传统扩散模型最早用于图像生成(比如 Stable Diffusion),其原理是从纯噪声开始,通过多步"去噪"逐步还原出清晰内容。过去人们认为这种机制难以用于离散的文本(因为文字不像像素可微)。
LLaDA2.0 是蚂蚁集团推出的一系列基于扩散机制的大语言模型,年初还是个小众方向的「扩散语言模型(dLLM)」,现在已经被扩展到千亿参数的规模了。和传统语言模型(比如 LLaMA)逐字生成文本不同,它能一次性并行生成多个词,速度更快------实测推理速度达到 535 tokens/秒,比同级别自回归模型快 2.1 倍;它包含 16B 的 mini 版和 100B 的 flash 版(采用 MoE 架构),是全球首个突破百亿参数的扩散语言模型,在代码生成、数学和智能体任务上表现尤为出色;更关键的是,它通过创新的训练方法复用已有模型的知识,避免从头训练,并已将全部模型权重和代码以 Apache 2.0 协议开源,真正把扩散语言模型从理论带入了实际应用。
性能亮点
- 领先的 MoE 架构 : 开源的 混合专家(MoE)扩散大型语言模型 在 Ling2.0 系列上持续训练,使用了大约 20 万亿个标记。
- 高效的推理 : flash版虽然总参数量为 1000 亿 ,但在推理过程中仅激活 61 亿 参数。LLaDA2.0-flash 显著降低了计算成本,同时超越了类似规模的开源密集型模型。
- 在代码和复杂推理任务上的出色表现 : 在诸如 代码生成 和 高级数学推理 等任务中表现出色,展示了强大的推理能力。
- 工具使用 : 支持 工具调用 并在复杂的基于代理的任务中表现出色。
- 开放与可扩展性 : 完全开源并致力于透明度。我们计划在未来发布一个 领先的推理框架 ,并继续投资于前沿领域如 扩散大语言模型 (dLLM) 以推动颠覆性创新。
训练过程
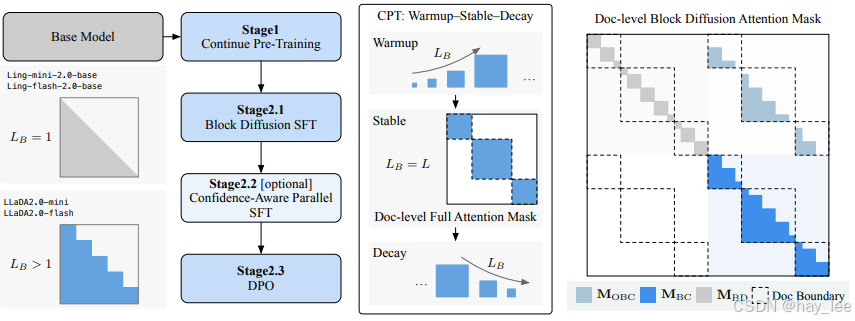
LLaDA2.0 无需代价高昂的从头训练,而是秉持知识继承、渐进式适应与效率优先的设计原则,利用一种新颖的三阶段、基于块级权重空间分解(WSD)的训练方案,将预训练的 AR 模型无缝转换为 dLLM:第一阶段为块扩散中的块尺寸逐步增大(预热阶段),第二阶段为大规模全序列扩散(稳定阶段),第三阶段则回退至紧凑块尺寸的扩散(衰减阶段)。结合后续基于监督微调(SFT)和直接偏好优化(DPO)的对齐训练,我们得到了两个面向实际部署优化的指令微调版混合专家(MoE)模型:LLaDA2.0-mini(160 亿参数)和 LLaDA2.0-flash(1000 亿参数)。这些模型保留了并行解码的优势,在前沿规模下实现了卓越的性能与效率。两个模型均已开源。
Benchmark Performance of LLaDA2.0
LLaDA2.0-flash
| 基准 | Qwen3-30B-A3B-Instruct-2507 | Ling-flash-2.0 | LLaDA2.0-flash-preview | LLaDA2.0-flash |
|---|---|---|---|---|
| 平均 | 79.47 | 78.03 | 71.92 | 79.32 |
| 知识 | ||||
| MMLU | 87.13 | 87.98 | 83.15 | 87.69 |
| MMLU-Pro | 74.23 | 76.84 | 49.22 | 73.36 |
| GPQA | 57.34 | 67.12 | 46.59 | 61.98 |
| arc-c | 95.81 | 95.08 | 93.90 | 95.93 |
| CMMLU | 86.36 | 86.59 | 67.53 | 85.13 |
| C-EVAL | 88.17 | 88.03 | 66.54 | 86.75 |
| GAOKAO-Bench | 94.53 | 93.24 | 86.12 | 93.90 |
| 推理 | ||||
| SQuAD 2.0 | 89.51 | 81.32 | 85.61 | 90.00 |
| DROP | 87.57 | 88.32 | 79.49 | 87.90 |
| KOR-Bench | 68.00 | 68.96 | 37.26 | 64.24 |
| HellaSwag | 86.31 | 81.59 | 86.00 | 84.97 |
| 编码 | ||||
| CRUXEval-O | 86.75 | 82.75 | 61.88 | 85.12 |
| MBPP | 86.65 | 85.01 | 77.75 | 88.29 |
| MultiPL-E | 70.67 | 65.76 | 62.43 | 74.87 |
| HumanEval | 93.29 | 85.98 | 80.49 | 94.51 |
| Bigcodebench-Full | 41.49 | 40.70 | 30.44 | 41.58 |
| LiveCodeBench | 41.63 | 44.11 | 28.58 | 42.29 |
| Spider | 81.79 | 80.58 | 81.37 | 82.49 |
| 数学 | ||||
| GSM8K | 96.36 | 95.45 | 89.01 | 96.06 |
| MATH | 96.70 | 96.1 | 73.50 | 95.44 |
| OlympiadBench | 77.59 | 76.19 | 47.78 | 74.07 |
| AIME 2025 | 61.88 | 55.89 | 23.33 | 60.00 |
| 代理与对齐 | ||||
| BFCL_Live | 73.19 | 67.57 | 74.11 | 75.43 |
| IFEval-strict -prompt | 84.29 | 81.52 | 62.50 | 81.70 |
LLaDA2.0-mini
| 基准 | Qwen3-8B (无思考) | Ling-mini-2.0 | LLaDA2.0-mini-preview | LLaDA2.0-mini |
|---|---|---|---|---|
| 平均 | 70.19 | 72.13 | 61.75 | 71.67 |
| 知识 | ||||
| MMLU | 80.94 | 82.15 | 72.49 | 80.53 |
| MMLU-Pro | 65.48 | 63.72 | 49.22 | 63.22 |
| GPQA | 46.59 | 56.80 | 31.82 | 47.98 |
| arc-c | 93.35 | 93.09 | 89.15 | 93.56 |
| CMMLU | 79.17 | 80.84 | 67.53 | 79.50 |
| C-EVAL | 81.36 | 82.10 | 66.54 | 81.38 |
| GAOKAO-Bench | 84.94 | 87.23 | 74.46 | 84.30 |
| 推理 | ||||
| SQuAD 2.0 | 85.21 | 75.56 | 85.61 | 86.50 |
| DROP | 84.56 | 78.80 | 79.49 | 81.91 |
| KOR-Bench | 54.48 | 62.72 | 37.26 | 50.40 |
| HellaSwag | 79.56 | 69.02 | 74.01 | 79.01 |
| 编码 | ||||
| CRUXEval-O | 74.06 | 76.12 | 61.88 | 71.62 |
| MBPP | 78.92 | 84.07 | 77.75 | 81.50 |
| MultiPL-E | 61.7 | 67.09 | 62.43 | 67.46 |
| HumanEval | 84.76 | 85.98 | 80.49 | 86.59 |
| BigCodeBench-Full | 36.05 | 35.00 | 30.44 | 32.89 |
| LiveCodeBench | 26.38 | 34.97 | 19.93 | 31.50 |
| Spider | 72.80 | 76.43 | 75.64 | 76.76 |
| 数学 | ||||
| GSM8K | 93.63 | 94.62 | 89.01 | 94.24 |
| MATH | 86.28 | 94.66 | 73.50 | 93.22 |
| OlympiadBench | 55.33 | 72.30 | 36.67 | 67.70 |
| AIME 2025 | 22.08 | 47.66 | 10.00 | 36.67 |
| 代理与对齐 | ||||
| BFCL_Live | 70.08 | 53.98 | 74.11 | 70.90 |
| IFEval-strict -prompt | 86.9 | 76.16 | 62.50 | 80.78 |
大模型相关课程:
|----|---|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | 一 | 1.大模型的发展与局限性 |
| 2 | 二 | 1.1 ollama本地快速部署deepseek |
| 3 | 二 | 1.2 linux本地部署deepseek千问蒸馏版+web对话聊天 |
| 4 | 二 | 1.3 linux本地部署通义万相2.1+deepseek视频生成 |
| 5 | 二 | 1.4 Qwen2.5-Omni全模态大模型部署 |
| 6 | 二 | 1.5 Stable Diffusion中文文生图模型部署 |
| 7 | 二 | 1.6 DeepSeek-OCR部署尝鲜 |
| 8 | 二 | 2.1 从零训练自己的大模型概述 |
| 9 | 二 | 2.2 分词器 |
| 10 | 二 | 2.3 预训练自己的模型 |
| 11 | 二 | 2.4 微调自己的模型 |
| 12 | 二 | 2.5 人类对齐训练自己的模型 |
| 13 | 二 | 3.1 微调训练详解 |
| 14 | 二 | 3.2 Llama-Factory微调训练deepseek-r1实践 |
| 15 | 二 | 3.3 transform+LoRA代码微调deepseek实践 |
| 16 | 二 | 4.1 文生图(Text-to-Image)模型发展史 |
| 17 | 二 | 4.2 文生图GUI训练实践-真人写实生成 |
| 18 | 二 | 4.3 文生图代码训练实践-真人写实生成 |
| 19 | 二 | 5.1 文生视频(Text-to-Video)模型发展史 |
| 20 | 二 | 5.2 文生视频(Text-to-Video)模型训练实践 |
| 21 | 二 | 6.1 目标检测模型的发展史 |
| 22 | | 6.2 YOLO模型训练实践及目标跟踪 |
| 23 | 三 | 1.1 Dify介绍 |
| 24 | 三 | 1.2 Dify安装 |
| 25 | 三 | 1.3 Dify文本生成快速搭建旅游助手 |
| 26 | 三 | 1.4 Dify聊天助手快速搭建智能淘宝店小二 |
| 27 | 三 | 1.5 Dify agent快速搭建爬虫助手 |
| 28 | 三 | 1.6 Dify工作流快速搭建数据可视化助手 |
| 29 | 三 | 1.7 Dify chatflow快速搭建数据查询智能助手 |
| 30 | 三 | 2.1 RAG介绍 |
| 31 | 三 | 2.2 Spring AI-手动实现RAG |
| 32 | 三 | 2.3 Spring AI-开箱即用完整实践RAG |
| 33 | 三 | 2.4 LlamaIndex实现RAG |
| 34 | 三 | 2.5 LlamaIndex构建RAG优化与实践 |
| 35 | 三 | 2.6 LangChain实现RAG企业知识问答助手 |