_queue1 "send_email"
(integer) 1
# 3. 客户端A 立即返回结果
1) "task_queue1" # 从哪个键弹出的
2) "send_email" # 弹出的元素
# BRPOP 同理,只是从尾部弹出
127.0.0.1:6379> BRPOP task_queue1 5 # 最多阻塞5秒
# ... 5秒内无元素则返回 (nil)4. 核心特点
-
阻塞性:当所有给定的键都为空时,命令会阻塞连接,直到有其他客户端推入元素或超时。
-
轮询机制 :如果监听多个键,它会按参数顺序依次检查每个键,并从第一个非空的键中弹出元素。
-
单线程友好:在阻塞期间,不会占用 Redis 服务器的 CPU 资源。
5. 核心用途
-
可靠的消息队列:构建生产者-消费者模型,消费者可以安全地等待新任务的到来,无需忙等待(busy-waiting)。
-
等待某个事件的发生:例如,等待用户完成某项操作。
6、一句话总结
BLPOP/BRPOP key [key ...] timeout是阻塞版的 LPOP/RPOP,当列表为空时会等待,直到有元素可用或超时,是构建可靠消息队列的核心命令。
六、Redis命令-set类型

1、SADD key member...用法:
1. 基本语法
SADD key member [member ...]- 向集合(Set)中添加一个或多个成员(member)。
2. 返回值
-
新添加成功的成员数量 (
integer)。-
如果成员已存在,则不会重复添加,也不会计入成功数量。
-
如果键不存在,会先创建一个空集合再执行添加。
-
3. 常用示例
# 1. 向集合添加单个成员
127.0.0.1:6379> SADD tags "redis"
(integer) 1
# 2. 向集合添加多个成员(含重复项)
127.0.0.1:6379> SADD tags "database" "cache" "redis"
(integer) 2 # 只添加了 "database" 和 "cache","redis" 已存在
# 3. 验证结果
127.0.0.1:6379> SMEMBERS tags
1) "redis"
2) "database"
3) "cache"4. 核心特点
-
唯一性 :集合内的成员是唯一且无序的,自动去重。
-
无序性:成员没有固定的顺序。
-
原子性:单次调用添加多个成员是原子操作。
5. 核心用途
-
标签系统:为用户、文章等打标签。
-
好友关系:存储用户的关注者或好友 ID。
-
去重:快速过滤重复的数据。
6. 配套命令
-
SMEMBERS key:获取集合中的所有成员。 -
SISMEMBER key member:检查成员是否存在于集合中。 -
SREM key member:从集合中移除成员。
7、一句话总结
SADD key member...向集合添加一个或多个成员,自动去重,返回成功添加的新成员数量,是实现标签、好友等唯一性集合的基石。
2、SREM key member...用法:
1. 基本语法
SREM key member [member ...]- 从集合(Set)中移除一个或多个指定的成员(member)。
2. 返回值
-
**成功移除的成员integer`)。
-
如果指定的成员不存在于集合中,则忽略该成员,不计入成功数量。
-
如果键不存在,也视为所有成员都不存在,返回
0。
-
3. 常用示例
# 1. 准备一个集合
127.0.0.1:6379> SADD fruits "apple" "banana" "orange" "grape"
(integer) 4
# 2. 移除单个存在的成员
127.0.0.1:6379> SREM fruits "banana"
(integer) 1 # 成功移除1个
# 3. 移除多个成员(含不存在的成员)
127.0.0.1:6379> SREM fruits "apple" "kiwi" "grape"
(integer) 2 # 只移除了 "apple" 和 "grape","kiwi" 不存在
# 4. 验证结果
127.0.0.1:6379> SMEMBERS fruits
1) "orange"4. 核心特点
-
精确移除:只移除明确指定的成员。
-
静默失败:尝试移除不存在的成员不会报错,只是返回的成功数量为 0。
-
原子性:单次调用移除多个成员是原子操作。
5. 核心用途
- 管理标签/关系 :取消用户的某个标签、移除好友关系 数据清理:从集合中删除不再需要的元素。
6. 配套命令
-
SADD key member:向集合添加成员。 -
SMEMBERS key:获取集合中的所有成员。 -
SISMEMBER key member:检查成员是否存在于集合中。
7、一句话总结
SREM key member...从集合中移除一个或多个指定的成员,返回成功移除的数量,是管理集合成员的核心删除命令。
3、SCARD key...用法:
1. 基本语法
SCARD key- 获取集合(Set)的基数(Cardinality),即成员的数量**。
2. 返回值
-
集合中成员的数量 (
integer)。 -
如果键不存在,返回
0(因为空集合的基数为0)。
3. 常用示例
# 1. 准备一个集合
127.0.0.1:6379> SADD tags "redis" "database" "cache"
(integer) 3
# 2. 获取集合的成员数量
127.0.0.1:6379> SCARD tags
(integer) 3
# 3. 对不存在的键使用 SCARD
127.0.0.1:6379> SCARD non_existent_set
(integer) 04. 核心特点
-
高性能 :时间复杂度为 O(1),无论集合有多大,计算速度都恒定。
-
只读:不会修改原始集合。
5. 核心用途
-
快速计数:统计粉丝数、在线人数、标签数量等。
-
容量检查:在执行某些操作前,先判断集合是否为空或达到上限。
6. 配套命令
-
SADD key member:向集合添加成员。 -
SREM key member:从集合移除成员。 -
SMEMBERS key:获取所有成员(慎用,如果集合很大)。
7、一句话总结
SCARD key返回集合中成员的数量(基数),时间复杂度为 O(1),是进行快速计数的核心命令。
4、SISMEMBER key member用法:
1. 基本语法
SISMEMBER key member- 检查指定的
member是否存在于集合(Set)中。
2. 返回值
-
1:成员 存在 于集合中。 -
0:成员 不存在 于集合中,或者键本身不存在。
3. 常用示例
# 1. 准备一个集合
127.0.0.1:6379> SADD admins "alice" "bob"
(integer) 2
# 2. 检查存在的成员
127.0.0.1:6379> SISMEMBER admins "alice"
(integer) 1 # alice 是管理员
# 3. 检查不存在的成员
127.0.0.1:6379> SISMEMBER admins "charlie"
(integer) 0 # charlie 不是管理员
# 4. 检查不存在的集合
127.0.0.1:6379> SISMEMBER non_existent_set "anyone"
(integer) 0 # 集合不存在,所以成员也不存在4. 核心特点
-
高性能 :时间复杂度为 O(1),无论集合有多大,检查速度都恒定。
-
布尔型查询:常用于权限校验、关系判断等需要"是/否"答案的场景。
5. 核心用途
-
权限校验:判断用户是否是某个角色(如管理员)的一员。
-
关系判断:检查用户是否关注了某个话题、是否拥有某物品。
-
去重判断:在添加数据前,快速判断其是否已存在。
6. 配套命令
-
SADD key member:向集合添加成员。 -
SREM key member:从集合移除成员。 -
SCARD key:获取集合成员总数。
7、一句话总结
SISMEMBER key member检查成员是否存在于集合中,返回 1(存在) 或 0(不存在),因 O(1) 的高性能而常用于程序中的权限和关系判断。
5、SMEMBERS用法:
1. 基本语法
SMEMBERS key- 获取集合(Set)中所有的成员。
2. 返回值
-
包含所有成员的列表(
list-reply)。 -
如果键不存在,返回空列表
(empty list or set)。
3. 常用示例
# 1. 准备一个集合
127.0.0.1:6379> SADD languages "Python" "Java" "Go" "Rust"
(integer) 4
# 2. 获取所有成员
127.0.0.1:6379> SMEMBERS languages
1) "Python"
2) "Java"
3) "Go"
4) "Rust"
# 3. 对不存在的键使用 SMEMBERS
127.0.0.1:6379> SMEMBERS non_existent_set
(empty list or set)4. 核心特点与警告
-
无序性 :返回的列表顺序不能保证 是固定的,每次调用可能不同。如果需要有序结果,请使用
SSORTED SETS(ZSET) 或SORT命令。 -
性能风险 :绝对不要 对包含成千上万个 成员的大型集合使用
SMEMBERS。此命令会一次性将所有成员加载到内存中,可能导致服务器阻塞或内存溢出。
5. 安全替代方案
-
使用
SSCAN命令 :它可以像SCAN遍历键一样,渐进式、分批地迭代集合中的成员,避免阻塞。# 安全迭代 languages 中的所有成员 SSCAN languages 0 MATCH * COUNT 10
6. 核心用途
-
快速查看小型集合的全部内容(例如在调试或管理工具中)。
-
获取成员数量有限的集合的所有元素。
7、一句话总结
SMEMBERS key返回集合的所有成员,但因其无序性和潜在的性能风险,对大型集合应优先使用 SSCAN进行安全迭代。
6、SINTER key1 key2 ...用法:
1. 基本语法
SINTER key1 [key2 ...]- 计算给定的一个或多个集合的交集(Intersection),返回所有集合中都存在的成员。
2. 返回值
-
包含交集成员的列表(
list-reply)。 -
如果没有交集或任何一个键不存在,返回空列表
(empty list or set)。
3. 常用示例
# 1. 准备两个集合
127.0.0.1:6379> SADD candidates_A "Alice" "Bob" "Charlie"
(integer) 3
127.0.0.1:6379> SADD candidates_B "Bob" "David" "Eve"
(integer) 3
# 2. 找出同时存在于两个集合中的候选人
127.0.0.1:6379> SINTER candidates_A candidates_B
1) "Bob" # Bob 是唯一的共同候选人
# 3. 计算三个集合的交集
127.0.0.1:6379> SADD candidates_C "Bob" "Frank"
(integer) 1
127.0.0.1:6379> SINTER candidates_A candidates_B candidates_C
1) "Bob"4. 核心特点
-
数学运算:执行标准的集合交集运算。
-
原子性:所有集合的交集计算在一个原子步骤内完成。
-
性能:如果参与计算的集合非常大,可能会消耗较多 CPU 和内存。
5. 变种命令
SINTERSTORE destination key1 [key2 ...]:将交集结果存储 到一个新的键destination中,而不是直接返回。这在需要复用结果集时非常有用。
6. 核心用途
-
共同好友/兴趣:找出同时是两个用户的好友的人,或拥有共同兴趣爱好的用户。
-
标签筛选:筛选出同时拥有多个标签的商品或文章。
-
权限计算:找出同时满足多项条件的用户群体。
7、一句话总结
SINTER key1 key2 ...计算多个集合的交集并返回共有成员,是实现共同好友、多标签筛选等功能的数学基石。
7、SDIFF key1 key2...:用法:
1. 基本语法
SDIFF key1 [key2 ...]- 计算给定集合的差集 (Difference),返回在第一个集合
key1中,但不在任何其他集合 (key2, ...) 中的成员。
2. 返回值
-
包含差集成员的列表(
list-reply)。 -
如果
key1不存在,返回空列表(empty list or set)。
3. 常用示例
# 1. 准备两个集合
127.0.0.1:6379> SADD all_users "Alice" "Bob" "Charlie" "David"
(integer) 4
127.0.0.1:6379> SADD paid_users "Bob" "David"
(integer) 2
# 2. 找出在 all_users 中但不在 paid_users 中的用户 (即免费用户)
127.0.0.1:6379> SDIFF all_users paid_users
1) "Alice"
2) "Charlie"
# 3. 多个集合的差集 (在 A 中,但不在 B 和 C 中)
127.0.0.1:6379> SADD banned_users "Alice"
(integer) 1
127.0.0.1:6379> SDIFF all_users paid_users banned_users
1) "Charlie" # 只有 Charlie 是既不是付费用户也不是被禁用户4. 核心特点
-
顺序敏感 :差集的计算强烈依赖 于第一个键
key1。SDIFF A B和SDIFF B A的结果是不同的。 -
数学运算:执行标准的集合差集运算。
5. 变种命令
SDIFFSTORE destination key1 [key2 ...]:将差集结果存储 到一个新的键destination中,而不是直接返回。
6. 核心用途
-
找出独有元素:例如,找出所有注册用户中尚未付费的用户、找出商品库中独有的 SKU 等。
-
数据对比与过滤:从一个基准集合中排除掉其他集合包含的干扰项。
7、一句话总结
SDIFF key1 key2 ...计算集合差集,返回在第一个集合 key1中但不在后续任何集合中的成员,结果依赖于第一个键的顺序。
8、SUNION key1 key2用法:
1. 基本语法
SUNION key1 [key2 ...]- 计算给定一个或多个集合的并集(Union),返回一个包含所有集合中所有成员的合集(自动去重)。
2. 返回值
-
包含并集成员的列表(
list-reply)。 -
如果所有给定的键都不存在,返回空列表
(empty list or set)。
3. 常用示例
# 1. 准备两个集合
127.0.0.1:6379> SADD python_devs "Alice" "Bob"
(integer) 2
127.0.0.1:6379> SADD java_devs "Bob" "Charlie"
(integer) 2
# 2. 找出所有开发者(Python 或 Java)
127.0.0.1:6379> SUNION python_devs java_devs
1) "Alice"
2) "Bob"
3) "Charlie"
# 3. 并集会自动去重 ("Bob" 在两个集合中只出现一次)4. 核心特点
-
数学运算:执行标准的集合并集运算。
-
自动去重:即使成员在多个集合中出现,结果集中也只会保留一份。
-
原子性:所有集合的并集计算在一个原子步骤内完成。
5. 变种命令
SUNIONSTORE destination key1 [key2 ...]:将并集结果存储 到一个新的键destination中,而不是直接返回。这在需要持久化合并结果时非常有用。
6. 核心用途
-
聚合数据:合并来自不同来源或类别的数据,例如合并多个标签列表、获取所有相关用户。
-
构建全量名单:快速生成一个包含所有相关实体的完整列表。
7、一句话总结
SUNION key1 key2 ...计算多个集合的并集并返回所有不重复的成员,是合并和聚合数据的核心命令。
七、Redis命令-SortedSet类型

1、ZADD key score member用法:
1. 基本语法
ZADD key [NX|XX] [GT|LT] [CH] [INCR] score member [score member ...]-
最简形式 :
ZADD key score member -
向有序集合(Sorted Set/ZSet)添加一个或多个成员,或更新已存在成员的分数。
2. 返回值
-
新添加 的成员数量 (
integer)。 -
如果使用
XX或NX等选项,返回的是根据条件更新的成员数量。
3. 常用示例
# 1. 添加单个成员
127.0.0.1:6379> ZADD leaderboard 100 "Alice"
(integer) 1
# 2. 添加多个成员
127.0.0.1:6379> ZADD leaderboard 200 "Bob" 150 "Charlie"
(integer) 2 # 成功添加了 Bob 和 Charlie 两个新成员
# 3. 更新已存在成员的分数
127.0.0.1:6379> ZADD leaderboard 120 "Alice" # Alice 的分数从 100 更新为 120
(integer) 0 # 因为 Alice 不是新添加的成员,所以返回 04. 核心特点
-
排序依据 :成员按 score 从小到大排序。
-
唯一性:成员(member)是唯一的,但分数(score)可以重复和更新。
-
灵活性 :通过可选参数可以实现复杂的条件更新(如
NX仅新增、XX仅更新)。
5. 核心用途
-
排行榜:最经典的用法,根据分数实时排名(如游戏积分、热搜榜)。
-
带权重的队列:根据优先级(score)处理任务。
-
范围查找:快速获取 Top N 或某个分数区间内的成员。
6. 配套命令
-
ZRANGE key start stop [WITHSCORES]:按排名范围获取成员。 -
ZREVRANGE key start stop [WITHSCORES]:按排名范围反向获取(从高到低)。 -
ZRANK key member:获取成员的排名(从低到高)。
7、一句话总结
ZADD key score member向有序集合添加或更新成员及其分数,成员按分数排序,是实现排行榜等有序场景的核心命令。
2、ZREM key member用法:
1. 基本语法
ZREM key member [member ...]- 从有序集合(Sorted Set/ZSet)中移除一个或多个指定的成员(member)。
2. 返回值
-
成功移除的成员数量 (
integer)。-
如果指定的成员不存在于集合中,则忽略该成员,不计入成功数量。
-
如果键不存在,也视为所有成员都不存在,返回
0。
-
3. 常用示例
# 1. 准备一个有序集合
127.0.0.1:6379> ZADD leaderboard 100 "Alice" 200 "Bob" 150 "Charlie"
(integer) 3
# 2. 移除单个存在的成员
127.0.0.1:6379> ZREM leaderboard "Bob"
(integer) 1 # 成功移除1个
# 3. 移除多个成员(含不存在的成员)
127.0.0.1:6379> ZREM leaderboard "Alice" "David" "Charlie"
(integer) 2 # 只移除了 "Alice" 和 "Charlie","David" 不存在
# 4. 验证结果
127.0.0.1:6379> ZRANGE leaderboard 0 -1 WITHSCORES
1) "Alice" # 注意:这个例子里 Alice 应该被移除了,这里仅为演示命令格式
2) "100"4. 核心特点
-
精确移除:只移除明确指定的成员。
-
静默失败:尝试移除不存在的成员不会报错,只是返回的成功数量为 0。
-
原子性:单次调用移除多个成员是原子操作。
5. 核心用途
-
管理排行榜:将玩家、用户从排行榜中移除(如账号注销、作弊封禁)。
-
数据清理:从有序集合中删除不再需要的元素。
6. 配套命令
-
ZADD key score member:向有序集合添加成员。 -
ZRANGE key start stop:获取指定排名范围内的成员。 -
ZCARD key:获取有序集合的成员总数。
7、一句话总结
ZREM key member...从有序集合中移除一个或多个指定的成员,返回成功移除的数量,是管理排行榜等有序集合的核心删除命令。
3、ZSCORE key member用法:
1. 基本语法
ZSCORE key member- 获取有序集合(Sorted Set/ZSet)中指定成员(member)的分数(score)。
2. 返回值
-
成员的分数(
string-reply)。 -
如果成员或键不存在,返回
(nil)。
3. 常用示例
# 1. 准备一个有序集合
127.0.0.1:6379> ZADD leaderboard 95 "Alice" 88 "Bob" 92 "Charlie"
(integer) 3
# 2. 获取存在的成员分数
127.0.0.1:6379> ZSCORE leaderboard "Alice"
"95" # 返回字符串形式的分数
# 3. 获取不存在的成员分数
127.0.0.1:6379> ZSCORE leaderboard "David"
(nil)4. 核心特点
-
高性能 :时间复杂度为 O(1),无论集合有多大,查询速度都恒定。
-
只读:不会修改原始集合或成员的分数。
5. 核心用途
-
查询具体数值:在排行榜中查看特定用户的精确得分。
-
业务逻辑判断:根据分数判断用户等级、权限或进行进一步计算。
6. 配套命令
-
ZADD key score member:添加或更新成员分数。 -
ZINCRBY key increment member:为成员分数增加指定值。 -
ZRANGE key start stop WITHSCORES:获取排名范围内的成员及其分数。
7、一句话总结
ZSCORE key member返回有序集合中指定成员的分数,时间复杂度 O(1),是查询排行榜等场景中成员具体数值的高效命令。
4、ZRANK key member用法:
1. 基本语法
ZRANK key member- 获取有序集合(Sorted Set/ZSet)中指定成员(member)的排名(Rank)。
2. 返回值
-
成员的排名(从 0 开始的索引,
integer)。 -
如果成员或键不存在,返回
(nil)。
3. 重要特性:升序排名
-
ZRANK返回的是升序排名 :即分数最低 的成员排名为0。 -
如果需要降序排名 (分数最高的排第 0 名),请使用
ZREVRANK。
4. 常用示例
# 1. 准备一个有序集合 (分数越低,排名越靠前)
127.0.0.1:6379> ZADD scores 85 "Alice" 92 "Bob" 78 "Charlie"
(integer) 3
# 排序后: Charlie(78), Alice(85), Bob(92)
# 2. 获取升序排名 (分数最低的排第0)
127.0.0.1:6379> ZRANK scores "Alice"
(integer) 1 # Alice 的分数是 85,排在第 1 位 (0: Charlie, 1: Alice, 2: Bob)
# 3. 获取降序排名 (分数最高的排第0)
127.0.0.1:6379> ZREVRANK scores "Alice"
(integer) 1 # Alice 在降序排列中是第 1 位 (0: Bob, 1: Alice, 2: Charlie)
# 4. 获取不存在的成员排名
127.0.0.1:6379> ZRANK scores "David"
(nil)5. 核心用途
- 排行榜名次查询 :查询用户在排行榜中的位置(需根据升序/降序需求选择
ZRANK或ZREVRANK)。
6. 配套命令
-
ZREVRANK key member:获取成员的降序排名(从高到低)。 -
ZSCORE key member:获取成员的分数。 -
ZRANGE key start stop:按升序范围获取成员。
7、一句话总结
ZRANK key member返回成员在有序集合中的升序排名(分数最低者为 0),查询降序排名请用 ZREVRANK。
5、ZCARD key用法:
1. 基本语法
ZCARD key- 获取有序集合(Sorted Set/ZSet)的基数 (Cardinality),即集合中成员的总数量。
2. 返回值
-
集合中成员的数量 (
integer)。 -
如果键不存在,返回
0(因为空集合的基数为0)。
3. 常用示例
# 1. 准备一个有序集合
127.0.0.1:6379> ZADD leaderboard 100 "Alice" 200 "Bob" 150 "Charlie"
(integer) 3
# 2. 获取集合的成员总数
127.0.0.1:6379> ZCARD leaderboard
(integer) 3
# 3. 对不存在的键使用 ZCARD
127.0.0.1:6379> ZCARD non_existent_zset
(integer) 04. 核心特点
-
高性能 :时间复杂度为 O(1),无论集合有多大,计算速度都恒定。
-
只读:不会修改原始集合。
5. 核心用途
-
快速计数:统计排行榜总人数、在线用户数等。
-
容量检查:在执行某些操作前,先判断集合是否为空或达到上限。
6. 配套命令
-
ZADD key score member:向有序集合添加成员。 -
ZREM key member:从有序集合移除成员。 -
ZCOUNT key min max:获取分数在指定区间内的成员数量。
7、一句话总结
ZCARD key返回有序集合中成员的总数量(基数),时间复杂度 O(1),是进行快速计数的核心命令。
6、ZCOUNT key min max用法:
1. 基本语法
ZCOUNT key min max- 计算有序集合(Sorted Set/ZSet)中,分数在 **min, max** 闭区间内的成员数量。
2. 返回值
-
分数在指定区间内的成员数量 (
integer)。 -
如果键不存在,返回
0。
3. 常用示例
# 1. 准备一个有序集合
127.0.0.1:6379> ZADD salaries 5000 "Alice" 6000 "Bob" 7500 "Charlie" 8000 "David"
(integer) 4
# 2. 计算工资在 [5500, 7800] 之间的员工数量
127.0.0.1:6379> ZCOUNT salaries 5500 7800
(integer) 2 # Bob(6000) 和 Charlie(7500) 符合条件
#. 使用无穷大
127.0.0.1:6379> ZCOUNT salaries 7000 +inf
(integer) 2 # Charlie(7500) 和 David(8000) 符合条件4. 核心特点
-
区间查询:高效地统计某个分数范围内的成员数量,无需取出所有成员。
-
边界包含 :
min和max值是闭区间 ,即包含等于min或max的成员。 -
特殊值:
-
-inf代表负无穷。 -
+inf代表正无穷。
-
5. 核心用途
-
范围统计:统计考试成绩在某个分数段的学生人数、薪资在某个级别的人数等。
-
数据分析:快速。
6. 配套命令
-
ZADD key score member:添加成员。 -
ZRANGEBYSCORE key min max:获取分数在指定区间内的所有成员(不只是数量)。
7、一句话总结
ZCOUNT key min max统计有序集合中分数在 min, max 闭区间内的成员数量,是进行高效范围统计的核心命令。
7、ZINCRBY key increment member用法:
1. 基本语法
ZINCRBY key increment member- 为有序集合(Sorted Set/ZSet)中指定成员(member)的分数(score)增加指定的增量(
increment)。
2. 返回值
- 成员增加后的新分数 (
bulk-string-reply)。
3. 常用示例
# 1. 对不存在的成员执行 ZINCRBY,会先将其初始化为 0 再 +increment
127.0.0.1:6379> ZINCRBY player:scores 10 "Alice"
"10"
# 2. 对已存在的成员增加指定值
127.0.0.1:6379> ZINCRBY player:scores 5 "Alice"
"15"
# 3. 支持负值进行减少
127.0.0.1:6379> ZINCRBY player:scores -3 "Alice"
"12"4. 核心特点
-
原子性:增加操作是原子的,在高并发下安全可靠。
-
自动创建 :如果成员或键不存在,会自动创建并将其分数设为
increment。 -
灵活增减 :
increment可以是正数(增加)或负数(减少)。
5. 核心用途
-
计数器/排行榜:实现游戏积分、文章阅读量、用户活跃度等需要频繁增减的计分场景。
-
实时评分系统:动态调整项目的权重或热度。
6. 配套命令
-
ZADD key score member:直接设置或更新分数。 -
ZSCORE key member:获取成员当前的分数。 -
ZREVRANGE key start stop WITHSCORES:获取排行榜前列。
一句话总结
ZINCRBY key increment member将有序集合指定成员的分数原子性地增加 increment并返回新分数,是实现动态计数器和排行榜的首选命令。
8、ZARNGE key min max用法:
1. 基本语法
ZRANGE key start stop [WITHSCORES]- 按升序(从小到大) 返回有序集合(Sorted Set/ZSet)中,指定排名(
start至stop)区间内的成员。
2. 参数含义
-
start,stop:排名索引(从 0 开始)。负数表示从尾部开始计数(-1 是最后一个元素)。 -
WITHSCORES:可选参数。如果提供,会同时返回成员对应的分数。
3. 常用示例
# 准备一个有序集合: leaderboard -> [(Alice, 100), (Bob, 200), (Charlie, 150)]
127.0.0.1:6379> ZADD leaderboard 100 "Alice" 200 "Bob" 150 "Charlie"
(integer) 3
# 1. 获取排名 0 到 1 的成员 (即前2名)
127.0.0.1:6379> ZRANGE leaderboard 0 1
1) "Alice" # 分数最低,排名第一
2) "Charlie" # 分数第二低,排名第二
# 2. 获取所有成员 (按升序)
127.0.0.1:6379> ZRANGE leaderboard 0 -1
1) "Alice"
2) "Charlie"
3) "Bob"
# 3. 获取所有成员及其分数
127.0.0.1:6379> ZRANGE leaderboard 0 -1 WITHSCORES
1) "Alice"
2) "100"
3) "Charlie"
4) "150"
5) "Bob"
6) "200"4. 核心特点
-
升序排列:返回结果是按分数从小到大(从低到高)排序的。
-
闭区间 :返回的结果包含
start和stop索引处的成员。 -
排名索引 :参数是基于排名(索引),而非分数。
5. 变种命令
ZREVRANGE key start stop [WITHSCORES]:按降序(从大到小) 返回指定排名区间内的成员。这是获取排行榜Top N 的常用命令。
6. 核心用途
-
范围查询 :获取排行榜的前几名(配合
ZREVRANGE)或某一区间段的用户。 -
分页展示:对有序数据进行分页显示。
7、一句话总结
ZRANGE key start stop按升序返回有序集合中指定排名范围的成员,加上 WITHSCORES可同时返回分数,获取降序排名请用 ZREVRANGE。
9、ZRANGEBYSCORE key min max用法:
1. 基本语法
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]- 按分数 从低到高,返回有序集合(Sorted Set/ZSet)中分数在 **min, max** 闭区间内的所有成员。
2. 参数含义
-
min,max:分数范围。-inf和+inf分别代表正负无穷。 -
WITHSCORES:可选参数。同时返回成员的分数。 -
LIMIT offset count:可选参数。用于分页,offset是偏移量,count是返回数量。
3. 常用示例
# 准备一个有序集合: products -> [(pen, 1), (book, 5), (laptop, 1000)]
127.0.0.1:6379> ZADD products 1 "pen" 5 "book" 1000 "laptop"
(integer) 3
# 1. 获取价格在 [2, 500] 之间的所有商品
127.0.0.1:6379> ZRANGEBYSCORE products 2 500
1) "book" # pen(1)太便宜,laptop(1000)太贵,只有 book(5) 符合条件
# 2. 获取价格在 0 到正无穷之间的所有商品(即全部)
127.0.0.1:6379> ZRANGEBYSCORE products 0 +inf
1) "pen"
2) "book"
3) "laptop"
# 3. 获取价格在 [1, 1000] 之间的商品,并显示分数,进行分页(跳过0个,取2个)
127.0.0.1:6379> ZRANGEBYSCORE products 1 1000 WITHSCORES LIMIT 0 2
1) "pen"
2) "1"
3) "book"
4) "5"4. 核心特点
-
按分数筛选 :与按排名筛选的
ZRANGE不同,ZRANGEBYSCORE是根据分数范围来获取成员。 -
闭区间 :默认情况下,
min和max是包含的。可以使用括号(来改为开区间,例如(1 5表示大于1且小于5。 -
高效查询:无需遍历整个集合即可完成范围查询,性能极高。
5. 现代替代命令 (推荐)
在 Redis 6.2.0 及以后版本,官方推荐使用功能更强大的 ZRANGE命令来替代 ZRANGEBYSCORE。
# 使用 ZRANGE 实现相同的功能 (score >= 2 and score <= 500)
ZRANGE products 2 500 BYLEX
# 或者使用 BYSCORE (更直观)
ZRANGE products BYSCORE 2 5006. 核心用途
-
范围数据查询:例如,筛选价格、年龄、温度等在某一区间内的所有数据。
-
数据分页 :结合
LIMIT对大量数据进行高效分页。
一句话总结
ZRANGEBYSCORE key min max按分数范围从低到高返回成员,但已被功能更强的 ZRANGE ... BYSCORE取代,建议在新项目中使用后者。
10、ZDIFF、ZINTER、ZUNION用法:
这三个命令都是对多个有序集合进行计算,并返回结果集。
1. ZDIFF (差集)
基本语法
ZDIFF numkeys key [key ...] [WITHSCORES]- 计算第一个集合与后续所有集合的差集,返回在第一个集合中但不在任何其他集合中的成员。
返回值
- 包含差集成员的列表,按第一个集合的分数排序。使用
WITHSCORES可同时返回分数。
示例
# 集合A: {A:1, B:2, C:3}, 集合B: {B:20, D:4}
127.0.0.1:6379> ZADD setA 1 A 2 B 3 C
(integer) 3
127.0.0.1:6379> ZADD setB 20 B 4 D
(integer) 2
# 计算 A - B (在A中但不在B中)
127.0.0.1:6379> ZDIFF 2 setA setB
1) "A"
2) "C"
# B在setB中也存在,所以被排除了2. ZINTER (交集)
基本语法
ZINTER numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] [WITHSCORES]- 计算所有给定集合的交集,返回同时存在于所有集合中的成员。
返回值
- 包含交集成员的列表,分数由
AGGREGATE决定。使用WITHSCORES可同时返回分数。
示例
# 集合A: {A:1, B:2, C:3}, 集合B: {B:20, C:30, D:4}
127.0.0.1:6379> ZADD setA 1 A 2 B 3 C
(integer) 3
127.0.0.1:6379> ZADD setB 20 B 30 C 4 D
(integer) 3
# 计算 A ∩ B (同时在A和B中)
127.0.0.1:6379> ZINTER 2 setA setB
1) "B"
2) "C"
# 计算交集,并使用 WEIGHTS 和 AGGREGATE
# 结果分数 = (A.score * 1) + (B.score * 0.5),然后取最大值
127.0.0.1:6379> ZINTER 2 setA setB WEIGHTS 1 0.5 AGGREGATE MAX WITHSCORES
1) "B"
2) "20" # max(2 * 1, 20 * 0.5)=max(2,10)=10? Wait, let's check. Actually, it's aggregate of the weighted scores.
# Let's simplify: The example shows the flexibility.3. ZUNION (并集)
基本语法
ZUNION numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] [WITHSCORES]- 计算所有给定集合的并集,返回一个包含所有集合中不重复成员的集合。
返回值
- 包含并集成员的列表,分数由
AGGREGATE决定。使用WITHSCORES可同时返回分数。
示例
# 集合A: {A:1, B:2, C:3}, 集合B: {B:20, C:30, D:4}
127.0.0.1:6379> ZADD setA 1 A 2 B 3 C
(integer) 3
127.0.0.1:6379> ZADD setB 20 B 30 C 4 D
(integer) 3
# 计算 A ∪ B (所有出现在A或B中的成员)
127.0.0.1:6379> ZUNION 2 setA setB
1) "A"
2) "D" # 注意顺序可能因分数而异
3) "B"
4) "C"
# 计算并集,并对分数求和 (默认行为)
127.0.0.1:6379> ZUNION 2 setA setB WITHSCORES
1) "A"
2) "1"
3) "D"
4) "4"
5) "B"
6) "22" # 2 (from A) + 20 (from B)
7) "C"
8) "33" # 3 (from A) + 30 (from B)4、核心特点与用途
| 命令 | 核心逻辑 | 主要用途 |
|---|---|---|
**ZDIFF** |
A - B - C ... |
找出独有元素,如"仅在A组但不在B组的用户"。 |
**ZINTER** |
A ∩ B ∩ C ... |
计算共同部分,如"同时拥有所有标签的商品"、"共同好友"。 |
**ZUNION** |
A ∪ B ∪ C ... |
合并数据,如"合并多个来源的排行榜"、"所有相关用户的总列表"。 |
5、变种命令 (推荐用于生产环境)
ZDIFFSTORE,ZINTERSTORE,ZUNIONSTORE:将计算结果存储到一个新的键中,而不是直接返回。这在需要复用结果集时非常有用,可以避免重复计算。
6、一句话总结
ZDIFF/ZINTER/ZUNION分别用于计算有序集合的差集、交集和并集,numkeys指定要计算的集合数量,它们常与对应的 *STORE命令联用以提升性能。