随着互联网系统规模不断扩大,高可靠、高并发以及降本增效 ,已经成为几乎所有技术团队无法回避的现实挑战。从分布式系统的整体架构,到某一个热点接口、某一段关键代码,性能优化不再是"锦上添花"的能力,而是工程师的基本功 。
在面试中,它往往决定你是"会写代码",还是"能扛系统"。
然而,在真实的工作场景中,很多性能问题的处理方式却非常原始:
- 没有量化指标,只能凭经验猜
- 找不到瓶颈,只能"加机器、扩线程"
- 出现问题靠临时补救,治标不治本
- 缺乏方法论,也缺乏工具体系的支撑
性能优化是软件工程的深水区 ,也是衡量程序员技术深度的重要标志。
要真正掌握性能优化,第一步不是"调参数",而是建立正确的认知和方法论。
1. 性能优化方法论
1.1 衡量指标
任何性能优化,都必须以指标为前提。没有指标的优化,本质上是玄学。
常见且核心的性能指标包括:
1️⃣ 吞吐量(Throughput)
单位时间内系统能够处理的请求数量,重点关注并行能力,典型应用场景包括批处理系统、高并发服务。
2️⃣ 响应时间(Latency)
单个请求从发起到完成所需的时间,通常用于串行链路优化,例如接口耗时、页面加载时间。
3️⃣ 并发量(Concurrency)
系统在同一时间能够承载的请求数量,反映系统的整体负载能力和稳定性。
4️⃣ 秒开率
在移动互联网场景下尤为重要,"秒开"本身就是一种极佳的用户体验。
5️⃣ 正确性(Correctness)
性能评估时常被忽略,但却极其重要。
在高压场景下,熔断、降级、限流可能导致数据不可用,如果牺牲正确性换来的性能,是没有工程价值的。
👉 性能优化不是追求某一个数字,而是多个指标之间的平衡。
1.2 常见切入点
从工程角度看,性能优化大致可以分为两类:
- 业务优化:通过减少需求复杂度、降低业务冗余、调整产品策略来提升性能
- 技术优化:在既定业务逻辑下,通过技术手段提升系统执行效率
业务优化往往能带来数量级的性能提升,但它依赖产品决策和业务重构;
而技术优化是程序员最常面对、也最可控的优化方式。
本文重点关注技术优化,其常见切入点可以归纳为以下几个方向。
1.2.1 复用优化
复用的本质不是"代码少写",而是避免重复计算、重复 I/O、重复资源创建。
在工程实践中,复用主要体现在 缓冲(Buffer) 和 缓存(Cache) 两个层面。
缓冲的核心目标是:
👉 将零散、频繁的操作,合并为顺序、批量的操作
典型场景包括:
- 文件读写
- 网络 I/O
- 日志落盘
- 数据批量入库
示例:使用缓冲流提升文件写入性能
java
// 不使用缓冲
try (FileOutputStream fos = new FileOutputStream("data.txt")) {
for (int i = 0; i < 1_000_000; i++) {
fos.write(("line-" + i + "\n").getBytes());
}
}
// 使用缓冲
try (BufferedOutputStream bos =
new BufferedOutputStream(new FileOutputStream("data.txt"))) {
for (int i = 0; i < 1_000_000; i++) {
bos.write(("line-" + i + "\n").getBytes());
}
}差异本质:
- 前者:大量小 I/O,频繁系统调用
- 后者:内存中先缓冲,批量写入磁盘
在 I/O 密集型场景下,性能差距非常明显。
缓存的核心目标是:
👉 用空间换时间,减少重复读取和重复计算
缓存主要针对 读多写少 、结果稳定 、热点明显 的数据。
常见层级包括:
- JVM 本地缓存(如 Guava Cache)
- 分布式缓存(Redis)
- 数据库查询结果缓存
示例:避免重复计算的本地缓存
java
private final Map<String, Result> cache = new ConcurrentHashMap<>();
public Result query(String key) {
return cache.computeIfAbsent(key, k -> {
// 假设这是一个非常耗时的计算或远程调用
return expensiveQuery(k);
});
}⚠️ 注意:
缓存带来的不是"免费性能",而是一致性、过期策略、内存占用的权衡。
1.2.2 计算优化
很多系统"慢",并不是 CPU 不够,而是 CPU 没被用好。
并行化:榨干多核能力
如果多个任务之间 不存在数据依赖,就应该并行执行。
串行写法(低效):
java
Result r1 = task1();
Result r2 = task2();
Result r3 = task3();并行写法(高效):
java
ExecutorService pool = Executors.newFixedThreadPool(3);
Future<Result> f1 = pool.submit(this::task1);
Future<Result> f2 = pool.submit(this::task2);
Future<Result> f3 = pool.submit(this::task3);
Result r1 = f1.get();
Result r2 = f2.get();
Result r3 = f3.get();⚠️ 并行不是银弹:
- 线程切换有成本
- 锁竞争可能放大问题
- 受限于 CPU / I/O 瓶颈
异步化:释放主流程
异步的目标不是"更快",而是 让关键路径更短。
典型场景:
- 日志上报
- 消息通知
- 非核心统计
java
CompletableFuture.runAsync(() -> {
sendLog();
});只要业务允许"最终一致",异步化往往是性价比极高的优化手段。
1.2.3 结果集优化
很多接口慢,不是逻辑复杂,而是数据太多、格式太重。
序列化格式对比
- XML:冗余标签多、解析慢
- JSON:结构紧凑、可读性好
- Protobuf:二进制、小体积、高性能
典型场景:RPC 接口
在高并发 RPC 场景下,
使用 Protobuf 往往可以显著降低:
- 网络带宽消耗
- 序列化 / 反序列化时间
- GC 压力
减少"没必要返回的数据"
java
// 不推荐
SELECT * FROM order;
// 推荐
SELECT id, status, amount FROM order;👉 结果集优化,本质是"只返回真正需要的内容"
1.2.4 资源冲突优化
在高并发系统中,很多慢请求不是"算得慢",而是在等资源。
常见冲突点
- 锁竞争
- 数据库连接池
- 线程池
示例:过度同步导致性能下降
java
public synchronized void update() {
// 实际只有一小段代码需要同步
}优化方式:
- 缩小锁粒度
- 使用并发容器(如
ConcurrentHashMap) - 避免在锁内执行 I/O
1.2.5 算法优化
需要反复问自己三个问题:
- 时间复杂度是否合理?
- 是否在热点路径中创建大量临时对象?
- 是否引入了过深的抽象层?
示例:List 查找优化
java
// O(n)
list.contains(x);
// O(1)
set.contains(x);👉 数据结构的选择,往往比"写得巧"重要得多。
1.2.6 JVM 优化
Java 程序运行在 JVM 之上,任何性能问题最终都会反映到:
- GC 次数
- 停顿时间
- 内存分配速度
- 垃圾回收器选择(G1 / ZGC)
- 堆大小是否合理
- 是否存在对象逃逸和内存泄漏
bash
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200目前在生产环境中,G1 GC 以"可预测的停顿时间"成为主流选择。
1.3 系统资源瓶颈
系统性能遵循木桶效应 :
👉 决定系统上限的,永远不是"平均能力",而是当前最短的那块板。
但在真实系统中,瓶颈往往不是显而易见的指标峰值,而是资源之间相互牵制后形成的"隐性短板" 。
性能分析真正困难的地方在于:
你看到的慢,往往只是结果,而不是原因。
在工程实践中,最常见的系统级瓶颈依然集中在 CPU、内存和 I/O,但它们并不是孤立存在的。
1.3.1 CPU 瓶颈
当系统出现 CPU 瓶颈时,表面现象通常是:
- Load 持续走高
- 请求开始排队
- 接口响应时间明显抖动
但需要特别强调的是:
CPU 高并不等价于 CPU 在"做有效计算"。
在 Java 服务中,CPU 的消耗来源非常复杂:
- 真实的业务计算
- 锁竞争导致的自旋
- 频繁的上下文切换
- GC 线程抢占 CPU
这也是为什么只看 top 里的 CPU 使用率,往往会得出错误结论。
例如,当 top 中 CPU 使用率很高,但业务吞吐并没有提升时,常见原因并不是"算力不足",而是 线程模型失衡或同步策略不当 。
线程数远超 CPU 核数,会导致大量时间浪费在调度和切换上,最终表现为"CPU 很忙,系统却很慢"。
因此,判断 CPU 是否真的是瓶颈,关键不是"用了多少",而是:
CPU 的时间,是否花在了你真正关心的业务逻辑上。
1.3.2 内存瓶颈
相比 CPU,内存瓶颈更具迷惑性。
很多系统在内存不足之前,早已开始变慢,但并不会立刻 OOM,而是表现为:
- GC 次数明显增多
- 接口延迟呈现周期性抖动
- 吞吐量在高峰期突然下降
这类问题的本质往往不是"内存不够",而是 内存使用方式不健康。
在 Java 系统中,内存瓶颈通常源于:
- 对象创建速度远大于回收速度
- 大量短生命周期对象进入老年代
- 缓存、集合无上限增长
更危险的是 Swap 。
一旦操作系统开始将内存页换出到磁盘,Java 程序的性能会呈现断崖式下降:
线程被频繁换出,GC 停顿时间不可预测,系统几乎无法稳定服务。
这也是为什么在生产环境中,宁可提前限流,也不能让 Java 服务发生 Swap。
1.3.3 I/O 瓶颈
I/O 瓶颈往往是最容易被误判的一类问题。
在这类场景下,你可能会看到:
- CPU 使用率很低
- 系统负载却不低
- 请求响应缓慢甚至超时
这类"反直觉"现象的原因在于:
线程并没有在计算,而是在等待 I/O 完成。
在 Java 应用中,I/O 瓶颈经常被以下行为放大:
- 同步日志写入
- 频繁的小数据读写
- 慢 SQL 导致数据库连接长期占用
当 I/O 变慢后,线程会大量阻塞,进而拖垮线程池;
线程池被占满后,新请求只能排队,最终形成"级联放大"的性能问题。
从表面看是接口慢,
从本质上看,却是 I/O 等待被线程模型无限放大。
2. 工具支持
性能优化本质上是一个数据驱动的工程问题 。
没有工具支撑的性能分析,往往只能停留在经验判断和猜测层面。
不同层级的性能问题,需要不同层级的工具:
从 系统资源 → JVM 运行时 → 代码级别行为,逐层下钻,才能真正定位问题。
2.1 nmon
nmon 是一款轻量但信息密度极高的系统级性能监控工具,常用于:
- 压测期间采集系统资源变化
- 线上故障发生后的性能回溯
- 验证"是不是系统资源成为瓶颈"
它可以一站式采集:
- CPU 使用情况(user / system / wait)
- 内存与 Swap 使用
- 磁盘 I/O
- 网络吞吐
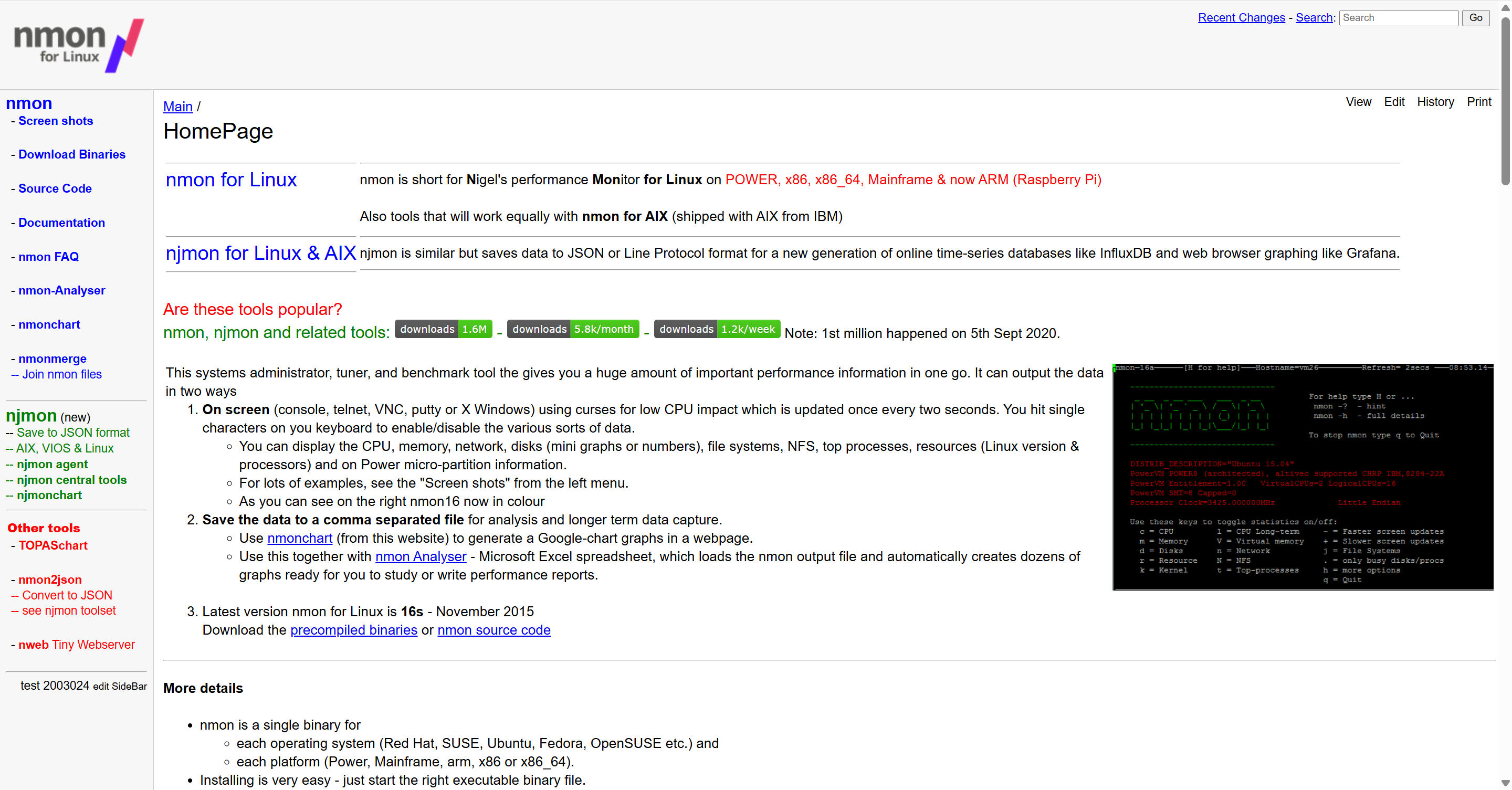
nmon 解决的核心问题是:
当前系统慢,是不是因为底层资源已经被打满?
在压测场景中,nmon 尤其有价值。
例如,当你发现接口响应时间飙升时,通过 nmon 可以快速判断:
- CPU 是否已经跑满?
- 磁盘 I/O 是否成为瓶颈?
- 是否发生了 Swap?
如果系统资源并未达到极限,那么问题大概率不在"机器性能",而在 JVM 或代码层面。
2.2 JVisualVM
JVisualVM 是许多 Java 开发者接触的第一个 JVM 性能分析工具,非常适合:
- 本地调试
- 测试环境问题复现
- 初步理解 JVM 行为
它可以帮助你直观地看到:
- 线程状态分布(RUNNABLE / BLOCKED / WAITING)
- 堆内存使用情况
- GC 次数与停顿
- 方法级别的 CPU 消耗
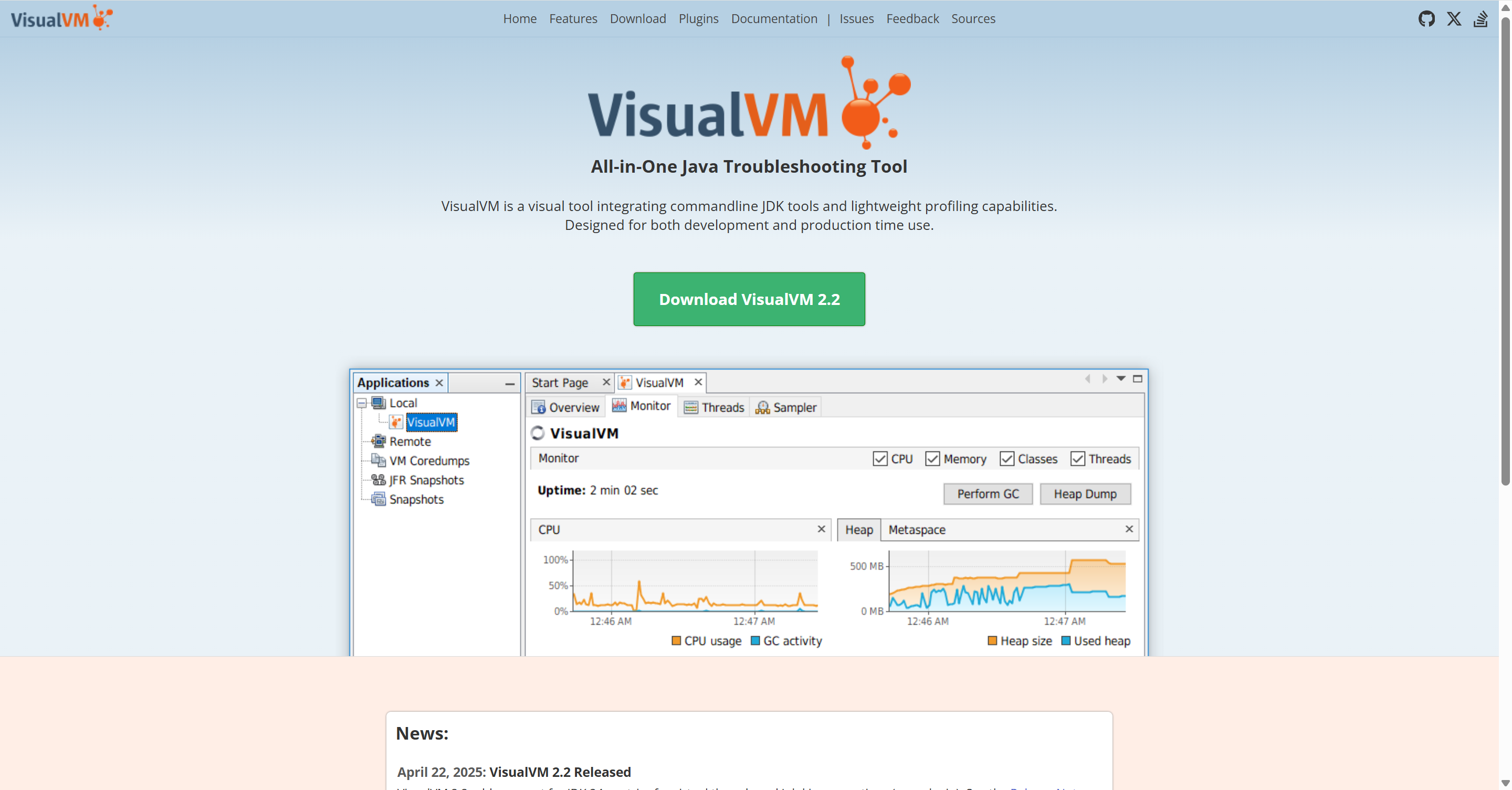
JVisualVM 擅长解决的问题是:
JVM 现在在"忙什么"?
例如:
- 为什么线程数很多,但吞吐上不去?
- 是否存在大量线程阻塞?
- 哪些方法占用了主要 CPU 时间?
需要注意的是,JVisualVM 更适合 开发和测试环境 ,
在生产环境使用时需要谨慎评估其性能开销。
2.3 JMC(Java Mission Control)
如果说 JVisualVM 更偏向"开发期工具",那么 JMC + JFR 则是为生产环境而生的性能分析方案。
JMC 基于 Java Flight Recorder,可以:
- 长时间采集 JVM 运行数据
- 对生产环境影响极小
- 支持事后回放分析
通过 JMC,你可以深入分析:
- 方法调用耗时分布
- 对象分配热点
- 锁竞争情况
- GC 行为和停顿原因
JMC 解决的是一个关键问题:
线上性能问题如何在不影响业务的前提下被完整记录下来?
这使得 JMC 非常适合:
- 排查偶发性慢请求
- 分析高峰期性能抖动
- 做长期性能趋势分析
2.4 Arthas
Arthas 是很多工程师在遇到线上性能问题时的"救命工具"。它最大的特点是:
- 无需重启应用
- 无需提前埋点
- 可直接附着到正在运行的 JVM
Arthas 可以实时查看:
- 方法执行耗时(trace / watch)
- 调用链路
- 线程堆栈
- JVM 运行状态

Arthas 解决的核心问题是:
线上已经慢了,我现在就要知道"慢在哪里"。
例如:
- 某个接口偶发性耗时很长,但无法复现
- 线程池被打满,想知道线程在干什么
- 怀疑某个方法性能异常,但没有日志
通过 Arthas,你可以在不中断服务的情况下,快速定位性能热点。
2.5 wrk
wrk 是一款轻量但性能极强的 HTTP 压测工具,主要用于:
- 模拟高并发请求
- 测试系统吞吐极限
- 验证优化前后的效果差异
wrk 关注的不是"单次请求有多快",而是:
- QPS 能跑到多少
- 延迟分布如何
- 系统在压力下的稳定性
wrk 能帮助你回答的问题是:
系统在高并发下还能不能扛?瓶颈出现在哪里?
在性能优化过程中,wrk 经常用于:
- 验证是否真的"优化有效"
- 观察系统在极限压力下的行为
- 发现潜在的资源瓶颈或退化点
2.6 JMH
在性能优化中,有一个非常常见的误区:
"我觉得这个写法更快。"
JMH 的存在,正是为了消除这种主观判断。JMH 是 Java 官方提供的微基准测试框架,它可以:
- 屏蔽 JIT 编译影响
- 处理逃逸分析、指令重排等问题
- 提供可信的性能对比结果
JMH 解决的问题是:
在 JVM 语义下,这段代码到底快不快?
典型使用场景包括:
- 不同实现方式的性能对比
- 数据结构选型验证
- 底层工具类性能测试
需要强调的是:
JMH 用于"方法级判断",而不是系统级优化。
把 JMH 结果直接等同于线上性能,是一个常见误区。
3. 实践案例
本节通过 3 个真实场景的性能问题案例,完整演示"工具定位-根源分析-优化实施-效果验证"的全流程,将前文的方法论与工具落地到实际开发中。每个案例均聚焦一类核心瓶颈,覆盖 CPU、I/O、内存三大维度,帮助你建立"问题-工具-方案"的对应思维。
3.1 高频接口 CPU 100% 飙升
3.1.1 问题现象
某电商平台的"商品详情页查询"接口,在大促预热期间 QPS 提升至 5000+ 后,出现响应时间从 50ms 飙升至 2s+ 的情况。通过监控面板发现,对应服务的 CPU 使用率持续 100%,但业务吞吐量不升反降,部分请求出现超时。
3.1.2 工具定位过程
-
系统级瓶颈初判:nmon
首先使用 nmon 采集系统资源数据,发现:CPU 使用率中
user占比 95%+,sys占比 3%,idle接近 0;内存、磁盘 I/O、网络均无异常。排除系统资源瓶颈,确定问题在应用层。 -
应用层热点定位:Arthas
由于是线上环境,选择 Arthas 附着到目标进程,执行
thread -n 3查看最忙的 3 个线程,输出结果显示:多个线程处于RUNNABLE状态,堆栈均指向com.ecommerce.goods.service.GoodsDetailService.getDetail()方法中的同步代码块。继续执行
trace com.ecommerce.goods.service.GoodsDetailService getDetail -n 10跟踪方法调用耗时,发现:同步代码块内的逻辑耗时仅 1ms,但整个方法的总耗时高达 1.8s,耗时主要消耗在"等待锁"阶段。 -
锁竞争验证:JMC
为进一步确认锁竞争情况,通过 JMC 启动 JFR 录制 5 分钟(生产环境低开销),回放分析发现:
getDetail()方法的synchronized锁竞争次数达 10 万+,平均等待时间 1.2s,存在严重的锁自旋消耗。
3.1.3 根源分析
查看 GoodsDetailService 源码,发现核心逻辑如下:
java
@Service
public class GoodsDetailService {
// 全局锁对象
private final Object lock = new Object();
public GoodsDetailVO getDetail(Long goodsId) {
// 全方法加锁,防止缓存击穿
synchronized (lock) {
// 1. 查本地缓存
GoodsDetailVO cacheVO = localCache.get(goodsId);
if (cacheVO != null) {
return cacheVO;
}
// 2. 查数据库(耗时 1ms)
GoodsDO goodsDO = goodsMapper.selectById(goodsId);
// 3. 数据转换
GoodsDetailVO vo = convert(goodsDO);
// 4. 放入本地缓存
localCache.put(goodsId, vo, 300, TimeUnit.SECONDS);
return vo;
}
}
}问题根源:使用全局锁防止缓存击穿,但锁粒度过大。所有商品的详情查询都竞争同一把锁,即使是不同商品 ID 的请求,也需要排队等待。大促期间 QPS 激增,导致大量线程在锁外自旋等待,CPU 被完全耗尽。
3.1.4 优化方案
核心思路:缩小锁粒度,按商品 ID 进行分段加锁,让不同商品的查询请求竞争不同的锁,降低锁竞争强度。
优化后的代码:
java
@Service
public class GoodsDetailService {
// 分段锁:使用商品ID的哈希值映射到不同的锁对象
private final int LOCK_COUNT = 16;
private final Object[] locks = new Object[LOCK_COUNT];
// 初始化分段锁
public GoodsDetailService() {
for (int i = 0; i < LOCK_COUNT; i++) {
locks[i] = new Object();
}
}
public GoodsDetailVO getDetail(Long goodsId) {
// 1. 先查缓存,未命中再加锁(双重检查锁)
GoodsDetailVO cacheVO = localCache.get(goodsId);
if (cacheVO != null) {
return cacheVO;
}
// 2. 按商品ID哈希获取分段锁
int lockIndex = (int) (goodsId % LOCK_COUNT);
synchronized (locks[lockIndex]) {
// 3. 再次检查缓存(防止加锁期间其他线程已写入)
cacheVO = localCache.get(goodsId);
if (cacheVO != null) {
return cacheVO;
}
// 4. 查数据库、转换、放入缓存(逻辑不变)
GoodsDO goodsDO = goodsMapper.selectById(goodsId);
GoodsDetailVO vo = convert(goodsDO);
localCache.put(goodsId, vo, 300, TimeUnit.SECONDS);
return vo;
}
}
}补充优化:引入双重检查锁,避免加锁前已被其他线程写入缓存的无效等待,进一步提升并发效率。
3.1.5 效果验证
使用 wrk 进行压测验证(保持 QPS 5000+):
-
优化前:响应时间 P95 2.1s,CPU 100%,吞吐量 3200 QPS(部分超时);
-
优化后:响应时间 P95 80ms,CPU 使用率 45%,吞吐量 5200 QPS(无超时)。
通过 JMC 再次录制分析,锁竞争次数降至 800+,平均等待时间 2ms,锁自旋消耗基本消除。
3.2 批量数据导入接口慢
3.2.1 问题现象
某后台管理系统的"批量导入商品"接口,导入 1 万条商品数据时,耗时长达 150s,远超预期的 10s 阈值。运维反馈该接口执行期间,数据库服务器的磁盘 I/O 使用率持续 100%,但应用服务器 CPU 使用率仅 15%。
3.2.2 工具定位过程
-
系统级瓶颈确认:nmon
在数据库服务器上运行 nmon,发现:磁盘 I/O 的
%util100%,await(I/O 等待时间)30ms+,svctm(服务时间)0.5ms,说明存在大量频繁的小 I/O 请求,导致磁盘 I/O 拥堵。 -
应用层 I/O 行为分析:Arthas
使用 Arthas 跟踪导入接口的核心方法
com.ecommerce.admin.service.GoodsImportService.importBatch(),执行watch com.ecommerce.admin.service.GoodsImportService importBatch "{params, returnObj, costTime}" -n 1,发现:方法总耗时 148s,其中循环调用goodsMapper.insert()1 万次,单次插入耗时 12-15ms,累计耗时 142s,是主要耗时点。 -
数据库执行分析:慢查询日志
查看数据库慢查询日志,发现 1 万条独立的
INSERT INTO goods (...) VALUES (...)语句,每条语句执行时间 10ms+,属于典型的"高频小事务"导致的 I/O 瓶颈。
3.2.3 根源分析
查看 GoodsImportService 源码,核心逻辑如下:
java
@Service
public class GoodsImportService {
@Autowired
private GoodsMapper goodsMapper;
@Transactional
public ImportResult importBatch(List<GoodsDTO> goodsList) {
ImportResult result = new ImportResult();
int successCount = 0;
for (GoodsDTO dto : goodsList) {
try {
// 循环单条插入
goodsMapper.insert(convert(dto));
successCount++;
} catch (Exception e) {
result.addErrorMsg(dto.getGoodsName() + "导入失败:" + e.getMessage());
}
}
result.setSuccessCount(successCount);
return result;
}
}问题根源:采用循环单条插入的方式处理批量数据,每插入一条数据都需要发起一次数据库连接、执行一次 SQL、刷盘一次,1 万条数据产生 1 万次独立的 I/O 操作。磁盘 I/O 无法承受高频小请求,导致整体耗时激增。
3.2.4 优化方案
核心思路:批量合并 I/O,将多条插入语句合并为一条批量插入语句,减少数据库连接次数和磁盘 I/O 次数。
优化步骤:
-
改造 Mapper 接口,支持批量插入;
-
在应用层将数据按批次拆分(避免单条 SQL 过长),每批 1000 条;
-
批量插入并优化事务粒度。
优化后的代码:
java
@Service
public class GoodsImportService {
@Autowired
private GoodsMapper goodsMapper;
// 每批插入数量(根据数据库性能调整)
private static final int BATCH_SIZE = 1000;
@Transactional
public ImportResult importBatch(List<GoodsDTO> goodsList) {
ImportResult result = new ImportResult();
int successCount = 0;
// 按批次拆分数据
List<List<GoodsDTO>> batches = splitIntoBatches(goodsList, BATCH_SIZE);
for (List<GoodsDTO> batch : batches) {
try {
// 批量转换
List<GoodsDO> doList = batch.stream().map(this::convert).collect(Collectors.toList());
// 批量插入(一条SQL插入1000条数据)
goodsMapper.insertBatch(doList);
successCount += batch.size();
} catch (Exception e) {
// 批次失败,记录失败商品名称
batch.forEach(dto -> result.addErrorMsg(dto.getGoodsName() + "导入失败:" + e.getMessage()));
}
}
result.setSuccessCount(successCount);
return result;
}
// 拆分批次工具方法
private <T> List<List<T>> splitIntoBatches(List<T> list, int batchSize) {
List<List<T>> batches = new ArrayList<>();
for (int i = 0; i < list.size(); i += batchSize) {
int end = Math.min(i + batchSize, list.size());
batches.add(list.subList(i, end));
}
return batches;
}
}对应的 Mapper XML 优化(MyBatis):
xml
<insert id="insertBatch" parameterType="java.util.List">
INSERT INTO goods (goods_id, goods_name, price, stock)
VALUES
<foreach collection="list" item="item" separator=",">
(#{item.goodsId}, #{item.goodsName}, #{item.price}, #{item.stock})
</foreach>
</insert>3.2.5 效果验证
导入 1 万条商品数据进行测试:
-
优化前:耗时 150s,数据库磁盘 I/O 100%,1 万次插入 SQL;
-
优化后:耗时 8s,数据库磁盘 I/O 峰值 60%,仅 10 次批量插入 SQL。
通过 nmon 再次监控,磁盘 I/O 的 await 降至 5ms,I/O 拥堵问题彻底解决。
3.3 接口周期性延迟抖动
3.3.1 问题现象
某支付系统的"订单支付回调"接口,正常情况下响应时间稳定在 30ms 左右,但每间隔 2-3 分钟就会出现一次响应时间飙升至 500ms+ 的抖动,抖动期间部分回调请求超时,影响订单状态同步。
3.3.2 工具定位过程
-
系统级资源排查:nmon
监控应用服务器资源,发现抖动期间 CPU 使用率短暂升至 80%(平时 30%),内存使用无明显异常,磁盘 I/O、网络正常。初步怀疑是 GC 导致的停顿。
-
JVM GC 分析:JVisualVM
在测试环境复现问题,使用 JVisualVM 监控 JVM 运行状态,发现:每 2-3 分钟会发生一次 Young GC,GC 停顿时间达 450ms+,与接口延迟抖动的时间完全吻合,初步确认 GC 停顿是导致接口延迟的直接原因。
进一步查看堆内存分布,发现 Young 区的 Eden 空间每次 GC 前都接近满负荷,GC 后内存占用骤降,说明存在大量短生命周期对象快速创建的情况。
3.3.3 根源分析
查看"订单支付回调"接口的核心处理类 com.payment.order.service.PaymentCallbackService 源码,重点分析回调数据处理逻辑:
Plain
@Service
public class PaymentCallbackService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private PaymentLogService paymentLogService;
public CallbackResult handleCallback(PaymentCallbackDTO callbackDTO) {
// 1. 解析回调参数(生成大量临时字符串)
String orderNo = callbackDTO.getOrderNo();
String payAmount = callbackDTO.getPayAmount();
String payTime = callbackDTO.getPayTime();
String payStatus = callbackDTO.getPayStatus();
// 2. 生成详细的支付日志(拼接大量字符串,创建日志对象)
StringBuilder logBuilder = new StringBuilder();
logBuilder.append("订单支付回调处理:").append("\n")
.append("订单号:").append(orderNo).append("\n")
.append("支付金额:").append(payAmount).append("\n")
.append("支付时间:").append(payTime).append("\n")
.append("支付状态:").append(payStatus).append("\n");
// 3. 循环处理回调中的扩展参数(创建大量临时 Map Entry 对象)
Map<String, String> extParams = callbackDTO.getExtParams();
for (Map.Entry<String, String> entry : extParams.entrySet()) {
logBuilder.append("扩展参数-").append(entry.getKey()).append(":").append(entry.getValue()).append("\n");
}
// 4. 记录支付日志(日志对象包含完整的字符串内容)
PaymentLogDO paymentLogDO = new PaymentLogDO();
paymentLogDO.setOrderNo(orderNo);
paymentLogDO.setLogContent(logBuilder.toString());
paymentLogDO.setCreateTime(new Date());
paymentLogService.saveLog(paymentLogDO);
// 5. 更新订单状态
OrderDO orderDO = orderMapper.selectByOrderNo(orderNo);
orderDO.setPayStatus(payStatus);
orderDO.setPayTime(DateUtils.parse(payTime));
orderMapper.updateById(orderDO);
return CallbackResult.success();
}
}结合 JVisualVM 的监控数据和源码分析,问题根源如下:
-
回调接口处理逻辑中,每次请求都会通过
StringBuilder拼接大量字符串(包含订单信息、扩展参数等),生成的日志内容平均长度达 2KB,且扩展参数循环遍历过程中会创建大量临时的Map.Entry对象; -
支付系统的回调 QPS 稳定在 300+,大量短生命周期对象(字符串、Map.Entry、日志对象等)快速填充 Young 区的 Eden 空间,导致 Eden 区频繁溢出,触发 Young GC;
-
Young GC 执行时会暂停所有用户线程(STW),每次停顿时间达 450ms+,这正是接口周期性延迟抖动的直接原因。
3.3.4 优化方案
核心思路:减少短生命周期对象的创建频率,优化内存分配,降低 Young GC 的触发频率和停顿时间。具体优化措施如下:
-
优化日志拼接逻辑,避免大量临时字符串生成 :使用日志框架(如 Logback)的参数化日志输出,替代手动拼接字符串,减少
StringBuilder及临时字符串对象的创建; -
限制日志内容长度,避免冗余信息:支付日志无需记录全部扩展参数,仅保留关键参数(如支付渠道、交易流水号),减少日志对象的内存占用;
-
优化 Young 区内存分配:调整 JVM 参数,增大 Eden 区空间,减少 Eden 区溢出的频率;同时选用 G1 GC 并设置合理的停顿时间目标,优化 GC 性能。
优化后的代码:
Plain
@Service
public class PaymentCallbackService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private PaymentLogService paymentLogService;
// 引入日志框架,使用参数化输出
private static final Logger logger = LoggerFactory.getLogger(PaymentCallbackService.class);
public CallbackResult handleCallback(PaymentCallbackDTO callbackDTO) {
// 1. 解析核心回调参数
String orderNo = callbackDTO.getOrderNo();
String payAmount = callbackDTO.getPayAmount();
String payTime = callbackDTO.getPayTime();
String payStatus = callbackDTO.getPayStatus();
Map<String, String> extParams = callbackDTO.getExtParams();
// 2. 参数化输出日志,避免手动拼接(日志框架内部优化字符串拼接)
logger.info("订单支付回调处理:订单号={}, 支付金额={}, 支付时间={}, 支付状态={}, 核心扩展参数(渠道={}, 流水号={})",
orderNo, payAmount, payTime, payStatus,
extParams.get("payChannel"), extParams.get("tradeNo"));
// 3. 简化支付日志内容,仅保留关键信息
PaymentLogDO paymentLogDO = new PaymentLogDO();
paymentLogDO.setOrderNo(orderNo);
// 日志内容简化,避免冗余
String logContent = String.format("订单号:%s,支付状态:%s,支付金额:%s,支付时间:%s,支付渠道:%s,流水号:%s",
orderNo, payStatus, payAmount, payTime,
extParams.get("payChannel"), extParams.get("tradeNo"));
paymentLogDO.setLogContent(logContent);
paymentLogDO.setCreateTime(new Date());
paymentLogService.saveLog(paymentLogDO);
// 4. 更新订单状态(逻辑不变)
OrderDO orderDO = orderMapper.selectByOrderNo(orderNo);
orderDO.setPayStatus(payStatus);
orderDO.setPayTime(DateUtils.parse(payTime));
orderMapper.updateById(orderDO);
return CallbackResult.success();
}
}补充 JVM 参数优化(替换原有 GC 参数):
Plain
-XX:+UseG1GC # 使用 G1 GC,支持可预测的停顿时间
-XX:MaxGCPauseMillis=100 # 目标最大 GC 停顿时间 100ms
-XX:G1HeapRegionSize=16m # 设置 G1 区域大小为 16m,优化内存回收效率
-XX:SurvivorRatio=8 # Eden 区与 Survivor 区比例 8:1,增大 Eden 区空间
-Xms4g -Xmx4g # 堆内存固定为 4g,避免内存波动3.3.5 效果验证
优化后,通过 JVisualVM 监控 JVM 运行状态,并使用 wrk 模拟 300+ QPS 的回调请求进行压测验证:
-
GC 频率优化:Young GC 触发间隔从 2-3 分钟延长至 15-20 分钟,触发频率显著降低;
-
GC 停顿时间优化:Young GC 平均停顿时间从 450ms+ 降至 80ms 以内,远低于 100ms 的目标阈值;
-
接口性能优化:接口响应时间稳定在 30-50ms 之间,周期性延迟抖动完全消除,无任何超时请求;
-
系统资源优化:应用服务器 CPU 使用率稳定在 30% 左右,无明显波动,内存占用平稳。
通过 nmon 再次监控系统资源,抖动期间的 CPU 峰值消失,整体系统稳定性大幅提升,订单状态同步延迟问题彻底解决。