【论文笔记•(多智能体)】Ask Patients with Patience: Enabling LLMs for Human-Centric Medical Dialogue with Grounded Reasoning
1 一句话总结
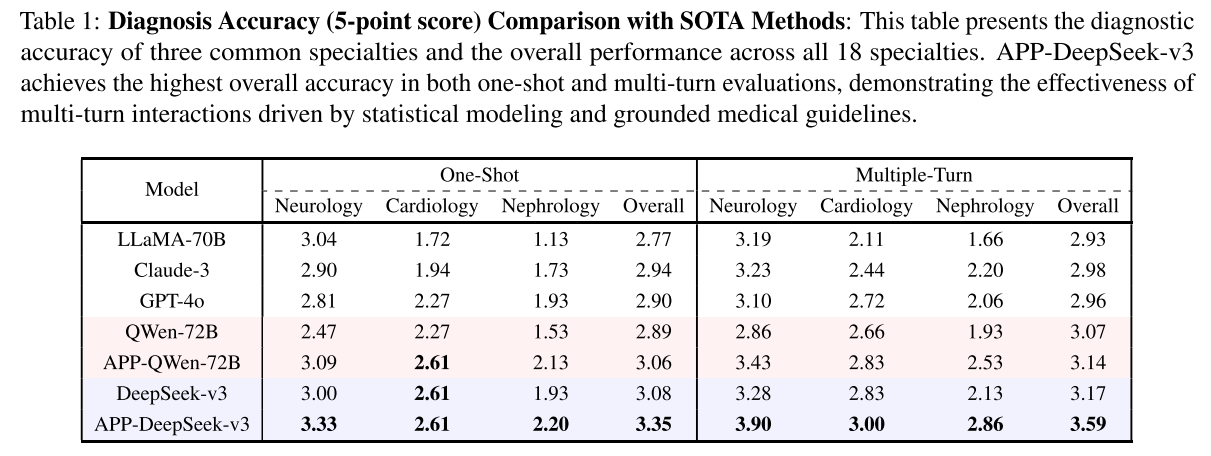
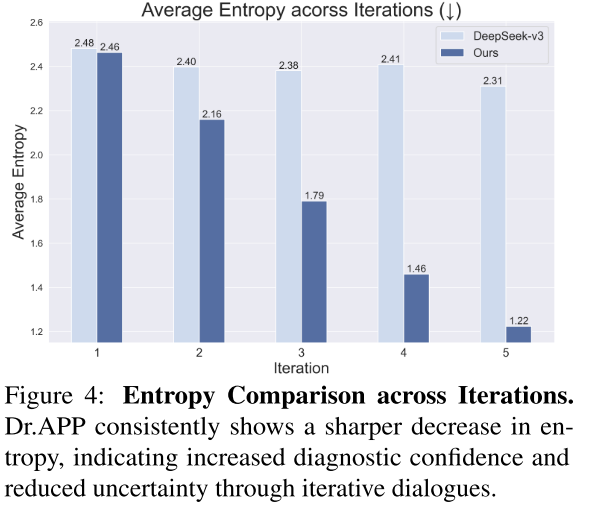
为解决全球医生短缺导致的医疗可及性问题,同时克服现有大语言模型(LLMs)在临床对话中缺乏以患者为中心的交互、诊断缺乏权威性依据和透明度不足等缺陷,研究团队提出Ask Patients with Patience(APP) 医疗助手模型。该模型基于权威医学指南(如 MSD 手册) 和贝叶斯主动学习,通过多轮共情对话引导患者清晰表达症状,动态更新疾病概率分布以提升诊断准确性;同时构建了基于 300 + 真实医患对话的基准测试集,经实验验证,APP 在诊断准确率(多轮场景下整体 3.59 分 / 5 分) 、不确定性降低(迭代 5 次后熵值降至 1.22) 和人文关怀维度(各项指标均超 4.5 分 / 5 分) 上显著优于 GPT-4o、Claude-3 等现有 SOTA 模型,为 AI 医疗对话与实际临床应用搭建了桥梁。
2 论文基本信息

🏫单位:牛津大学
🔖会议:EMNLP 2025 Main
⏰阅读时间:2025.12.17
3 研究的核心问题和背景
医生资源严重短缺,医疗资源紧张。大模型的出现极大的提高了获得医疗咨询的机会。然而,现在的大模型临床咨询仍然面临问题:它们无法通过对话互动引出患者最相关的医疗状况。大模型往往仅根据用户最初的输入来输出结果,而没有进一步的询问。这与现实世界中的门诊不同,在现实世界中,患者往往很难在一开始提供所有相关信息,需要医生的一步步询问来引导患者说出更多的情况。

😷:我最近一直胃痛,但不确定是什么原因。
👨⚕️:常见原因包括消化不良、压力、感染或饮食中的某些因素。如果疼痛持续、加剧或伴有发热或呕吐等其他症状,请务必就医接受专业评估。
最近提出使用大模型与患者进行多回合对话,这种方式比单轮对话更有效,但也存在以下问题:
1️⃣交互机械:缺乏共情,语言晦涩,无法引导患者清晰表达症状。
2️⃣大模型的黑箱模式:大模型存在没有明确来源的情况下使用模糊的医学术语,在没有基础推理的情况下做出确定性的医疗决策的情况,这限制了其在现实世界的应用。

😷:我最近一直胃痛,但不确定是什么原因。
👨⚕️:胃痛是从何时开始的?频率有多高?疼痛的具体位置在哪里?是绞痛、刺痛还是灼烧感?你是否曾注意到有任何诱因,比如食物或压力?这些信息将有助于我们更好地了解情况。
😷:我最近下腹部经常出现绞痛,通常是在进食几小时后...
👨⚕️:最可能的诊断是功能性胃肠道疾病,例如肠易激综合征(IBS),尤其考虑到下腹部的痉挛性疼痛以及其在餐后反复发作且无明显诱因的情况
因此,本文要解决的核心问题是:如何让大模型在医疗对话中既遵循权威医学指南实现有依据、透明的诊断,又具备人文关怀与高效引导能力,从而解决现有大模型在医疗诊断上的痛点,同时缓解全球医生短缺导致的医疗可及性不足困境?
4 框架及具体实现
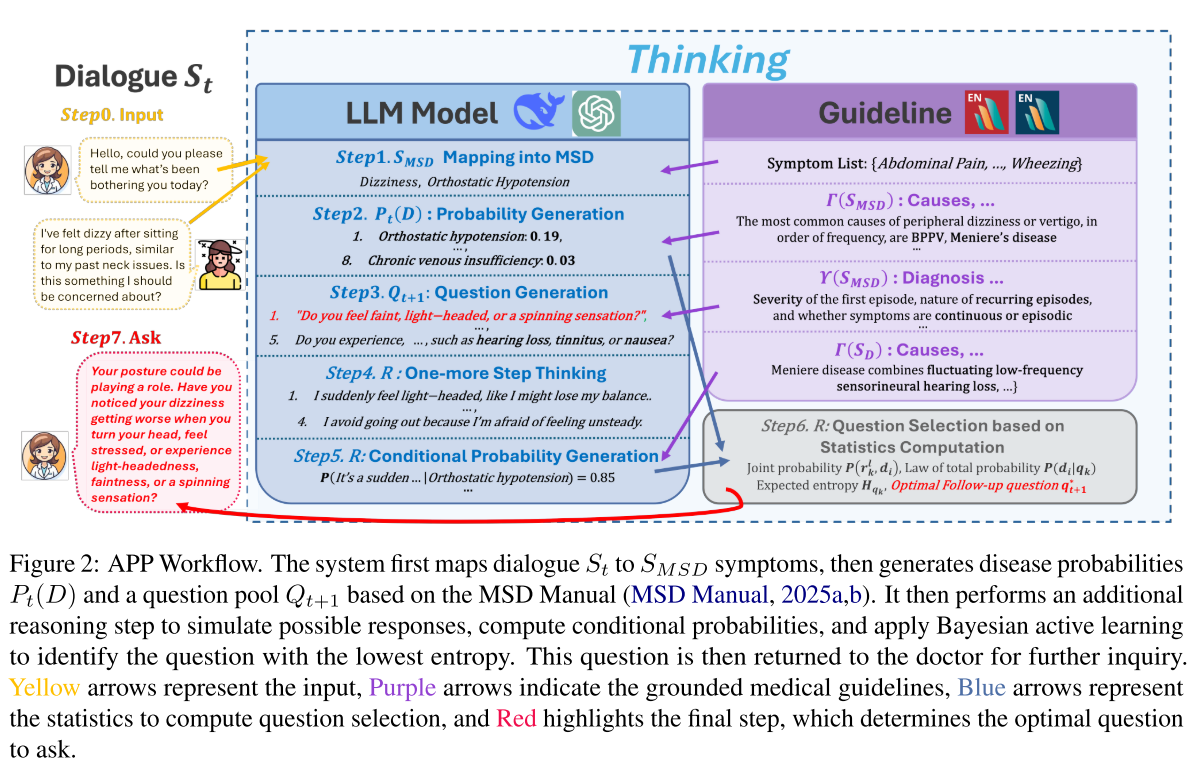
4.1 关键技术支撑
1️⃣MSD 手册:作为Dr.APP 的权威医学依据,有专业版和消费者版两种版本。
2️⃣贝叶斯主动学习:利用贝叶斯概率模型来精确衡量模型对未标注数据的困惑程度(不确定性),从而挑选出最有价值的数据让人类进行标注,以最少的标注成本达到最好的模型效果。\[#6.1 贝叶斯主动学习]
4.2 映射到 MSD 手册
将 MSD 手册中的专业症状与消费者容易理解的描述进行配对,存储到本地库中,后续通过 RAG 快速匹配用户表述。在每次诊断开始后,将初始对话 S 1 S_{1} S1 映射到 MSD 手册的专业和消费者症状列表 S M S D = S p r o f , S c o n s S_{MSD}={S_{prof},S{cons}} SMSD=Sprof,Scons 中。
4.3 生成初始疾病概率分布
根据 MSD 症状集 S M S D S_{MSD} SMSD,访问详细的症状页面,包括有关症状的原因、病理生理学等相关知识,表示为 Γ ( S M S D ) Γ(S_{MSD}) Γ(SMSD),并结合当前的对话历史 S t S_{t} St 通过贝叶斯概率公式计算所有可能疾病的概率:
P t ( D ∣ Γ ( S M S D ) , S t ) = { P t ( d i ∣ Γ ( S M S D ) , S t ) ∣ d i ∈ D , ∑ i = 1 I P t ( d i ∣ Γ ( S M S D ) , S t ) = 1 } P_{t}(D\mid \Gamma(S_{MSD}),S_{t})=\{P_{t}(d_{i}\mid \Gamma(S_{MSD}),S_{t})\mid d_{i}\in D, \sum_{i=1}^I P_{t}(d_{i}\mid \Gamma(S_{MSD}),S_{t})=1\} Pt(D∣Γ(SMSD),St)={Pt(di∣Γ(SMSD),St)∣di∈D,∑i=1IPt(di∣Γ(SMSD),St)=1}
其中 P t ( d i ∣ Γ ( S M S D ) , S t ) P_{t}(d_{i}\mid \Gamma(S_{MSD}),S_{t}) Pt(di∣Γ(SMSD),St) 表示在给定医学知识 Γ ( S M S D ) Γ(S_{MSD}) Γ(SMSD) 和对话历史 S t S_{t} St 的情况下,在迭代 t 时,疾病 d i d_{i} di 的估计概率。
- 例:患者表述 "头晕" 后,初始概率可能为 "直立性低血压:0.22、颈椎病:0.19、眩晕症:0.17、其他疾病:0.42",让诊断逻辑透明化。
4.4 问题生成
在估计完疾病概率后,需要一个紧接着的问题来完善诊断。在每次迭代 t 中,基于 MSD 手册中"诊断要点""医生问诊建议"等章节(表示为 Υ ( S M S D ) \Upsilon(S_{MSD}) Υ(SMSD)),结合当前疾病分布概率,生成针对性的问题池 Q t + 1 = q 1 , ... , q K Q_{t+1}={q_{1},\dots,q_{K}} Qt+1=q1,...,qK。
问题的设计需要满足以下要求:
• 临床相关性:每个问题都对应某类高概率疾病的关键鉴别点。
• 以人为中心:避免提出宽泛的问题,要进行简单易懂的提问。
4.5 预判回复与计算条件概率
对于每个候选问题 q k ∈ Q t + 1 q_{k}\in Q_{t+1} qk∈Qt+1 ,大模型生成一组回答,形成回复集合 R k = r k 1 , ... , r k L R_{k}={r^1_{k},\dots,r^L_{k}} Rk=rk1,...,rkL
例如:针对问题 "头晕时是什么感觉?",预判回复可能是 "天旋地转""头重脚轻""站立不稳但不眩晕" 等。
结合 MSD 手册中疾病与症状的关联知识 Γ ( d i ) \Gamma(d_{i}) Γ(di),计算每个回复对应每种疾病的条件概率 P ( r k l ∣ Γ ( d i ) ) P(r^l_{k}\mid \Gamma(d_{i})) P(rkl∣Γ(di))
例如:"我感到头晕"的回复在直立性低血压(例如0.4)下可能有更高的概率,但在眩晕(例如0.1)下的概率较低。
4.6 问题选择
这一步的主要任务是使用贝叶斯主动学习从问题池中选择最优问题。
基于条件概率,通过贝叶斯推理计算每个候选问题 q k q_{k} qk 的虚拟后续疾病概率分布 P ( d i ∣ q k ) P(d_{i}\mid q_{k}) P(di∣qk):
- 先计算回复与疾病的联合概率: P ( r k l , d i ) = P ( r k l ∣ Γ ( d i ) ⋅ P t ( d i ) ) P(r^l_{k},d_{i})=P(r^l_{k}\mid \Gamma(d_{i})\cdot P_{t}(d_{i})) P(rkl,di)=P(rkl∣Γ(di)⋅Pt(di));
- 再通过全概率公式更新提问后的疾病后验概率: P ( d i ∣ q k ) = ∑ l = 1 L P ( r k l , d i ) ∑ j = 1 I ∑ l = 1 L P ( r k l , d j ) P\left(d_{i} \mid q_{k}\right)=\frac{\sum_{l=1}^{L} P\left(r_{k}^{l}, d_{i}\right)}{\sum_{j=1}^{I} \sum_{l=1}^{L} P\left(r_{k}^{l}, d_{j}\right)} P(di∣qk)=∑j=1I∑l=1LP(rkl,dj)∑l=1LP(rkl,di);
- 计算每个问题的预期熵值: H q k = − ∑ i = 1 I P ( d i ∣ q k ) ⋅ l o g P ( d i ∣ q k ) H_{qk}=−\sum\nolimits_{i=1}^{I} P(d_{i} | q_{k}) · logP(d_{i} | q_{k}) Hqk=−∑i=1IP(di∣qk)⋅logP(di∣qk),熵值越低表示提问后诊断不确定性越小。选择熵值最小的问题作为下个最优问题 q t + 1 ∗ q_{t+1}^* qt+1∗,确保每一轮提问都能最大程度缩小诊断范围,逐步达到最终诊断 d ∗ d^* d∗。
4.7 人文化提问与对话更新
对最优问题 q t + 1 ∗ q_{t+1}^* qt+1∗ 进行人文化改造:
- 使用易懂的语言进行提问;
- 要问一个具体的问题,而不是一个宽泛的问题,如问"你吃过牛奶之类的食物或喝过苏打水之类的饮料吗 "而不是"你吃了什么不寻常的东西吗"?
- 采用只需让患者回答是或不是的问题。
5 实验
5.1 数据集
ReMeDi
- 数据来源:选取 ReMeDi 数据集(含 1557 条标注医患对话)中,仅包含 "诊断" 标签的 329 条真实对话,随机抽取 100 条作为实验样本;
- 数据覆盖:涵盖 18 个医学专科(如耳鼻喉科、妇科、消化内科等)、72 种常见疾病(如过敏性鼻炎、多囊卵巢综合征、胃食管反流病等);
- 数据特点:对话均源自真实临床咨询,能反映患者表达模糊性、症状关联性等真实场景特征,确保实验的生态有效性。
5.2 患者模拟
- 构建逻辑:基于 100 条样本中的患者信息,用 DeepSeek-v3 提取结构化患者画像(含症状、年龄、就医意图、性格等属性);
- 模拟规则:
- 患者模拟器仅基于画像回应,不访问原始对话,避免信息泄露;
- 加入 "融入符合性格的日常细节" 等指令,模拟真实患者的表达习惯(如犹豫、补充细节、非专业表述等);
- 核心作用:构建 "可控且可复现" 的医患对话场景,解决真实患者交互难以标准化评估的问题。
5.3 实验设置
1️⃣指标:
• 准确率:0-5 分,由三位专家评估。
• 熵值:评估诊断置信度。 H t = − ∑ i = 1 I P ( d i ) ⋅ l o g P ( d i ) H_{t}=−\sum\nolimits_{i=1}^{I} P (d_{i} ) · logP (d_{i}) Ht=−∑i=1IP(di)⋅logP(di) 。对比不同模型在迭代过程中熵值的下降速率,验证 Dr.APP 的不确定性降低效率
• 人文关怀指标:
-
可理解性:评估语言对非医学用户的清晰和容易程度。
-
同情度:语言中体现关怀、缓解患者焦虑的程度。
-
回复相关度:评估模型是否诊断患者问题精准回应。
-
关系培养能力:评估模型是否能建立信任、友好的医患氛围。
2️⃣每轮迭代生成 5 个候选问题(K=5),每个问题预设 2-5 个合理患者回复(2≤L≤5)
3️⃣迭代次数=6
5.4 实验结果
1️⃣诊断准确性
2️⃣诊断置信度
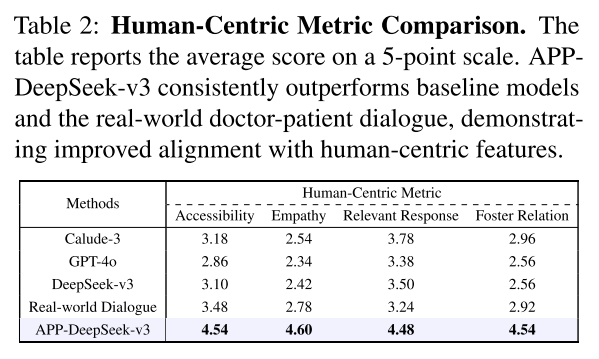
3️⃣人文关怀
6 附录
6.1 贝叶斯主动学习
• 背景:模型往往非常"自信"。即使面对它完全没见过的错误数据,它可能也会给出一个很高的置信度。这种过度自信会导致主动学习失效,因为模型不知道自己其实是在瞎猜。
什么是主动学习?
主动学习的目标是:不是随机找一些去标注,而是让模型自己挑:哪些样本最值得标注。
如果模型预测猫=0.5,狗=0.5 说明它最犹豫 → 值得标注
如果预测猫=0.99,狗=0.01 说明它很确定 → 不值得标注
• 过程:
- 初始训练:在少量的已标注数据集上训练一个贝叶斯模型(如贝叶斯神经网络或高斯过程)。
- 不确定性评估:使用模型对大量未标注数据进行预测。不同于普通预测,这里模型会输出一个预测分布。
- 采集策略 (Acquisition):通过采集函数计算每个样本的价值。如果模型对某个样本的预测分布方差很大(意见很不统一),说明模型对该样本非常不确定。
- 人工标注 (Oracle):挑选出不确定性最高的那些样本,交给人类专家进行标注。
- 更新模型:将新标注的数据加入训练集,更新模型的后验分布(Posterior)。
- 重复:回到第2步,直到模型性能达标或预算耗尽。
• 常见的采集策略: - 最大熵采样 (Max Entropy Sampling): 选择预测概率分布熵(Entropy)最大的样本。也就是模型觉得它是A、B、C的概率都差不多,最"纠结"的样本。
- BALD (Bayesian Active Learning by Disagreement) : 这是贝叶斯主动学习中最著名的算法。
- 原理 :它寻找的是这样的样本------模型参数的后验分布对预测结果有最大的互信息 (Mutual Information)。
- 通俗解释 :我们可以把贝叶斯模型想象成一个"委员会",里面有很多个子模型。如果委员会里的成员对某个样本的预测结果分歧最大(有的说是A,有的说是B),那么这个样本的 BALD 分数就最高,最有标注价值。