系列文章目录
MySQL 运维之日常运维篇 一
MySQL 运维之日常运维篇 二
文章目录
- 系列文章目录
- 前言
- 一、测试环境搭建
- [二、MySQL 数据备份与恢复:从原理到实操全流程](#二、MySQL 数据备份与恢复:从原理到实操全流程)
-
- 前言:为什么备份与恢复是数据库运维的"生命线"?
- 一、数据备份:先搞懂3个核心问题
-
- [1. 备份前必明确:你的业务需要什么样的备份策略?](#1. 备份前必明确:你的业务需要什么样的备份策略?)
- [2. 3种备份方式:全量、增量、差异](#2. 3种备份方式:全量、增量、差异)
- [3. 备份避坑:常见问题及解决方案](#3. 备份避坑:常见问题及解决方案)
- 二、数据恢复:不同场景下的完整流程
-
- [1. 恢复前必做:3个准备工作](#1. 恢复前必做:3个准备工作)
- [2. 场景1:基于全量备份恢复(无增量数据)](#2. 场景1:基于全量备份恢复(无增量数据))
- [3. 场景2:全量+增量备份恢复(数据量较大)](#3. 场景2:全量+增量备份恢复(数据量较大))
- [4. 场景3:基于binlog的时间点恢复(PITR)](#4. 场景3:基于binlog的时间点恢复(PITR))
- [5. 场景4:基于binlog的单独恢复误删除的数据](#5. 场景4:基于binlog的单独恢复误删除的数据)
- [6. 恢复避坑:常见问题及解决方案](#6. 恢复避坑:常见问题及解决方案)
- 三、进阶:备份与恢复的自动化与监控
-
- [1. 自动化备份脚本(示例:全量+增量+清理)](#1. 自动化备份脚本(示例:全量+增量+清理))
- [2. 备份监控:确保备份"可信赖"](#2. 备份监控:确保备份“可信赖”)
- 四、备份与恢复的核心原则
- 五、动手实验
-
- [mysqldump 全量备份与恢复](#mysqldump 全量备份与恢复)
- [xtrabakcup 全量备份+增量备份与恢复](#xtrabakcup 全量备份+增量备份与恢复)
- 三、异常环境的模拟与问题处理
-
- [**「高 CPU 使用率 + 低 I/O」错误**](#「高 CPU 使用率 + 低 I/O」错误)
- **模拟「高内存占用」环境**
- 总结
前言
在看本文前,建议先看完 MySQL 运维之日常运维篇 一
本文的主要内容有MySQL 测试环境的搭建、MySQL的数据备份与恢复、环境异常的模拟与处理
一、测试环境搭建
服务器配置如下
OS:Ubuntu-20.04
CPU:2 核
内存:4G
建议配置小一点,方便后面做测试时模拟环境的建立
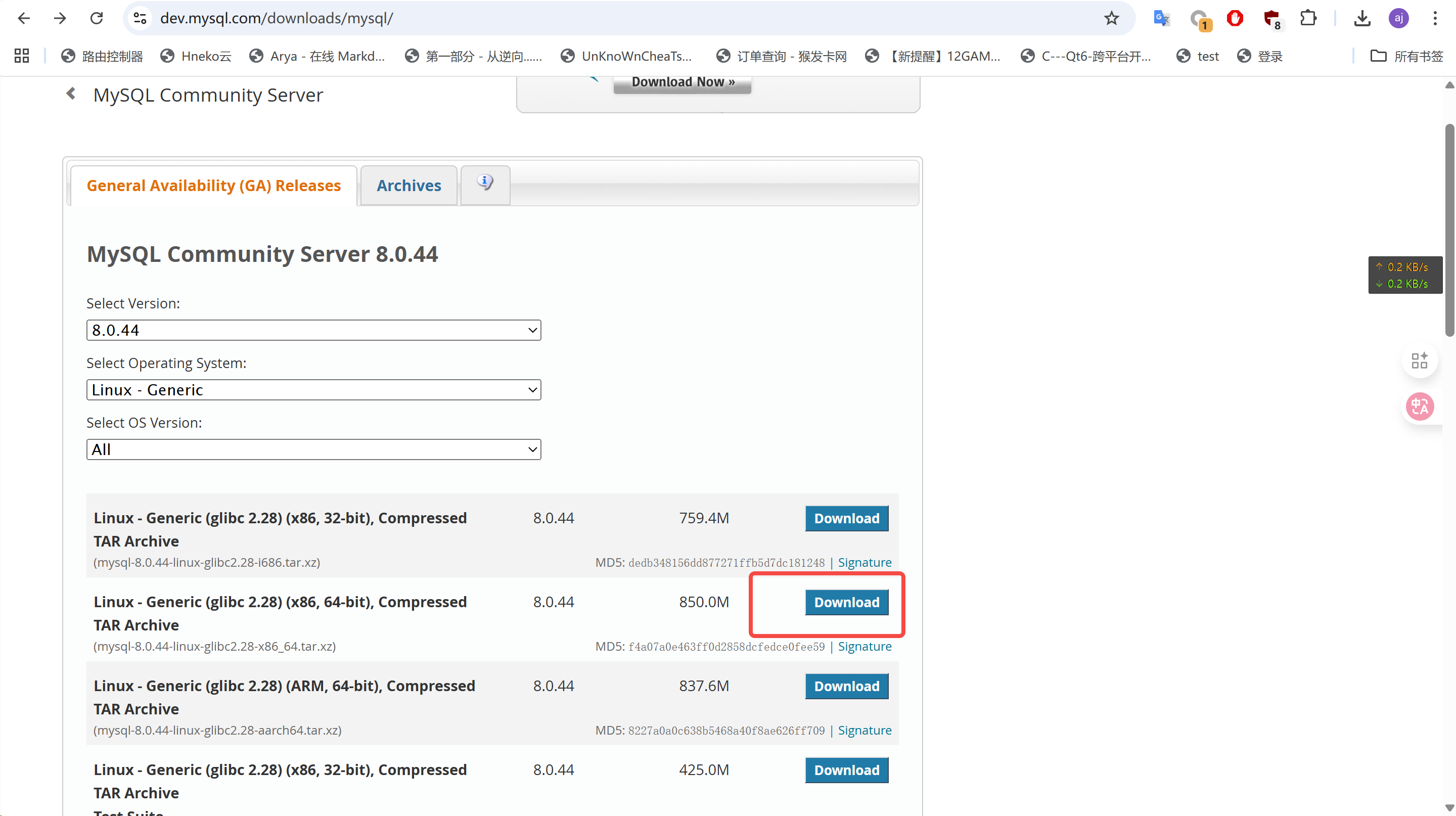
下载包并上传到服务器上的 /usr/local
bash
# 安装目录
mkdir -p /usr/local/mysql
# 数据目录
mkdir -p /data/mysql
# 日志目录(对应 my.cnf 配置)
mkdir -p /var/log/mysql
# 套接字文件目录(对应 my.cnf 配置)
mkdir -p /var/run/mysqld
# 创建 mysql 用户(隔离权限)
groupadd mysql
useradd -r -g mysql -s /bin/false mysql
# 授权目录权限
chown -R mysql:mysql /usr/local/mysql
chown -R mysql:mysql /data/mysql
chown -R mysql:mysql /var/log/mysql
chown -R mysql:mysql /var/run/mysqld- 解压与初始化
bash
tar -xvf mysql-8.0.44-linux-glibc2.28-x86_64.tar.xz -C /usr/local/mysql --strip-components=1
cd /usr/local/mysql/bin
./mysqld --initialize --user=mysql --datadir=/data/mysql --basedir=/usr/local/mysql
cat /var/log/mysql/error.log | grep temporary
# 在结果中找到
A temporary password is generated for root@localhost: TrE8p;ufsEg3- 配置 my.cnf
bash
cat > /etc/my.cnf << "EOF"
[client]
port=3306
socket=/var/run/mysqld/mysqld.sock
[mysql]
default_character_set=utf8mb4
prompt="mysql-test> "
auto-rehash
[mysqld]
port=3306
bind-address=0.0.0.0
user=mysql
basedir=/usr/local/mysql
datadir=/data/mysql
socket=/var/run/mysqld/mysqld.sock
pid-file=/data/mysql/mysql.pid
tmpdir=/tmp
lc-messages-dir=/usr/share/mysql
skip-external-locking
character_set_server=utf8mb4
collation_server=utf8mb4_unicode_ci
init_connect='SET NAMES utf8mb4'
character_set_filesystem=utf8mb4
slow_query_log=1
slow_query_log_file=/var/log/mysql/slow.log
long_query_time=1
log_queries_not_using_indexes=1
min_examined_row_limit=1000
log_slow_admin_statements=1
log_bin=/var/log/mysql/mysql-bin
binlog_format=ROW
binlog_expire_logs_seconds=2592000
max_binlog_size=100M
binlog_cache_size=32M
max_binlog_cache_size=4G
server-id=1
innodb_redo_log_capacity=2G
innodb_log_buffer_size=64M
innodb_buffer_pool_size=2G
innodb_flush_log_at_trx_commit=1
innodb_file_per_table=1
innodb_flush_method=O_DIRECT
max_connections=1000
wait_timeout=600
interactive_timeout=600
max_allowed_packet=64M
skip-name-resolve
sql_mode=STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION
log_error=/var/log/mysql/error.log
[mysqld_safe]
log-error=/var/log/mysql/error.log
pid-file=/data/mysql/mysql.pid
EOF- 启动MySQL
bash
# 方式1:直接启动 mysqld(后台运行)
/usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf &
# 方式2:用 mysqld_safe 启动(带守护进程,崩溃自动重启)
/usr/local/mysql/bin/mysqld_safe --defaults-file=/etc/my.cnf &
# 查看进程
ps -aux | grep mysqld
# 查看端口监听
ss -tulpn | grep 3306
# 查看日志(确认无报错)
tail -n 20 /var/log/mysql/error.log方式1:优雅停止(需输入 root 密码)
/usr/local/mysql/bin/mysqladmin -u root -p shutdown
方式2:强制停止(紧急情况使用)
pkill -9 mysqld
- 修改默认密码
bash
# 将密码改为你的临时密码
/usr/local/mysql/bin/mysql -u root -p's?9>-GV6LBRb'
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root@123456';
FLUSH PRIVILEGES;
# 允许root可远程连接
CREATE USER 'root'@'%' IDENTIFIED BY 'root@123456';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
FLUSH PRIVILEGES;- 创建示例数据,验证是否成功搭建
sql
create database if not exists test_db;
-- 仅在容器首次启动时执行,后续重启不重复执行
USE test_db;
-- 创建测试表
CREATE TABLE IF NOT EXISTS test_user(
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(50) NOT NULL COMMENT '用户名',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间'
) COMMENT '测试用户表';
INSERT INTO test_db.test_user (username) VALUES ('test_user1'), ('test_user2');
SELECT * from test_db.test_user;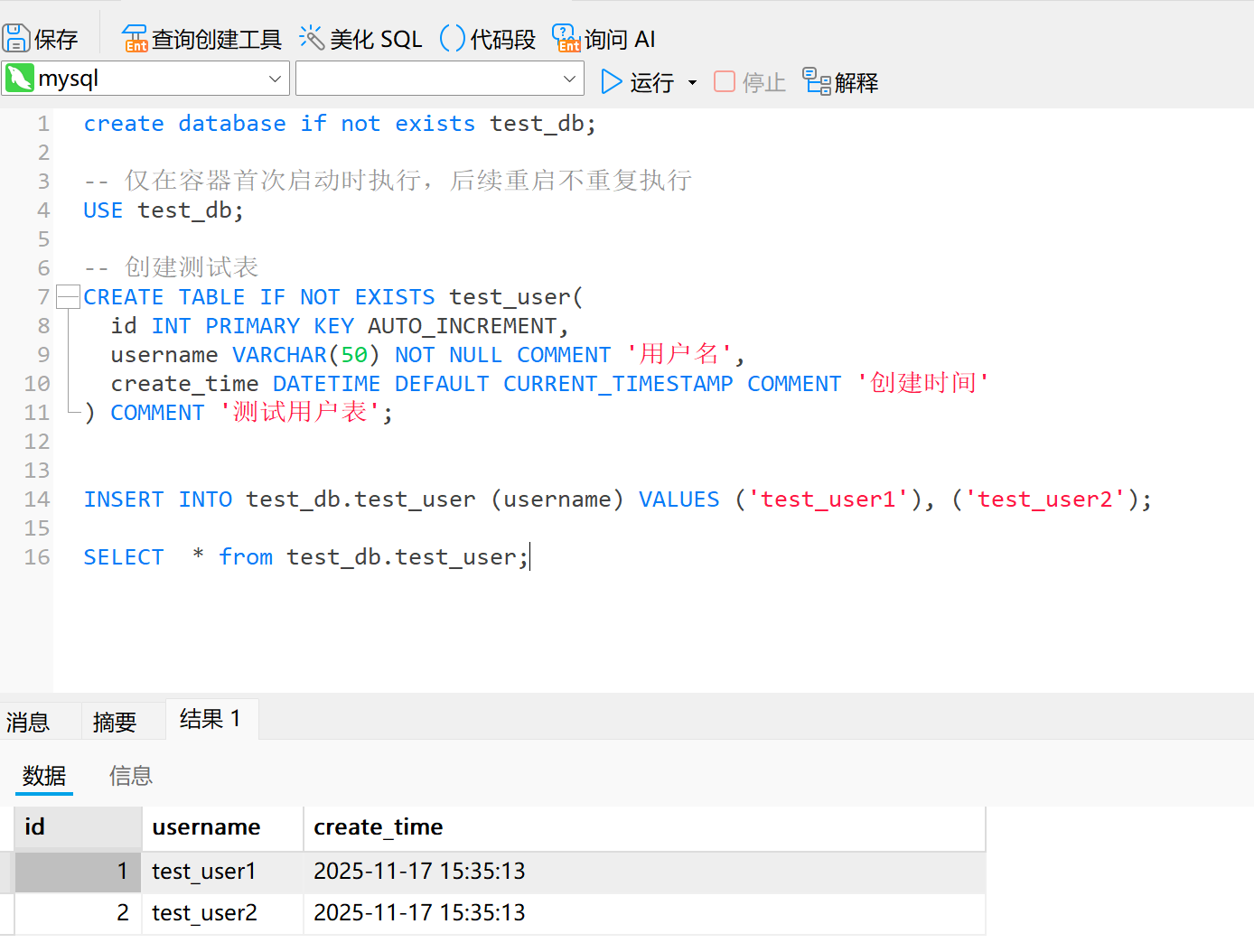
- 将命令行加入环境变量
bash
vim ~/.bashrc
export PATH=$PATH:/usr/local/mysql/bin
source ~/.bashrc测试环境搭建完成
二、MySQL 数据备份与恢复:从原理到实操全流程
前言:为什么备份与恢复是数据库运维的"生命线"?
- 核心价值:避免数据丢失(误删、崩溃、勒索)、保障业务连续性
- 痛点场景:误删表/库、服务器宕机、主从同步中断、数据篡改
- 核心原则:"可备份、可恢复、可验证"(备份后必须测试恢复)
一、数据备份:先搞懂3个核心问题
1. 备份前必明确:你的业务需要什么样的备份策略?
- 关键决策点:
- RPO(恢复点目标):最多能接受丢失多少数据?(如1小时/5分钟)
- RTO(恢复时间目标):最多能接受多久恢复服务?(如1小时/30分钟)
- 备份窗口:业务低峰期(如凌晨2-4点),避免影响线上业务
- 常见场景对应策略:
- 小业务(数据量<100GB):全量备份(每日1次)+ binlog(实时)
- 中大型业务(数据量100GB-1TB):全量(每周1次)+ 增量(每日1次)+ binlog
- 超大型业务(数据量>1TB):全量(每周1次)+ 增量(每6小时1次)+ binlog + 分区表备份
2. 3种备份方式:全量、增量、差异
(1)全量备份:备份所有数据(基础中的基础)
- 定义:一次性备份数据库实例中所有数据(表、索引、存储过程等)
- 工具:mysqldump(逻辑备份,跨版本兼容)、xtrabackup(物理备份,速度快)
- 优缺点:
- 优点:恢复简单(直接还原)、无依赖
- 缺点:耗时久、占用空间大(如1TB数据备份需数小时)
- 实操命令示例:
- mysqldump 全量备份(适用于小数据量):
bash
# 忽略系统表,因为系统表一般不允许手动修改
mysqldump -uroot -p -h 127.0.0.1 -P 3306 \
--databases $(mysql -uroot -p -h 127.0.0.1 -P 3306 -NBe "SELECT SCHEMA_NAME FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME NOT IN ('mysql', 'sys', 'information_schema', 'performance_schema')") \
--add-drop-database \
--add-drop-table \
--routines \
--events \
--triggers \
--single-transaction \
--quick \
> full_back_$(date +%Y%m%d).sql-
xtrabackup 全量备份(适用于大数据量):
bashxtrabackup --user=root --password=xxx --backup --target-dir=/backup/full_$(date +%Y%m%d)
(2)增量备份:备份上次备份后新增/变更的数据
-
定义:基于上一次全量/增量备份,仅备份变化的数据(需依赖全量备份为基础)
-
工具:xtrabackup(仅物理备份支持增量,mysqldump不支持)
-
优缺点:
- 优点:耗时短、占用空间小
- 缺点:恢复复杂(需先还原全量+所有增量,顺序不能乱)
-
实操命令示例(基于全量备份的增量备份):
bashxtrabackup --user=root --password=xxx --backup --target-dir=/backup/inc_$(date +%Y%m%d) --incremental-basedir=/backup/full_20251117
(3)差异备份:基于上一次全量的变化数据
- 定义:基于上一次全量备份,备份所有变化的数据(与增量的区别:增量基于上一次备份,差异基于上一次全量)
- 适用场景:RPO要求不高,且不想频繁做全量备份的场景
- 优缺点:
- 优点:恢复比增量简单(全量+最新差异)
- 缺点:占用空间比增量大
3. 备份避坑:常见问题及解决方案
- 问题1:备份时锁表,导致线上业务卡顿?
- 原因:mysqldump 未加
--single-transaction(InnoDB),或备份MyISAM表(表级锁) - 解决方案:InnoDB用
--single-transaction实现热备份;MyISAM需在业务低峰期备份,或迁移到InnoDB
- 原因:mysqldump 未加
- 问题2:备份文件过大,磁盘占满?
- 解决方案:压缩备份(
mysqldump ... | gzip > backup.sql.gz)、定时清理过期备份、使用对象存储(OSS/S3)存储备份
- 解决方案:压缩备份(
- 问题3:备份成功但恢复失败?
- 原因:备份文件损坏、版本不兼容(如MySQL 5.7备份还原到8.0)、缺少binlog
- 解决方案:备份后校验文件完整性(
md5sum backup.sql)、测试恢复流程、备份时同步备份binlog
- 问题4:备份耗时过长,超出备份窗口?
- 解决方案:换用xtrabackup物理备份、分库分表备份、增量备份替代部分全量备份
二、数据恢复:不同场景下的完整流程
1. 恢复前必做:3个准备工作
- 确认恢复目标:恢复到哪个时间点?(如2025-11-17 10:00)
- 检查备份文件:全量/增量备份是否完整、binlog是否齐全(从全量备份时间点到目标时间点)
- 准备恢复环境:测试环境先验证(避免直接影响线上)、确保磁盘空间充足
2. 场景1:基于全量备份恢复(无增量数据)
- 适用场景:误删表后,且增量数据可忽略(如刚做完全量备份)
- 恢复流程:
-
停止业务写入(可选,避免恢复后数据不一致)
-
还原全量备份:
-
mysqldump 备份还原:
bashmysql -u root -p < full_backup_20251117.sql -
xtrabackup 备份还原(需先准备数据):
bashxtrabackup --user=root --password=xxx --prepare --target-dir=/backup/full_20251117 xtrabackup --copy-back --target-dir=/backup/full_20251117 --datadir=/var/lib/mysql
-
-
启动MySQL,验证数据完整性(如查询关键表行数)
-
3. 场景2:全量+增量备份恢复(数据量较大)
- 适用场景:全量备份后有增量数据,需恢复到最新状态
- 恢复流程(顺序不能乱):
-
准备全量备份(xtrabackup专属步骤):
bashxtrabackup --prepare --apply-log-only --target-dir=/backup/full_20251117 -
合并增量备份(按备份时间顺序,多次增量需依次合并):
bashxtrabackup --prepare --apply-log-only --target-dir=/backup/full_20251117 --incremental-dir=/backup/inc_20251117_1 xtrabackup --prepare --target-dir=/backup/full_20251117 --incremental-dir=/backup/inc_20251117_2 -
还原合并后的全量数据(同场景1的还原步骤)
-
验证数据(如对比业务核心表的最新数据)
-
4. 场景3:基于binlog的时间点恢复(PITR)
- 适用场景:误操作后(如删库、删表),需恢复到误操作前的某个时间点
- 核心前提:已开启binlog,且binlog文件完整
- 恢复流程:
-
找到全量备份的时间点(如2025-11-17 02:00)
-
还原全量备份(同场景1)
-
解析binlog,找到误操作的时间范围:
bash# 查看binlog文件列表 show binary logs; # 解析binlog,找到误操作的pos点或时间 mysqlbinlog --start-datetime="2025-11-17 02:00:00" --stop-datetime="2025-11-17 10:00:00" /var/lib/mysql/mysql-bin.000001 -
回放binlog(从全量备份时间点到误操作前):
bashmysqlbinlog --start-datetime="2025-11-17 02:00:00" --stop-datetime="2025-11-17 09:59:00" /var/lib/mysql/mysql-bin.000001 | mysql -u root -p -
验证数据(如确认误删的表已恢复,且后续数据正常)
-
5. 场景4:基于binlog的单独恢复误删除的数据
- 适用场景:误操作后(如删库、删表)
- 核心前提:已开启binlog,且binlog文件完整;binlog 格式为 ROW;已知目标库名、表名,以及大致误删时间
6. 恢复避坑:常见问题及解决方案
- 问题1:binlog 回放时报错"Duplicate entry"?
- 原因:全量备份已包含该数据,binlog重复回放
- 解决方案:使用
--skip-duplicate-key-error参数跳过重复错误,或精准定位binlog的pos点
- 问题2:xtrabackup 还原后MySQL无法启动?
- 原因:数据目录权限错误(如属主不是mysql)
- 解决方案:
chown -R mysql:mysql /var/lib/mysql,重启MySQL
- 问题3:恢复后数据不一致(如部分表缺失)?
- 原因:备份时遗漏了数据库、或binlog不完整
- 解决方案:备份时用
--all-databases备份所有库,恢复前校验binlog的完整性
三、进阶:备份与恢复的自动化与监控
1. 自动化备份脚本(示例:全量+增量+清理)
bash
#!/bin/bash
DATE=$(date +%Y%m%d)
FULL_BACKUP_DIR=/backup/full
INC_BACKUP_DIR=/backup/inc
MYSQL_USER=root
MYSQL_PASS=xxx
# 周日做全量备份,其余时间做增量备份
if [ $(date +%w) -eq 0 ]; then
# 全量备份
xtrabackup --user=$MYSQL_USER --password=$MYSQL_PASS --backup --target-dir=$FULL_BACKUP_DIR/$DATE
# 清理7天前的全量备份
find $FULL_BACKUP_DIR -mtime +7 -delete
else
# 增量备份(基于最新的全量备份)
LATEST_FULL=$(ls -t $FULL_BACKUP_DIR | head -1)
xtrabackup --user=$MYSQL_USER --password=$MYSQL_PASS --backup --target-dir=$INC_BACKUP_DIR/$DATE --incremental-basedir=$FULL_BACKUP_DIR/$LATEST_FULL
# 清理7天前的增量备份
find $INC_BACKUP_DIR -mtime +7 -delete
fi2. 备份监控:确保备份"可信赖"
- 监控指标:备份是否成功、备份文件大小是否正常、备份耗时是否合理
- 告警方式:脚本执行失败后发送邮件/短信告警(如用mailx、企业微信机器人)
- 定期验证:每周至少1次在测试环境演练恢复流程,确保备份可用
四、备份与恢复的核心原则
- 备份是基础,恢复是目标:备份的价值在于能恢复,必须定期测试
- 组合策略更可靠:全量+增量+binlog 覆盖大部分场景,RPO/RTO更优
- 自动化+监控:减少人工操作失误,及时发现备份问题
- 测试环境先验证:避免直接在生产环境恢复导致二次故障
五、动手实验
mysqldump 全量备份与恢复
- 数据为创建测试环境时的测试数据,直接备份数据
bash
# 忽略系统表,因为系统表一般不允许手动修改
mysqldump -uroot -p -h 127.0.0.1 -P 3306 \
--databases $(mysql -uroot -p -h 127.0.0.1 -P 3306 -NBe "SELECT SCHEMA_NAME FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME NOT IN ('mysql', 'sys', 'information_schema', 'performance_schema')") \
--add-drop-database \
--add-drop-table \
--routines \
--events \
--triggers \
--single-transaction \
--quick \
> full_back_$(date +%Y%m%d).sql- 删除数据
sql
# 查看数据
SELECT * FROM test_db.test_user;
# 删除数据
drop DATABASE test_db;- 恢复数据
bash
# 恢复
mysql -uroot -proot@123456 -h 127.0.0.1 -P 3306 < full_back.sql
# 查看恢复的结果,正常情况下是可以恢复数据的
SELECT * FROM test_db.test_user;xtrabakcup 全量备份+增量备份与恢复
- 备份数据
bash
# 这是全量备份
# user/password: MySQL的账号与密码
# host/port: mysql的访问地址
./bin/xtrabackup --user=root --password=root@123456 --host=127.0.0.1 --port=3306 \
--backup --target-dir=/data/backup/mysql/full_20251218
# 增量备份
# 这是第一个增量备份,以全量备份为基础
./bin/xtrabackup --user=root --password=root@123456 --host=127.0.0.1 --port=3306 \
--backup --target-dir=/data/backup/mysql/incr_20251219 \
--incremental-basedir=/data/backup/mysql/full_20251218
# 这个第二个增量备份,以第一个增量备份为基础
./bin/xtrabackup --user=root --password=root@123456 --host=127.0.0.1 --port=3306 \
--backup --target-dir=/data/backup/mysql/incr_20251220 \
--incremental-basedir=/data/backup/mysql/incr_20251219- 恢复数据
bash
# XtraBackup 是热备工具,备份过程中 MySQL 仍在读写数据,因此直接备份的文件是「不一致」的(比如 InnoDB 数据文件和 redo log 事务未同步),所以在恢复前需要做prepare操作,apply-log-only 是为了将所有的增量备份合并到一起
# --prepare(准备):核心作用是将备份文件恢复到一致性状态,模拟 MySQL 启动时的「崩溃恢复」过程 ------ 应用 redo log(已提交但未刷盘的事务)、回滚 undo log(未提交的事务),最终生成可直接恢复的一致性数据文件。
# --apply-log-only(仅应用日志):是 --prepare 的「增强参数」,只应用 redo log(提交事务),不回滚 undo log(未提交事务),专为增量 / 差异备份合并设计。
# 步骤 1:准备全量备份(--apply-log-only 避免回滚)
xtrabackup --prepare --apply-log-only --target-dir=/data/backup/mysql/base_full_20251218
# 步骤 2:合并第一次增量到全量
xtrabackup --prepare --apply-log-only --target-dir=/data/backup/mysql/base_full_20251218 \
--incremental-dir=/data/backup/mysql/incr_20251219
# 步骤 3:合并最后一次增量(不加 --apply-log-only)
xtrabackup --prepare --target-dir=/data/backup/mysql/base_full_20251218 \
--incremental-dir=/data/backup/mysql/incr_20251220
# 停止MySQL → 清空数据目录 → copy-back → 修复权限 → 启动
systemctl stop mysqld
# 这一步做好备份,防止备份失败导致MySQL无法使用
mv /data/mysql/* /tmp/mysql
xtrabackup --copy-back --target-dir=/data/backup/mysql/base_full_20251218 --datadir=/data/mysql
# 这一步必须要,否则会因为权限问题无法启动
chown -R mysql:mysql /data/mysql
systemctl start mysqld差异备份:就是每次新备份都是以全量备份为基础的增量备份
三、异常环境的模拟与问题处理
shell
# 安装必要的工具
apt install -y percona-toolkit下面做一个实验,演示当出现上述告警时,该如何排查
「高 CPU 使用率 + 低 I/O」错误
sql
-- 创建数据库(如果不存在)
CREATE DATABASE IF NOT EXISTS big_data_db;
USE big_data_db;
-- 创建大数据量表(无索引)
CREATE TABLE IF NOT EXISTS big_data_table (
id INT NOT NULL AUTO_INCREMENT,
user_id INT NOT NULL,
user_name VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
phone VARCHAR(20) NOT NULL,
address VARCHAR(255) NOT NULL,
create_time DATETIME NOT NULL,
update_time DATETIME NOT NULL,
status TINYINT NOT NULL DEFAULT 1,
remark VARCHAR(500),
PRIMARY KEY (id) -- 主键索引默认存在,但我们不添加其他索引
);
-- 插入大量数据(使用存储过程批量生成)
DELIMITER //
CREATE PROCEDURE generate_big_data(IN row_count INT)
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE user_id INT;
DECLARE user_name VARCHAR(50);
DECLARE email VARCHAR(100);
DECLARE phone VARCHAR(20);
DECLARE address VARCHAR(255);
DECLARE create_time DATETIME;
DECLARE update_time DATETIME;
DECLARE status TINYINT;
DECLARE remark VARCHAR(500);
-- 开启事务,提高插入效率
START TRANSACTION;
WHILE i <= row_count DO
-- 生成随机数据
SET user_id = FLOOR(1 + RAND() * 100000);
SET user_name = CONCAT('user_', i);
SET email = CONCAT('user_', i, '@example.com');
SET phone = CONCAT('138', FLOOR(10000000 + RAND() * 90000000));
SET address = CONCAT('address_', i, '_street');
SET create_time = DATE_ADD('2020-01-01', INTERVAL FLOOR(RAND() * 365 * 5) DAY);
SET update_time = create_time;
SET status = FLOOR(0 + RAND() * 2);
SET remark = CONCAT('remark_', i);
-- 插入数据
INSERT INTO big_data_table (
user_id, user_name, email, phone, address, create_time, update_time, status, remark
) VALUES (
user_id, user_name, email, phone, address, create_time, update_time, status, remark
);
SET i = i + 1;
END WHILE;
-- 提交事务
COMMIT;
SELECT CONCAT('成功插入 ', row_count, ' 条数据到 big_data_table 表中');
END //
DELIMITER ;
-- 调用存储过程生成 1000 万条数据(可以根据需要调整数量)
CALL generate_big_data(10000000);
###################
-- 开启查询时间统计
SET profiling = 1;
-- 全表扫描查询(无索引)
SELECT * FROM big_data_table WHERE user_id = 50000;
SELECT * FROM big_data_table WHERE status = 1;
SELECT * FROM big_data_table WHERE create_time BETWEEN '2022-01-01' AND '2023-01-01';
-- 查看查询时间,查询时间都为好几秒是正常的
SHOW PROFILES;模拟高CPU占用率
simulate_high_cpu.sh
执行这个脚本,cpu占用率会明显提升,我的环境中CPU占用率达到了100%
shell
#!/bin/bash
# 模拟100个并发全表扫描查询
THREADS=100
PORT=3306
USER=root
PASSWORD=root@123456
QUERY="SELECT * FROM big_data_db.big_data_table;"
率,全表扫描
while true; do
for ((i=0; i<THREADS; i++)); do
# 后台执行查询,忽略输出(避免刷屏)
mysql -u $USER -P $PORT -p$PASSWORD -N -B -e "$QUERY" --skip-ssl > /dev/null 2>&1 &
echo "启动线程 $i,执行全表扫描..."
done
done
# 等待所有线程结束(可按Ctrl+C终止)
wait开始排查
sql
# 1. 查询当前的连接
# 重点关注:
# - State列:出现「Lock wait」→锁冲突;「Sending data」→全表扫描
# - Time列:时间>60秒→长连接/长查询
# 以TIME列降序
SELECT * FROM information_schema.PROCESSLIST ORDER BY TIME DESC;
# 2. 统计连接状态分布
SELECT
USER,
STATE,
COUNT(*) AS connection_count
FROM
INFORMATION_SCHEMA.PROCESSLIST
GROUP BY
USER,
STATE
ORDER BY
USER,
connection_count DESC;
-- 查看关键线程状态指标
SHOW GLOBAL STATUS LIKE 'Threads_running'; -- 正在运行的线程数
SHOW GLOBAL STATUS LIKE 'Threads_connected'; -- 总连接数
-- 查询全局最大连接数(当前配置值)
SHOW VARIABLES LIKE 'max_connections';这时候会发现有很多执行中的SQL,找出 执行时间长的SQL,一般情况下,就是这个sql导致了CPU占用过高。现在可以通过 kill 347089(sql对应的ID)来强制停止,或者将这个sql记录下来交给 DBA 或者 开发 来配合处理。
| ID | USER | HOST | DB | COMMAND | TIME | STATE | INFO |
|---|---|---|---|---|---|---|---|
| 5 | event_scheduler | localhost | Daemon | 17076 | Waiting on empty queue | ||
| 347089 | root | 172.19.0.1:48636 | Query | 563 | executing | SELECT * FROM big_data_db.big_data_table | |
| 347090 | root | 172.19.0.1:48366 | Query | 562 | executing | SELECT * FROM big_data_db.big_data_table |
一般情况下上面这些操作就能找出哪些SQL在影响MySQL,如果还找不到或者想更全面的分析则需要慢查询日志
sql
-- 查看最近执行的、耗时最长的 SQL 语句
SELECT
EVENT_ID,
SQL_TEXT,
TIMER_WAIT/1000000000 AS EXEC_TIME_SEC,
LOCK_TIME/1000000000 AS LOCK_TIME_SEC,
ROWS_EXAMINED,
ROWS_SENT
FROM performance_schema.events_statements_history
WHERE SQL_TEXT NOT LIKE '%performance_schema%' -- 排除自身查询
ORDER BY TIMER_WAIT DESC
LIMIT 10;
-- 查看慢查询日志文件路径
SHOW VARIABLES LIKE 'slow_query_log_file';
shell
-- 获取 日志文件,并用 percona-tookit 工具进行解析
root@DESKTOP-S5N7E5R:~/mysql/logs# pt-query-digest slow.log
# 180ms user time, 30ms system time, 28.62M rss, 34.00M vsz
# Current date: Thu Nov 13 15:17:45 2025
# Hostname: DESKTOP-S5N7E5R
# Files: slow.log
# Overall: 1.29k total, 24 unique, 0.13 QPS, 39.68x concurrency __________
# Time range: 2025-11-13T04:26:02 to 2025-11-13T07:14:52
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
# Exec time 401994s 339us 969s 311s 720s 283s 314s
# Lock time 9ms 0 2ms 7us 7us 75us 2us
# Rows sent 9.63M 0 9.54M 7.64k 124.25 264.91k 124.25
# Rows examine 7.00G 0 9.54M 5.55M 9.30M 4.58M 9.30M
# Query size 271.71k 28 564 215.51 441.81 185.07 59.77
# Profile
# Rank Query ID Response time Calls R/Call V/M
# ==== ============================= ================== ===== ======== ===
# 1 0xA0C80AB133FF7050BB94772E... 401938.8944 100.0% 747 538.0708 40.45 SELECT big_data_db.big_data_table
# MISC 0xMISC 54.9335 0.0% 544 0.1010 0.0 <23 ITEMS>
# Query 1: 0.11 QPS, 58.54x concurrency, ID 0xA0C80AB133FF7050BB94772E763E7F09 at byte 126421
# This item is included in the report because it matches --limit.
# Scores: V/M = 40.45
# Time range: 2025-11-13T04:29:07 to 2025-11-13T06:23:33
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 57 747
# Exec time 99 401939s 3s 969s 538s 756s 148s 511s
# Lock time 79 7ms 0 2ms 9us 11us 99us 2us
# Rows sent 0 91.79k 0 126 125.83 124.25 4.54 124.25
# Rows examine 99 6.96G 9.54M 9.54M 9.54M 9.54M 0 9.54M
# Query size 16 45.23k 62 63 62.00 59.77 0.11 59.77
# String:
# Databases big_data_d... (440/58%)... 1 more
# Hosts 172.19.0.1
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s #
# 10s+ ################################################################
# Tables
# SHOW TABLE STATUS FROM `big_data_db` LIKE 'big_data_table'\G
# SHOW CREATE TABLE `big_data_db`.`big_data_table`\G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT * FROM big_data_db.big_data_table\G
# 下面是相关的参数配置
innodb_buffer_pool_size:
InnoDB 核心内存缓存大小,指定了 InnoDB 用于缓存表数据、索引、undo 日志等核心数据的内存区域大小,是 InnoDB 性能的 "命脉"
如果设置过小,会导致频繁的磁盘 I/O,但如果设置过大,可能导致内存竞争和 SWAP,间接升高 CPU,也会导致 "缓存命中率" 暴跌。
innodb_flush_log_at_trx_commit:
InnoDB redo 日志刷盘策略,控制 InnoDB 重做日志(redo log)的写入和刷盘时机,直接决定事务的 "持久性"(ACID 中的 D)。
#取值 1(最高安全级):每提交一个事务,必须将 redo log 从内存缓冲(log buffer)写入日志文件,并同步刷到磁盘(调用 fsync());
#取值 2(平衡性能与安全):事务提交时仅写入文件系统缓存,不强制刷盘,依赖操作系统定期同步;
#取值 0(性能优先):每秒批量写入并刷盘一次,与事务提交无关。
sync_binlog:
二进制日志(binlog)刷盘策略,控制 MySQL 二进制日志(记录所有数据修改操作,用于主从复制、数据恢复)的刷盘时机,与 innodb_flush_log_at_trx_commit 合称 "双 1 配置"。
# binlog 先写入内存缓存,sync_binlog 决定缓存何时同步到磁盘;
# 取值 1:每提交一个事务,立即将 binlog 缓存刷到磁盘;
# 取值 N(如 100):积累 N 个事务后批量刷盘;取值 0:由操作系统决定刷盘时机。
1. 与 innodb_flush_log_at_trx_commit = 1 配合,事务提交时需完成 "redo log 刷盘 + binlog 刷盘" 两次磁盘 I/O;
2. 磁盘 I/O 压力翻倍,CPU 需等待两次刷盘完成,进一步加剧 I/O 等待,导致 CPU 资源无法充分利用(或因频繁等待而负载异常)。
max_connections:
限制 MySQL 同时允许的客户端连接总数(包括所有用户的连接,如应用程序、管理工具、后台线程等)。如果连接数过多,线程切换会消耗大量 CPU。模拟「高内存占用」环境
shell
# 执行下面的测试命令,手动模拟高内存占用的环境
mysqlslap -u root -proot@123456 -h localhost --concurrency=1 --iterations=10 --q
uery="SELECT * FROM big_data_db.big_data_table limit 6000000;" --create-schema=big_data_db
# 效果如下
top - 17:07:18 up 1 day, 5:46, 1 user, load average: 0.67, 0.74, 2.79
Tasks: 48 total, 1 running, 47 sleeping, 0 stopped, 0 zombie
%Cpu(s): 48.2 us, 20.8 sy, 0.0 ni, 30.6 id, 0.2 wa, 0.0 hi, 0.2 si, 0.0 st
MiB Mem : 3917.7 total, 413.9 free, 3416.5 used, 87.3 buff/cache
MiB Swap: 1024.0 total, 2.3 free, 1021.7 used. 391.1 avail Mem排查开始
sql
# 1. 先查连接数
## 1.1 连接数
-- Threads_Connected、Threads_Running、最大连接数、连接使用率
SELECT
gs1.VARIABLE_VALUE AS Threads_Connected,
gs2.VARIABLE_VALUE AS Threads_Running,
@@max_connections AS Max_Connections,
ROUND(IF(@@max_connections = 0, 0, gs1.VARIABLE_VALUE / @@max_connections * 100), 2) AS Connection_Usage_Percent
FROM
`performance_schema`.global_status gs1
JOIN `performance_schema`.global_status gs2 ON gs1.VARIABLE_NAME = 'Threads_Connected'
AND gs2.VARIABLE_NAME = 'Threads_Running';
## 1.2 当前连接详情
SELECT * FROM information_schema.PROCESSLIST ORDER BY TIME DESC;
# 2. 查慢查询
## 找到慢查询日志的路径
SHOW VARIABLES LIKE '%slow_query%';
## 使用 percona-toolkit 解析慢查询日志,找到大结果集、无索引排序/分组、多表关联等低效查询,因为这些查询需要用到大量的内存用于存放临时表
pt-query-digest /var/log/mysql/slow.log
# 3. 检查配置
SHOW VARIABLES
WHERE Variable_name LIKE '%buffer%'
OR Variable_name IN ('sort_buffer_size', 'join_buffer_size', 'tmp_table_size');
# 4. 查看临时表
## 4.1 查看临时表的大小限制
SHOW VARIABLES LIKE 'tmp_table_size';
SHOW VARIABLES LIKE 'max_heap_table_size';
# 5. 查看InnoDB 状态:
show engine innodb status;在突然的内存占用高的情况下,一般都是在第 2 步 查慢查询中可以找出原因
bash
root@DESKTOP-S5N7E5R:~# pt-query-digest /var/log/mysql/slow.log
# 130ms user time, 30ms system time, 30.00M rss, 36.99M vsz
# Current date: Fri Nov 21 16:55:23 2025
# Hostname: DESKTOP-S5N7E5R
# Files: /var/log/mysql/slow.log
# Overall: 25 total, 10 unique, 0.00 QPS, 0.06x concurrency ______________
# Time range: 2025-11-20T05:53:43 to 2025-11-21T08:53:37
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
# Exec time 5633s 3ms 919s 225s 918s 316s 63s
# Lock time 409us 1us 66us 16us 44us 16us 12us
# Rows sent 81.33M 105 9.54M 3.25M 6.61M 3.07M 1.39M
# Rows examine 241.45M 1000 19.07M 9.66M 15.90M 4.38M 9.30M
# Query size 1.86k 40 240 76.20 151.03 45.22 59.77
# Profile
# Rank Query ID Response time Calls R/Call V/M
# ==== ============================== =============== ===== ======== =====
# 1 0xE5AF2ACC8DED919BBEC1BB6D1... 5250.5193 93.2% 12 437.5433 26... SELECT big_data_db.big_data_table
# 2 0x869228DB2EBE555AFD83C1716... 283.4257 5.0% 1 283.4257 0.00 SELECT big_data_db.big_data_table
# MISC 0xMISC 98.6356 1.8% 12 8.2196 0.0 <8 ITEMS>
# Query 1: 0.00 QPS, 0.06x concurrency, ID 0xE5AF2ACC8DED919BBEC1BB6D1C2713ED at byte 17759
# This item is included in the report because it matches --limit.
# Scores: V/M = 268.25
# Time range: 2025-11-20T08:02:31 to 2025-11-21T08:47:00
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 48 12
# Exec time 93 5251s 64s 919s 438s 918s 343s 223s
# Lock time 58 239us 1us 66us 19us 36us 16us 17us
# Rows sent 36 29.73M 105 9.54M 2.48M 6.61M 3.06M 1.39M
# Rows examine 59 144.17M 9.54M 19.07M 12.01M 15.90M 3.01M 10.76M
# Query size 39 744 62 62 62 62 0 62
# String:
# Databases big_data_db
# Hosts localhost (11/91%), 172.23.176.1 (1/8%)
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s
# 10s+ ################################################################
# Tables
# SHOW TABLE STATUS FROM `big_data_db` LIKE 'big_data_table'\G
# SHOW CREATE TABLE `big_data_db`.`big_data_table`\G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT * FROM big_data_db.big_data_table ORDER BY user_id DESC\G
# Query 2: 0 QPS, 0x concurrency, ID 0x869228DB2EBE555AFD83C1716D9D0734 at byte 204
06
# This item is included in the report because it matches --limit.
# Scores: V/M = 0.00
# Time range: all events occurred at 2025-11-21T08:51:51
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 4 1
# Exec time 5 283s 283s 283s 283s 283s 0 283s
# Lock time 11 45us 45us 45us 45us 45us 0 45us
# Rows sent 8 6.72M 6.72M 6.72M 6.72M 6.72M 0 6.72M
# Rows examine 2 6.72M 6.72M 6.72M 6.72M 6.72M 0 6.72M
# Query size 2 40 40 40 40 40 0 40
# String:
# Databases big_data_db
# Hosts localhost
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s
# 10s+ ################################################################
# Tables
# SHOW TABLE STATUS FROM `big_data_db` LIKE 'big_data_table'\G
# SHOW CREATE TABLE `big_data_db`.`big_data_table`\G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT * FROM big_data_db.big_data_table\G根据上面的结果可知是 SELECT * FROM big_data_db.big_data_table 与 SELECT * FROM big_data_db.big_data_table ORDER BY user_id DESC 这两个查询导致的,这时查看这个表信息就会发现它没有建立任何的索引,导致每次查询都是全表扫描,然后会将查询的大结果集放到内存中缓存导致内存被大量占用。
总结
MySQL 运维之日常运维篇完结
本篇的主要内容有:
- 测试环境的搭建
- MySQL 数据备份与恢复
- 异常环境的模拟与处理