注:该文用于个人学习记录和知识交流,如有不足,欢迎指点。
一、用户态网络缓存区是什么?
在用户态定义的缓存区段(发送、接收)
二、有什么用?
发送缓存区:
一次发送不玩,暂存在缓存区中,后续再发送
接收缓存区:
- 在TCP中接收的包可能是不完整的(包之间以 \r\n 分隔),暂存在缓存区中直至完整了再处理。
- 接收的数据先存在缓存区中,定时再批量处理也行。
三、如何实现
1. 数组
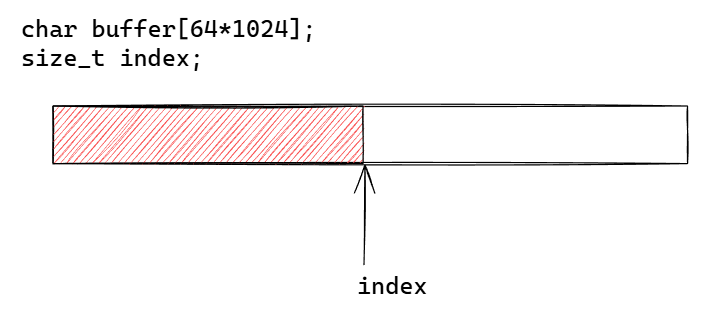
缺点:
- 频繁挪移数据:每次读完部分数据,就要将剩余数据挪到数组开头
- 伸缩性差:数组是定长的
- 内存浪费:有部分内存可能永远都用不到
2. 队列(环形)
ringbuffer
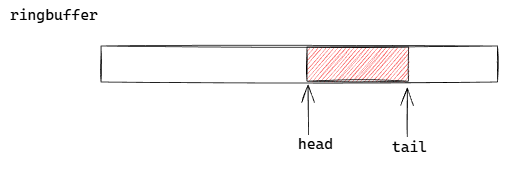
缺点:
-
伸缩性差
-
内存浪费
tips: 在linux系统中,可以使用writev 或者 readv, 同时操作队尾和队首两块区域。(这样子将两次系统调用合并为1次,可以提高性能)
3. 链式缓存区
chainbuffer
ChainBuffer(也叫「链表缓冲区 / 链式缓存」)是由多个离散的内存块(缓冲区节点)通过链表串联而成的用户态缓存区 ------ 它对外呈现 "连续可读写" 的抽象,实则内部通过链表管理多个独立的小块内存,是解决「动态长度数据缓存」的核心方案(尤其适合网络编程)。
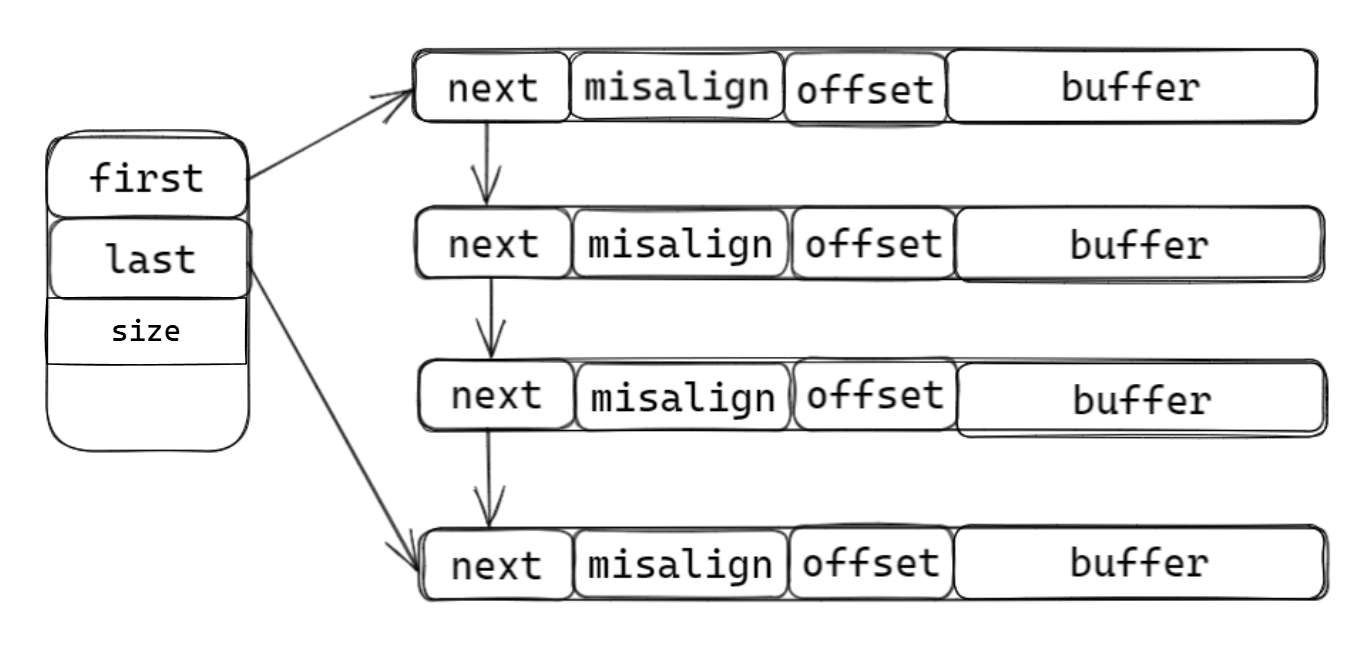
优点:
1. 动态扩容无拷贝开销
线性缓冲区扩容时(如
vector满了),需要分配更大的连续内存,再把旧数据拷贝过去;而 ChainBuffer 扩容只需新建一个小块内存节点,追加到链表尾部即可,无任何数据拷贝。2. 规避大内存分配风险
单次分配 100MB 连续内存容易失败(内存碎片),但分配 100 个 1MB 的小块内存成功率极高;ChainBuffer 天然适配这种 "小块内存拼接" 的场景。