大家好,我是 Kerten。
最近在研究 NLP(自然语言处理) ,想着做一个 偏实用向的项目 来练练手。刚好这几年垃圾分类要求越来越细,有时候拿着个东西真的不知道该扔哪个桶,于是就动手写了这个 基于 RoBERTa 预训练模型的智能垃圾分类系统。
这个项目并不是简单地"调个模型跑一跑",而是加入了我自己设计的一套 「混合预测模式」:
- 对于数据集中已经存在的常见垃圾,直接 规则查表返回,保证 100% 准确;
- 对于规则库里没有的新词、模糊词,则交给 RoBERTa 模型进行语义推理,提高泛化能力。
整体思路是:能确定的就不用 AI,不确定的再交给 AI,在准确率和实用性之间做一个平衡。
目前已将项目 完整开源,主要是供大家学习交流,比较适合:
- 想入门 PyTorch / Transformers 的坛友
- 想做 中文文本分类实战 的
- 或者学习 FastAPI 写后端接口 的同学
📌 项目地址(欢迎 Star ⭐ 支持一下)
👉 https://github.com/MTQ851/garbage-classification-roberta
一、项目特点
✅ 混合预测模式(核心亮点)
- 数据库中已有的垃圾 → 直接规则匹配(100% 准确)
- 未命中的新垃圾 → RoBERTa 模型语义预测
✅ 中文效果优秀
- 使用哈工大讯飞
chinese-roberta-wwm-ext - 相比普通 BERT 对中文粒度更友好
✅ 生产级 API
- 基于 FastAPI
- 支持 GET 请求
- 自带 Swagger 接口文档
✅ 附带 Web 页面 Demo
- 可直接浏览器查询
- 适合小程序 / H5 / 教学演示
二、技术栈
- Python 3.8+
- PyTorch 2.x
- HuggingFace Transformers
- FastAPI + Uvicorn
- RoBERTa-wwm-ext(中文)
三、项目结构
text
garbage_classification/
├── data/
│ └── garbage_sorting.csv # 垃圾分类数据集
├── src/
│ ├── train.py # 模型训练(Fine-tuning)
│ ├── predict.py # 命令行预测(规则 + AI)
│ ├── api_server.py # FastAPI 接口服务
│ ├── check_data.py # 数据冲突检测
│ └── analyze_errors.py # 错误样本分析
├── static/
│ └── index.html # Web 前端页面
├── model/ # 训练生成的模型(已忽略)
└── requirements.txt四、使用说明
1️⃣ 数据检查(必做)
bash
python src/check_data.py确保 CSV 中不存在「同名不同类」的脏数据。
2️⃣ 模型训练
bash
python src/train.py- 首次会自动下载 RoBERTa 预训练模型
- 微调完成后模型保存至
model/roberta_garbage_model - 建议使用 GPU,CPU 也可运行但较慢
3️⃣ 命令行预测
bash
python src/predict.py可交互式输入垃圾名称进行测试。
4️⃣ 启动 API 服务
bash
python src/api_server.py- 服务地址:
http://127.0.0.1:9000 - Swagger 文档:
http://127.0.0.1:9000/docs
五、接口示例
请求:
GET /predict?text=香蕉皮返回:
json
{
"name": "香蕉皮",
"type": 3,
"confidence": "100.00%",
"source": "rule_match",
"desc": "厨余垃圾"
}
source=rule_match表示规则命中
source=ai_predict表示模型推理
六、在线 Demo
可直接浏览器测试垃圾分类。
七、截图说明
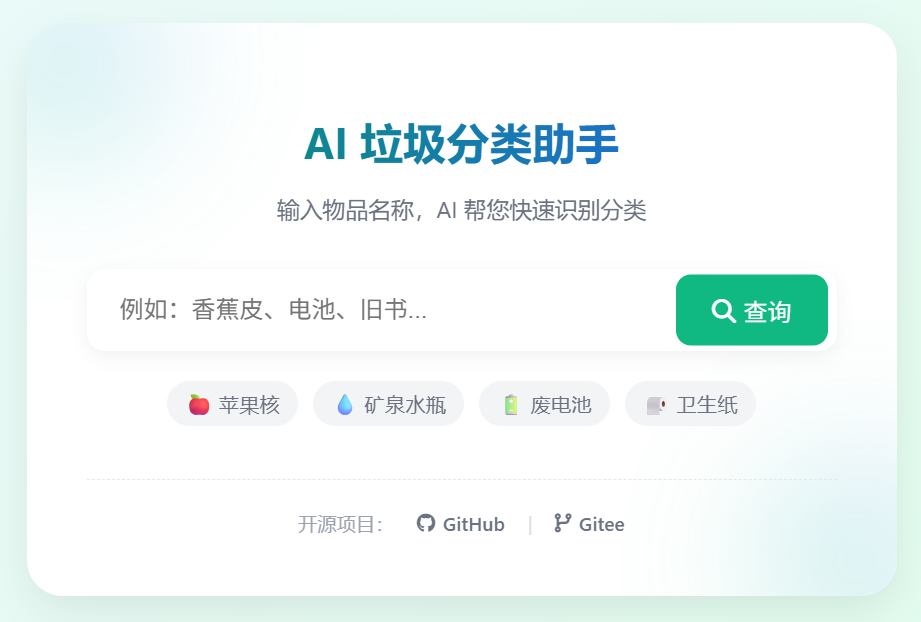
1️⃣ Web 界面演示
- 浏览器打开 Web 页面,输入垃圾名称
- 展示分类结果
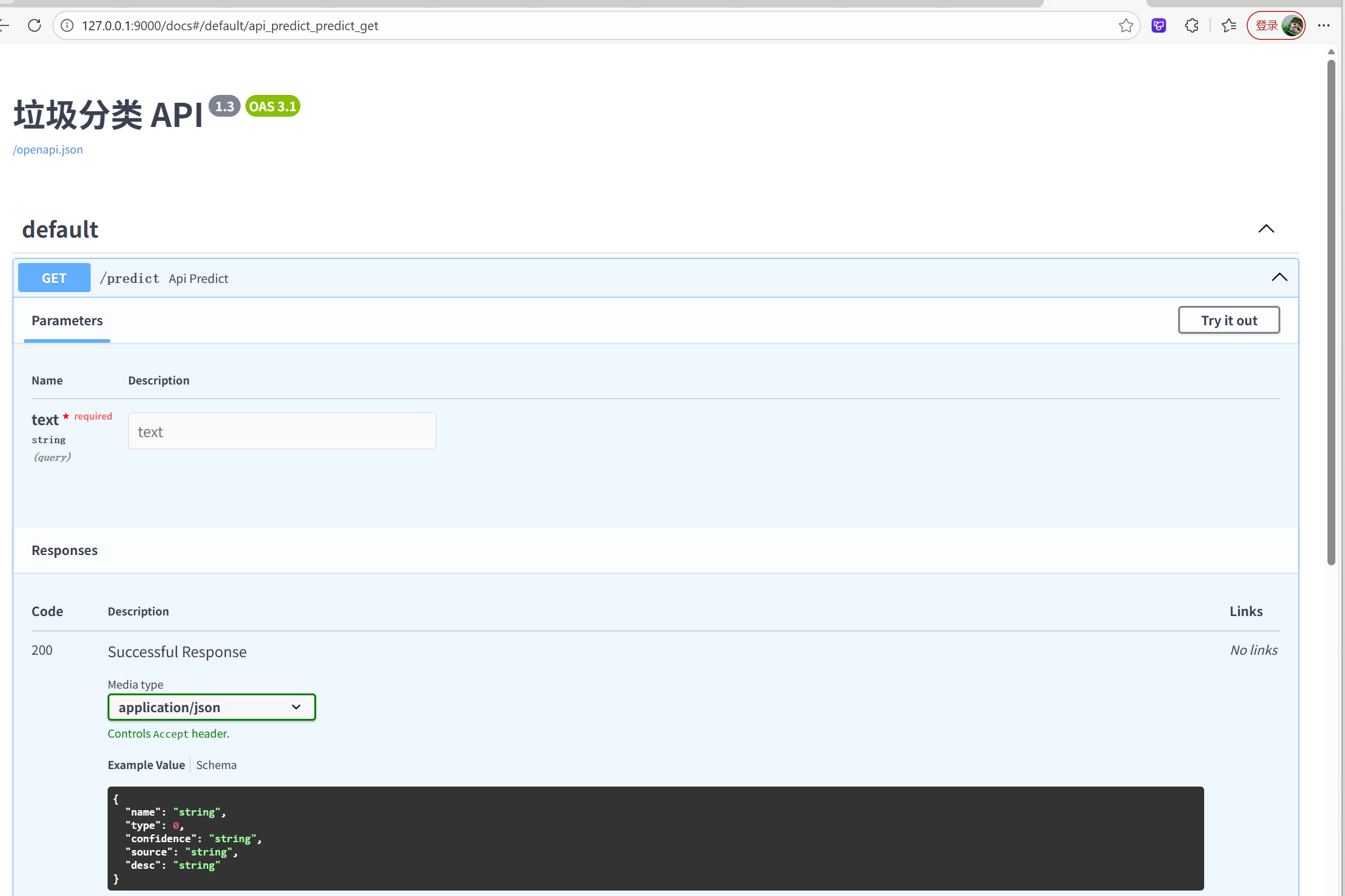
2️⃣ Swagger API 调试
- 打开
http://127.0.0.1:9000/docs - 展示
/predict接口返回 JSON
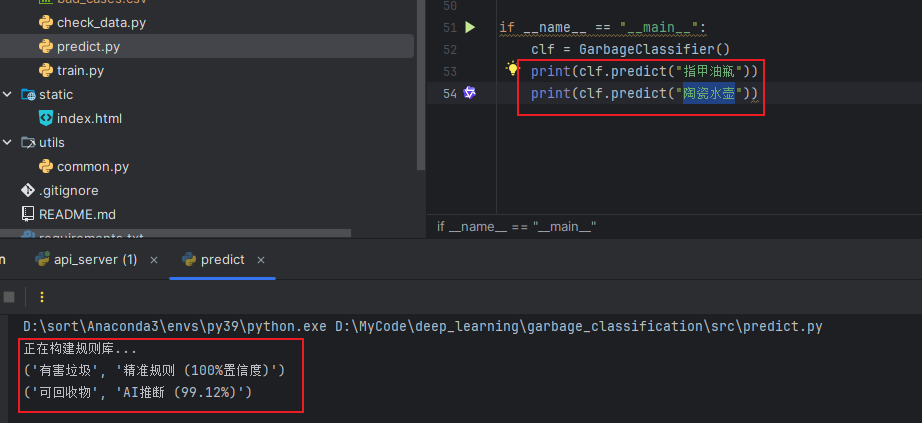
3️⃣ 模型训练 / 命令行预测
- 终端显示训练过程或命令行预测结果
八、说明与声明
- 模型文件较大(约 400MB),未上传仓库
- 请自行运行
train.py生成模型 - 数据集和分类标准可按本地城市规则替换
九、结语
📌 本项目适合:
- AI/深度学习实战
- 中文文本分类
- 垃圾分类系统后端
- FastAPI + Transformers 学习
欢迎大家 Star ⭐️ https://github.com/MTQ851/garbage-classification-roberta
有问题欢迎留言交流!