1. 准备
jdk 此处不再赘述
Hadoop3.3.6下载:https://archive.apache.org/dist/hadoop/common/hadoop-3.3.6/
2. 配置主机名
2.1 修改hosts
powershell
# 修改配置文件
vim /etc/hosts
# 增加以下内容
192.168.195.10 hadoop12.2 设置主机名和配置免密登录
powershell
# 设置主机名
hostnamectl set-hostname hadoop1
# 生成密钥,一路回车即可
ssh-keygen -t rsa
# 上传公钥到服务器:用户名@主机名;输入命令后,要输一次密码
ssh-copy-id root@hadoop1
# 测试,设置成功的话,直接会进入
ssh root@hadoop1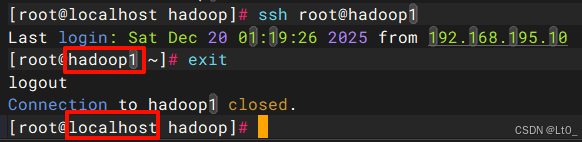
3. 安装
解压到指定目录
shell
tar -zxvf hadoop-3.3.6.tar.gz -C /opt/module/
配置环境变量
shell
# 修改环境配置文件
vim /etc/profile
# 修改为自己的安装目录
export HADOOP_HOME=/opt/module/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
# 刷新环境配置
source /etc/profile
# 查看版本
hadoop version
4. 配置(记得修改自己Hadoop的安装路径)
4.1 修改core-site.xml
vim /opt/module/hadoop-3.3.6/etc/hadoop/core-site.xml
xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
<description>指定HDFS中NameNode的地址,9820是RPC通信的端口</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/module/hadoop-3.3.6/tmp</value>
<description>hadoop的临时目录</description>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
<description>设置 Web UI 为静态用户</description>
</property>
</configuration>4.2 修改hdfs-site.xml
vim /opt/module/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>指定HDFS储存数据的副本数目,默认情况下为3份</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop1:9868</value>
<description>指定 SecondaryNameNode 的WebUI监听地址和端口</description>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9870</value>
<description>NameNode Web端访问地址</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/module/hadoop-3.3.6/hdfs/namenode</value>
<description>指定 NameNode 存储其元数据的本地目录路径</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/module/hadoop-3.3.6/hdfs/datanode</value>
<description>指定 DataNode 存储HDFS数据块(blocks)的本地目录路径</description>
</property>
</configuration>4.3 修改mapred-site.xml
vim /opt/module/hadoop-3.3.6/etc/hadoop/mapred-site.xml
xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定MR运行在yarn上</description>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
$HADOOP_CONF_DIR,
$HADOOP_COMMON_HOME/share/hadoop/common/*,
$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,
$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,
$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,
$HADOOP_YARN_HOME/share/hadoop/yarn/*,
$HADOOP_YARN_HOME/share/hadoop/yarn/lib/*,
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*
</value>
<description>指定MapReduce任务运行所需依赖jar</description>
</property>
</configuration>4.4 修改yarn-site.xml
vim /opt/module/hadoop-3.3.6/etc/hadoop/yarn-site.xml
xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
<description>指定YARN的ResourceManager的地址</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>指定reduce获取数据的方式</description>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
<description>指定shuffle服务的类</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>启动日志聚合</description>
</property>
</configuration>4.5 修改workers
vim /opt/module/hadoop-3.3.6/etc/hadoop/workers
powershell
hadoop14.6 修改hadoop-env.sh
vim /opt/module/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
shell
# 配置 JAVA_HOME 和 HADOOP_HOME 环境变量
export JAVA_HOME=/opt/module/jdk1.8.0_301/
export HADOOP_HOME=/opt/module/hadoop-3.3.6/
# 设置启动集群的用户
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root4.7 格式化HDFS
shell
hdfs namenode -format注意,执行该命令时,要保证 dfs.namenode.name.dir和dfs.datanode.data.dir配置的目录不存在
4.8 启动
cd /opt/module/hadoop-3.3.6/sbin
shell
start-dfs.sh
start-yarn.sh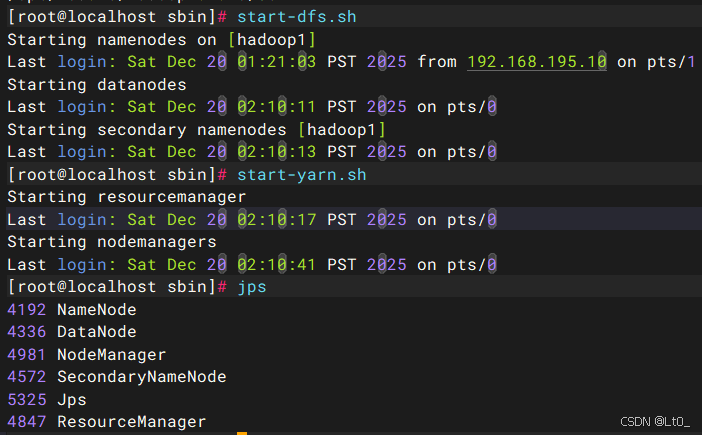
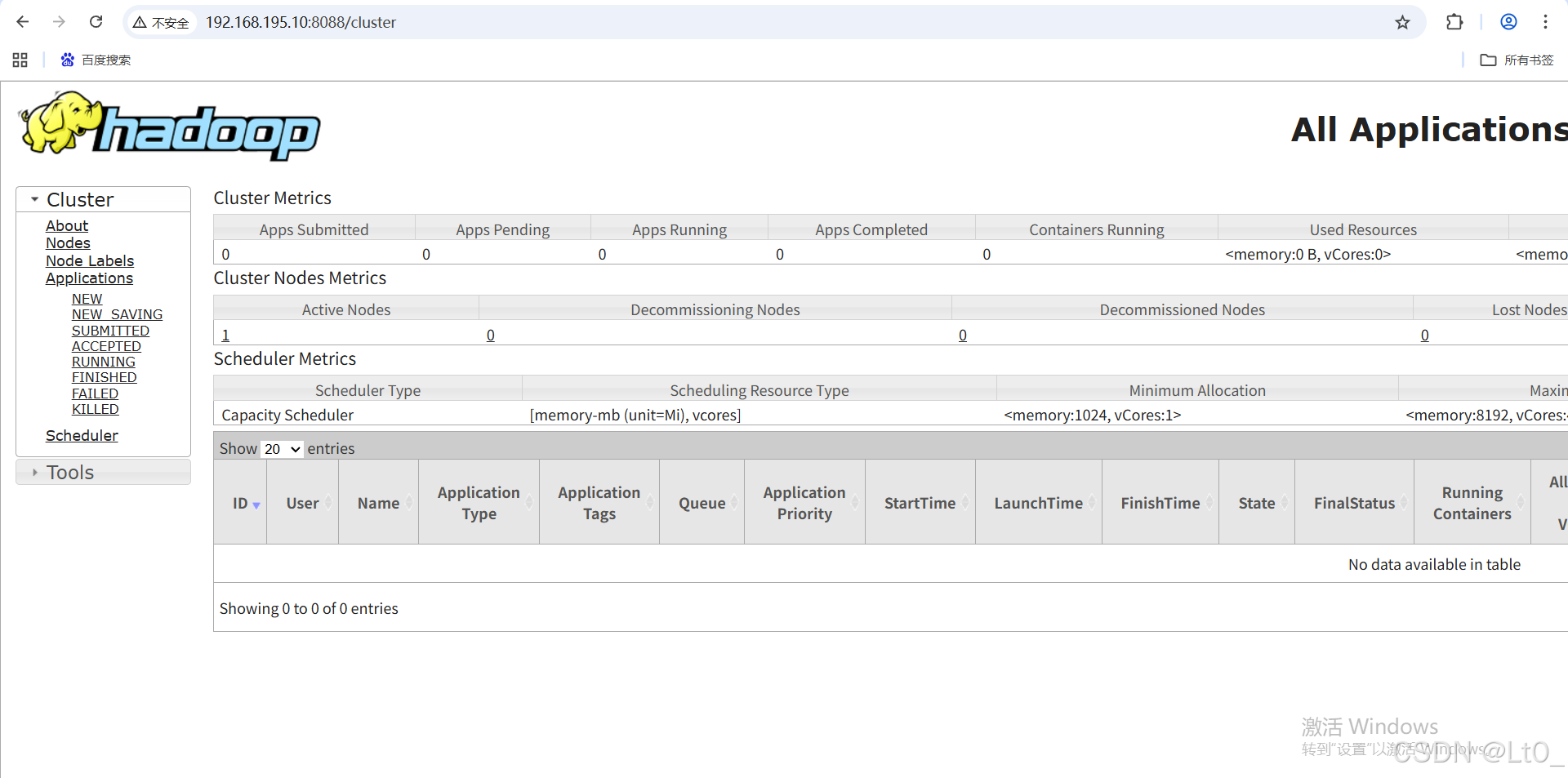
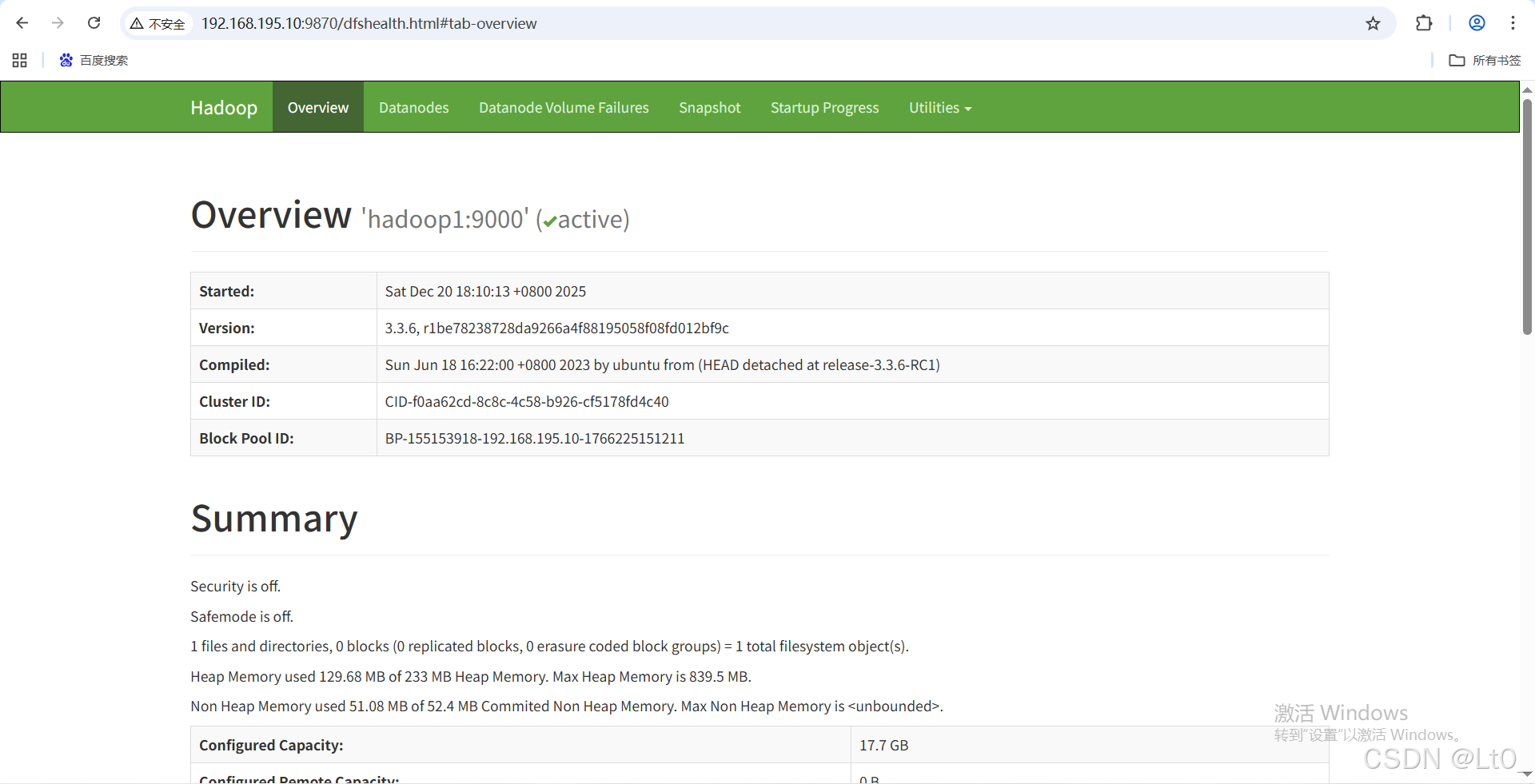
4.9 访问UI界面
HDFS的WebUI界面:9870 端口
YARN的WebUI界面:8088 端口