文章梳理了 FPGA 常见逻辑设计方法(计数器、移位寄存器、FSM)以及它们在波形对齐上的典型现象,并把序列检测与网络数据解析用状态机思路贯通起来。随后补充网络基础(分层与封装/解封装、以太网帧结构、MAC/PHY 分工),为后续用 FPGA 设计以太网/UDP 发送电路做铺垫。
一.FPGA逻辑设计方法 梳理

1.1 计数器
1.1.1 同步边沿检测电路
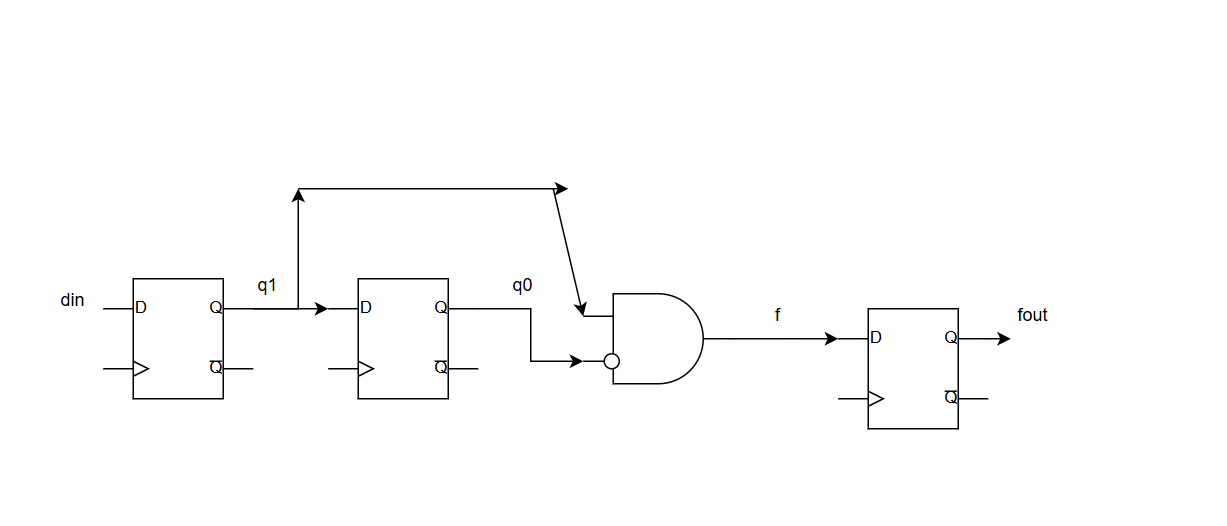
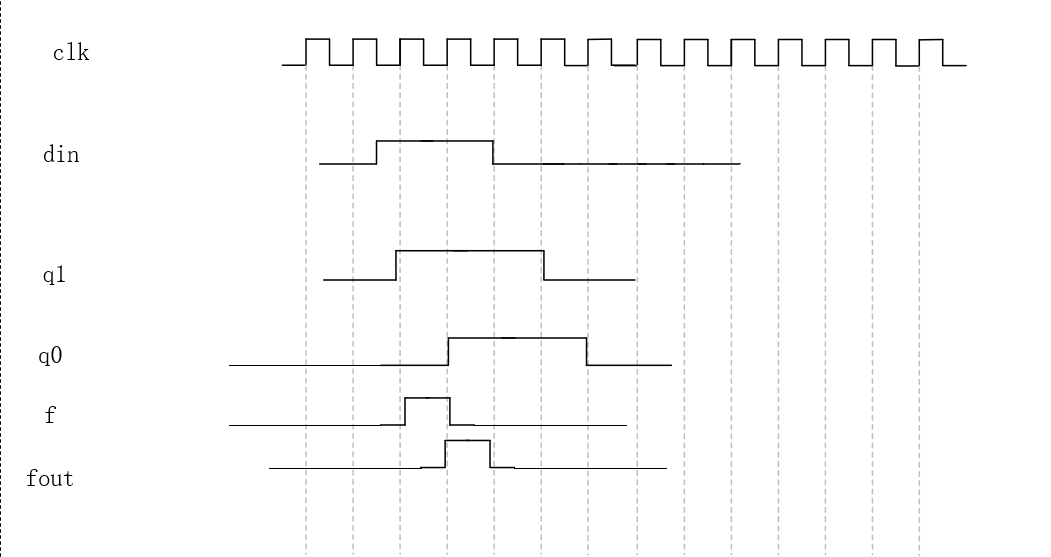
上升沿检测信号组合输出f'比时序输出fo晚1clk。
1.1.2 图样检测

不同写法 fhead和sr(shift reg)信号相位不同
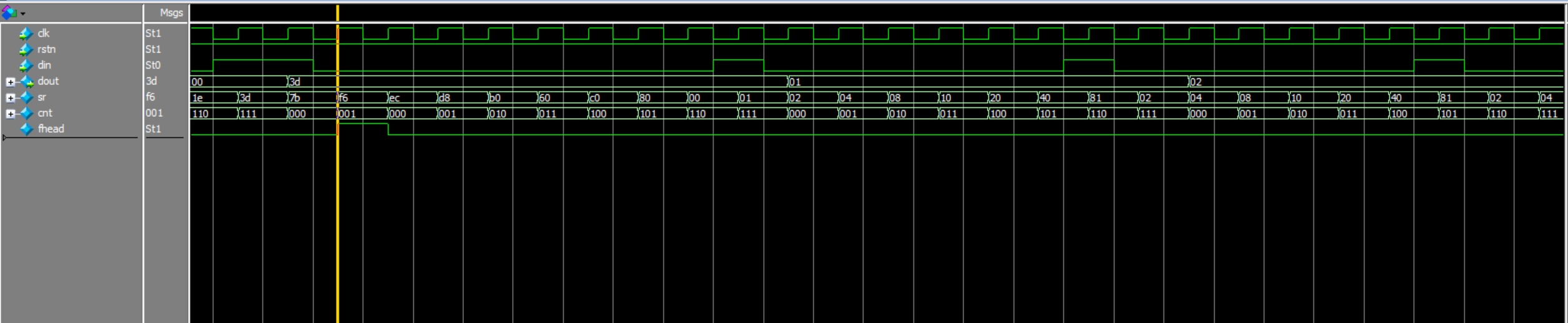

-
写法 A:
fhead用寄存器输出(时序版)always @(posedge clk) fhead <= (sr==8'hF6);现象:
fhead拉高时,cnt往往会显示成 1(或看起来从 1 开始) ,并且整体对齐会比你直觉晚一拍。 -
写法 B:
fhead用组合逻辑(组合逻辑版)assign fhead = (sr==8'hF6);
同一个检测条件 (sr==8'hF6),如果 fhead 做成寄存器输出,cnt 的动作看起来会"晚一拍/从1开始";如果 fhead 用组合输出,fhead 会更早出现,但 cnt 仍按时钟更新,所以波形上会出现 fhead=1 时 cnt 还是 0 的"错拍感"。(一般不影响最终功能,只是波形对齐不同)
`timescale 1ns/1ns
module pattern_detc(
input clk, // 时钟信号
input rstn, // 复位信号
input din, // 输入数据信号
output reg [7:0] dout // 输出数据信号
);
reg [7:0] sr; // 移位寄存器,用来存储数据
reg [2:0] cnt; // 计数器,用来追踪存储的数据位数
reg fhead; // 标志信号,表示检测到特定模式 (0xF6)
// 数据存储 - 移位寄存器 (sr)
always @(posedge clk or negedge rstn) begin
if (~rstn)
sr[7:0] <= 8'b0; // 复位时清空寄存器
else
sr[7:0] <= {sr[6:0], din}; // 每个时钟周期将新数据推入移位寄存器
end
// 特征识别 - 检测模式 0xF6
always @(posedge clk or negedge rstn) begin
if (~rstn)
fhead <= 0;
else
fhead <= (sr == 8'hF6); // 当移位寄存器中的数据为 0xF6 时置位
end
/*wire fhead;
assign fhead = (sr == 8'hF6); */
// 计数器控制 - 在检测到模式后开始计数
always @(posedge clk or negedge rstn) begin
if (~rstn)
cnt <= 0; // 复位时计数器清零
else if (fhead)
//cnt<=0;
cnt <= 1; // 当检测到模式 0xF6 时,从 1 开始计数
else
cnt <= cnt + 1; // 否则继续计数
end
// 数据输出 - 当计数器达到 7 时,将数据存储到 dout
always @(posedge clk or negedge rstn) begin
if (~rstn)
dout <= 8'b0; // 复位时输出清零
else if (cnt==7)
dout <= sr[7:0];
end
endmodule1.1.3 脉宽计数器 vs 脉冲数量计数器
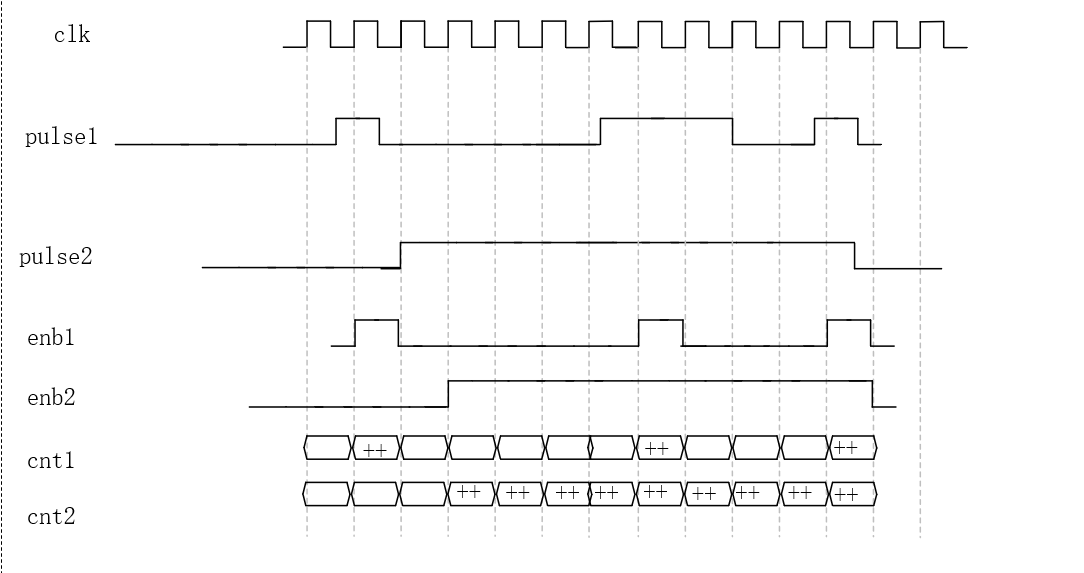
cnt1 统计来了几次脉冲,cnt2 统计脉冲高了多久(以 clk 周期为单位)。
-
输入 :
pulse1 / pulse2(和clk同步),rst_n复位 -
数量计数 cnt1(pulse1)
每出现一次上升沿,
cnt1++------不管脉冲多宽,都只算一次 -
脉宽计数 cnt2(pulse2) :把
enb2 = q1当作"高电平窗口使能",pulse2为高的每个时钟周期都cnt2++,下降沿后停止计数
波形图
 对比写法,时序逻辑写法注释掉了:
对比写法,时序逻辑写法注释掉了:
module counterN (
input wire clk,
input wire rst_n,
input wire pulse,
output reg enb1,
output reg [7:0] cnt1
);
/*wire enb1_w = (~q0) & q1;
always @(posedge clk or negedge rst_n) begin
if(!rst_n) cnt1 <= 8'd0;
else if(enb1_w) cnt1 <= cnt1 + 8'd1;
end
*/
//enb1 用寄存器会导致"计数晚一拍"(通常不影响数量,但波形可能不完全一样)
reg q0,q1;
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
q0 <= 1'b0;
q1 <= 1'b0;
end else begin
q0 <= q1;
q1 <= pulse;
end
end
always @(posedge clk or negedge rst_n) begin
if (!rst_n)
enb1<=0;
else
enb1<=~q0&q1;
end
always @(posedge clk or negedge rst_n) begin
if (!rst_n)
cnt1 <= 8'd0;
else if(enb1)
cnt1 <= cnt1 + 8'd1;
end
endmodule1.2 移位寄存器应用
1.2.1并串转换
(参考资料:老师图)
信号:
-
clk:系统时钟 -
reset:复位 -
pdata[15:0]:输入并行数据(每 16 个时钟更新一次) -
dind(pin / 起始指示):告诉系统"新一帧数据来了,从这里开始" -
latchd[15:0]:锁存后的稳定数据帧 -
cnt[3:0]:位序号计数器(0~15) -
sind(sin):同步后的起始指示/串行输出有效窗口(常用于标记 sdata 正在输出一帧) -
sdata:串行输出数据位,高位先出(按 cnt 依次输出 latchd 的各 bit)
后面把串并数据指示位都记英语缩写pin,sin了
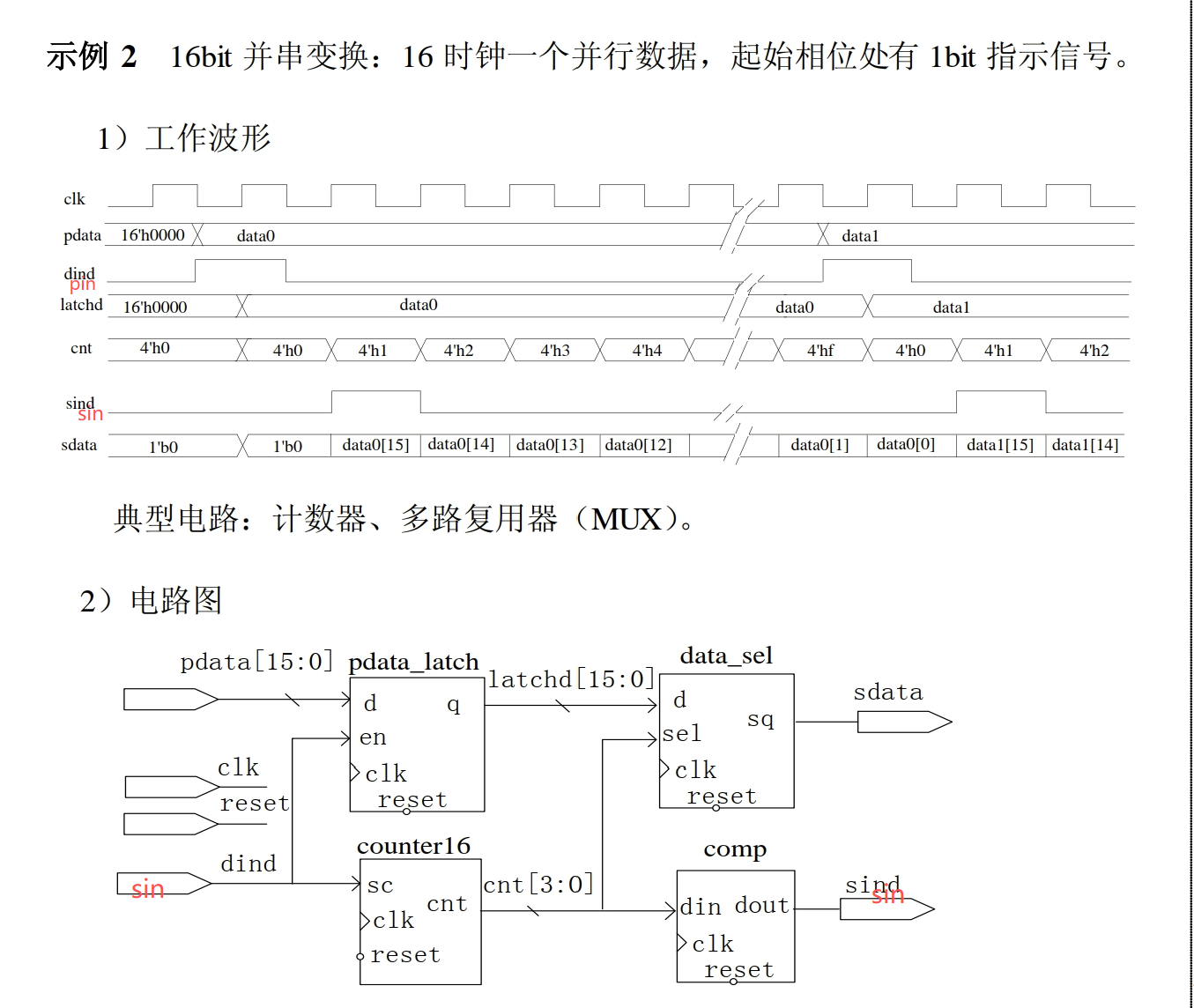
pin→锁存 pdata 到 latchd,同时 counter16 从 0 开始计数;每个 clk 用 cnt 去 MUX 选择 latchd 的一位输出到 sdata,连续 16 拍完成一帧,并用 sind 标记这段输出有效区间。
对比data_sel(主要逻辑):
-
assign sdata = latchd15 - cnt (之前博客记录的AI写的代码实现逻辑)
-
移位寄存器写法
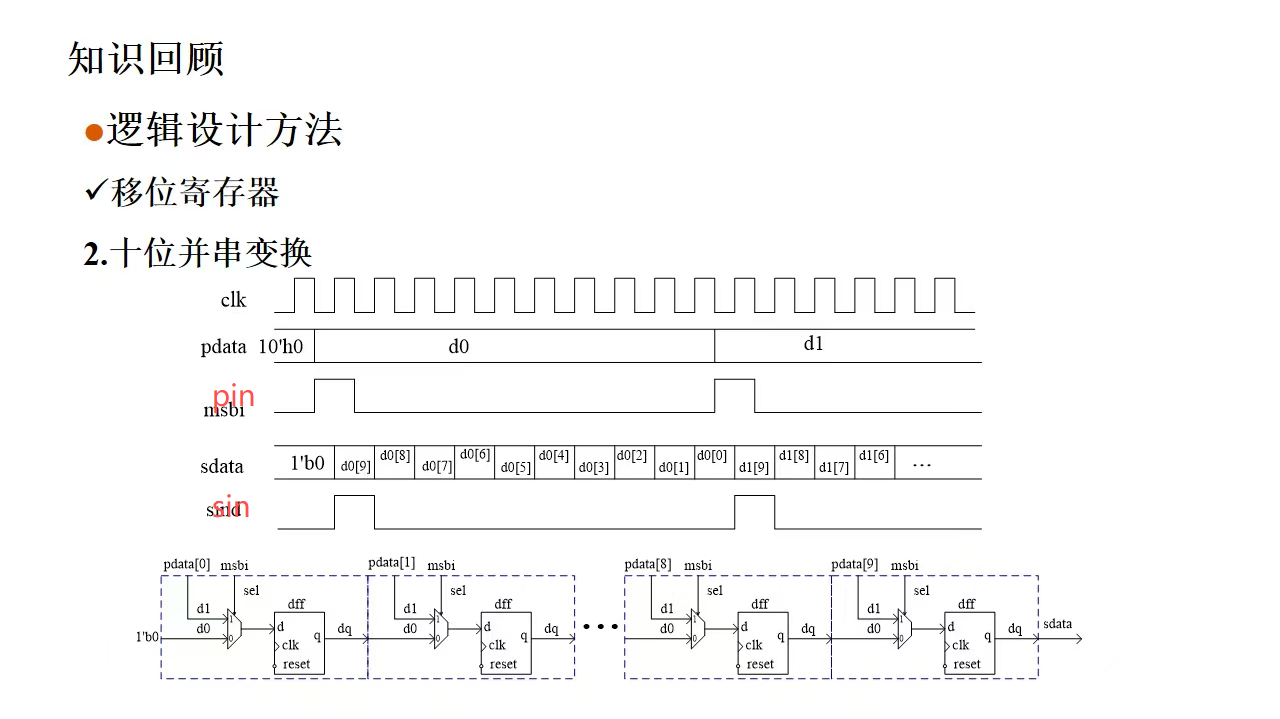
pin起始位使能选择器,使pdata0,pdata1....pdata15并行进入,否则移位寄存器功能串行输出,低位补0。
核心逻辑,{dout,sr1514:0}={sr14:0,1'b0}
信号说明:pdata_latch={dout,sr1514:0},sr15为15个shift reg移位寄存器+reg dout=16个shift reg
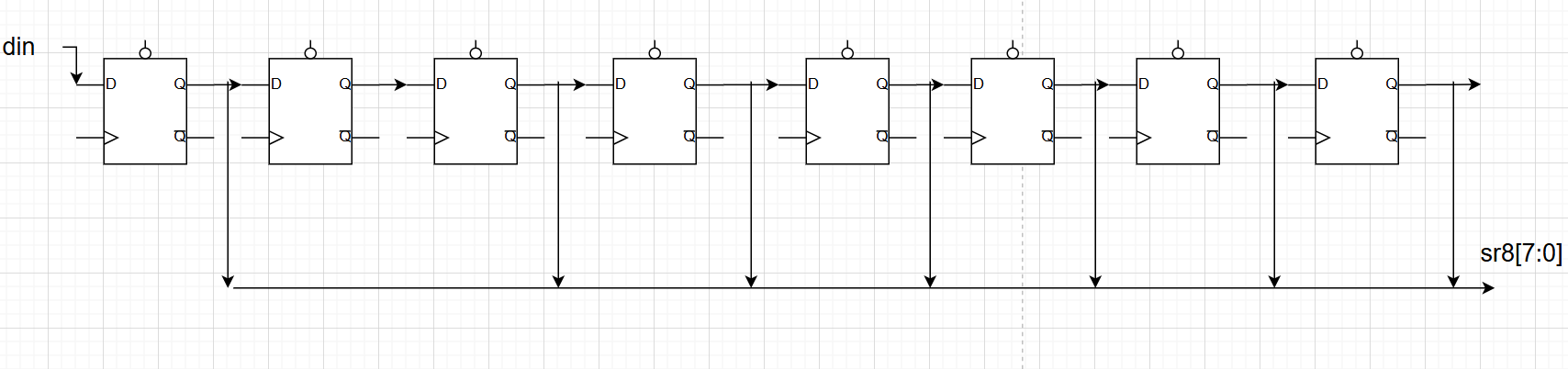
对比:关于移位寄存器串并转换,1bit=>8bit:sr8<={sr86:0,din};低位补din,counter计数控制八位输出sr7:0/pdata7:0。
下面是老师给的10位转1位代码,
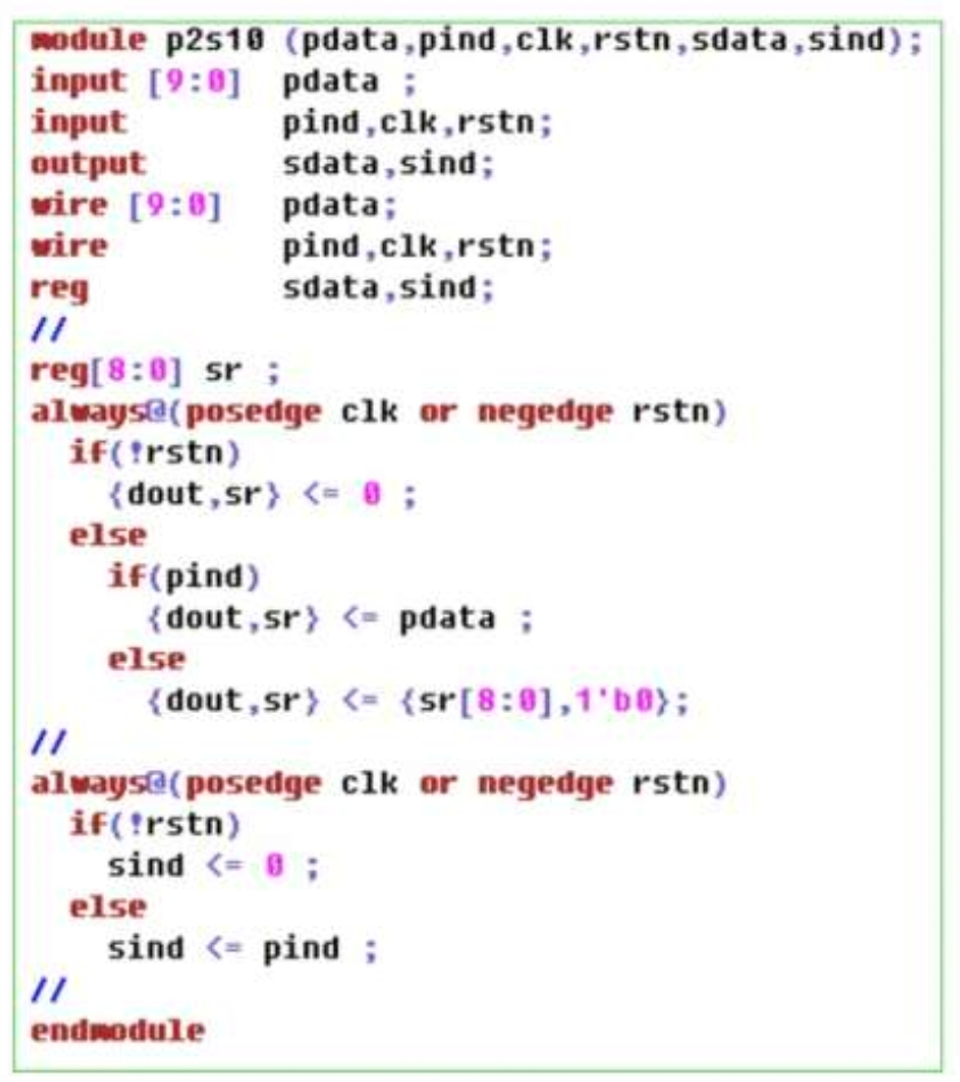
1.3 有限状态机
1.3.1 序列检测
一般为移位寄存器实现,这里简化版应用,可以对比网络数据包发送接收逻辑,用状态图表示:空闲状态,接收前导码,以太网帧头等,只是序列检测的数据逻辑比较简化。
-
序列检测(0110 / 4'h6):
也是 FSM,只不过"输入很简单(1bit)+ 规则很短(4位)",状态表示"匹配到前缀多少位"。
-
网络数据解析:
本质也是"序列检测",但序列变成了"多段长格式":前导码→以太网头→IP头→ICMP头→数据。
状态不是"匹配到第几位",而是"正在解析哪一段协议字段"。
序列检测是"短模式匹配"的 FSM;网络解析是"长格式分段解析"的 FSM。两者思想一致:用状态表示进度,用转移表示条件。
下面又又又直接偷老师图:

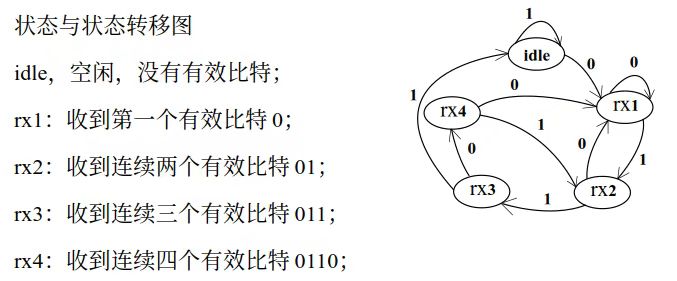
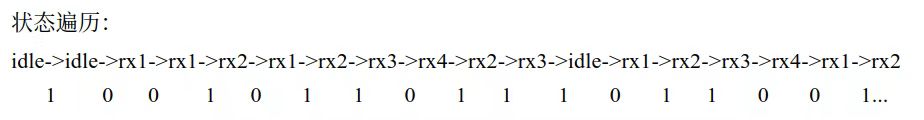

1.3.2 网络数据解析
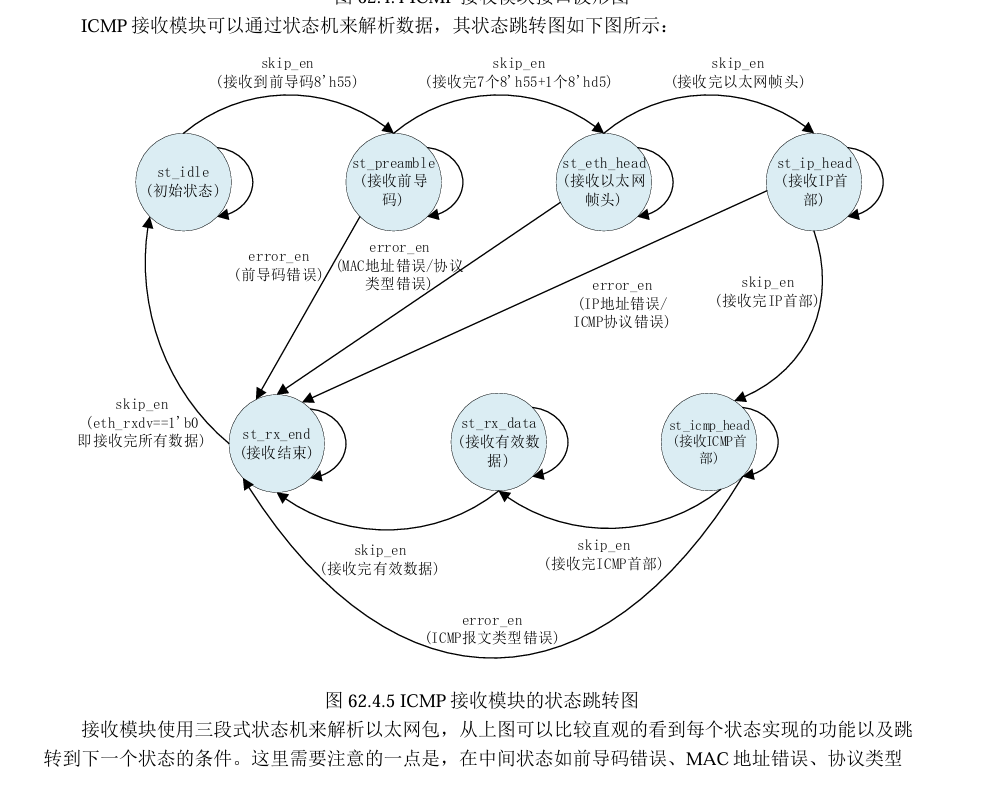
参考正点原子FPGA开发指南
(1)
图里的 ICMP 接收状态机就是在做这件事:一边按字节接收数据,一边按协议格式分段解析。
状态机流程
-
st_idle(空闲)
等待网卡开始吐数据(接收开始)。
-
st_preamble(前导码)
先跳过以太网"同步用"的前导码
55...55 D5。这段不属于真正的数据内容,只是为了让收发双方"对齐节拍"。 -
st_eth_head(以太网帧头)
开始读帧头:目的 MAC、源 MAC、类型 EtherType。
- 如果目的 MAC 不匹配(不是发给我的)或类型不是 IP → 直接丢掉(走 error_en / rx_end)。
-
st_ip_head(IP 头)
读 IP 首部:版本、长度、协议号、源/目的 IP 等。
- 如果目的 IP 不对,或者 IP 协议号不是 ICMP(或者你图里写的 TCP 之类)→ 丢弃。
-
st_icmp_head(ICMP 头)
读取 ICMP 类型/校验等。
- 类型不对(比如只想要 echo request/reply)→ 丢弃。
-
st_rx_data(有效载荷数据)
真正把 payload 当"有效数据"接收下来(缓存/上交)。
-
st_rx_end(接收结束)
一帧处理完,回到 idle,准备下一帧。
说明:
(1)
skip_en :这一段我不需要存,只需要计数跳过(比如前导码、某些头部字段)。
error_en :中途发现不符合条件,立刻放弃这帧(省资源、也避免把错数据当真)。
(2)为什么网络解析必须用状态机?
因为网络帧是"流式输入 + 分段结构 + 条件分支很多"。
-
数据是"边来边处理"的
以太网数据是一拍一字节/一拍几bit连续进来的,不是一次性给你完整包。状态机能记住"我现在解析到哪一段了"。
-
协议是"分层封装"的
以太网里嵌 IP,IP 里嵌 ICMP。每层的头部长度/字段不同。状态机就是"按层拆箱"的流程控制器。
-
有大量"早退/丢包"条件
MAC 不对就丢、IP 不对就丢、协议号不对就丢、ICMP 类型不对就丢。
状态机天然适合做"走一步判断一步,不符合就结束"。
-
不只要识别,还要控制资源与时序
哪些字节需要保存,哪些只要跳过;什么时候开始写 FIFO,什么时候停止;这些都靠状态机在正确时刻开关控制信号。
二. 以太网UDP数据报文发送电路设计0-基础知识
2.1 OSI模型
通信系统的功能分层/分工图,通信过程里需要完成的功能(比如:比特怎么传、怎么成帧、怎么寻址路由、怎么建立连接、怎么表示/加密数据、怎么给应用用)分成 7 层。
ISO开发系统和TCP/IP协议栈分别对应OSI模型的七层和四层。
七层
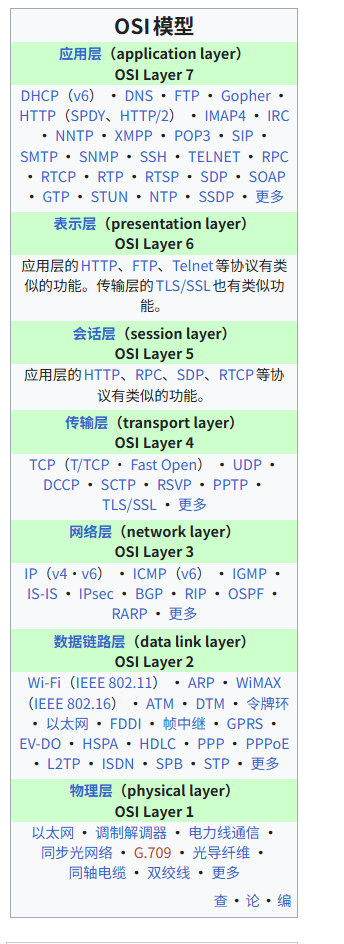
详情查看维基百科,链接
https://zh.wikipedia.org/wiki/OSI%E6%A8%A1%E5%9E%8B
四层-tcp/ip网络协议栈
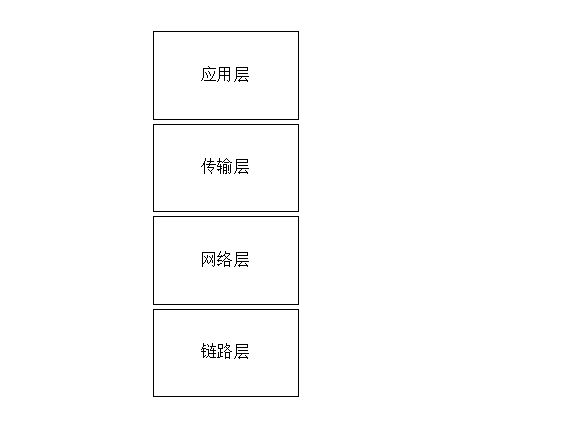
2.2 数据
2.2.1 封装
(1)概念
通信过程每层协议都要加一个数据首部(header)称为封装。
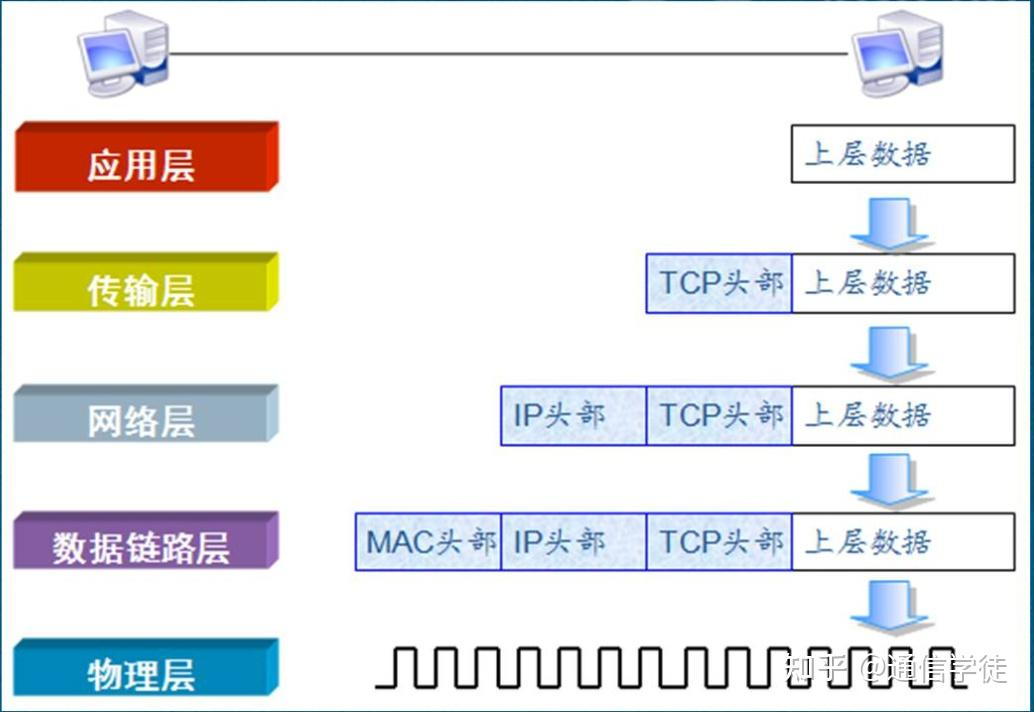
同一份用户数据,在不同层会加上不同的控制信息(首部/尾部):
-
传输层 :TCP 叫 段 segment ;UDP 常叫 数据报 datagram
关键作用:端口号、可靠传输(TCP)、分段重传等。
-
网络层(IP) :叫 IP 数据报 / 分组 packet
关键作用:IP 地址、路由转发。
-
链路层(以太网) :叫 帧 frame
关键作用:MAC 地址、同一链路内传输、差错检测(FCS)。
每层都把数据"包装成自己这一层的格式"。
2.2.2 封装与解封装
发送端:从上到下逐层封装
应用数据往下走时,每层都加自己的首部(链路层还会加尾部 FCS),形成:
应用数据
→ TCP首部 + 应用数据 (传输层:段)
→ IP首部 + TCP段 (网络层:IP数据报)
→ 以太网首部 + IP数据报 + 以太网尾部FCS (链路层:帧)
→ 变成比特流在网线/无线里发出去(物理层)
接收端:从下到上逐层解封装
收到的是以太网帧:
-
链路层先检查帧格式/FCS,正确就把以太网首部/尾部去掉,把"有效载荷"交给上层。
-
网络层再检查 IP 首部,决定交给 TCP/UDP,再把 IP 首部去掉。
-
传输层根据端口号交给正确的应用进程,最后应用程序拿到原始数据。
2.2.3 典例
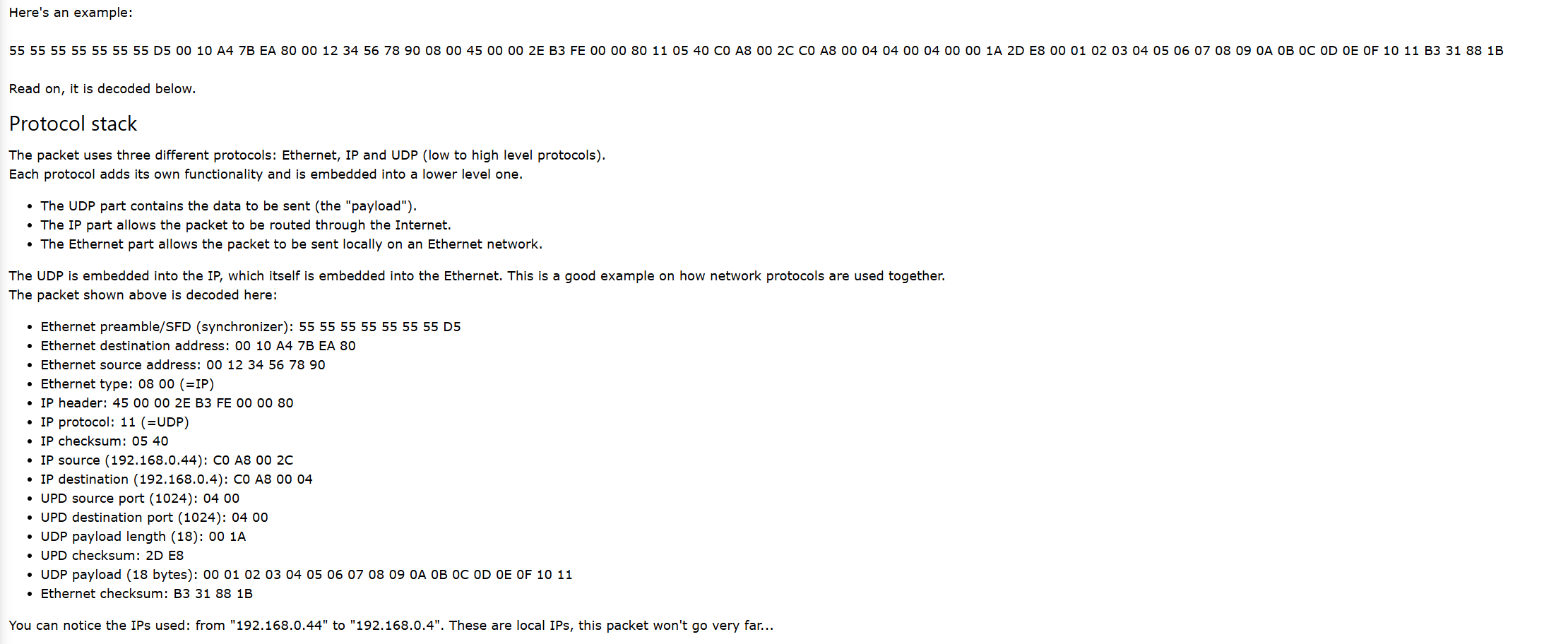
让我们专注于以太网/IP/UDP数据包。 这些数据包很容易生成;但功能强大,它们可以在互联网上传输(并发送到世界任何地方!)。
这是一个例子:
55 55 55 55 55 55 55 D5 00 10 A4 7B EA 80 00 12 34 56 78 90 08 00 45 00 00 2E B3 FE 00 00 80 11 05 40 C0 A8 00 2C C0 A8 00 04 04 00 04 00 00 1A 2D E8 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F 10 11 B3 31 88 1B
下面是它的解码。
协议栈:
该数据包使用三种不同的协议:以太网、IP和UDP(从低到高层协议)。 每种协议都添加了自己的功能,并嵌入到较低级别的协议中。 UDP部分包含要发送的数据("有效负载")。 IP部分允许数据包通过互联网路由。 以太网部分允许数据包在以太网网络上本地发送。 UDP嵌入到IP中,IP本身又嵌入到以太网中。 这是一个关于如何一起使用网络协议的好例子。
上面显示的数据包在此处解码:
以太网前导码/SFD(同步器):55 55 55 55 55 55 55 D5
以太网目标地址:00 10 A4 7B EA 80
以太网源地址:00 12 34 56 78 90
以太网类型:08 00(=IP)
IP报头:45 00 00 2E B3 FE 00 00 80
IP协议:11(=UDP)
IP校验和:05 40
IP源地址(192.168.0.44):C0 A8 00 2C
IP目标地址(192.168.0.4):C0 A8 00 04
UDP源端口(1024):04 00
UDP目标端口(1024):04 00
UDP有效负载长度(18):00 1A
UDP校验和:2D E8
UDP有效负载(18 字节):00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F 10 11
以太网校验和:B3 31 88 1B
您可以注意到使用的IP:从"192.168.0.44"到"192.168.0.4"。 这些是本地IP,此数据包不会传播很远...
2.3 以太网(Ethernet)
1.当今现有局域网采用的最通用的通信协议标准。
分类,标准以太网(10M bit/s),快速以太网(100M),千兆以太网(1000M)
2.以太网接口
开发板/网卡上说的"以太网接口"一般包含两部分:
-
MAC 控制器(Media Access Control):链路层的 MAC 子层(偏数字逻辑)
-
PHY(Physical Layer Transceiver):物理层收发器(偏模拟/高速电路)
再加上两者之间的标准连接口:MII / RMII / GMII / RGMII / SGMII 等。
3.MAC 控制器
MAC 主要做的是 以太网帧(frame)这一层相关工作,负责构造/解析"以太网帧"的格式与校验(链路层)
例如:
-
组帧/解帧:目的 MAC、源 MAC、EtherType、Payload
-
添加/检查 FCS(CRC32)
-
帧间隔、最小帧长、填充
-
与上层(IP/ARP)或用户逻辑之间的数据搬运:常见是 FIFO / DMA 接口
说明:
(1)MAC 不负责 IP 路由、UDP/TCP 端口等网络层/传输层功能。
IP/UDP/TCP 的"包"通常在 CPU 的协议栈里生成,或者在 FPGA 里写"硬件协议栈/简化协议栈"生成。
(2)MAC 通常是一个硬件模块(外设/控制器),可能出现在:
-
MCU/SoC 内部(比如 STM32 的以太网 MAC 外设)
-
FPGA 里(自己写 Verilog/VHDL,或用厂商 IP Core)
-
独立网卡芯片中
CPU/单片机做的更多是:
-
管理 MAC/PHY 寄存器
-
把要发送的数据交给 MAC(通过 DMA/FIFO),或者从 MAC 收到数据再处理
-
跑协议栈(ARP/IP/UDP/TCP)
4.PHY
PHY 是 物理层收发器,负责把"数字比特流"变成"网线上能跑的电信号",以及反过来恢复回来。包括:
-
自协商(Auto-Negotiation):10/100/1000 速率、双工模式协商
-
向 MAC 提供一个标准数字接口(MII/RMII/RGMII/SGMII 等)
-
线路编码/解码(不同速率/标准不同)
-
模拟前端:驱动网线、接收放大、滤波、时钟恢复(CDR)
5.以太网接口典型发送路径:
-
上层(CPU/FPGA逻辑)准备好一帧以太网数据(至少包含 MAC 地址、类型、payload)
-
MAC 加工:补齐、算 CRC、控制发送时序
-
MAC 通过 MII/RMII/RGMII 等把数据喂给 PHY
-
PHY 把它编码成电信号送到 RJ45(中间还要经过隔离变压器"磁性器件")
接收路径反过来:
PHY 从线缆恢复比特 → 交给 MAC → MAC 校验 CRC/拆帧 → 上交给协议栈或用户逻辑。
以太网接口电路设计可以FPGA实现MAC控制器,然后通过RGMII接口发给PHY,关于RGMII高速接口可以调用IP核简化。