在之前的文章中,我们聊了持久化如何保数据,分布式锁如何保互斥。今天,我们要聊聊 Redis 生产环境中两个最头疼、最容易引发线上事故的"毒瘤":热 Key (Hot Key) 和 大 Key (Big Key)。
很多时候,Redis 整体运行良好,但就是因为某一个 Key 的出现,导致整个集群瘫痪。这一篇,我们彻底拆解它们的成因、危害及解决方案。
一、 热 Key (Hot Key):万人空巷买爆款
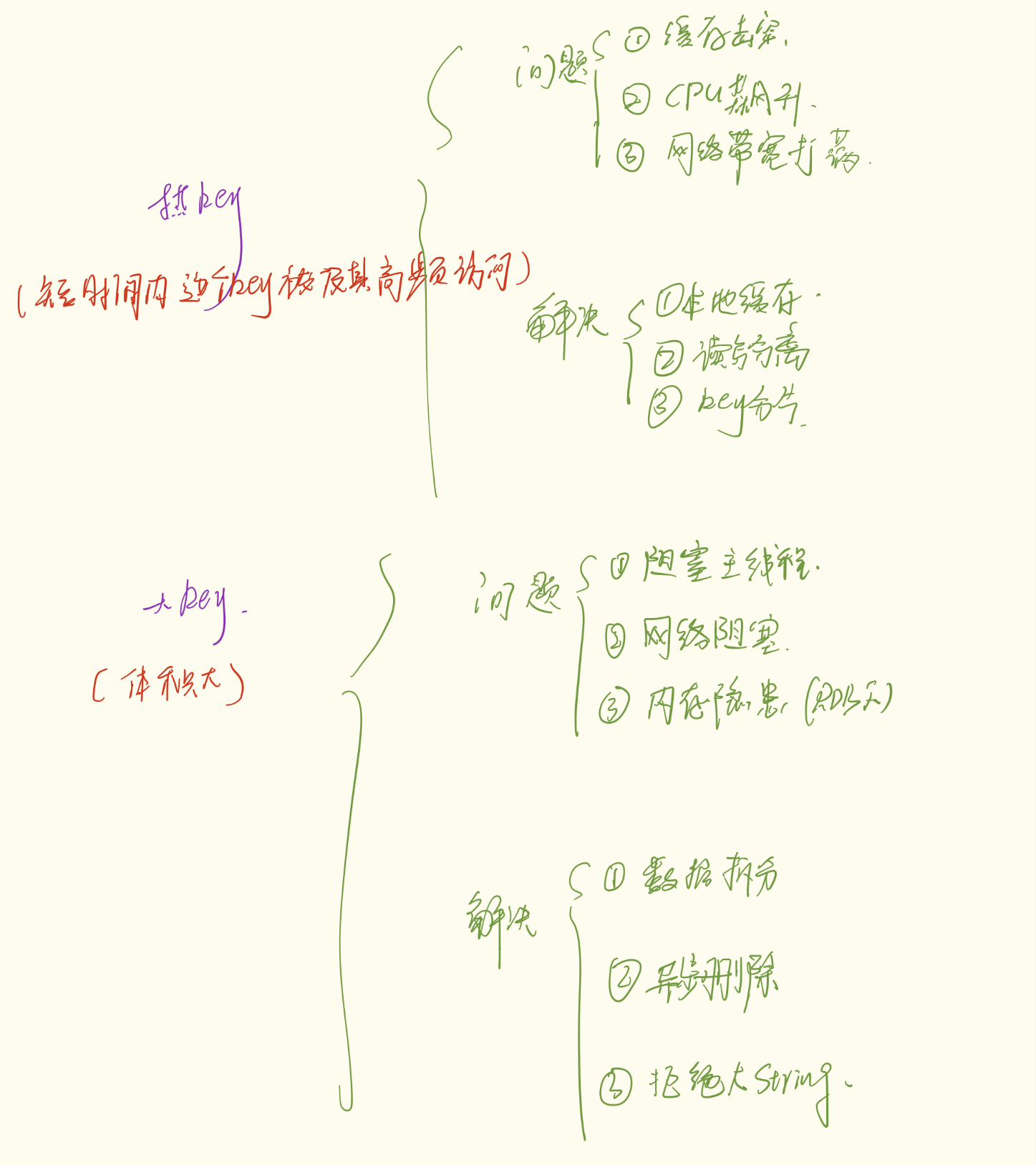
1. 什么是热 Key(对应缓存击穿问题)?
核心特征:频次高 (QPS 爆炸)。
指的是在短时间内,某个 Key 被极高频地访问(比如每秒几万次请求)。
形象比喻:
想象一家奶茶店(Redis),平时大家有序排队。突然,周杰伦发了新歌 MV,手里拿着一杯**"莫吉托特调"**。
瞬间,几万个粉丝冲进店里,都要点这一杯"莫吉托"。店员(主线程)光是处理这一个商品的点单就忙疯了,根本没空理其他顾客。
2. 有什么危害?
-
CPU 飙升:Redis 是单线程的,处理热 Key 占用了绝大部分 CPU 时间片,导致其他正常请求排队阻塞,甚至超时。
-
网络带宽打满:虽然数据包可能不大,但每秒几十万次的进出,瞬间把网卡流量塞满。
-
缓存击穿风险:一旦这个热 Key 突然过期,这几万倍的流量会瞬间"击穿"缓存,直接打在脆弱的数据库上,导致数据库雪崩。
3. 解决方案
方案 A:本地缓存 (Local Cache) ------ 最强解法
既然 Redis 扛不住,那就别去 Redis 了。
-
思路:在应用服务器(如 Tomcat/JVM)的内存中再存一份。
-
实现 :使用 Caffeine 或 Guava Cache。
-
流程:请求来了 -> 先查本地缓存 -> 有就直接返回(耗时 0ms) -> 没有再去查 Redis。
-
热 Key 发现:
-
自动发现:客户端代码统计 Key 的访问频率,超过阈值自动升级为本地缓存。
-
LRU 淘汰:设置本地缓存上限(如 5000 个),利用 LRU 机制,热 Key 会天然留在本地缓存中,冷数据会被自动挤出。
-
方案 B:读写分离 (Read-Write Separation) ------ 人海战术
-
思路:利用热 Key 通常是**"读多写少"**的特性。
-
实现 :部署 1 主 N 从。
-
Master:负责写(哪怕热 Key 修改了,也只打一次 Master)。
-
Slave:负责读。将 10 万次读请求分摊给 4 个 Slave 节点,每个节点抗 2.5 万次,压力瞬间减小。
-
-
局限:如果热 Key 是**"写热点"**(如秒杀扣库存),此方案无效(写请求只能打 Master)。
方案 C:Key 分片 (Sharding)
-
思路:把一个热 Key 拆成多个替身。
-
实现 :将
product:1001备份为product:1001_1...product:1001_10。每次请求时,随机选一个后缀去访问。 -
缺点:数据同步麻烦(更新时要同时改 10 份)。
二、 大 Key (Big Key):搬运一架大钢琴
1. 什么是大 Key?
核心特征:体积大 (Size 臃肿)。
-
String 类型:单个 Value 超过 10KB(甚至达到 MB 级别)。
-
集合类型 (Hash/List/Set):元素个数超过 5000 个(甚至上百万个)。
形象比喻:
奶茶店正常运营,突然有个顾客下单买了一个**"超大号冰雕",重达 1 吨。
要把这个冰雕搬出来给客户,店员需要耗时 1 秒。在这 1 秒内,门口排队的 1000 个买奶茶的客户全部被堵在大门外**,动弹不得。
2. 有什么危害?
-
阻塞主线程:这是最致命的。Redis 是单线程模型,处理大 Key(读取或删除)耗时极长,导致服务假死。
-
网络阻塞:一个大 Key 的响应数据可能占满带宽,导致其他请求挤不进来。
-
内存隐患:在使用 RDB 持久化时,如果主线程修改大 Key,操作系统需要进行 Copy-On-Write 复制大量内存,可能导致 OOM(内存溢出)。
3. 解决方案
方案 A:数据拆分 (Split) ------ 化整为零
-
思路:别存一个巨大的 Hash,拆成多个小的。
-
实现:
-
原 Key:
UserList(100万个用户)。 -
拆分后:
UserList_1...UserList_100。 -
存取时,通过
hash(UserID) % 100找到对应的子 Key。
-
方案 B:异步删除 (UNLINK) ------ 悄悄丢弃
这是 Redis 4.0 引入的神器,专门解决**"删除大 Key 阻塞"**的问题。
-
DEL 命令 (同步):主线程必须亲自释放那 2MB 的内存,耗时 30ms,期间 Redis 卡死。
-
UNLINK 命令 (异步):
-
主线程只做一个动作:把 Key 的名字从"账本"里划掉(耗时忽略不计)。
-
主线程立马返回 OK,不阻塞后续请求。
-
真正的内存回收工作,交给后台的 BIO 线程 慢慢去做。
-
-
注意 :UNLINK 解决的是**"删"的阻塞,如果你硬要去"读"**大 Key,依然会阻塞。
方案 C:拒绝大 String
-
不要在 Redis 里存图片、视频二进制数据,或者超长的 JSON。
-
这类数据应该存入 OSS (对象存储),Redis 只存 URL。
三、 总结与对比(记忆宫殿)
| 维度 | 热 Key (Hot Key) | 大 Key (Big Key) |
|---|---|---|
| 核心特征 | 请求次数多 (QPS 高) | 数据体积大 (Size 大) |
| 形象比喻 | 周杰伦发新歌 (流量爆表) | 搬运大钢琴 (堵塞通道) |
| 最大危害 | CPU 满载、击穿 DB | 阻塞主线程、网络拥塞、OOM |
| 最强解法 | 本地缓存 (Caffeine) | 拆分 (Split) + 异步删 (UNLINK) |
| 辅助解法 | 读写分离 (解决读热点) | 存 OSS、避免大 String |
最后给开发的建议:
-
事前:做好系统设计,预判热 Key(如秒杀商品),规避大 Key(如大列表)。
-
事中 :使用
redis-cli --bigkeys定期扫描,发现异常及时拆分。 -
事后:完善监控,一旦发现 Redis 响应变慢或 CPU 飙升,优先排查是否出现了这两个"隐形杀手"。