
摘要
随着生成式人工智能(Generative AI)和大语言模型(LLM)的突破性进展,销售赋能(Sales Enablement)领域正经历一场从静态脚本向动态仿真演进的范式转移。传统的销售培训依赖于固定的角色扮演脚本或人工陪练,存在成本高、反馈滞后、场景有限等弊端。现代 AI 销售陪练系统(AI Sales Coach)旨在构建一个具备高情商、实时反应能力且能够严格遵循销售方法论(如 MEDDIC、SPIN)的虚拟对练伙伴。
本报告旨在详尽阐述构建企业级 AI 销售陪练系统所需的技术架构、工程挑战及解决方案。报告将深入探讨:
- 架构选型: 级联架构与端到端语音模型(S2S)的权衡。
- 交互体验: 实时通话中的全双工(Full-Duplex)与打断(Barge-in)处理。
- 认知控制: 基于状态机(FSM)的对话管理与知识图谱增强的异议处理(RAG)。
- 评估体系: 基于销售方法论的多维度自动化评分体系。
通过对大量前沿研究与技术文档的综合分析,本报告揭示了实现"亚秒级"延迟与"类人"交互流畅度背后的工程复杂性,并为技术决策者提供了具体的实施路径。
1. 系统架构演进:从模块化级联到端到端语音模型
构建 AI 销售陪练的核心在于选择合适的语音交互流水线(Pipeline)。这一选择直接决定了系统的延迟表现、可控性及情感表达能力。
1.1 级联架构(Cascade Architecture):模块化的控制力与延迟困境
级联架构是当前企业级应用的主流选择,其工作流由 ASR(自动语音识别) -> LLM(大语言模型) -> TTS(文本转语音) 串联而成。
-
技术优势:
-
高可观察性与审计能力: 中间层的文本输出允许开发者进行正则匹配、敏感词过滤和逻辑校验,确保合规。
-
业务集成能力: 文本 LLM 擅长处理 Function Calling,能精准构造 API 请求(如查询 CRM、调用计算器),这是纯音频模型目前的短板。
-
组件解耦: 允许灵活拼装最优组件(如 Whisper v3 + Llama 3 + ElevenLabs),便于针对性优化。
-
核心劣势:延迟累积
一个交互回合的耗时通常包含:用户说话 -> VAD检测(~500ms) -> ASR(~200-400ms) -> LLM首字推理(~400-800ms) -> TTS首包合成(~200-500ms) -> 网络传输(~100ms)。端到端延迟往往超过 1.5 秒,破坏沉浸感,且文本转换过程会丢失语调等副语言信息。
1.2 端到端语音模型(Speech-to-Speech):极速与拟真
以 GPT-4o Audio 为代表,直接输入输出音频 Token,跳过中间文本环节。
-
技术突破:
-
超低延迟: 延迟有望降至 300-500ms,接近人类自然反应速度。
-
丰富情感: 原生理解并生成笑声、停顿、语速变化,能高保真模拟"愤怒客户"等压力环境。
-
工程挑战:
-
控制难点: 音频生成的"黑盒"性质导致传统文本过滤失效,难以拦截错误定价或违规承诺。
-
定制化门槛: 微调极其昂贵且数据稀缺,模仿特定口音往往需依赖少样本语音克隆(Zero-shot Cloning)。
1.3 2025年架构选型建议:混合路径
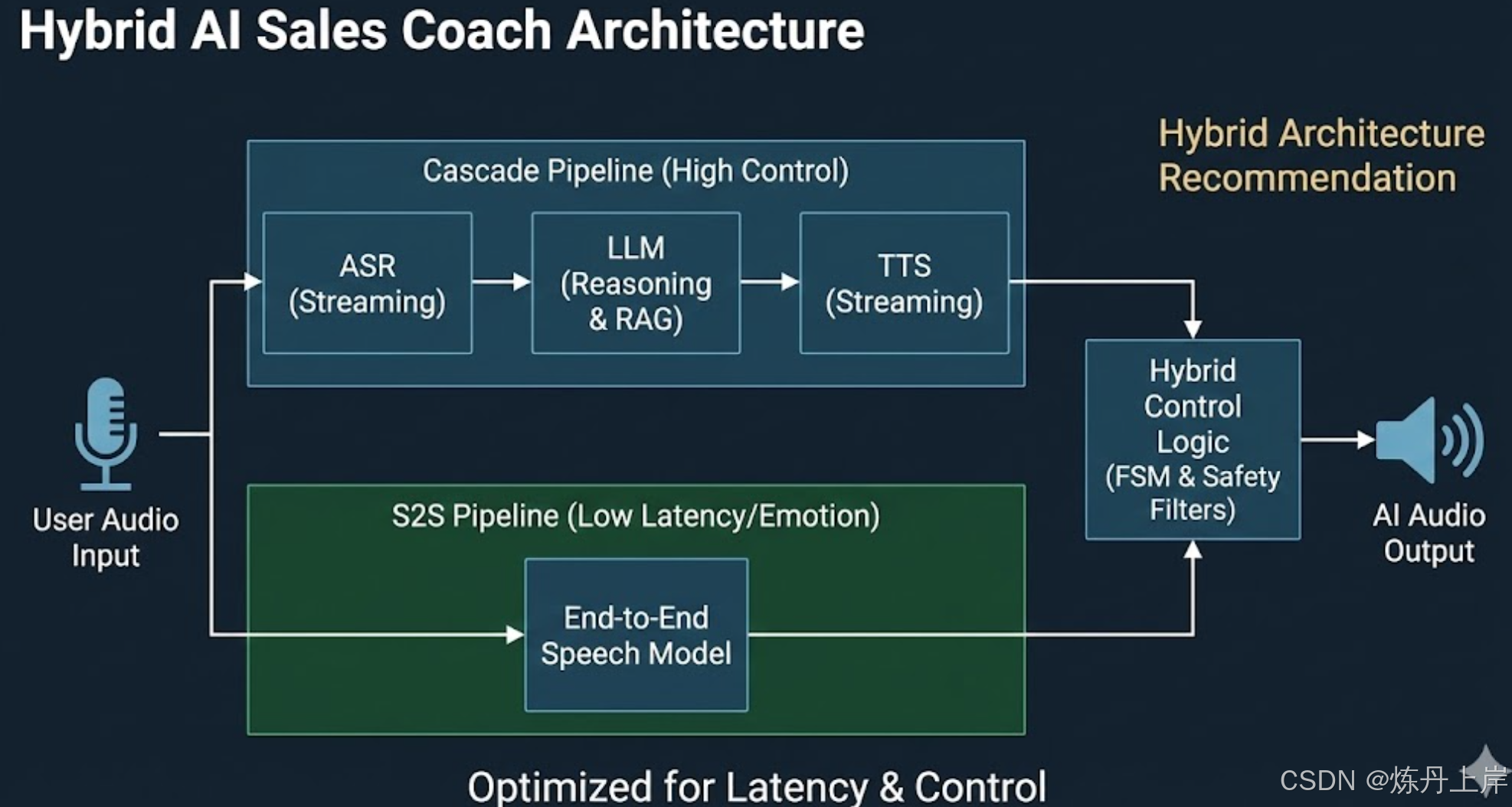
针对 AI 销售陪练场景,建议采用 混合架构(Hybrid Architecture):保留级联架构处理核心逻辑,在语音层引入流式优化,并在非关键环节引入 S2S 增强情感。
| 架构特性 | 级联架构 (Cascade) | 端到端语音 (S2S) | 混合架构 (Hybrid Recommendation) |
|---|---|---|---|
| 适用场景 | 复杂 B2B 销售、逻辑谈判、CRM 集成 | 情感陪练、破冰闲聊、发音纠正 | 全流程销售模拟 |
| 平均延迟 | 800ms - 2000ms | < 500ms | 500ms - 1000ms (优化后) |
| 可控性 | 极高 (正则/逻辑过滤) | 低 (依赖模型对齐) | 高 (关键节点文本校验) |
| 情感感知 | 弱 (仅依赖文本情感) | 强 (原生音频特征) | 中 (需辅助音频情感模型) |
2. 核心技术难点:实时通话中的全双工与低延迟工程
系统必须具备 全双工(Full-Duplex) 能力,即在"说"的同时保持"听",并智能处理打断。
2.1 延迟预算与流式优化策略
为了逼近人类 200ms 的自然轮替停顿,必须全链路实施流式处理:
- 流式 ASR: 持续输出中间转录结果(Partial Transcripts)。
- 推测性执行: 接收到部分文本即开始预加载 RAG 上下文或生成初步逻辑。
- 流式 TTS: LLM 生成 Token 即推送至 TTS,首字合成无需等待完整回复。
2.2 "打断"(Barge-in)处理机制与 VAD 调优

- 回声消除(AEC): 基于 WebRTC 内置算法,防止麦克风收录 AI 声音导致自循环。
- 语义 VAD: 区分"真正的打断"与"消极反馈(如'嗯'、'对')",避免错误中断 AI。
- 中断信号流: 一旦确认打断,立即执行原子操作:Send Interrupt Signal(停止生成) -> Clear Buffer(清空缓冲区) -> Truncate Context(截断上下文并拼接打断内容)。
- 参数调优: 精细调节
threshold和prefix_padding_ms,平衡噪音误触与灵敏度。
2.3 传输协议:WebRTC vs WebSocket
- WebSocket: 基于 TCP,抗弱网能力差,不适合极低延迟语音。
- WebRTC: 事实上的工业标准。基于 UDP,集成 AEC、降噪(NS)、自动增益(AGC)等媒体引擎,优先保证实时性。
- 难点: 需通过 SFU 或客户端流操作实现多路音频分离,以便后续的说话人区分与评分。
3. 认知智能与对话管理:从脚本到思维链
AI 必须遵循销售流程(如开场 -> 挖掘 -> 缔结),防止被用户带偏。
3.1 混合对话管理:有限状态机(FSM)+ LLM
引入 混合对话管理系统 解决 LLM 的不可控性:
- FSM(宏观控制): 定义状态(如
Discovery_Phase)和转移条件(如Budget_Confirmed=True)。 - LLM(微观生成): 基于当前状态动态注入 System Prompt(例如:"处于挖掘阶段,不要报价")。
3.2 知识检索增强(RAG):战卡(Battlecards)的数字化
传统 RAG 的模糊检索在逻辑对抗中往往失效。建议引入 GraphRAG(知识图谱 RAG) 或结构化 JSON Schema。
- 数据模型示例: 针对"竞品A便宜"的异议,结构化存储应包含
response_logic,强制 LLM 输出kill_shot_fact(如"竞品A额外收20%服务费"),而非通用废话。
3.3 提示词工程 vs 微调
- 提示词工程: 利用长上下文和 Few-Shot Learning 解决大部分逻辑控制和语气规范。
- 微调: 当需要特定的说话风格(如行业黑话)或调整 S2S 模型的语音韵律时使用。
4. 评估与反馈体系:从主观感到客观数据
4.1 销售方法论的数字化编码
系统打分必须基于 MEDDIC / SPIN 等方法论。
- LLM 裁判(LLM-as-a-Judge): 利用 思维链(Chain-of-Thought) 技术,要求 GPT-4 先引用原文证据再打分。
- 示例: "针对 Economic Buyer,先寻找询问决策流程的句子。若只问'你是决策者吗'得 1 分;若深入询问流程得 5 分"。
4.2 说话人分离(Speaker Diarization)
为确保评分准确,必须清楚每句话的归属。建议录制 Stereo Recording(独立音轨) 或使用高精度 Diarization 模型(如 Pyannote.audio)结合时间戳校准,防止因网络延迟导致的识别错误。
5. 基础设施与部署建议
- 成本与扩展性: ASR/TTS 部署于支持动态批处理的推理服务器(如 NVIDIA Triton);实施 滚动摘要(Rolling Summary) 机制控制 Token 成本。
- 数据隐私: 销售对话涉及商业机密,建议本地化部署或使用支持零数据保留(Zero Data Retention)的云服务。
6. 结论
构建优秀的 AI 销售陪练系统是音频工程、实时通信与认知科学的综合挑战。
- 技术核心: 在不稳定网络下利用 WebRTC 和流式架构实现 <500ms 延迟,并优雅处理"打断"。
- 业务核心: 利用 FSM 和 GraphRAG 约束 AI,使其成为遵循方法论的严师。
- 未来展望: 结合视觉分析(微表情)和屏幕互动,提供全维度沉浸式训练。
附录:核心技术栈参考
| 组件层级 | 推荐技术/模型 | 关键参数/配置建议 |
|---|---|---|
| 前端协议 | WebRTC (Client-side) | 开启 AEC, AGC, NS; 使用 DataChannel 传输控制信号 |
| VAD | Silero VAD / WebRTC VAD | Threshold: 0.5-0.7; Padding: 300ms; Min Speech: 100ms |
| ASR (STT) | Deepgram Nova-2 / Whisper v3 (Streaming) | 开启 Interim Results; 关键词增强 (Boost sales terms) |
| LLM (Brain) | GPT-4o / Llama 3 (Fine-tuned) | Temperature: 0.7; System Prompt 注入当前 FSM 状态 |
| TTS | ElevenLabs Turbo / Azure Neural TTS | 开启 Streaming; 预加载常用短语 (Prefetching) |
| 后端框架 | Python (FastAPI) / Go | 异步非阻塞架构; WebSocket/WebRTC 网关 |
| 数据库 | PostgreSQL (pgvector) + Neo4j | 混合检索 (Hybrid Search): 向量 + 知识图谱 |