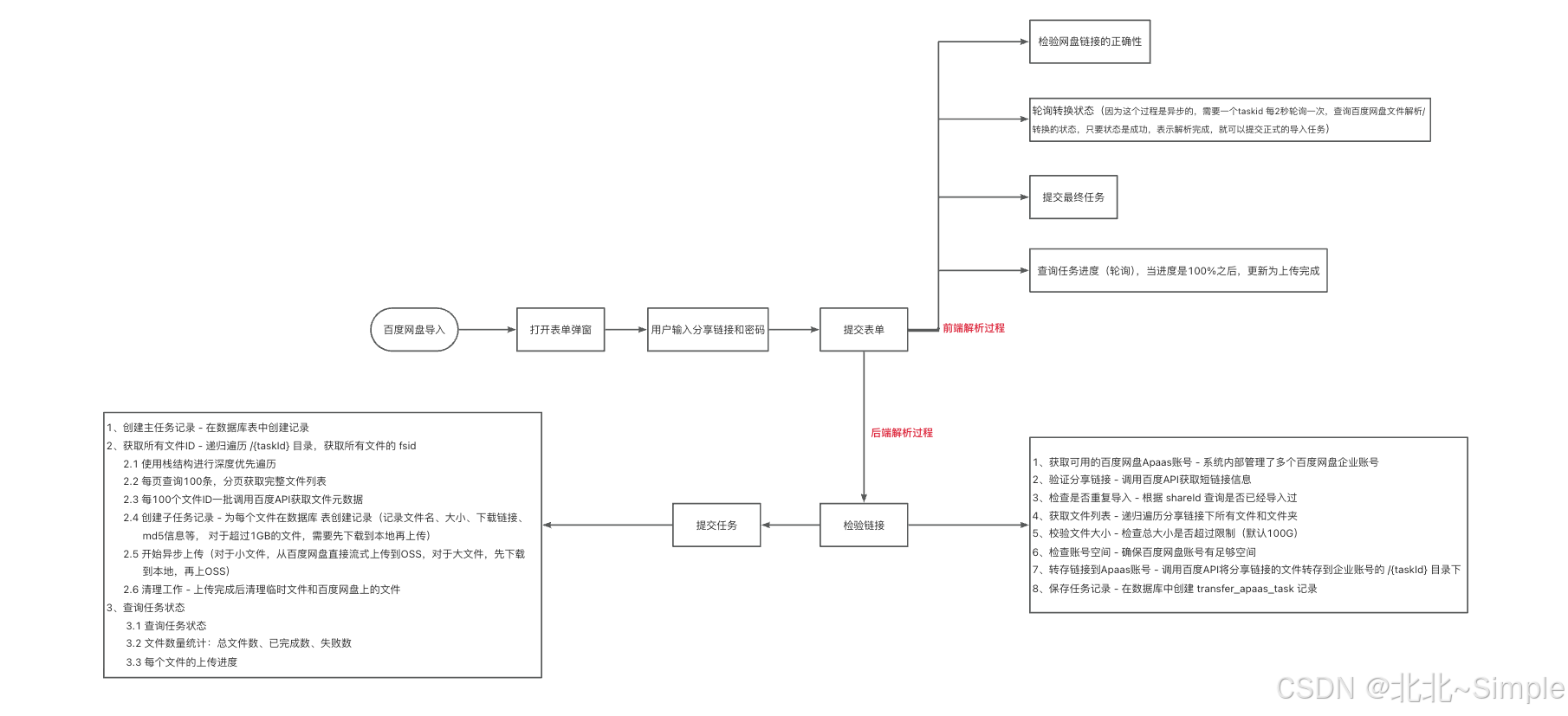
需求:根据百度分享的一个链接,进行解析,找到对应的文件,将文件上传到自己服务器上
实现流程图:
问题1: 为什么百度网盘要进行转存:
核心原因:用户分享链接不可靠!
1️⃣ 用户分享链接不稳定
用户可能的操作:
❌ 手动取消分享
❌ 删除原文件
❌ 修改提取码
❌ 分享链接过期(有些分享有时效性)
转存后:文件在系统企业账号中,不受用户操作影响!
2️⃣ 异步处理需要时间
用户分享链接 ↓直接开始下载第1个文件 ✅ ↓下载第2个文件 ✅ ↓【10分钟后,用户取消分享】 ↓下载第3个文件 ❌ 链接失效! ↓后续所有文件失败...
但是百度后台转存(可能几分钟到几小时,取决于文件大小)
转存后进行下载,就不用担心分享链接失效了,因为已经转存了
3️⃣ 权限控制问题
用户分享链接:
可能需要提取码访问、可能有访问次数限制、可能有下载速度限制
转存到企业账号后:
使用企业API访问(更稳定)、没有访问限制、企业级下载速度
4️⃣ 失败重试机制
如果下载失败,可以重试,因为:
✅ 文件已经转存了❌ 如果没转存,用户链接可能已经失效,无法重试
5️⃣ 并发控制
系统管理多个企业账号,可以:
多个用户同时导入不同的分享链接
每个任务独占一个账号
转存到各自的 /{taskId}/ 目录,互不干扰
问题2: 为什么超过1GB的文件要先下载到本地再上传?
"本地"指的是:运行这个Java应用的服务器(不是你的电脑,也不是百度网盘)
为什么要这样做?
1、流式上传的限制
从百度网盘URL直接流式上传到OSS有大小限制(默认1GB)
超过限制会导致内存溢出或连接超时
2、需要分片上传
大文件需要使用OSS的分片上传API(MultipartUpload)
分片上传需要随机访问文件内容
网络流无法随机访问,必须保存到本地
问题3: oss是什么?
OSS是一个通用概念,指对象存储服务
| 术语 | 含义 |
|---|---|
| 对象存储 | 通用概念 |
| OSS | Object Storage Service的缩写,也是通用概念 |
| 阿里云OSS | 阿里云的对象存储产品,恰好就叫OSS |
| 腾讯云COS | 腾讯云的对象存储产品 |
| AWS S3 | 亚马逊的对象存储产品 |
问题4: 涉及到的表
1、转存任务表:记录百度网盘转存任务的信息:记录任务id、百度分享链接、百度分享ID、转存路径、转存状态
2、vms_transfer_task(主任务表):记录整个导入任务的总体信息 : 任务唯一标识、平台类型(百度网盘/其他)、任务进度状态、任务详细信息(JSON)
3、vms_transfer_task_record(文件记录表):记录每个文件的上传信息:关联到 vms_transfer_task 的 ID、文件名、百度网盘下载链接、文件是否上传完成(0=未完成,1=完成,2=失败)、上传到OSS后的文件ID、OSS存储路径
问题5: 文件下载时机
🔴 大文件(≥1GB):先下载到服务器本地,再上传到OSS
🟢 小文件(<1GB):不下载,直接从百度网盘流式上传到OSS
完整的时间线:
用户操作:submitTask
↓ 立即返回 taskUid
↓
【后台异步执行】
↓
- 获取所有文件ID列表
例如:file1.jpg, video.mp4(2GB), doc.pdf
↓ - 创建 vms_transfer_task_record 记录
- file1.jpg (50MB) - 无localFilePath
- video.mp4 (2GB) - 有localFilePath=/data/download/...
- doc.pdf (10MB) - 无localFilePath
↓
- 开始遍历上传每个文件
↓
├─ file1.jpg (50MB)
│ → 小文件,直接流式上传
│ → 不下载!
│ → 百度URL → OSS ✅
│
├─ video.mp4 (2GB)
│ → 大文件,需要先下载
│ → ⏰ 此时触发下载!
│ → 百度URL → /data/download/xxx/video.mp4
│ → 下载完成,再上传到OSS
│ → /data/download/xxx/video.mp4 → OSS ✅
│
└─ doc.pdf (10MB)
→ 小文件,直接流式上传
→ 不下载!
→ 百度URL → OSS ✅
下载时机:
| 时间点 | 动作 | 是否下载 | |
|---|---|---|
| 是否下载 | 转存到企业账号 | ❌ 不下载 |
| submitTask开始 | 创建任务记录 | ❌ 不下载 |
| submitTask异步 | 获取文件列表 | ❌ 不下载 |
| 上传小文件时 | 流式传输 | ❌ 不下载 |
| 上传大文件时 | 先下载再上传 | ✅ 此时下载! |
问题6: 大文件下载失败处理机制
失败处理的层次结构:
第1层:分片级别重试(每个分片重试1次)
↓ 失败
第2层:整体下载重试(整个文件重试3次)
↓ 失败
第3层:记录失败状态(标记该文件失败)
↓ 失败
第4层:任务继续/终止(根据策略决
🔍 第1层:分片级别的重试
单个分片失败时:
✅ 第1次下载失败 → 立即重试1次
❌ 第2次还是失败 → 返回 "FAIL",终止整个文件下载
⚠️ 不继续下载后续分片,避免浪费资源
分片下载的错误处理:
错误场景:
🔴 HTTP状态码非200/206 → 返回false
🔴 网络超时(连接超时5秒,读取超时20秒)→ 抛异常,返回false
🔴 任何其他异常 → 捕获并返回false
🔄 第2层:整体下载的重试
处理逻辑:
第1次尝试:
→ downloadFile() → FAIL
↓
第2次尝试:
→ downloadFile() → FAIL
↓
第3次尝试:
→ downloadFile() → FAIL
↓
抛出异常,进入第3层处理
📝 第3层:记录失败状态
更新数据库记录
失败后的操作:
❌ 更新 vms_transfer_task_record 表
assetTransferred = 2(失败状态)
这个更新vms_transfer_task_record表的原因是:这个vms_transfer_task_record是记录上传的情况的,但是由于下载和上传是一起的,因为下载失败了,造成上传也失败了
📝 记录错误日志
🚫 抛出异常,终止当前任务
🔍 第4层:任务级别的处理
验证步骤:
✅ 文件大小验证:localFile.length() == 预期大小
✅ MD5校验:计算的MD5 == 百度返回的MD5
❌ 任何一个不通过 → 返回 "FAIL"
可能的失败原因:
| 失败原因 | 触发位置 | 处理方式 |
|---|---|---|
| 🔴 网络超时 | downloadChunk | 分片重试1次 |
| 🔴 HTTP错误码 | downloadChunk | 分片重试1次 |
| 🔴 连续2次分片失败 | downloadFile | 终止下载,整体重试 |
| 🔴 文件大小不符 | downloadFile | 返回FAIL,整体重试 |
| 🔴 MD5校验失败 | downloadFile | 返回FAIL,整体重试 |
| 🔴 连续3次整体失败 | doRetry | 标记失败,抛异常 |
| 🔴 用户取消任务 | downloadFile | 返回CANCEL |
失败流程图:
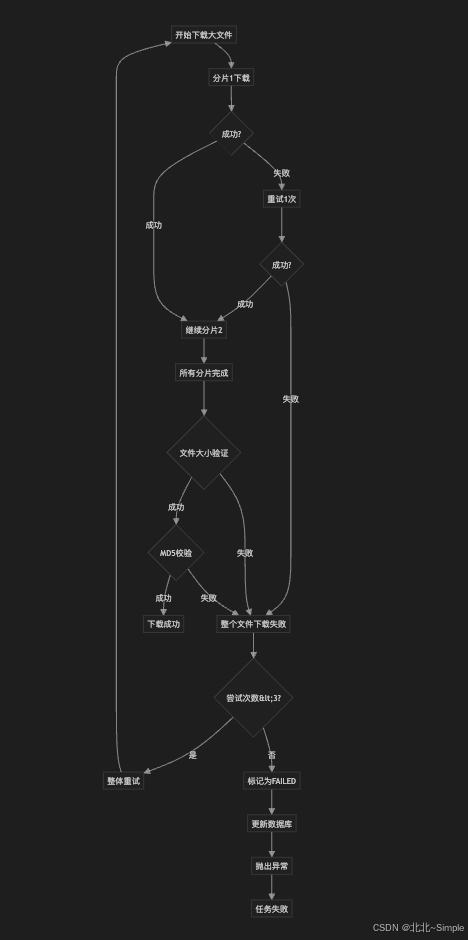
💡 实际例子:下载2GB视频,第50片失败
graph TD
A开始下载大文件 --> B分片1下载
B --> C{成功?}
C -->|失败| D重试1次
D --> E{成功?}
E -->|失败| F整个文件下载失败
E -->|成功| G继续分片2
C -->|成功| G
G --> H[所有分片完成]
H --> I{文件大小验证}
I -->|失败| F
I -->|成功| J{MD5校验}
J -->|失败| F
J -->|成功| K[下载成功]
F --> L{尝试次数<3?}
L -->|是| M[整体重试]
M --> A
L -->|否| N[标记为FAILED]
N --> O[更新数据库]
O --> P[抛出异常]
P --> Q[任务失败]场景:网络极差,连续3次都失败
文件:video.mp4 (2GB)
分片大小:30MB
总分片数:68片
进度:
片1-49: ✅ 成功(已下载 1.47GB)
片50: ❌ 失败
↓
【分片重试】
片50 重试: ❌ 再次失败
↓
【终止当前下载】
返回 "FAIL",已下载的1.47GB保留在磁盘
↓
【整体重试 - 第1次】
检测到本地文件 1.47GB,但不完整
删除本地文件
重新开始下载:
片1-68: ✅ 全部成功
文件大小验证: ✅ 通过
MD5校验: ✅ 通过
↓
【下载成功】✅
继续上传到OSS
📝 总结
大文件下载失败的处理策略:
分片级别:每片重试1次(最多2次机会)
文件级别:整体重试3次
验证级别:大小+MD5双重校验
记录级别:标记失败状态到数据库
任务级别:抛出异常,终止任务
设计优势:
✅ 网络波动不影响(自动重试)
✅ 数据完整性保证(MD5校验)
✅ 资源不浪费(分片重试而非全部重试)
✅ 状态可追踪(数据库记录)
✅ 用户友好(可以查看失败原因)
问题7:什么是分片上传和断点续传啊
分片上传(Multipart Upload)
🍕 生活例子:吃披萨
想象你要吃一个超大披萨:
❌ 一口吞(普通上传):- 披萨太大,嘴巴塞不下- 容易噎住- 失败了要重吃整个披萨✅ 切成小块吃(分片上传):- 把披萨切成8块- 一块一块地吃- 某一块掉了,只需要重吃那一块
💻 技术解释
分片上传 = 把大文件切成小块,分别上传
]
📊 实际例子
假设要下载一个 300MB 的视频:
文件大小:300MB分片大小:30MB (CHUNK_SIZE)分片数量:300 ÷ 30 = 10片分片1: 0MB - 30MB (bytes 0 - 31457279)分片2: 30MB - 60MB (bytes 31457280 - 62914559)分片3: 60MB - 90MB (bytes 62914560 - 94371839)...分片10: 270MB - 300MB (bytes 283115520 - 314572799)
下载过程:
for (int i = 0; i < 10; i++) { downloadChunk(url, file, startByte, endByte, i, 10); // 第1片:下载 0-30MB ✅ // 第2片:下载 30-60MB ✅ // 第3片:下载 60-90MB ❌ 失败! // 重试第3片 ✅ // 第4片:继续...}
🔄 二、断点续传(Resume Upload)
📚 生活例子:看书
想象你在读一本厚书:
❌ 没有书签(无断点续传):- 今天读到第50页- 明天忘记读到哪了- 只能从第1页重新开始✅ 有书签(断点续传):- 今天读到第50页,放个书签- 明天打开书,从第50页继续读- 节省时间,不用重复
💻 技术解释
断点续传 = 传输中断后,从上次的位置继续,不用重新开始
📊 实际场景
场景:上传1GB的文件(分成20片,每片50MB)
第一次尝试:片1 ✅ 已上传片2 ✅ 已上传片3 ✅ 已上传片4 ✅ 已上传片5 ❌ 网络断了!❌ 如果没有断点续传:- 重新开始- 片1-4 需要重新上传(浪费!)✅ 如果有断点续传:- 检查:片1-4 已上传 ✅- 从片5继续上传- 节省时间和流量
🔍 三、下载的分片+断点续传体现:
检查本地文件是否存在
如果文件大小正确且MD5匹配 → 直接返回成功(不重复下载)
否则删除重新下载
上传的分片+断点续传
特性:
分片大小:50MB (PART_SIZE)
并发线程:根据文件大小动态调整(1/3/5个线程)
断点续传:setEnableCheckpoint(true)
📊 四、对比表格
特性 普通上传 分片上传 分片+断点续传
文件大小限制 小文件 大文件可以 大文件可以
失败后 重新上传全部 重传失败的片 从断点继续
速度 慢 快(可并发) 最快
内存占用 高(整个文件) 低(只加载一片) 低
网络要求 必须稳定 容忍小故障 容忍断网
🎯 五、实际应用场景
场景1:下载2GB的视频
普通下载(❌ 不现实):- 一次性下载2GB- 中间断网 → 重新下载2GB- 需要稳定网络持续2小时分片下载(✅ 可行):- 分成67片(每片30MB)- 某一片失败 → 只重传30MB- 网络不稳定也能完成分片+断点续传(✅✅ 最佳):- 今天下载到50%,断网了- 明天继续从50%开始- 不浪费已下载的1GB
场景2:上传1GB的设计文件
普通上传:- 上传到90%,网络波动- 失败,重新上传1GB- 浪费时间和流量分片+断点续传:- 上传到90%(18/20片)- 网络波动,只重传失败的2片- 总共只重传100MB
💡 六、为什么需要这些技术?
- 大文件传输困难
100MB文件:还可以一次传1GB文件:一次传很容易失败10GB文件:几乎不可能一次传成功 - 网络不稳定
办公室网络:可能突然断开移动网络:信号时好时坏跨国传输:延迟高、丢包多 - 用户体验
❌ 没有断点续传:用户上传到99%,断网了→ 用户:😭 要重新上传?我不干了!✅ 有断点续传:用户上传到99%,断网了→ 网络恢复后,从99%继续→ 用户:😊 太好了!
🔑 七、HTTP Range请求(技术细节)
分片下载的底层原理:
// 请求第3片(60MB-90MB)request.setHeader("Range", "bytes=62914560-94371839");
HTTP响应:
HTTP/1.1 206 Partial ContentContent-Range: bytes 62914560-94371839/314572800Content-Length: 31457280这一片的数据...
206 Partial Content = 部分内容,支持分片!
📝 八、总结
分片上传
定义:把大文件切成小块分别传输目的:降低单次传输失败的影响比喻:把整个披萨切成小块吃
断点续传
定义:传输中断后从断点继续,不重头开始目的:节省时间和流量比喻:读书时用书签标记进度
在这个项目中
下载百度网盘文件
分片大小:30MB
支持断点续传(通过检查本地文件)
上传到OSS
分片大小:50MB
并发上传:1-5个线程
阿里云SDK自动处理断点续传
为什么重要?
❌ 没有这些技术:- 大文件传不了- 网络不稳定就失败- 用户体验差✅ 有这些技术:- 10GB文件也能传- 断网重连也能继续