GPU 可以执行与 TPU 相同的集合操作:ReduceScatter、AllGathers、AllReduces 和 AllToAlls。与 TPU 不同的是,这些操作的工作方式会根据执行位置的不同而有所差异:是在节点级别(通过 NVLink)还是在更高级别(通过 InfiniBand)执行。NVIDIA 在NVSHMEM和NCCL (读作"nickel")库中实现了这些集合操作。NCCL 已在此处开源。虽然 NCCL 根据延迟要求/拓扑结构使用多种实现方式(详情请见此处),但接下来我们将讨论在交换树结构上的理论最优模型。
节点内集体
AllGather 或 ReduceScatter:对于节点级别的 AllGather 或 ReduceScatter 操作,您可以像在 TPU 上一样,围绕环形结构执行这些操作,并在每次跳跃时使用完整的 GPU 间带宽。您可以任意排列 GPU 的顺序,并使用完整的 GPU 间带宽将数组的一部分沿环形结构发送。每次跳跃的成本是T跳=bytes/(N∗GPU 出口带宽)因此,总成本为:
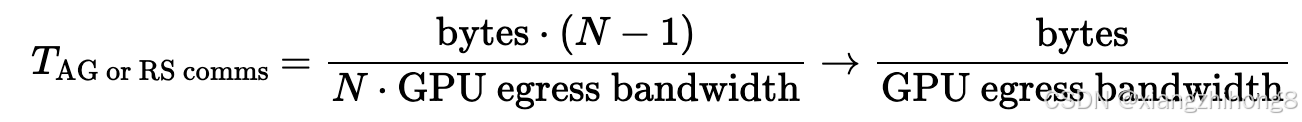
你会注意到这与 TPU 上的情况完全相同。对于 AllReduce 操作,你可以像往常一样组合 RS 和 AG,但成本会翻倍。
 **图:**带宽最优的一维环形AllGather算法。对于B字节的数据,该算法通过顶层交换机发送V/X字节,次数为X-1次。
**图:**带宽最优的一维环形AllGather算法。对于B字节的数据,该算法通过顶层交换机发送V/X字节,次数为X-1次。
如果您担心延迟(例如,如果您的数组非常小),您可以进行树形归约,其中先对 2 个元素进行 AllReduce 操作,然后对 4 个元素进行 AllReduce 操作,最后对 8 个元素进行 AllReduce 操作,总共进行 2 次 AllReduce 操作。log ( N ) 啤酒花代替N− 1尽管总成本仍然相同。
小测验 1 AllGather 时间
使用 8xH100 节点,带宽为 450 GB/s 全双工,AllGather(bf16B X , F) 需要多长时间?B = 1 0 2 4,F = 1 6 , 3 8 4。
答:我们总共有字节,单向带宽为 450e9。这大约需要T 通讯= ( 2 ⋅ B ⋅ F) / 450e9或者更确切地说利用所提供的数值,我们可以大致得出以下结果。或者更准确地说,。
所有 GPU 之间相互连接:节点内的 GPU 之间可以完全互联,这使得所有 GPU 的全连接通信非常容易。每个 GPU 只需直接向目标节点发送数据即可。在节点内,对于 B 字节的数据,每个 GPU 都有B / N 字节和发送( B / N 2)字节到N− 1目标节点总数为。
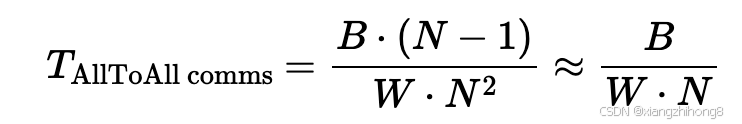 相比之下,TPU 的成本是B / ( 4 W )因此,在单个节点内,我们理论上可以获得 2 倍的运行时加速(B / 4W)对比(B/ 8W)。
相比之下,TPU 的成本是B / ( 4 W )因此,在单个节点内,我们理论上可以获得 2 倍的运行时加速(B / 4W)对比(B/ 8W)。
对于混合专家(MoE)模型,我们经常需要进行稀疏或不规则的AllToAll映射,其中我们保证最多k的N输出维度上的分片非零,也就是说T 所有的一切→ K *B* , *N* 最多k的N每个轴上的数值均不为零。这降低了成本。k/ N 总计约对于弹性模量,我们通常是独立随机地选取非零值,因此存在出现数值少于零值的概率。k非零值,大约( N − 1 ) / N ⋅ min ( k / N , 1 ) ⋅ B / ( W ⋅ N )
小测验 2 AllToAll 时间:
使用 8xH100 节点,单向带宽为 450 GB/s,AllToAll X->N (bf16B X , N) 需要多长时间?如果我们知道 8 个条目中只有 4 个非零,结果又会如何?
答案:由以上可知,在稠密情况下,成本为, 或者B / ( W ⋅ N)如果我们只知道1/2条目将不包含填充内容,我们可以发送大约占总成本的一半。
要点:数组上的 AllToAll 的成本B 单个节点内 GPU 上的字节数约为T通讯= ( B ⋅ ( 8 − 1 ) ) / ( 82⋅ W GPU出口) ≈ B / ( 8 ⋅ WGPU出口)对于一个破旧的(顶部-k
k ) AllToAll,这将进一步减少到( B ⋅ k ) / ( 6 4 ⋅ WGPU 出口)。
实测结果:以下是 8 个 H100 节点上 AllReduce 带宽的实测结果。算法带宽 (Algo BW) 为实测带宽(字节/运行时间),总线带宽 (Bus BW) 的计算方法如下:理论上,这可以衡量实际链路带宽。你会注意到,我们确实达到了接近 370GB/s 的速率,虽然低于 450GB/s,但也相当接近,尽管每个设备仅能达到约 10GB。这意味着,尽管这些估算在理论上是正确的,但需要传输大量数据才能实现。
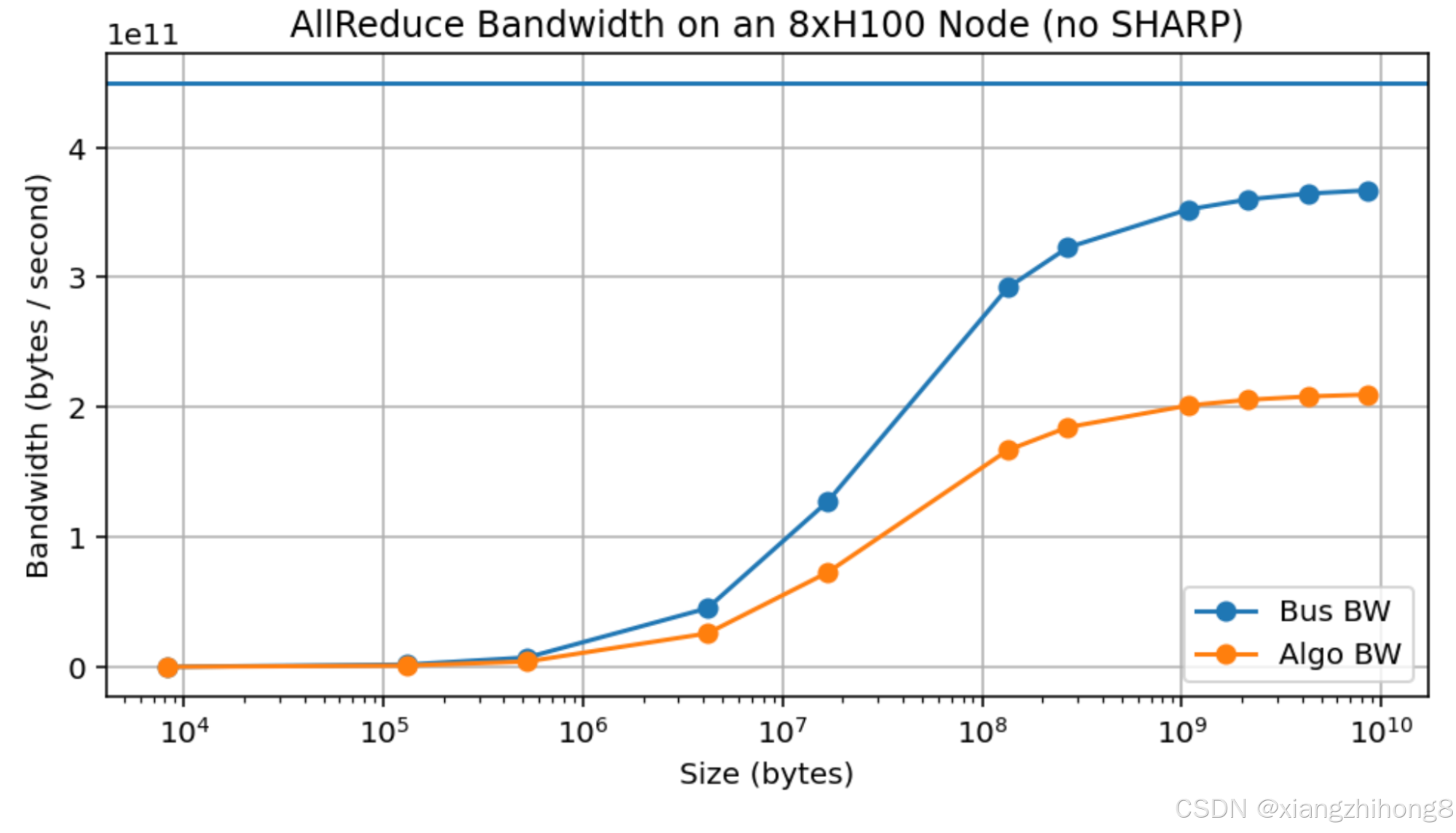 **图:**禁用 SHARP 的 8xH100 节点的 AllReduce 吞吐量。蓝色曲线为经验链路带宽,计算方法如下:根据实测数据,即使使用10GB的超大容量阵列,我们也无法达到宣称的450GB/s带宽。
**图:**禁用 SHARP 的 8xH100 节点的 AllReduce 吞吐量。蓝色曲线为经验链路带宽,计算方法如下:根据实测数据,即使使用10GB的超大容量阵列,我们也无法达到宣称的450GB/s带宽。
这是一个实际存在的问题,因为它显著地使我们能够提出的任何理论论断变得复杂。例如,即使是对一个大小合理的数组(例如 LLaMA-3 70B 的 MLP,大小为 1000bf16[8192, 28672]或采用 8 路分片bf16[8192, 3584] = 58MB)执行 AllReduce 操作,其吞吐量也只能达到约 150GB/s,而峰值吞吐量可达 450GB/s。相比之下,TPU 在消息大小远小于此的情况下即可达到峰值带宽(参见附录 B)。
在网络缩减方面:自 Hopper 架构以来,NVIDIA 交换机就支持"SHARP"(可扩展分层聚合和缩减协议),该协议允许"网络内缩减"。这意味着网络交换机本身可以执行缩减操作,并将结果复用或"多播"到多个目标 GPU:
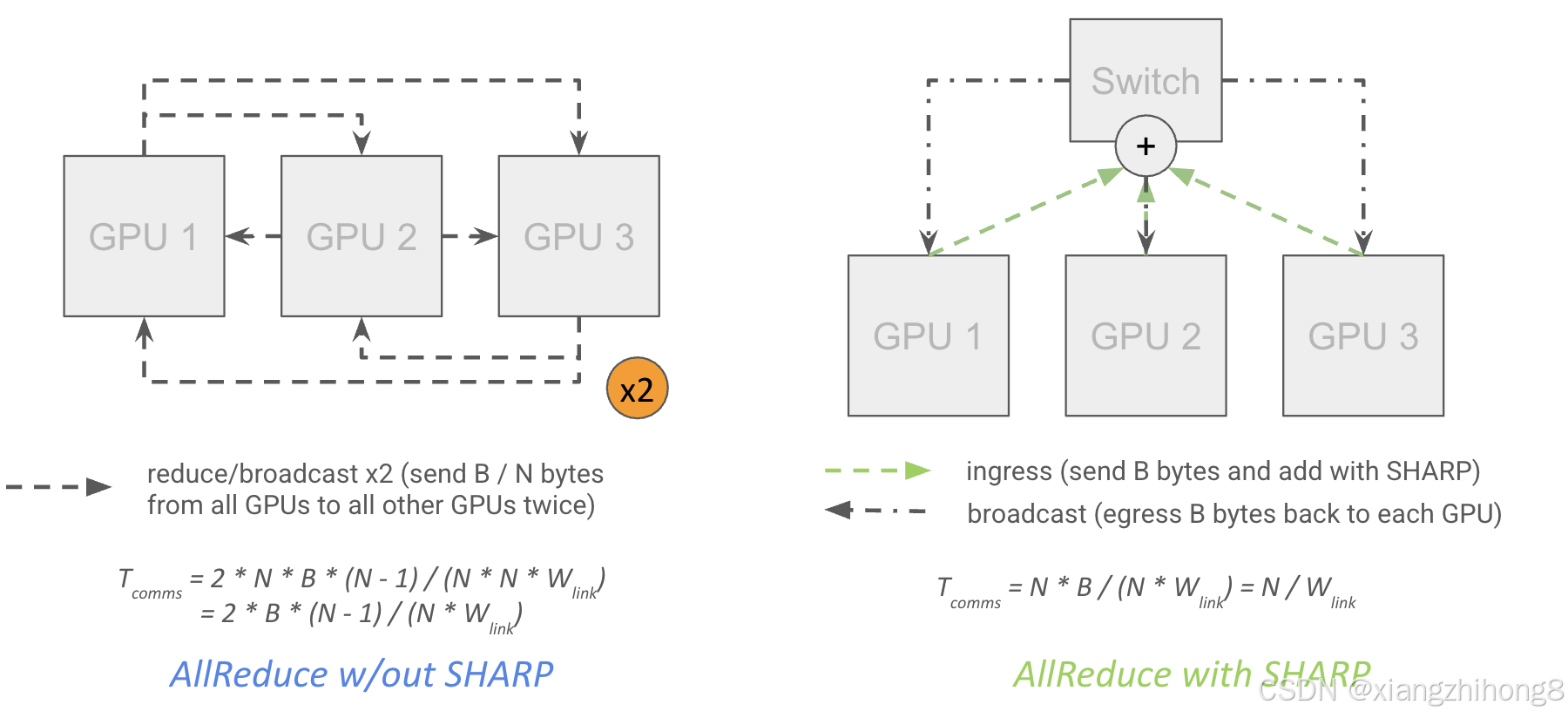 **图示:**不使用 SHARP 的 AllReduce 算法的理论成本是实际成本的两倍,因为它需要两次经过每个 GPU。实际上,速度提升仅约为 30%(数据来自 NCCL 2.27.5)。
**图示:**不使用 SHARP 的 AllReduce 算法的理论成本是实际成本的两倍,因为它需要两次经过每个 GPU。实际上,速度提升仅约为 30%(数据来自 NCCL 2.27.5)。
理论上,这几乎可以将 AllReduce 的成本减半,因为这意味着每个 GPU 都可以将其数据发送到顶层交换机,由顶层交换机执行归约并将结果广播到每个 GPU,而无需两次向每个 GPU 发送数据,同时还可以减少网络延迟。
 请注意,这是精确值,没有误差。1
请注意,这是精确值,没有误差。1
/
N
1 / N因为每个GPU都会输出首先,接收其本地分片的部分缩减版本(入口)。),完成还原操作,然后退出再次,然后完全简化的结果进入(进入),结果恰好B
B已接收字节数。
然而,在实际应用中,我们发现启用 SHARP 后带宽仅提升了约 30%,而预期提升幅度为 75%。这使得我们的有效总带宽仅达到约 480GB/s,远未达到 2 倍。
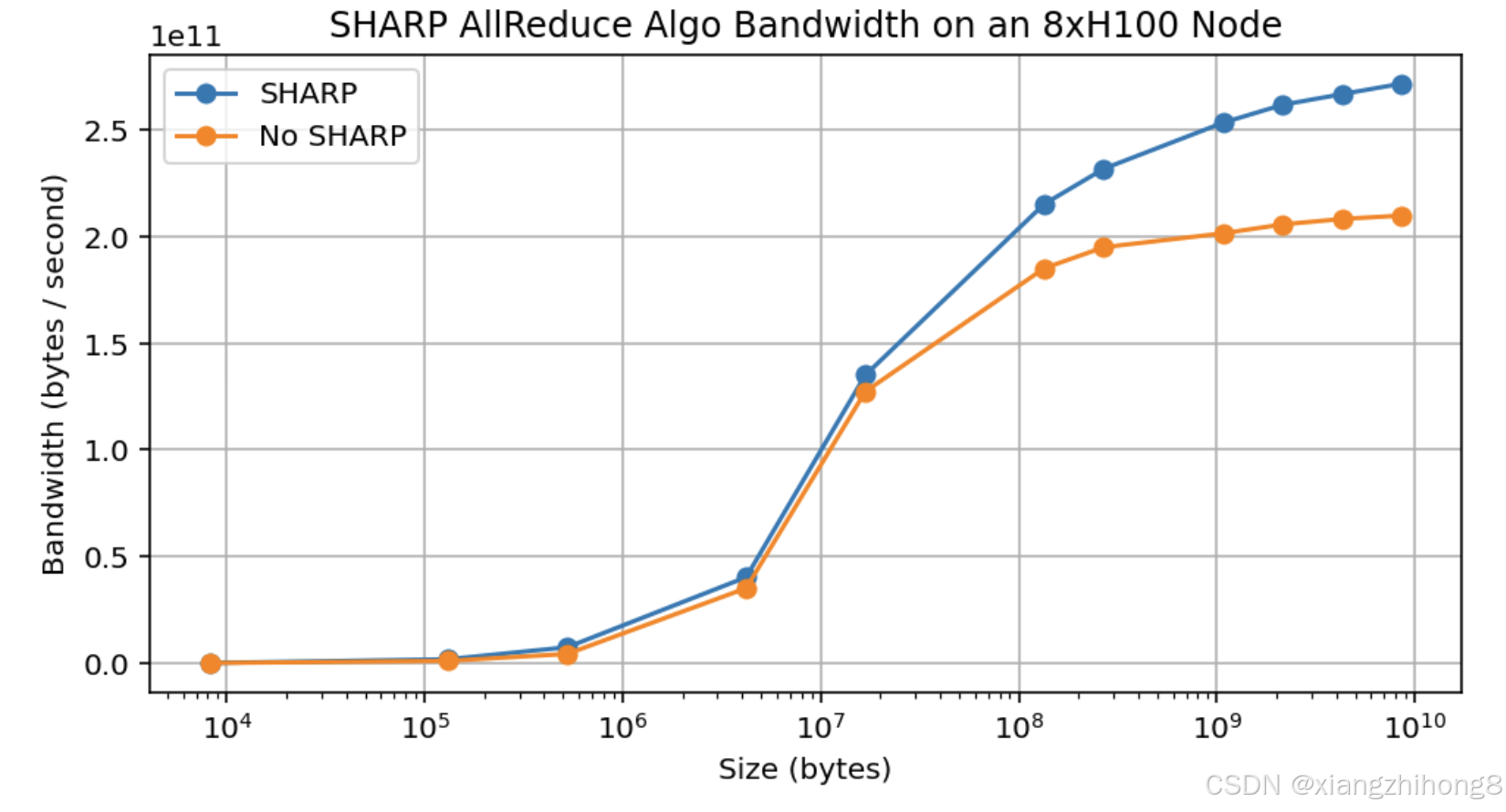 **图:**节点内启用和禁用 NVIDIA SHARP 时 AllReduce 算法带宽的实测结果。峰值吞吐量提升约 30%,而理论上算法应该能够实现接近 75% 的提升。
**图:**节点内启用和禁用 NVIDIA SHARP 时 AllReduce 算法带宽的实测结果。峰值吞吐量提升约 30%,而理论上算法应该能够实现接近 75% 的提升。
要点:理论上,NVIDIA SHARP(大多数NVIDIA交换机都支持)应该可以降低AllReduce的成本。B来自大约的字节到然而,在实际应用中,带宽提升仅约为 30%。由于 LLM 中纯粹的 AllReduce 操作相当少见,因此这种提升意义不大。
跨节点集体
当我们超越节点级别时,成本就变得更加微妙了。对树进行归约时,可以考虑从下往上进行归约,首先在节点内部进行归约,然后在叶节点级别进行归约,最后在树干级别进行归约,每一层都使用常规算法。特别是对于 AllReduce 来说,可以看到这可以减少我们整体传输的数据量,因为在节点级别进行 AllReduce 之后,我们只需要进行外部传输即可。B字节数直到叶子节点,而不是*B N。
这样做成本有多高?初步估算,由于我们拥有完整的二分带宽,AllGather 或 ReduceScatter 的成本大致等于缓冲区大小(以字节为单位)除以节点出口带宽(H100 上为 400GB/s),而与树归约的任何细节无关。
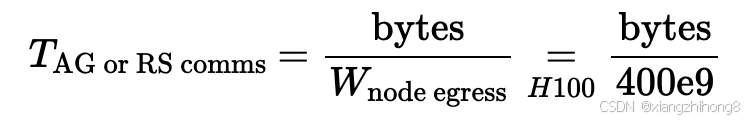 在哪里在 节点对于上述 H100 网络(每个节点有 8 条 400Gbps IB 链路出口),出口流量通常为 400GB/s。最直观的理解方式是想象对集群中的每个节点进行环形缩减。由于采用了胖树拓扑结构,我们总能构造出一个环。在节点在任意两个节点之间建立出口,并执行常规缩减操作。节点级缩减几乎永远不会成为瓶颈,因为它具有更高的整体带宽和更低的延迟,尽管通常成本较高。
在哪里在 节点对于上述 H100 网络(每个节点有 8 条 400Gbps IB 链路出口),出口流量通常为 400GB/s。最直观的理解方式是想象对集群中的每个节点进行环形缩减。由于采用了胖树拓扑结构,我们总能构造出一个环。在节点在任意两个节点之间建立出口,并执行常规缩减操作。节点级缩减几乎永远不会成为瓶颈,因为它具有更高的整体带宽和更低的延迟,尽管通常成本较高。
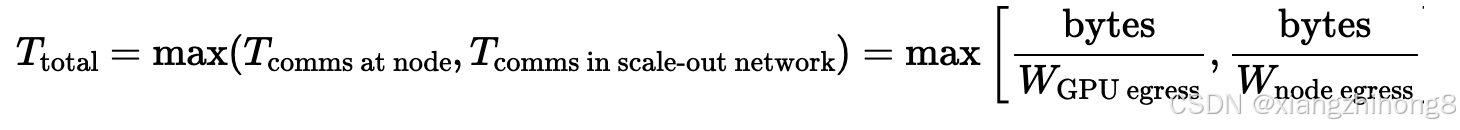
其他类型的集合:除非启用 SHARP,否则 AllReduce 的成本仍然是上述值的两倍。NVIDIA 也销售启用 SHARP 的 IB 交换机,但并非所有供应商都提供。AllToAll 在不同节点间变化较大,因为它们不像 AllReduce 那样具有"分层"结构。如果我们想将数据从每个 GPU 发送到其他所有 GPU,就无法在节点级别充分利用二分查找带宽。这意味着,如果我们有一个跨越多个节点的 N 路 AllToAll,M = N/ 8节点,成本为
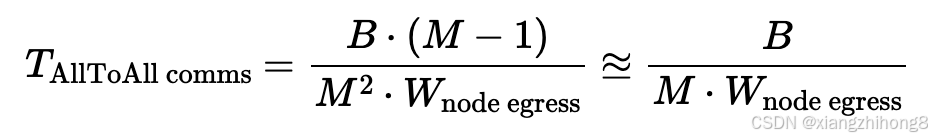 这实际上只有 50GB/s 的带宽,而不是 400GB/s。我们从B / ( 8 ∗ 450e9 )在单个 H100 节点内B/ ( 2 ⋅ 400e9 )跨越 2 个节点时,性能下降超过 4 倍。
这实际上只有 50GB/s 的带宽,而不是 400GB/s。我们从B / ( 8 ∗ 450e9 )在单个 H100 节点内B/ ( 2 ⋅ 400e9 )跨越 2 个节点时,性能下降超过 4 倍。
以下是1024GPU DGX H100 SuperPod架构的概述:
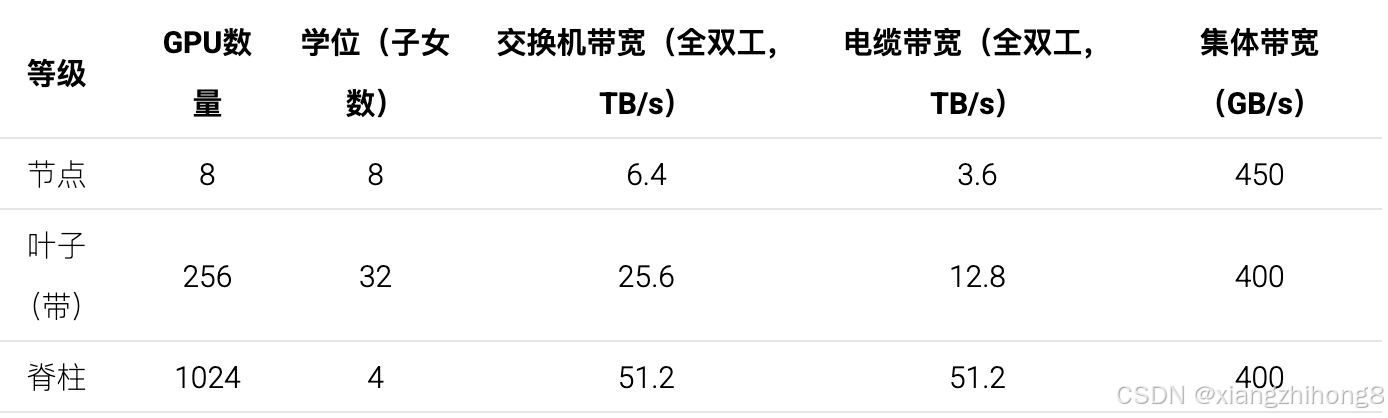 我们使用术语"集体带宽"来描述我们可以从 GPU 或节点输出数据的有效带宽。它也是。
我们使用术语"集体带宽"来描述我们可以从 GPU 或节点输出数据的有效带宽。它也是。
要点:在节点级别之外,对 B 字节执行 AllGather 或 ReduceScatter 操作的成本大致为B黑白 节点出口,即B/ 400e9在 H100 DGX SuperPod 上,除非启用 SHARP,否则 AllReduce 的成本是原来的两倍。整体拓扑结构为胖树形,旨在确保任意两个节点对之间带宽恒定。
数组按不同轴分片时,归约操作:考虑如下归约操作的成本:
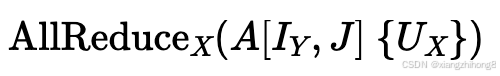
这里我们正在对一个本身沿另一个轴分片的数组进行全归约操作在TPU上,这项操作的总成本降低了......倍。与未分片版本相比,因为我们发送的是分片版本。每个轴的数据量都相同。在 GPU 上,成本取决于哪个轴是"内部"轴(节点内轴还是节点间轴),以及每个分片是否跨越多个节点。假设是内轴,数组有通过计算总字节数,总体成本有效降低了。但前提是跨越多个节点:
 其中 N 为 GPU 的数量,再次D节点是节点中 GPU 的数量(节点的度)。如您所见,如果Y < D 节点这样,我们在节点层面上取得了优势,但通常看不到整体运行时间的减少;而如果Y > D节点速度提升与所跨越的节点数成正比。
其中 N 为 GPU 的数量,再次D节点是节点中 GPU 的数量(节点的度)。如您所见,如果Y < D 节点这样,我们在节点层面上取得了优势,但通常看不到整体运行时间的减少;而如果Y > D节点速度提升与所跨越的节点数成正比。
如果我们想要精确地描述环的简化,那么对于树 AllGather X (A Y { U X })(假设 Y 是内轴),一般规则是:
 在哪里S我其中 M * N * ... 表示树中第 i 层以下子节点的大小。这大致意味着,我们覆盖的 GPU 或节点越多,可用带宽就越大,但仅限于该节点内部。
在哪里S我其中 M * N * ... 表示树中第 i 层以下子节点的大小。这大致意味着,我们覆盖的 GPU 或节点越多,可用带宽就越大,但仅限于该节点内部。
随堂测验 3 沿两个轴分片:假设我们想要进行众人聚集AllGatherX ( bf16 *DX* ,*F和* )在哪里是单个SU(256个芯片)的内轴。这需要多长时间?D,F, 和?
答案:我们可以将其分为两种情况,即 Y ≤ 8 和 Y > 8。我们仍然受限于叶开关,所以答案和往常一样是:T通讯= 2 ∗ D ∗ F ∗ ( 3 2 − 1 ) / ( 3 2 ∗ 4 0 0 e9 )当 Y > 8 时,根据以上内容,大致可知
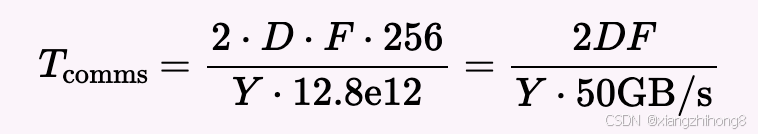 对于
对于D = 8192,F = 32,768我们有:
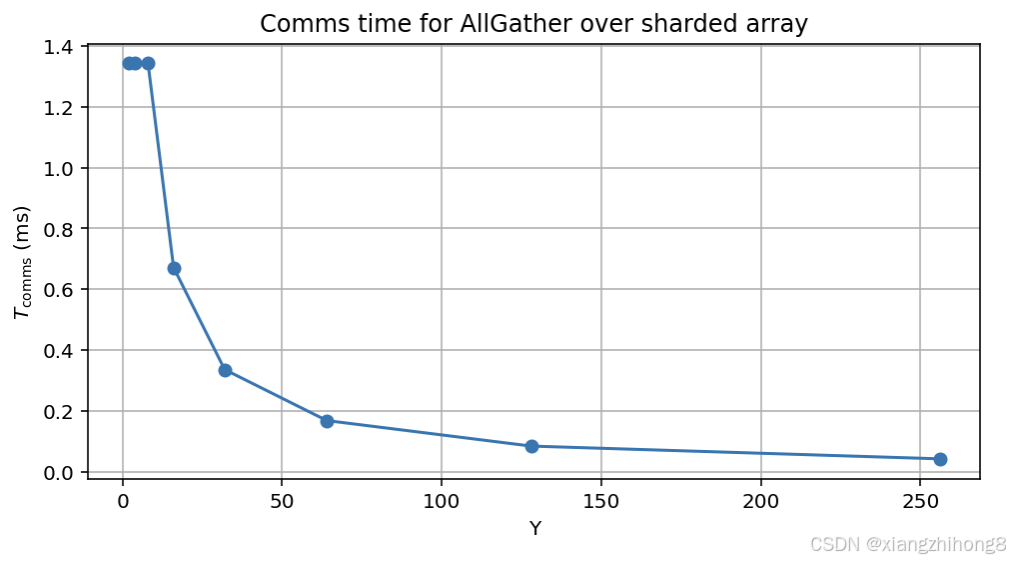 **图:**随着内轴跨越更多节点,分片 AllGather 的理论成本。
**图:**随着内轴跨越更多节点,分片 AllGather 的理论成本。
注意,如果我们采用 8 路并行模型,实际上可以将节点级缩减的成本降低 8 倍,但总体成本保持不变,因此它是免费的,但对提高整体带宽没有帮助。
测验 4:集体
问题 1 SU AllGather
仅考虑一个具有 M 个节点且每个节点有 N 个 GPU 的 SU。在 AllGather 期间,节点级交换机究竟会接收和发送多少字节的数据?顶层交换机的情况又如何?
答:让我们一步一步来,逐个分析简化过程的各个组成部分:
-
每个GPU发送B / M N 向交换机发送字节,总流入量为N B / M N = B / M字节入口。
-
我们完全退出B / M字节数直至脊柱交换机。
-
我们进入B ∗ ( M − 1 ) / M来自脊柱交换机的字节
-
我们离开B − B / M N 字节N 次数,总共NN ∗ ( B − B / M N ) = N B − B / M。
总计为B入口和北 出口处存在瓶颈,因此我们应该会受到出口处的瓶颈影响,总时间将是TAllGather= B ⋅ ( M − 1 ) / ( M ⋅ W 节点) = B ⋅ ( M − 1 ) / ( M⋅ 400e9 )。
问题 2 单节点 SHARP AR
考虑一个单节点,每个节点有 N 个 GPU。在使用 SHARP(网络内归约)进行 AllReduce 时,交换机究竟会接收和发送多少字节的数据?
答:和以前一样,我们一步一步来。
-
每个GPU发送B ∗ ( N − 1 ) / N 字节,所以我们有N ∗ B ∗ ( N − 1 ) / N = B ∗ ( N− 1 )已进入。
-
我们将部分和累加起来,然后寄回。B / N 每个GPU分配的字节数,因此NN ∗ B / N = B字节数已传出。
-
我们在本地对残差进行部分求和,然后将结果发送回交换机。总和为N ∗ B / N = B已接收字节数。
-
我们捕获所有分片并进行多播,发送B ∗ ( N − 1 ) / N 到N目的地,总计B ∗ ( N − 1 ) / N ∗ N = B ∗ ( N− 1 )已离开。
因此,总数为B ∗ ( N − 1 ) + B = B N流入和流出的字节数。这支持了总吞吐量恰好为零。
问题 3 跨节点 SHARP AR
考虑一个分布在 N 个 GPU 的单个节点上的数组 bf16D X , F Y 。AllReduce(bf16D, F Y { U X }) 需要多长时间?假设我们进行的是网络内归约。解释一下,如果节点不止一个,结果会有什么不同?
答:我们可以尝试修改上面问题的答案。基本上,我们首先出口B ∗ ( X − 1 ) / X Y 然后从每个GPU发送字节B / X Y 将数据发送到每个GPU,然后将相同数量的数据发送回交换机,然后再发送B ∗ ( X − 1 ) / X Y 回到每个GPU。总计为进出都需要时间,所以总时间为T通讯= N B / ( Y ∗ N ∗ W 关联) = N ∗ 2 D F / ( Y ∗ N ∗ W 关联) = 2 ∗ D ∗ F / ( Y ∗ W关联)因此,总时间确实会减少。。
如果涉及多个节点,我们可以进行与上述大致相同的缩减操作,但当我们从节点级交换机发出数据时,我们需要发送所有 B 字节,而不仅仅是 B 字节。这是因为我们需要将每个碎片分开。
问题 4 脊柱水平 AR 成本
考虑与上述相同的设置,但有Y= 2 5 6(因此,AR 发生在脊柱层面)。AllReduce 需要多长时间?同样,您可以假设所有费用均在网络内扣除。
答:这使我们能够充分利用主干层惊人的带宽。我们在 4 个节点上拥有 25.6TB/s 的带宽,因此 AllReduce 带宽为 6.4TB/s。使用 SHARP,这只需2 * D * F / 6.4e12几秒钟即可完成。