论文链接:https://arxiv.org/pdf/2402.13243
文章背景
端到端自动驾驶的核心思路是从大规模人类驾驶数据中学习类人驾驶策略,但传统方法存在关键缺陷:
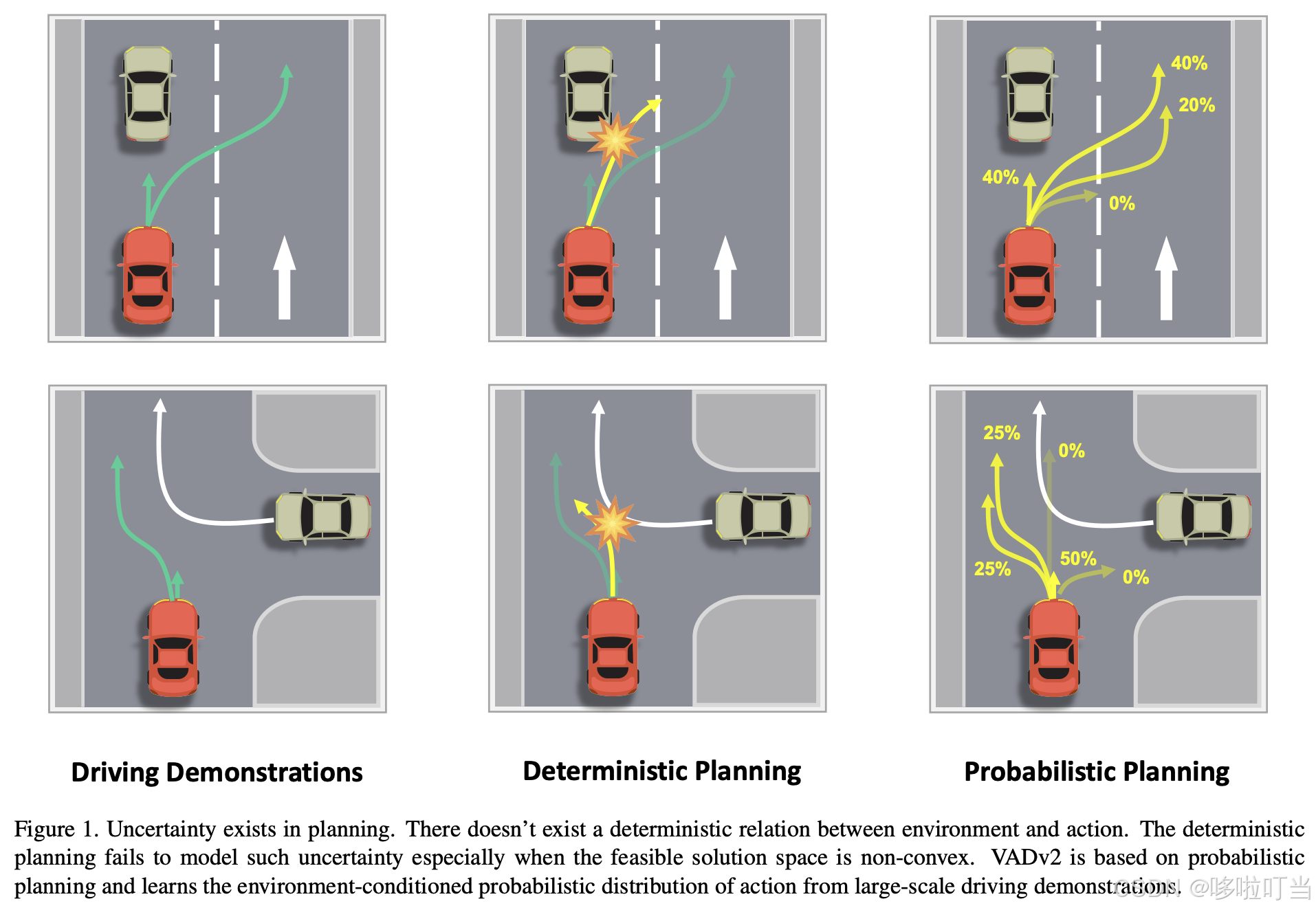
- 驾驶行为的不确定性:同一环境下人类驾驶员可能有多种合理决策(如跟车时可保持车道或超车、会车时可让行或超车),且受大量潜在因素影响,不存在 "环境→动作" 的确定性映射。
- 确定性规划的局限性:现有方法多采用 "直接回归动作" 的确定性范式(如预测单一轨迹或控制信号),无法处理非凸可行解空间(如多选项决策场景),可能输出 "中间态动作" 导致安全风险;且易偏向训练数据中占比最高的动作(如直行、停车),泛化性差。
因此,论文提出概率规划(Probabilistic Planning) 范式,建模动作的概率分布而非单一动作,以应对不确定性。
核心设计
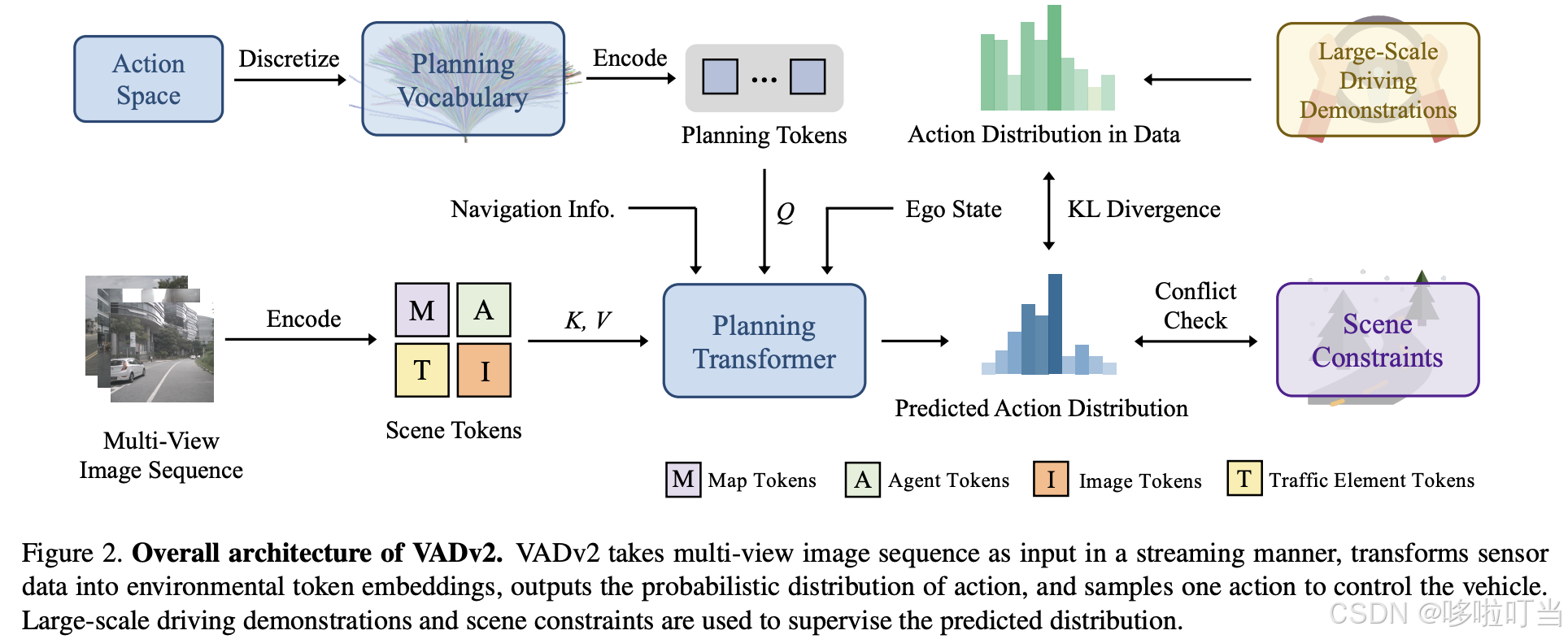
VADv2 的整体框架是 "输入多视角图像序列→编码环境特征→输出动作概率分布→采样动作控制车辆",核心模块包括 3 部分:
1. 场景编码器(Scene Encoder)
将原始传感器数据(多视角图像)转换为高层语义令牌嵌入(Token Embeddings),明确提取环境关键信息,包含 4 类 token:
- Map Token:预测矢量化地图(车道中心线、道路边界、斑马线等);
- Agent Token:预测其他交通参与者的状态(位置、速度、多模态未来轨迹);
- Traffic Element Token:预测交通信号(红绿灯、停车标志)的状态;
- Image Token:保留原始图像的丰富信息,与上述实例级令牌互补。此外,还将导航信息、自车状态通过 MLP 编码为嵌入,共同构成环境特征 Eenv。
2. 概率规划(Probabilistic Planning)
这是论文的核心创新,灵感来自大语言模型(LLM):LLM 通过学习上下文条件下的词汇概率分布生成文本,VADv2 则学习环境条件下的动作概率分布。具体设计:
- 动作空间离散化:驾驶动作是高维连续时空空间(如未来 T 步的位置序列),直接建模不可行。因此,从大规模驾驶数据中提取所有轨迹,通过 "最远轨迹采样" 选择 N 个代表性轨迹作为规划词汇表(Planning Vocabulary)(默认 N=4096),每个词汇自然满足车辆运动学约束(控制信号不超界)。
- 概率场建模:借鉴 NeRF(神经辐射场)的思路,设计概率场函数 ,将连续动作空间映射到概率分布。具体:
- 用位置编码(Positional Encoding)将每个轨迹(动作)编码为高维规划令牌 E(a);
- 通过级联 Transformer 解码器,让规划令牌与环境特征 Eenv、导航嵌入 Enavi、自车状态嵌入 Estate 交互;
- 用 MLP 输出每个动作的概率:p(a)=MLP(Transformer(E(a),Eenv)+Enavi+Estate)。
训练和推理
- 训练损失:采用三重监督确保模型可靠性:
- 分布损失(Distribution Loss):用 KL 散度最小化预测分布与真实驾驶数据分布的差异,对接近真实轨迹的负样本赋予较小惩罚;
- 冲突损失(Conflict Loss):对与其他智能体未来运动、道路边界冲突的动作赋予高惩罚,强化驾驶先验;
- 令牌损失(Token Loss):分别监督地图、智能体、交通元素令牌的预测精度(如 L1 损失回归位置、Focal 损失分类类型)。
- 推理策略:
- 基础策略:采样概率最高的动作,通过 PID 控制器转换为转向、油门、刹车信号;
- 鲁棒策略:采样 Top-K 个高概率动作,结合规则过滤和优化后处理,还可根据动作概率判断是否切换到传统规划模块(PnC)。