1.0 工作流概述
此工作流的核心战略价值在于,将耗时且重复的新闻搜集与整理工作完全自动化。通过自动从指定信息源获取最新动态,利用人工智能进行筛选、抓取、总结,并最终以结构化的简报形式分发给团队,该系统极大地节省了人力成本,确保了信息传递的时效性,并提供了可高度定制化的情报服务。
核心功能
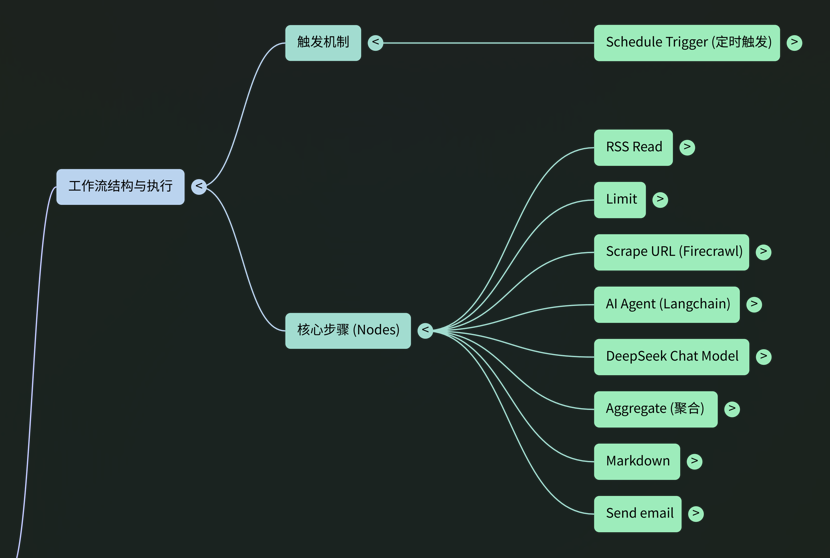
本工作流整合了多个功能模块,实现了一个完整的数据处理与分发管道:
- 定时触发 (Scheduled Trigger): 以预设的固定周期(每4小时)自动启动整个工作流,无需人工干预。
- 信息获取 (Data Ingestion): 从指定的 RSS 源(Hacker News)拉取最新的新闻条目列表。
- 内容筛选 (Content Filtering): 设定处理上限,仅保留最新的若干篇文章,以控制处理成本和提高执行效率。
- 深度抓取 (Web Scraping): 访问每篇筛选后文章的原始链接,利用 Firecrawl 服务提取完整的网页正文内容。
- AI 摘要生成 (AI Summarization): 将抓取到的非结构化文本输入给大型语言模型(DeepSeek),根据预设指令将其提炼成一份结构清晰、重点突出的新闻简报。
- 结果聚合 (Result Aggregation): 将多篇独立生成的简报内容合并为一个统一的数据集,为后续的格式化处理做准备。
- 格式转换 (Format Conversion): 将聚合后的文本内容从 Markdown 格式转换为 HTML,以确保在电子邮件客户端中获得最佳的渲染效果。
- 邮件分发 (Email Delivery): 通过 SMTP 服务,将最终生成的 HTML 格式新闻简报发送给指定的收件人列表。
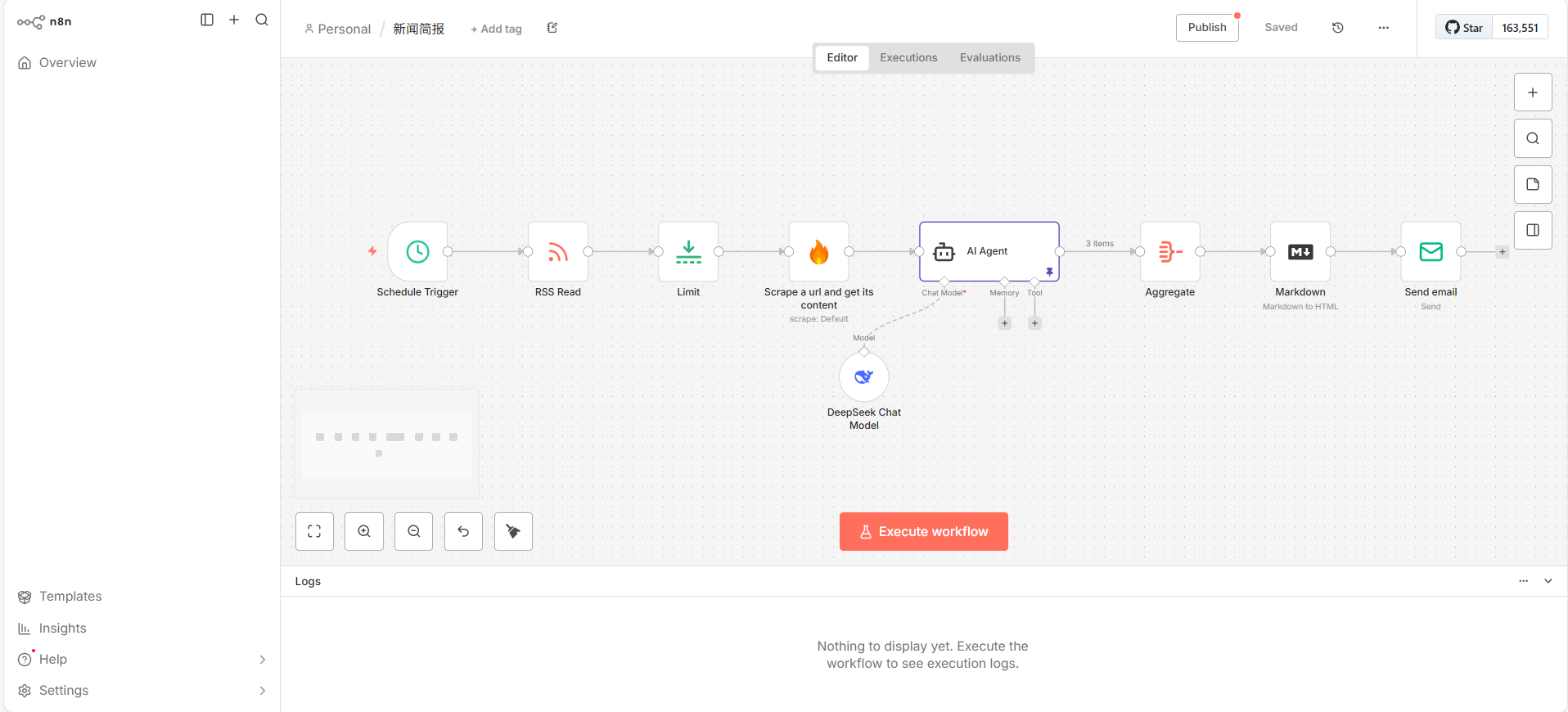
系统架构流程
工作流中的数据处理遵循一个清晰的线性逻辑。各个节点按以下顺序依次执行,每一步都为下一步的操作准备必要的数据和前提条件:
- Schedule Trigger**(调度触发器):** 流程起点,确保无人值守的周期性自动化执行。
- RSS Read**(RSS 读取):** 获取原始数据输入,为整个流程提供最新的新闻源。
- Limit**(数量限制):** 控制 API 成本和处理时间,在启动资源密集型的抓取和 AI 操作前进行前置筛选。
- Scrape a url and get its content**(网页内容抓取):** 从链接提取全文,为 AI 摘要提供丰富、完整的上下文信息。
- AI Agent**(AI 代理):** 核心价值创造环节,将非结构化的原始文本转化为精炼、结构化的情报。
- Aggregate**(结果聚合):** 将多次循环处理的独立结果合并,为生成单一、完整的报告做准备。
- Markdown**(格式转换):** 确保最终输出内容在邮件客户端中具有良好的可读性和专业排版。
- Send email**(邮件发送):** 工作流的终点,将处理完成的情报可靠地交付给最终用户。
2.0 工作流执行逻辑与数据流
触发器和数据流是自动化工作流的"心跳"和"血脉"。本章节将详细剖析工作流是如何被周期性启动的,以及数据如何在各个处理节点之间被依次传递、转换和丰富的。
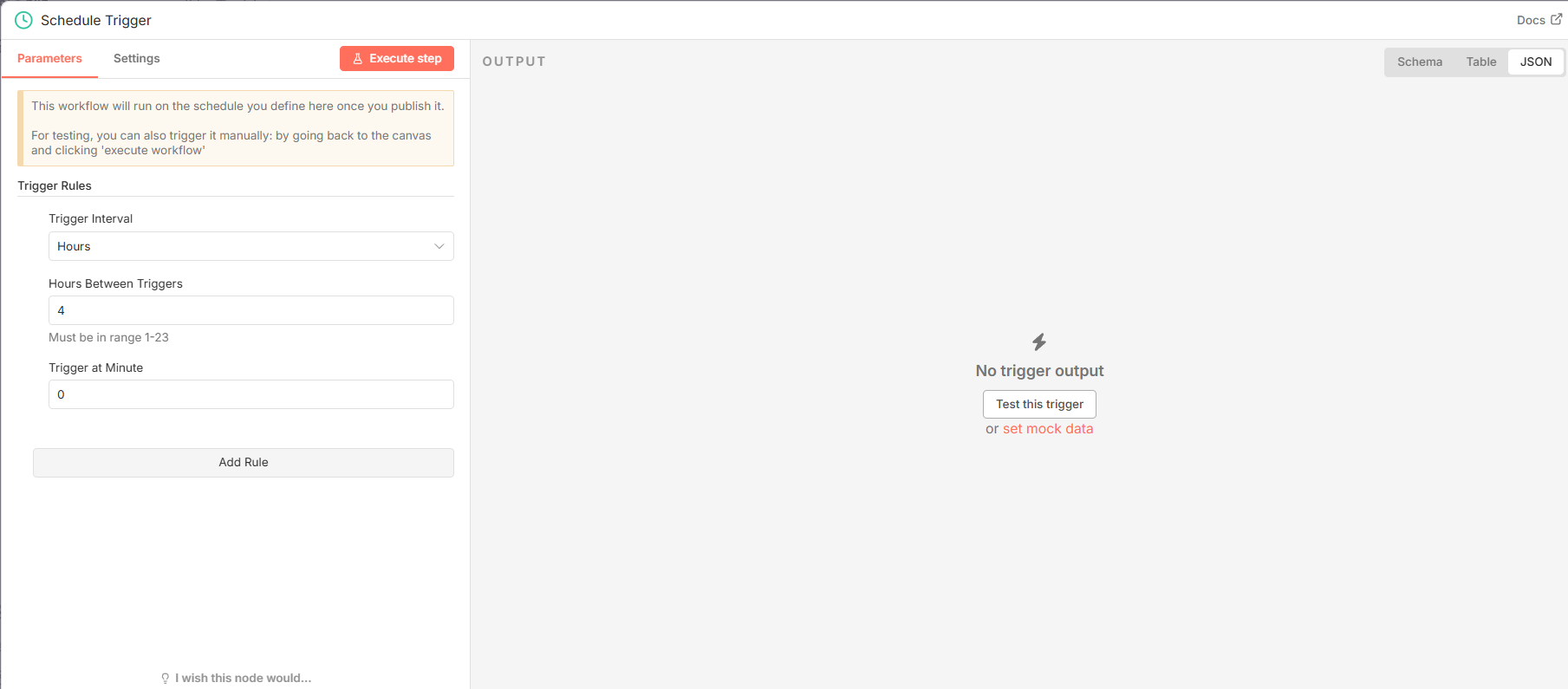
2.1 调度触发器 (Schedule Trigger)
该节点 (n8n-nodes-base.scheduleTrigger) 是整个工作流的起点,它不依赖任何外部输入,而是根据内部设定的时间规则自动激活流程。
|-------------------------------|---------|-----------------|
| 参数 | 值 | 说明 |
| rule.interval.field | hours | 设定时间间隔的单位为"小时"。 |
| rule.interval.hoursInterval | 4 | 设定具体的时间间隔数值。 |
根据以上配置,工作流的执行频率为每4小时自动触发一次。
2.2 数据处理管道
数据流从 Schedule Trigger 启动后,按以下路径进行处理:
- RSS Read 节点从指定 URL 获取最新的新闻文章列表,并将这个包含多篇文章(标题、链接等信息)的数组作为输出。
- 该文章数组被传递给 Limit 节点,该节点根据
maxItems参数筛选出最新的3篇文章,并将这个规模更小的数组传递下去。 Limit节点输出一个包含3个文章对象的数组。n8n 随后会遍历此数组,将每个独立的对象 依次传递给 Scrape a url and get its content 节点进行处理。Scrape节点针对每篇文章的链接 (link),抓取其完整的网页正文内容。抓取到的正文文本 (data) 随后被送入 AI Agent 节点。- AI Agent 节点调用 DeepSeek Chat Model,将文本内容根据预设的系统指令(Prompt)生成结构化的新闻简报。
- 由于步骤3至5对3篇文章进行了循环处理,会产生3份独立的简报。这些简报被传递给 Aggregate 节点。
- Aggregate 节点将所有独立的简报输出 (
output) 收集并合并成一个单一的文本数组。 - 该数组被传递给 Markdown 节点,该节点将数组内的所有文本用换行符连接,并整体转换为 HTML 格式。
- 最终,Send email 节点接收到格式化后的 HTML 内容,并将其作为邮件正文发送给预设的收件人,完成整个流程。
3.0 核心处理节点详解
本章节是技术规范的核心部分,我们将逐一解构工作流中的每个关键处理节点,详细分析其具体功能、关键配置参数以及在整个数据处理链中的作用。
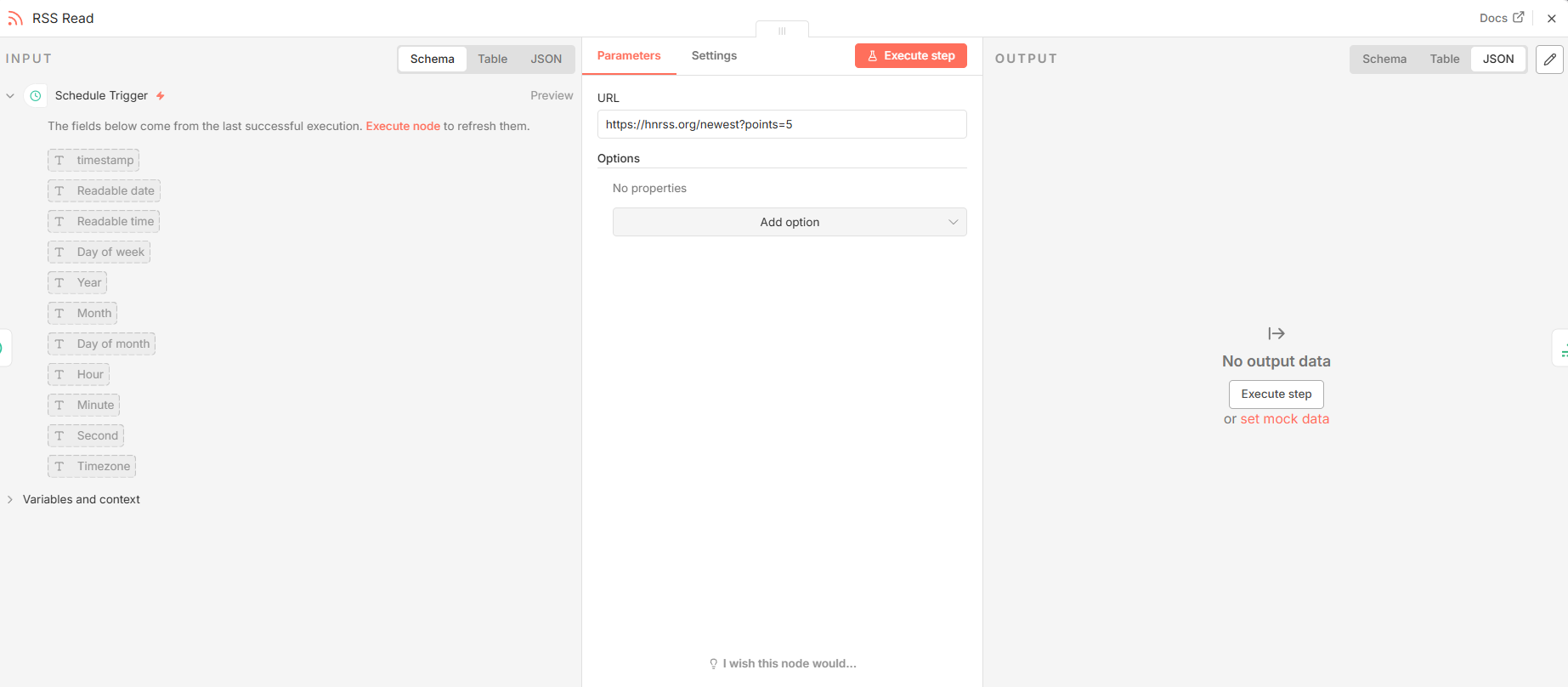
3.1 RSS Read ( n8n-nodes-base.rssFeedRead**)**
- 功能分析: 此节点是工作流的数据源入口。它的核心功能是访问一个指定的 RSS Feed URL,解析 XML 内容,并将其转换为结构化的 JSON 数据,以便后续节点可以轻松处理。
- 关键参数配置:
|-------|-------------------------------------|-------------------|
| 参数 | 值 | 说明 |
| url | https://hnrss.org/newest?points=5 | 指定要抓取的目标 RSS 源地址。 |
- 输入与输出:
- 输入: 无(由调度器触发)。
- 输出: 输出一个 JSON 数组,其中每个对象代表一篇文章,并包含
title、link和pubDate等键。
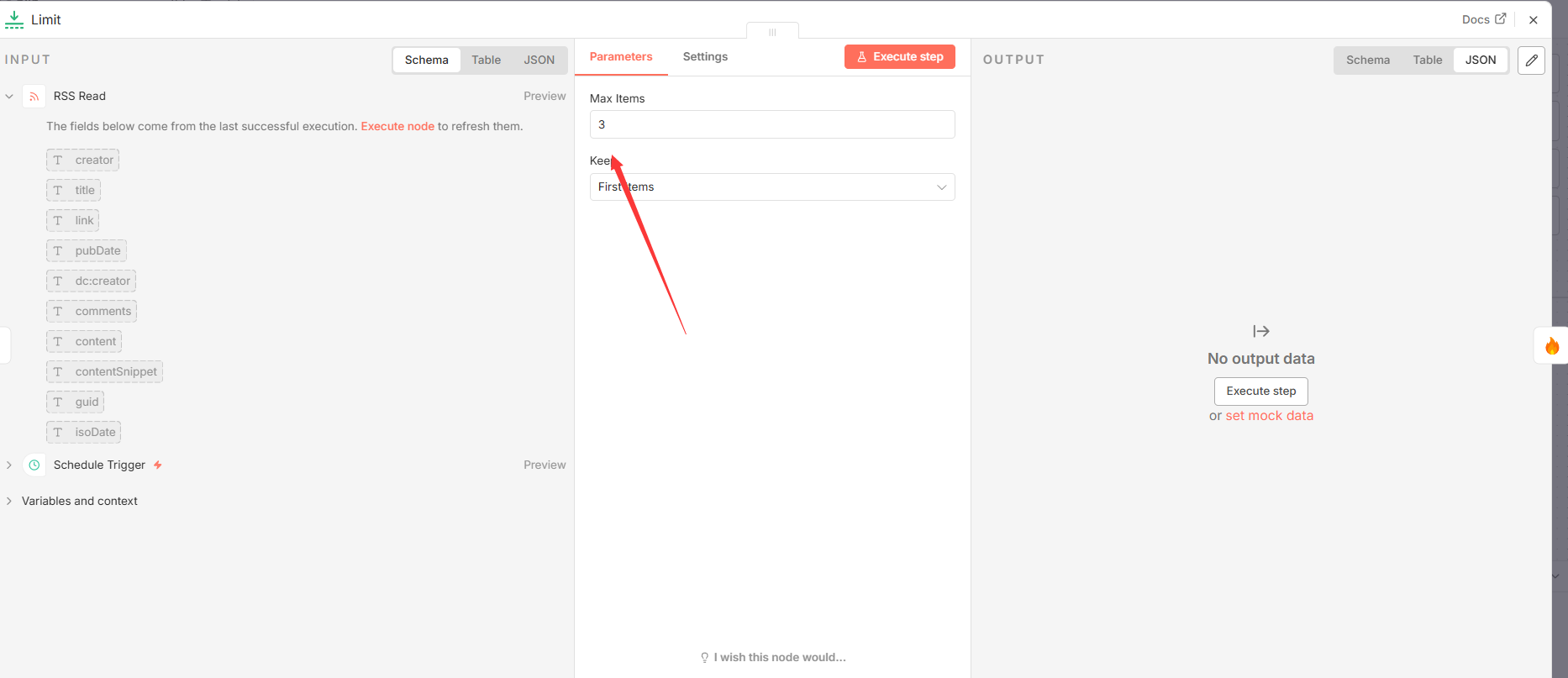
3.2 Limit ( n8n-nodes-base.limit**)**
- 功能分析: 该节点扮演着流量控制和成本管理的关键角色。它接收一个项目列表,并根据设定的数量上限返回一个子集。此举可有效防止对下游 Firecrawl 和 DeepSeek LLM 的过度 API 调用,这些服务通常按使用量计费,是工作流的主要运营成本来源。
- 关键参数配置:
|------------|-----|--------------------------|
| 参数 | 值 | 说明 |
| maxItems | 3 | 设定每次工作流执行时,最多处理的文章数量为3篇。 |
- 输入与输出:
- 输入:
RSS Read节点输出的文章对象数组。 - 输出: 一个经过筛选的文章对象数组,其长度不超过
maxItems的设定值。
- 输入:
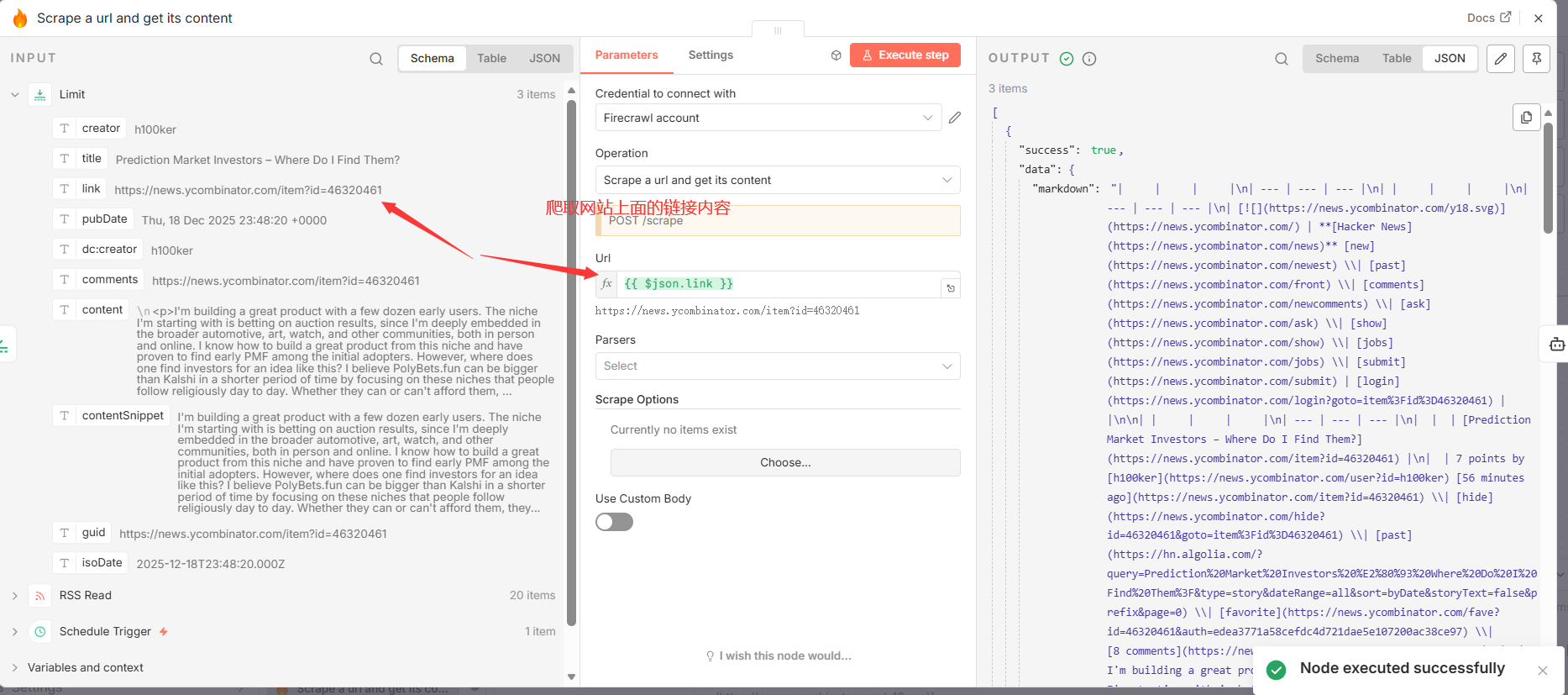
3.3 Scrape a url and get its content ( @mendable/n8n-nodes-firecrawl.firecrawl**)**
- 功能分析: 此节点负责从 RSS 条目提供的链接中提取核心内容。它利用外部服务 Firecrawl 智能地解析网页,去除广告、导航栏等无关元素,仅返回干净的文章正文,为后续的 AI 处理提供高质量的输入数据。此节点依赖于有效的
Firecrawl服务凭证。 - 关键参数配置:
|-------------|-----------------------|-----------------------------------|
| 参数 | 值 | 说明 |
| operation | scrape | 指定节点执行的操作为"抓取"。 |
| url | ={``{ $json.link }} | 动态引用上游节点传入的每篇文章的 link 字段作为抓取目标。 |
- 输入与输出:
- 输入:
Limit节点输出的单篇文章对象。 - 输出: 输出一个 JSON 对象,其中包含抓取到的内容,主要位于
data键内,其值为干净的文章文本字符串。
- 输入:
在完成对常规数据处理节点的分析后,下一章将聚焦于本工作流的大脑------人工智能处理核心。
4.0 人工智能处理核心
AI 代理和语言模型是本工作流中实现价值创造的核心。它将原始、非结构化的网页文本转化为精炼、高价值的新闻简报,是整个系统实现智能化的关键。此核心在架构上遵循关注点分离 原则:AI Agent 节点负责定义任务和提示策略(即"做什么"),而 DeepSeek Chat Model 节点则作为可替换的执行引擎(即"谁来做")。这种模块化设计增强了系统的灵活性,允许在不改变核心业务逻辑的情况下,更换底层的语言模型(例如,切换到 OpenAI 或 Anthropic 模型)。
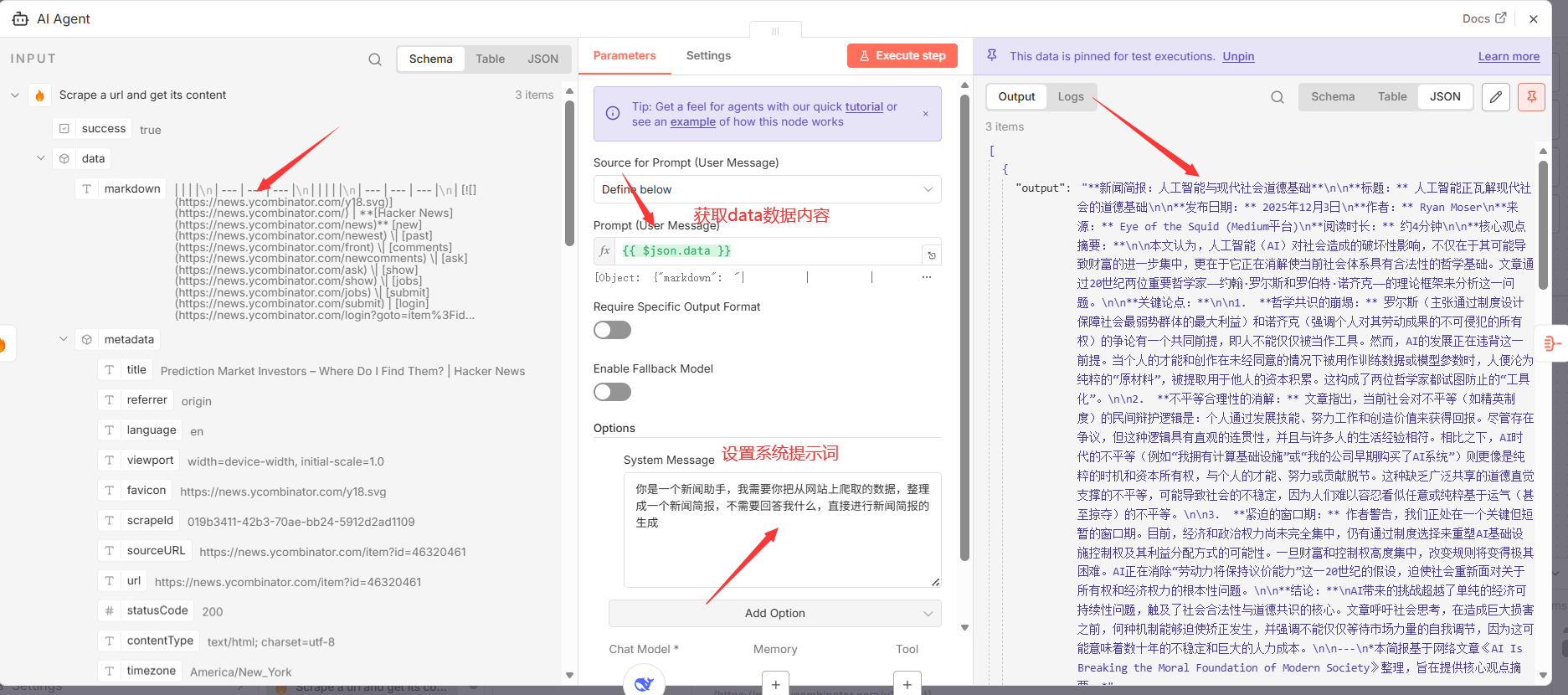
4.1 AI Agent ( @n8n/n8n-nodes-langchain.agent**)**
- 功能分析: 该节点作为与大型语言模型(LLM)交互的接口或代理。它负责接收上游节点传入的文本数据,并将其与一个预设的系统指令(System Message)打包,然后发送给绑定的语言模型进行处理,最后返回模型生成的文本。
- 关键参数配置:
|-------------------------|----------------------------------------------------------|-----------------------------------------------|
| 参数 | 值 | 说明 |
| promptType | define | 表明将直接在此节点内定义提示(Prompt)。 |
| text | ={``{ $json.data }} | 将上游 Scrape 节点输出的网页正文内容(data 字段)作为输入文本。 |
| options.systemMessage | 你是一个新闻助手,我需要你把从网站上爬取的数据,整理成一个新闻简报,不需要回答我什么,直接进行新闻简报的生成 | 设定一个系统级的指令,精确地指导 AI 的角色、任务和输出格式,并排除不必要的对话式回应。 |
4.2 DeepSeek Chat Model ( @n8n/n8n-nodes-langchain.lmChatDeepSeek**)**
此节点是为 AI Agent 提供底层自然语言处理能力的具体语言模型实现。它接收来自 AI Agent 的指令和文本,利用其强大的文本理解和生成能力,执行核心的摘要与格式化任务。要正常工作,该节点必须配置有效的 DeepSeek 服务凭证。
4.3 AI 生成内容示例
为了直观展示 AI 核心的处理效果,以下是从一次实际运行中捕获的单篇新闻简报输出示例:
新闻简报:人工智能与现代社会道德基础
标题: 人工智能正瓦解现代社会的道德基础
发布日期: 2025年12月3日 作者: Ryan Moser 来源: Eye of the Squid (Medium平台) 阅读时长: 约4分钟
核心观点摘要:
本文认为,人工智能(AI)对社会造成的破坏性影响,不仅在于其可能导致财富的进一步集中,更在于它正在消解使当前社会体系具有合法性的哲学基础。文章通过20世纪两位重要哲学家------约翰·罗尔斯和罗伯特·诺齐克------的理论框架来分析这一问题。
关键论点:
- 哲学共识的崩塌: 罗尔斯(主张通过制度设计保障社会最弱势群体的最大利益)和诺齐克(强调个人对其劳动成果的不可侵犯的所有权)的争论有一个共同前提,即人不能仅仅被当作工具。然而,AI的发展正在违背这一前提。当个人的才能和创作在未经同意的情况下被用作训练数据或模型参数时,人便沦为纯粹的"原材料",被提取用于他人的资本积累。这构成了两位哲学家都试图防止的"工具化"。
- 不平等合理性的消解: 文章指出,当前社会对不平等(如精英制度)的民间辩护逻辑是:个人通过发展技能、努力工作和创造价值来获得回报。尽管存在争议,但这种逻辑具有直观的连贯性,并且与许多人的生活经验相符。相比之下,AI时代的不平等(例如"我拥有计算基础设施"或"我的公司早期购买了AI系统")则更像是纯粹的时机和资本所有权,与个人的才能、努力或贡献脱节。这种缺乏广泛共享的道德直觉支撑的不平等,可能导致社会的不稳定,因为人们难以容忍看似任意或纯粹基于运气(甚至掠夺)的不平等。
- 紧迫的窗口期: 作者警告,我们正处在一个关键但短暂的窗口期。目前,经济和政治权力尚未完全集中,仍有通过制度选择来重塑AI基础设施控制权及其利益分配方式的可能性。一旦财富和控制权高度集中,改变规则将变得极其困难。AI正在消除"劳动力将保持议价能力"这一20世纪的假设,迫使社会重新面对关于所有权和经济权力的根本性问题。
结论: AI带来的挑战超越了单纯的经济可持续性问题,触及了社会合法性与道德共识的核心。文章呼吁社会思考,在造成巨大损害之前,何种机制能够迫使矫正发生,并强调不能仅仅等待市场力量的自我调节,因为这可能意味着数十年的不稳定和巨大的人力成本。
本简报基于网络文章《AI Is Breaking the Moral Foundation of Modern Society》整理,旨在提供核心观点摘要。
在生成了高质量的简报内容后,下一步是将这些内容进行整合与分发。
5.0 输出整合与分发
工作流的最后阶段同样至关重要,它负责将处理结果进行最终的整合、格式化,并可靠地交付给最终用户。本章节将详细介绍系统如何将多份由 AI 生成的独立简报聚合成一个统一的报告,并将其格式化后通过电子邮件发送。
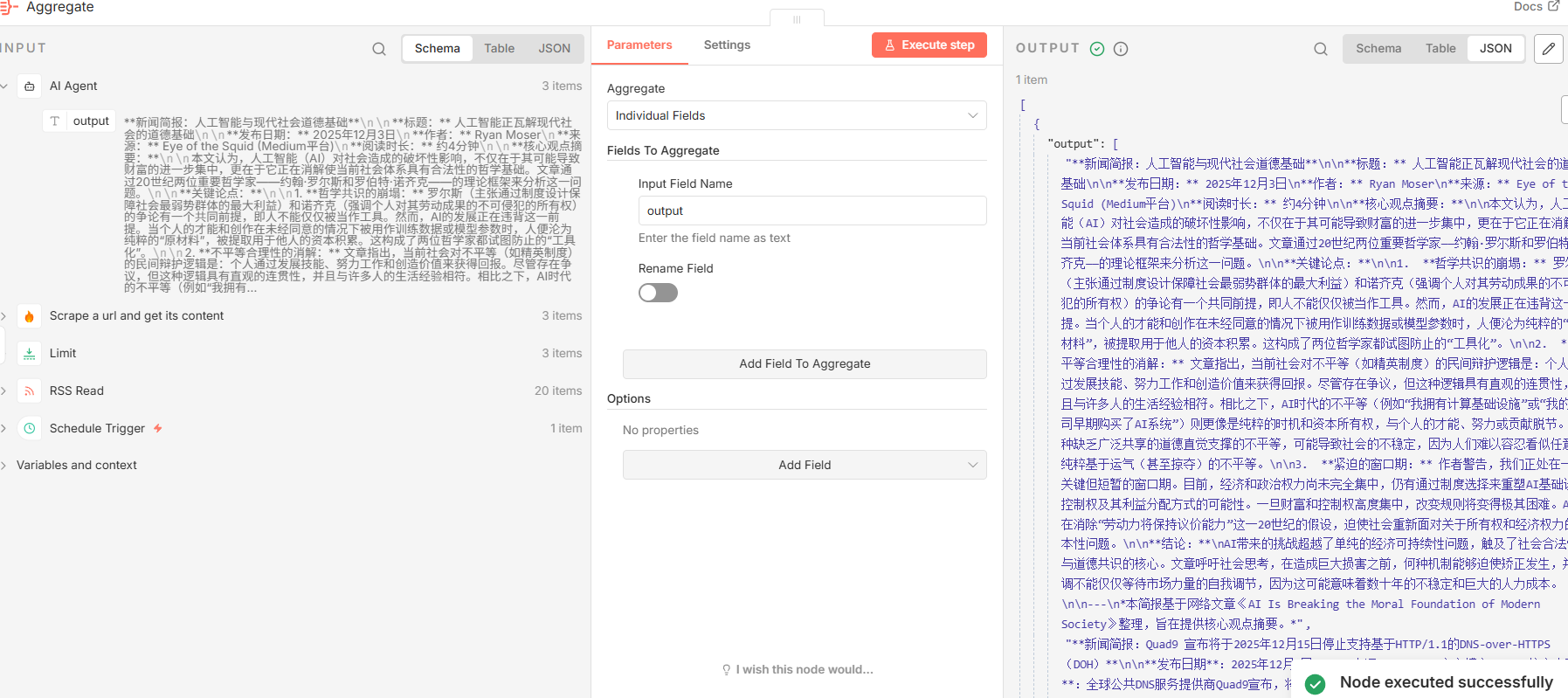
5.1 Aggregate ( n8n-nodes-base.aggregate**)**
- 功能分析: 此节点扮演着"收集器"的角色。由于前面的
AI Agent节点对多篇文章进行了循环处理,产生了多个独立的输出项。Aggregate节点的作用就是将这些分散的输出项收集起来,并将指定的字段(output)合并成一个单一的数组,为后续的统一处理奠定基础。 - 关键参数配置:
|---------------------|------------------------------------------------------------|--------------------------------------|
| 参数 | 值 | 说明 |
| fieldsToAggregate | json{"fieldToAggregate":[{"fieldToAggregate":"output"}]} | 配置节点以提取每个传入项目的 output 字段,并将它们聚合起来。 |
- 输入与输出:
- 输入: 多个独立的 JSON 对象,每个对象都包含一个
output字段。 - 输出: 一个包含
output字段的 JSON 对象,该字段的值是一个字符串数组,例如:['briefing 1', 'briefing 2', 'briefing 3']。
- 输入: 多个独立的 JSON 对象,每个对象都包含一个
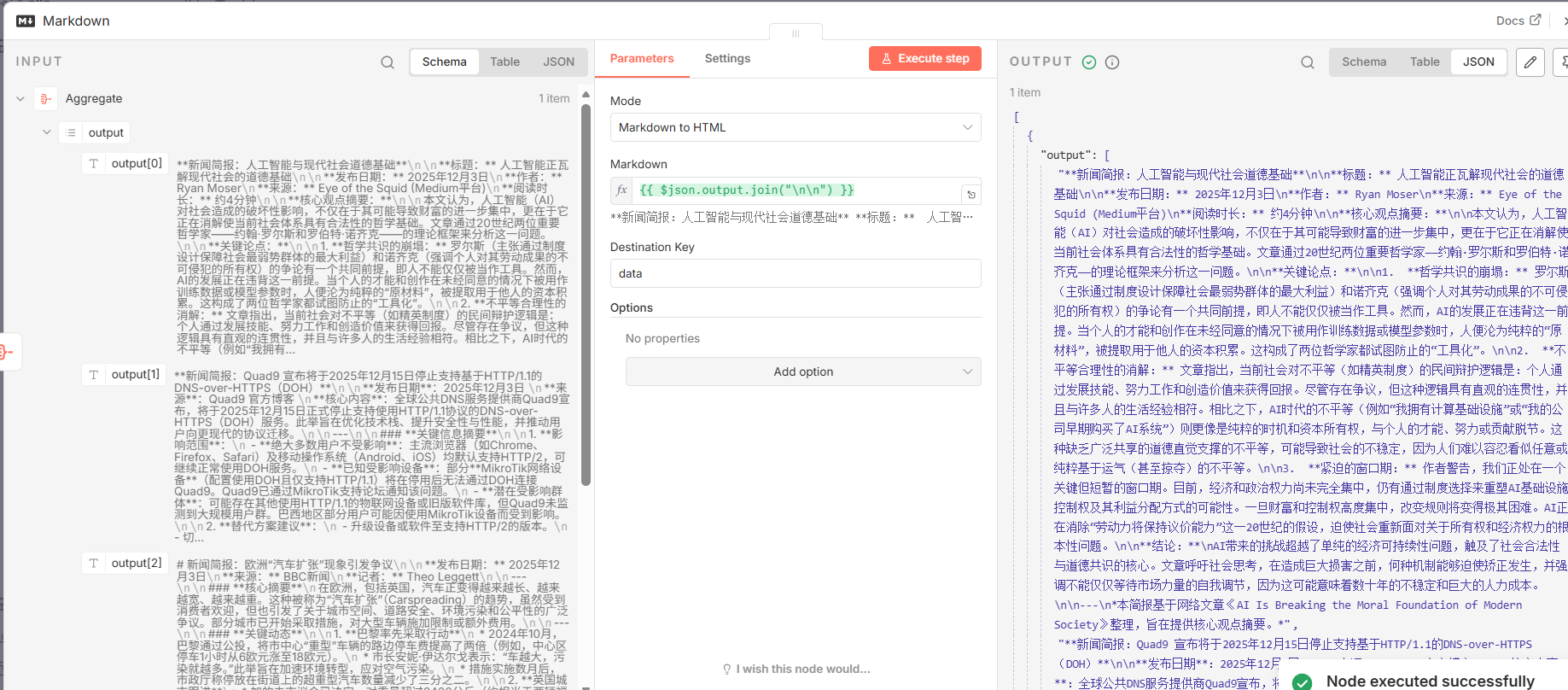
5.2 Markdown ( n8n-nodes-base.markdown**)**
- 功能分析: 该节点是一个格式转换工具。它接收聚合后的文本数组,通过
join函数将其合并为一个完整的 Markdown 字符串,并随后将这个字符串转换为 HTML 格式。这一步是确保新闻简报在各种电子邮件客户端中能够保持良好排版和可读性的关键。 - 关键参数配置:
|------------|----------------------------------------|-----------------------------------|
| 参数 | 值 | 说明 |
| mode | markdownToHtml | 指定操作模式为"Markdown 转 HTML"。 |
| markdown | ={``{ $json.output.join("\\n\\n") }} | 将上游传入的 output 数组用两个换行符连接成一个字符串。 |
- 输入与输出:
- 输入:
Aggregate节点输出的包含output数组的对象。 - 输出: 一个包含
data字段的对象,该字段的值是转换后的 HTML 字符串。
- 输入:
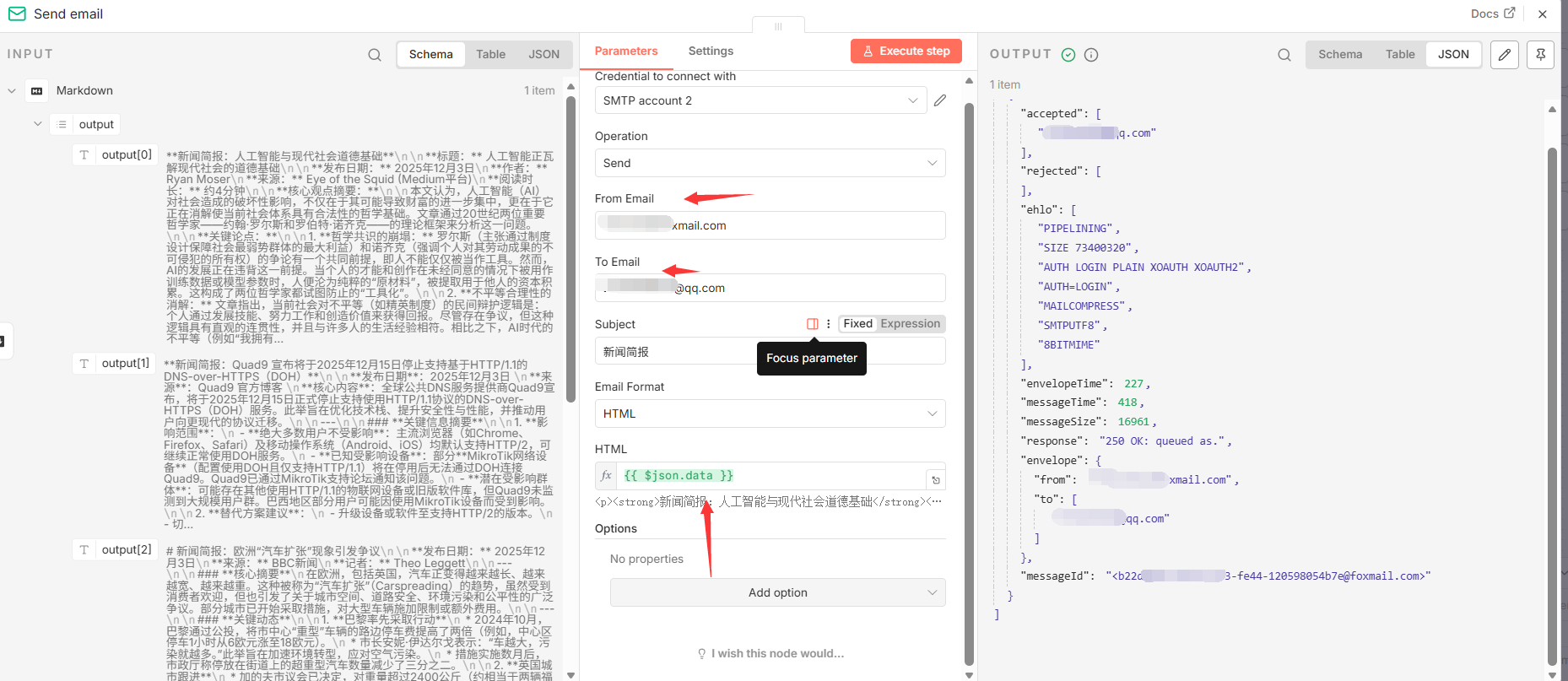
5.3 Send email ( n8n-nodes-base.emailSend**)**
- 功能分析: 这是工作流的最后一个动作节点,负责将最终成果交付给用户。它通过连接到一个 SMTP 服务器,将生成的 HTML 内容作为邮件正文,发送到指定的电子邮箱地址。此节点依赖于有效的
SMTP服务凭证。 - 关键参数配置:
|-------------|-----------------------|------------------------------------|
| 参数 | 值 | 说明 |
| fromEmail | xxxxxx@foxmail.com | 邮件发送方地址。 |
| toEmail | xxxxx@qq.com | 邮件接收方地址。 |
| subject | 新闻简报 | 邮件主题。 |
| html | ={``{ $json.data }} | 将 Markdown 节点生成的 HTML 字符串作为邮件正文。 |
- 输入与输出:
- 输入:
Markdown节点输出的包含 HTML 字符串的对象。 - 输出: 无(执行发送操作,流程结束)。
- 输入:
至此,工作流完成了从数据获取到最终分发的全部流程。最后一个章节将汇总工作流运行所需的所有外部服务依赖。
6.0 依赖项与凭证管理
要成功部署和复现此工作流,必须正确配置所有依赖的外部服务及其相应的认证凭证。这些服务为工作流提供了网页抓取、人工智能处理和邮件发送等核心能力。本节提供了一份清晰的依赖项清单。
依赖服务清单
|---------------|------------------------------------|---------------------|
| 服务 | 关联节点 | 凭证名称 |
| Firecrawl | Scrape a url and get its content | Firecrawl account |
| DeepSeek | DeepSeek Chat Model | DeepSeek account |
| SMTP | Send email | SMTP account 2 |
文档总结
本技术规范详细阐述了一个 AI 驱动的新闻简报自动化工作流。通过有机整合定时调度、RSS 读取、网页抓取、大型语言模型以及电子邮件服务,该系统构建了一个高效、智能、无需人工干预的新闻处理与分发管道。本文档为理解、实施和维护这一自动化解决方案提供了所有必要的技术细节,确保了其可复现性和可扩展性。