全面解读 GPT-Image-1.5:ChatGPT 全新图像模型与体验
2025 年 12 月 16 日,OpenAI 正式发布了全新图像生成与编辑模型 GPT-Image-1.5 ,并在 ChatGPT 中推出了全新 ChatGPT Images 系统,让从图像创作到编辑的体验更直观、更强大、更快捷。该模型不仅作为 ChatGPT 内置图像引擎上线,同时可通过 OpenAI API 调用。

GPT-Image-1.5:旗舰图像模型
GPT-Image-1.5 是 OpenAI 最新的 旗舰级通用图像生成与编辑模型,旨在让图像创作既能符合用户的视觉想法,又能具备更高的质量与实用性。它在以下方面相比前代有显著提升:
✔ 精准编辑与保持细节一致性 -- 修改图像时更忠实用户指令,只改动指定内容,同时保留光线、构图、人物特征等重要元素。
✔ 指令遵循更强 -- 不仅能理解复杂要求,还能生成更符合预期的图像结果。
✔ 速度提升 -- 图像生成与编辑性能最高提升 4 倍,让迭代更快、更流畅。
✔ 文字渲染增强 -- 对图像内密集或小字号文字的表现能力有所增强。
这些改进意味着 GPT-Image-1.5 不仅适合娱乐创作,更具备生产级应用的潜力。

编辑与创造能力
GPT-Image-1.5 不仅能生成全新图像,还具备非常强的 编辑与组合能力。原官方博客按体验细节划分如下:
📌 精准保留关键细节
用户对已有图像提出编辑请求时,模型会:
-
只修改明确要求的部分;
-
保持其余元素(如光照、构图、人物面貌等)不变;
-
实现更真实的服装、发型等改动。
这种能力使得从简单修图到复杂重构都更可靠,适合实用性更强的应用场景。
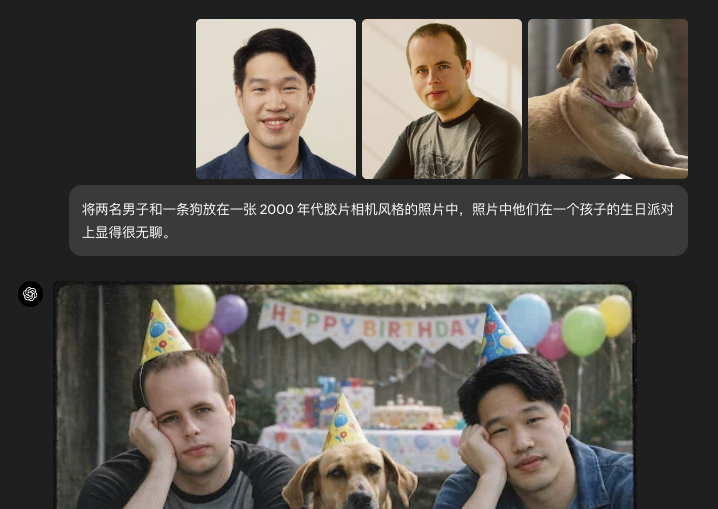
创意转换与视觉拓展
GPT-Image-1.5 在"创意变换"方面表现优异,例如:
-
建立从静物到电影海报风格的多层面图像;
-
添加或删减图像元素;
-
改变风格同时保留细节点。
这些创作过程通常只需要自然语言指令,降低了繁琐操作门槛。
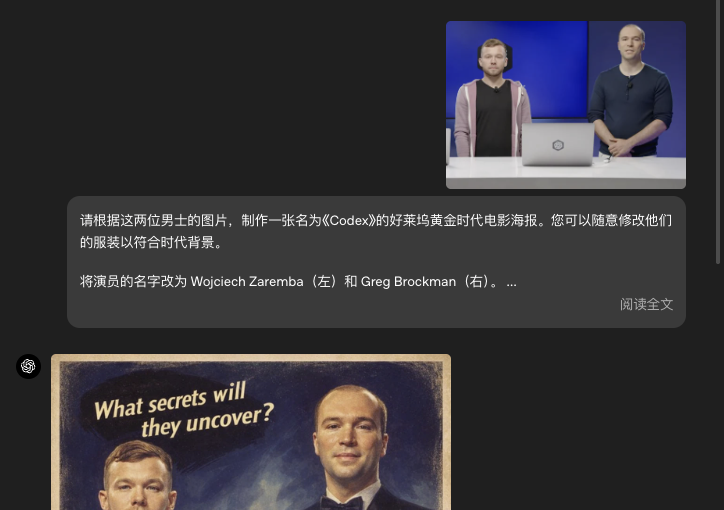
跟随指令更一致
新的模型相比旧版本在指令遵循方面更强,即使是复杂布局、元素关系和视觉逻辑,也能更准确理解和执行。
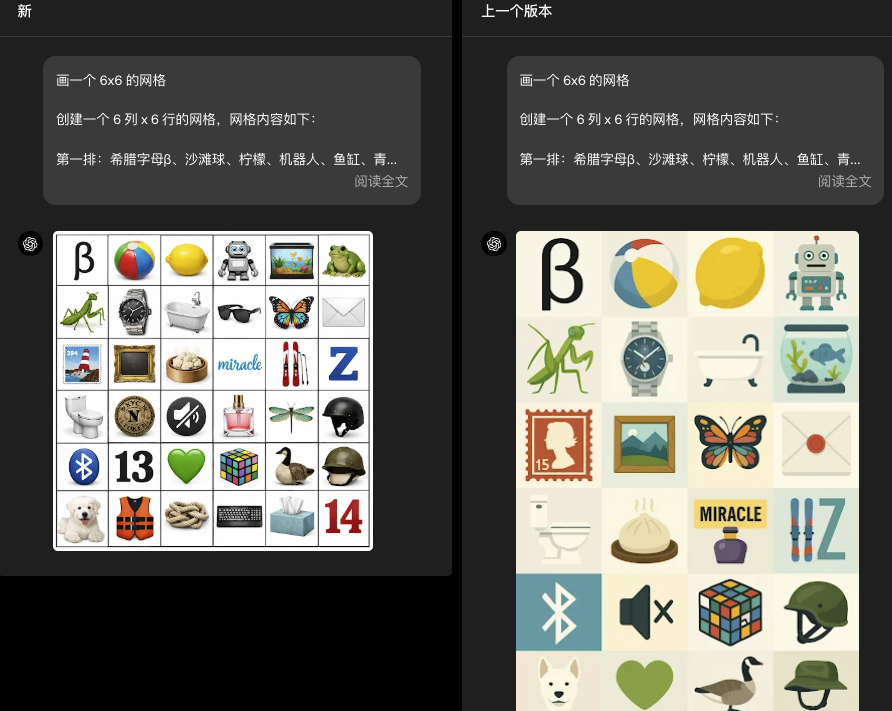
文本渲染与布局能力
GPT-Image-1.5 在原有基础上进一步增强了对 图像中文本内容的渲染能力,能够处理更密集、更小字体的文字布局,例如信息图、排版海报等,帮助用户实现更复杂的视觉设计输出。
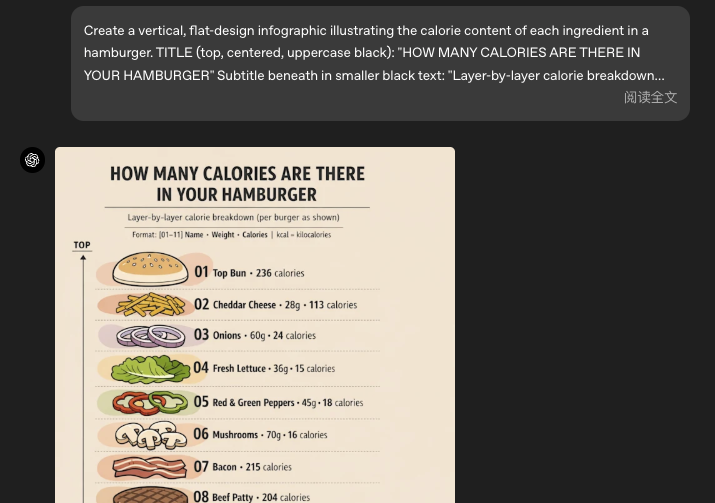
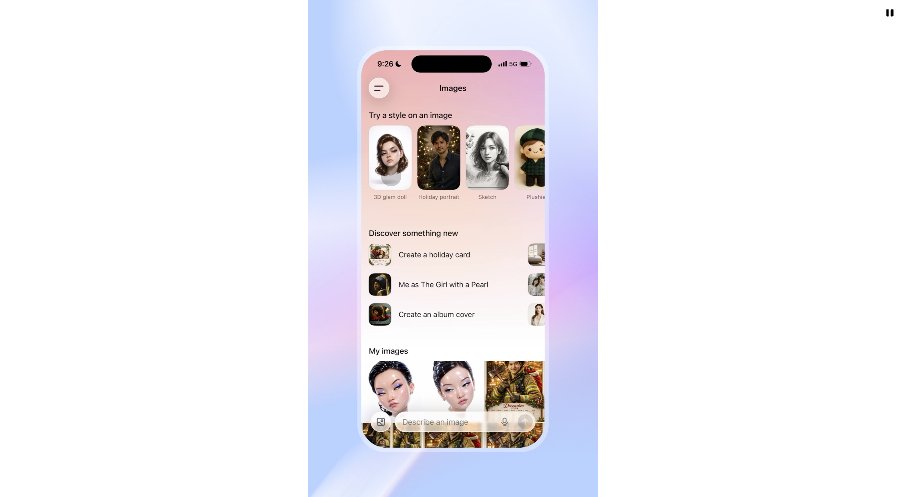
全新 "Images" 创作空间
为了让图像创作更便捷,OpenAI 在 ChatGPT 中新增了一个名为 "Images" 的界面版块,特色包括:
✅ 预设风格与提示模板,以少量输入快速启动创作;
✅ 一键创意尝试,无需复杂语句即可生成灵感图像;
✅ 快速浏览与管理已生成图像,提升创作与迭代效率。
"Images" 旨在让 ChatGPT 不只是文字生成工具,更是一体化的视觉创作空间。
API支持、价格、可视化测试
OpenAI 表示 GPT-Image-1.5 不仅面向普通 ChatGPT 用户,同时也通过 OpenAI API 对开发者开放。开发者可以借助新模型实现图像生成、编辑、变换等功能集成,为应用提供更丰富的视觉交互能力。
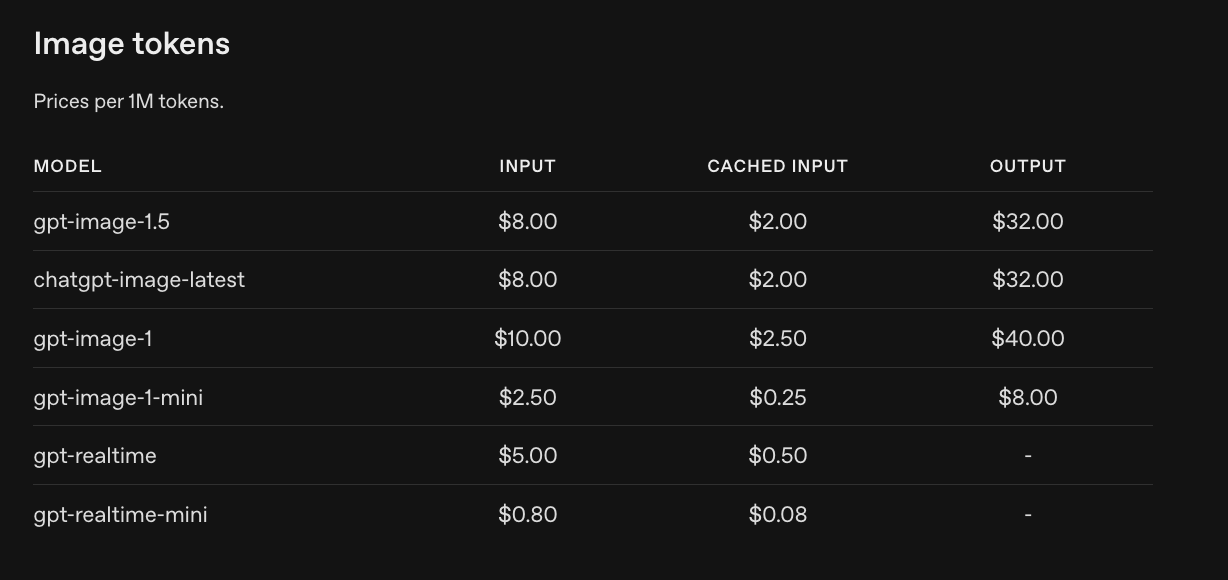
此外,相比上一代模型,新模型的图像输入与输出计费 降低约 20%,使得规模化应用更具成本效益。
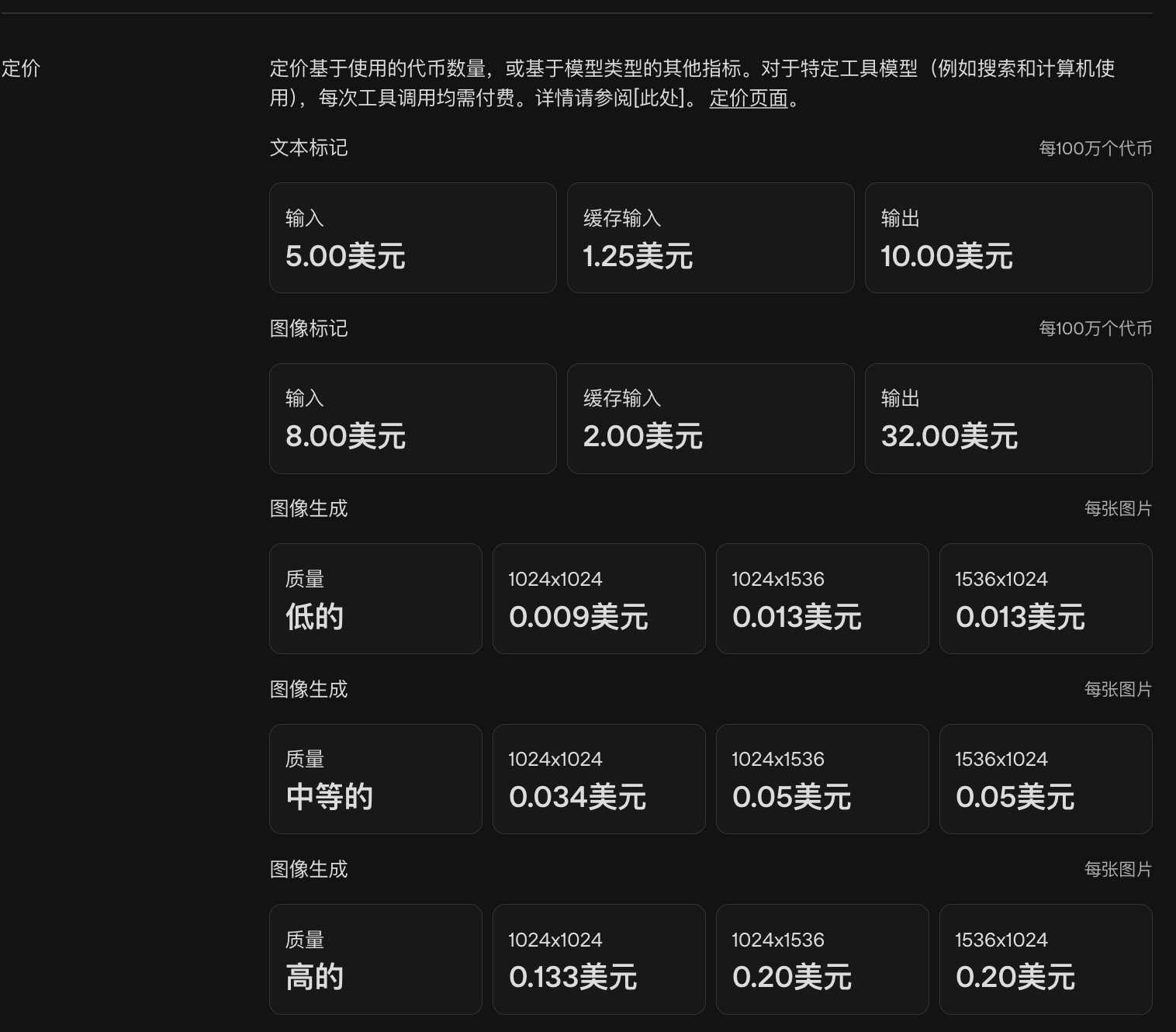
GPT-Image-1.5官方定价:
使用 "神马中转 API" 调用GPT-Image-1.5示例(Python)
📌 所有对话模型,都使用同一个接口:
POST /v1/chat/completions只需要把:
"model": "模型名"换成:
-
"gpt-image-1.5"
-
"claude-opus-4-5-20251101-thinking"
-
"gpt-5.1-2025-11-13"
-
...
即可调用对应模型,很统一、兼容 ChatCompletions 标准。
可直接调用gpt-image-1.5的 Python 代码
python
import http.client
import json
conn = http.client.HTTPSConnection("YOUR_SHENMA_API_DOMAIN")
payload = json.dumps({
"model": "gpt-image-1.5", # ← 换成要调用的模型名称
"messages": [
{
"role": "user",
"content": "画一只猫"
}
],
"stream": false,
})
headers = {
'Accept': 'application/json',
'Authorization': 'Bearer YOUR_API_KEY',
'Content-Type': 'application/json'
}
conn.request("POST", "/v1/chat/completions", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))可视化调用流程说明
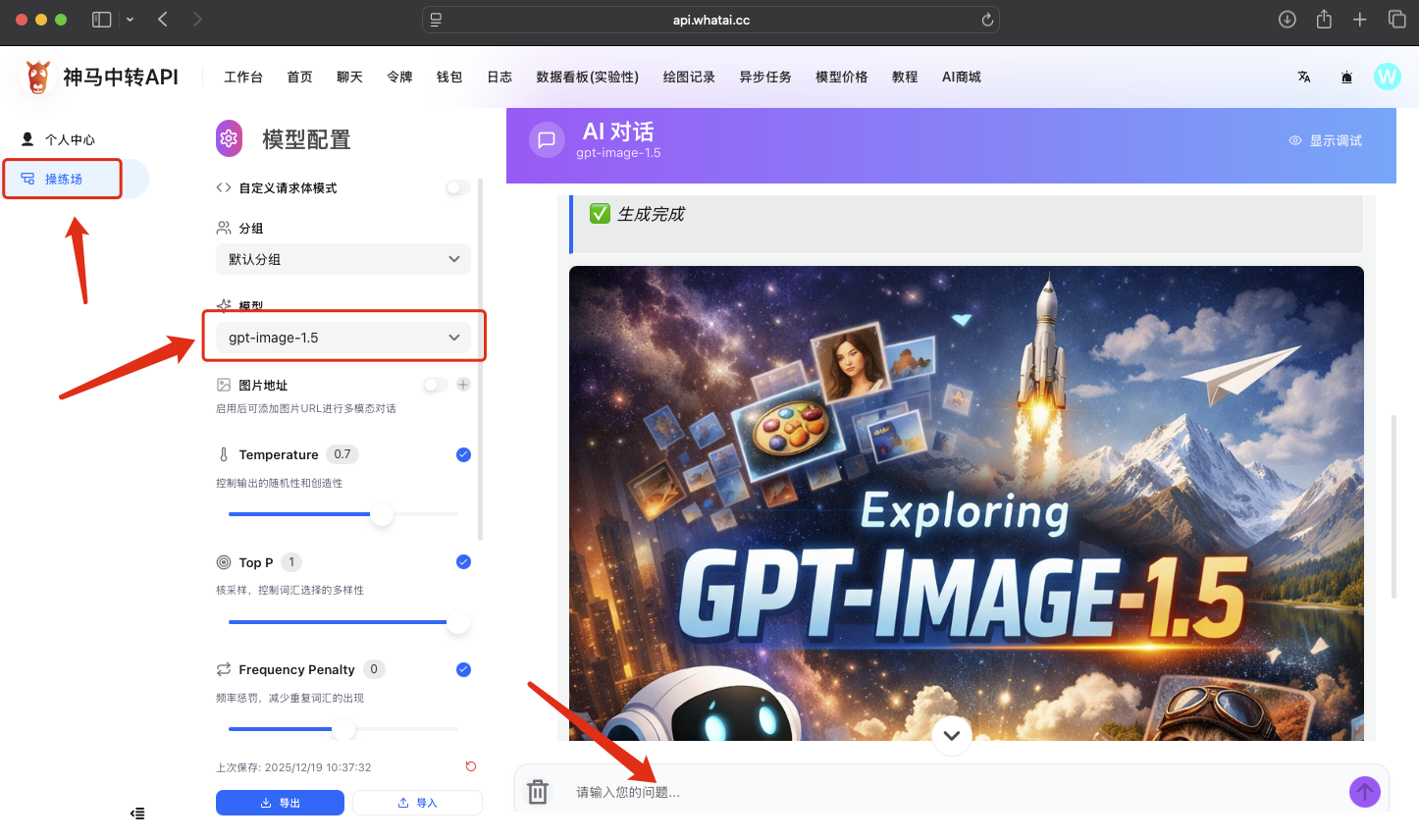
步骤:使用神⻢中转 API 首页 → 操练场
1️⃣ 登录 神马中转 API 首页
进入控制台后,左边导航栏会看到:
👉 「操练场」
2️⃣ 点击「操练场」
左侧会出现模型选择列表。
3️⃣ 选择模型
从左侧模型列表中选择:
✔ gpt-image-1.5
4️⃣ 输入你的提示词
比如
生成一张【GPT-Image-1.5】介绍文章的封面即可直接获得gpt-image-1.5生成的图片。
可用性、局限性与未来展望
官方提到 GPT-Image-1.5 展现出更强的实用性与细节控制能力,但仍处于图像生成技术不断迭代的阶段。有些复杂场景或特定真实感表现,还有持续优化空间。此外,在产业级竞争中,GPT-Image-1.5 正积极与其它先进模型展开比拼。
这表明未来的图像模型重点将从"能生成"转向"高质量、可用、智能"。

GPT-Image-1.5 的核心价值
GPT-Image-1.5 作为 OpenAI 的新旗舰图像模型,其关键优势可以概括为:
🔹 高保真与细节一致性编辑
🔹 更强的指令理解与执行能力
🔹 显著加速的生成与编辑效率
🔹 友好的无代码创作流程
🔹 API 支持与成本优化
这些能力让 GPT-Image-1.5 不仅适合创意表达,还可成为生产力工具链的重要组成部分。