
论文标题:xLSTM-Mixer: Multivariate Time Series Forecasting by Mixing via Scalar Memories
论文链接:https://github.com/mauricekraus/xLSTM-Mixer
研究背景
在气象预测、交通管理、能源调度、金融市场等领域,我们每天都在和时间序列打交道。这些数据的显著特点往往是多变量、长序列、强依赖,比如上百个气象指标同时变化上千个时间步。
问题是------随着序列变长、通道变多,模型开始"吃力":
传统的 RNN / LSTM 虽然顺序建模能力强,但对长依赖记忆力差,训练也慢;
Transformer虽然强大,但注意力机制的计算量随序列长度平方增长,对长序列预测非常不友好;
而 线性模型比如DLinear、NLinear虽然轻快,却容易忽视复杂的非线性动态关系。
这就引出本文的一个核心问题,👉 有没有可能让"老牌的循环网络",既捕捉长程依赖,又保持高效?
研究思路:让循环模型学会"混合思考"
来自德国达姆施塔特工业大学与荷兰埃因霍温理工大学的研究团队提出了一个全新的框架,xLSTM-Mixer:一种基于标量记忆混合的多变量时间序列预测模型。他们的想法非常有趣:
既然Transformer 善于混合不同时间点的信息(time mixing),而 LSTM 善于记忆时间依赖(temporal memory),那为什么不让LSTM也学会"混合"?
于是,作者提出了xLSTM-Mixer,把传统LSTM的记忆机制和Mixer结构的通道混合思路结合了起来,形成一种"可混合的记忆网络"。
模型方法
整套架构可以分成三个阶段:
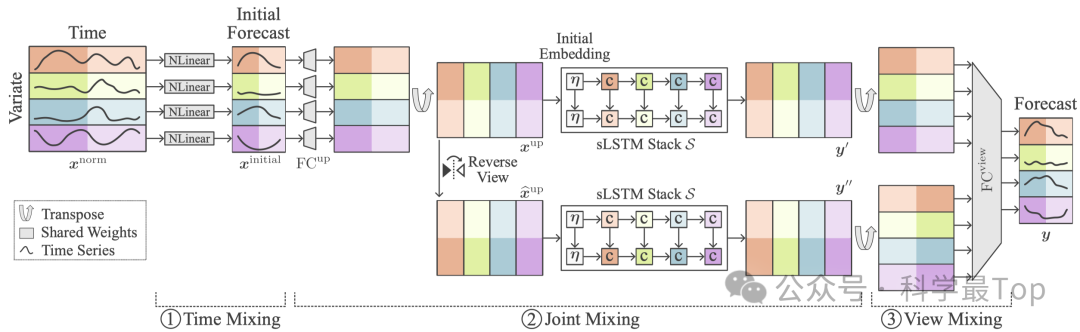
第一层:线性打底(Time Mixing)
先用一个轻量的NLinear 模型对每个通道独立建模,快速捕捉趋势变化,这个线性预测在各通道间共享权重,相当于一种天然的正则化。
第二层:sLSTM 堆栈(Joint Mixing)
模型使用一系列 sLSTM(scalar LSTM)块来处理非线性特征。注意不是沿时间展开,而是"跨通道地循环"------每一步处理一个通道,但在隐层中共享时间记忆。这种方式让模型能高效地捕捉变量之间的动态耦合关系。
此外,还加入了一个可学习的初始 token(soft prompt),类似于语言模型的"提示词",帮助网络自动适应不同数据集的特性。
第三层:双视角融合(View Mixing)
训练时,模型不仅使用原始嵌入进行预测,还反转嵌入顺序(reverse view)再预测一次。最后通过线性融合获得最终结果。这种"多视角"设计相当于一种正反向思考机制,让模型在学习时更稳、更准。
实验结果
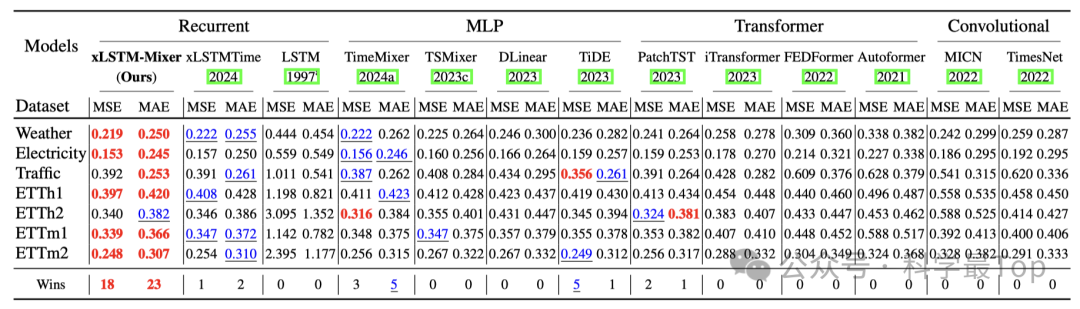
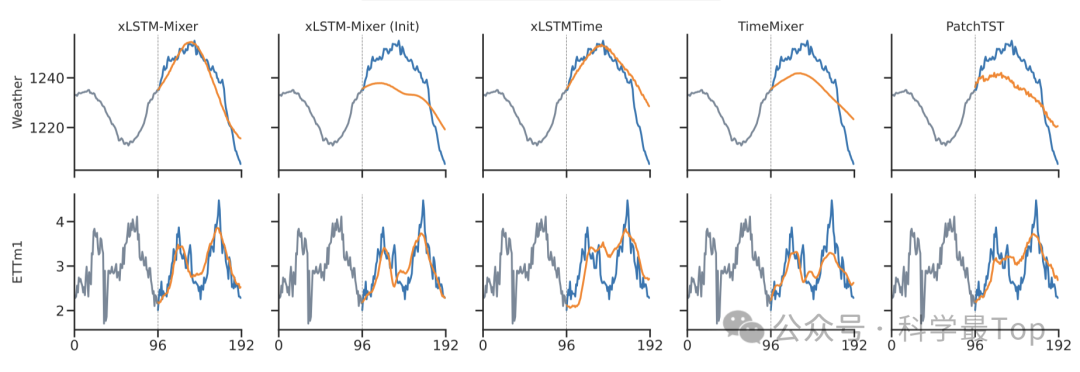
与Transformer、MLP、CNN、RNN等13种主流模型对比,xLSTM-Mixer几乎全面领先。尤其是在长序列预测上,它的性能优势最明显:相比于TimeMixer、PatchTST等新一代模型,误差下降了3%~5%,而推理效率却保持在RNN级别的轻量水准。
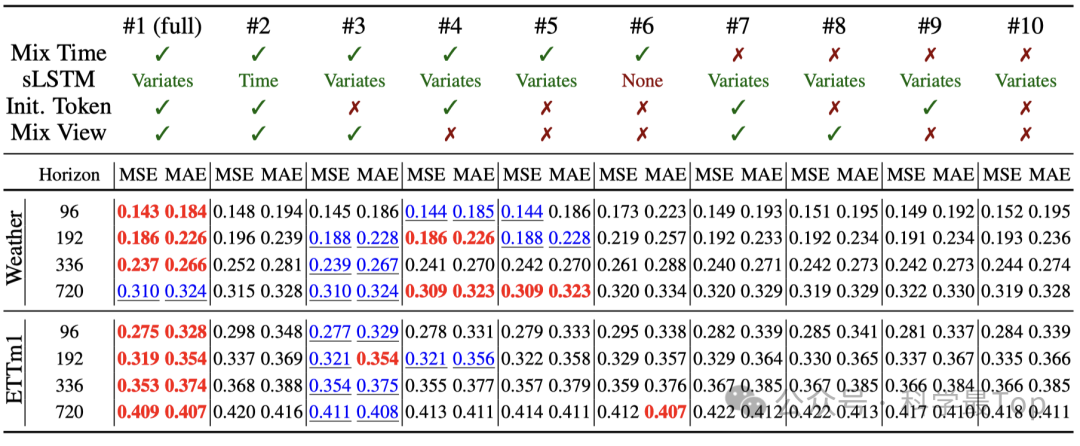
消融实验结果显示:
去掉时间混合(NLinear) → 性能下降 10% 以上;去掉 sLSTM 堆栈 → 模型几乎退化为线性预测;去掉初始token或双视角融合 → 仍能工作,但预测更不稳。
此外,作者还发现:
增大隐层维度 D 对长预测明显有益;模型能稳定处理超长 lookback 窗口;初始token在不同数据集上会自动学习出周期性或趋势性结构,具有可解释性。
写在最后:循环网络的"第二春"
过去几年,Transformer主导了时间序列预测的舞台,但随着 xLSTM-Mixer 等新模型的出现,研究者重新看到了循环网络的潜力。也许不是LSTM不行,而是我们还没给它足够好的结构。"
**大家可以关注我【科学最top】,第一时间follow时序高水平论文解读!!!**获取时序论文合集
