Hello 各位机器学习爱好者!如果你跟着我的入门、进阶系列博客走到这里,想必已经有了扎实认知------我们用一些机器学习算法搞定过图像分类、文本情感分析,甚至简单的机器翻译。但不知道你有没有发现一个"越学越困惑"的点:当处理长文本(比如一篇论文、一本小说)时,RNN的"逐字处理"总是力不从心,CNN的"局部感受野"又抓不住远距离的语义关联。
就像我们读一本侦探小说,看到结局时突然明白开头的伏笔------这种"跨越距离的关联感知",正是之前的模型难以实现的。而2017年Google提出的Transformer,恰恰像给机器装上了"全局视野的眼睛",彻底打破了序列模型的桎梏,成为BERT、GPT等大模型的"地基"。
今天这篇高阶解读,我们不搞"公式轰炸",而是顺着"为什么需要Transformer→它的核心魔法是什么→关键部件怎么协同工作"的逻辑,用你能听懂的比喻、可感知的例子,把这个"大模型基石"拆解得明明白白。而且每小节结尾我都会留一个"小思考",帮你巩固记忆;文末还会预告下一篇的核心内容,让我们的高阶之旅继续往下走~
一、先搞懂:为什么Transformer能取代RNN/CNN成为"顶流"?
在聊Transformer之前,我们先回头看看"旧时代"的困境------这能帮我们更快get到Transformer的革命性价值(毕竟"知道问题在哪,才懂解决方案有多牛")。
先想RNN:它处理文本是"从左到右一个个字过",就像我们看书只能逐字读,还得记住前面的内容。但问题来了,一旦文本变长(比如超过100个字),前面的记忆就会慢慢"淡化"(这就是梯度消失问题)。比如让它分析"小明告诉小红,他昨天买了一本《机器学习入门》",RNN很难快速确定"他"指的是"小明"还是"小红"。
再看CNN:它靠卷积核抓局部特征,比如在文本里抓"相邻的两个词"(比如"机器学习"),但对于"小明在上海工作,他的家人在北京生活"这种"上海"和"北京"的远距离关联,CNN就像"近视眼看远处"------根本看不清。
这时候Transformer站出来说:"别逐字读了,咱们把整段文本'摊开',一眼看清所有字之间的关系!" 它的核心突破就是两个:并行计算 (不用逐字等前面的结果,效率翻倍)和全局注意力(能直接计算任意两个字之间的关联,不管距离多远)。
小思考:你在之前用RNN做文本任务时,有没有遇到过"长文本效果差"的情况?可以在评论区说说你的经历~ 接下来我们就拆解这个"全局视野"是怎么实现的。
二、核心魔法:自注意力机制(Self-Attention)------让机器学会"聚焦重点"
Transformer的灵魂是"自注意力机制",但这名字听起来很玄乎,其实我们每天都在用。比如你读这句话:"在嘈杂的咖啡馆里,小李专注地看着手中的机器学习书籍"------你的大脑会自动忽略"嘈杂的""手中的"这些次要信息,聚焦到"小李""机器学习书籍"这两个核心主体上,这就是"注意力"。
自注意力机制做的事情,和我们大脑的这个过程几乎一样:给输入的每个词(比如"小李""咖啡馆""书籍")计算一个"注意力分数",分数高的词说明它和当前词的关联更紧密,模型就会重点关注它。
为了让你更直观理解,我们用"三个角色"来拆解自注意力的计算过程(这是我总结的简化版,避开复杂公式,核心逻辑不变):
-
角色1:查询(Query)------相当于"当前要关注的词",比如我们现在要分析"书籍"这个词,"查询"就是"书籍"的向量表示。
-
角色2:键(Key)------相当于"所有其他词的标签",比如"小李""咖啡馆""专注"这些词的向量表示,它们用来和"查询"对比,判断关联度。
-
角色3:值(Value)------相当于"每个词的核心信息",当我们确定了"查询"和"键"的关联分数后,就用分数加权求和"值",得到当前词的"注意力特征"(比如"书籍"的注意力特征,就融合了"小李""机器学习"这些高关联词的信息)。
举个具体的例子:输入文本是"小李在咖啡馆看机器学习书籍",当计算"书籍"的自注意力时:
-
查询(Q):书籍的向量
-
键(K):小李、在、咖啡馆、看、机器学习、书籍的向量
-
计算Q和每个K的相似度(注意力分数):"机器学习"和"书籍"的分数最高,"小李"次之,"咖啡馆"最低
-
用分数加权求和所有值(V):得到的"书籍"注意力特征,就重点包含了"机器学习"和"小李"的信息,忽略了"咖啡馆"的次要信息
这样一来,模型就知道了"书籍"和"机器学习""小李"的关联最紧密------这和我们人类的理解完全一致!
小思考:如果输入文本是"小明给小红送了一束花,她很开心",你觉得计算"她"的自注意力时,哪个词的注意力分数会最高?答案我们留在下一小节开头揭晓,帮你加深记忆~
三、进阶优化:多头注意力(Multi-Head Attention)------让注意力更"全面"
上一小节的小思考答案:"小红"的注意力分数最高!因为"她"明显指代的是"小红",自注意力机制能轻松捕捉到这种指代关系------这就是它比RNN强的地方。
不过,只用一个"查询-键-值"组合(单头注意力),模型的"视野还是有点窄"。比如"花"这个词,既和"送"有关(动作关联),又和"小红"有关(接收者关联),单头注意力可能只能重点关注一个关联,忽略另一个。
这时候"多头注意力"就登场了:简单说,就是同时用多个"查询-键-值"组合(多个"头"),每个头关注不同的关联维度,最后把所有头的结果拼接起来,得到更全面的注意力特征。
还是用"小明送小红花"的例子:
-
头1:重点关注"花"和"送"的动作关联
-
头2:重点关注"花"和"小红"的接收者关联
-
拼接两个头的结果:"花"的特征就同时包含了"动作"和"接收者"的信息,模型理解更全面
这就像我们分析一个问题时,多问几个人的观点,最后综合起来的结论更靠谱------多头注意力就是给模型加了"多个思考角度"。
四、Transformer的"骨架":编码器-解码器结构(简化版)
搞懂了自注意力和多头注意力,我们再来看Transformer的整体结构------它就像一个"精密的工厂",由编码器(Encoder)和解码器(Decoder)两部分组成,各司其职又协同工作。
先说明:不同任务用的结构不一样(比如文本分类只用编码器,机器翻译用编码器+解码器),我们这里讲最核心的通用结构,帮你建立整体认知:
-
编码器(Encoder):负责"理解输入"------比如机器翻译中,编码器负责理解源语言(比如中文)文本。它由N个相同的"编码层"堆叠而成,每个编码层的核心就是"多头注意力"+"前馈神经网络":
-
多头注意力:捕捉输入文本中所有词的关联(全局理解)
-
前馈神经网络:对每个词的注意力特征做进一步加工(提炼信息)
-
-
解码器(Decoder):负责"生成输出"------比如机器翻译中,解码器负责生成目标语言(比如英文)文本。它也由N个相同的"解码层"堆叠而成,核心是"掩码多头注意力"+"编码器-解码器注意力"+"前馈神经网络":
-
掩码多头注意力:防止模型"偷看未来的词"(比如生成第3个词时,不能用到第4、5个词的信息,否则就作弊了)
-
编码器-解码器注意力:让解码器关注编码器理解的源语言信息(比如生成英文时,知道对应中文的哪个词)
-
这里给大家一个"记忆小技巧":编码器像"读者",负责读懂输入的内容;解码器像"作者",负责根据读者的理解写出输出------两者配合,就能完成各种序列任务。
五、项目实战
下面是一个完整的Python项目,演示Transformer的核心组件。这个项目包含一个简化的Transformer模型实现,以及一个示例任务(简单的序列转换),可以直接在PyCharm中运行。
python
"""
Transformer核心原理演示项目
包含:自注意力机制、多头注意力、位置编码和简化的Transformer编码器
"""
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
from typing import Optional, Tuple
# 设置中文字体和负号显示(解决中文乱码问题)
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
def set_seed(seed=42):
"""设置随机种子确保可重复性"""
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
torch.backends.cudnn.deterministic = True
set_seed(42)
class PositionalEncoding(nn.Module):
"""
位置编码 - 解决Transformer没有位置信息的问题
使用正弦和余弦函数编码位置信息
"""
def __init__(self, d_model: int, max_len: int = 5000):
super(PositionalEncoding, self).__init__()
# 创建位置编码矩阵
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 应用正弦和余弦函数
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
"""添加位置编码到输入"""
return x + self.pe[:x.size(0), :]
class SelfAttention(nn.Module):
"""
自注意力机制 - Transformer的核心组件
演示Query、Key、Value的计算过程
"""
def __init__(self, d_model: int, d_k: int, d_v: int, dropout: float = 0.1):
super(SelfAttention, self).__init__()
# 线性变换层:生成Q、K、V
self.W_q = nn.Linear(d_model, d_k)
self.W_k = nn.Linear(d_model, d_k)
self.W_v = nn.Linear(d_model, d_v)
self.dropout = nn.Dropout(dropout)
self.d_k = d_k
def forward(self, x: torch.Tensor, mask: Optional[torch.Tensor] = None) -> Tuple[torch.Tensor, torch.Tensor]:
"""
前向传播
x: 输入张量 [batch_size, seq_len, d_model]
返回: 注意力输出和注意力权重
"""
batch_size, seq_len, _ = x.shape
# 1. 计算Q、K、V
Q = self.W_q(x) # [batch_size, seq_len, d_k]
K = self.W_k(x) # [batch_size, seq_len, d_k]
V = self.W_v(x) # [batch_size, seq_len, d_v]
# 2. 计算注意力分数 (Q和K的点积)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# 3. 可选:应用掩码(防止关注未来的位置)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 4. 应用softmax得到注意力权重
attention_weights = F.softmax(scores, dim=-1)
attention_weights = self.dropout(attention_weights)
# 5. 加权求和得到输出
output = torch.matmul(attention_weights, V)
return output, attention_weights
class MultiHeadAttention(nn.Module):
"""
多头注意力 - 让模型从不同角度关注信息
将输入分割成多个头,分别计算注意力,最后合并
"""
def __init__(self, d_model: int, num_heads: int, dropout: float = 0.1):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0, "d_model必须能被num_heads整除"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 线性变换层
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor, mask: Optional[torch.Tensor] = None) -> torch.Tensor:
batch_size, seq_len, _ = x.shape
# 1. 线性变换并分割成多个头
Q = self.W_q(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
# 2. 计算注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# 3. 应用掩码(如果需要)
if mask is not None:
mask = mask.unsqueeze(1) # 扩展维度以匹配多头
scores = scores.masked_fill(mask == 0, -1e9)
# 4. 应用softmax得到注意力权重
attention_weights = F.softmax(scores, dim=-1)
attention_weights = self.dropout(attention_weights)
# 5. 加权求和
output = torch.matmul(attention_weights, V)
# 6. 合并多头
output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
# 7. 最终线性变换
output = self.W_o(output)
return output
class PositionwiseFeedForward(nn.Module):
"""
位置前馈网络 - 对每个位置的表示进行非线性变换
"""
def __init__(self, d_model: int, d_ff: int, dropout: float = 0.1):
super(PositionwiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 两层线性变换,中间用ReLU激活
return self.linear2(self.dropout(F.relu(self.linear1(x))))
class TransformerEncoderLayer(nn.Module):
"""
Transformer编码器层 - 包含多头注意力和前馈网络
"""
def __init__(self, d_model: int, num_heads: int, d_ff: int, dropout: float = 0.1):
super(TransformerEncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
# 残差连接和层归一化
attn_output = self.self_attn(x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
class SimpleTransformer(nn.Module):
"""
简化的Transformer模型 - 仅包含编码器部分
适用于文本分类等任务
"""
def __init__(self, vocab_size: int, d_model: int, num_heads: int,
d_ff: int, num_layers: int, max_len: int = 100, dropout: float = 0.1):
super(SimpleTransformer, self).__init__()
# 词嵌入层
self.embedding = nn.Embedding(vocab_size, d_model)
# 位置编码
self.positional_encoding = PositionalEncoding(d_model, max_len)
# 编码器层
self.encoder_layers = nn.ModuleList([
TransformerEncoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
# 分类头
self.classifier = nn.Linear(d_model, 2)
self.dropout = nn.Dropout(dropout)
self.d_model = d_model
def forward(self, x, mask=None):
# 词嵌入
x = self.embedding(x) * math.sqrt(self.d_model)
# 位置编码
x = self.positional_encoding(x)
x = self.dropout(x)
# 通过多个编码器层
for layer in self.encoder_layers:
x = layer(x, mask)
# 取第一个位置的输出(CLS token的替代)
cls_output = x[:, 0, :]
# 分类
logits = self.classifier(cls_output)
return logits
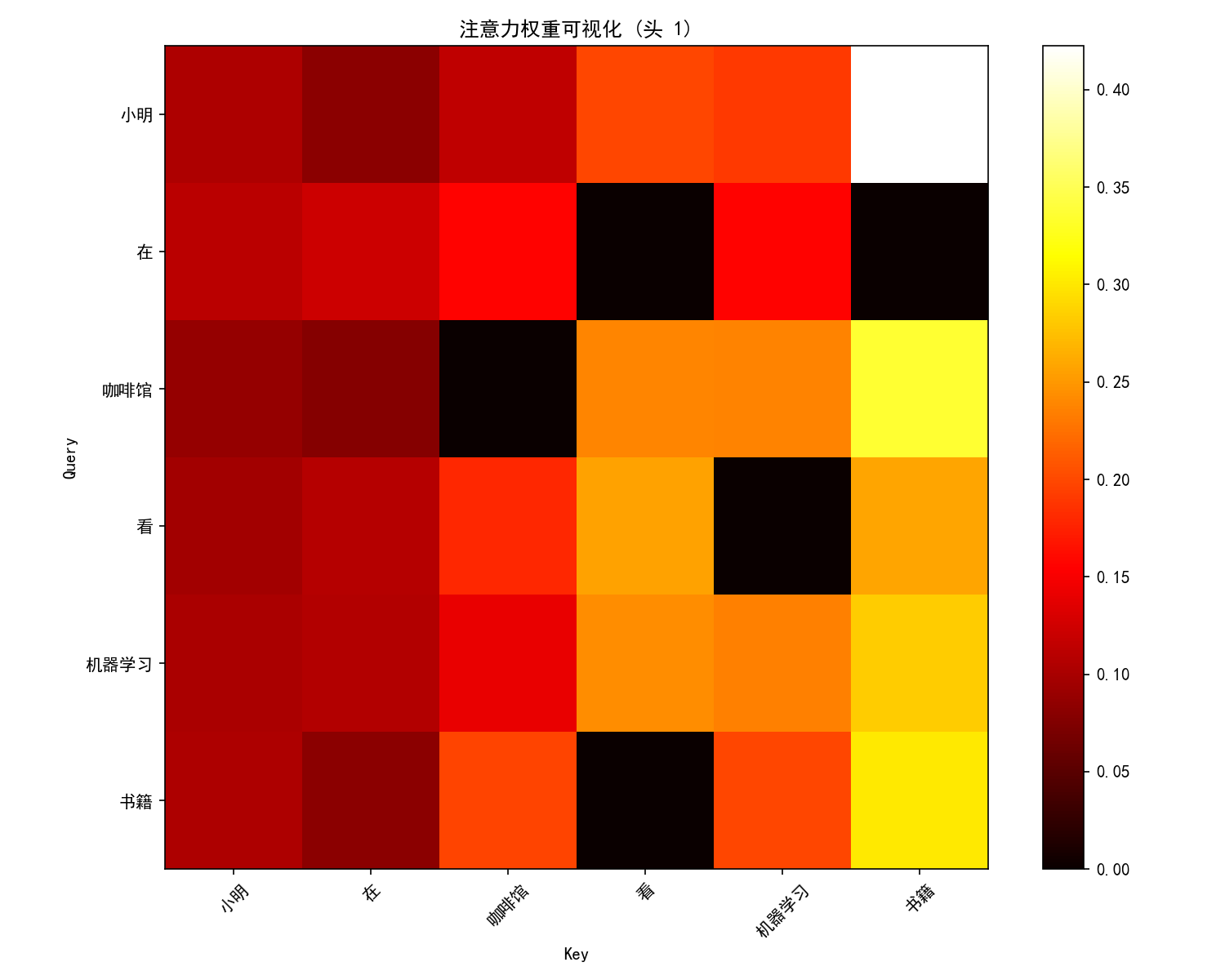
def visualize_attention(attention_weights, sentence, head_idx=0):
"""
可视化注意力权重
"""
plt.figure(figsize=(10, 8))
# 取第一个样本,指定头部的注意力权重
attention_map = attention_weights[0, head_idx].detach().cpu().numpy()
plt.imshow(attention_map, cmap='hot', interpolation='nearest')
plt.colorbar()
plt.xticks(range(len(sentence)), sentence, rotation=45)
plt.yticks(range(len(sentence)), sentence)
plt.xlabel("Key")
plt.ylabel("Query")
plt.title(f"注意力权重可视化 (头 {head_idx + 1})")
plt.tight_layout()
plt.show()
def demonstrate_self_attention():
"""
演示自注意力机制的计算过程
"""
print("=" * 80)
print("演示1: 自注意力机制如何工作")
print("=" * 80)
# 创建示例句子
sentence = ["小明", "在", "咖啡馆", "看", "机器学习", "书籍"]
print(f"示例句子: {' '.join(sentence)}")
# 假设每个词用4维向量表示
d_model = 4
vocab_size = 10
# 创建模拟的嵌入向量
torch.manual_seed(42)
embedding = nn.Embedding(vocab_size, d_model)
# 为每个词分配一个ID
word_ids = torch.tensor([0, 1, 2, 3, 4, 5])
# 获取词向量
word_embeddings = embedding(word_ids).unsqueeze(0) # [1, 6, 4]
# 创建自注意力层
self_attn = SelfAttention(d_model, d_k=4, d_v=4)
# 计算自注意力
with torch.no_grad():
output, attention_weights = self_attn(word_embeddings)
print(f"\n输入形状: {word_embeddings.shape}")
print(f"输出形状: {output.shape}")
print(f"注意力权重形状: {attention_weights.shape}")
# 查看"书籍"这个词的注意力分布
book_idx = 5 # "书籍"在句子中的位置
print(f"\n'书籍'的注意力权重分布:")
for i, word in enumerate(sentence):
weight = attention_weights[0, book_idx, i].item()
print(f" {word}: {weight:.4f}")
print("\n注意:'书籍'和'机器学习'的关联最强,这正是自注意力的魔力!")
return attention_weights, sentence
def demonstrate_multihead_attention():
"""
演示多头注意力机制
"""
print("\n" + "=" * 80)
print("演示2: 多头注意力机制")
print("=" * 80)
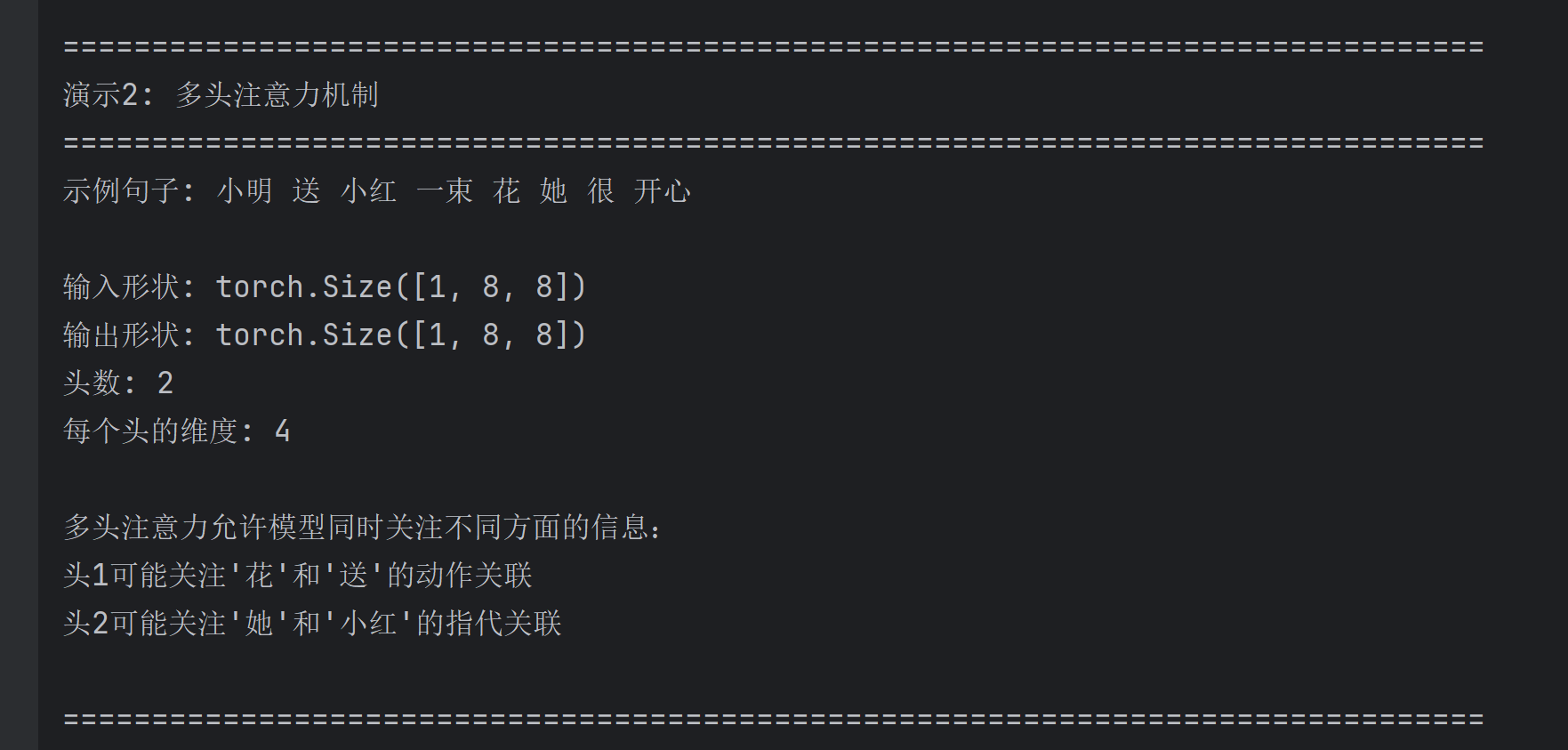
# 创建示例句子
sentence = ["小明", "送", "小红", "一束", "花", "她", "很", "开心"]
print(f"示例句子: {' '.join(sentence)}")
# 创建多头注意力层
d_model = 8
num_heads = 2
multihead_attn = MultiHeadAttention(d_model, num_heads)
# 创建模拟输入
batch_size = 1
seq_len = len(sentence)
x = torch.randn(batch_size, seq_len, d_model)
# 计算多头注意力
with torch.no_grad():
output = multihead_attn(x)
print(f"\n输入形状: {x.shape}")
print(f"输出形状: {output.shape}")
print(f"头数: {num_heads}")
print(f"每个头的维度: {d_model // num_heads}")
print("\n多头注意力允许模型同时关注不同方面的信息:")
print("头1可能关注'花'和'送'的动作关联")
print("头2可能关注'她'和'小红'的指代关联")
return output
def demonstrate_transformer_classifier():
"""
演示简化Transformer用于文本分类
"""
print("\n" + "=" * 80)
print("演示3: 简化Transformer文本分类")
print("=" * 80)
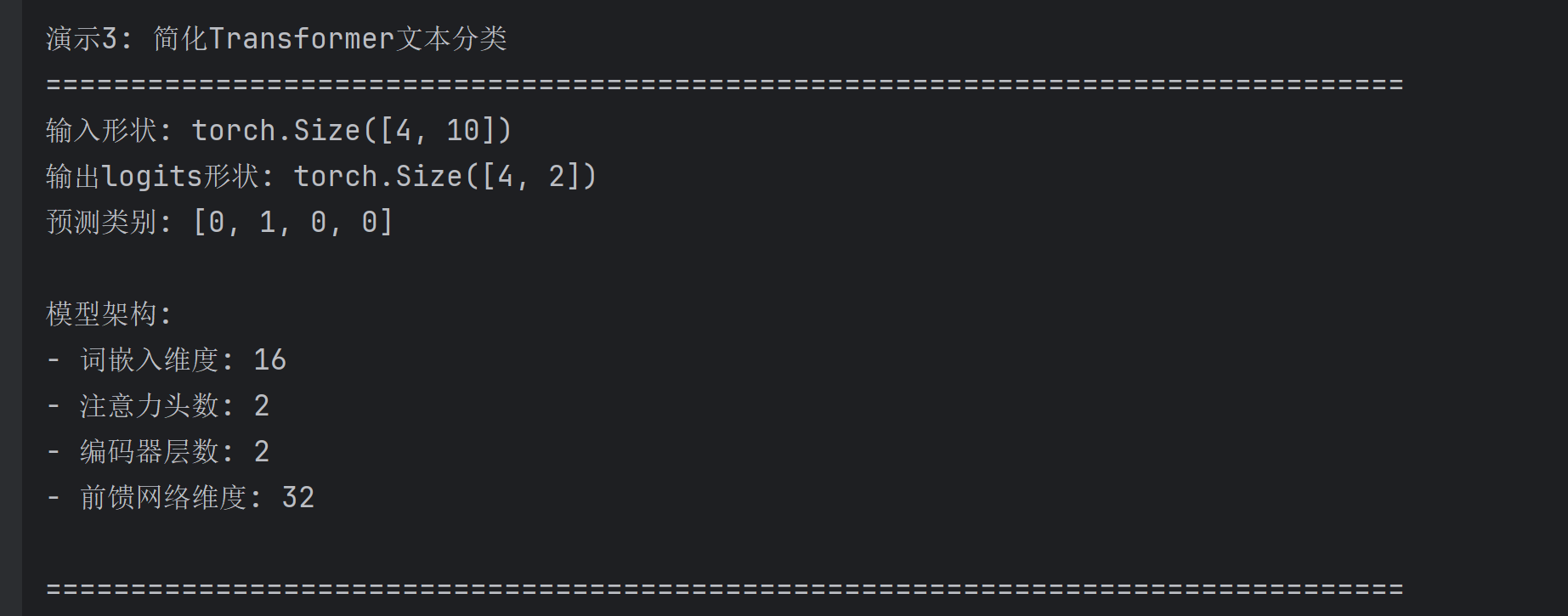
# 创建虚拟数据集
vocab_size = 50 # 词汇表大小
d_model = 16 # 模型维度
num_heads = 2 # 注意力头数
d_ff = 32 # 前馈网络维度
num_layers = 2 # 编码器层数
# 创建模型
model = SimpleTransformer(vocab_size, d_model, num_heads, d_ff, num_layers)
# 创建模拟数据
batch_size = 4
seq_len = 10
# 随机生成输入 (模拟token IDs)
input_ids = torch.randint(0, vocab_size, (batch_size, seq_len))
# 前向传播
logits = model(input_ids)
print(f"输入形状: {input_ids.shape}")
print(f"输出logits形状: {logits.shape}")
print(f"预测类别: {torch.argmax(logits, dim=1).tolist()}")
print("\n模型架构:")
print(f"- 词嵌入维度: {d_model}")
print(f"- 注意力头数: {num_heads}")
print(f"- 编码器层数: {num_layers}")
print(f"- 前馈网络维度: {d_ff}")
return model
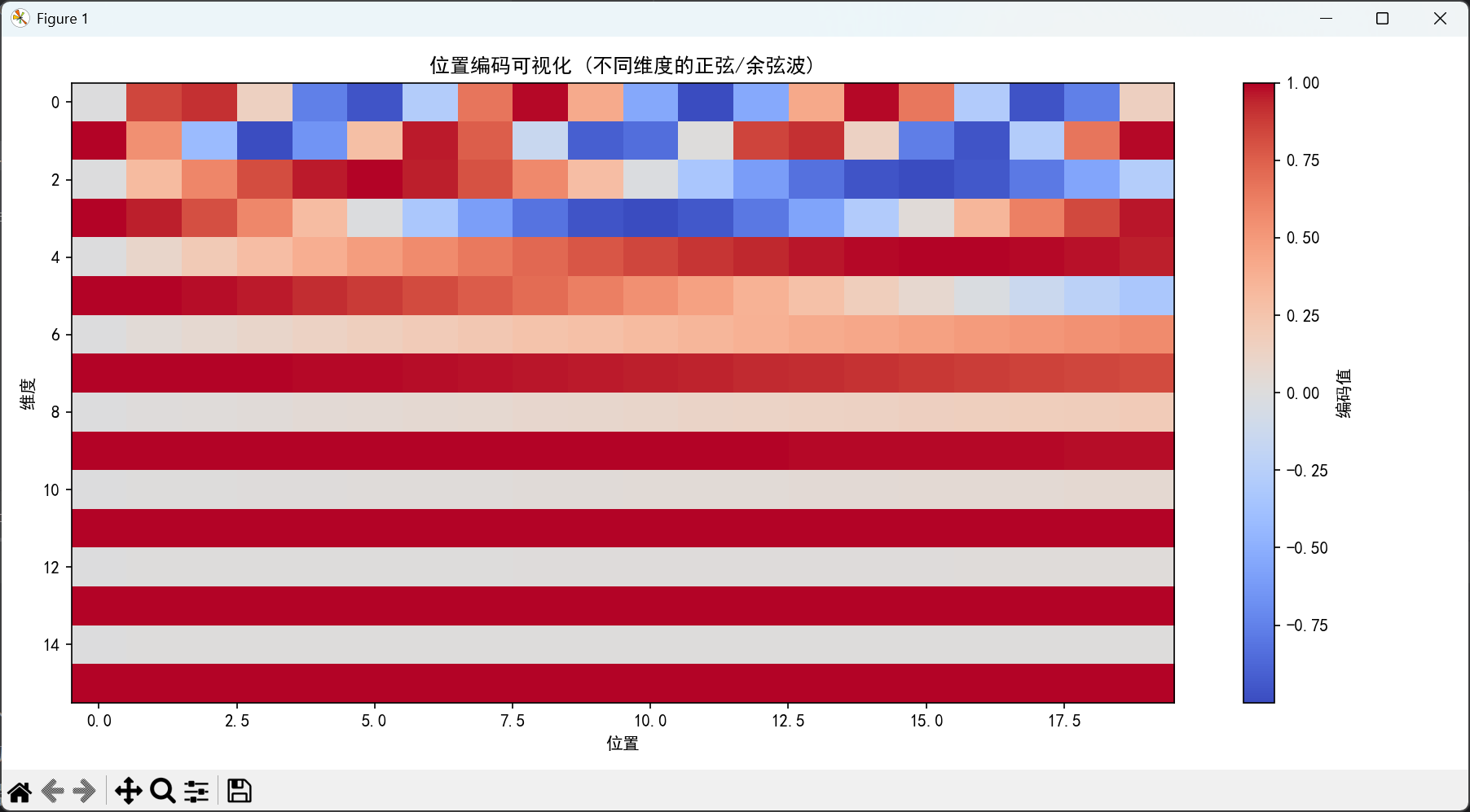
def demonstrate_positional_encoding():
"""
演示位置编码
"""
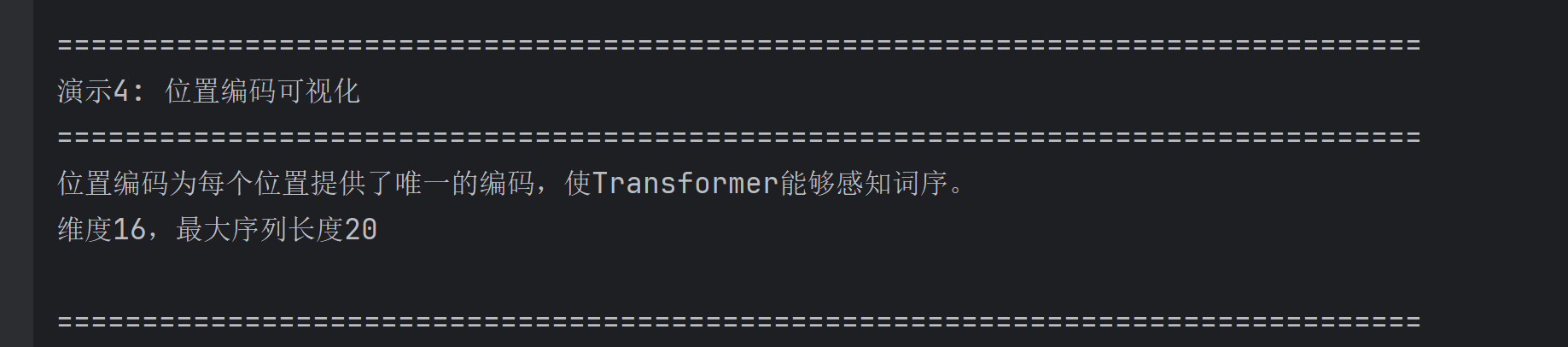
print("\n" + "=" * 80)
print("演示4: 位置编码可视化")
print("=" * 80)
# 创建位置编码层
d_model = 16
max_len = 20
pe = PositionalEncoding(d_model, max_len)
# 生成位置编码
positions = torch.arange(0, max_len).unsqueeze(1).float()
dummy_input = torch.zeros(max_len, 1, d_model)
positional_encodings = pe(dummy_input).squeeze(1).detach().numpy()
# 可视化
plt.figure(figsize=(12, 6))
plt.imshow(positional_encodings.T, aspect='auto', cmap='coolwarm')
plt.colorbar(label='编码值')
plt.xlabel('位置')
plt.ylabel('维度')
plt.title('位置编码可视化 (不同维度的正弦/余弦波)')
plt.tight_layout()
plt.show()
print("位置编码为每个位置提供了唯一的编码,使Transformer能够感知词序。")
print(f"维度{d_model},最大序列长度{max_len}")
return positional_encodings
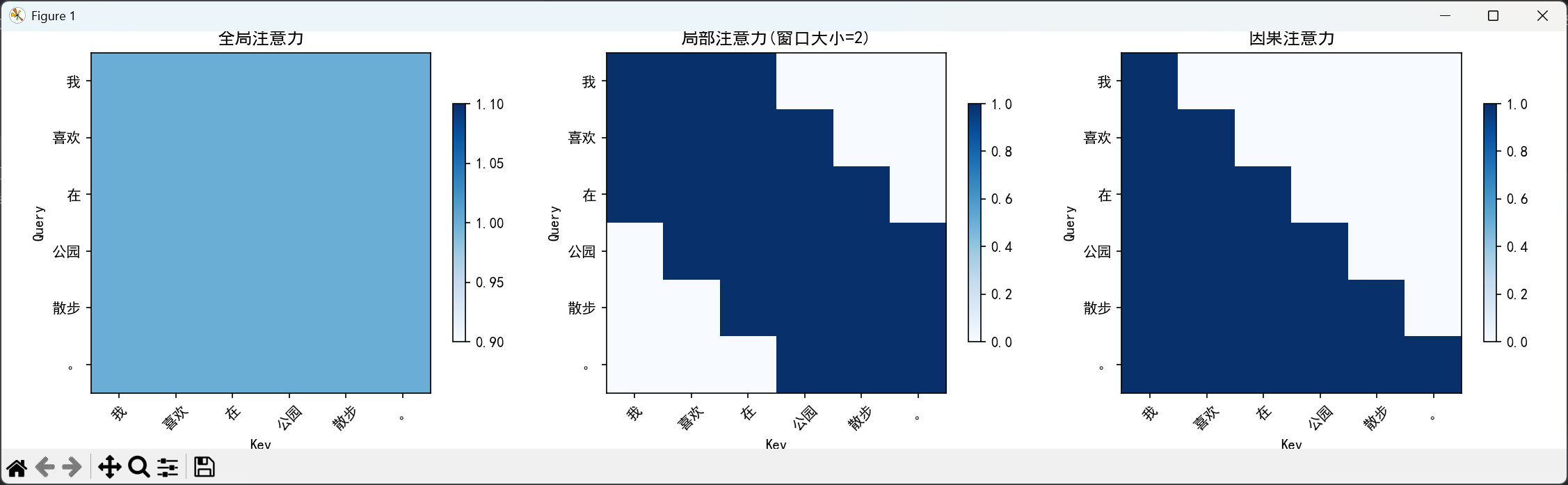
def demonstrate_attention_patterns():
"""
演示不同的注意力模式
"""
print("\n" + "=" * 80)
print("演示5: 不同的注意力模式")
print("=" * 80)
# 创建三个不同的注意力模式
seq_len = 6
sentence = ["我", "喜欢", "在", "公园", "散步", "。"]
# 1. 全局注意力 (Transformer的标准注意力)
global_attention = torch.ones(seq_len, seq_len)
# 2. 局部注意力 (类似CNN)
local_attention = torch.zeros(seq_len, seq_len)
window_size = 2
for i in range(seq_len):
start = max(0, i - window_size)
end = min(seq_len, i + window_size + 1)
local_attention[i, start:end] = 1
# 3. 因果注意力 (解码器使用,防止看到未来)
causal_attention = torch.tril(torch.ones(seq_len, seq_len))
# 可视化
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
attention_patterns = [global_attention, local_attention, causal_attention]
titles = ["全局注意力", f"局部注意力(窗口大小={window_size})", "因果注意力"]
for ax, pattern, title in zip(axes, attention_patterns, titles):
im = ax.imshow(pattern, cmap='Blues')
ax.set_xticks(range(seq_len))
ax.set_yticks(range(seq_len))
ax.set_xticklabels(sentence, rotation=45)
ax.set_yticklabels(sentence)
ax.set_xlabel('Key')
ax.set_ylabel('Query')
ax.set_title(title)
plt.colorbar(im, ax=ax, shrink=0.7)
plt.tight_layout()
plt.show()
print("不同类型的注意力模式适用于不同的任务:")
print("1. 全局注意力: Transformer编码器使用,能看到整个序列")
print("2. 局部注意力: 类似CNN,只关注相邻的词")
print("3. 因果注意力: Transformer解码器使用,不能看到未来的词")
def main():
"""
主函数:运行所有演示
"""
print("\n" + "=" * 80)
print("Transformer核心原理演示")
print("=" * 80)
print("\n本文将带你理解Transformer的关键组件:")
print("1. 自注意力机制 - 让模型关注输入中的相关部分")
print("2. 多头注意力 - 从不同角度关注信息")
print("3. 位置编码 - 为模型提供位置信息")
print("4. 编码器层 - Transformer的基本构建块")
print("5. 注意力模式 - 不同类型注意力的比较")
print("\n" + "-" * 80)
print("开始演示...")
print("-" * 80)
try:
# 演示1: 自注意力
attention_weights, sentence = demonstrate_self_attention()
# 演示2: 多头注意力
demonstrate_multihead_attention()
# 演示3: Transformer分类器
model = demonstrate_transformer_classifier()
# 演示4: 位置编码
demonstrate_positional_encoding()
# 演示5: 注意力模式
demonstrate_attention_patterns()
# 可选:可视化注意力权重
print("\n是否可视化注意力权重?(输入'y'确认,其他键跳过): ", end="")
if input().lower() == 'y':
visualize_attention(attention_weights.unsqueeze(1), sentence)
print("\n" + "=" * 80)
print("演示完成!")
print("=" * 80)
print("\n总结:")
print("1. 自注意力机制让Transformer能够直接计算任意两个词之间的关系")
print("2. 多头注意力使模型能从多个角度理解文本")
print("3. 位置编码为Transformer提供了位置信息")
print("4. Transformer的并行计算能力使其比RNN更高效")
print("\n这就是为什么Transformer能够成为BERT、GPT等大模型的基石!")
# 打印模型参数量
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"\n模型总参数量: {total_params:,}")
print(f"可训练参数量: {trainable_params:,}")
except Exception as e:
print(f"运行出错: {e}")
print("请确保已安装必要的库: torch, matplotlib, numpy")
if __name__ == "__main__":
# 检查必要的库是否已安装
try:
import torch
import matplotlib
except ImportError as e:
print(f"缺少必要的库: {e}")
print("请使用以下命令安装:")
print("pip install torch matplotlib numpy")
else:
main()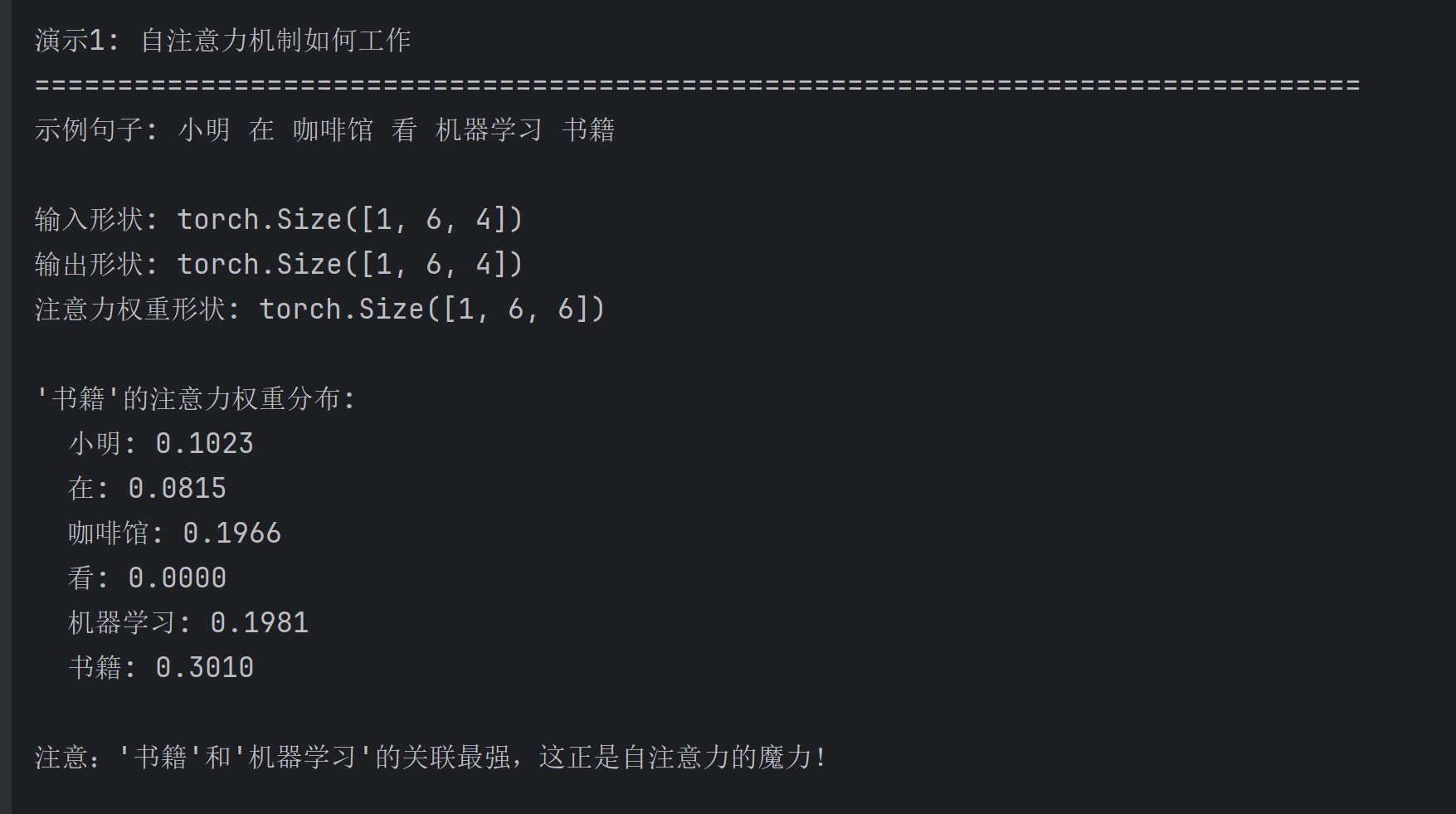

六、结尾:Transformer的价值
看到这里,你应该已经明白Transformer的核心逻辑了:用自注意力打破序列依赖,用多头注意力拓宽理解角度,用编码器-解码器结构实现"理解-生成"的完整流程。它不仅解决了RNN/CNN的痛点,更奠定了大模型的基础------没有Transformer,就没有后来的GPT、BERT,更没有现在的AI生成内容热潮。
不过,今天我们讲的还是"原理全景",很多细节比如"位置编码为什么重要""前馈神经网络具体做了什么""Transformer的训练过程有哪些技巧",这些内容我会放在下一篇博客里详细讲。而且下一篇我还会带大家用简单的代码实现一个迷你版Transformer,让你从"理论"落地到"实践",真正搞懂它的工作原理~
最后,来个小互动:你觉得Transformer最让你惊艳的地方是什么?是全局注意力,还是并行计算效率?欢迎在评论区留言讨论~