code:character-ai/Ovi
介绍
问题:为什么"一次性联合生成"这么难?现有开源方法多数是"先固定一个模态、再生成另一个模态",靠后处理或额外对齐模块。但真实内容要求:口型必须同步、动作与音效必须同步、音乐节奏要贴场景变化。而真正大规模、开源、方法透明的"一次性联合音视生成"基本空缺(点名 Veo3 但闭源)。
因此提出 Ovi:单次生成同时出视频+音频,并把同步当成模型内部学习出来的能力。

方法
核心思想:Twin Backbone + Blockwise Cross-Modal Fusion
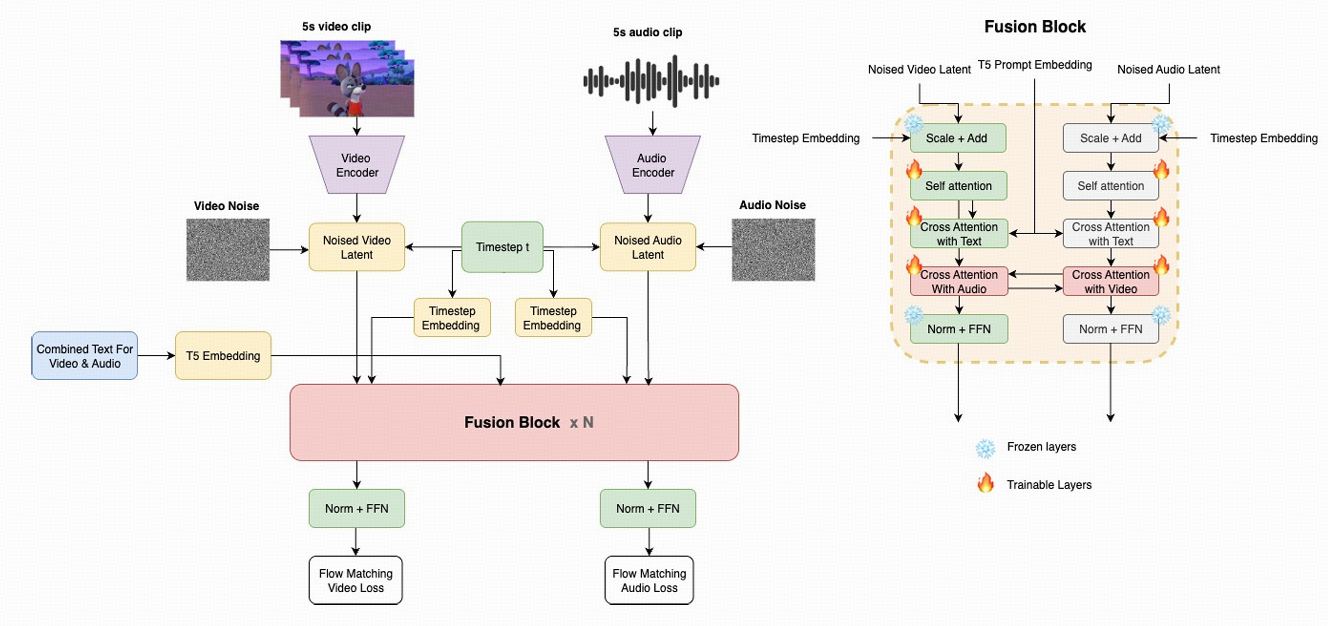
Twin Backbone是什么?
不是简单两个网络并排,而是两条结构完全一样的 DiT:
-
视频塔:直接拿强视频模型的初始化(初始化自 Wan2.2 5B)
-
音频塔:结构完全照抄视频塔(层数、heads、维度、FFN 都一致),但从零开始训练音频,学会语音与音效
好处:两边 latent 维度一致,跨模态注意力时不需要额外投影层(减少参数、减少不稳定来源),并且保留了单模态预训练学到的注意力结构。
Blockwise Cross-Modal Fusion
在每一个 Transformer block里都插入一对跨模态 cross-attn:
-
音频 tokens attend 到视频 tokens
-
视频 tokens 也 attend 回音频 tokens(双向)
逐层交换线索,让同步信号可以在整个深网络里持续流动,而不是只在某一层"碰一下"。
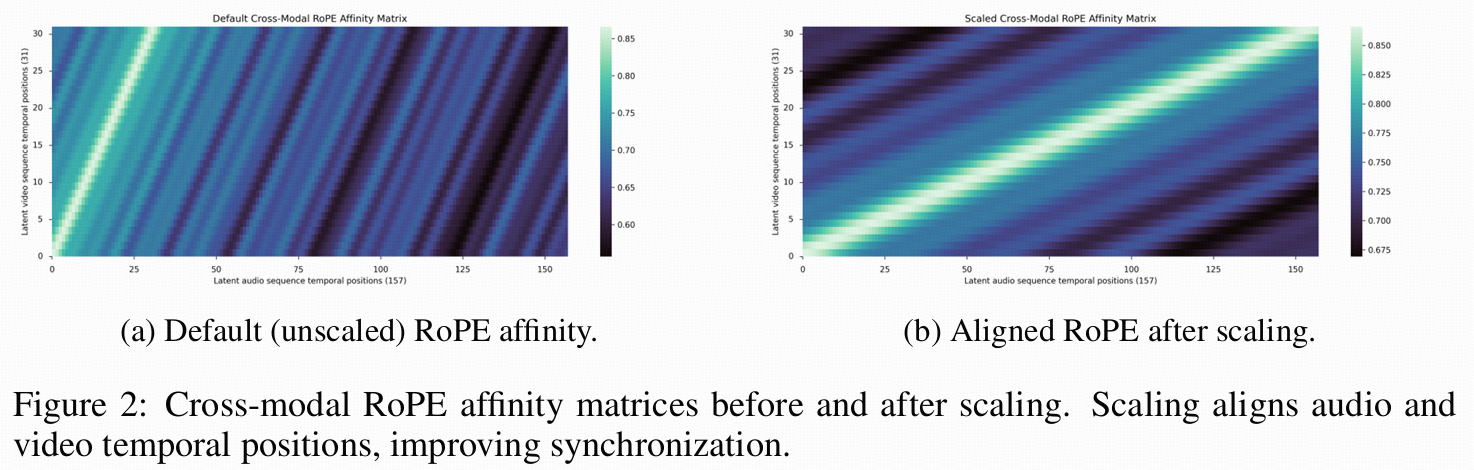
解决"时间分辨率不一致":Scaled RoPE 对齐时间
音频 token 时间更密,视频帧更稀。Ovi 的做法:仍然让两边互相注意力,但用 RoPE 频率缩放把音频的时间位置"拉伸到"与视频对齐。
论文给了直观证据:不缩放时,跨模态 RoPE affinity 的"对角线"会错位;缩放后对角线变得对齐更清晰,有利于同步。
可以理解成:先把"时间坐标系"统一,再谈语义融合;否则注意力会在时间上乱串。
文本条件:冻结 T5,统一控制两种模态
Ovi 用 单个冻结 T5 对"合并后的 prompt"编码,然后分别给音频塔、视频塔做 cross-attn 条件注入。这个 prompt 不是一句话,而是把:
-
描述视频中视觉事件的 caption(还带语音片段标记 <S>...<E>)
-
以及一段丰富音频描述(<AUDCAP>...<ENDAUDCAP>)
合在一起,让同一个语义上下文同时约束"看见什么"和"听见什么"。
作者还提到:他们试过"分开编码"(比如另用 CLAP 管音效、T5 管语音文本),但发现反而不够"统一",难把语音与音效自然混成同一条音轨;合并 prompt 后音频指标与对齐更好。
实验
训练策略:先把音频塔练成"基础音频模型",再学融合
阶段一:音频塔预训练(Ovi-Aud)
-
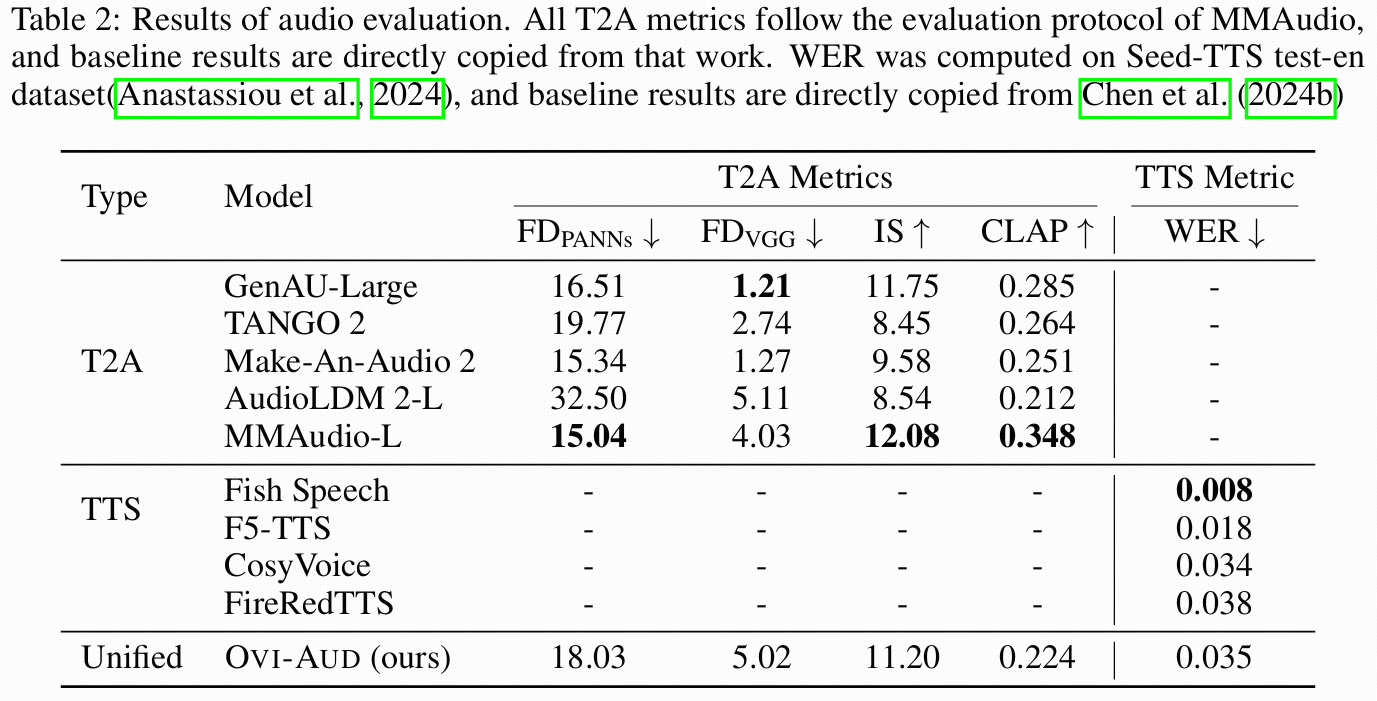
音频不直接在 waveform 上扩散,而是在 MMAudio 的 1D VAE latent 上训练(STFT→mel→VAE latent;生成后用 BigVGAN 声码器复原)
-
训练目标:Flow Matching(速度场/向量场预测式的 FM)
预训练分两步:
-
最长到 12 秒的变长音频:主要学语音一致性(音色、情绪、韵律)
-
再 fine-tune 到固定约 5 秒左右:对齐后续视频 clip 的时长分布,并加入更多音效,让它成为 AV 生成可用的"通用音频底座"。
并且为了避免后面切换阶段再适配时间编码,作者在音频塔所有 attention 层一开始就使用了 scaled RoPE。
阶段二:音视融合训练(Ovi)
把"预训练好的音频塔 + 预训练视频塔"拼起来:
-
跨模态注意力层从零初始化
-
但为了省显存、稳训练,作者冻结 FFN,只训练 self-attn / cross-attn(包括文本 cross-attn 与跨模态 cross-attn),11B 参数里约 5.7B 可训练。 arXiv+1
训练时的关键机制是:
-
音频与视频各自加独立噪声
-
但 共享同一个 diffusion timestep
-
两个分支同时做 FM loss,总 loss 是加权和
共享 timestep + 双向 cross-attn,会促使模型在同一"生成阶段"学习对应关系(口型、动作-音效等),而不需要额外显式同步 loss。
推理时,两条分支也共享采样日程,用同一个 ODE solver(文中说用 UniPC 更稳定)。
数据管线:为什么强调"严格同步过滤 + 富文本标注"?
作者直接说:哪怕只有少量不同步数据,也会显著伤害 lip-sync,所以做了严格过滤。
标注上,他们用 MLLM 看 7 帧 + 听全音轨,生成"按时间顺序"的详尽 caption,并且对含语音的片段特别强调说话人属性(年龄、口音、情绪、语速等),这是为了让音频塔能学到"身份与情感"。 arXiv
实验:证明"融合真的学到了同步"
做了两类证据:
-
跨模态注意力可视化:把 A2V cross-attn 平均后投影到像素热力图,展示音频 token 会关注到相关视觉区域------例如说话关注嘴部、打鼓关注鼓、动物叫声关注身体部位等。
-
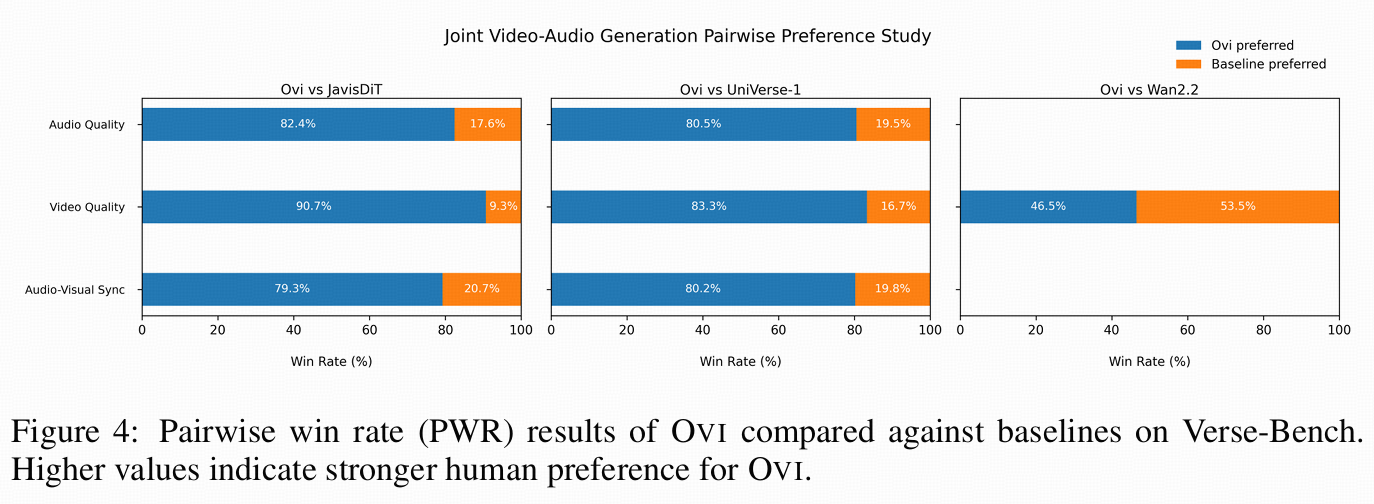
人类偏好评测:对 joint audio-video generation 做盲测,报告 pairwise win rate(PWR)和其他基线对比(文中提到会对比 JavisDiT、UniVerse-1,并检查视频质量相对 Wan2.2 的退化幅度)。

OVI 和 UniAVGen 的差别
-
OVI:靠 全局、对称、逐层双向 cross-attn + 时间编码对齐(scaled RoPE),用大数据"纯数据驱动"学同步,不引入脸部 mask 或额外同步模块。
-
UniAVGen:认为全局对称互看训练不稳/不够针对"人脸口型",因此引入非对称时间对齐交互(窗口/插值)+ 人脸优先调制(FAM)+ 推理期 MA-CFG 来强化"人相关同步"。(这一点在 UniAVGen 里对 Ovi 的定位也很明确。)
1) 骨架层:都走"双塔/双分支",但 UniAVGen更强调"统一潜空间的对齐训练"
-
Ovi:论文里明确说是 symmetric dual-tower architecture 做联合生成。
-
UniAVGen:同样是对称双分支(dual-branch)联合合成,但它把"对称性"当成"可对齐表征的前提",并在此基础上加了后续三件套(ATI/FAM/MA-CFG)。
-
换句话说:Ovi 的"对称"主要是结构选择;UniAVGen 的"对称"是为了服务后面更精细的跨模态对齐机制。
2) 交互层:Ovi 用"对称全局交互",UniAVGen 用"非对称时间对齐交互(ATI)"
-
Ovi:symmetric global cross-modal interactions(全局互看,且是对称的)。
-
UniAVGen:认为"全局互看"缺少显式时间对齐,收敛和稳定性更难;它提出 ATI:
-
A2V:视频帧看音频的邻域窗口(更符合口型受前后音素影响)
-
V2A:音频 token 看视频的插值过渡(更符合音频时间粒度更细)
-
-
Ovi "每个 token 看全场";UniAVGen "强制按时间对齐,但 A→V 和 V→A 用不同策略",更贴合两种模态的时间尺度差异。
3) 人类特征约束:UniAVGen 有 FAM(脸部优先的交互约束),Ovi 没有
-
Ovi 缺少 human-specific modulation,导致 OOD/跨域泛化受限。
-
UniAVGen 的对应方案是 Face-Aware Modulation (FAM):预测脸部 mask,用(逐渐衰减的)监督把跨模态交互先聚焦在脸区域,后期再放开