11 月 18 日,OceanBase 正式开源了其首款 AI 原生数据库 seekdb (官网:https://www.oceanbase.ai/ )。这是一个专门为AI 应用打造的新一代混合搜索引擎,能够统一处理向量、全文、多模态、结构化/半结构化数据 ,同时提供低成本、本地化、可嵌入的使用体验,seekdb仓库地址( https://github.com/oceanbase/seekdb )。
随着 RAG、Agent、多模态应用的全面爆发,AI 应用对数据层的要求已经远远超过传统数据库的范畴。检索不仅需要快,更需要"懂语义""懂上下文""懂业务特征"。seekdb 正是在这样的背景下诞生:既要方便开发者,又要支持企业级能力;既要轻量级嵌入式,又要有 OceanBase 的内核实力。
本篇文章作为我深入 seekdb 的初体验总结,也希望能帮助更多开发者轻松上手这一款极具潜力的 AI 原生数据库。
一、seekdb 是什么?为什么值得关注?
官方给出的定义是:
AI-Native Search Database ------ 为 AI 应用打造的混合搜索引擎
但我使用后的第一印象非常直接:
它像 SQLite 一样轻量、像 Elasticsearch 一样全文检索、又像向量数据库一样能进行 embedding 搜索,并且统一在一个引擎里。
它解决的正是当前 AI 开发者普遍面临的问题:
● 数据类型杂 :文本、结构化字段、文档、图片 embedding......
● 需要混合搜索 :语义搜索 + 关键词过滤 + 结构化条件
● 向量库部署复杂 :常见向量库需要独立进程、配置复杂、资源消耗大
● RAG / Agent 对检索要求提升 :不仅要"查得到",更要"查得准"
而 seekdb 的优势在于:
1. 开箱即用:不需要启动 server
像 SQLite 一样:
pip install pyseekdb → 写代码 → 直接跑。
开发者连"数据库服务进程"都不用考虑。
2. 真正的统一存储与检索
一个引擎搞定:
● 文本全文检索(倒排索引)
● 向量语义检索(内置 embedding)
● JSON / 半结构化数据查询
● 标签过滤、字段查询
这种数据统一能力目前在国产数据库里几乎是唯一的。
3. 天然兼容 AI 应用场景
seekdb 最适用于如下领域:
● RAG 系统与企业知识库
● AI Agent 的长期记忆系统
● 个性化推荐、企业内部搜索引擎
● 边缘端AI(车载、教育设备、机器人)
● 语义搜索、图文混检、多模态检索
无论你是做 AI 系统、应用、还是轻量级工具,seekdb 的嵌入式能力都会极大提升开发效率。
二、我的上手体验:嵌入式数据库也能很"丝滑"
我基于官方文档与 Python SDK 进行了简单体验。从创建 Collection、添加文档、到执行混合查询,全流程非常顺畅。
示例代码(关键片段)如下:
python
import pyseekdb
client = pyseekdb.Client()
collection = client.create_collection(name="notes")
docs = ["今天跑了 10 公里", "Mapbox polyline 编码研究", "Python asyncio 对比 gevent"]
ids = ["run1", "map1", "py1"]
metas = [{"tag":"run"}, {"tag":"map"}, {"tag":"python"}]
collection.add(ids=ids, documents=docs, metadatas=metas)
res = collection.query(query_texts="跑步 状态", n_results=2)全流程的感觉可以用四个字概括:零门槛,零负担。
● 不需要 Docker ● 不需要配置文件 ● 不需要 server 进程 ● 不需要自己做 embedding
对于开发者来说,这种"拿来即用"的体验太难得了。
三、seekdb 能做什么?------AI 时代的"统一数据底座"
在海量 AI 应用爆发的今天,一个问题被反复提起:
向量搜索够吗?结构化数据怎么办?要不要再加全文检索?多模态如何统一?
过去,我们通常需要:
● 一个向量数据库处理 embedding 搜索
● 一个全文引擎处理关键字检索
● 一个关系数据库管理结构化数据
● 外加一些 glue code 做聚合、过滤与顺序控制
不仅麻烦,而且每多一个组件,部署成本、故障概率、学习成本都会指数上升。
seekdb 的出现,本质上是在重新定义 AI 应用的数据层。
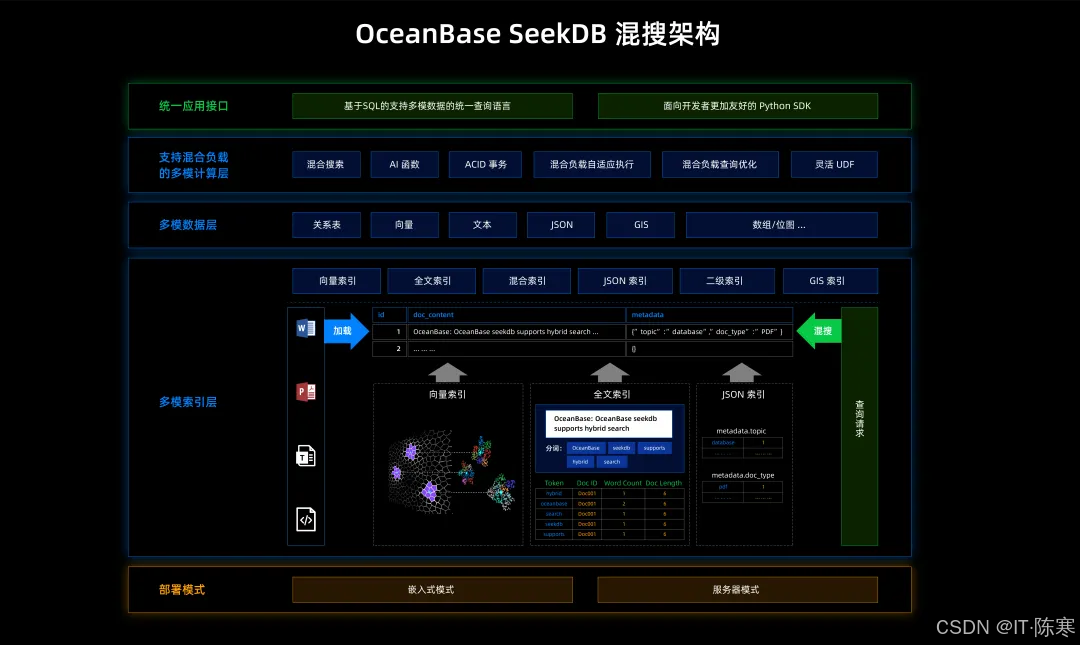
它在一个轻量级引擎里原生提供:
| 数据类型 | seekdb 能力 |
|---|---|
| 文本(Text) | 全文检索、BM25、倒排索引 |
| 向量(Vector) | HNSW、ANN 搜索、自动 Embedding |
| 结构化(Structured) | 类 MySQL 模式,支持字段过滤、条件搜索 |
| 半结构化(Semi-Structured) | JSON-like 存储与检索 |
| 多模态(Multimodal) | 支持执行 pipeline 让文本、向量、属性一起参与评分 |
一句话总结:
它不是用一个数据库"模拟"多模能力,而是把多模检索当作"第一公民"在底层统一实现。
这让 AI 应用的开发方式产生质变:
● 你不再需要维护复杂的 Elastic + Milvus + MySQL 组合拳
● 你可以只依赖单文件数据库完成检索、过滤、排序与embedding
● 更重要的是:它适合从个人开发者到企业级研发的全场景
对 AI 开发者而言,这就是"重新发明 SQLite",但面向 AI 时代。
四、怎么玩 seekdb?------10 分钟完成 AI 应用的"数据大脑"
seekdb 的使用门槛低到离谱:
无需服务端、无需配置、无需额外组件。一个 pip install 就能跑完整的混合搜索引擎。
下面我以最典型的三种玩法介绍你能用它快速构建什么。
玩法 1:本地 RAG / 个人知识库 ------ 零到一只需 10 行代码
创建 Collection、添加文档、执行混合检索,只需要几行:
python
import pyseekdb
client = pyseekdb.Client()
coll = client.create_collection("notes")
coll.add(
ids=["1"],
documents=["今天跑了十公里,心率状态不错"],
metadatas=[{"tag": "run"}]
)
res = coll.query("跑步 状态", n_results=3)
print(res)无需维护向量模型、无需独立全文检索系统,seekdb 会自动完成:
● embedding ● 向量存储 ● 倒排索引 ● BM25 混合排序
你只需关心"使用",不再需要关心"搭积木"。
玩法 2:快速构建 AI Agent 的长期记忆(建议结合 PowerMem)
如果你做 Agent(Coze、Reka、LangChain agent、cursor agent 等),一定会遇到:
● 如何让 Agent 有"长期记忆"?
● 如何让 Agent 的记忆可筛选、可检索、可清理?
● 如何让 Agent在处理多模态任务时不乱套?
seekdb + PowerMem 可以天然解决:
✔ 自动 embedding
✔ 结构化 + 向量 + 全文 检索统一
✔ 记忆按 Session / Agent 分区
✔ 多模记忆(文本 / 图像描述 / JSON)统一存储
示例:
python
from powermem import MemClient
mc = MemClient(storage="seekdb")
mc.add_memory("agent1", "用户喜欢跑步,偏好10公里训练")
result = mc.search("agent1", "今天继续跑步吗?")
print(result)只需几步,你就能为 Agent 配上真正的"可进化记忆"。
玩法 3:用 seekdb 做多模态 RAG(建议结合 PowerRAG)
传统 RAG 的难点:
● 大量 PDF / 表格解析
● 文本向量化处理链复杂
● 检索质量难优化
● 多模态(图像 / 表格 / 文档)处理链更复杂
● 权限、租户隔离难搞
PowerRAG 将复杂流程封装成"开箱即用"的 SDK,而 seekdb 则作为其底层引擎,提供:
● 向量 + 全文 + 结构化 三路混合检索
● 更快的索引构建
● 更稳的批量插入
● 支持企业级权限、过滤条件
这意味着:
你可以用极低的成本构建一套真正可用的企业级 RAG 系统。
五、为什么推荐大家在 GitHub 上玩 seekdb?(不是口号,是趋势)
一个产品的未来不是由官方定义的,而是由开发者生态定义的。
seekdb 天然适合开源协作的三个原因:
(1)它足够轻量、足够"嵌入式",特别适合做 Demo / 插件 / SDK
例如:
● VSCode 插件(AI 辅助代码搜索)
● 本地知识库
● 移动端 AI 应用
● 车载模型轻量存储
● 离线搜索工具
几乎所有这些场景,都可以直接放一个 seekdb 文件即可运行。
python
目前只能在linux环境运行,据说未来会支持Mac和其他系统(2)API 简洁,非常方便重复造轮子
你可以轻松写:
● JS / TS SDK ● Flutter binding ● Rust binding ● 局部增强插件
并贡献到 GitHub,让更多人踩着你的肩膀继续创新。
(3)seekdb 的未来方向会受 GitHub issue / PR 影响非常大
官方已经明确支持:
● 社区扩展插件 ● 多模态支持 ● edge AI 应用 ● 多 SDK 生态 ● 和 MCP 协议的集成
也就是说:
你写的任何工具、示例、插件,都可能成为 seekdb 的"官方推荐实践"。
六、结语:AI 时代的数据库应该更简单、更强大、更贴近开发者
seekdb 正在尝试做一件很酷的事情:
把传统大数据库的能力,用"嵌入式"的方式交到所有开发者手里。
它的轻量、不用 server、自动 embedding、统一检索、兼容 MySQL、友好 API,让我对"AI 原生数据库"这个概念有了更深的理解。
未来的 AI 应用体系,不再是模型中心,而是"模型 × 数据 × 系统"的整体能力。
seekdb 正好站在这个趋势的中心。