一、同步调用(Synchronous Call)
(一)什么是同步调用
同步调用是指:
调用方发起请求后,必须等待被调用方处理完成并返回结果,才能继续执行后续逻辑。
常见形式:
HTTP / REST 接口
RPC(如 Dubbo 同步调用)
本地方法调用
(二)同步调用的特点
1. 同步调用的优势
(1)实时性强
调用方可以立即获取执行结果,适合强一致性、强时效性的业务场景
(如:登录校验、下单校验、余额校验)
(2)流程简单、易于理解
请求 → 处理 → 返回结果,调用链清晰,调试方便
(3)便于事务控制
可以在一个调用链中完成事务提交或回滚
(三)同步调用的问题
1. 拓展性差
调用方与被调用方强依赖
一旦服务数量增加,调用链变长,系统复杂度指数级上升
2. 性能下降
调用方线程需要阻塞等待
并发高时,线程资源被大量占用
TPS 容易受下游服务性能拖累
3. 级联失败(雪崩效应)
下游服务变慢或不可用
↓
上游服务请求堆积、线程耗尽
↓
整个系统不可用
这是微服务架构中最常见的问题之一。
二、异步调用(Asynchronous Call)
(一) 什么是异步调用
异步调用是指:
调用方发送请求后不等待处理结果,立即返回,由系统在后台异步完成后续处理。
在分布式系统中,异步调用通常是基于消息通知的方式实现的。
(二)异步调用的核心角色
异步调用一般包含三个角色:
1. 消息发送者(Producer)
发送消息的一方
原来的"调用方"
2. 消息代理(Broker)
负责消息的接收、存储、转发
如:RabbitMQ、Kafka
3. 消息接收者(Consumer)
接收并处理消息的一方
原来的"服务提供方"
(三)异步调用的优势
1. 系统解耦,拓展性强
调用方无需关心下游是谁、有多少个
新增或修改消费者不影响原有系统
2. 无需等待,吞吐量高
调用方只负责发送消息即可返回
不阻塞线程,系统并发能力显著提升
3. 故障隔离
下游服务宕机 ≠ 上游服务不可用
消息可以暂存于 Broker 中,等待下游恢复
4. 削峰填谷
高并发请求先写入消息队列
下游服务按自身能力消费
防止系统被瞬时流量击穿
(四)异步调用的问题与挑战
1. 无法立即获取结果(最终一致性)
调用方无法立刻知道执行结果
业务通常需要:
回调
状态查询
事件通知
2 消息可靠性问题
消息是否丢失?
是否被重复消费?
是否顺序消费?
这些问题都需要MQ + 业务层共同解决。
3. 业务安全依赖 Broker 的可靠性
MQ 一旦不可用,会影响整个异步链路
需要:
消息持久化
集群部署
监控告警
重试与补偿机制
三、MQ 技术选型对比
(一) 什么是 MQ(Message Queue)
MQ(消息队列)是实现异步通信的核心中间件,在异步调用中充当 Broker 角色。
在分布式系统和微服务架构中,消息队列(MQ)是实现系统解耦、异步处理、削峰填谷 的重要基础组件。
目前主流的 MQ 产品主要包括 RabbitMQ、Kafka、RocketMQ ,此外还有逐渐被淘汰的 ActiveMQ。
不同 MQ 的设计目标和适用场景差异较大,因此在技术选型时,需要结合业务特点进行选择。
(二) RabbitMQ
RabbitMQ 是一款基于 AMQP(Advanced Message Queuing Protocol) 协议的消息中间件,强调消息可靠性与灵活的路由能力。
RabbitMQ 提供了多种 Exchange 类型(direct、topic、fanout、headers),可以满足复杂的业务分发需求。在可靠性方面,支持消息持久化、生产者确认(Publisher Confirm)、消费者确认(ACK)、死信队列、延迟队列等机制。
优点:
路由能力强,适合复杂业务场景
消息可靠性高,机制完善
学习成本低,文档和社区成熟
与 Spring Boot / Spring AMQP 集成友好
缺点:
吞吐量相对 Kafka 较低
不适合超大规模日志或流式数据处理
适用场景:
订单系统
支付、通知、消息推送
业务解耦、事件驱动架构
总体来看,RabbitMQ 更偏向 "业务型 MQ",非常适合中小规模、对可靠性和可维护性要求较高的业务系统。
(二)Kafka
Kafka 最初由 LinkedIn 开源,设计目标是 高吞吐、可扩展、分布式日志系统,在大数据领域应用广泛。
Kafka 采用分区(Partition)机制,消息以追加日志的方式顺序写入磁盘,能够支撑极高的并发写入和消费能力。同时,Kafka 支持消息长期存储和回溯消费,非常适合数据分析场景。
优点:
吞吐量极高,适合大规模数据场景
天然支持分区与水平扩展
消息可回溯,适合流式计算
与大数据生态(Flink、Spark)深度结合
缺点:
路由能力较弱,不适合复杂业务分发
对业务幂等性要求高
运维与学习成本较高
适用场景:
日志收集
行为埋点
实时数据分析
流式计算
Kafka 更偏向 "数据型 MQ",核心优势在于吞吐量,而非复杂业务处理能力。
(三)RocketMQ
RocketMQ 是阿里巴巴开源的消息中间件,专为 高并发、高可靠业务场景 设计,在国内电商和金融系统中应用较多。
RocketMQ 支持顺序消息、延迟消息以及事务消息,尤其在分布式事务场景中具有一定优势。
优点:
高并发、高可用
原生支持事务消息
适合核心业务系统
缺点:
运维复杂度相对较高
社区和生态不如 Kafka、RabbitMQ 成熟
学习成本高于 RabbitMQ
适用场景:
电商订单
库存扣减
交易、金融系统
RocketMQ 更偏向 "高并发业务型 MQ",适合对性能和一致性要求极高的核心系统。
(四)ActiveMQ
ActiveMQ 是较早期的消息中间件,功能齐全,但在性能和扩展性方面已经难以满足现代高并发系统需求。
目前在新项目中基本不再推荐,更多用于维护历史系统。
(五)常见 MQ 对比总结
| 对比维度 | RabbitMQ | Kafka | RocketMQ |
|---|---|---|---|
| 设计目标 | 业务解耦 | 高吞吐数据流 | 高并发业务 |
| 吞吐量 | 中 | 极高 | 高 |
| 消息可靠性 | 高 | 较高 | 高 |
| 路由能力 | 强 | 弱 | 中 |
| 顺序消息 | 支持 | 支持 | 支持 |
| 事务消息 | 一般 | 不支持 | 强 |
| 学习成本 | 低 | 高 | 中 |
| 典型场景 | 业务系统 | 日志、流数据 | 电商、交易 |
Kafka 擅长"处理数据",RocketMQ 擅长"承载高并发交易",RabbitMQ 擅长"处理业务消息"。
四、RabbitMQ 简介
在前面的 MQ 技术选型中,我们已经对 RabbitMQ 的定位和适用场景进行了对比分析。
本节将从实现原理和设计背景的角度,进一步介绍 RabbitMQ。
RabbitMQ 是一款 基于 Erlang 语言开发的开源消息中间件,实现了AMQP(Advanced Message Queuing Protocol) 协议。
之所以选择 Erlang 作为实现语言,主要是因为 Erlang 天然适合构建高并发、高可靠、分布式系统,其核心特性包括:
高并发:基于轻量级进程模型,可轻松支撑海量并发连接
高可靠:进程隔离机制完善,单个进程异常不会影响整体系统
分布式支持良好:天生支持节点通信与集群化部署
这些特性,使 RabbitMQ 在消息投递可靠性和系统稳定性方面具备天然优势。
RabbitMQ 官方用一句话概括其设计理念:
One broker to queue them all
即通过一个可靠的消息代理(Broker),统一管理系统中的消息通信,
从而实现系统解耦、异步处理和流量削峰。
五、Ubuntu 虚拟机上安装 RabbitMQ
RabbitMQ: One broker to queue them all | RabbitMQ
1. 更新系统环境
在安装 RabbitMQ 之前,先确保系统环境是最新的:
sudo apt update
sudo apt upgrade -y2. 安装 Erlang(RabbitMQ 运行依赖)
# 安装必要工具
sudo apt install -y curl gnupg apt-transport-https
# 下载 Erlang 官方仓库包
curl -fsSL https://packages.erlang-solutions.com/erlang-solutions_2.0_all.deb -o erlang-solutions.deb
sudo dpkg -i erlang-solutions.deb
# 更新 apt 并安装 Erlang
sudo apt update
sudo apt install -y erlang(1)尝试通过官方 Erlang 仓库安装(可能失败)
在部分网络环境或虚拟机中,执行以下命令可能会失败:
curl -fsSL https://packages.erlang-solutions.com/erlang-solutions_2.0_all.deb -o erlang-solutions.deb
sudo dpkg -i erlang-solutions.deb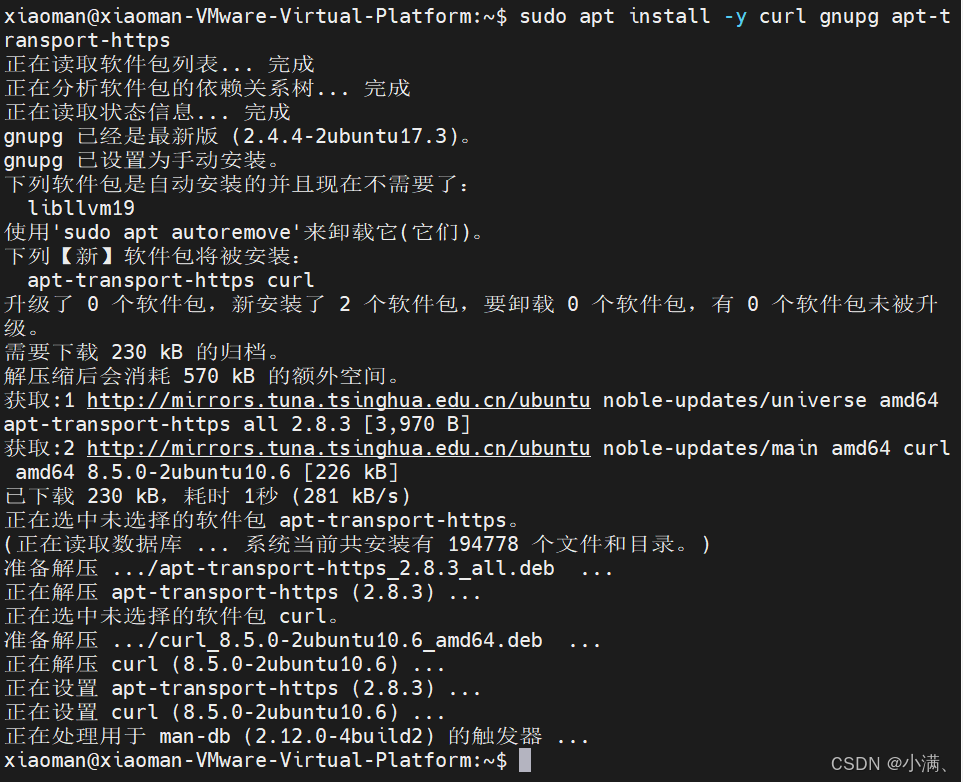

说明 .deb 文件下载失败,常见原因包括:
虚拟机网络未正确配置(NAT / 桥接异常)
官方仓库暂时不可用
防火墙或代理限制外部访问
(2)解决方案 A:使用 Ubuntu 官方仓库安装
对于学习和开发环境来说,Ubuntu 自带的 Erlang 版本已经完全满足 RabbitMQ 的使用需求。
sudo apt update
sudo apt install -y erlang

这种方式无需访问外部 Erlang 官方仓库,稳定性最高,最推荐。
(3)验证 Erlang 是否安装成功
erl
如果进入如下界面,说明安装成功:
Eshell V...输入以下命令退出:
q().(4)方案 B:手动下载 Erlang .deb 包到本地再安装
在宿主机或浏览器下载 erlang-solutions_2.0_all.deb:
https://packages.erlang-solutions.com/erlang-solutions_2.0_all.deb
通过 VM 的共享文件夹或 scp 拷贝到 Ubuntu VM
安装:
sudo dpkg -i erlang-solutions_2.0_all.deb
sudo apt update
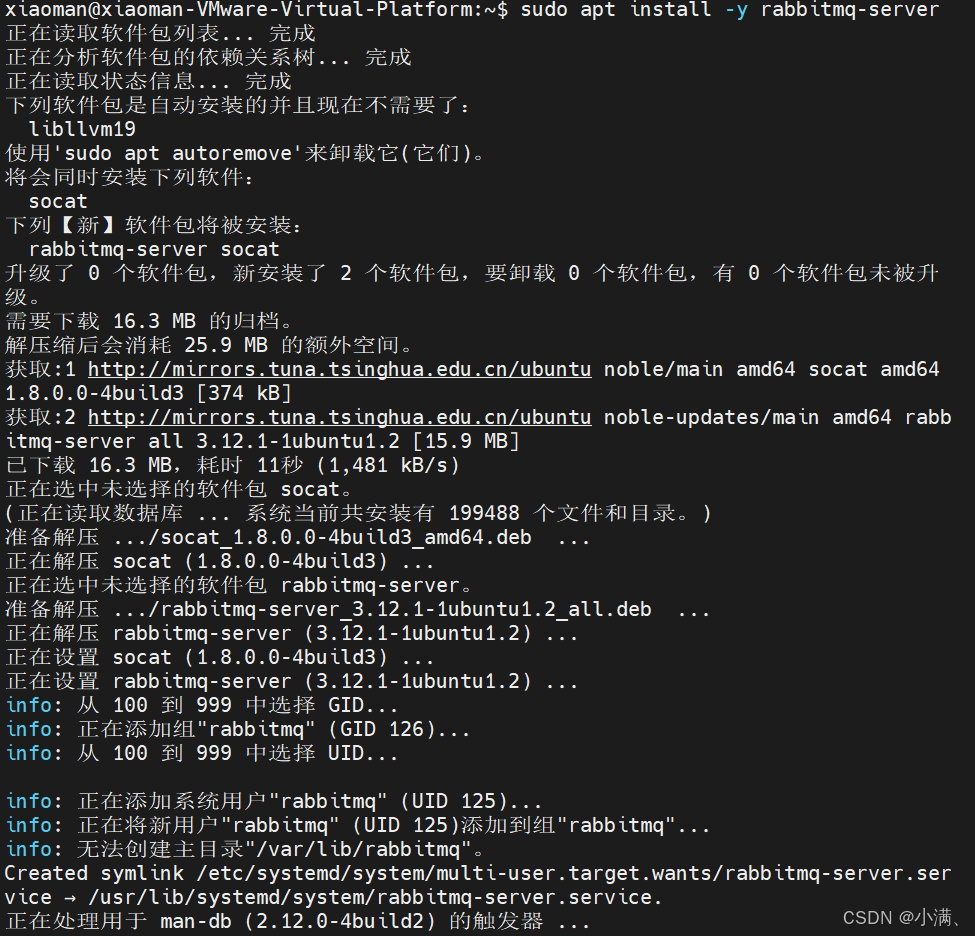
sudo apt install -y erlang3. 安装RabbitMQ
在 Erlang 安装完成后,直接通过 apt 安装 RabbitMQ:
# 更新 apt 并安装 RabbitMQ
sudo apt update
sudo apt install -y rabbitmq-server
4. 启动 RabbitMQ 并设置开机自启
sudo systemctl start rabbitmq-server
sudo systemctl enable rabbitmq-server
验证运行状态:
sudo systemctl status rabbitmq-server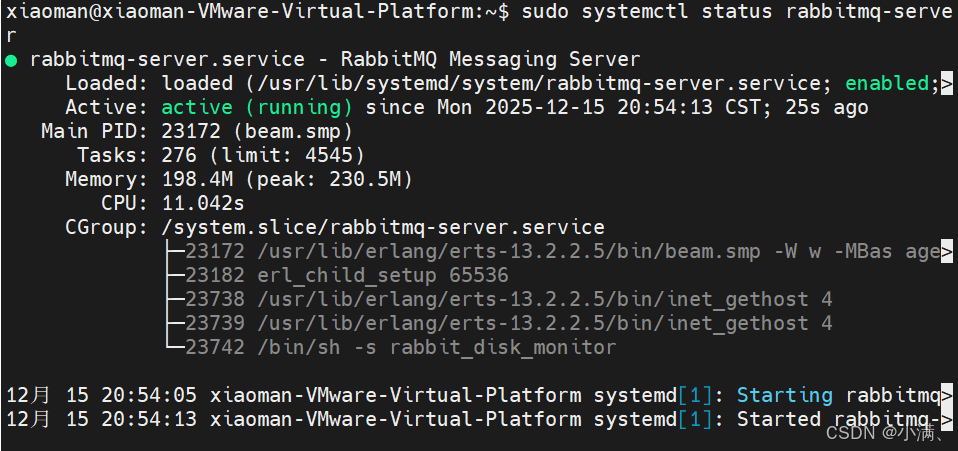
状态为 active (running) 即表示启动成功。
5. 启用 RabbitMQ 管理控制台
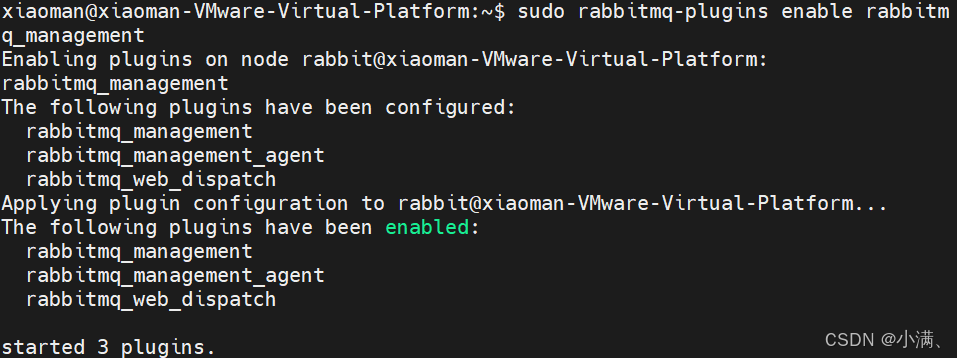
RabbitMQ 默认提供 Web 管理界面,但需要手动启用插件:
sudo rabbitmq-plugins enable rabbitmq_management启用后,RabbitMQ 会监听以下端口:
15672:管理控制台
5672:AMQP 通信端口
6. 访问管理界面
浏览器访问:
http://<VM_IP>:15672默认账号信息为:
用户名:guest
密码:guest
六、guest 用户无法远程登录的问题说明
如果你在浏览器中使用 guest / guest 登录时失败,这是 RabbitMQ 的安全设计,而不是配置错误。
原因说明
RabbitMQ 有一条硬性安全规则:
guest 用户只能从 localhost(127.0.0.1)登录
也就是说:
在服务器本机访问可以
从其他机器或虚拟机 IP 访问不可以
七、创建新的管理员用户
为了正常通过浏览器远程访问管理界面,需要创建一个新的用户。
(一)创建新用户
sudo rabbitmqctl add_user Aria 1007(二)设置用户角色为管理员
sudo rabbitmqctl set_user_tags Aria administrator(三)授予该用户所有权限
sudo rabbitmqctl set_permissions -p / Aria ".*" ".*" ".*"(四)确认用户是否创建成功
sudo rabbitmqctl list_users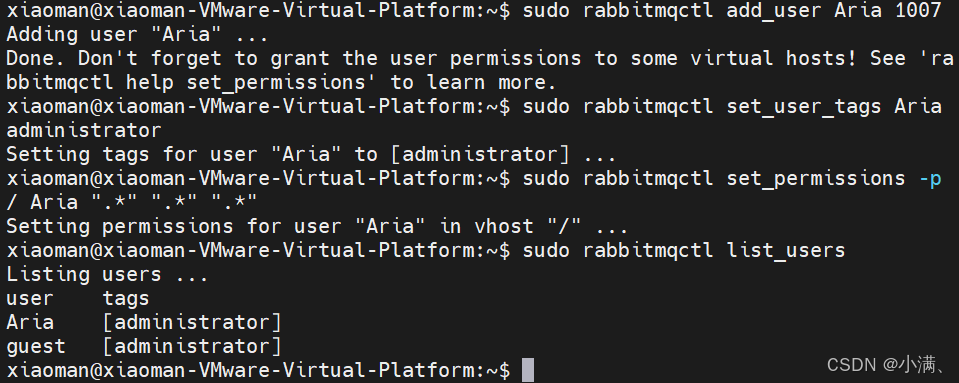
(五)使用新用户登录管理界面
浏览器访问:
http://192.168.41.136:15672输入:
用户名:Aria
密码:1007
即可成功进入 RabbitMQ 管理控制台。
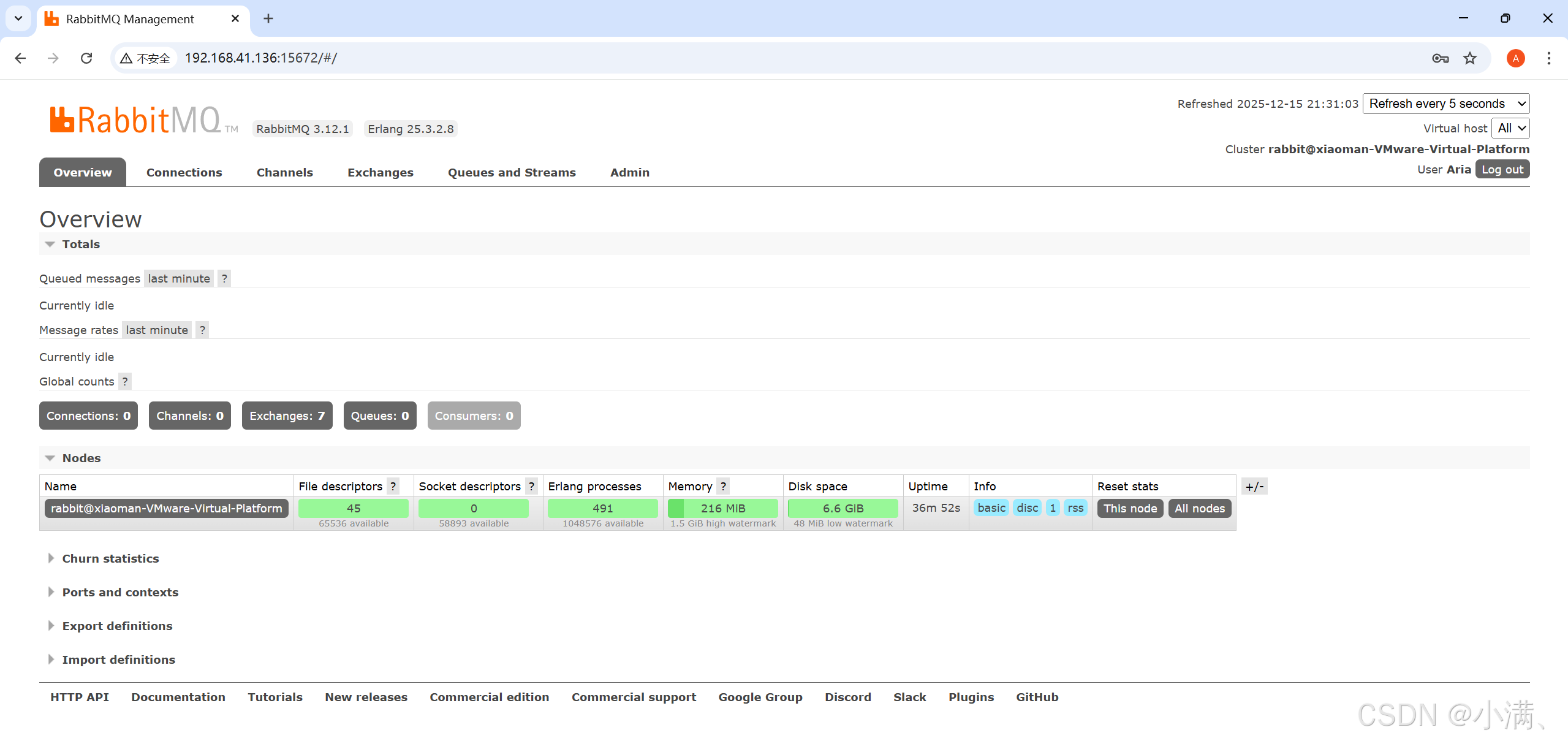
八、RabbitMQ 基本架构与核心概念
在正式使用 RabbitMQ 之前,有必要先理解其整体架构以及核心组成部分。
(一)RabbitMQ 核心概念
RabbitMQ 的消息通信模型主要由以下几个核心组件构成:
1. Virtual Host(vhost)
虚拟主机,用于资源与权限隔离。
不同 vhost 之间的交换机、队列、绑定关系完全隔离。
2. Publisher(生产者)
负责发送消息的一方,只与交换机(Exchange)交互。
3. Consumer(消费者)
负责从队列中获取并处理消息的一方。
4. Queue(队列)
用于真正存储消息的地方,消息在这里等待被消费。
5. Exchange(交换机)
负责根据路由规则将消息投递到一个或多个队列,本身不存储消息。
九、RabbitMQ 管理控制台概览
登录 RabbitMQ 管理控制台:
http://<IP>:15672顶部可以看到 RabbitMQ 的核心管理模块:
Overview | Connections | Channels | Exchanges | Queues | Admin(一)Overview(总览)
Overview 是 RabbitMQ 的全局运行状态监控面板,用于快速判断系统是否处于健康状态。
在这里可以看到:
RabbitMQ 是否正常运行
当前节点信息
消息整体流量情况
交换机 / 队列 / 连接数量
内存、磁盘使用情况
Flow Control(水位线)状态
(二)常见关键指标说明
| 指标 | 含义 |
|---|---|
| Ready | 队列中等待被消费的消息数量 |
| Unacked | 已投递但**尚未确认(ACK)**的消息数量 |
| Total | Ready + Unacked |
| Message rates | 消息生产 / 消费速率 |
| Node memory | RabbitMQ 节点内存使用 |
| Disk free | 磁盘剩余空间 |
十、RabbitMQ 控制台实践
下面通过一系列控制台实验,验证 RabbitMQ 的核心行为和设计原则。
实践一:验证 没有绑定队列 → 消息会消失
1. 实验目的
验证 交换机不存储消息,只有被路由到队列的消息才会被保存。
2. 操作步骤
(1) 新建一个交换机
Exchanges → Add a new exchange
Name:test.direct
Type:direct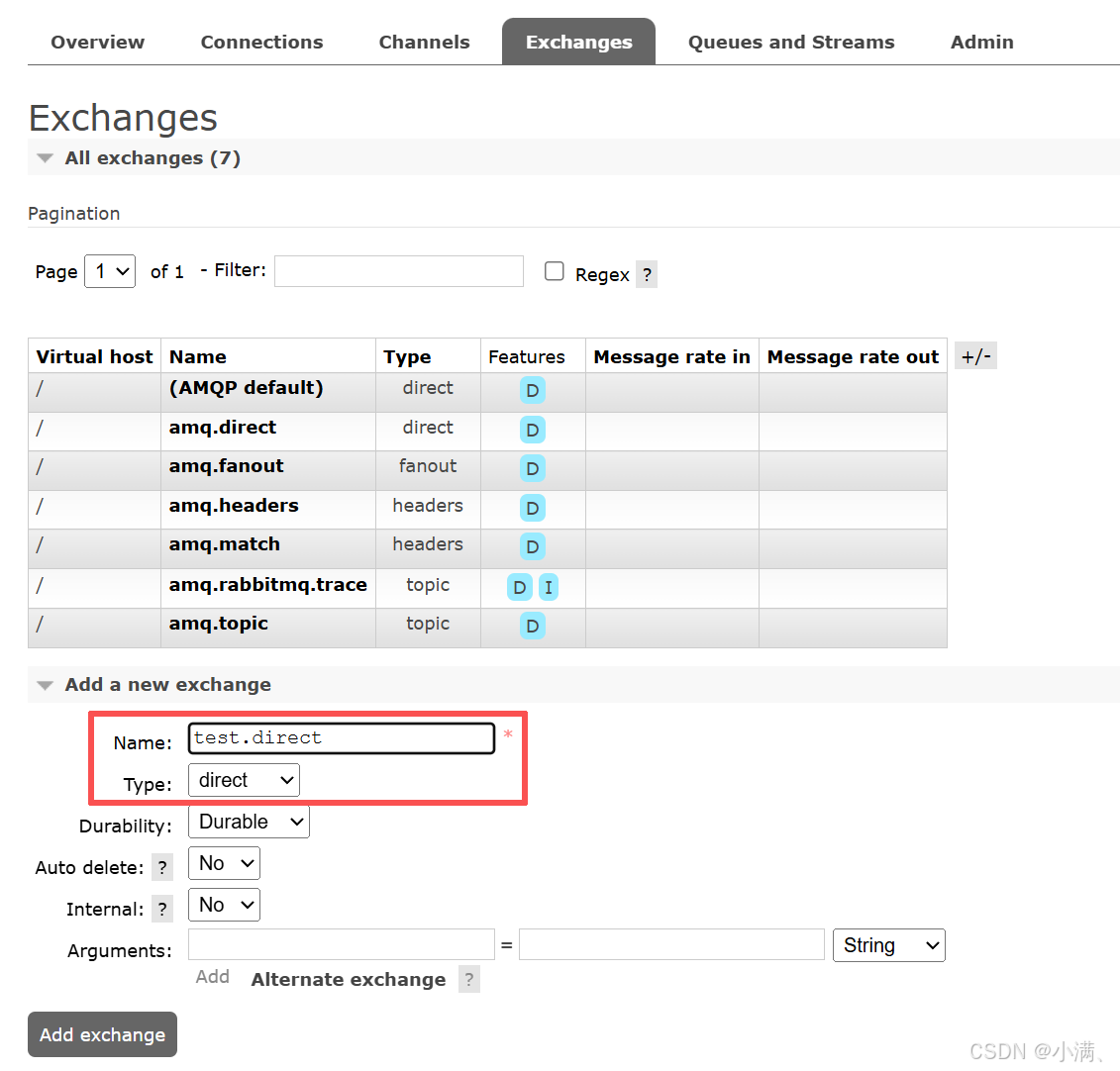
(2)不绑定任何队列
(3)向 test.direct 发布消息
Routing key:order
Payload:msg1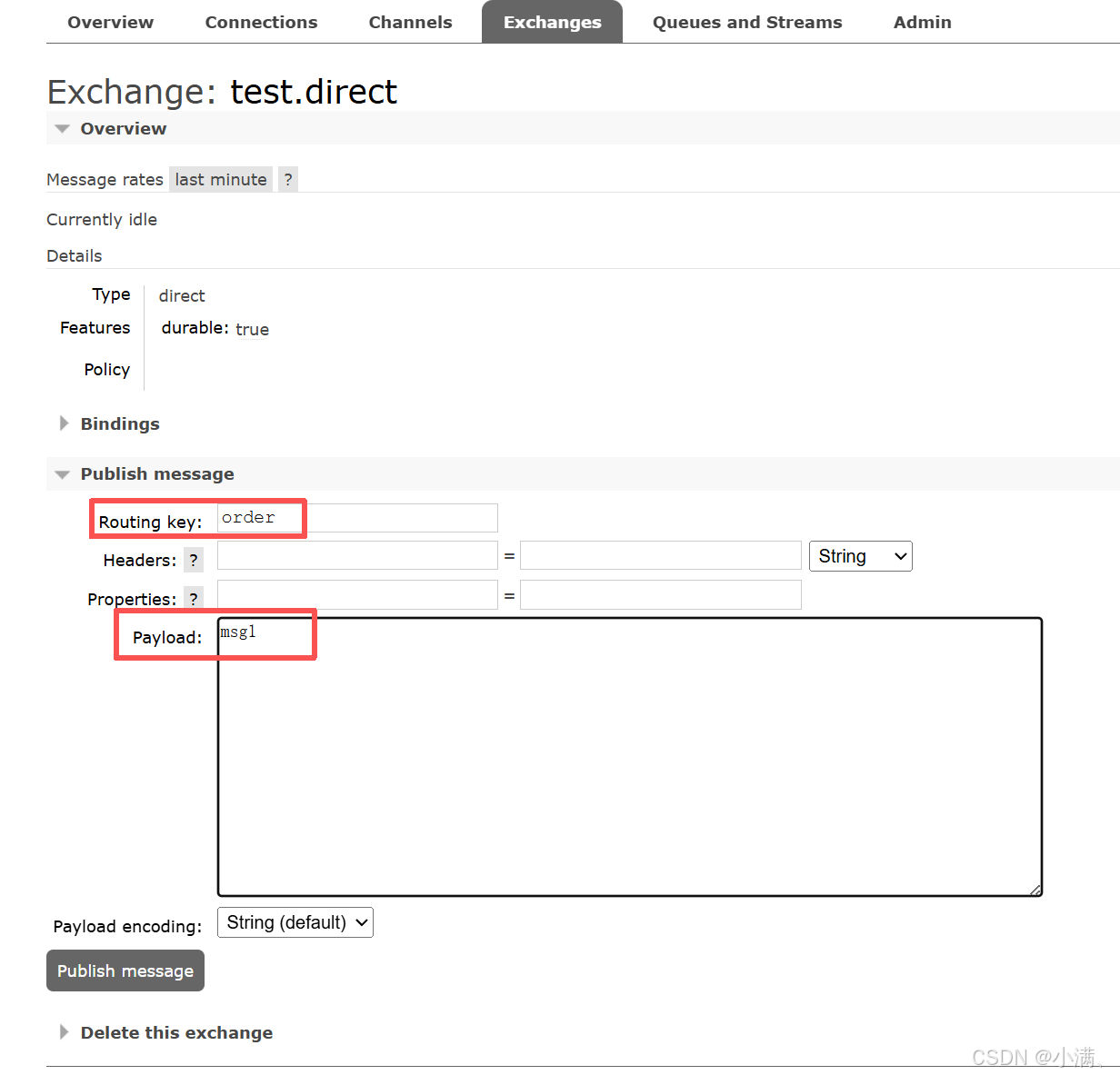
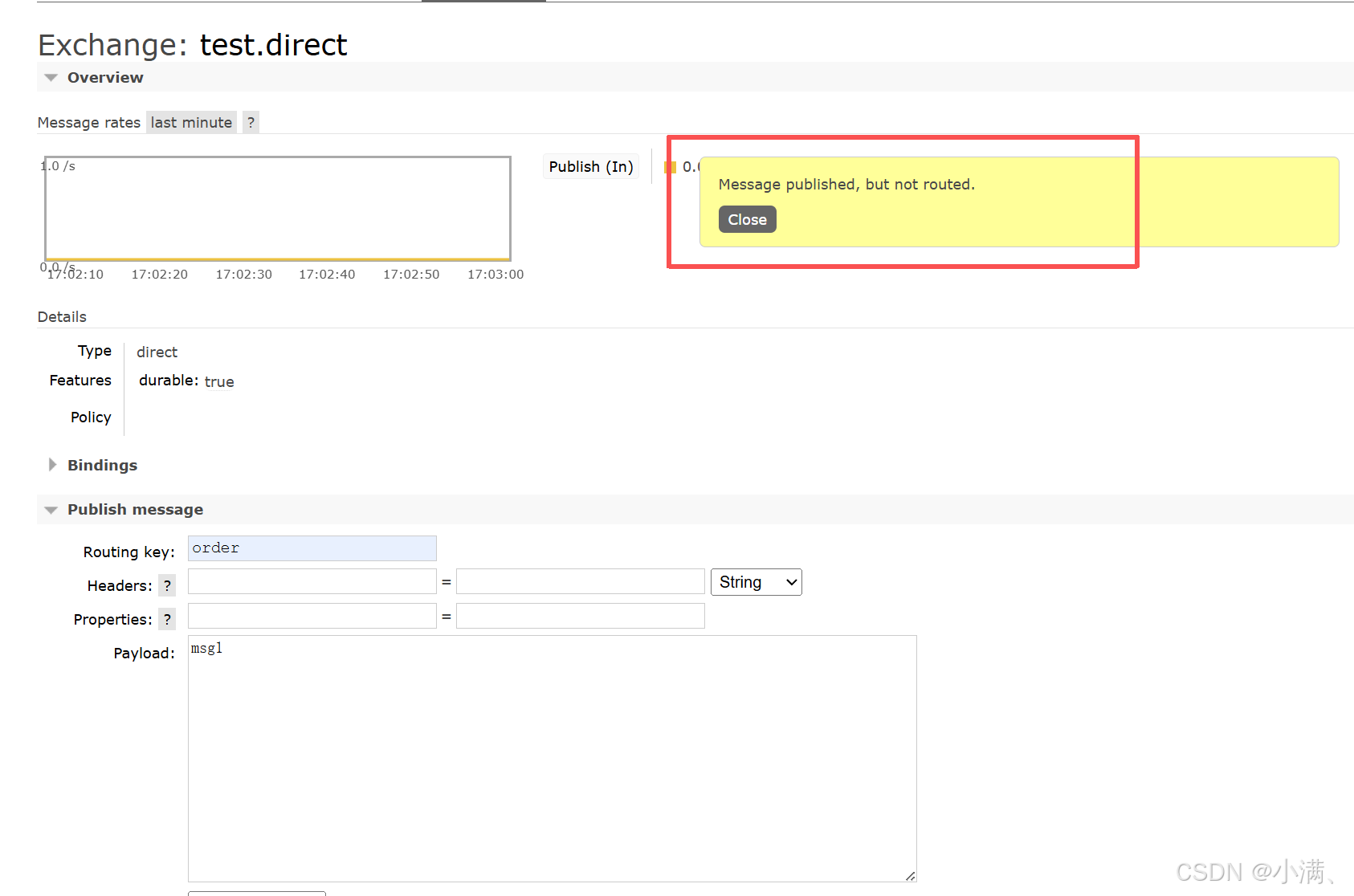
控制台提示:
Message published, but not routed3. 观察结果
没有任何队列收到消息
控制台无报错
4. 结论
消息到达了交换机,但没有匹配的队列,最终被直接丢弃。
实践二:验证 Direct 交换机是 精确匹配
1. 实验目的
验证 Direct Exchange 依赖 routing key 的精确匹配规则。
2. 操作步骤
(1)创建队列:
order.queue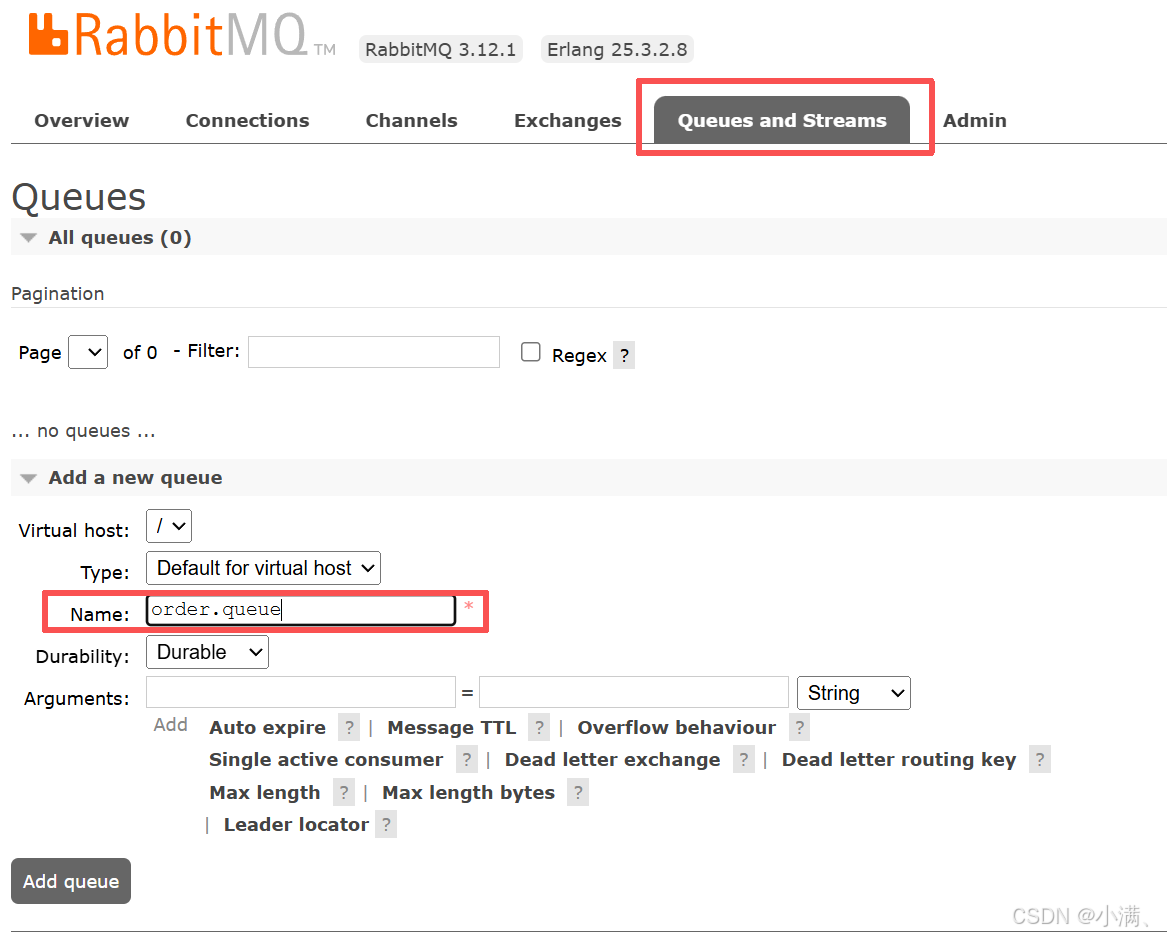
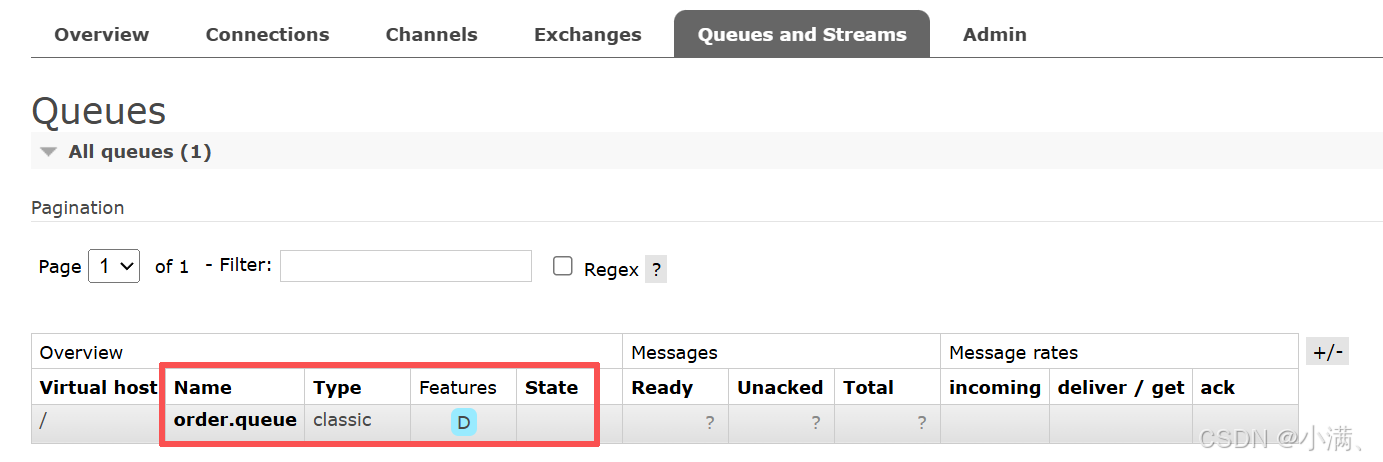
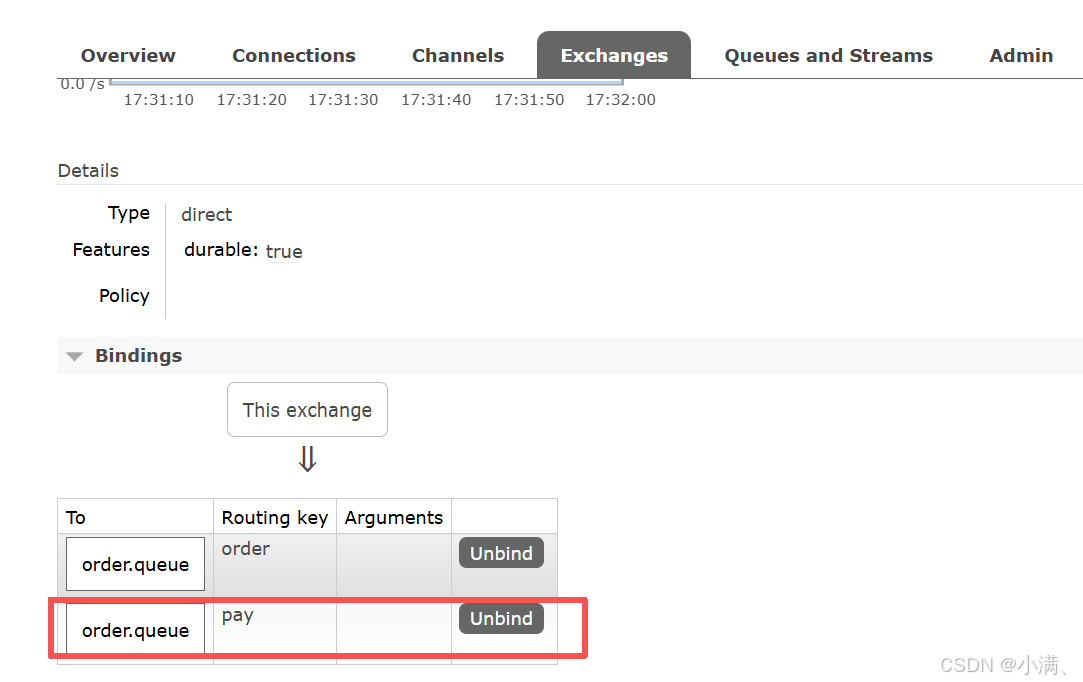
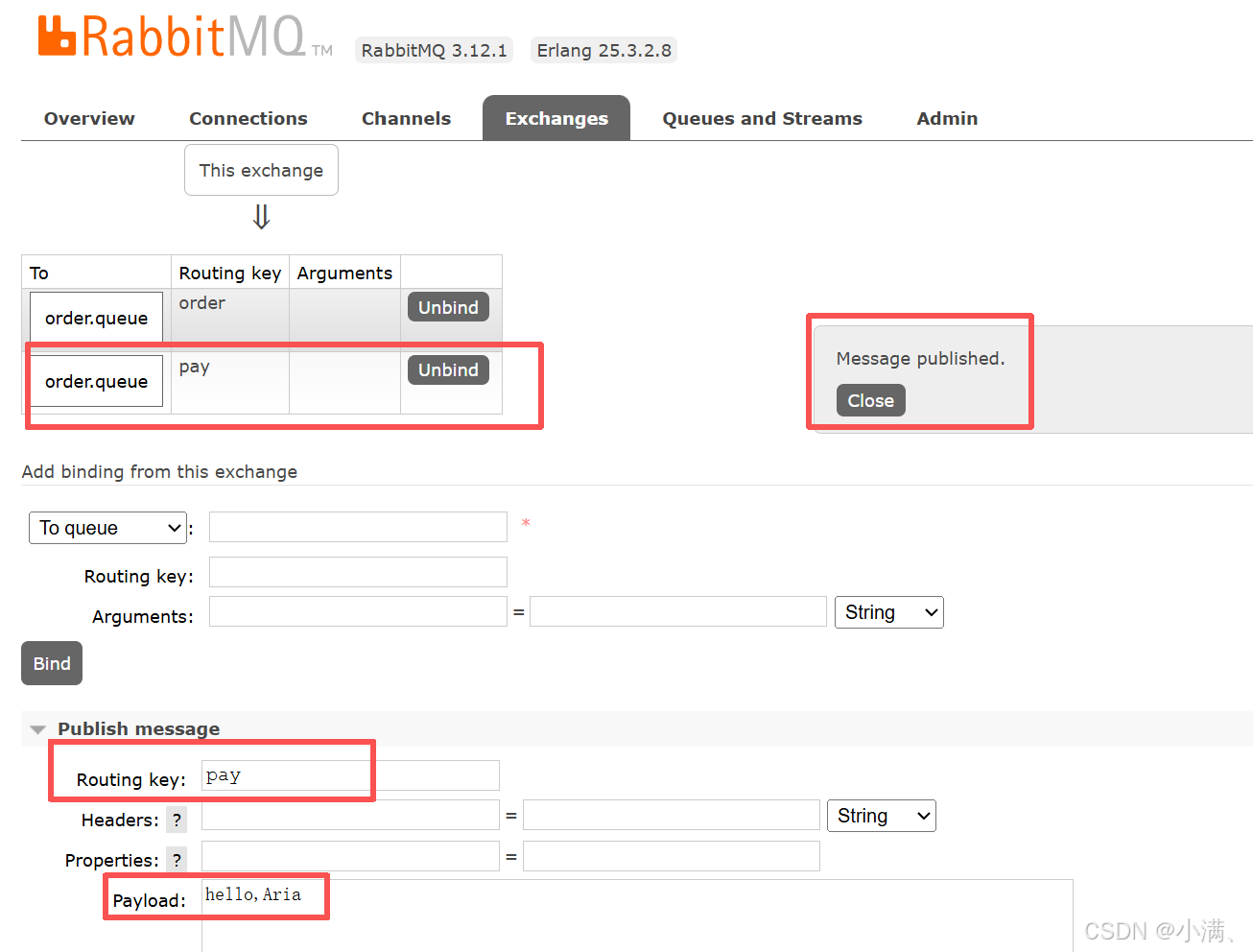
(2)绑定关系:
Exchange:test.direct
Queue:order.queue
Routing key:order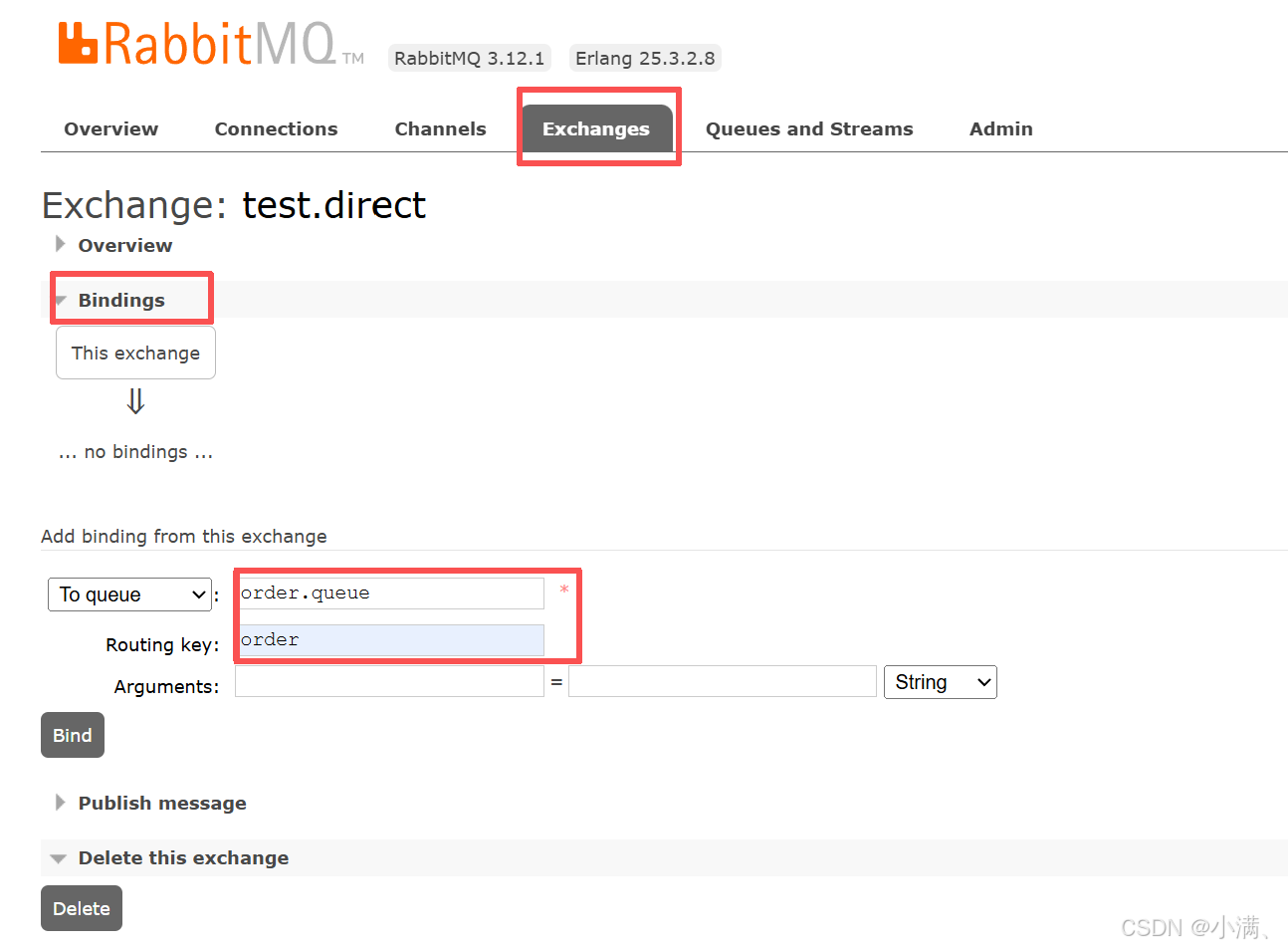
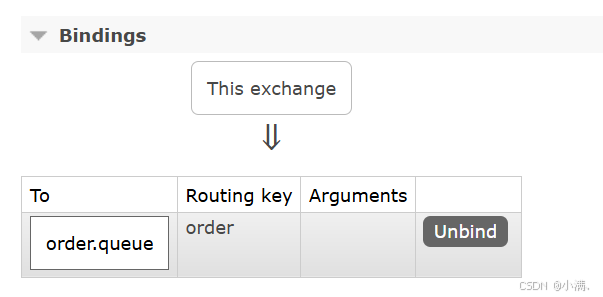
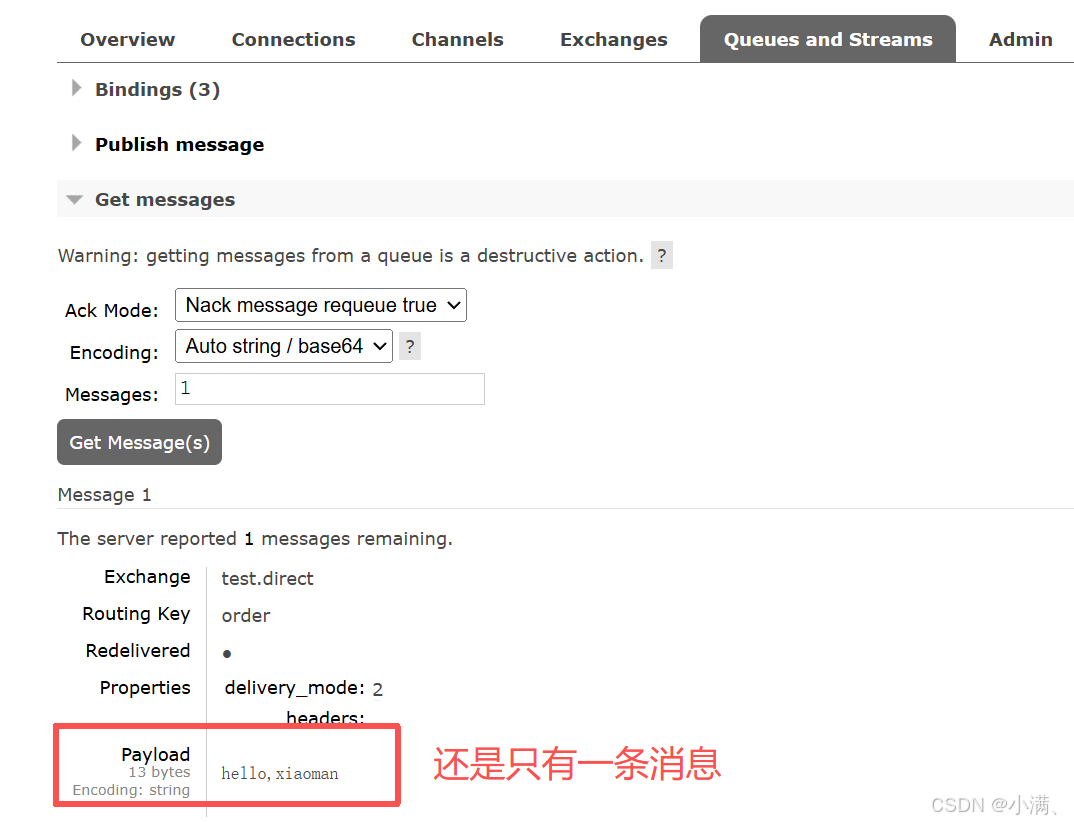
(3)发布消息测试:
Routing key:order → 能收到
Routing key:pay → 收不到
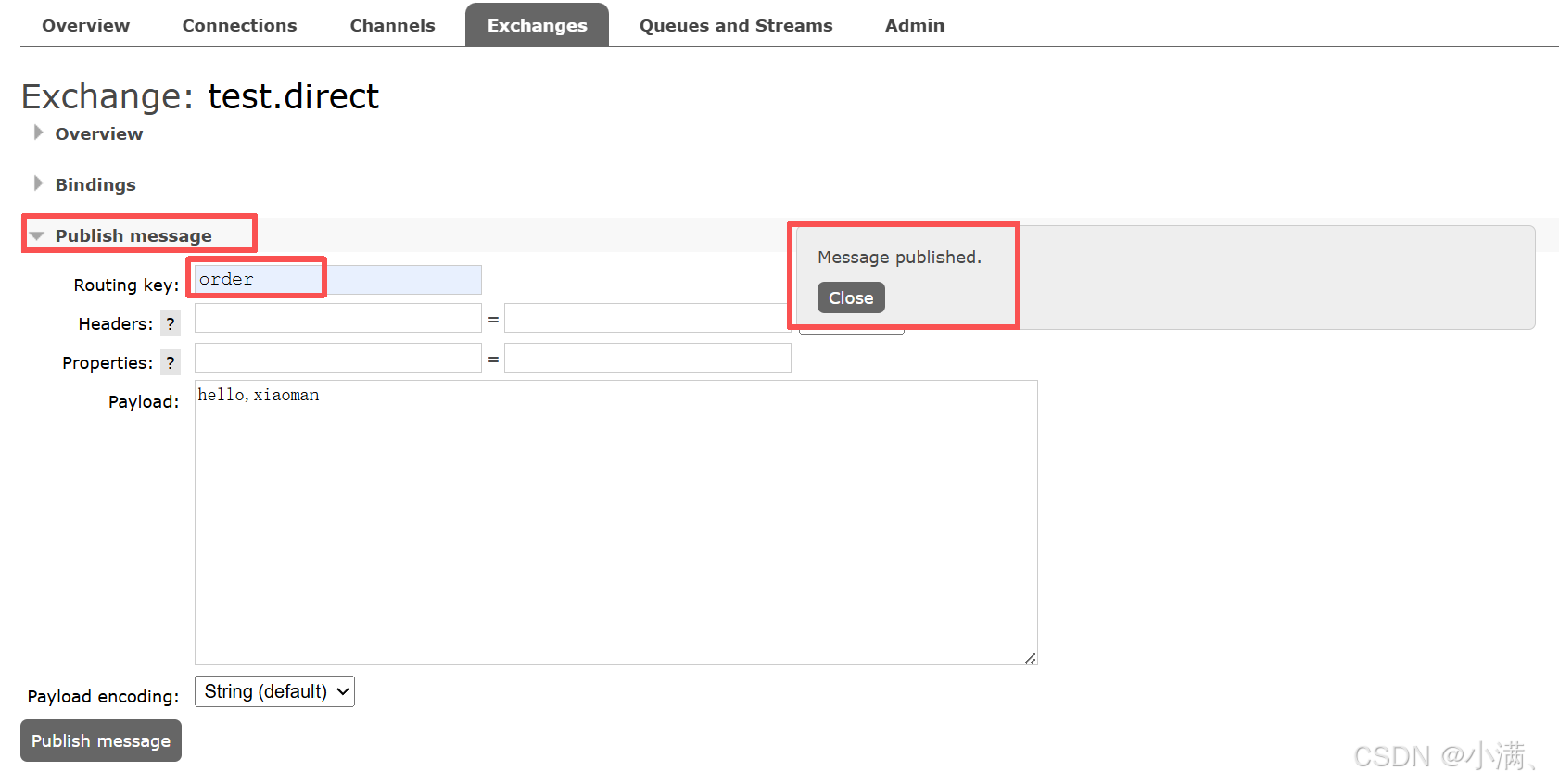
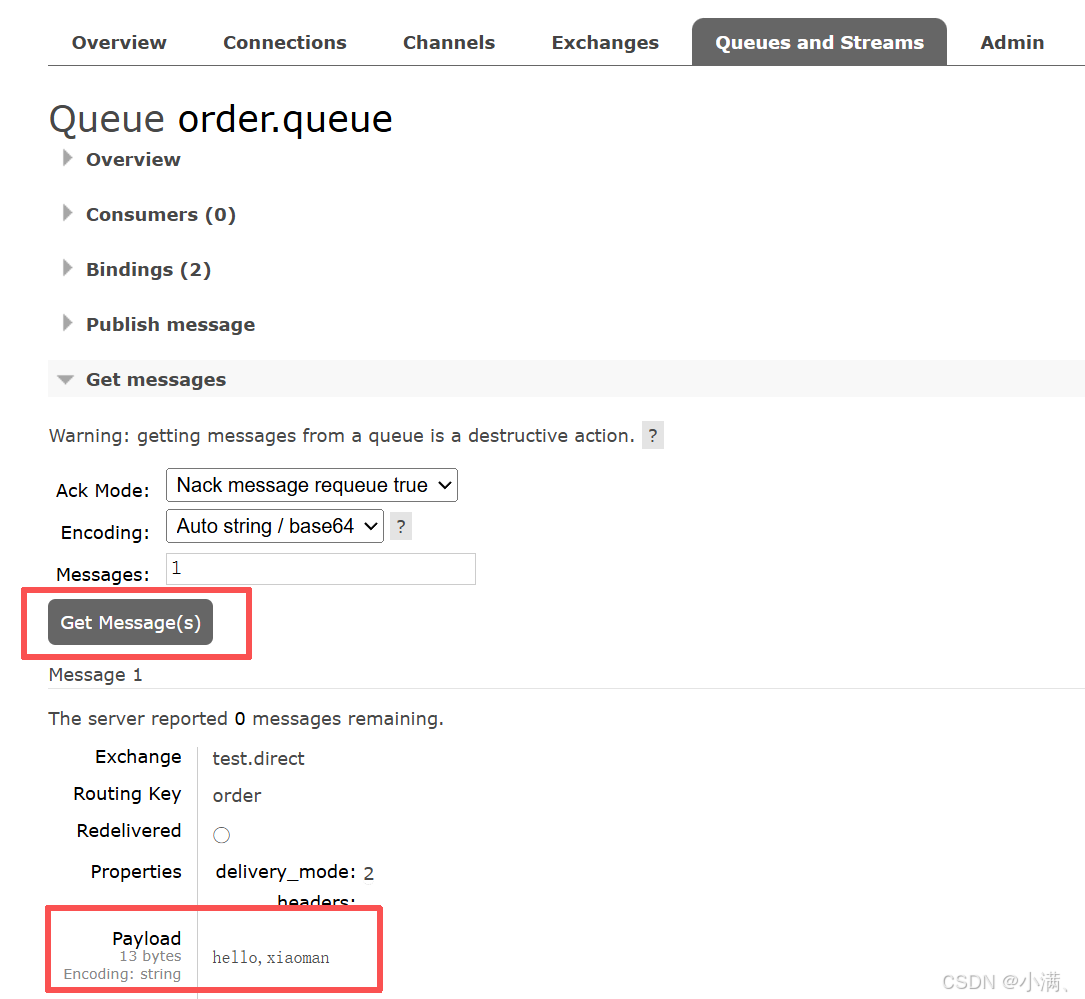
3. 结论
在 Direct 交换机中,routing key 与 binding key 必须完全一致,消息才会被路由到队列。
实践三:验证 Topic 交换机的通配符规则
1. 实验目的
理解 Topic Exchange 的模糊匹配机制。
2. 操作步骤
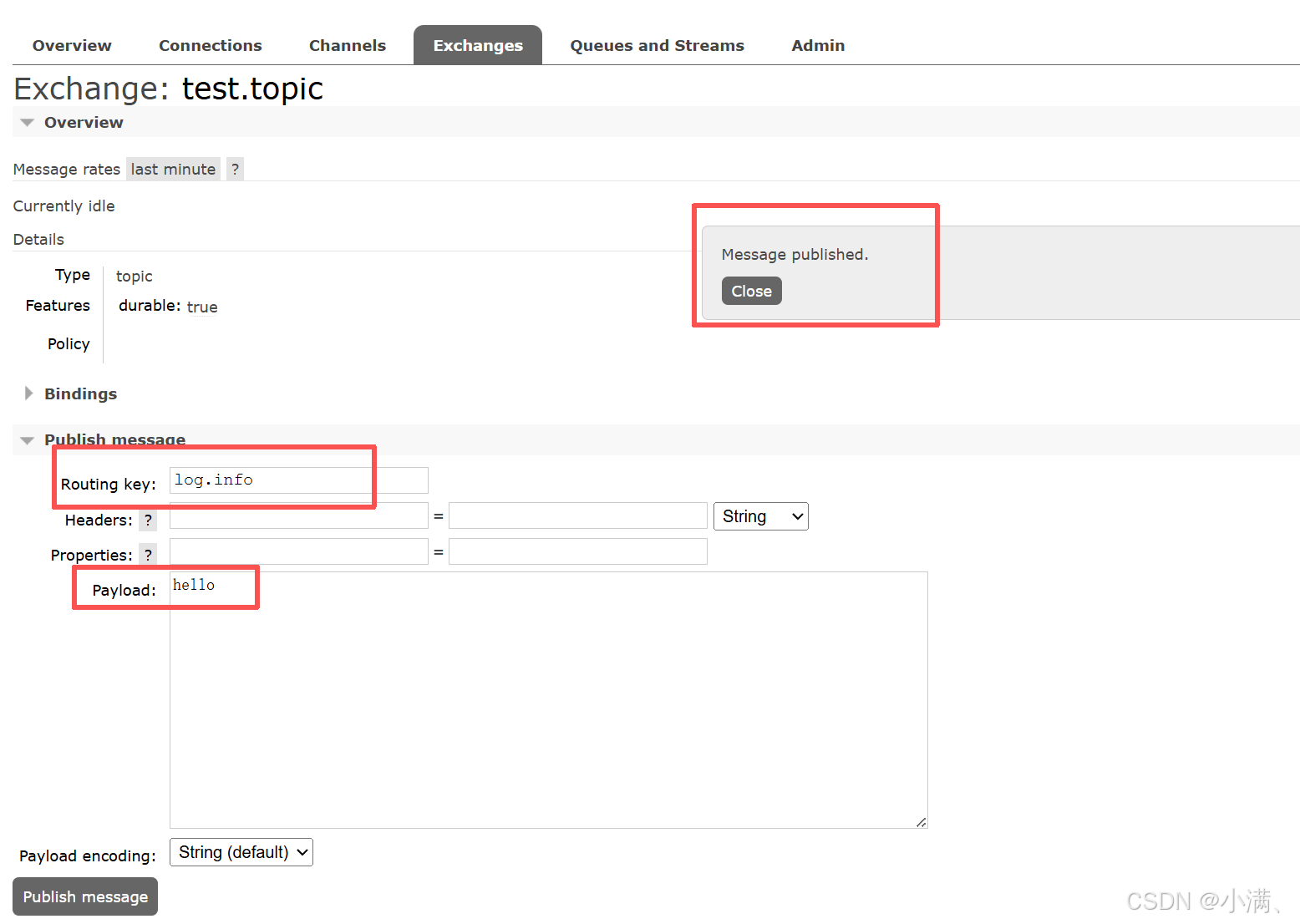
(1)新建交换机:
Name:test.topic
Type:topic
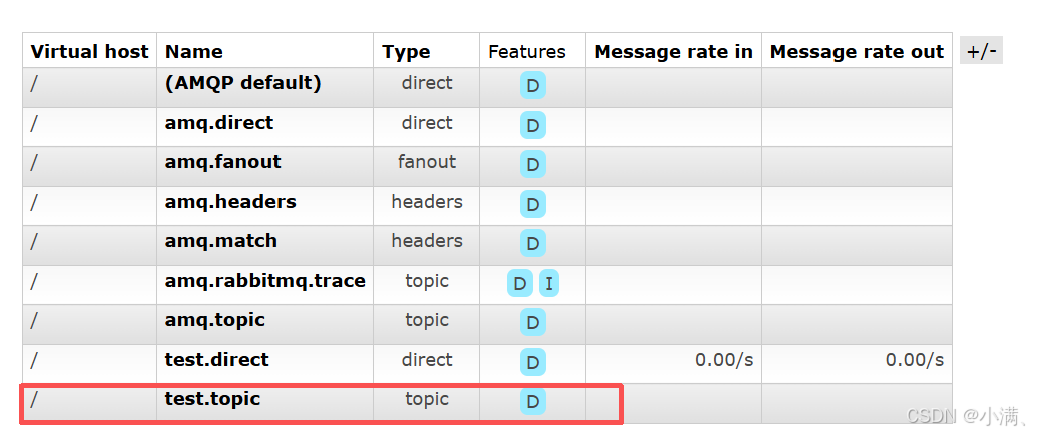
(2) 新建队列:
log.queue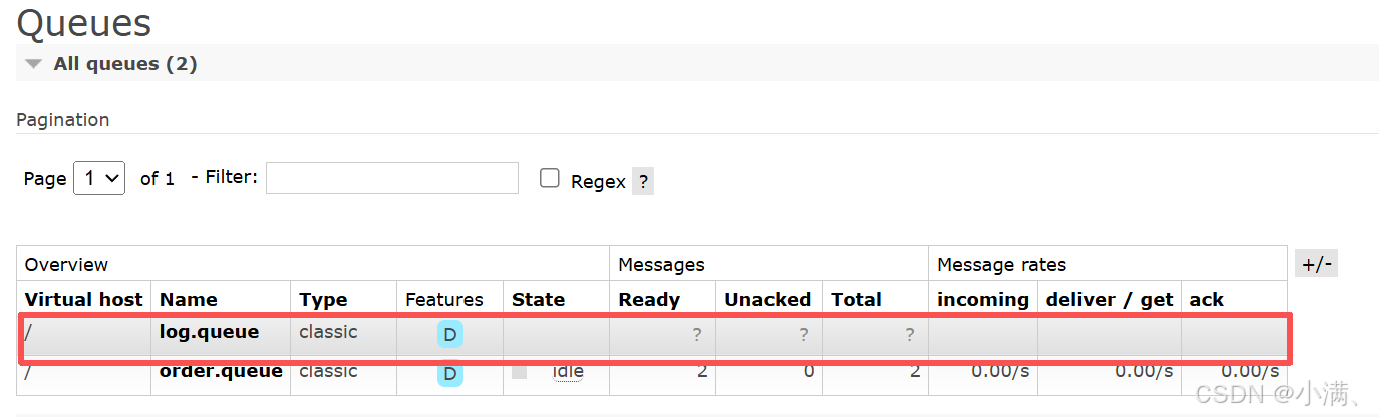
(3) 绑定:
Routing key:log.*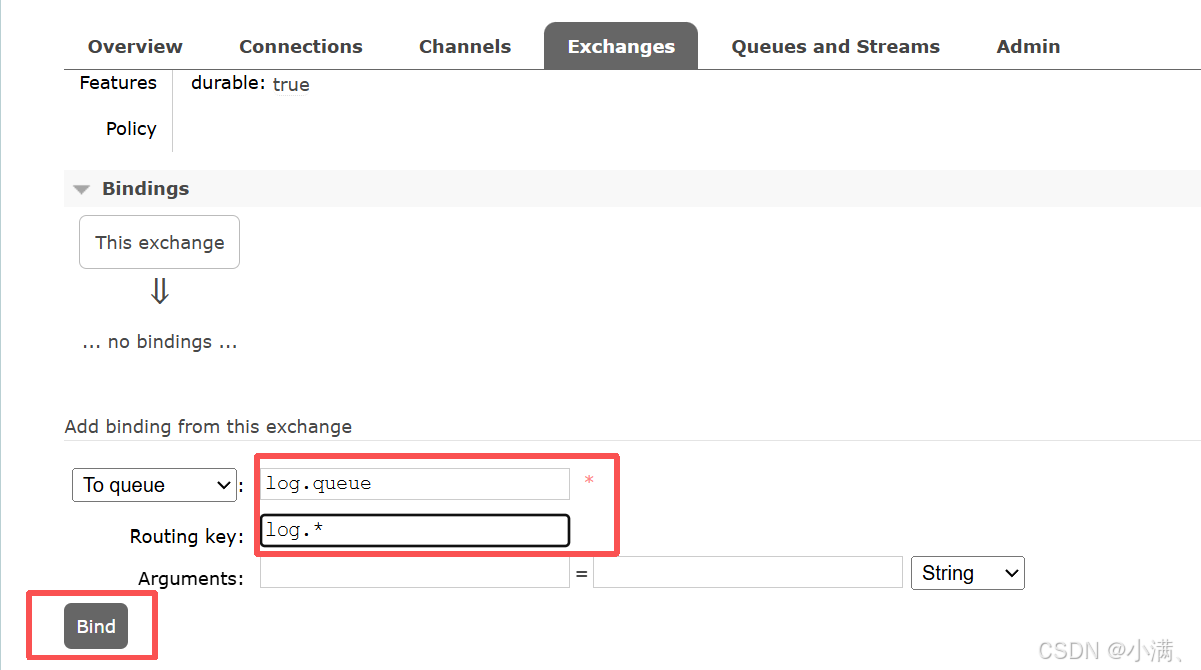
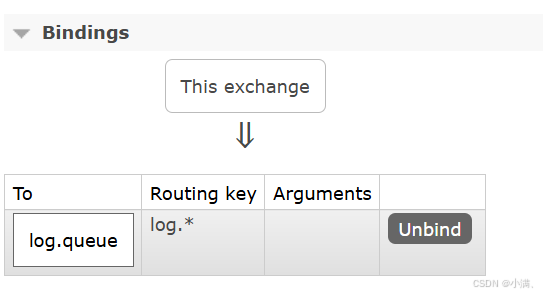
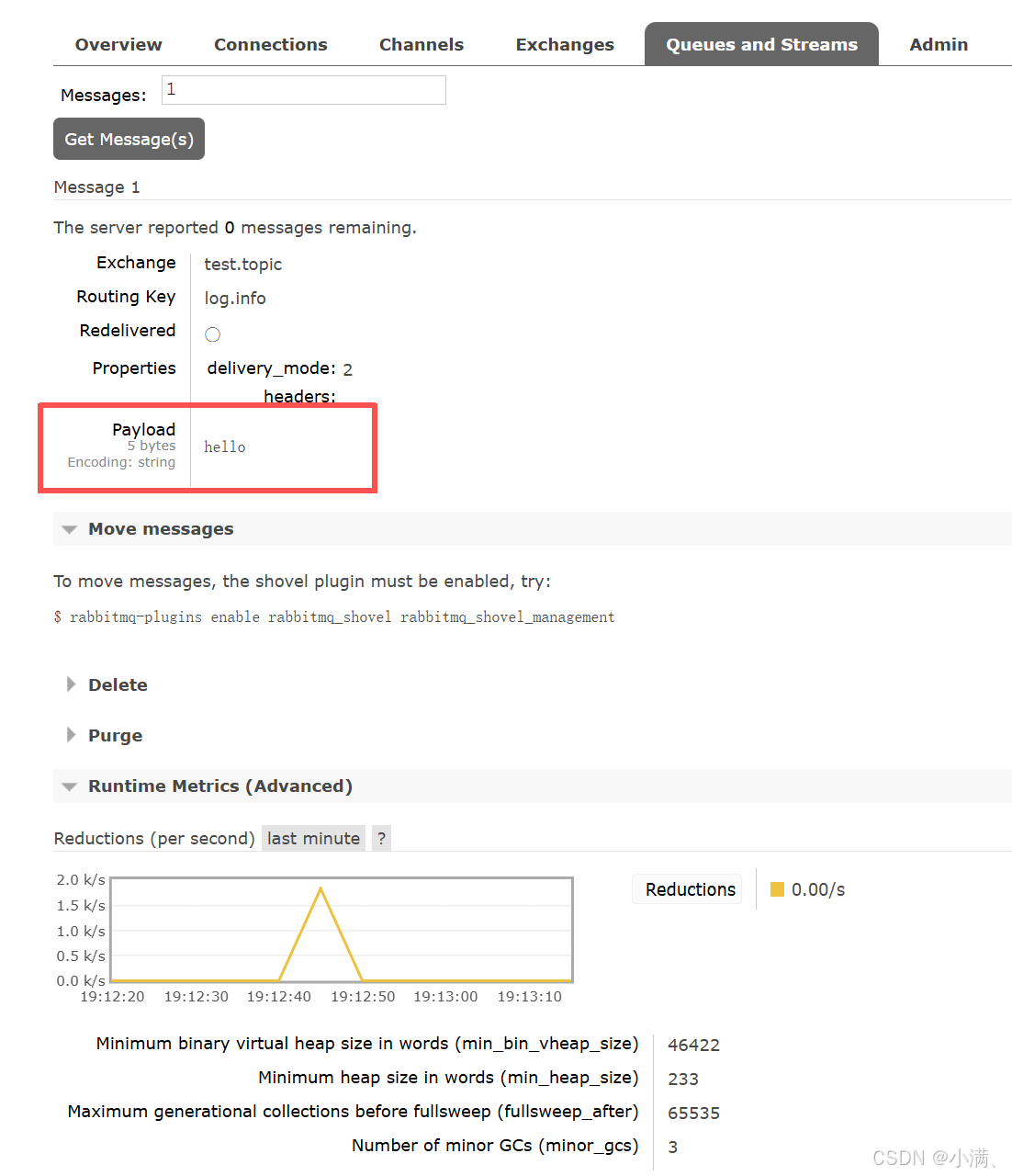
发布消息测试:
| routing key | 是否收到 |
|---|---|
| log.info | 是 |
| log.error | 是 |
| log.system.error | 否 |
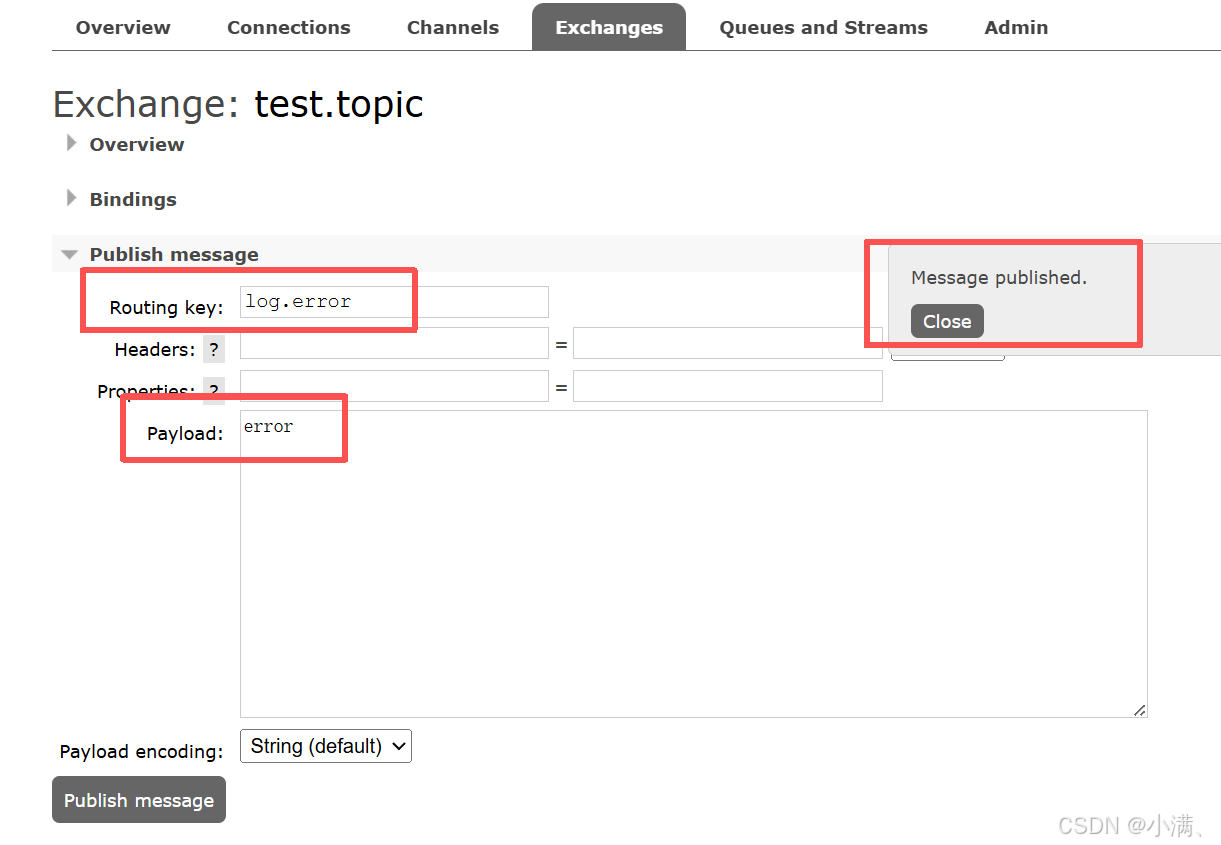
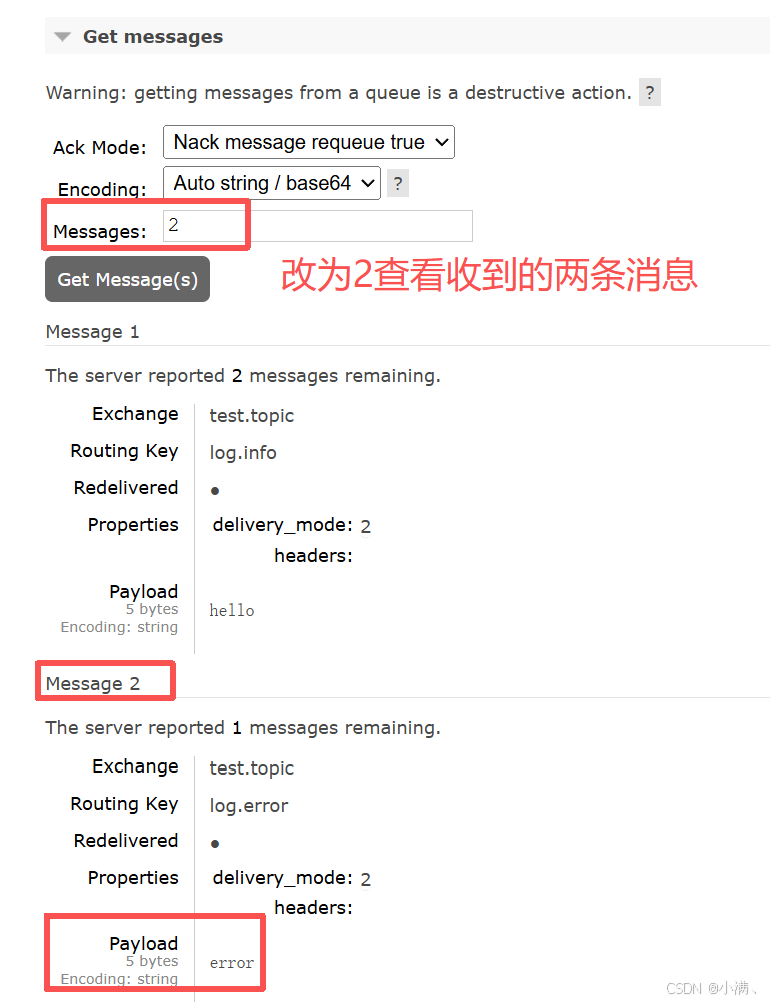
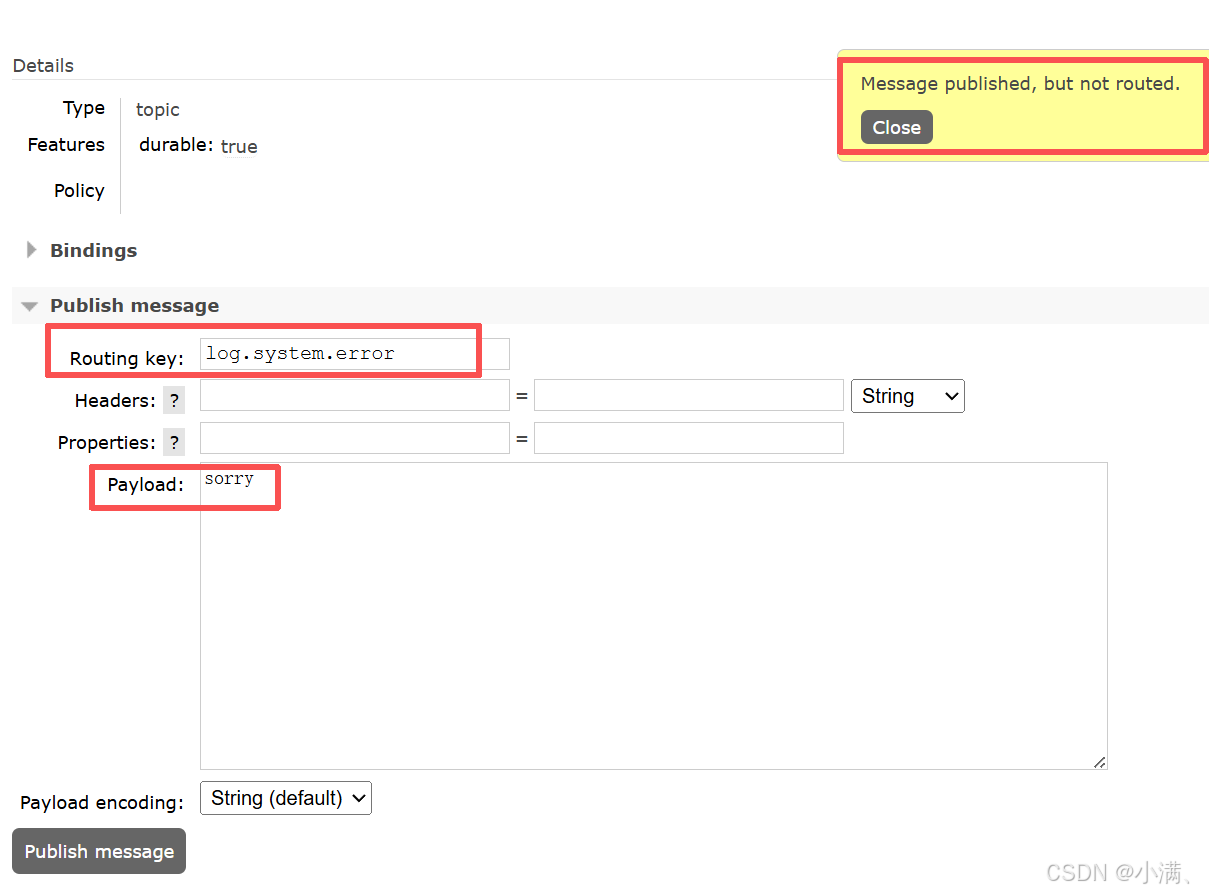
再绑定一条规则:
Routing key:log.#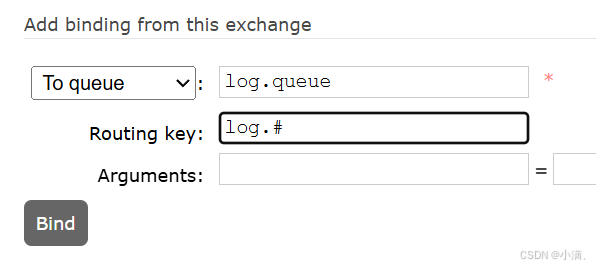
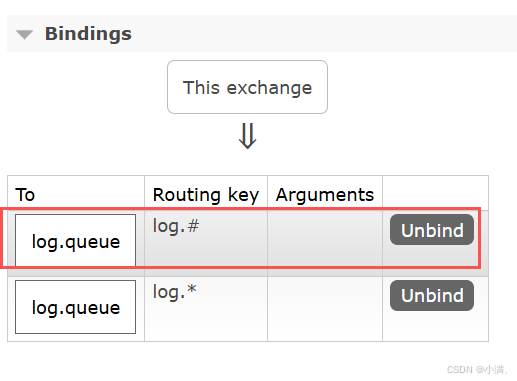
再次发送:
log.system.error → ✔
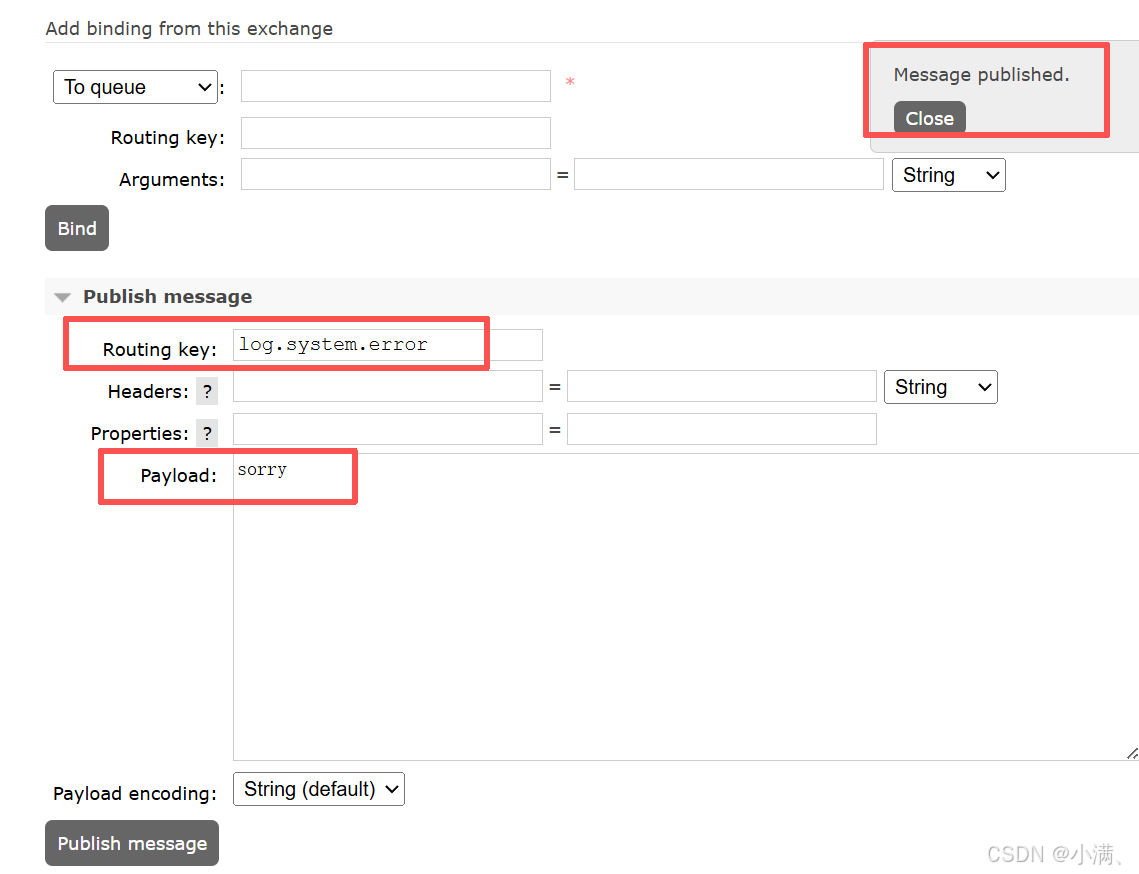
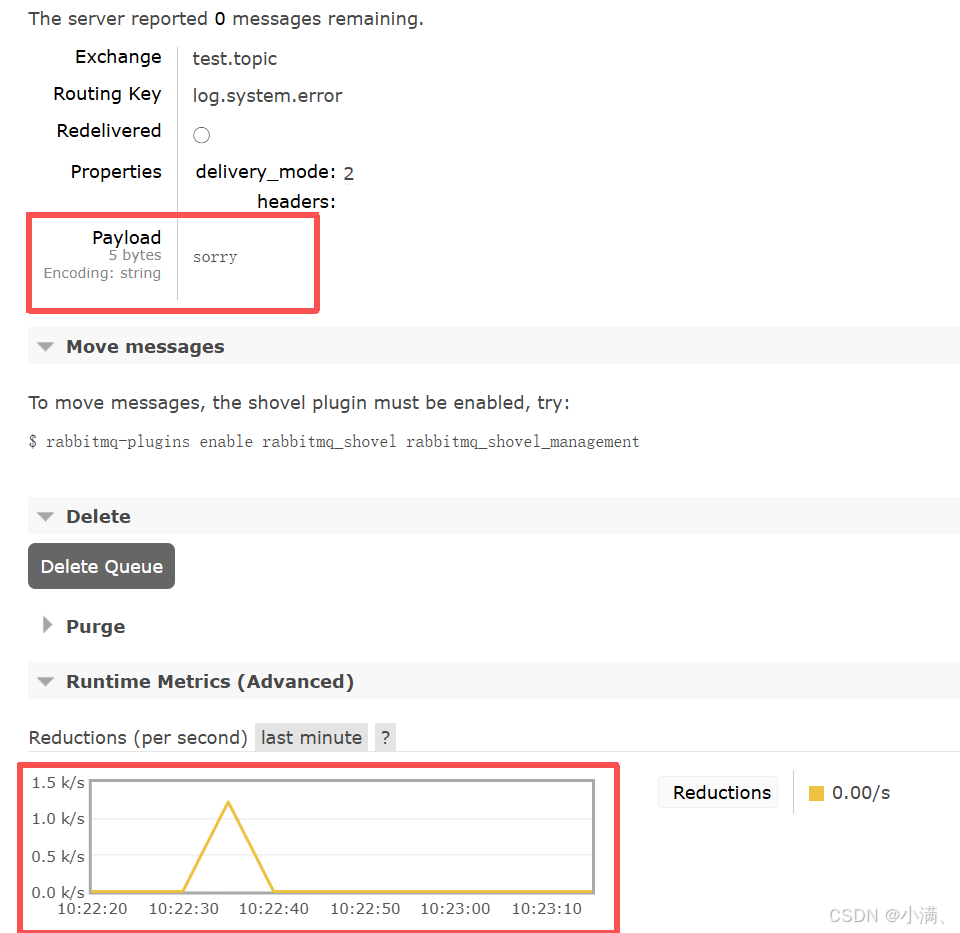
3. 结论
Topic 是基于规则的模糊匹配,但依然是路由机制,而不是广播。
实践四:验证Fanout 才是真正的广播
1. 实验目的
区分广播与路由。
2. 操作步骤:
(1)创建两个队列
queue1
queue2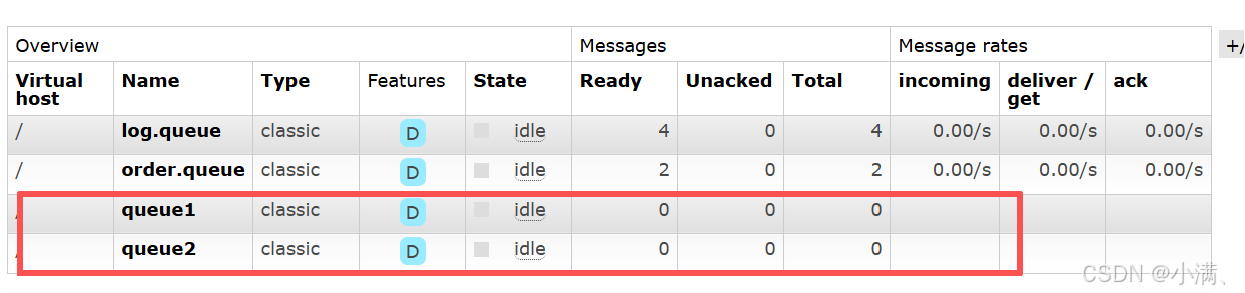
(2)将两个队列都绑定到 amq.fanout
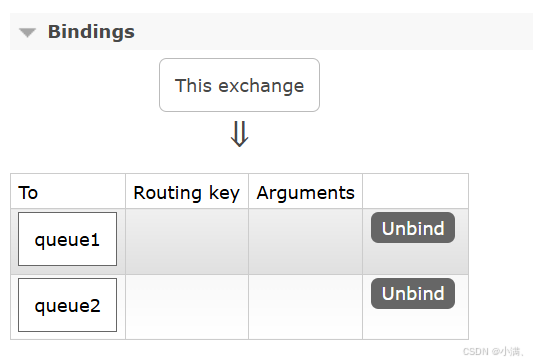
(3)在 amq.fanout 页面发布消息
在 Publish message 区域:
Routing key:任意 / 不填
Payload:hello fanout
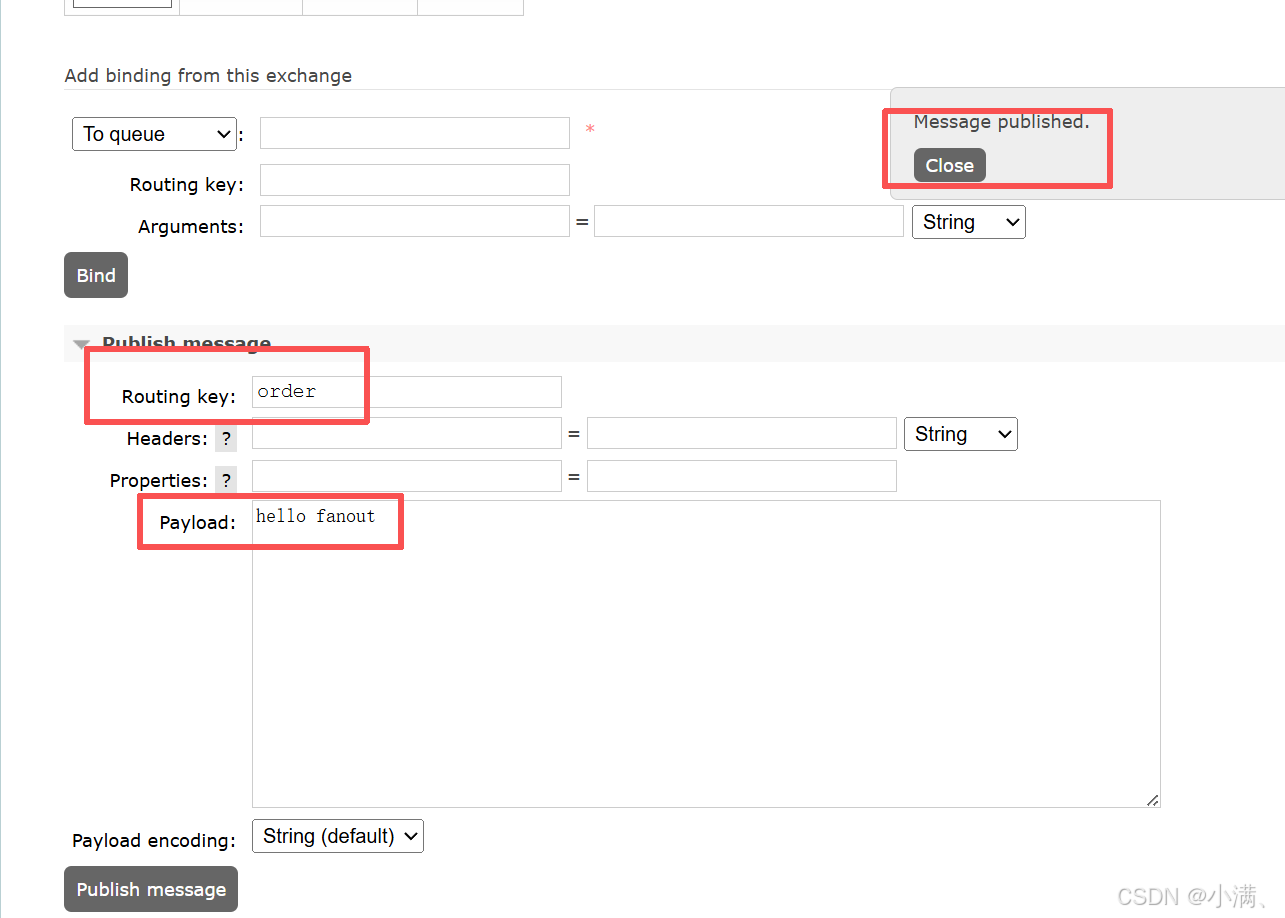
去两个队列里 Get message
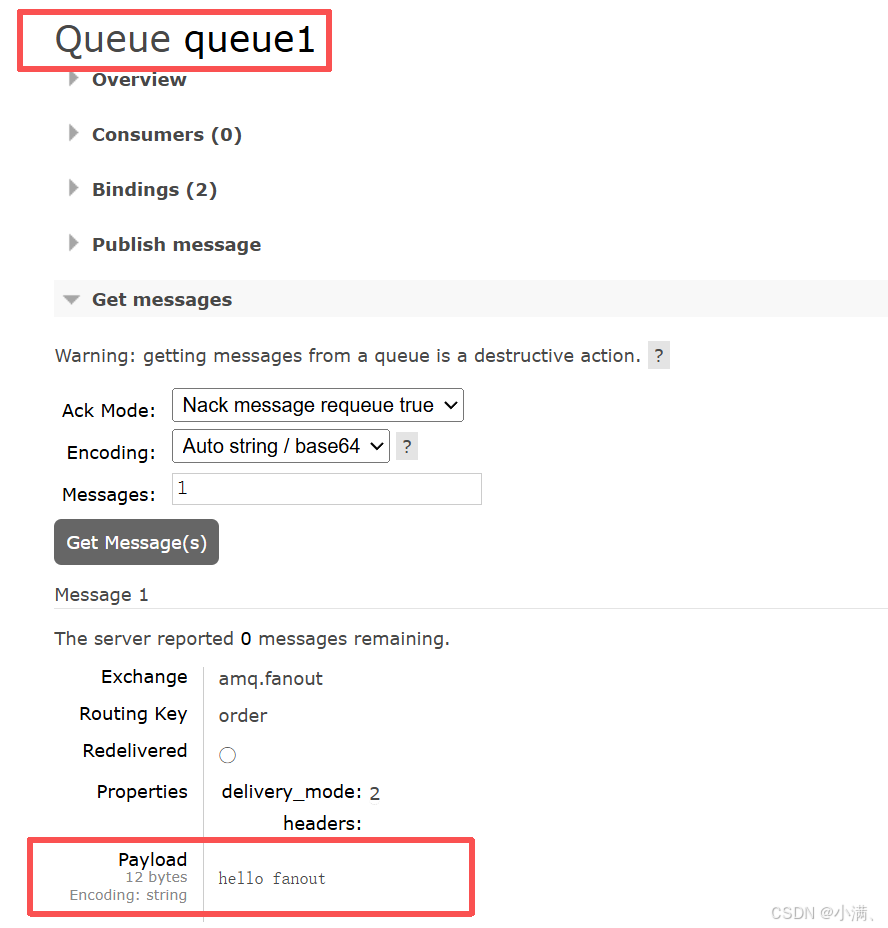
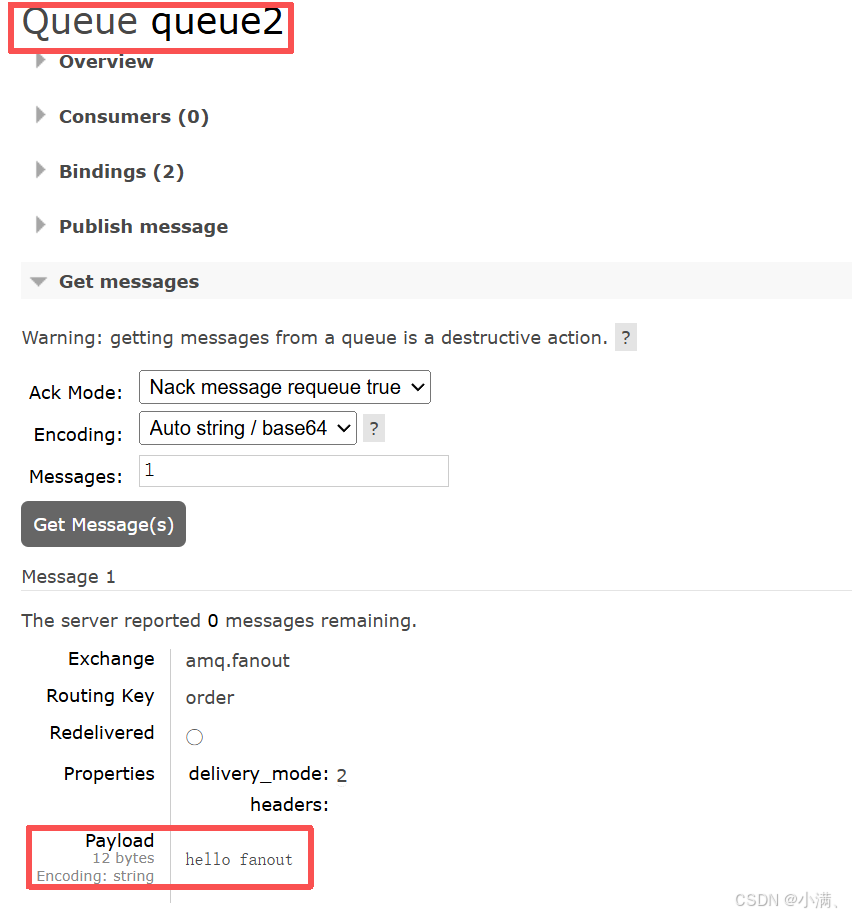
3. 观察现象
routing key 填什么都没用
所有绑定队列都收到
4. 结论
广播是 Fanout 交换机的特性,不是所有交换机的通用能力。
实践五:验证队列才是真正存消息的地方
1. 实验目的
确认消息存储位置及持久化行为。
2. 操作步骤
(1)创建交换机(Direct)
**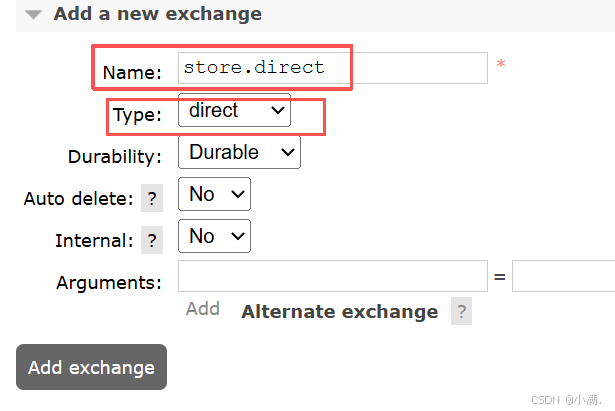 **
**
(2)创建队列(非持久化)
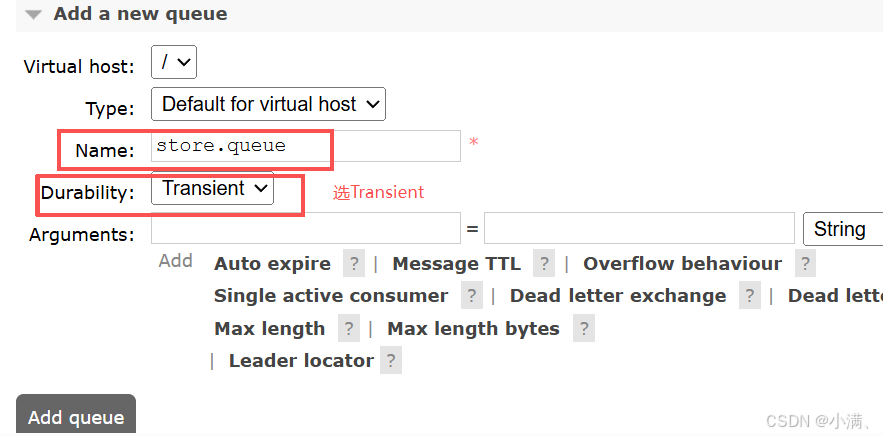
绑定队列到交换机
(3)绑定后连续发送 3 条消息
Routing key:order
Payload:
msg-1
msg-2
msg-3不要 Get,直接观察队列
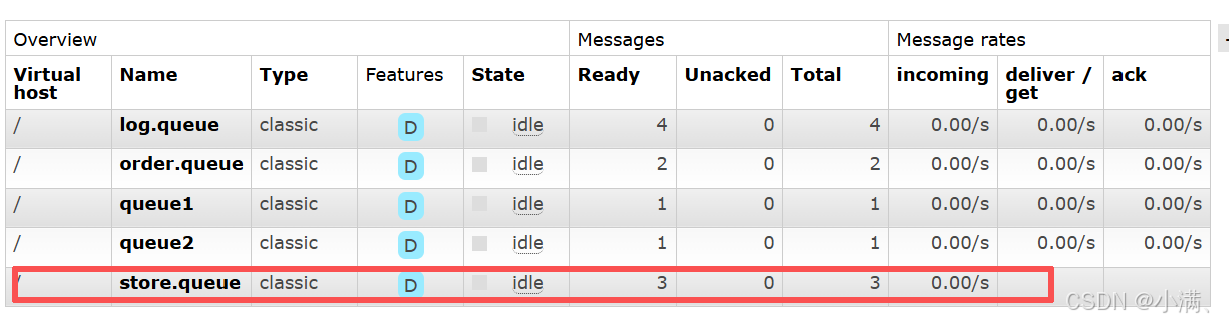
可以看到:
Ready:3
Unacked:0
说明:消息已经存进队列
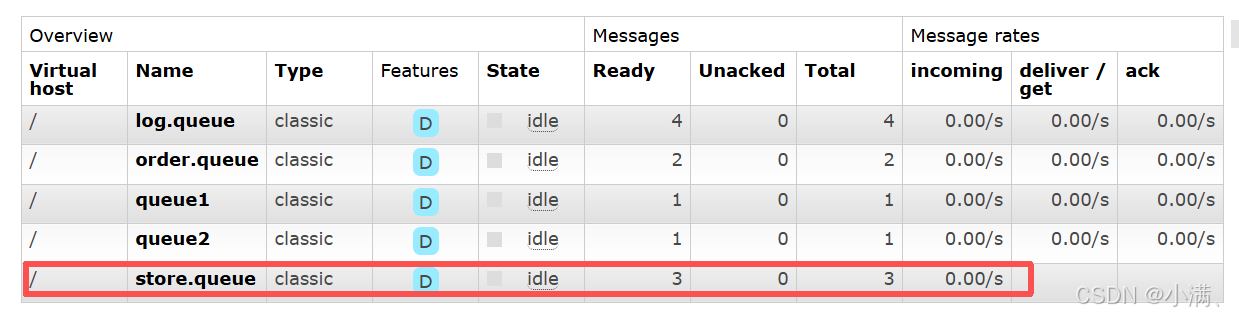
刷新浏览器页面(F5)
再次查看:
Ready:3
说明:刷新不会影响消息
重启 RabbitMQ
在服务器执行:
sudo systemctl restart rabbitmq-server
再次进入控制台查看队列
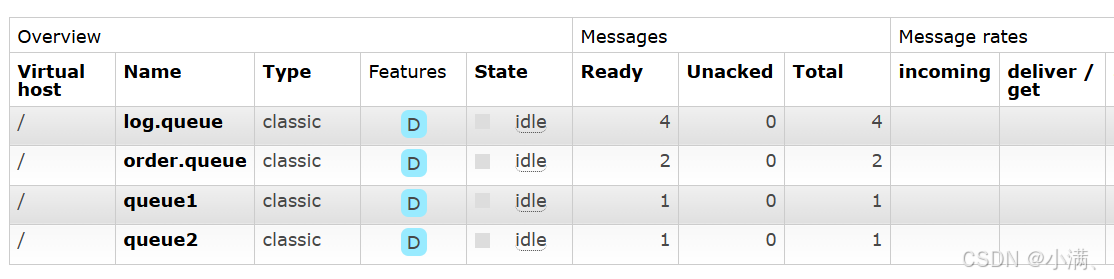
再次进入控制台:
队列消失
消息随之丢失
管理控制台发布消息时,默认使用 persistent 模式,且当前 UI 无法修改 delivery_mode。
若需验证 transient 消息行为,需使用客户端代码或 CLI。
3. 结论
消息存储在队列中,而不是交换机;
是否持久化,取决于 队列 + 消息 的配置。
实践六:模拟多消费者竞争消费(工作队列)
1. 实验目的
验证 RabbitMQ 的竞争消费模型。
2. 操作步骤
(1)创建队列 work.queue
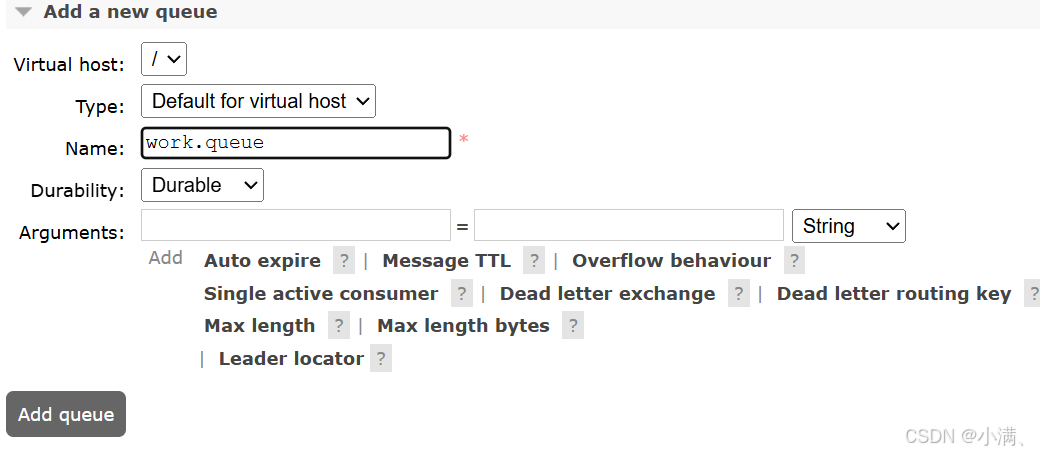
(2)向队列发送多条消息
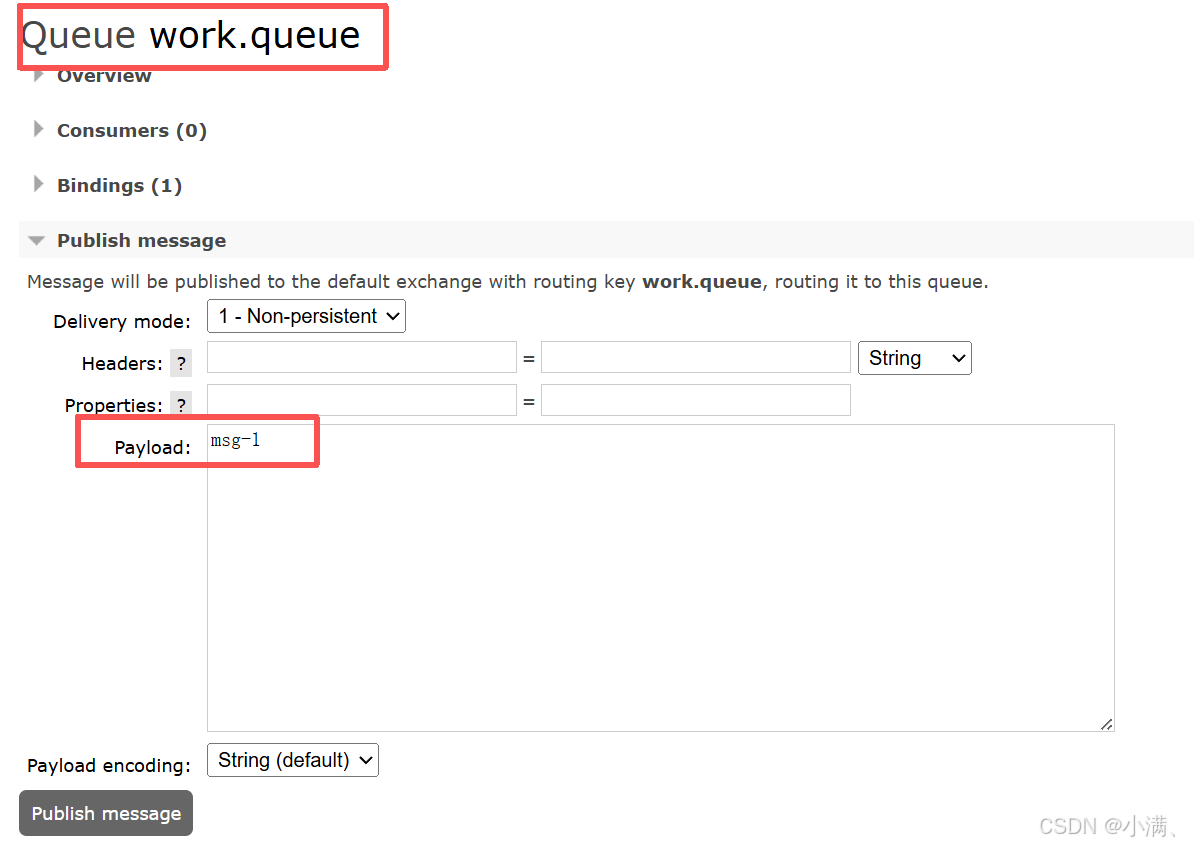
在work.queue队列页面直接发消息
Payload(多发几条):msg-1 msg-2 msg-3 msg-4
(3)打开多个浏览器窗口,模拟多个消费者
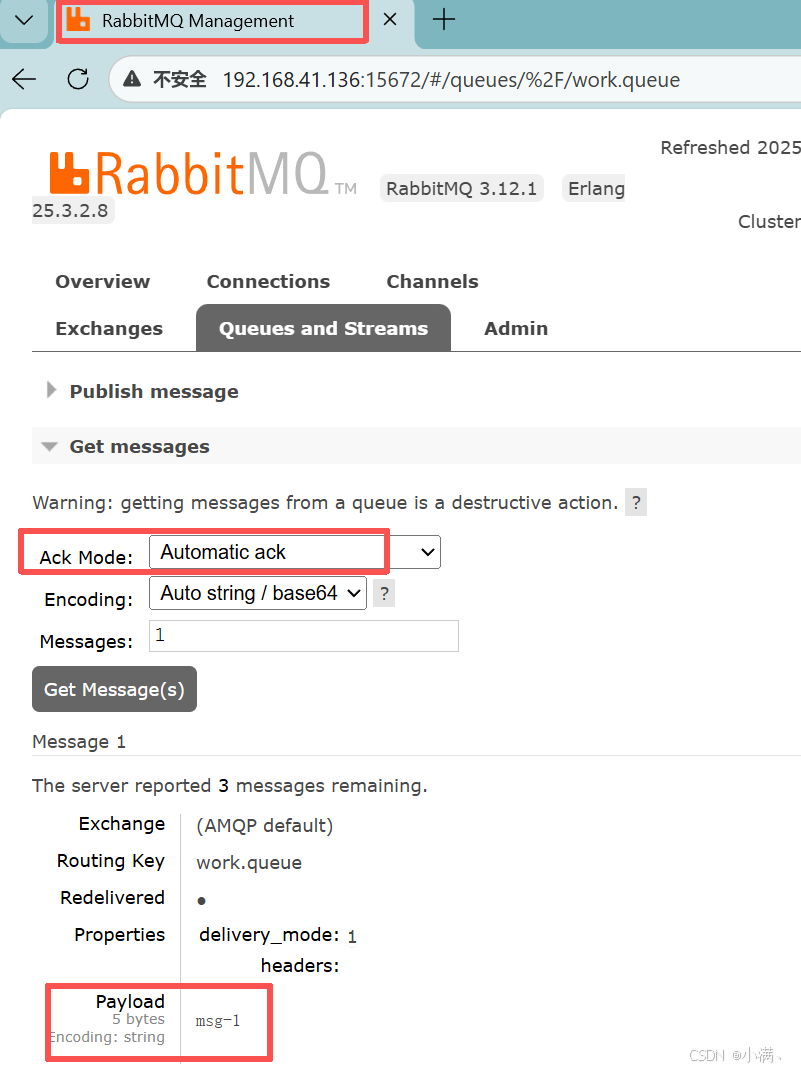
消费者 1(不确认)
Queues → work.queueAck mode:Automatic ack
Messages:1
点击 Get Message(s)
看到 msg-1 后:
此时什么都不要点(不 Reject、不 Nack、不关页面)

| 控制台 Ack mode | 实际语义 |
|---|---|
| Automatic ack | 自动确认(相当于 autoAck = true) |
| Reject requeue true | 手动拒绝 + 放回队列 |
| Reject requeue false | 手动拒绝 + 丢弃 |
| Nack message requeue true | 批量/单条 Nack + 放回队列 |
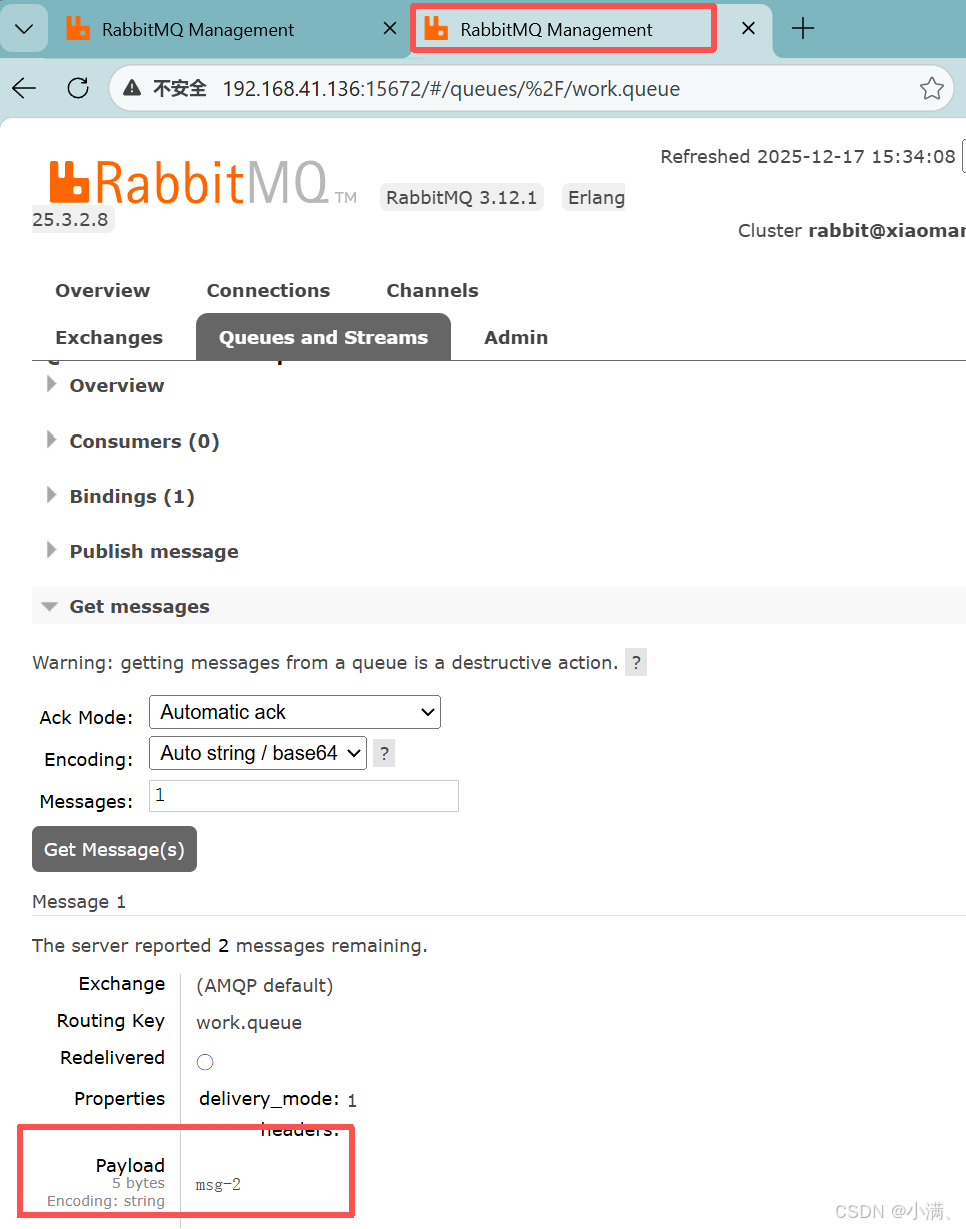
消费者 2(关键对照)
新开一个浏览器窗口 / 无痕窗口
同样进入:
Queues → work.queue → Get messages设置同样的 Ack mode
点击 Get Message(s)
你会看到:
拿到的是 msg-2
绝对拿不到 msg-1
再开窗口,得到msg-3
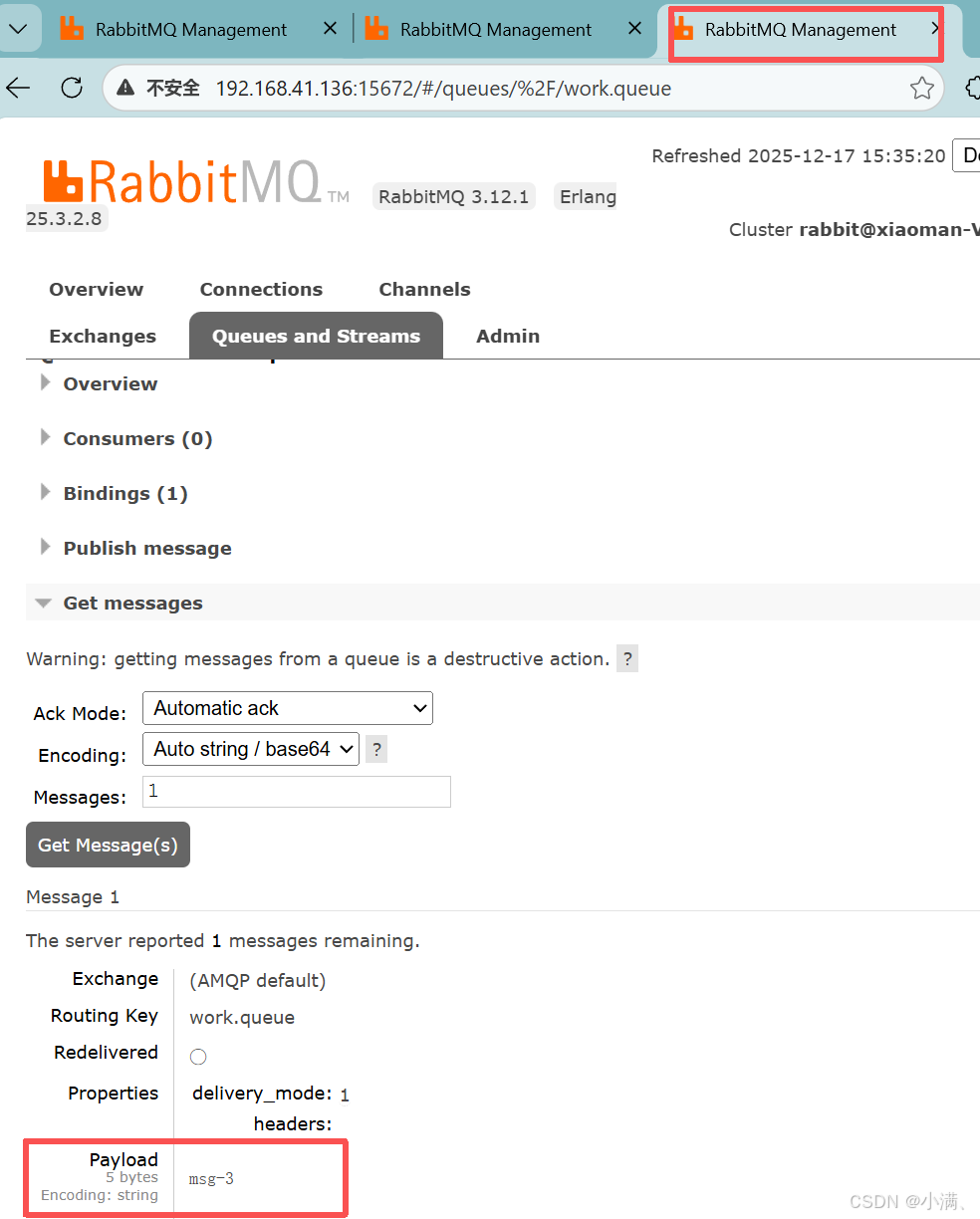
观察队列状态
刷新队列列表页
Queues → work.queue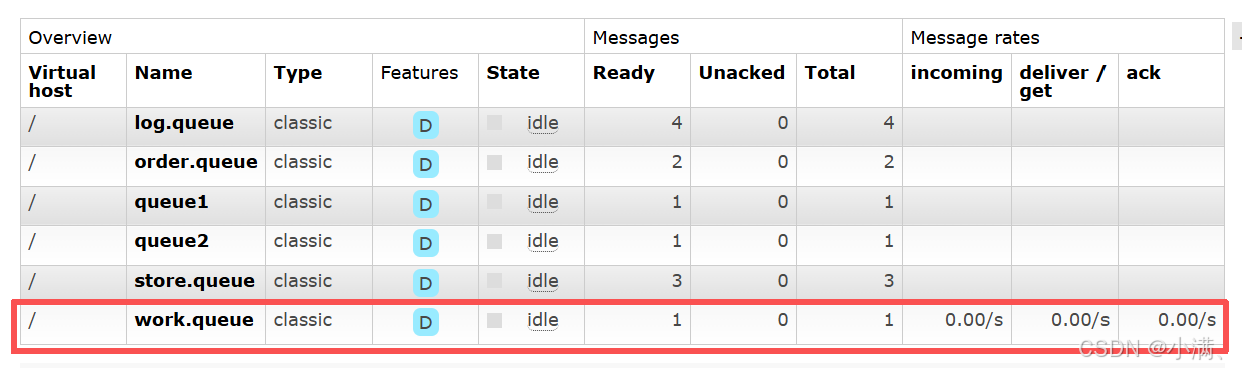
3. 结论
RabbitMQ 的竞争消费本质是队列级别的,每条消息只会被一个消费者消费;Ack 模式只是控制消息确认和 Unacked 显示,Automatic ack 不破坏竞争消费,只是看不到未确认状态。(RabbitMQ 的竞争消费是队列级别的:一条消息只会被一个消费者处理。)
实践七:验证广播 + 各自消费
1. 实验目的
区分广播模型与竞争消费模型。
2. 操作步骤
(1)创建队列 queue1、queue2
(2)绑定队列到交换机
注意:fanout 类型的交换机 不使用 routing key,消息会广播到所有绑定队列
(3)发布广播消息
fanout.ex → Publish message:
Payload:
msg-broadcast-1(4)分别消费两个队列
消息会被复制到 queue1 和 queue2,每个队列都有一份。
各自消费消息
消费 queue1
查看到:
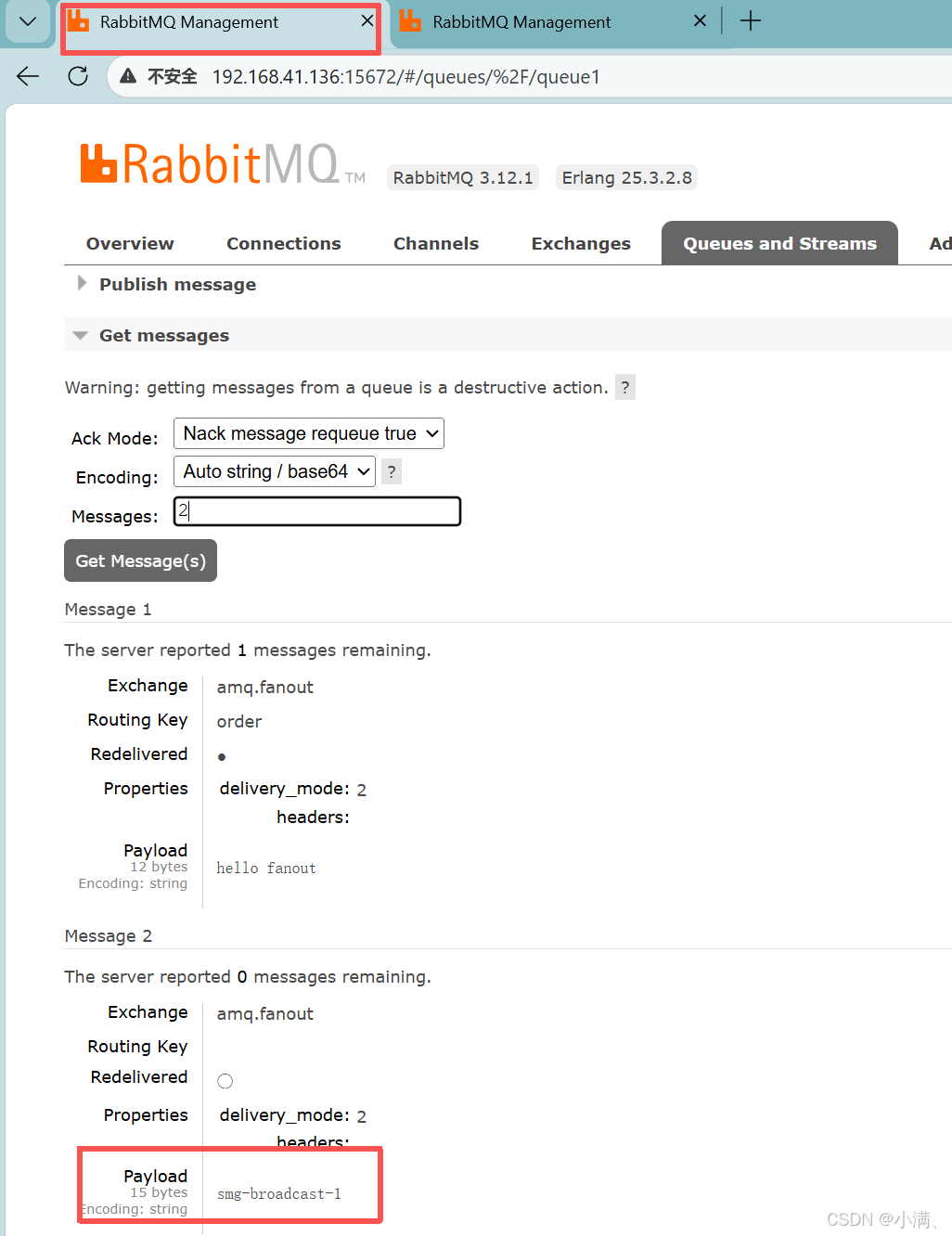
消费 queue2
新开一个窗口或标签页:
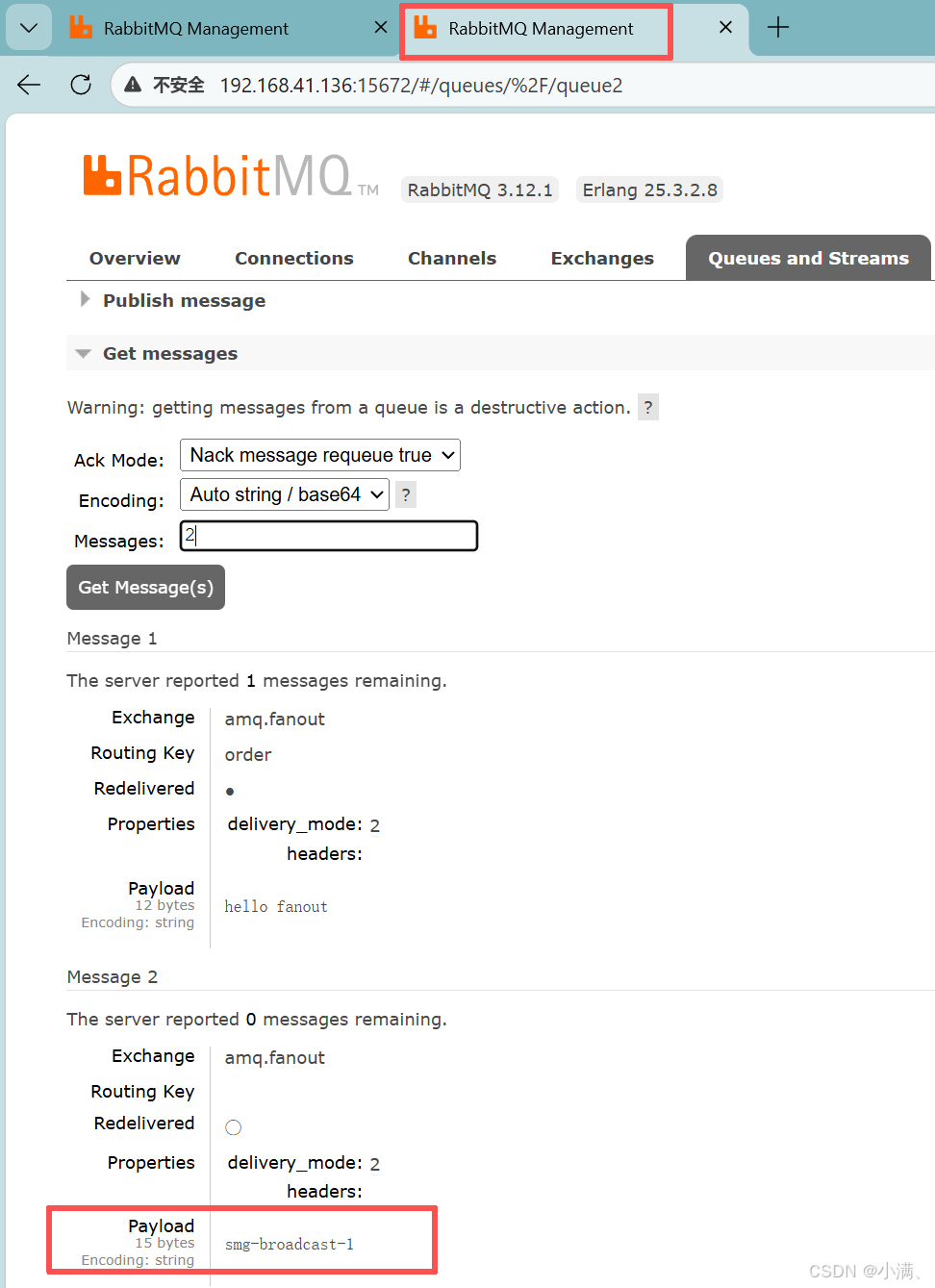
3. 观察结果
两个队列各自都有完整消息副本,消费互不影响。
4. 实验结论
广播 ≠ 多消费者
广播是:消息复制到多个队列
多消费者是:同一队列,消费者竞争
十一、总结
本文从同步调用与异步调用的对比出发,分析了同步调用在分布式系统中面临的性能瓶颈、系统耦合和级联失败问题,并引出了以消息队列为核心的异步通信方案。随后,通过对 RabbitMQ、Kafka、RocketMQ 等主流消息队列的对比,明确了不同 MQ 在设计目标和适用场景上的差异:Kafka 更偏向高吞吐的数据流处理,RocketMQ 适合高并发、强一致性的核心业务,而 RabbitMQ 则在业务解耦、消息可靠性和灵活路由方面更具优势。因此,在以业务消息为主的系统中,RabbitMQ 往往是更合适的选择。
在此基础上,文章对 RabbitMQ 进行了深入介绍,从架构与核心概念出发,结合 Erlang 语言的并发与可靠性优势,解释了 RabbitMQ 的设计理念和整体定位。通过管理控制台的一系列实践实验,进一步验证了 RabbitMQ 的关键行为和设计原则。
实验结果显示,交换机只负责路由,不存储消息,消息真正存放在队列中;Direct 交换机是精确匹配,Topic 交换机基于规则匹配而非广播,Fanout 才是真正的广播机制;竞争消费发生在同一队列内,而广播本质是消息复制到多个队列。这些实验不仅帮助理解 RabbitMQ 的工作机制,也为后续在真实业务中正确使用 RabbitMQ 奠定了基础。