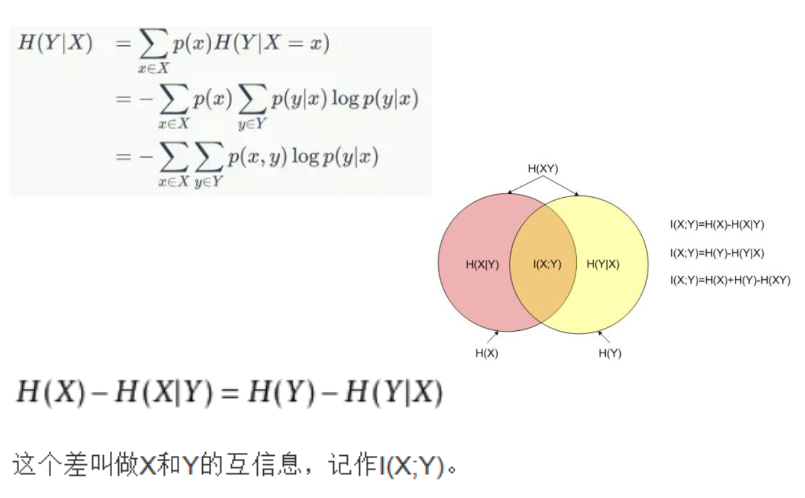
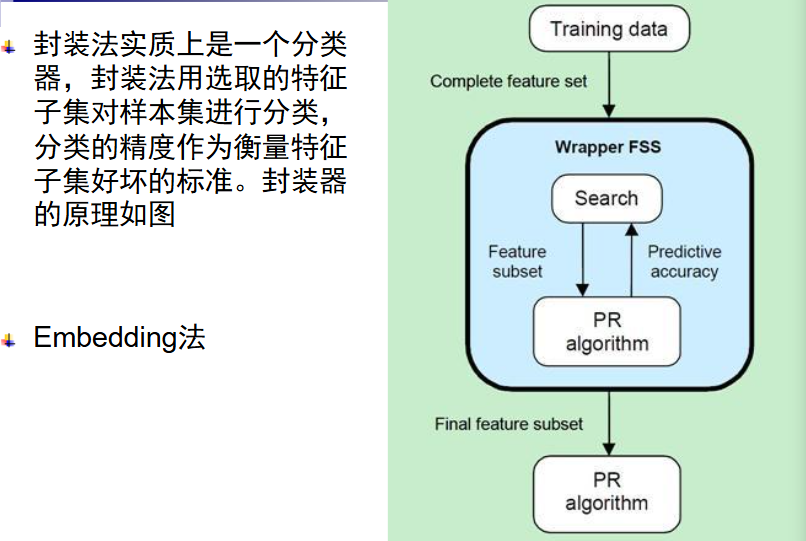
监督的特征选择与提取以训练样本为依据,非特征的特征选择与提取从未知数据触发,需要利用只是或假定。
修斯现象说明,随着特征数量的增加,分类器的性能也会提高,直到达到最佳特征数。继续增加更多的特特征回降低分类器的性能。
在实际应用中,特征数量往往较多,其中可能存在不相关特征,特征之间也可能存在相互依赖,容易导致下面后果:
- 特征个数多,分析特征、训练模型所需的时间就越长
2.特征个数越多,会有维度灾难,模型越复杂,推广能力也会下降
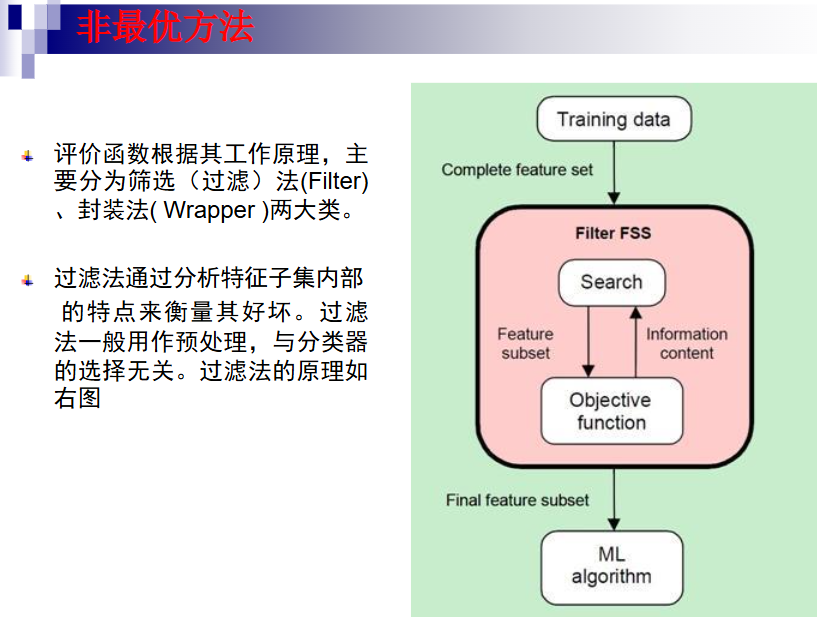
特征选择能剔除不相关和冗余特征,从而达到减少特征个数,提高模型精度,减少运行时间的目的。同时简化模型
一 维数灾难
满足一定统计指标(期望和方差)的模型,需要的样本数量将随着维度的增加,指数增长。其在空间采样,样本划分中的表现较多,同时噪声影响大,因此需要进行特征降维。

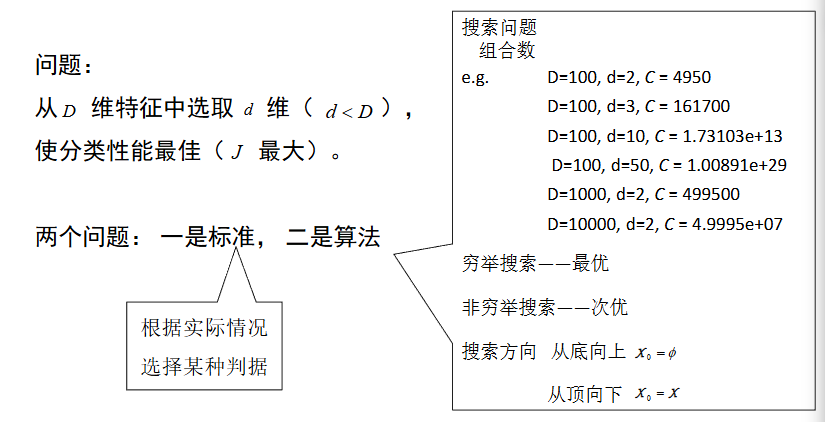
特征选择 首先从特征全集中产生一个特征子集,然后用评价函数对该特征子集进行评价,评价结果与停止准则进行比较,如果评级结果比停止准则好就停止,否则就继续产生下一组特征自己,选出来的特征子集一般还要验证其有效性。
综上所述,特征选择一般包括产生过程、评价函数、停止准则、验证过程四个部分
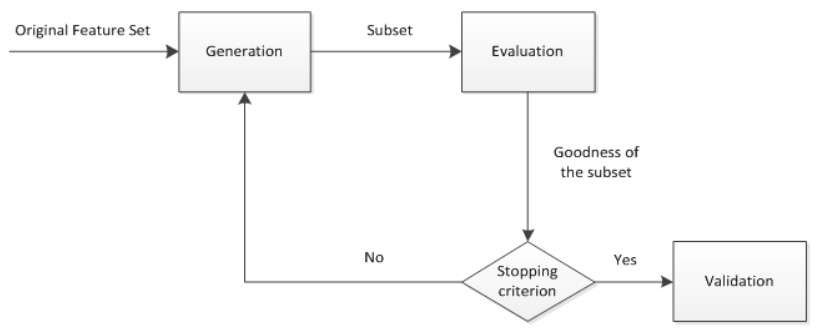
1.产生过程:是搜索特征子集的过程,负责为评价函数提供特征子集
2.评价函数评价一个子集好坏的一个准则
3.停止准则:与评价函数相关,一般是一个阈值
4.验证过程:在验证数据集上验证选出来的特征子集的有效性
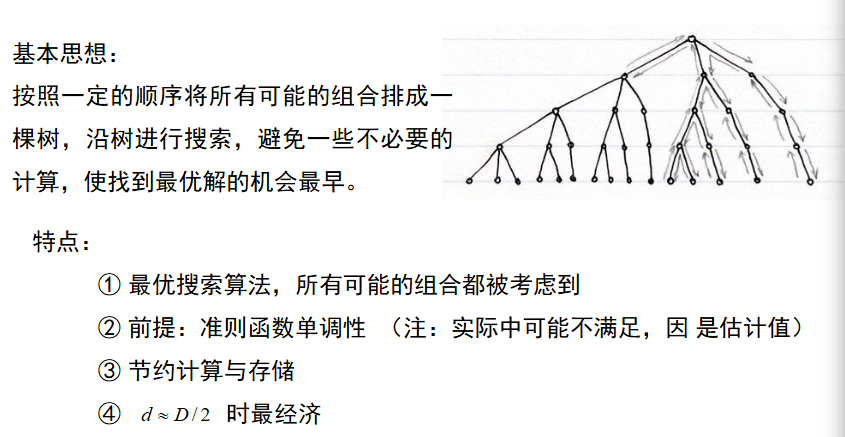
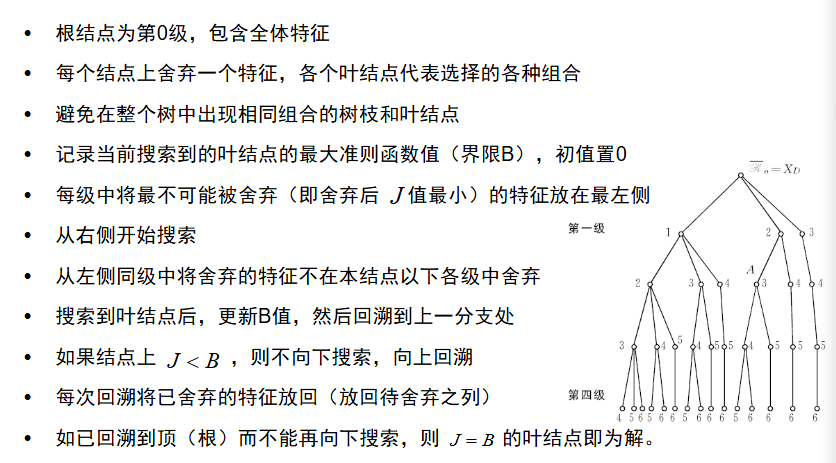
产生过程的搜索算法分为完全搜索,启发式搜索,随机搜索3大类