声明:本文只做实际测评,并非广告
第一章 跨境电商数据采集的行业困境与技术破局
当下全球跨境电商市场竞争早已白热化,数据驱动决策已成商家生存的核心。对商家来说,能否实时洞察竞品的价格、库存及排名波动,直接决定了流量与订单的归属。然而,高价值的数据往往伴随着高强度的封锁。随着网站防护机制日益严苛,传统爬虫技术正面临开发门槛高、维护成本大等问题。
1.1 数据采集痛点
具体来说跨境电商数据采集主要面临三大技术问题:
-
高频访问的反爬拦截:Amazon等平台部署了复杂的Web应用防火墙技术。高频次的单一IP访问会瞬间触发CAPTCHA验证或直接导致IP被封禁,导致数据链断裂。
-
地理位置的访问限制:不同国家站点的商品定价、库存及配送政策截然不同。使用非本土IP访问时,平台会自动重定向至默认站点或隐藏特定地区的SKU信息,导致采集数据失真。
-
账号关联与封号风险:在进行竞品调研或多账号运营时,如果网络环境(IP、ISP信息)无法做到彻底隔离,极易被判定为关联账号,引发店铺封停的后果。
第二章 IPIDEA技术优势
作为企业级全球代理IP服务商,IPIDEA为此提供了强有力的基础设施支持。其核心服务覆盖动态住宅IP、静态住宅IP及数据中心代理等多种形态,能帮助企业有效应对地区管理与网站防护机制,轻松进行数据采集。
官网:http://www.ipidea.net/?utm-source=cy&utm-keyword=?cy
2.1 全球合规IP池
在跨境业务中,数据的准确性依赖于访问源的真实性。
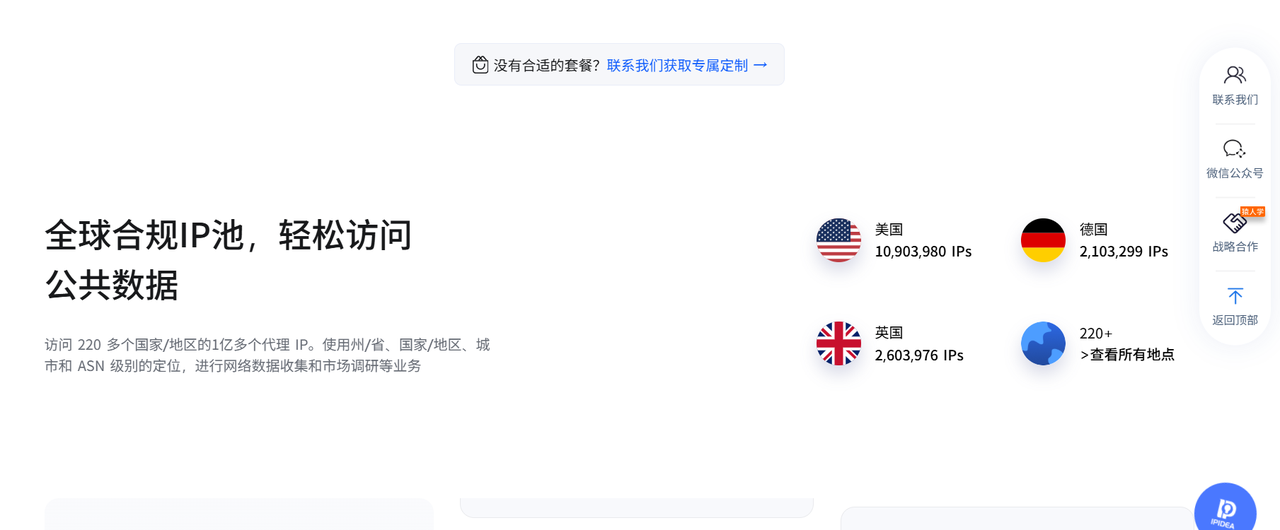
该网络覆盖了全球绝大多数国家和地区,这意味着采集程序可以模拟来自纽约、伦敦、东京或柏林的真实消费者访问行为。这种全球化的节点部署,确保了在采集Amazon不同站点(如Amazon US, Amazon DE, Amazon JP)时,能够获取到该地区专属的定价策略和促销信息,消除了地理位置带来的数据偏差。
2.2 多场景适用性
IPIDEA的产品设计高度贴合细分行业需求,包括:跨境电商、SEO优化、广告验证及社交媒体管理。
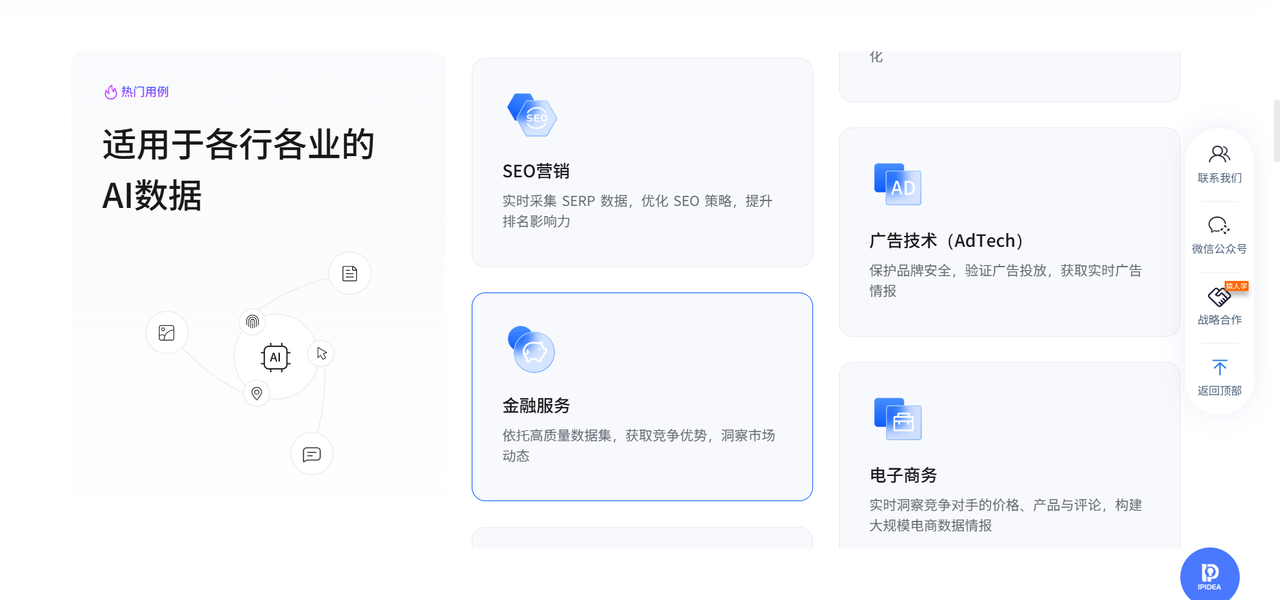
针对跨境电商(特别是Amazon和TikTok Shop),系统提供了特定的优化线路。这些线路针对电商平台的服务器响应特征进行了调整,能够有效应对高并发下的连接稳定性问题。
对于需要进行广告验证的场景,真实的住宅IP能够确保看到的广告投放情况与真实用户一致,防止被广告平台的大数据管理。
2.3 AI赋能
传统的代理服务往往采用轮询机制,容易被目标网站识别模式。

IPIDEA采用了AI算法来管理网络请求。当发起采集请求时,智能路由会根据目标网站的实时连通率、延迟以及风控等级,动态选择最优的出口节点。这种动态调整机制使得采集行为在流量特征上呈现出高度的随机性和拟人化,极大地降低了触发Amazon反爬虫机制的概率,提高了数据采集的成功率。
2.4 自定义数据集
在精细化运营阶段,仅仅定位到国家是不够的。开发者可以根据特定业务需求,定制IP筛选规则。例如,指定特定的城市(City)、特定的互联网服务提供商(ISP,如AT&T, Verizon)甚至特定的时段。在Amazon比价场景中,通过指定目标配送区域的ISP,可以获取该区域的FBA配送费率和库存情况,实现高颗粒度的数据洞察。
第三章 开发前置准备与环境搭建
在正式编写采集代码之前,需要完成账户的注册、认证以及API环境的配置。
3.1 环境搭建
通过IPIDEA提供的注册链接进入系统,新用户能够获得可观的测试流量。
3.2 平台功能概览与导航
完成注册并登录后,用户将进入IPIDEA控制台首页
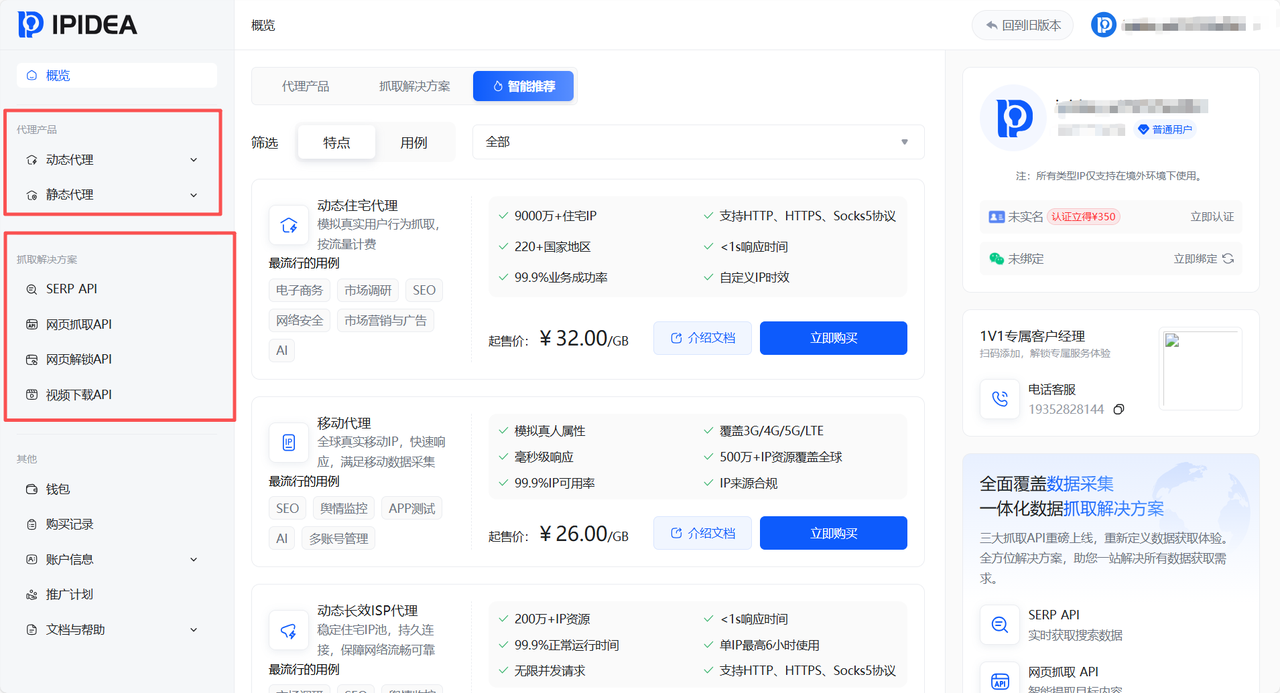
左侧导航栏集成了核心功能入口。平台将产品价格、开发文档、热门用例及核心特点进行了模块化展示。开发者能够迅速找到所需的资源,可以查看剩余流量、购买新套和查阅技术指南。
3.3 开发者文档体系
高质量的开发文档是SaaS产品的核心竞争力。IPIDEA帮助中心索引页提供了详尽的技术支持。
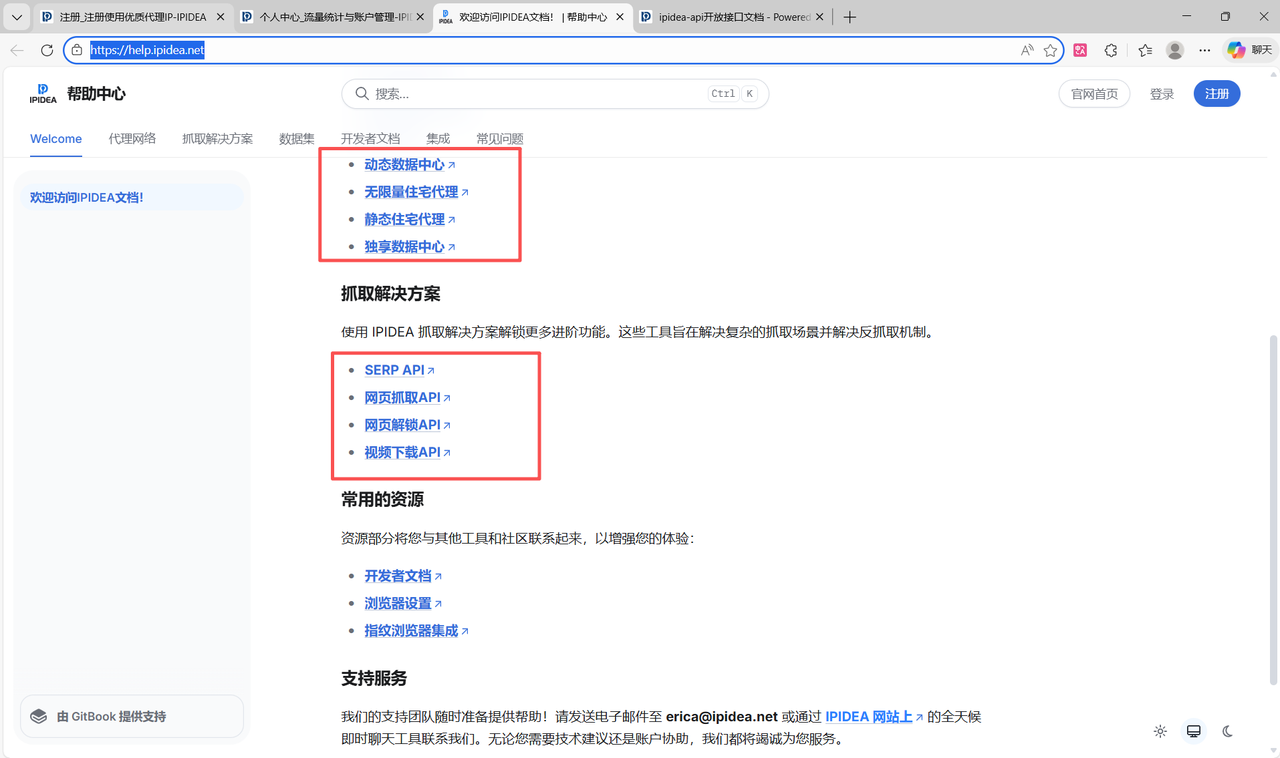
针对不同的业务需求(如API提取、账密认证),文档进行了分类。点击进入网页抓取API文档详情页(见下图),可以看到针对Amazon、Google等特定平台的抓取接口说明。
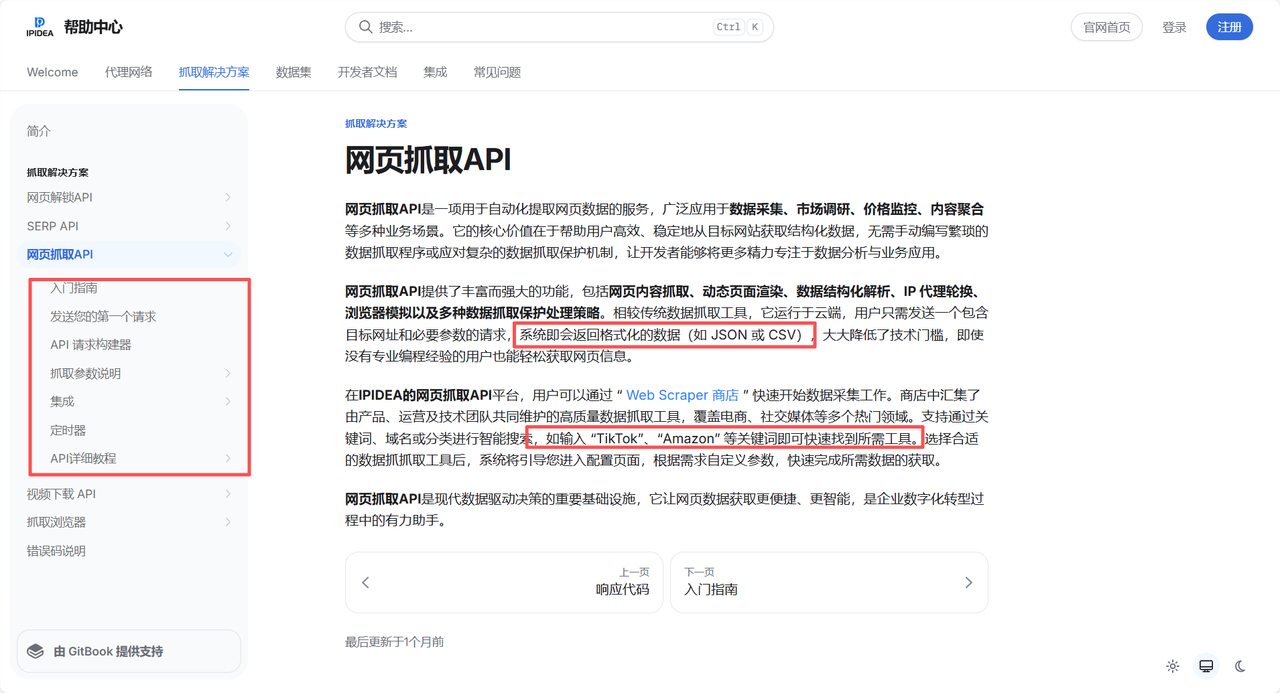
文档不仅提供了接口定义,还集成了Apipost等调试工具链接(https://www.ipidea.net/ucenter/ipidea-api.html?target_id=001),允许开发者在线调试,短了集成周期。
3.4 实名认证与代理选择
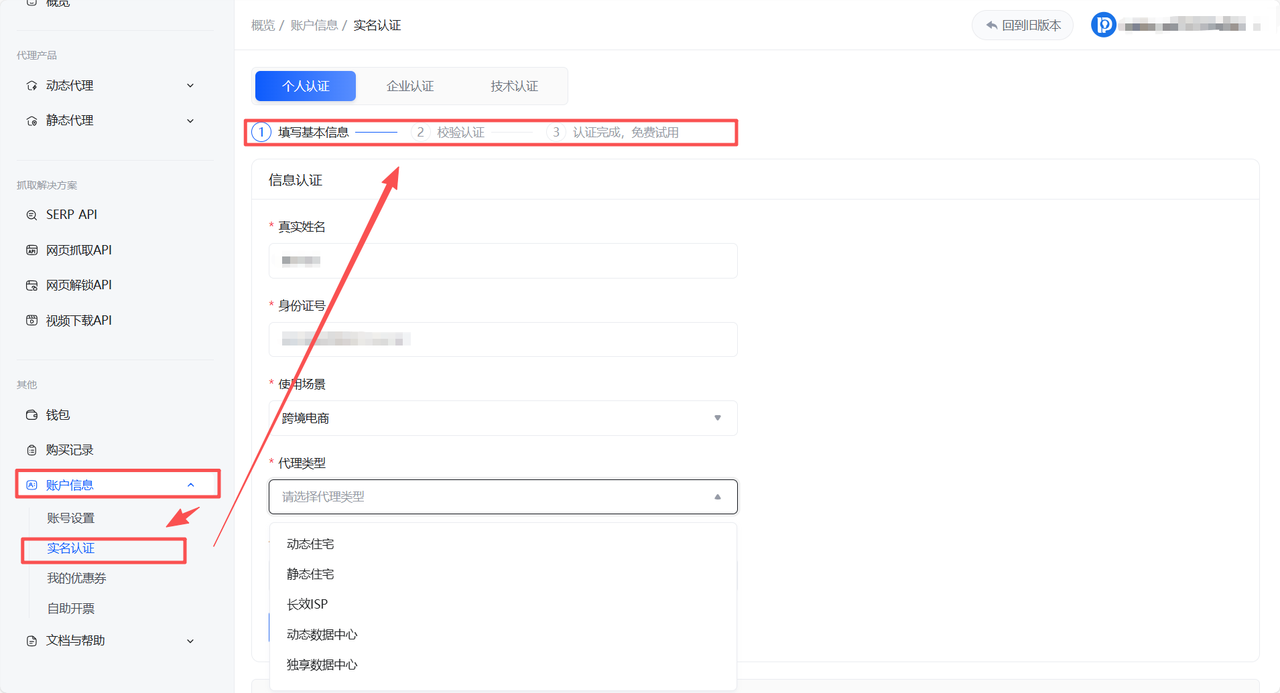
在代理类型的选择上,业务场景决定了技术选型:
-
跨境电商运营与养号 (FB/Amazon/TikTok):应选择静态住宅 或长效****ISP。这类IP稳定性高,长期不跳变,能够模拟真实家庭宽带环境,防止账号因IP变动被登出或封锁。
-
爬虫与批量数据抓取 :应选择动态住宅。这类IP在每次请求或短时间内会自动轮换,利用庞大的IP池来规避目标网站的封锁频率限制。
-
基础任务与成本控制 :可选择数据中心代理,虽然匿名度稍低,但速度快且成本低廉。
3.5 API Token生成与配置
对于Amazon自动化,核心在于调用"网页抓取API"。
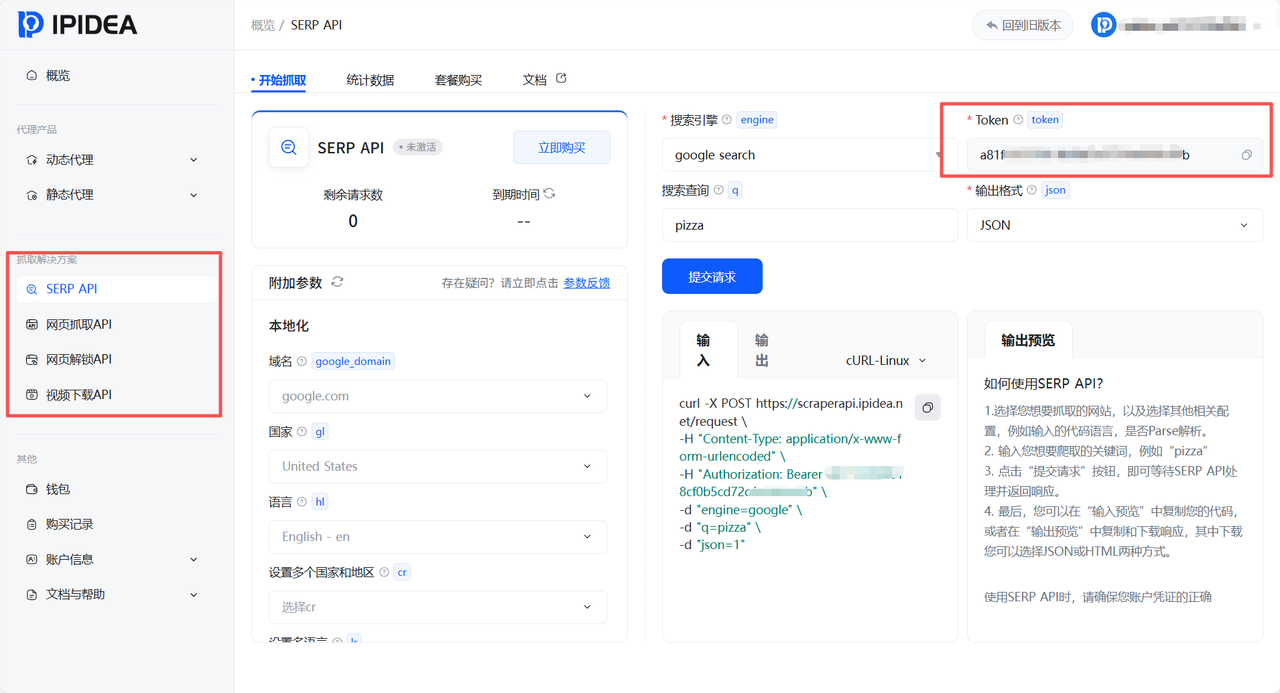
Token是API调用的身份凭证,决定了爬取任务的权限。为降低配置门槛,平台提供了需求指导性获取工具
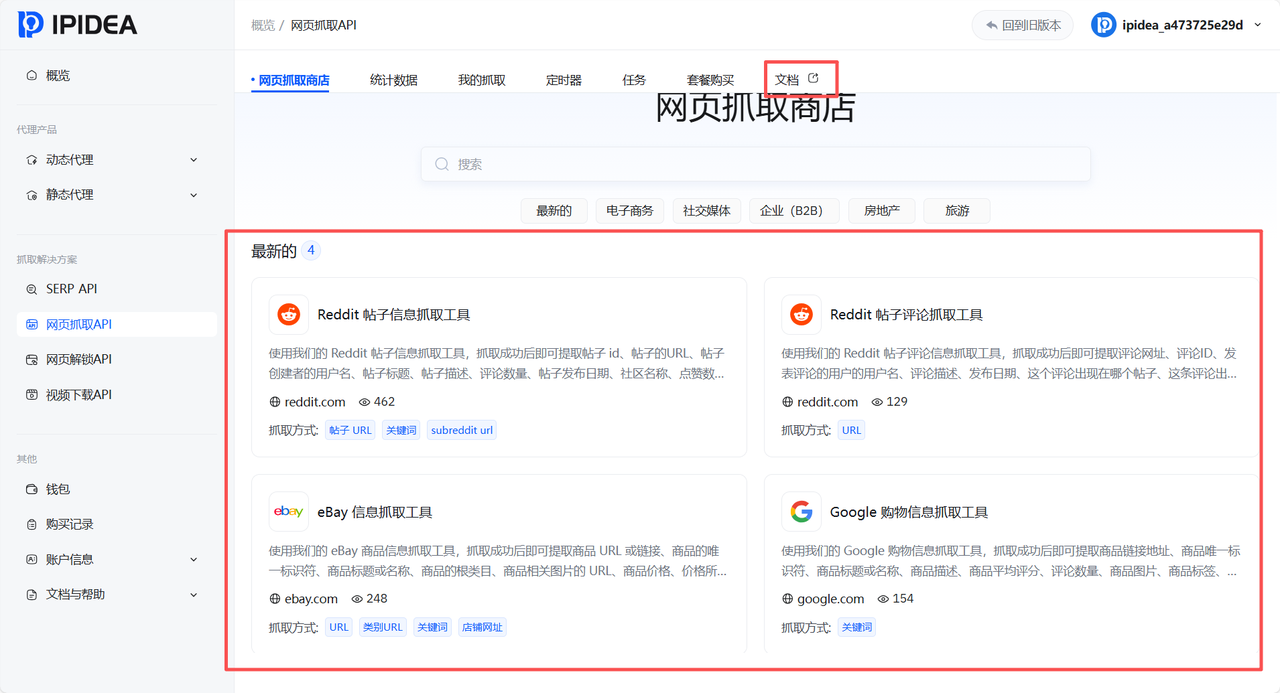
登陆IPIDEA官网,在工具中输入"Amazon",系统会自动筛选出Amazon产品详情信息抓取工具
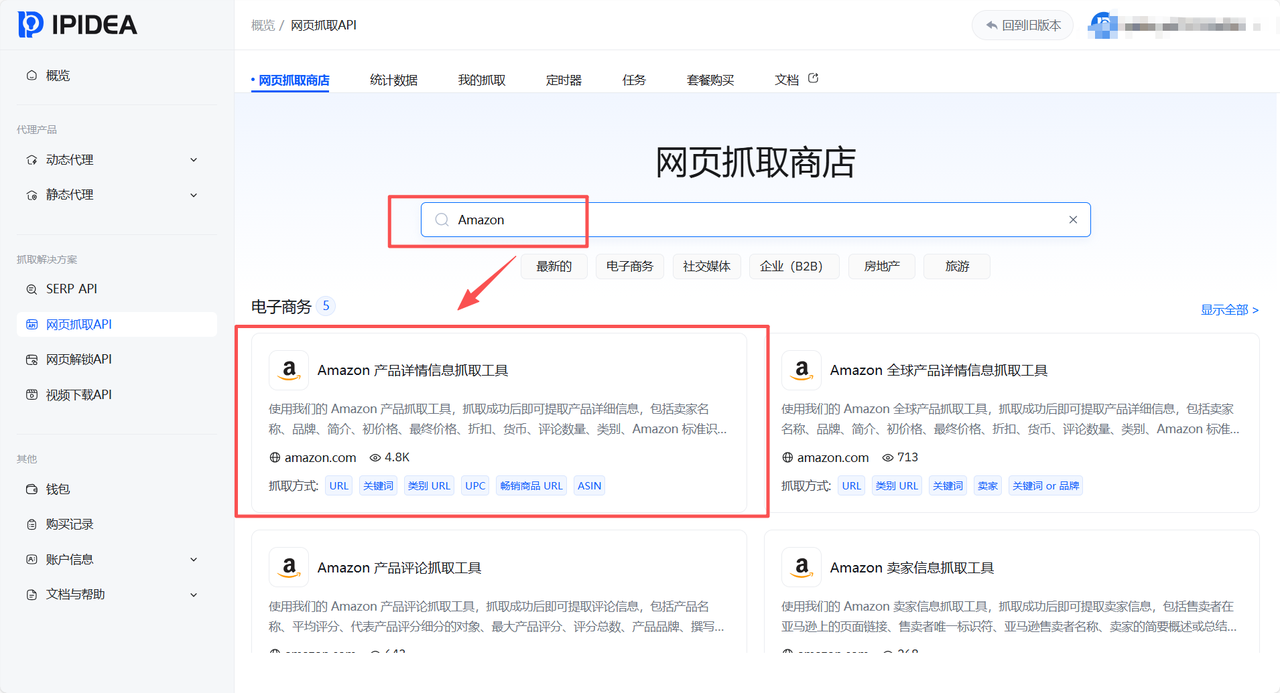
选定工具后,系统会自动生成所需的Token参数。此时无需复杂的鉴权代码编写,点击购买(或使用免费额度)即可直接激活该API端点,实现了"Key与功能"的一键绑定。
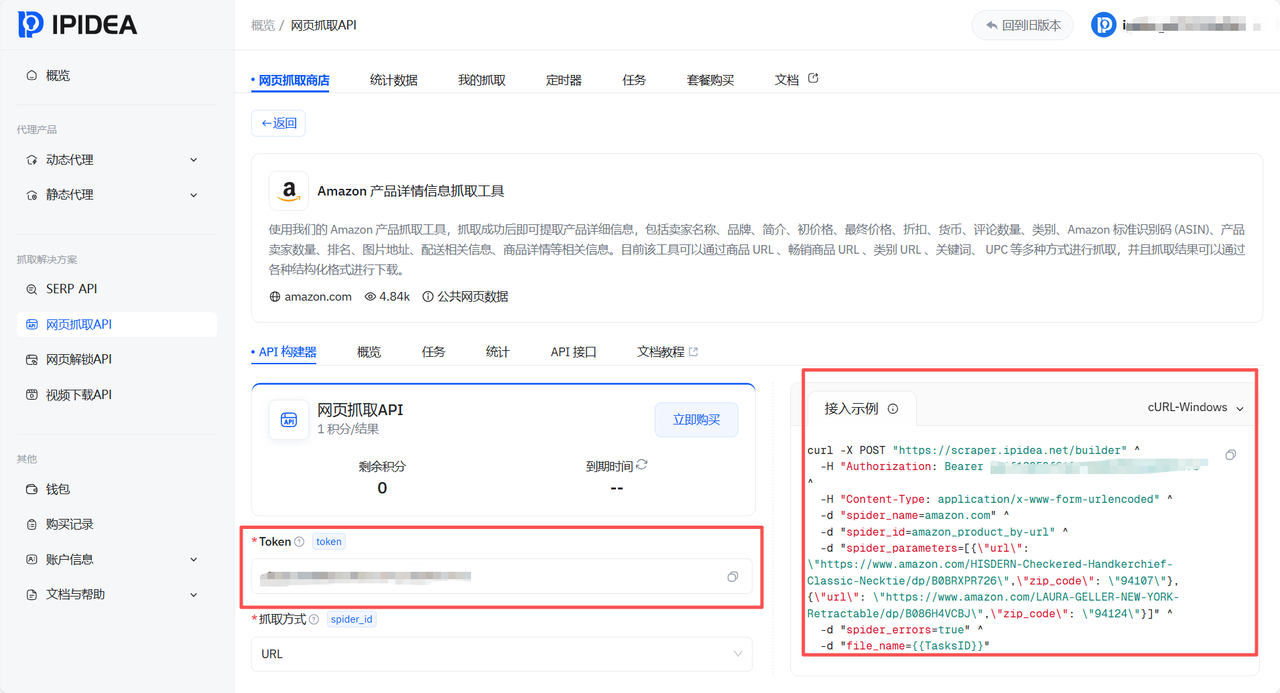
3.6 使用Demo:抓取男款运动鞋商品信息
为了更好的搭建接下来的Dify工作流, 需要测评个小Demo。先验证下抓"网站数据",运行过程、获得数据是否可靠。那么,我们可以使用本地命令行工具进行测试下。
测试网址:https://www.amazon.com/dp/B0DPHWWYYV
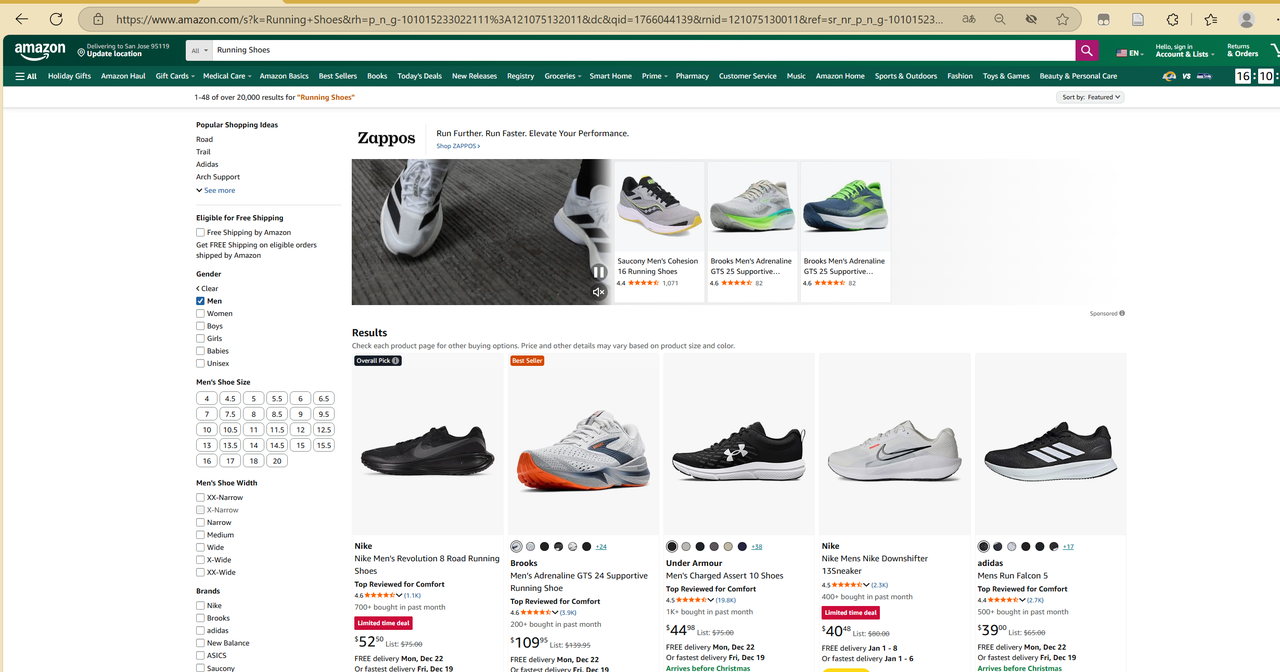
IPIDEA支持多种语言进行选择,其中推荐大家使用"cURL-Windows"请求Web服务器。因为我们在本地调用API便捷,同时cURL是广泛应用于开发、测试和系统管理中。
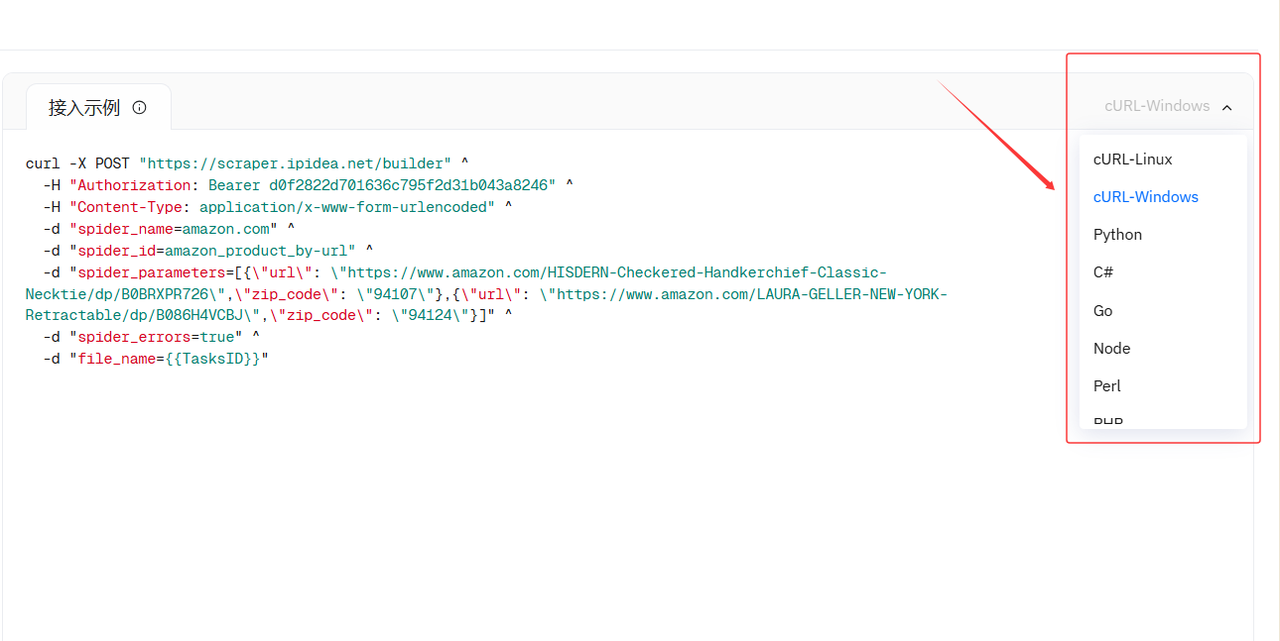
写好配置代码, 大家可以直接使用。
Plain
curl -X POST "https://scraper.ipidea.net/builder" ^
-H "Authorization: Bearer 改为您自己的API" ^
-H "Content-Type: application/x-www-form-urlencoded" ^
-d "spider_name=amazon.com" ^
-d "spider_id=amazon_product_by-url" ^
-d "spider_parameters=[{\"url\": \"https://www.amazon.com/dp/B0DPHWWYYV\",\"zip_code\": \"10001\"},{\"url\": \"https://www.amazon.com/dp/B0CZ7JJ8Z6\",\"zip_code\": \"90001\"},{\"url\": \"https://www.amazon.com/dp/B09XBWQ9Y9\",\"zip_code\": \"60601\"},{\"url\": \"https://www.amazon.com/dp/B0DZX7QG7Q\",\"zip_code\": \"77001\"},{\"url\": \"https://www.amazon.com/dp/B0CKMKYDL1\",\"zip_code\": \"85001\"},{\"url\": \"https://www.amazon.com/dp/B0F12PMLYG\",\"zip_code\": \"19103\"},{\"url\": \"https://www.amazon.com/dp/B0D33RZFGH\",\"zip_code\": \"98101\"},{\"url\": \"https://www.amazon.com/dp/B0D42CYPV9\",\"zip_code\": \"33101\"},{\"url\": \"https://www.amazon.com/dp/B0F13BTP68\",\"zip_code\": \"02110\"},{\"url\": \"https://www.amazon.com/dp/B0CZC8FY4F\",\"zip_code\": \"80202\"}]" ^
-d "spider_errors=true" ^
-d "file_name=ShoePrices"打开cmd命令行
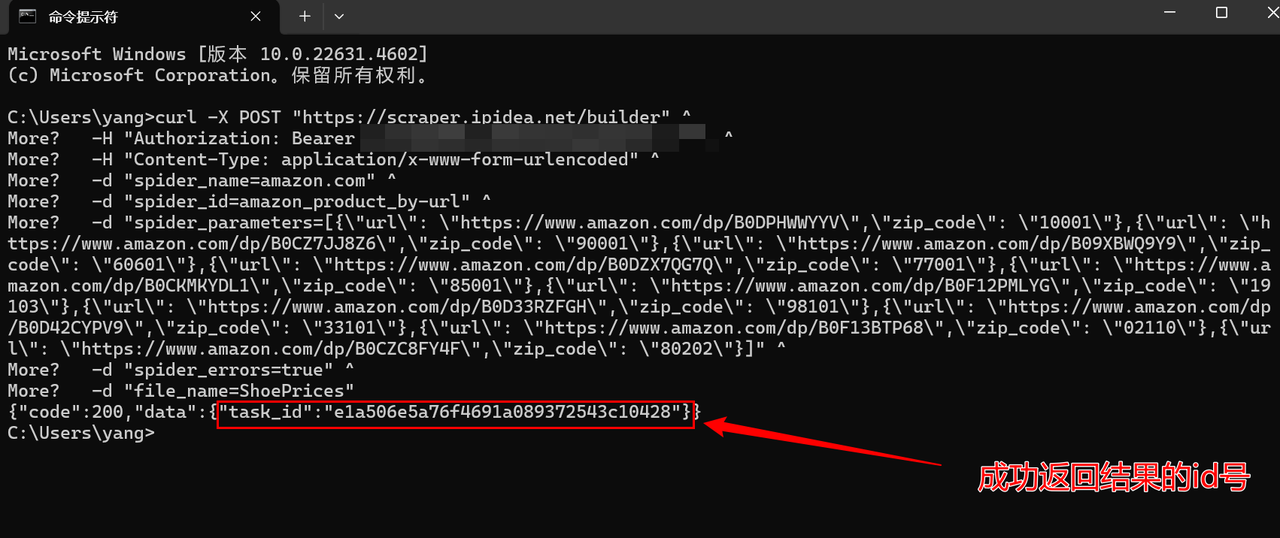
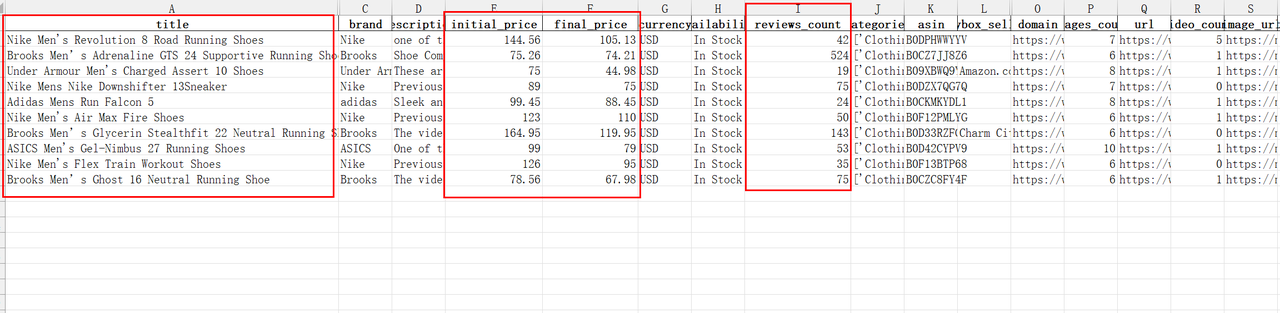
"打开IPIDEA平台 - 网页抓取API - 任务 - 点击下载",下载我们的商品数据。下载格式包括:CSV、JSON、xlsx。
下载xslx格式, 我们能看见成功获取的每个商品的标题,品牌,初始定价,最终价格和其浏览量等重要信息。
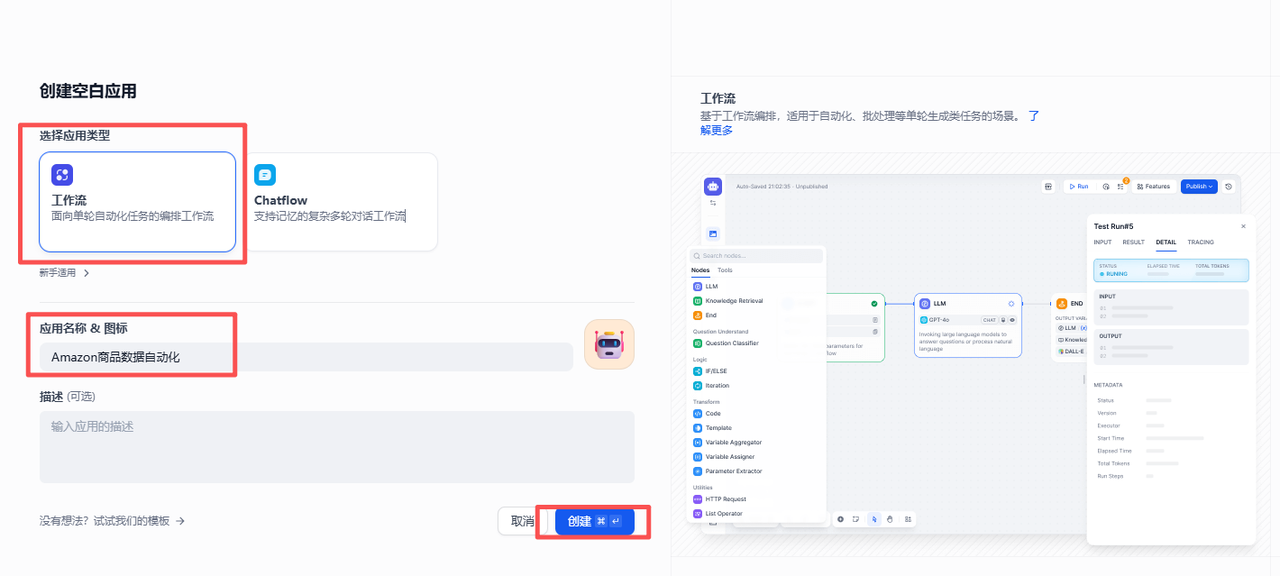
第四章 IPIDEA结合Dify实现Amazon数据自动化采集
手动配置代码固然可以实现数据获取,但为了更轻松的进行数据采集,这里我们采用IPIDEA与Dify(https://dify.ai/)工作流相结合的方式,构建一套商品信息的自动化采集系统。
4.1 工作流设计
利用Dify的工作流编排能力,可以调度IPIDEA资源,模拟真人浏览行为。
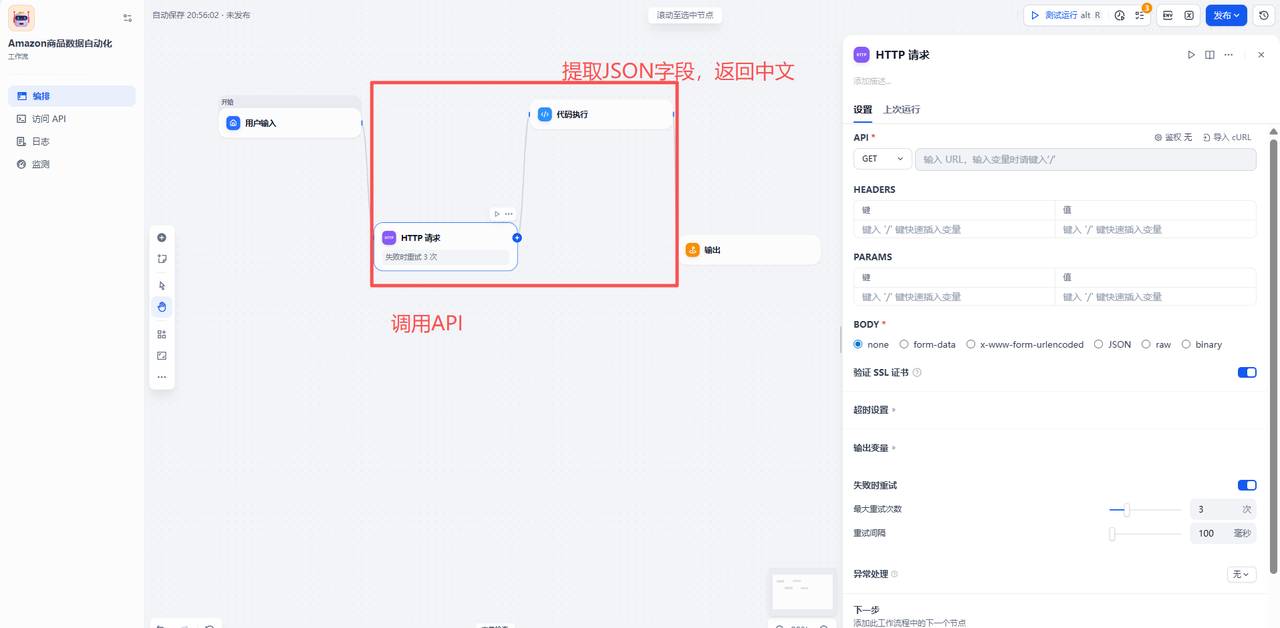
该流程主要包含两个核心环节:
-
HTTP请求节点:负责向IPIDEA发送采集指令(包含目标Amazon URL及邮编)。
-
代码执行与JSON解析节点:负责接收API返回的异步任务ID,并进一步提取最终的商品数据。
HTTP节点配置详情显示了在Dify中配置API请求的细节。由于API返回的数据通常是复杂的JSON嵌套结构,直接阅读困难,因此必须配合代码解析节点使用。
4.2 API参数配置与CURL导入
为了确保请求格式准确,建议采用CURL导入的方式。
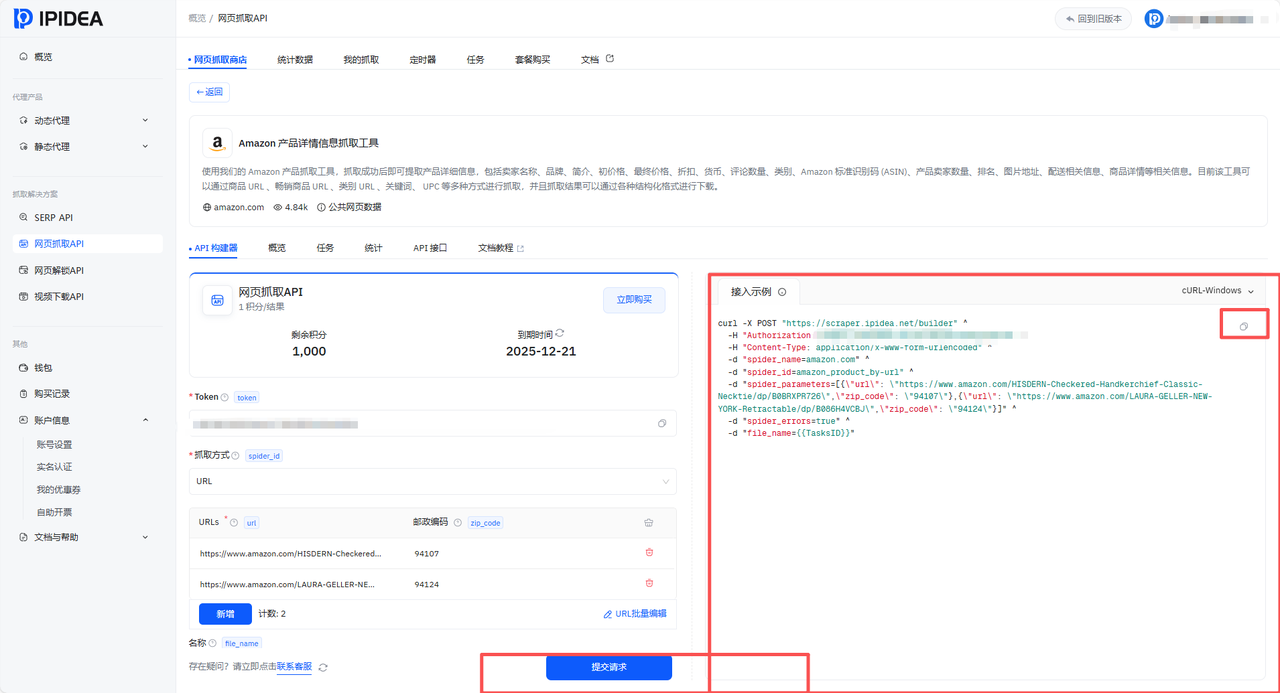
在Dify的HTTP节点中,点击导入CURL按钮(见下图)。
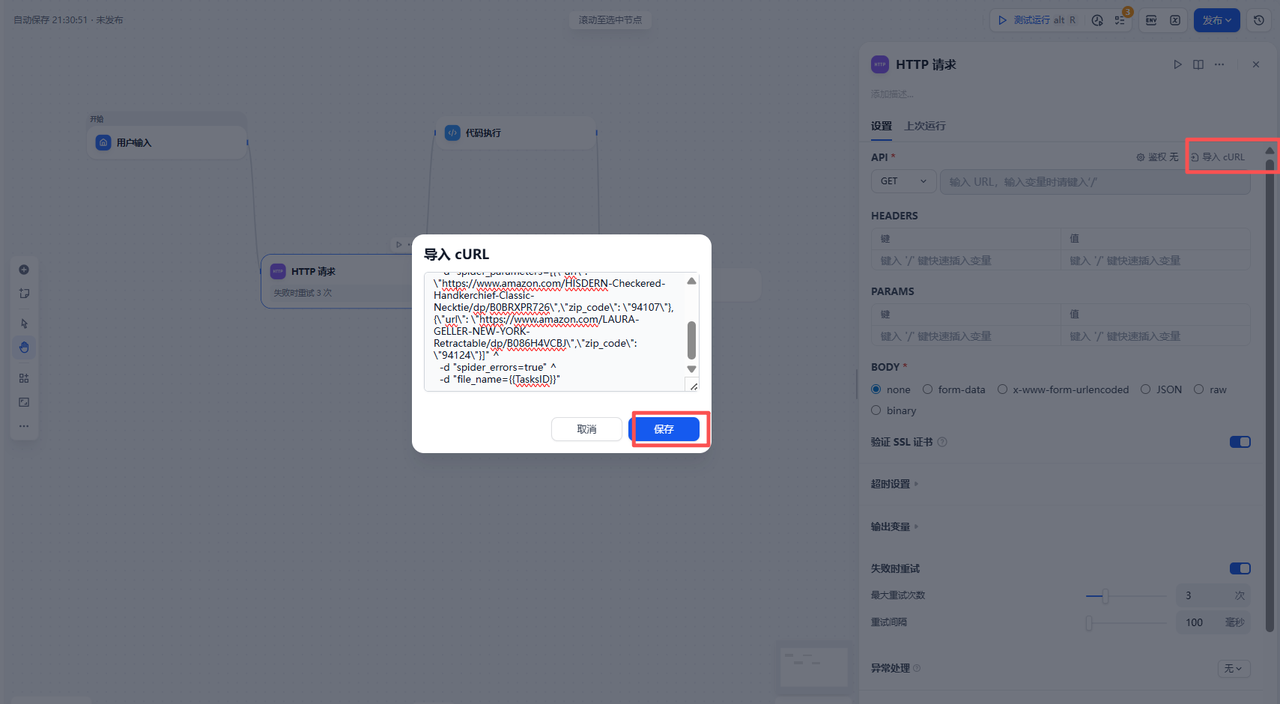
将代码粘贴后,系统会自动解析出Header、Method及Body参数。
关键参数配置表
在x-www-form-urlencoded模式下,必须严格按照下表配置键值对,这是采集任务能否成功的关键:
| 键 (Key) | 值 (Value) | 技术说明 |
| spider_name | amazon.com | 指定采集引擎的各种规则适配Amazon站点。 |
| spider_id | amazon_product_by-url | 指定具体的采集策略,此处为"基于URL采集商品详情"。 |
| spider_parameters | JSON数组 (见下文) | 包含目标URL和邮编。支持动态变量注入。 |
| spider_errors | TRUE | 开启错误回显,便于调试。 |
| file_name | 自定义或变量 | 定义生成文件的名称。 |
关于spider_parameters的示例值:
Plain
[
{"url": "https://www.amazon.com/dp/B0BRXPR726", "zip_code": "94107"},
{"url": "https://www.amazon.com/dp/B086H4VCBJ", "zip_code": "94124"}
]此处特别注意,zip_code参数的加入正是利用了IPIDEA的精准定位能力,确保获取到该邮编区域的准确价格和库存信息。
4.3 任务提交与异步ID获取
配置完成后,运行工作流。HTTP请求成功响应图 (见下图)显示,IPIDEA服务器返回了状态码200,并包含了一个核心字段:task_id。
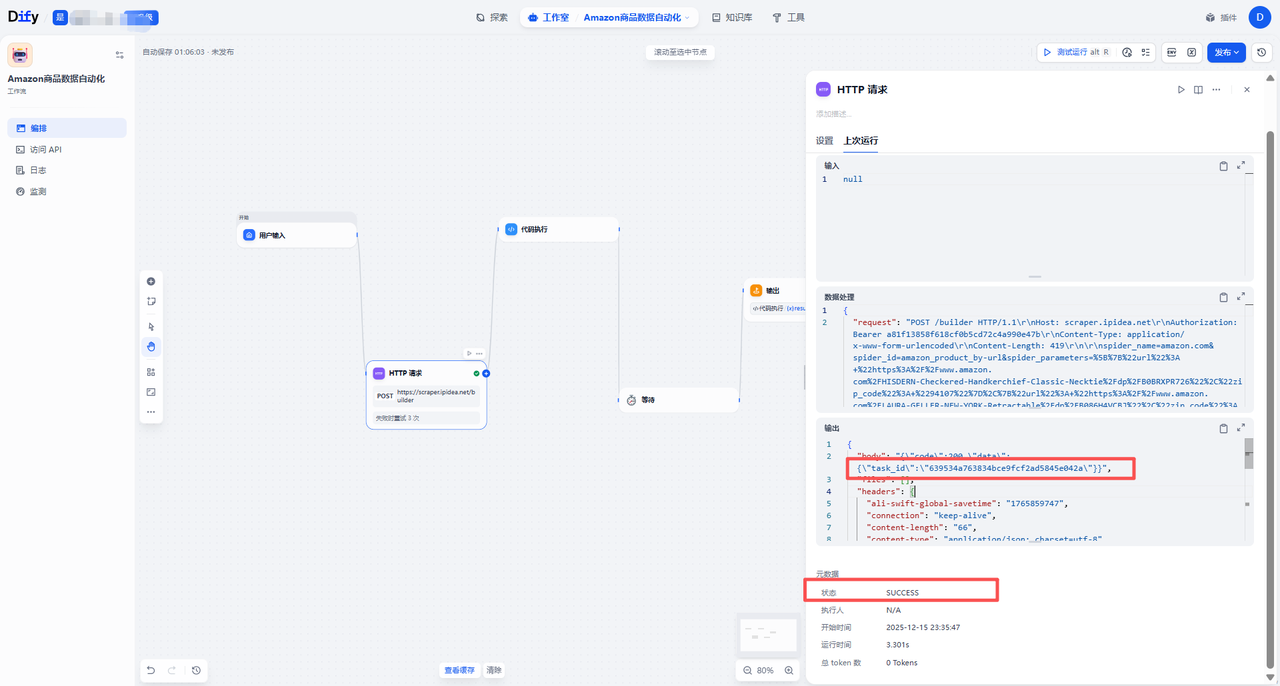
由于采集Amazon数据属于耗时操作,API采用异步设计。系统不会立即返回数据,而是返回一个任务ID。后续步骤需要凭此ID去"取货"。
4.4 数据提取与结果检索
拿到task_id后,需要构建第二个API请求来获取采集结果。数据检索API文档图 说明了get_task_result接口的使用规范。
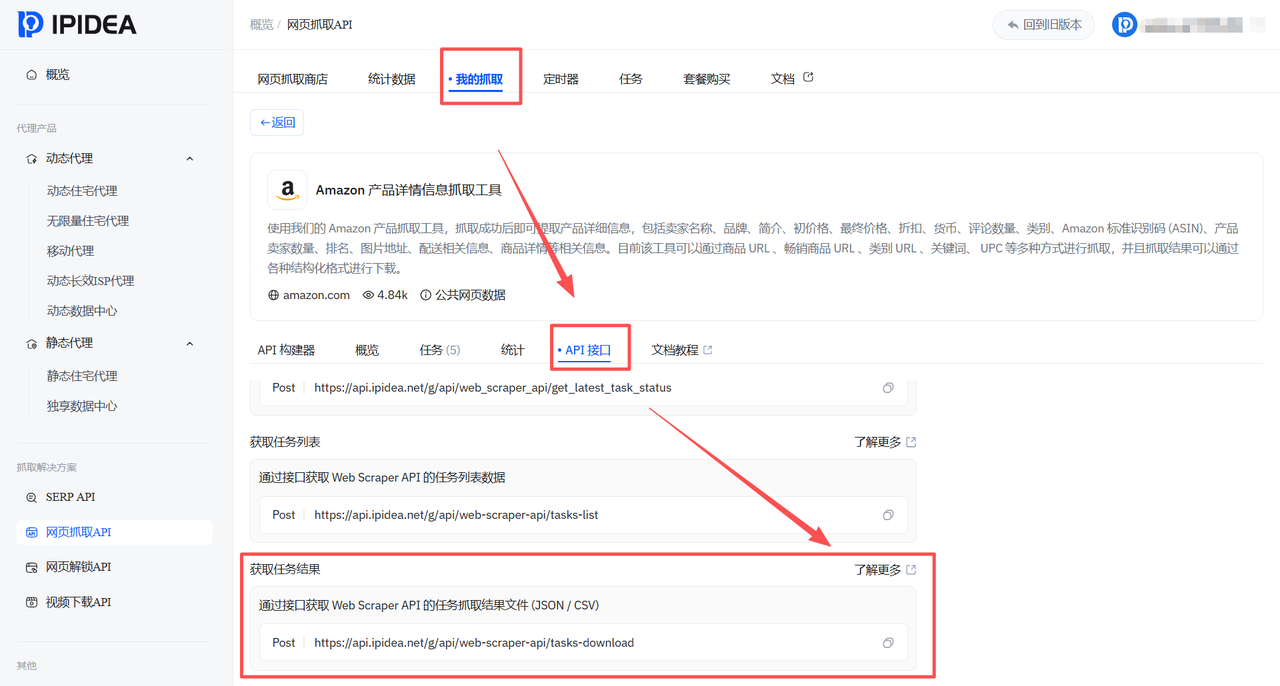
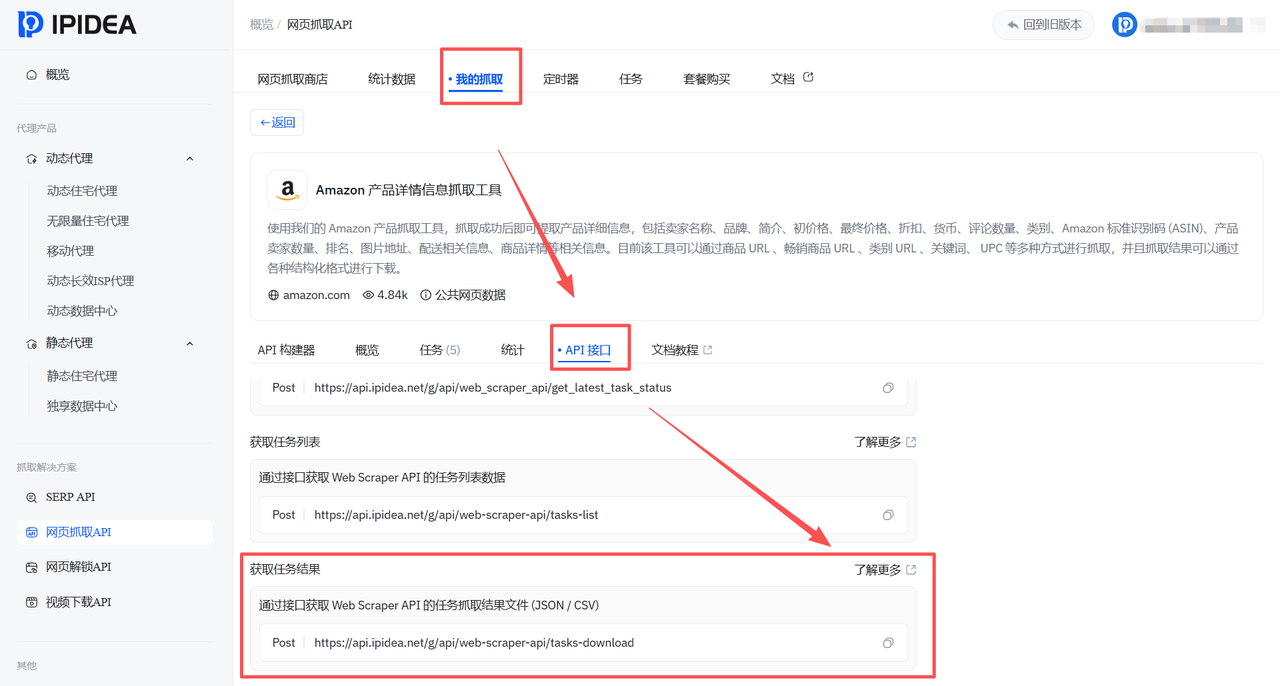
更多详细参数说明可参考IPIDEA官方帮助文档(https://help.ipidea.net/zhua-qu-jie-jue-fang-an/zhua-qu-jie-jue-fang-an/wang-ye-zhua-qu-api/api-xiang-xi-jiao-cheng/huo-qu-zhua-qu-jie-guo-wen-jian-shuo-ming)。
在Dify中配置第二个HTTP节点,将上一步获取的task_id作为参数传入。虽然文档提及Key,但在实际操作中,Token已足够。
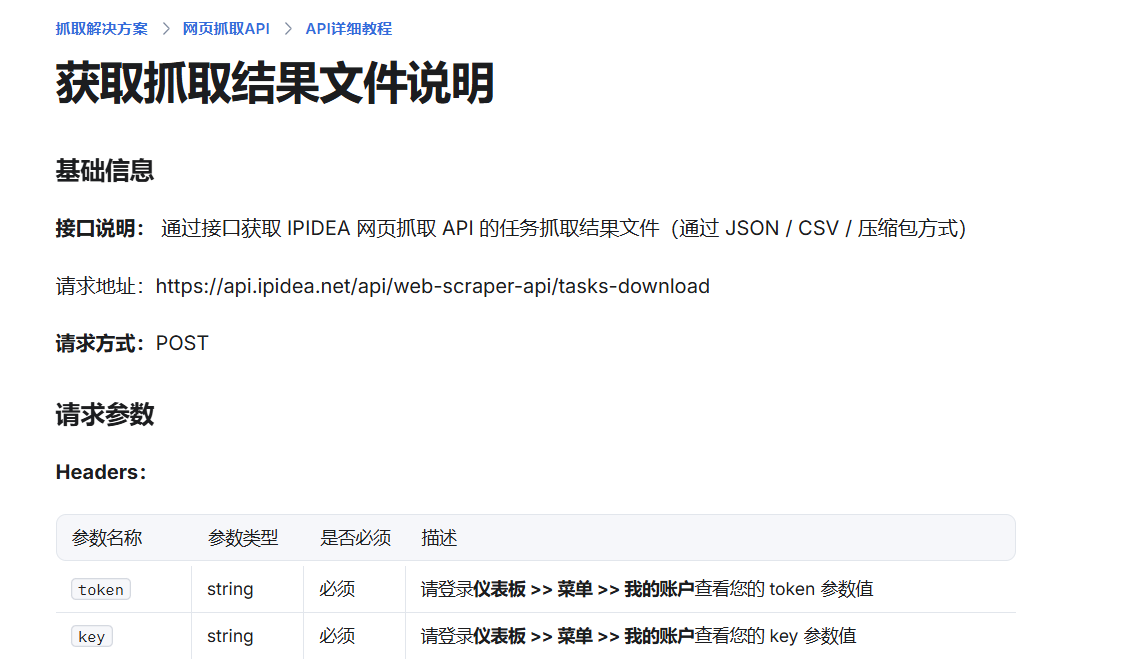
参数简化示意图再次确认了仅需Token即可完成验证。
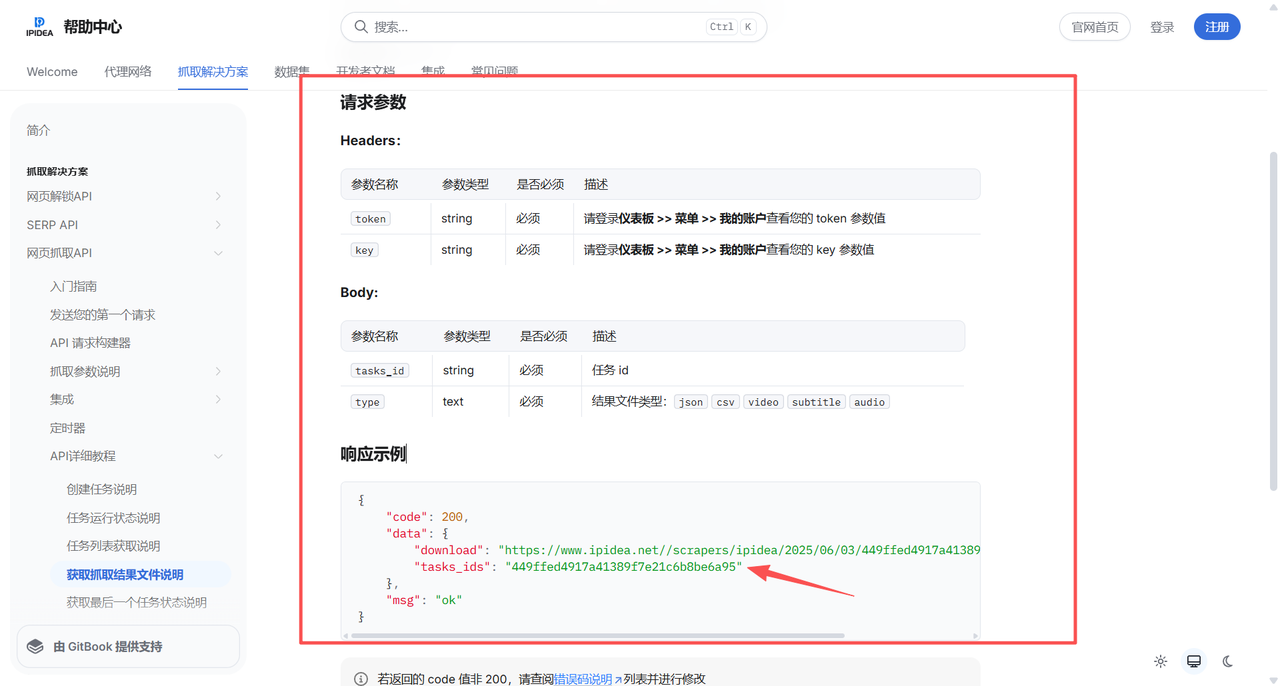
当该请求成功执行后,返回的JSON中将包含Amazon商品的详细数据链接。
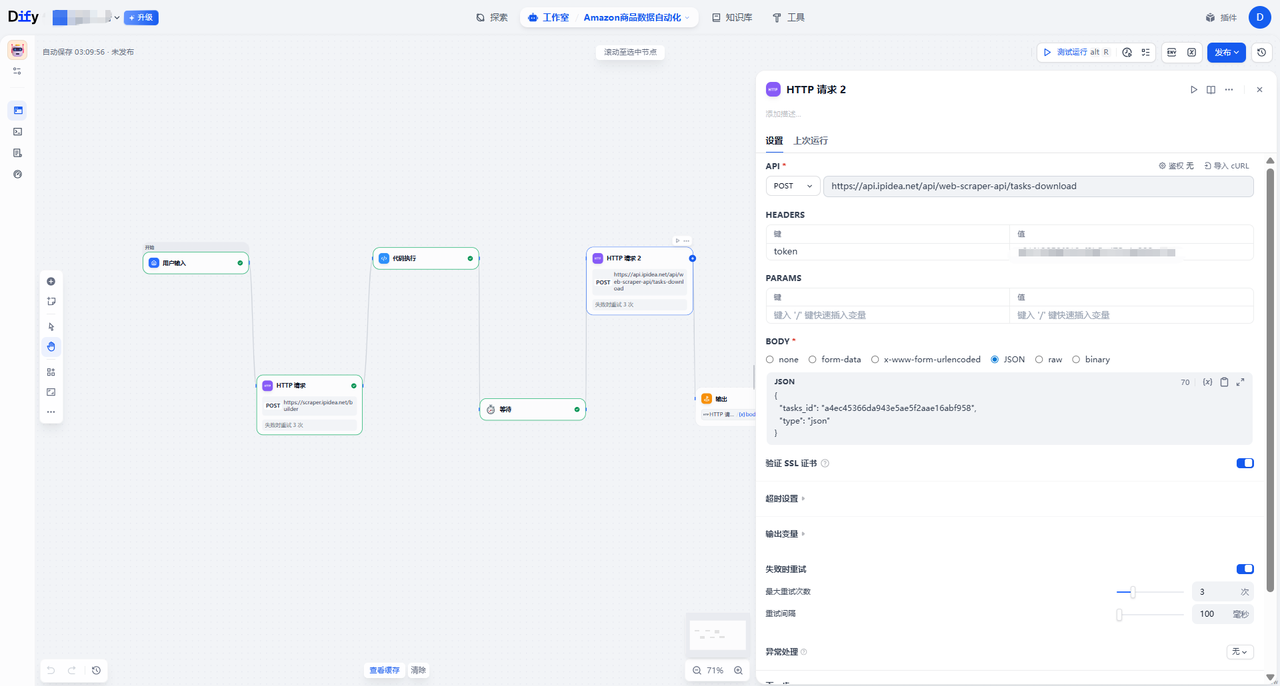
4.5 数据验证与清洗
完成所有步骤后,回到IPIDEA后台日志界面,可以清晰地看到API调用的完整记录。
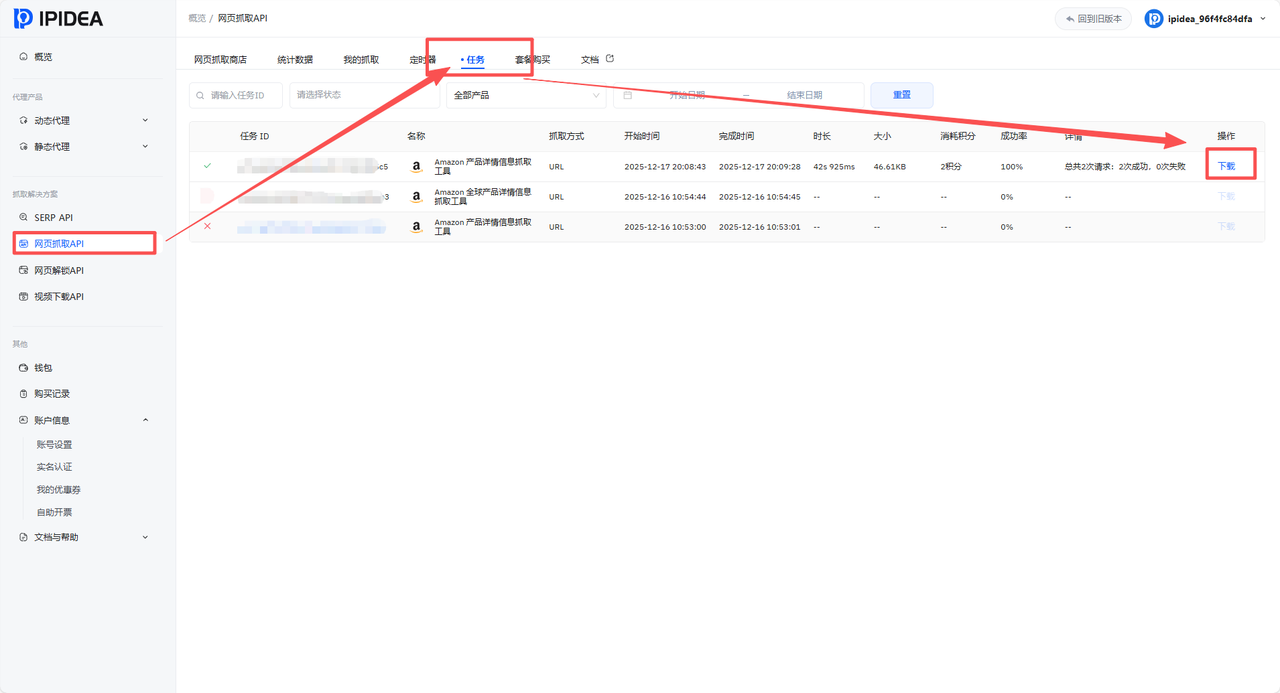
这里我们下载了CSV与JSON文件等下载入口。需要注意的是,由于数据存储在云端,下载链接需要特定的网络环境("魔法")才能访问。
打开下载的JSON文件,挤在一团了。面对如此详尽但稍显杂乱的原始数据,引入AI工具进行清洗是提升效率的最佳途径。
AI数据处理工具 :https://office.xiaohuanxiong.com/home
经过AI的自动化处理,清洗后的数据报表将杂乱的信息转化为结构清晰、可直接用于比价分析的表格。
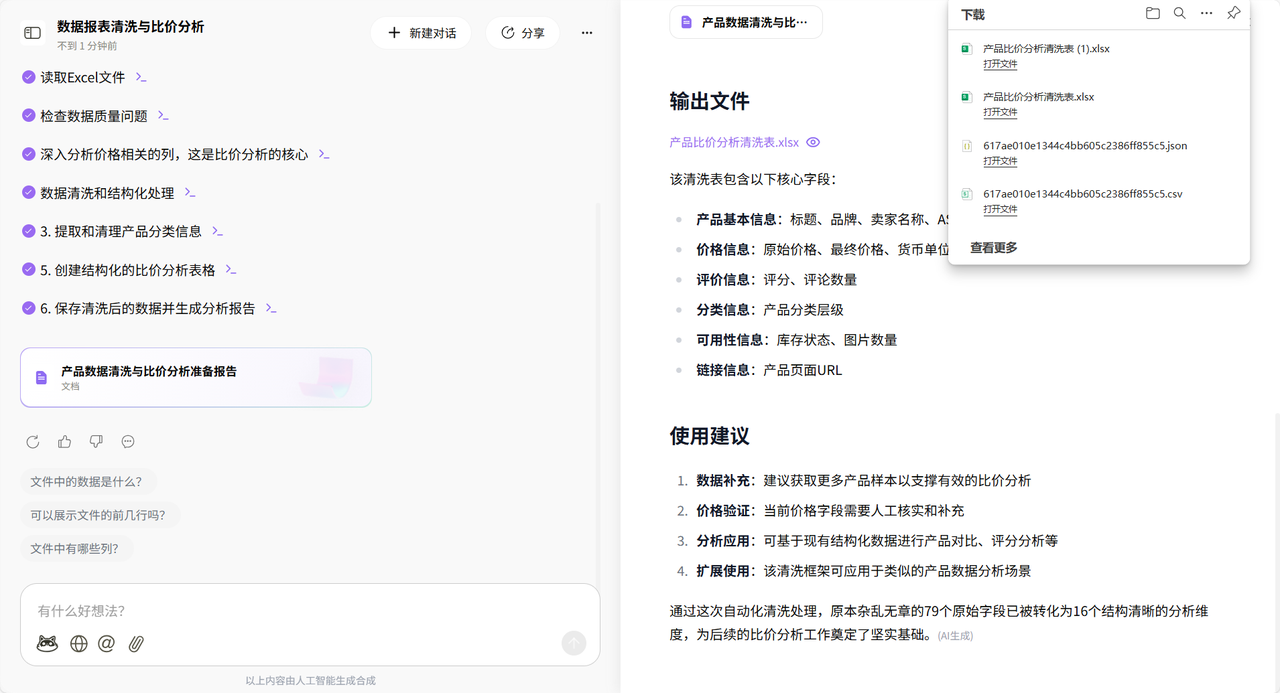
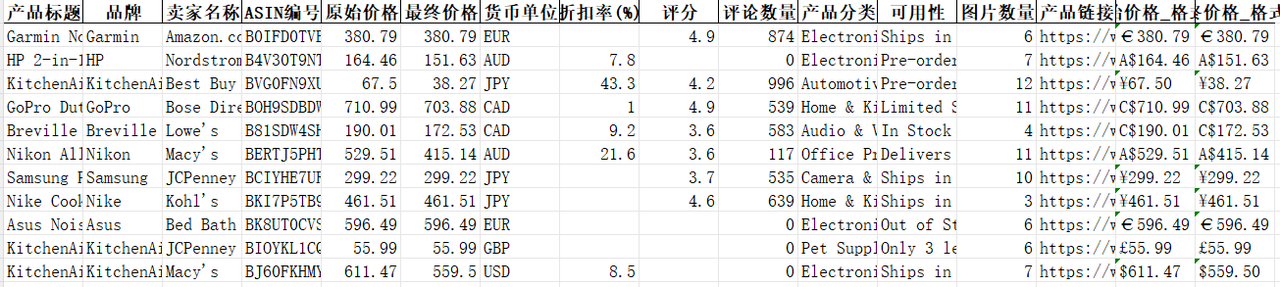
至此,从IPIDEA的底层网络支持,到Dify的流程编排,再到AI的数据清洗,一条完整的Amazon商品比价自动化采集链路打通。
第五章 总结
通过上述实战,我们已经利用IPIDEA和Dify成功实现了Amazon电商数据的自动化采集。在技术层面,IPIDEA通过全球住宅IP池与智能路由技术,成功解决了Amazon严苛的反爬虫封锁与地理位置限制问题,确保了数据的真实可用。在应用层面,结合Dify等自动化编排工具,大大降低了开发者的技术门槛。企业无需组建庞大的爬虫维护团队,即可通过标准化的API接口,实现对竞品价格、库存及排名的在线监控。
这种"高质量IP代理 + 自动化工作流 + AI数据处理"的组合模式,将运营人员从繁琐的手工记录中解放出来,让商业决策基于精准的实时数据,从而实现了跨境电商运营的降本增效。对于致力于在Amazon全球站点深耕的品牌而言,掌握这一套自动化采集技术栈,即是掌握了市场竞争的主动权。