一、数据集基本概况
本次分析的数据集包含10,000条记录 和8个字段,数据质量优秀,无缺失值和重复行。
我用夸克网盘给你分享了「Updated Quality of Life Data 代码+数据集」,点击链接或复制整段内容,打开「夸克APP」即可获
| 字段名称 | 数据类型 | 说明 |
|---|---|---|
| id | int64 | 唯一标识符 |
| gender | object | 性别(Male/Female) |
| occupation_type | object | 职业类型(14种) |
| avg_work_hours_per_day | float64 | 平均每日工作时间 |
| avg_rest_hours_per_day | float64 | 平均每日休息时间 |
| avg_sleep_hours_per_day | float64 | 平均每日睡眠时间 |
| avg_exercise_hours_per_day | float64 | 平均每日锻炼时间 |
| age_at_death | int64 | 死亡年龄 |
《Work-Life Balance and Longevity Dataset》是一份聚焦个体生活方式与寿命关联的合成数据集,涵盖10,000个个体的年龄、职业、日均工作、休息、睡眠、锻炼时长及死亡年龄等核心信息,不仅具备每日活动时长总和约24小时的现实约束、5%极端生活模式异常值等特征,还内置了睡眠时长与寿命的非线性关系、职业及性别维度的差异化规律,其意义与价值在于为回归建模、机器学习实践、统计分析等研究工作提供了高质量数据支撑,既能助力探索工作时长、睡眠时长等因素对寿命的具体影响,又可用于教学场景中特征工程、模型稳健性测试等知识点的实操演示,为揭示生活方式与长寿之间的内在联系提供了可靠的数据基础。
二、代码
1. 数据加载:load_data函数
python
def load_data(file_path):
"""读取数据并进行基本信息探索"""
print("正在读取数据...")
df = pd.read_csv(file_path)
print(f"数据集规模: {df.shape[0]}行 × {df.shape[1]}列")
# 检查缺失值
missing = df.isnull().sum()
if missing.sum() > 0:
print(f"存在缺失值的列: {missing[missing > 0].index.tolist()}")
else:
print("无缺失值")
# 检查重复行
duplicates = df.duplicated().sum()
if duplicates > 0:
print(f"发现 {duplicates} 个重复行")
else:
print("无重复行")
return df- 数据读取 :使用
pd.read_csv从指定路径读取CSV文件,将数据加载到DataFrame中,并打印数据集的规模,让我们对数据量有个初步认识。 - 缺失值检查 :通过
isnull().sum()统计每列的缺失值数量。如果存在缺失值,打印出包含缺失值的列名;若无缺失值,则给出相应提示。这一步对于了解数据完整性非常关键,缺失值可能会影响后续分析结果。 - 重复行检查 :利用
duplicated().sum()统计重复行的数量。若有重复行,告知用户重复行的个数;若没有,则提示无重复行。重复行可能会干扰数据分析,所以需要提前排查。最后返回加载并检查后的DataFrame。
2. 数据统计分析:analyze_data函数
python
def analyze_data(df):
"""数据统计分析"""
print("\n正在进行统计分析...")
# 分离数值型和分类型变量
numeric_cols = df.select_dtypes(include=[np.number]).columns.tolist()
categorical_cols = df.select_dtypes(include=['object']).columns.tolist()
# 排除ID列(唯一标识符,不参与分析)
if 'id' in numeric_cols:
numeric_cols.remove('id')
if 'ID' in numeric_cols:
numeric_cols.remove('ID')
if 'Id' in numeric_cols:
numeric_cols.remove('Id')
print(f"数值型变量: {numeric_cols}")
print(f"分类型变量: {categorical_cols}")
# 数值型变量描述统计
print("\n数值型变量统计描述:")
print(df[numeric_cols].describe().round(2))
# 分类型变量分布
print("\n分类型变量分布:")
for col in categorical_cols:
print(f"\n{col}: {df[col].value_counts().head()}")
return numeric_cols, categorical_cols- 变量类型分离 :使用
select_dtypes方法分别筛选出数值型和分类型变量,并将其列名存储在相应列表中。这样有助于针对不同类型变量进行特定的分析。 - 排除ID列 :检查数值型变量列表中是否存在常见的ID列名(如
id、ID、Id),若存在则将其移除,因为ID列通常是唯一标识符,不参与实际的统计分析。 - 数值型变量描述统计 :调用
describe方法生成数值型变量的统计描述,包括计数、均值、标准差、最小值、四分位数和最大值,并保留两位小数打印出来。这些统计量能让我们快速了解数值型变量的集中趋势、离散程度等特征。 - 分类型变量分布 :遍历分类型变量列表,对每个分类型变量使用
value_counts方法统计其不同取值的数量,并打印前5个值,以此了解分类型变量的分布情况。最后返回数值型和分类型变量的列名列表。
3. 数据可视化分析:visualize_data函数
python
def visualize_data(df, numeric_cols, categorical_cols, output_dir='.'):
"""数据可视化分析"""
print(f"\n正在生成可视化图表,保存到: {output_dir}")
# 1. 数值型变量分布
if numeric_cols:
plt.figure(figsize=(15, 10))
for i, col in enumerate(numeric_cols, 1):
plt.subplot(2, 3, i)
plt.hist(df[col], bins=30, alpha=0.7, edgecolor='black')
plt.title(col)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(f"{output_dir}/numerical_distributions.png", dpi=300)
plt.close()
print("✓ 数值型变量分布图已保存")
# 2. 相关性分析
if len(numeric_cols) >= 2:
plt.figure(figsize=(10, 8))
corr_matrix = df[numeric_cols].corr().round(2)
plt.imshow(corr_matrix, cmap='RdBu_r', vmin=-1, vmax=1)
plt.xticks(range(len(numeric_cols)), numeric_cols, rotation=45)
plt.yticks(range(len(numeric_cols)), numeric_cols)
plt.colorbar(label='相关系数')
plt.title('变量相关性热力图')
plt.tight_layout()
plt.savefig(f"{output_dir}/correlation_analysis.png", dpi=300)
plt.close()
print("✓ 相关性分析图已保存")
# 3. 性别对比
if 'gender' in categorical_cols and numeric_cols:
# 计算合适的子图网格大小
n_vars = len(numeric_cols)
n_cols = 2
n_rows = (n_vars + n_cols - 1) // n_cols
plt.figure(figsize=(12, 5 * n_rows))
for i, col in enumerate(numeric_cols, 1):
plt.subplot(n_rows, n_cols, i)
data = [df[df['gender'] == g][col] for g in df['gender'].unique()]
plt.boxplot(data, labels=df['gender'].unique(), patch_artist=True)
plt.title(f'{col} - 性别对比')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(f"{output_dir}/gender_comparison.png", dpi=300)
plt.close()
print("✓ 性别对比分析图已保存")
# 4. 职业对比(只显示前5个职业)
if 'occupation_type' in categorical_cols and numeric_cols:
# 计算合适的子图网格大小
n_vars = len(numeric_cols)
n_cols = 2
n_rows = (n_vars + n_cols - 1) // n_cols
top_occupations = df['occupation_type'].value_counts().head().index
plt.figure(figsize=(12, 5 * n_rows))
for i, col in enumerate(numeric_cols, 1):
plt.subplot(n_rows, n_cols, i)
data = [df[df['occupation_type'] == occ][col] for occ in top_occupations]
plt.boxplot(data, labels=top_occupations, patch_artist=True, showfliers=False)
plt.title(f'{col} - 职业对比')
plt.xticks(rotation=45)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(f"{output_dir}/occupation_comparison.png", dpi=300)
plt.close()
print("✓ 职业对比分析图已保存")- 数值型变量分布可视化 :如果存在数值型变量,创建一个包含多个子图的图形。使用
plt.hist为每个数值型变量绘制直方图,设置合适的参数,如bins为30,alpha为0.7,edgecolor为黑色。添加标题和网格,然后使用plt.tight_layout优化子图布局,并将图表保存为指定路径下的numerical_distributions.png文件,最后关闭图形并提示保存成功。 - 相关性分析可视化 :当数值型变量数量不少于2个时,计算这些变量的相关系数矩阵
corr_matrix并保留两位小数。使用plt.imshow绘制热力图,设置颜色映射为'RdBu_r',范围从 - 1到1。设置xticks和yticks显示变量名,并旋转xticks标签45度。添加颜色条和标题,优化布局后保存为correlation_analysis.png文件,关闭图形并提示保存成功。 - 性别对比可视化 :若数据集中存在
gender分类型变量且有数值型变量,根据数值型变量数量计算合适的子图网格布局。为每个数值型变量创建一个子图,使用plt.boxplot绘制不同性别下该数值型变量的箱线图,设置patch_artist=True使箱线图有填充颜色。添加标题和网格,优化布局后保存为gender_comparison.png文件,关闭图形并提示保存成功。 - 职业对比可视化 :当数据集中存在
occupation_type分类型变量且有数值型变量时,类似性别对比的步骤,先获取前5个职业类型,根据数值型变量数量计算子图网格布局。为每个数值型变量创建子图,绘制不同职业类型下该数值型变量的箱线图,设置showfliers=False不显示异常值,添加标题、旋转xticks标签并添加网格,优化布局后保存为occupation_comparison.png文件,关闭图形并提示保存成功。
4. 保存统计结果:save_results函数
python
def save_results(df, numeric_cols, categorical_cols, output_dir='.'):
"""保存统计结果"""
print("\n正在保存统计结果...")
# 整体统计摘要
summary = df[numeric_cols].describe().round(2)
summary.to_csv(f"{output_dir}/overall_statistics.csv")
# 性别分组统计
if 'gender' in categorical_cols:
gender_stats = df.groupby('gender')[numeric_cols].mean().round(2)
gender_stats.to_csv(f"{output_dir}/gender_statistics.csv")
# 职业分组统计
if 'occupation_type' in categorical_cols:
top_occupations = df['occupation_type'].value_counts().head(10).index
occ_stats = df[df['occupation_type'].isin(top_occupations)].groupby('occupation_type')[numeric_cols].mean().round(2)
occ_stats.to_csv(f"{output_dir}/occupation_statistics.csv")
print("✓ 统计结果已保存")- 整体统计摘要保存 :生成数值型变量的统计描述摘要,并保留两位小数,然后将其保存为
overall_statistics.csv文件。 - 性别分组统计保存 :若数据集中存在
gender分类型变量,按性别对数值型变量进行分组,并计算每组的均值,保留两位小数后保存为gender_statistics.csv文件。 - 职业分组统计保存 :如果数据集中存在
occupation_type分类型变量,获取出现次数前10的职业类型。筛选出这些职业类型的数据,按职业类型对数值型变量分组并计算均值,保留两位小数后保存为occupation_statistics.csv文件。最后提示统计结果已保存。
5. 主函数:main函数
python
def main(file_path, output_dir='.'):
"""主函数:执行完整分析流程"""
print("=" * 60)
print("生活质量数据集分析")
print("=" * 60)
try:
# 1. 数据读取
df = load_data(file_path)
# 2. 统计分析
numeric_cols, categorical_cols = analyze_data(df)
# 3. 可视化分析
visualize_data(df, numeric_cols, categorical_cols, output_dir)
# 4. 保存结果
save_results(df, numeric_cols, categorical_cols, output_dir)
print("\n" + "=" * 60)
print("分析完成!")
print("=" * 60)
return df, numeric_cols, categorical_cols
except Exception as e:
print(f"\n分析出错: {str(e)}")
raise- 流程执行 :主函数作为整个分析流程的驱动者,首先打印分隔线和分析标题。然后依次调用
load_data函数加载数据,analyze_data函数进行统计分析,visualize_data函数进行可视化分析,save_results函数保存统计结果。分析完成后,再次打印分隔线并提示分析完成,最后返回加载的数据以及数值型和分类型变量的列名列表。 - 异常处理:如果在分析过程中出现异常,捕获异常并打印错误信息,然后重新抛出异常,以便调用者进行更详细的错误处理。
6. 程序入口
python
if __name__ == "__main__":
DATA_FILE = "Updated Quality of Life Data.csv"
OUTPUT_DIR = "."
df_result, numeric_cols_result, categorical_cols_result = main(DATA_FILE, OUTPUT_DIR)在程序入口处,指定要分析的数据集文件路径DATA_FILE和结果输出目录OUTPUT_DIR,然后调用main函数执行完整的数据分析流程,并将返回的结果赋值给相应变量。
三、结果分析
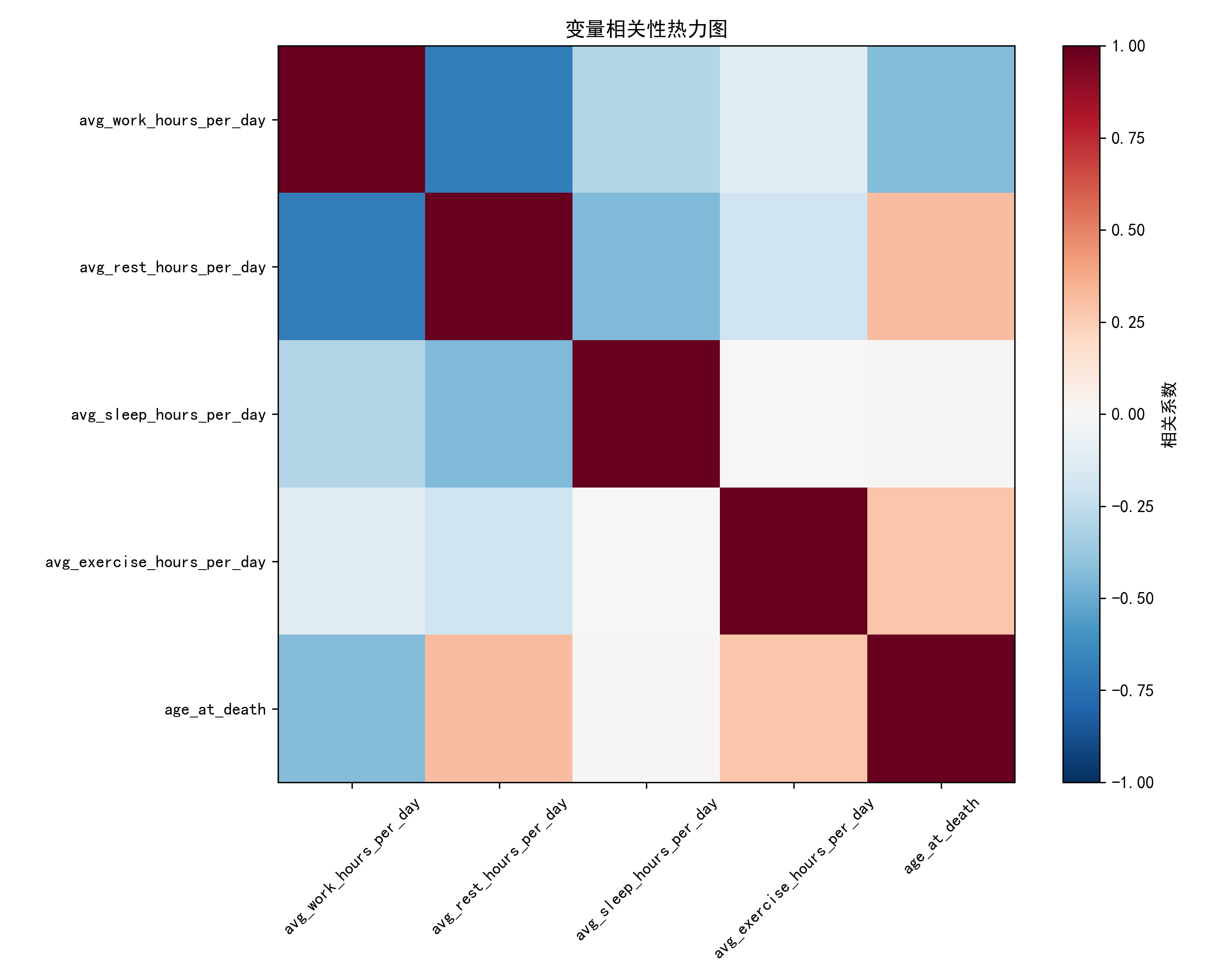
- 工作时间 vs 休息时间 :深蓝+深红的强对比,是显著负相关------工作越久,休息时间就越少,完全符合日常直觉。
- 睡眠时间/锻炼时间 vs 死亡年龄 :偏红色的浅色调,是弱正相关------睡得足、动得多的人,寿命大概率更长。
- 工作时间 vs 死亡年龄 :偏蓝色的浅色调,是弱负相关------长期超时工作,可能轻微拉低寿命水平。
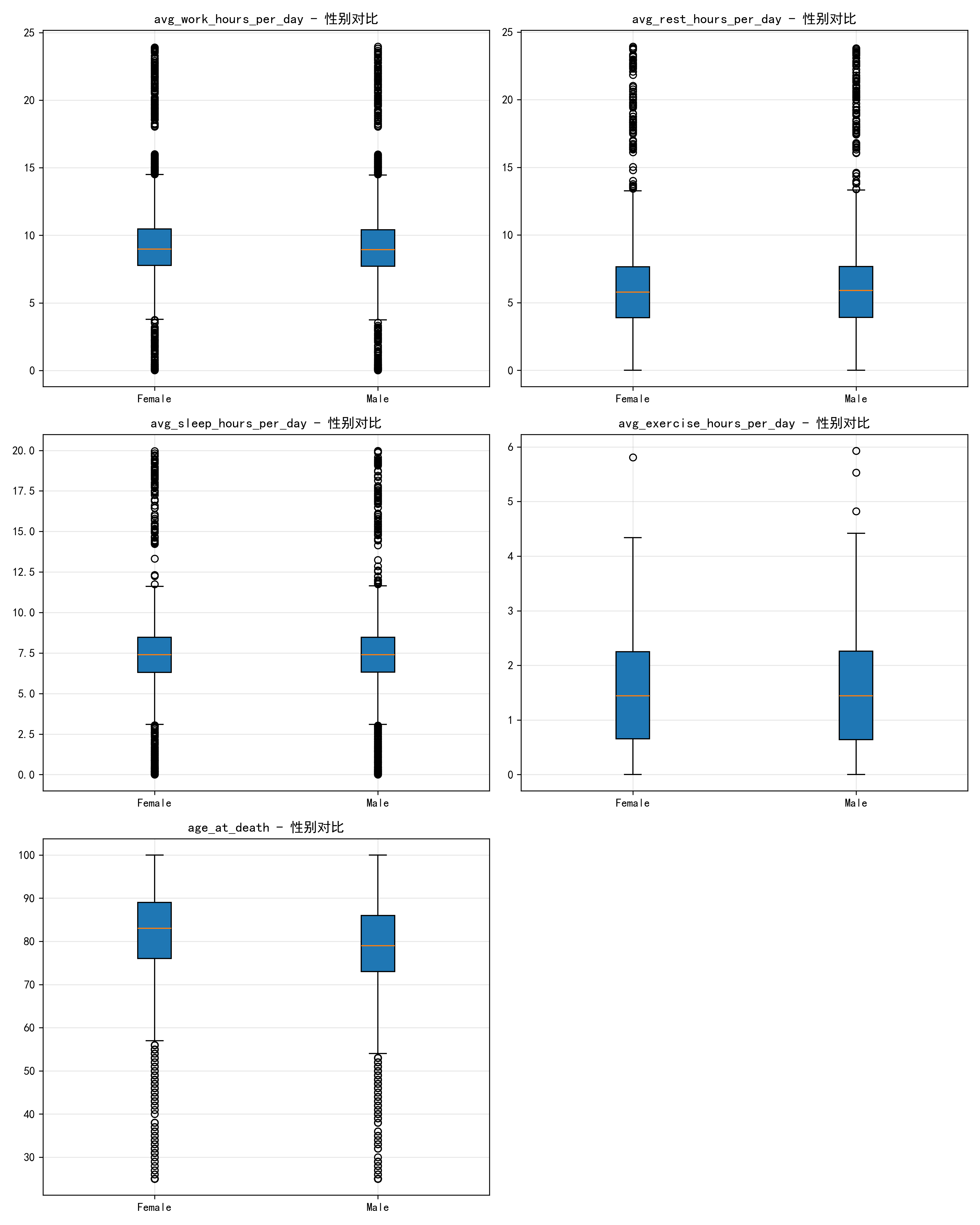
- 工作时间:男性箱线的中位数略高→ 男性日常工作时长稍长。
- 休息时间:女性箱线的中位数略高→ 女性休息时间比男性更充足。
- 睡眠时间:女性箱线的中位数明显高→ 女性更重视睡眠,符合"女性睡眠需求略高于男性"的生理特点。
- 锻炼时间:男女箱线几乎重合→ 男女锻炼时长差异很小。
- 死亡年龄:女性箱线的中位数显著高于男性→ 女性平均寿命比男性更长,和现实中的性别寿命规律一致。
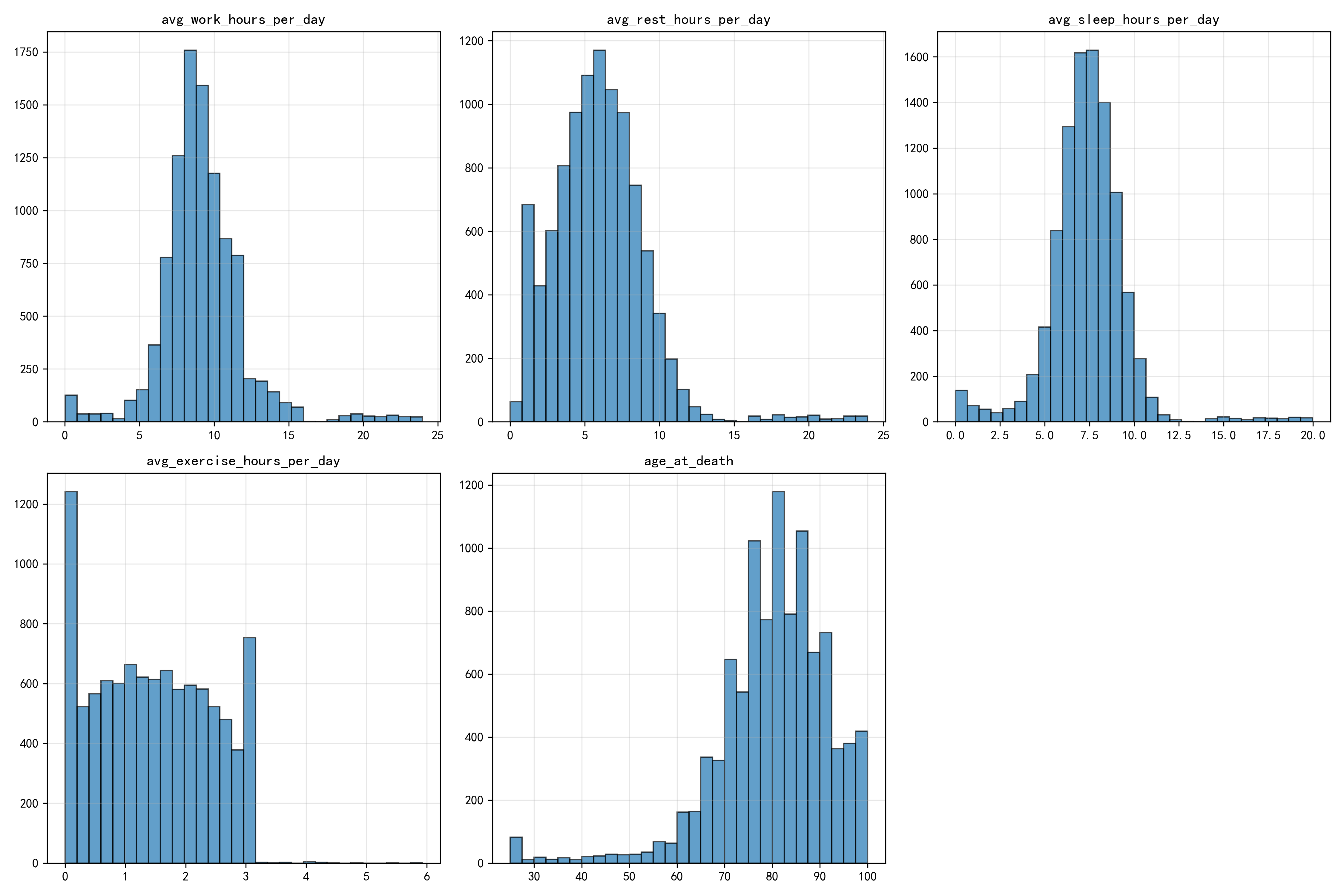
- 工作/休息时间:都呈"右偏分布"------大部分人每天工作/休息8-10小时,少数人(长尾部分)工作超15小时、休息不足5小时。
- 睡眠时间:分布很集中,峰值在7小时左右→ 大部分人能保持健康的睡眠时长。
- 锻炼时间:集中在1小时左右→ 人群锻炼时长差异不大,整体处于"适量"水平。
- 死亡年龄:近似"正态分布",峰值在80岁左右→ 样本人群的寿命符合正常人口的寿命分布规律。
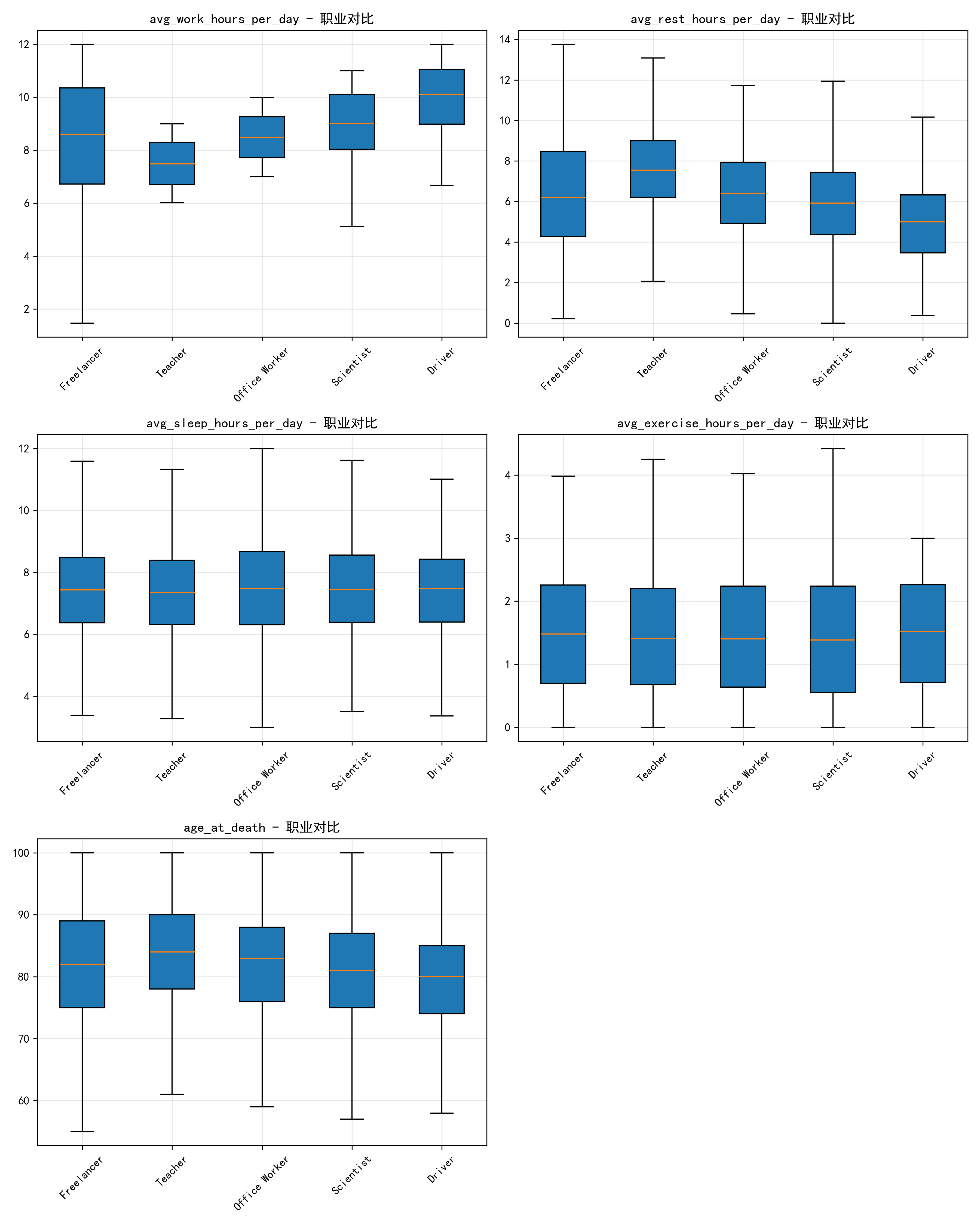
- 工作时间:Driver(司机)的箱线中位数最高→ 司机职业的工作强度最大。
- 休息时间:Teacher(教师)的箱线中位数最高→ 教师的休息时间相对更充裕。
- 睡眠时间:各职业差异不大→ 不同职业的睡眠时长都比较稳定。
- 锻炼时间:Freelancer(自由职业者)的箱线中位数略高→ 自由职业者的锻炼时间更灵活。
- 死亡年龄:Teacher的箱线中位数最高,Driver最低→ 教师的平均寿命更长,司机的职业健康压力相对更大。
作者及版权相关信息总结
-
作者信息
该数据集由 OLUWATOSIN ADEWALE 创作。
-
版权与许可
- 许可证类型:CC0: Public Domain(公共领域)

- 更新频率
数据集的预期更新频率为每年一次,用于持续完善数据内容以适配研究与教学需求。