
🔥小叶-duck:个人主页
❄️个人专栏:《Data-Structure-Learning》
✨未择之路,不须回头
已择之路,纵是荆棘遍野,亦作花海遨游
目录
前言
在上一篇文章吃透C++类和对象(中):构造函数与析构函数深度解析我们讲解了类中默认成员函数的构造函数以及析构函数,这篇文章主要是详细讲解拷贝构造函数,这个函数所涉及的知识点比前面两个函数都更多且需要掌握好前面两个函数的知识才能更好去学习理解拷贝构造函数。
一、拷贝构造函数
如果一个构造函数 的第一个参数 是自身类类型的引用 ,且任何额外的参数 都有默认值 (即缺省参数),则此构造函数也叫做拷贝构造函数 ,也就是说拷贝构造是一个特殊的构造函数。
拷贝构造的特点:
1. 拷贝构造函数是构造函数的一个重载。
原因很简单,两者的区别就是形参不同并且在同一作用域中,所以两者构成重载。
cpp
#include<iostream>
using namespace std;
class Date
{
public:
Date(int year = 1, int month = 1, int day = 1) //全缺省的构造函数
{
_year = year;
_month = month;
_day = day;
}
Date(const Date& d) //拷贝构造函数
{
_year = d._year;
_month = d._month;
_day = d._day;
}
void Print()
{
cout << _year << "/" << _month << "/" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1(2025, 12, 19);
d1.Print();
Date d2(d1);
d2.Print();
return 0;
}
2. 拷贝构造函数的第一个参数必须是类类型对象的引用 ,使用传值方式 编译器直接报错 ,因为语法逻辑 上会引发无穷递归调用 。拷贝构造函数也可以多个参数 ,但是第一个参数必须是类类型对象的引用,后面的参数 必须有缺省值。
cpp
class Date
{
public:
Date(int year = 1, int month = 1, int day = 1) //全缺省的构造函数
{
_year = year;
_month = month;
_day = day;
}
Date(Date d) //传值传参 error C2652 : "Date": 非法的复制构造函数: 第一个参数不应是"Date"
{
_year = d._year;
_month = d._month;
_day = d._day;
}
void Print()
{
cout << _year << "/" << _month << "/" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1(2025, 12, 19);
d1.Print();
Date d2(d1);
d2.Print();
return 0;
}
第一句话在刚开始学拷贝构造函数时是很多人不好去理解的。
要理解这句话首先我们要知道C++有一个规定 :传值传参时必须调用拷贝构造函数。
因为传值传参时,在C语言学习中我们就知道形参和实参是完全不同的东西 ,形参有着独立的内存地址 ,也就是说我们在调用函数时需要创建形参 ,在C++中就规定了传值传参必须调用拷贝构造函数 。
在我看来,我有一个更好理解这个规定的逻辑就是:传值传参 的结构为 Date d ,这个结构难道不就类似于前面我们学习到的创建一个新对象 吗?这样我们把C++中的这个规定理解成:当创建形参时相当于创建的是一个新对象,则必须调用拷贝构造函数。这样我们就能顺理成章的解释为什么传值传参会导致无限递归调用了:
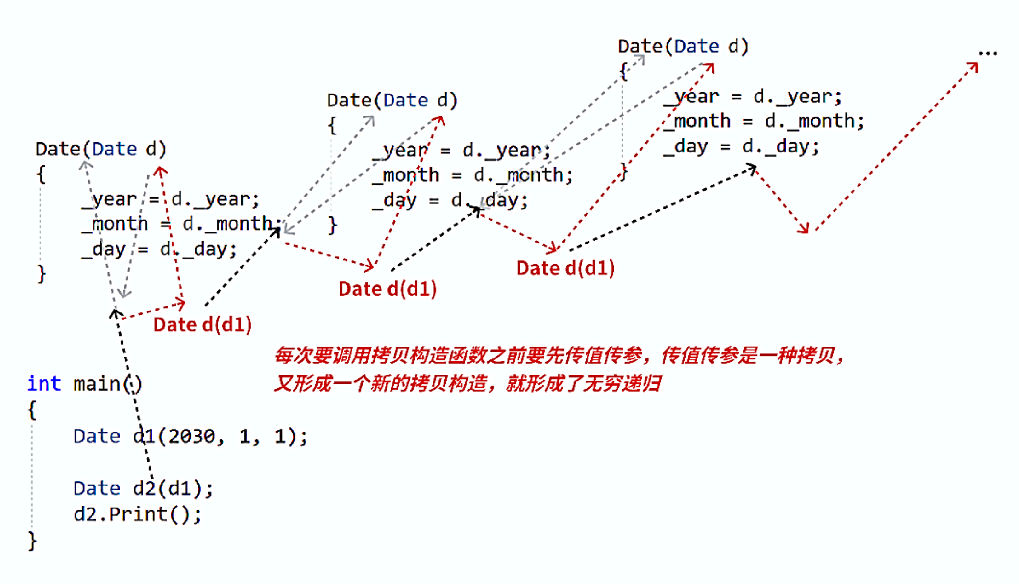
当我们传值传参时要创建形参 也就相当于创建一个新对象 ,需要调用拷贝构造函数 ,也就是函数自己本身 ,当调用自己时也需要创建形参,这也要调用拷贝构造函数,则又是函数自己本身,如此往复就会导致不断创建形参而调用函数自己的死循环。
那有些人理解了这个以后就提出了疑问:为什么引用传参就不会导致这种结果呢?
这就又要用到前面我们学习的知识啦,还记得前面学习引用时我们怎么说的:引用并没有开辟新的空间 ,没有创建新的变量 ,引用只是一个别名 ,也就是说引用传参 时实参和形参完全是同一个东西 ,也就没有**"创建"** 二字一说了,自然也就不会调用拷贝构造函数了。
3. C++规定自定义类型 对象进行拷贝行为 必须调用拷贝构造,所以这里自定义类型传值传参和传值返回都会调用拷贝构造完成。
4. 若未显式定义 拷贝构造,编译器会自动生成拷贝构造函数 。自动生成的拷贝构造对内置类型 成员变量会完成值拷贝/浅拷贝 (一个字节一个字节的拷贝 ),对自定义类型成员变量 会调用他的拷贝构造。
我们会发现拷贝构造函数在这里就与之前所学的构造函数与析构函数有所不同了,之前我们学习时就说过这两个函数对内置类型的成员变量 是不做处理 的,也就是说内置类型的成员变量初始化是不确定 的;但是拷贝构造函数对内置类型的成员变量也会做处理就是完成值拷贝,值拷贝 就可以类比理解为C语言中的memcpy 函数。对于自定义类型的成员变量就和前面所学的函数类似。
这样的话当我们知道拷贝构造函数对内置类型的成员变量也会做处理并且未显式定义拷贝构造时编译器也会自动生成,那我们还需要对上述代码手动写拷贝构造函数吗?是不是就不需要了,因为上述的 Date 类里面只有内置类型成员变量:
cpp
class Date
{
public:
Date(int year = 1, int month = 1, int day = 1) //全缺省的构造函数
{
_year = year;
_month = month;
_day = day;
}
//Date(const Date& d) //拷贝构造函数
//{
// _year = d._year;
// _month = d._month;
// _day = d._day;
//}
//也可以不手动写拷贝构造函数,因为编译器会自动生成并且对内置类型成员变量也会做处理
void Print()
{
cout << _year << "/" << _month << "/" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1(2025, 12, 19);
d1.Print();
Date d2(d1);
d2.Print();
return 0;
}
5.像Date 这样的类成员变量全是内置类型 且没有指向什么资源 ,编译器自动生成 的拷贝构造就可以完成需要的拷贝 ,所以不需要我们显示实现拷贝构造。像Stack 这样的类,虽然也都是内置类型,但是**_a 指向了资源** ,编译器自动生成的拷贝构造完成的值拷贝/浅拷贝不符合我们的需求 ,所以需要我们自己实现深拷贝 (对指向的资源也进行拷贝) 。像 MyQueue 这样的类型内部主要是自定义类型 Stack 成员,编译器自动生成的拷贝构造会调用 Stack 的拷贝构造,也不需要我们显示实现 MyQueue 的拷贝构造。这里还有一个小技巧,如果一个类显示实现了析构 并释放资源 ,那么他就需要显示写拷贝构造,否则就不需要。
这段话比较长,也不是很好理解,我们用代码一点一点来解释原因:
错误示范(没有显示实现拷贝构造):
cpp
typedef int STDataType;
class Stack
{
public:
Stack(int n = 4) //全缺省的构造函数
{
_arr = (STDataType*)malloc(sizeof(STDataType) * n);
if (_arr == nullptr)
{
perror("malloc fail");
return;
}
_top = 0;
_capacity = n;
}
~Stack() //析构函数
{
free(_arr);
_arr = nullptr;
_top = _capacity = 0;
}
private:
STDataType* _arr;
int _top;
int _capacity;
};
int main()
{
Stack st1;
Stack st2(st1);
return 0;
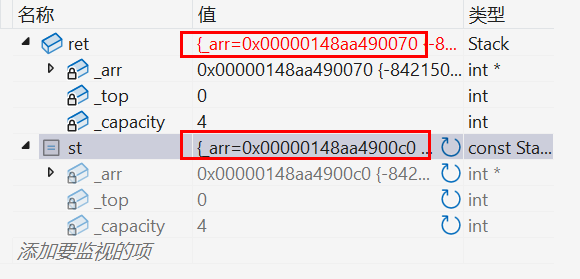
}上面我们讲了当没有显示实现拷贝构造时,则编译器会自动生成默认的拷贝构造,但自动生成的只能对内置类型的成员变量进行浅拷贝,也就类似于C语言中的 memcpy 函数,则在调试中会出现下面的结果:
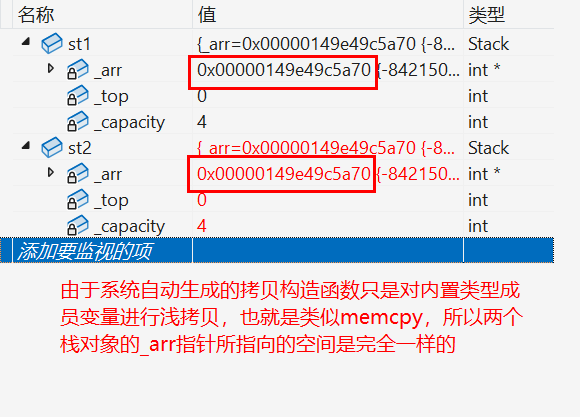
我们会发现由于浅拷贝会导致两个栈对象的 _a 指针所指向的空间都是一样的,当程序结束时调用析构函数就会出现问题了:
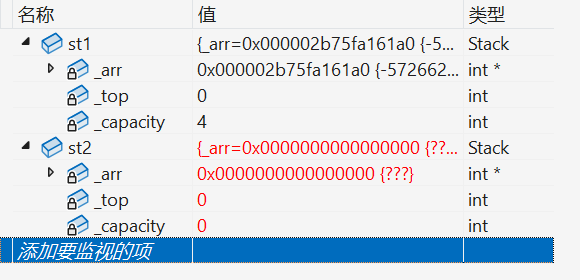
由前面学习析构函数的特点我们知道:后定义的对象会先被析构 。所以由上图所示先被析构 的对象是 st2 ,则接下来析构的是对象 st1,则问题就出来了:由于对象 st1 和 st2 的 _arr 指针所指向的空间是一样的,但是第一次 调用析构函数时我们已经将这块空间 free 了,则当我们第二次调用析构函数时不难知道会出现这个结果了:一块空间连续被 free 多次 。在C语言动态内存管理 中我们就已经讲过不能多次对同一块空间进行 free。
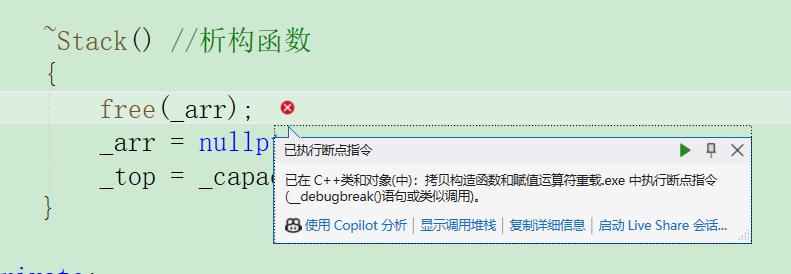
那我们怎么去解决这个问题呢?连续 free 同一块空间会出现问题,所以我们需要让两个栈对象的 _arr 所指向的空间不同,这就需要我们显示实现拷贝构造了。
正确示范(显示实现拷贝构造):
cpp
typedef int STDataType;
class Stack
{
public:
Stack(int n = 4) //全缺省的构造函数
{
_arr = (STDataType*)malloc(sizeof(STDataType) * n);
if (_arr == nullptr)
{
perror("malloc fail");
return;
}
_top = 0;
_capacity = n;
}
~Stack() //析构函数
{
free(_arr);
_arr = nullptr;
_top = _capacity = 0;
}
Stack(const Stack& st) //显示实现拷贝构造函数
{
_arr = (STDataType*)malloc(sizeof(STDataType) * st._capacity);
if (_arr == nullptr)
{
perror("malloc fail");
return;
}
memcpy(_arr, st._arr, sizeof(STDataType) * st._top);
//上面的代码才是深拷贝的核心逻辑:由于malloc函数开辟空间的位置是随机的,
//所以使得栈对象 st1 和 st2 所指向的空间不同,再用memcpy函数将 st1 的内容拷贝到 st2 中
_top = st._top;
_capacity = st._capacity;
}
private:
STDataType* _arr;
int _top;
int _capacity;
};
int main()
{
Stack st1;
Stack st2(st1);
Stack st3 = st1; //拷贝构造的第二种写法
return 0;
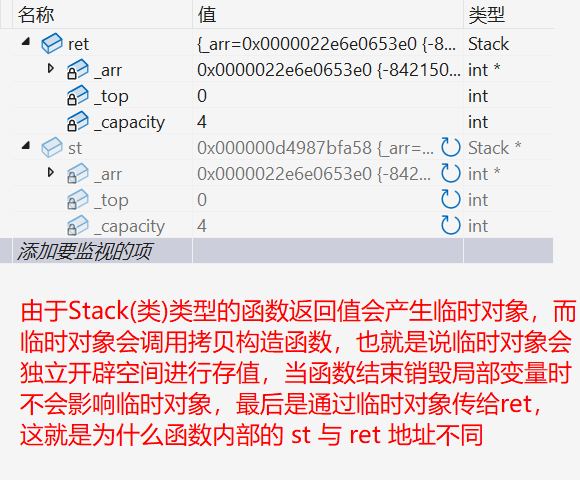
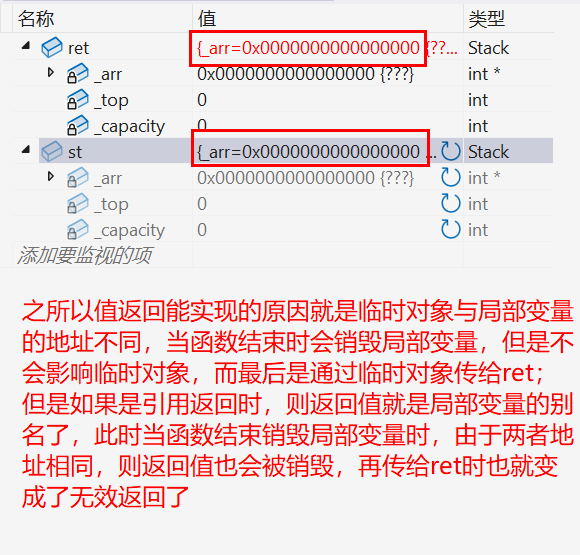
}6.传值返回 会产生一个临时对象 调用拷贝构造 ,传值引用返回 ,返回的是返回对象的别名 (引用),没有产生拷贝 。但是如果返回对象 是一个当前函数局部域 的局部对象 ,函数结束就销毁 了,那么使用引用返回是有问题 的,这时的引用相当于一个野引用 ,类似一个野指针一样。传引用返回可以减少拷贝 ,但是一定要确保返回对象在当前函数结束后还在,才能用引用返回。
传值返回:
cpp
typedef int STDataType;
class Stack
{
public:
Stack(int n = 4) //全缺省的构造函数
{
_arr = (STDataType*)malloc(sizeof(STDataType) * n);
if (_arr == nullptr)
{
perror("malloc fail");
return;
}
_top = 0;
_capacity = n;
}
~Stack() //析构函数
{
free(_arr);
_arr = nullptr;
_top = _capacity = 0;
}
Stack(const Stack& st) //显示实现拷贝构造函数
{
_arr = (STDataType*)malloc(sizeof(STDataType) * st._capacity);
if (_arr == nullptr)
{
perror("malloc fail");
return;
}
memcpy(_arr, st._arr, sizeof(STDataType) * st._top);
_top = st._top;
_capacity = st._capacity;
}
private:
STDataType* _arr;
int _top;
int _capacity;
};
Stack func() //如果返回对象是一个当前函数局部域的局部对象,传值返回不会有问题
{
Stack st;
return st;
}
int main()
{
Stack ret = func(); //由于返回的结果是类类型,所以结构上就是拷贝构造的第二种写法
return 0;
}
传值引用返回:
cpp
typedef int STDataType;
class Stack
{
public:
Stack(int n = 4) //全缺省的构造函数
{
_arr = (STDataType*)malloc(sizeof(STDataType) * n);
if (_arr == nullptr)
{
perror("malloc fail");
return;
}
_top = 0;
_capacity = n;
}
~Stack() //析构函数
{
free(_arr);
_arr = nullptr;
_top = _capacity = 0;
}
Stack(const Stack& st) //显示实现拷贝构造函数
{
_arr = (STDataType*)malloc(sizeof(STDataType) * st._capacity);
if (_arr == nullptr)
{
perror("malloc fail");
return;
}
memcpy(_arr, st._arr, sizeof(STDataType) * st._top);
_top = st._top;
_capacity = st._capacity;
}
private:
STDataType* _arr;
int _top;
int _capacity;
};
Stack& func() //但是如果是引用返回则会有问题
{
Stack st;
return st;
}
int main()
{
Stack ret = func(); //由于返回的结果是类类型,所以结构上就是拷贝构造的第二种写法
return 0;
}
那怎么样能够既可以利用引用返回来减少拷贝 ,又不想让函数返回时返回值被销毁 呢?我们可以利用static这个关键字,它能够使函数返回时局部变量不会被销毁而一直保留:
cpp
typedef int STDataType;
class Stack
{
public:
Stack(int n = 4) //全缺省的构造函数
{
_arr = (STDataType*)malloc(sizeof(STDataType) * n);
if (_arr == nullptr)
{
perror("malloc fail");
return;
}
_top = 0;
_capacity = n;
}
~Stack() //析构函数
{
free(_arr);
_arr = nullptr;
_top = _capacity = 0;
}
Stack(const Stack& st) //显示实现拷贝构造函数
{
_arr = (STDataType*)malloc(sizeof(STDataType) * st._capacity);
if (_arr == nullptr)
{
perror("malloc fail");
return;
}
memcpy(_arr, st._arr, sizeof(STDataType) * st._top);
_top = st._top;
_capacity = st._capacity;
}
private:
STDataType* _arr;
int _top;
int _capacity;
};
Stack& func() //这种写法就是对上面两个的优化:既可以利用引用返回来减少拷贝,利用 static 也不会让函数返回时返回值被销毁
{
static Stack st;
return st;
}
int main()
{
Stack ret = func(); //由于返回的结果是类类型,所以结构上就是拷贝构造的第二种写法
return 0;
}
结束语
到此,拷贝构造函数的特点就详细的讲解完了,内容量相较于前面两个函数还是比较多的,并且注意的点也更多,需要多去加以理解,但是在后面的学习中我们还会对拷贝构造函数的一些细节进行讲解,希望这篇文章对大家学习C++能有所帮助!
C++参考文档:
https://legacy.cplusplus.com/reference/
https://zh.cppreference.com/w/cpp
https://en.cppreference.com/w/