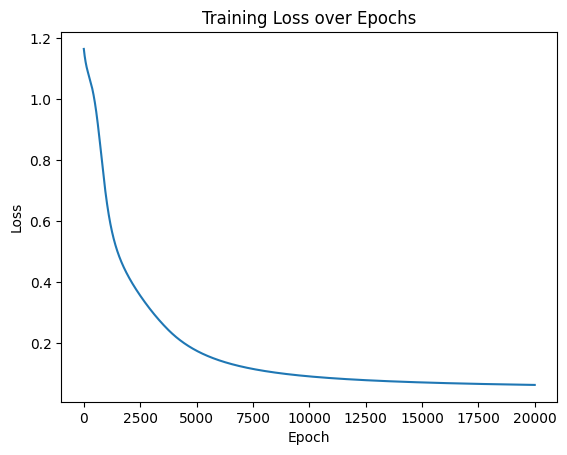
模型可视化和推理

clike
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import random
# =====================
# 1. 固定随机种子(保证可复现)
# =====================
seed = 42
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
# =====================
# 2. 加载与预处理数据
# =====================
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=seed
)
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)
# =====================
# 3. 定义 MLP 模型
# =====================
class MLP(nn.Module):
def __init__(self, hidden_dim):
super().__init__()
self.fc1 = nn.Linear(4, hidden_dim)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_dim, 3)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# =====================
# 4. 准确率函数
# =====================
def accuracy(logits, y):
preds = torch.argmax(logits, dim=1)
return (preds == y).float().mean().item()
# =====================
# 5. 训练函数(核心)
# =====================
def train_model(hidden_dim, optimizer_name, lr, weight_decay, epochs=2000):
model = MLP(hidden_dim)
criterion = nn.CrossEntropyLoss()
if optimizer_name == "SGD":
optimizer = optim.SGD(
model.parameters(),
lr=lr,
momentum=0.9,
weight_decay=weight_decay
)
else:
optimizer = optim.Adam(
model.parameters(),
lr=lr,
weight_decay=weight_decay
)
best_test_acc = 0.0
losses = []
for epoch in range(epochs):
# forward
outputs = model(X_train)
loss = criterion(outputs, y_train)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.item())
# evaluation
if (epoch + 1) % 200 == 0:
with torch.no_grad():
train_acc = accuracy(model(X_train), y_train)
test_acc = accuracy(model(X_test), y_test)
best_test_acc = max(best_test_acc, test_acc)
return best_test_acc, losses
# =====================
# 6. 超参数组合(对比实验)
# =====================
experiments = [
# 学习率对比(SGD)
{"hidden": 10, "opt": "SGD", "lr": 0.1, "wd": 0.0},
{"hidden": 10, "opt": "SGD", "lr": 0.01, "wd": 0.0},
{"hidden": 10, "opt": "SGD", "lr": 0.001, "wd": 0.0},
# 优化器对比
{"hidden": 10, "opt": "Adam", "lr": 0.001, "wd": 0.0},
# 隐藏层大小对比
{"hidden": 4, "opt": "Adam", "lr": 0.001, "wd": 0.0},
{"hidden": 32, "opt": "Adam", "lr": 0.001, "wd": 0.0},
# 正则化对比
{"hidden": 10, "opt": "Adam", "lr": 0.001, "wd": 1e-4},
{"hidden": 10, "opt": "Adam", "lr": 0.001, "wd": 1e-3},
]
# =====================
# 7. 运行实验
# =====================
results = []
for i, cfg in enumerate(experiments):
print(f"\nRunning Experiment {i+1}/{len(experiments)}: {cfg}")
best_acc, _ = train_model(
hidden_dim=cfg["hidden"],
optimizer_name=cfg["opt"],
lr=cfg["lr"],
weight_decay=cfg["wd"]
)
results.append({
**cfg,
"best_test_acc": best_acc
})
# =====================
# 8. 打印最终对比结果
# =====================
print("\n========== Final Results ==========")
print("hidden | opt | lr | weight_decay | best_test_acc")
print("-" * 55)
for r in results:
print(
f"{r['hidden']:>6} | "
f"{r['opt']:<4} | "
f"{r['lr']:<6} | "
f"{r['wd']:<12} | "
f"{r['best_test_acc']:.4f}"
)