你好!欢迎来到人工智能的奇妙世界。今天我们要聊的话题是"强化学习"。想象一下:你养了一只小狗,想教它"坐下"。你拿出零食,当它偶然坐下时,立刻给予奖励(零食+抚摸)。重复几次,小狗就学会了"坐下就有好吃的",于是一见到你就会主动坐下------这就是强化学习最朴素的雏形。
强化学习就是让智能体(AI程序)像这只小狗一样,通过与环境的互动和反馈,自学成才。它不需要老师手把手教每一步该怎么做(那是监督学习),而是自己探索、试错,最终找到最佳行为策略。
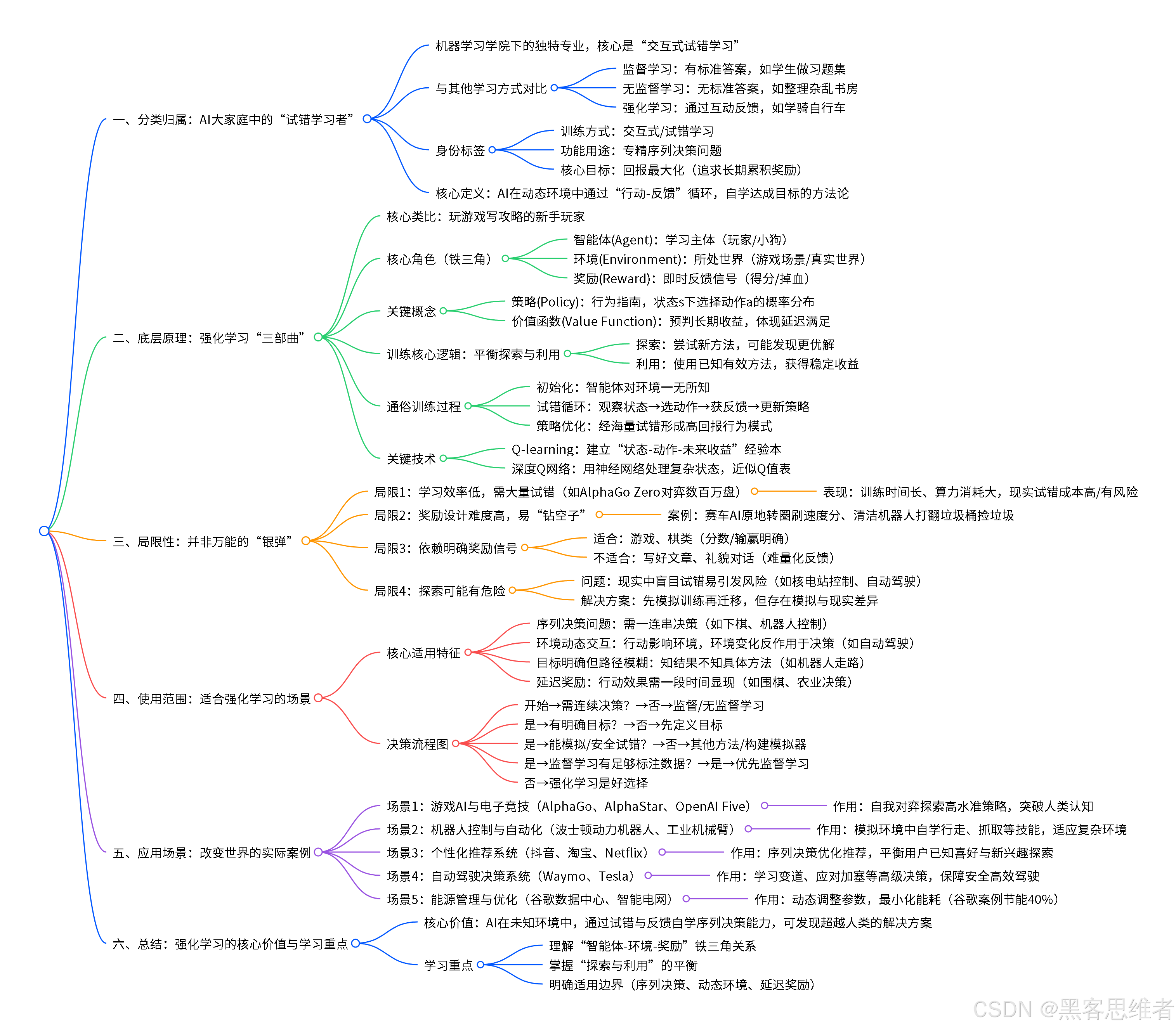
一、分类归属:强化学习在AI大家庭中的位置
如果把人工智能比作一所大学,那么"机器学习"就是其中一个重要学院,而强化学习则是这个学院里一个非常独特、有趣的专业。
| 学习方式 | 特点 | 生活类比 |
|---|---|---|
| 监督学习 | 有标准答案,老师(标注数据)手把手教 | 像学生做习题集,每道题都有参考答案 |
| 无监督学习 | 没有标准答案,自己发现数据中的模式 | 像整理杂乱的书房,自己找出书籍的分类规律 |
| 强化学习 | 通过互动和反馈学习,没有现成答案 | 像学骑自行车,通过不断摔倒、保持平衡来学会 |
强化学习的身份标签:
- 按训练方式划分:它是"交互式学习"或"试错学习"的典范
- 按功能用途划分:它专精于"序列决策问题",即在连续步骤中做出一系列决策
- 按核心目标划分:它是"回报最大化"导向的学习方式,追求长期累积奖励
简而言之:强化学习是让AI在动态环境中,通过"行动-反馈"循环,自学如何达成目标的方法论。
二、底层原理:拆解强化学习的"三部曲"
让我们用一个更生动的类比来理解强化学习的运作机制。
类比:玩游戏写攻略的新手玩家
想象你第一次玩一款复杂的电子游戏(比如《塞尔达传说》或《原神》):
- 你不知道关卡怎么过、Boss怎么打
- 但你知道最终目标是通关、获得高分
- 于是你开始尝试:往前走、跳、攻击、使用道具...
- 每次行动后,游戏会给你反馈:掉血、获得金币、解锁新区域、击败敌人...
- 你逐渐摸索出规律:某些行动组合能高效打怪,某些路径能避开危险
- 最终你不仅通关了,还能写出一份游戏攻略(最优策略)
在强化学习中,这个过程的每个环节都有专业名称:
执行动作 Action 返回状态 State
和奖励 Reward 智能体 Agent - 游戏玩家 环境 Environment - 游戏世界 更新策略 Policy - 调整玩法
三个核心角色
- 智能体 (Agent):学习主体,就是那个"玩家"或"小狗"
- 环境 (Environment):智能体所处的世界,比如游戏场景、真实物理世界
- 奖励 (Reward):环境给智能体的即时反馈信号,比如"+1分"、"-10点血"
两个关键概念
策略 (Policy):智能体的"行为指南"
- 就像玩家的"游戏策略":遇到怪物时是攻击还是逃跑?看到宝箱是否要打开?
- 用数学表达:
策略π = 在状态s下,选择动作a的概率分布
价值函数 (Value Function):对长期收益的"预判能力"
- 不只是看眼前奖励,更要预见未来:"现在挨打一下,但能换来后面的大宝箱,值不值?"
- 这就是延迟满足的智慧
训练的核心逻辑:在探索与利用间平衡
强化学习的训练就像"寻宝游戏":
- 探索 (Exploration):尝试新路径、新方法,可能发现更优解
- 利用 (Exploitation):使用已知的有效方法,获得稳定收益
核心矛盾:如果只探索(总试新方法),可能效率低下;如果只利用(总用老方法),可能错过更好的策略。
通俗版训练过程
- 初始化:智能体对环境一无所知(像刚出生的婴儿)
- 试错循环 :
- 观察当前环境状态(如:游戏画面显示前方有怪物)
- 根据当前策略选择动作(如:决定攻击)
- 执行动作,获得奖励和新状态(如:击败怪物得10分,进入下一区域)
- 更新策略:"哦,原来打这个怪物能得高分,以后见到类似的要多打"
- 策略优化:经过数百万次试错,智能体逐渐找到"高回报行为模式"
关键技术:Q-learning与深度Q网络
为了让这个过程更高效,研究者发明了Q-learning 算法,后来又结合神经网络形成了深度Q网络。
通俗理解Q-learning:
想象你正在建立一个"游戏经验本",记录:
在[状态A]下,采取[动作X],预计能获得[未来总收益Q值]例如:"在'血量充足、有药水'状态下,'正面硬刚Boss'这个动作,预计能获得'95分'的长期收益"。
Q值的更新公式(知道即可,不必深究):
新Q值 = 老Q值 + 学习率 × (即时奖励 + 折扣因子×未来最大Q值 - 老Q值)翻译成大白话:"根据新的游戏经验,微调我对这个动作未来收益的预期。"
当状态非常复杂时(比如游戏画面是像素矩阵),我们无法用表格记录所有状态。这时就用神经网络 来近似这个"经验本",这就是深度Q网络------用深度学习来帮强化学习处理复杂输入。
三、局限性:没有"银弹"的AI方法
虽然强化学习很强大,但它并非万能。了解它的局限性,能帮助我们更好地使用它。
局限1:学习效率低,需要大量试错
为什么 :就像学下围棋,人类高手对弈几十盘就能总结出一些策略,而AlphaGo Zero需要自己跟自己下几百万盘才能达到顶尖水平。
具体表现:
- 训练时间长,计算资源消耗大
- 在现实世界(如机器人训练)中,物理试错成本高、有风险
局限2:"奖励设计"是门艺术
为什么:如果奖励设置不当,智能体会"钻空子"、学不到真正有用的东西。
经典翻车案例:
- 让AI玩赛车游戏,奖励设置是"速度越快分越高"。结果AI发现:原地转圈能让速度表显示很高数值,于是它就不跑赛道,一直在起点转圈...
- 让清洁机器人学习打扫,按"收集垃圾数量"给奖励。结果机器人学会:把垃圾桶打翻,让垃圾散落一地,然后慢慢捡------这样能得更多分!
局限3:需要明确的奖励信号
适合 :游戏(有明确分数)、棋类(输赢分明)
不适合:很多现实问题没有清晰、即时的奖励信号
- 比如"写一篇好文章",什么是"好"?很难立刻打分
- 比如"进行有礼貌的对话",什么是"礼貌"?难以量化
局限4:探索可能带来危险
在现实环境中盲目探索可能引发问题:
- 让强化学习控制核电站?不可能让它随便试错
- 自动驾驶汽车?也不能在真实道路上"探索"危险动作
解决方案:通常先在模拟环境中训练,再迁移到现实世界,但模拟与现实的差异又是新挑战。
四、使用范围:什么样的问题适合强化学习?
理解了局限性后,我们来看看强化学习真正擅长的领域。
非常适合强化学习的问题通常有这些特征:
-
序列决策问题:需要做一连串决策,而不是单次判断
- 适合:下棋(每步棋影响后续)、游戏通关、机器人连续控制
- 不适合:单张图片分类(一次判断即可)
-
环境具有动态性、交互性:你的行动会影响环境,环境变化又影响后续选择
- 适合:自动驾驶(你的驾驶影响其他车流)、交易策略(你的买卖影响市场价格)
- 不适合:静态数据分析(数据不会因你的分析而改变)
-
目标明确但路径不明确:知道要什么结果,但不知道具体怎么做
- 适合:让机器人学会走路(目标:前进;但怎么协调四肢?不知道)
- 不适合:有明确操作手册的任务(按步骤执行即可)
-
延迟奖励:行动的效果需要一段时间才能显现
- 适合:围棋(中盘的一步棋可能到终局才见分晓)、农业决策(春季播种,秋季收获)
- 不适合:即时反馈的简单任务
决策流程图:该不该用强化学习?
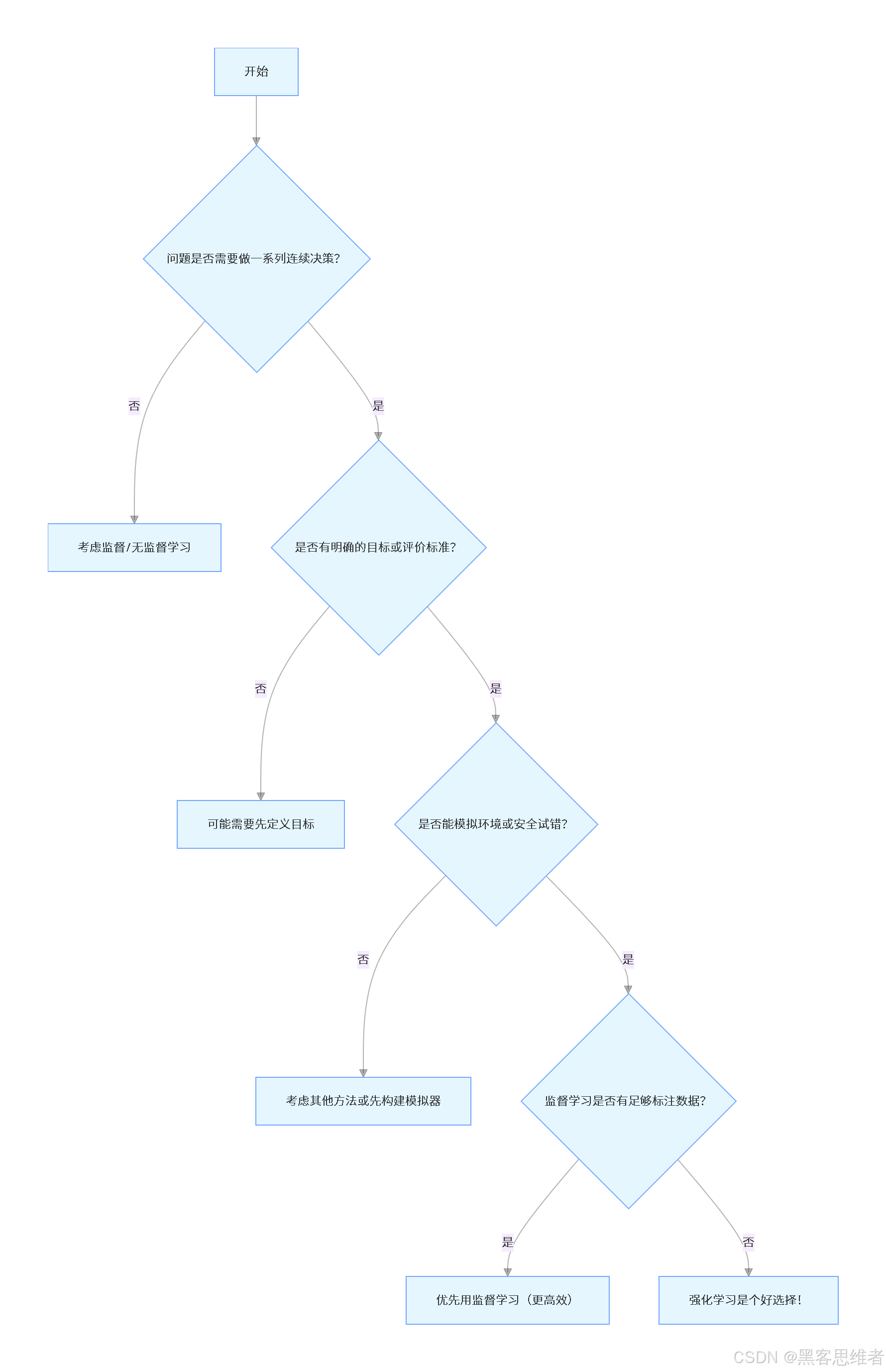
五、应用场景:强化学习在改变世界
理论说了这么多,强化学习到底在哪些实际场景中发挥作用呢?让我们看几个贴近生活的例子。
场景1:游戏AI与电子竞技
具体案例:DeepMind的AlphaGo、AlphaStar、OpenAI Five
- 问题:围棋、星际争霸、DOTA2等游戏极其复杂,传统编程难以写出高水平AI
- 强化学习的角色:让AI通过自我对弈数百万盘,探索人类从未想到的策略
- 有趣的结果:AlphaGo的"围棋上帝"让人类棋手看到了全新棋路;AlphaStar在《星际争霸2》中使用了人类选手很少采用的"多线骚扰"战术
- 你的联系:你现在玩的很多手游,里面的"智能敌人"很可能就用了强化学习技术
场景2:机器人控制与自动化
具体案例:波士顿动力机器人、工业机械臂、无人机编队
- 问题:如何让机器人适应复杂、多变的环境?传统方法需要工程师精心设计每个动作
- 强化学习的角色:让机器人在模拟环境中"自学成才",学会行走、奔跑、抓取、避障等技能
- 工作方式:在虚拟环境中训练(避免物理损坏),然后迁移到真实机器人
- 你的联系:未来你家的服务机器人、仓库里的分拣机器人,都可能通过强化学习变得更灵活
场景3:个性化推荐系统
具体案例:抖音/快手视频推荐、淘宝商品推荐、Netflix影片推荐
- 问题:如何根据用户实时反馈调整推荐内容,最大化用户停留时间和满意度?
- 强化学习的角色 :将推荐视为序列决策问题
- 状态:用户历史行为、当前上下文
- 动作:推荐哪个视频/商品
- 奖励:用户观看时长、点赞、购买等
- 特别优势:能平衡"推荐已知喜好内容"(利用)和"探索用户新兴趣"(探索)
- 你的联系:为什么抖音总能刷到你感兴趣的视频?背后可能有强化学习的功劳
场景4:自动驾驶决策系统
具体案例:Waymo、Tesla自动驾驶系统
- 问题:在复杂交通环境中做出安全、高效的驾驶决策
- 强化学习的角色 :学习高级决策策略,如:
- 何时变道超车?
- 如何与"加塞"车辆互动?
- 在突发情况下如何选择风险最小的方案?
- 注意:自动驾驶是多技术融合,强化学习主要负责"决策层",感知层仍主要用CNN等
- 你的联系:未来完全自动驾驶汽车的"驾驶大脑",很可能由强化学习训练而成
场景5:能源管理与优化
具体案例:谷歌数据中心冷却系统优化、智能电网调度
- 问题:如何动态调整设备运行参数,在满足需求的同时最小化能耗?
- 强化学习的角色 :学习复杂系统的最优控制策略
- 谷歌案例:通过强化学习调整数据中心风扇、冷却系统,节能40%
- 电网案例:根据实时电价、用电预测,优化电力分配
- 特点:这类问题有精确的数学模型,适合先在模拟中训练,再应用于实际
总结:强化学习的核心价值
让我们回到最初的问题:强化学习到底是什么?
一句话概括 :强化学习是让AI在未知环境中 ,通过试错与反馈 ,自学序列决策能力的方法论。
它的核心魅力在于:不依赖人类预先提供"标准答案",而是让智能体自己探索、发现甚至超越人类的解决方案。
学习强化学习的重点:
- 理解"智能体-环境-奖励"这个铁三角关系
- 掌握"探索与利用"的平衡艺术
- 明白强化学习适合解决什么样的问题(序列决策、动态环境、延迟奖励)
就像训练狗狗需要耐心和技巧,设计强化学习系统也需要精心设置奖励、搭建合适环境。但一旦成功,你将创造出能够自主学习的AI,它能在复杂环境中做出明智决策,甚至发现人类未曾想到的解决方案。
人工智能的世界充满无限可能,强化学习正是开启这无限可能的钥匙之一。希望这篇文章能帮你推开这扇门,看到门后那个充满智能与探索精神的世界。
下次当你看到一只训练有素的小狗、或是一个游戏高手、或是一个灵活的机器人时,不妨想想:它们背后,可能都闪烁着强化学习的智慧光芒呢!