你在 ArcGIS Pro 里做空间统计时,**"分析模式(Analyzing Patterns)"**往往回答的是"有没有聚集(是/否)";而 "聚类分布制图(Mapping Clusters)"更进一步:把聚类的位置、范围、类型、显著性 直接画出来------更适合写论文、做汇报、做治理决策。(ArcGIS Pro)
0. 工具集在哪里?
ArcGIS Pro 路径通常是:
Geoprocessing(地理处理)窗格 → 搜索工具名
或按工具箱层级:Spatial Statistics toolbox → Mapping Clusters toolset (空间统计 → 聚类分布制图)。(ArcGIS Pro)
1. 上手前的 3 个"必做准备"(不做很容易跑出一堆"不显著/乱跳")
- 统一投影坐标系 :涉及距离阈值的工具(Gi*、DBSCAN 等),尽量用米为单位的投影坐标系。
- 确认对象类型 :你输入的是 **点(事件/POI)**还是 面(区县/网格/街区)?不同工具最适配的场景不一样。
- 想清楚"你在聚什么":
- 聚"点是否扎堆" → DBSCAN(基于密度)(ArcGIS Pro)
- 聚"高值/低值是否抱团" → Gi* 热点(ArcGIS Pro)
- 聚"异常值"(周边都低它却高) → Local Moran's I (ArcGIS Pro)
- 按多指标"分类型" → 多元聚类 / 空间约束多元聚类(ArcGIS Pro)
- 把多个指标合成一个"指数" → 复合指数(ArcGIS Pro)
2. 12 个工具逐个讲:每个一个案例 + 操作步骤
下面每个工具都按这个结构写:它解决什么问题 → 一个常见案例 → ArcGIS Pro 怎么点 → 参数怎么选 → 结果怎么看
2.1 构建平衡区域(Build Balanced Zones / Build Balanced Regions)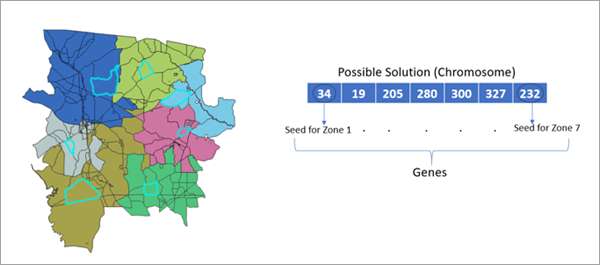
用来干什么 :把许多小单元自动合并成若干个空间连续 的"区域/片区",并让片区在某些指标上尽量均衡 (比如人口、需求量、业务量)。工具内部用"遗传增长算法"做优化。(ArcGIS Pro)
案例 :把社区(面要素)划分成 10 个消防服务片区,希望每个片区的"历史火警次数总和"尽量接近,且片区要连片,便于配置站点巡逻。
怎么做(操作)
- 打开:Geoprocessing → 搜索 Build Balanced Zones
Input Features:社区/网格面Zone Creation Method:选"固定分成 N 个区域(Target Number of Zones)"或"区域数 + 属性目标"(按你是否要严格控制区域数)Target Number of Zones:例如 10Zone Building Criteria:选择平衡字段(如火警次数、人口、需求量),可设置权重Spatial Constraints:一般保持"Contiguity(连片)"- 运行
结果怎么看
- 输出会带
Zone ID类字段,同一编号就是同一服务片区 - 建议:对每个 Zone 做汇总统计(sum/mean)检查是否"均衡"
实操小技巧:很多业务要把"片区编号"变成真正的片区面,可再配合 **Dissolve(溶解)**按 Zone ID 融合成更干净的片区边界(文首配图里也能看到类似流程界面)。
2.2 计算复合指数(Calculate Composite Index)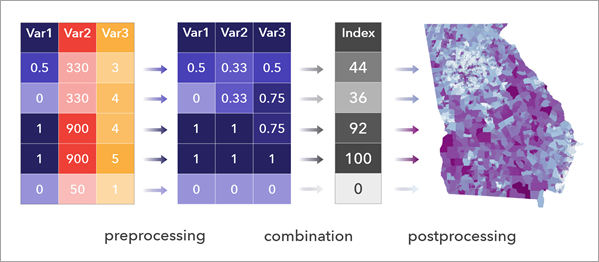
用来干什么 :把多个指标(不同量纲)按流程标准化 → 合成 → 再分类 ,生成一个"综合指数",并自动给出分布图表辅助解释。(ArcGIS Pro)
案例:做"城市热风险指数",用:地表温度、绿地率(反向)、不透水面比例、人口密度等合成一个指数。
怎么做(操作)
- 搜索 Calculate Composite Index
Input Table:区县/街道面(带多个字段)Input Variables:勾选参与合成的字段Reverse Direction:对"越大越好"的保护性变量(如绿地率)做反向(确保所有变量方向一致)(ArcGIS Pro)Method to Scale Input Variables:选择 Min-Max 或 Z-scoreMethod to Combine Scaled Variables:等权平均/加权平均(按需求选)- 运行
结果怎么看
- 输出通常是一个组图层:指数图层 + 分类图层 + 一些图表(直方图、箱线图、相关散点矩阵等),便于你解释"指数分布是否偏态、有无离群点、哪些变量贡献更大"。(ArcGIS Pro)
2.3 聚类和异常值分析(Anselin Local Moran's I)
用来干什么 :识别局部聚类(HH/LL)和空间异常值(HL/LH) 。(ArcGIS Pro)
- HH:高值周边也高(高-高聚类)
- LL:低值周边也低(低-低聚类)
- HL:自己高、周边低(高值"孤岛")
- LH:自己低、周边高(低值"洼地")
案例:用街道尺度的"房租均价"找:哪些地方是"高租金抱团",哪些街道是"高租金孤岛"(可能是核心商圈的小范围尖峰)。
怎么做(操作)
- 搜索 Cluster and Outlier Analysis (Anselin Local Moran's I)
Input Features:街道/网格面Input Field:房租均价Conceptualization of Spatial Relationships:面数据常用 Contiguity(邻接) 或 Fixed Distance(固定距离)- 如用固定距离:设置
Distance Band(别太小,否则邻居不足;别太大,否则局部差异被抹平) - 运行
结果怎么看
- 输出字段里会给出聚类类型与显著性(p 值、z 值等),你直接按类型符号化就能出图。(ArcGIS Pro)
2.4 基于密度的聚类(Density-based Clustering)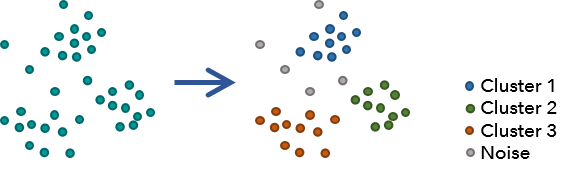
用来干什么 :对点数据 做 DBSCAN/OPTICS 等密度聚类,输出"哪些点属于同一团、哪些是噪点",并可选叠加时间维度做时空聚类。(ArcGIS Pro)
案例:用"外卖取餐点/订单点"找夜间订单聚集区,识别夜经济活跃带。
怎么做(操作)
- 搜索 Density-based Clustering
Input Point Features:订单点Clustering Method:选择 DBSCAN(常用)或 OPTICS(对不同密度更友好)(ArcGIS Pro)Search Distance:你认定"多近算一团"(如 300m/500m)Minimum Features:你认定"多少点才算聚集"(如 20/50)- (可选)时间字段:设置时间窗口,做空间-时间聚类(Esri)
- 运行
结果怎么看
-
输出会标记 Cluster ID 与 Noise(噪点),你可以:
- 用 Cluster ID 分类型配色出"团块"
- 噪点单独标注,常用于发现"零散需求/异常点"
2.5 热点分析(Getis-Ord Gi*)
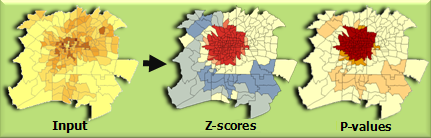
用来干什么 :识别统计显著的热点(高值聚集)与冷点(低值聚集) 。(ArcGIS Pro)
案例:交通事故分析:以网格为单元,字段是"事故次数(或严重度加权)",找事故热点走廊。
怎么做(操作)
- 搜索 *Hot Spot Analysis (Getis-Ord Gi)**
Input Features:网格面(或路口点)Analysis Field:事故次数/严重度Conceptualization of Spatial Relationships:固定距离 / K近邻 / 邻接(按数据选择)- 若用固定距离:填
Distance Band - 运行
结果怎么看
- 输出会按 90/95/99% 显著性分类热点/冷点(常见是 Gi_Bin 字段),直接符号化即可。(ArcGIS Pro)
2.6 热点分析对比(Hot Spot Analysis Comparison)
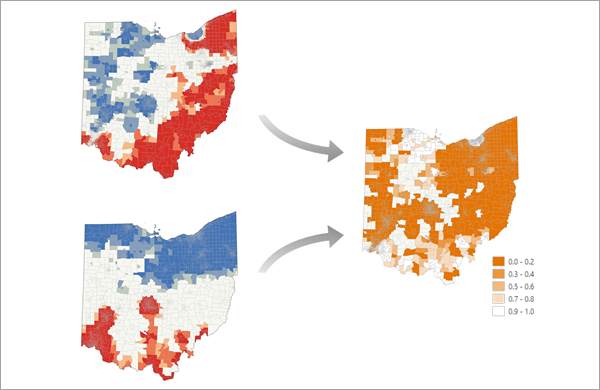
用来干什么 :比较两期(或两套)热点结果,量化它们的相似度(similarity)与关联度(kappa/association) ,并可映射出"哪里差异最大"。(ArcGIS Pro)
案例:对比 2019 vs 2024 的"盗窃案件热点网格",看热点是否迁移到新城。
怎么做(操作)
前提:你已经分别得到两张热点结果图层(Gi* 或优化热点)。
- 搜索 Hot Spot Analysis Comparison
Input Hot Spot Result Layer 1:2019 结果Input Hot Spot Result Layer 2:2024 结果- 运行
结果怎么看
- 工具会输出全局 similarity / kappa 等指标,并给每个空间单元的局部对比结果,可直接做"热点变化地图"。(ArcGIS Pro)
写作提示:
- 相似高:两期热点空间位置很像
- **关联(kappa)**高:不仅像,而且两期热点变量在统计关系上更"同步"(ArcGIS Pro)
2.7 多元聚类(Multivariate Clustering)
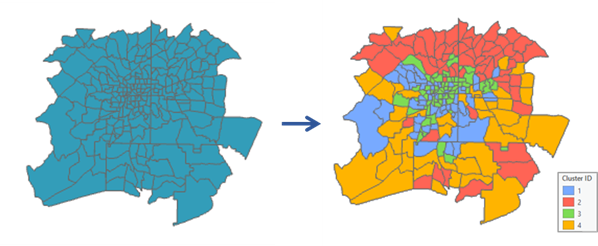
用来干什么 :只按属性把要素分成若干"自然类型"(不强制空间连片)。ArcGIS Pro 会输出 CLUSTER_ID 等字段并提供解释辅助。(ArcGIS Pro)
案例:把区县按"夜间灯光强度、人口密度、第三产业占比、道路密度"分成 5 类,得到"城市化/功能结构类型"。
怎么做(操作)
- 搜索 Multivariate Clustering
Input Features:区县面(或点/线也可以)(ArcGIS Pro)Analysis Fields:选择多个变量字段Number of Clusters:先试 4--8(常用)- 运行
结果怎么看
-
输出字段
CLUSTER_ID表示类别编号,你需要做的是:- 对每个类别做均值/箱线图
- 给类别起"可解释"的名字(如"高密高灯光---核心城区型")
2.8 优化的热点分析(Optimized Hot Spot Analysis)
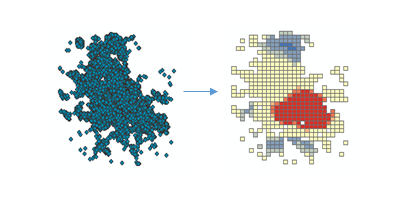
用来干什么 :你不确定距离阈值/尺度、或者输入是事件点时,用它"一键优化":自动聚合事件、自动选尺度,并处理多重检验与空间依赖等,让结果更稳。(ArcGIS Pro)
案例:用"火灾出警点"自动识别火灾热点区(不手动纠结距离阈值)。
怎么做(操作)
- 搜索 Optimized Hot Spot Analysis
Input Features:火灾点(或带权重点/面)- (可选)设置
Incident Data/聚合方式、研究区边界(避免把大片空白纳入) - 运行
结果怎么看
- 输出热点/冷点等级;同时会在运行消息里报告它自动选择的关键参数,便于你复现实验或写方法。(ArcGIS Pro)
2.9 优化的异常值分析(Optimized Outlier Analysis)
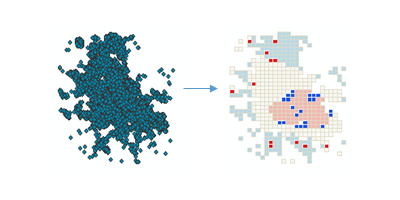
用来干什么 :相当于"自动挡"的 Local Moran's I:自动处理聚合、尺度选择等,输出热点/冷点/异常值,减少手动设参导致的不稳定。(ArcGIS Pro)
案例:用城市面数据的 AQI 找"污染异常城市"(周边都好它却很差:LH)。
怎么做(操作)
- 搜索 Optimized Outlier Analysis
Input Features:城市面/点Analysis Field:AQI- 运行
结果怎么看
- 输出 HH/LL/HL/LH + 显著性;并在消息里解释其自动选择的参数。(ArcGIS Pro)
2.10 相似搜索(Similarity Search)
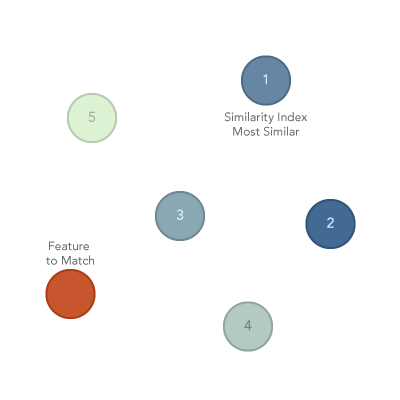
用来干什么 :给定一个或多个"样板",在候选要素中找"最相似/最不相似"的对象,常用于找对标地区、找可复制样板。(ArcGIS Pro)
案例:选一个"创新型高新区"作为样板,按"研发强度、企业密度、专利数、人才净流入"找全国最相似的 20 个园区。
怎么做(操作)
- 搜索 Similarity Search
Input Candidate Features:所有园区Input Query Features:样板园区(可多个)Match Fields:选择用于相似度计算的字段- 选择输出"Most Similar / Least Similar",并设置 Top N
- 运行
结果怎么看
-
输出会带相似度排序字段,你可以:
- Top 20 做地图
- 把"最不相似"作为反例对照
2.11 空间异常值检测(Spatial Outlier Detection)
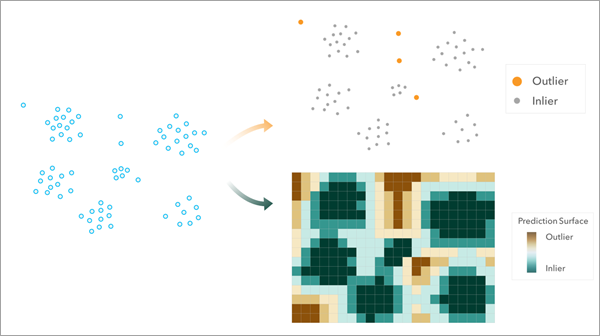
用来干什么 :专门识别点数据的全局/局部空间异常值 ,并可用 LOF(Local Outlier Factor)生成栅格表面辅助解释;工具也会帮助优化关键参数选择。(ArcGIS Pro)
案例:检测"共享单车故障报修点"异常:哪些点位报修次数异常高(可能是运维盲区或人为破坏高发点)。
怎么做(操作)
- 搜索 Spatial Outlier Detection
Input Point Features:报修点- 设置邻域/近邻数、异常比例等(工具支持优化建议)(ArcGIS Pro)
- (可选)输出 LOF 栅格表面(更直观展示异常强度连续面)(ArcGIS Pro)
- 运行
结果怎么看
- 输出会把点分为 outlier / inlier,并可用 LOF 强度做等级图,适合做"巡检优先级清单"。
2.12 空间约束多元聚类(Spatially Constrained Multivariate Clustering)
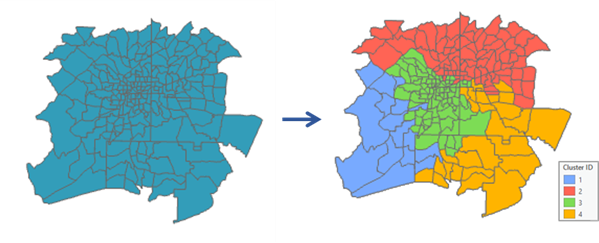
用来干什么 :按多个指标聚类,但强制聚类结果空间连片 ,常用于分区治理、规划分区。该工具基于 SKATER 算法。(ArcGIS Pro)
案例:城市更新分区:用"建筑年代、道路密度、人口密度、商业活跃度"把街区分为 6 类更新片区,并要求每类连片,便于政策落地。
怎么做(操作)
- 搜索 Spatially Constrained Multivariate Clustering
Input Features:街区/网格面Analysis Fields:选择多个指标字段Number of Clusters:例如 6(也可让工具评估最优数量)(ArcGIS Pro)- 设置空间约束(邻接关系)与可选的最小聚类规模,避免碎斑
- 运行
结果怎么看
- 输出类别编号 + 连片的类型区,并常配套图表(箱线图/特征数等)帮助解释"每一类到底有什么特征"。(ArcGIS Pro)
3. 一句话选工具
- 点堆在哪里 :基于密度的聚类(DBSCAN/OPTICS)(ArcGIS Pro)
- 高值/低值抱团在哪里 :热点分析 Gi* (ArcGIS Pro)
- 哪里是"异常值"(反常点) :Local Moran's I / 优化异常值(ArcGIS Pro)
- 两期热点是否迁移 :热点分析对比(ArcGIS Pro)
- 按多指标分类型(不要求连片) :多元聚类(ArcGIS Pro)
- 按多指标分类型(必须连片) :空间约束多元聚类(ArcGIS Pro)
- 多个指标揉成一个综合指标 :复合索引(ArcGIS Pro)
- 划服务片区、划均衡管理区 :构建平衡区域(ArcGIS Pro)
- 找"最像/最不像"的对标对象 :相似搜索(ArcGIS Pro)
- 专门抓点异常 + LOF 强度面 :空间异常值检测(ArcGIS Pro)
4. 3 个常见坑
- 尺度敏感 :距离阈值一改,热点范围就可能变;不确定就优先用"优化热点/优化异常值"先跑出可靠尺度。(ArcGIS Pro)
- 边界效应:研究区边缘邻居少,显著性更难出;可扩大研究范围或在文中解释。
- 聚类 ≠ 因果:热点/异常值只是"空间格局",原因要结合机制变量、回归/机器学习/案例进一步解释(这句话能帮你避免评论区杠精)。
参考(官方文档,建议你在 CSDN 文末挂上)
- Mapping Clusters 工具集概述(ArcGIS Pro)
- Build Balanced Zones(ArcGIS Pro)
- Calculate Composite Index(ArcGIS Pro)
- Cluster and Outlier Analysis (Anselin Local Moran's I)(ArcGIS Pro)
- Density-based Clustering(ArcGIS Pro)
- Hot Spot Analysis (Getis-Ord Gi*)(ArcGIS Pro)
- Optimized Hot Spot Analysis(ArcGIS Pro)
- Optimized Outlier Analysis(ArcGIS Pro)
- Hot Spot Analysis Comparison(ArcGIS Pro)
- Multivariate Clustering(ArcGIS Pro)
- Spatially Constrained Multivariate Clustering(ArcGIS Pro)
- Spatial Outlier Detection(ArcGIS Pro)