1.索引的分类
1.1主键索引
当在一个表中定义一个主键primary key时,MySQL会自动创建索引,索引的值是主键列的值.InnoDB将这种索引视为聚集索引
1.2普通索引
普通索引是专门针对于高频率查询的列而创建的索引,普通索引可以为多列创建组合索引,称为复合索引,且一般要求创建普通索引列的值的重复度不能太高,后面会介绍这一点
1.3唯一索引
当在一个表中定义一个唯一键unique时,MySQL会自动创建一个唯一索引,和普通索引类似,但是唯一索引的列不允许有重复值
1.4全文索引
全文索引是专门针对char,varchar或者text类型的列而创建的索引,为了提高列包含数据的查询效率,需要开发人员手动来创建
1.5聚集索引
聚集索引和主键索引是同一个概念,聚集索引和主键索引都可以标识数据行的唯一性,如果表中没有定义Primary Key主键时,InnoDB会自动使用第一个使用Unique和Not Null的列作为聚集索引
如果表中没有Primary Key主键和合适的Unique索引时,InnoDB会为每一条新插入的数据的行生成一个行号并用一个6字节的ROW_ID来记录,且ROW_ID单调递增,并使用ROW_ID作为索引
1.6非聚集索引
聚集索引以外的索引都称为非聚集索引或者二级索引 ,二级索引创建的索引树(后面介绍)中,叶子节点的记录中包含了对应列的值,且也包含了对应数据的主键值,该主键值会用来进行回表查询
2.索引覆盖和回表查询
2.1索引树
每创建一个索引就会创建一个索引树,而对于非聚集索引创建的索引树来说,索引树的叶子节点中不仅包含了对应索引指向的数据行的主键值
有了索引树之后,查询的流程就会变成:
此时假设创建了索引的列为name,首先MySQL会为name这一列创建一个索引树,索引树的节点会按照name的值进行排序.
此时假设sql为select gender from student where name='zhangsan'
此时,会先根据name的值去索引树中找到name的值为'zhangsan'的叶子节点,该叶子节点包含了'zhangsan'和zhangsan所处的数据行的主键id,由于我们想要查询的是gender的值,因为叶子节点中没有包含gender的值,此时就需要根据叶子节点中的主键值去表中查询,这个过程就是回表查询,但是如果叶子节点中包含了我们想要查询的列的值,此时直接返回叶子节点中对应列的值即可,此时就不要返回到表中查询了,这个过程就是索引覆盖
2.2回表查询
会标查询就是索引树的叶子节点中没有包含我们向要查询的列,需要根据叶子节点中的主键值,返回到对应的表中去查询
2.3索引覆盖
索引覆盖就是索引树的叶子节点就已经包含我们想要查询列的值了,此时就不要根据叶子节点中的主键值返回到表中查询
3.索引的使用
3.1修改表结构---Alter
语法:alter table 表明 add \| modify \| drop 要修改的内容
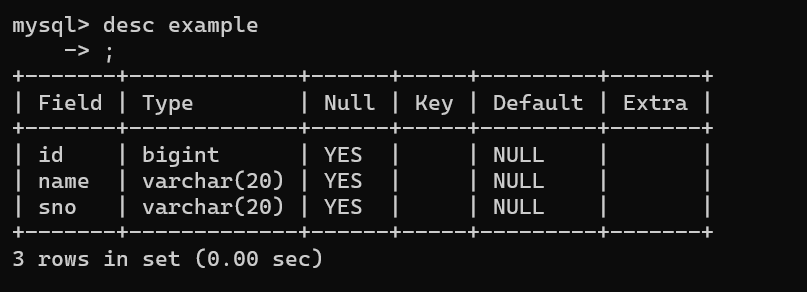
已创建下面这个表为例字:
sql
CREATE TABLE example(
id bigint,
name varchar(20),
sno varchar(20)
);1.add
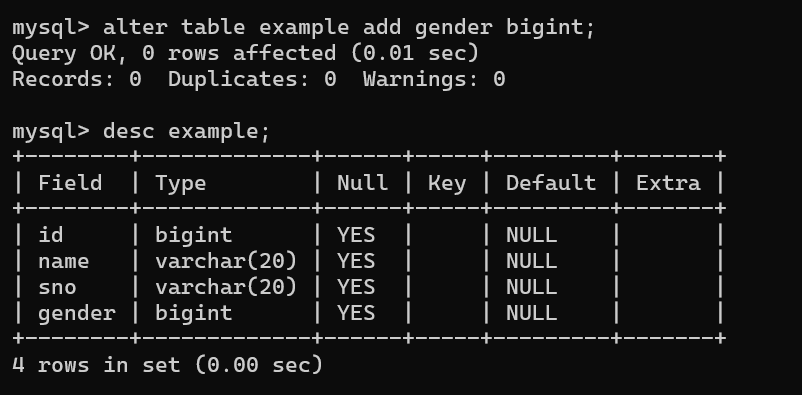
1.为examp添加一个类型为bigint,名称为gender的列
sql
alter table example add gender bigint;增加之前:
增加之后:
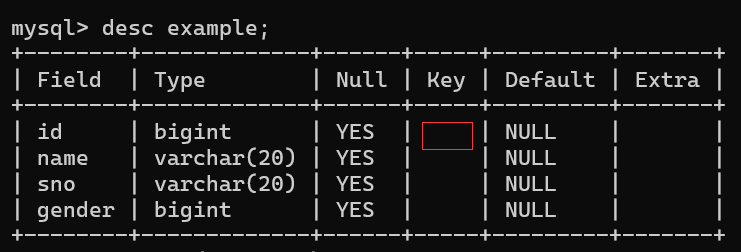
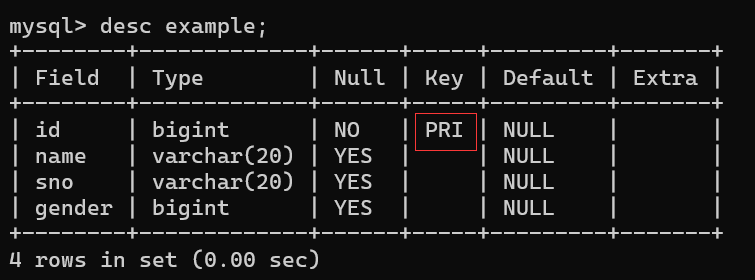
2.为example表中的id添加一个索引
sql
alter table example add primary key(id);添加前:
添加后:
2.modify
modify是用来修改列的属性的,例如修改列的数据类型,修改列的约束属性(null改为not null)等等,不能用来将一个列添加约束,例如不能添加primary key,unique key,foreign key
使用modify的注意事项:modify后面要写出完整列的定义,如下面的例子
将example表中的gender改为可以为not null
一开始可能会这样写,
sql
alter table example modify gender not null;但是这样会报错,因为没有modify后面没有将gender的类型写出来,没有写出完整列的定义
正确写法:
sql
alter table example modify gender bigint not null;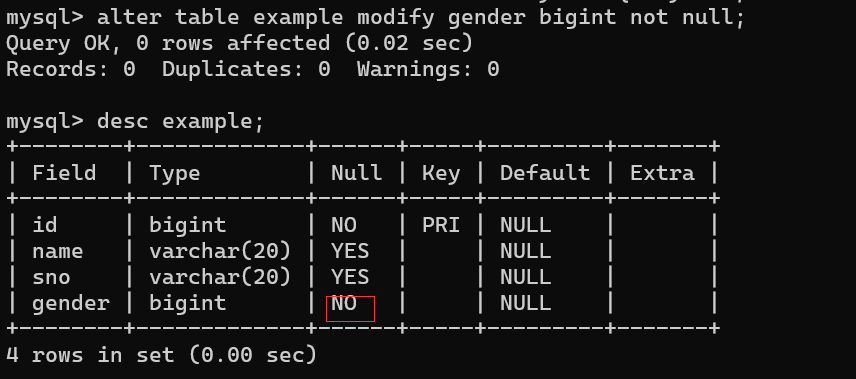
3.drop
删除example中的gender列
sql
alter table example drop gender;
4.索引的创建
查看表中的所有索引信息
show index from 表明

4.1创建主键索引
1.创建表示指定主键
sql
CREATE TABLE t_pk1(
id BIGINT PRIMARY KEY,
name VARCHAR(50)
);
2.创建表时,单独指定主键列
sql
CREATE TABLE t_pk2(
id BIGINT auto_increment,
name VARCHAR(50),
PRIMARY key(id)
);
3.通过alter add的方式为对应的列添加主键索引
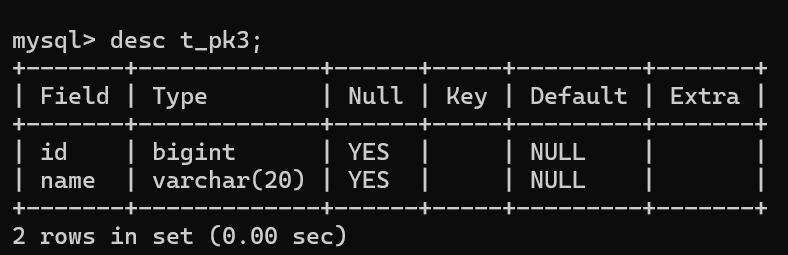
先创建一个表
sql
CREATE TABLE t_pk3(
id bigint,
name VARCHAR(20)
);添加索引前:
添加主键索引:
sql
ALTER TABLE t_pk3 add PRIMARY KEY(id);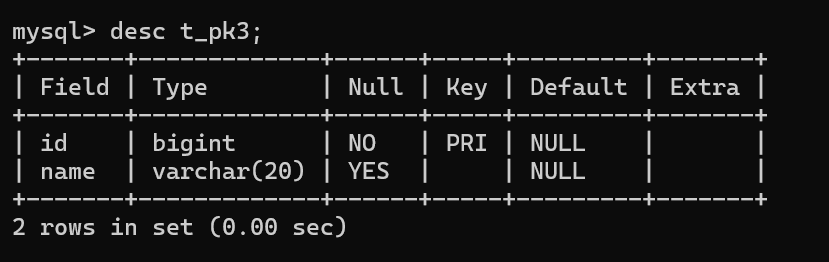

4.2创建唯一索引
1.在创建表时,指定唯一键
sql
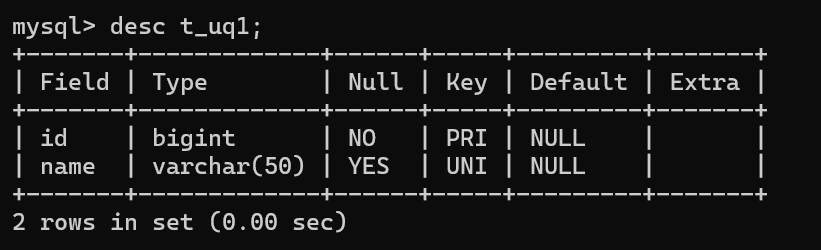
CREATE TABLE t_uq1(
id BIGINT PRIMARY KEY,
name VARCHAR(50) UNIQUE
);

2.在创建表时,单独指定唯一键
sql
CREATE TABLE t_uq2(
id BIGINT PRIMARY KEY,
name VARCHAR(50),
UNIQUE(name)
);
3.通过alter add的方式创建唯一索引
sql
CREATE TABLE t_uq3(
id BIGINT PRIMARY KEY,
name VARCHAR(50)
);
ALTER TABLE t_uq3 ADD UNIQUE(NAME); 
4.3创建普通索引
1.创建表示创建普通索引---index关键字
sql
CREATE TABLE t_index1(
id bigint PRIMARY KEY auto_increment,
name varchar(20) UNIQUE,
sno varchar(20),
INDEX(sno)
);
2.修改表中的列为普通索引
sql
CREATE TABLE t_index2(
id bigint PRIMARY KEY auto_increment,
name varchar(20) UNIQUE,
sno varchar(20)
);
-- 为对应的列添加索引
ALTER TABLE t_index2 ADD INDEX(sno);
3.手动创建索引
create index 索引名 on 索引名(列名)
索引名格式推荐:idx_表明_列名
sql
CREATE TABLE t_index3(
id bigint PRIMARY KEY auto_increment,
name varchar(20) UNIQUE,
sno varchar(20)
);
CREATE INDEX t_index3_sno ON t_index3(sno);
4.4创建复合索引
1.在创建表时指定复合索引的列
sql
create table t_index_4 (
id bigint PRIMARY key auto_increment,
name varchar(20),
sno varchar(20),
class_id bigint,
index (sno, name)
);
2.修改表中的列为复合索引
sql
create table t_index_5 (
id bigint PRIMARY key auto_increment,
name varchar(20),
sno varchar(20),
class_id bigint
);
ALTER TABLE t_index_5 ADD INDEX(sno,name);
3.手动创建复合索引
create index索引名 on 表明(列名,列名.....)
sql
create table t_index_6 (
id bigint PRIMARY key auto_increment,
name varchar(20),
sno varchar(20),
class_id bigint
);
CREATE INDEX idx_t_index_6_sno_name ON t_index_6(sno,name);
5.删除索引
5.1删除主键索引
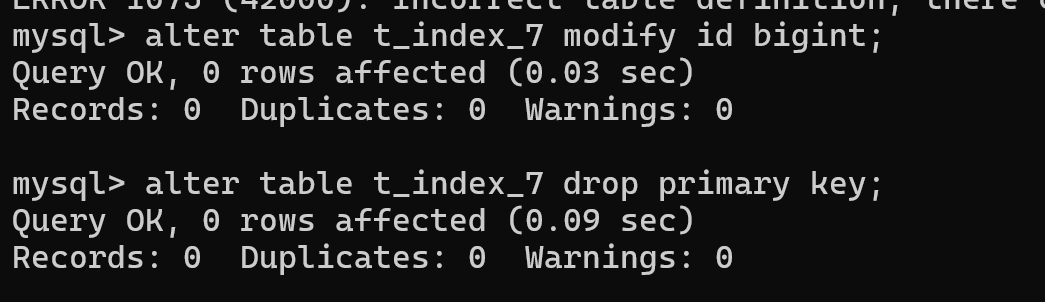
如果主键索引对应的列是auto_increment,首先要将该列修改为不是auto_increment
先创建一张表
sql
create table t_index_4 (
id bigint PRIMARY key auto_increment,
name varchar(20),
sno varchar(20),
class_id bigint,
index (sno, name)
);主键索引的列属性有auto_increment,此时如果直接删除主键索引的花会报错

要将主键索引列的auto_increment属性删掉,才可以删除主键索引

5.2删除其他索引
alter table 表明 drop index 索引名
先创建一张表
sql
create table t_index_8 (
name varchar(20),
sno varchar(20),
class_id bigint,
index (sno, name)
);
删除表中的复合索引
sql
alter table t_index_8 drop index sno;
6.查看执行计划---explain
假如我们已经创建好了索引,如何判断我们写的sql语句是否成功走索引了呢?此时就可以通过explain关键字来查询sql的执行计划
explain sql语句
1.不加条件,查询所有数据
sql
explain select * from t_index_8;

2.使用主键索引查询

3.子查询中使用索引

4.使用复合索引
在使用复合索引时,要遵循最左前缀原则,否则索引会失效,为什么下面的sql语句中还是会走索引呢,这是MySQL每部做的优化

但是如果在使用复合索引时,出现了索引覆盖,此时走索引就和顺序没关系了
