- 输入:源本体(Os(O_s(Os)和目标本体(Ot(O_t(Ot),支持两类命名规范(自然语言型Type 1、代码型Type 2)。
- 输出:实体等价映射集合(A={(ei,ej)∣ei∈Os,ej∈Ot}(A = \{(e_i, e_j) | e_i \in O_s, e_j \in O_t\}(A={(ei,ej)∣ei∈Os,ej∈Ot})。
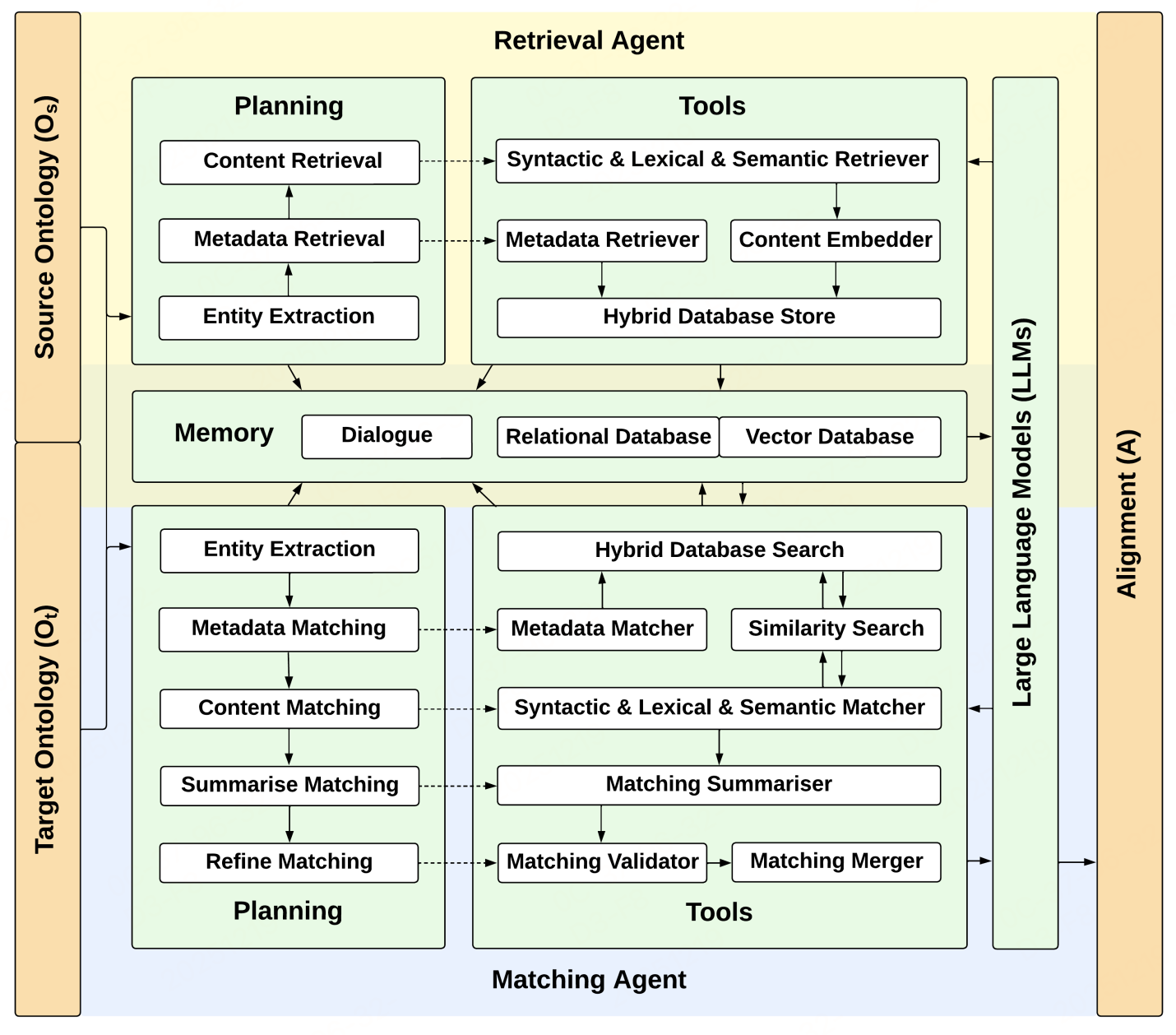
核心逻辑:将"检索→匹配"流程,拆分为两个共享内存的代理(Retrieval Agent + Matching Agent),配合规划模块、OM工具集和混合数据库,实现高效、低幻觉的匹配。
Retrieval Agent
- 功能:提取本体实体的多维度信息,存储至混合数据库。
- 工作流程:Rint⇒Rext⇒RstoR_{int} \Rightarrow R_{ext} \Rightarrow R_{sto}Rint⇒Rext⇒Rsto(内部信息检索→外部信息检索→信息存储)。
- 工具:
- 元数据检索器(Metadata Retriever):提取实体的类别(源/目标本体)和类型(类/属性)。
- 句法+词汇+语义检索器(Syntactic & Lexical & Semantic Retriever):分别提取实体的句法(分词/归一化)、词汇(通用/上下文/注释含义)、语义(三元组关系)信息。
- 混合数据库存储工具(Hybrid Database Store):将元数据存入关系数据库,将句法/词汇/语义信息嵌入后存入向量数据库。
Matching Agent
- 功能:从混合数据库中检索候选实体,通过多维度匹配、验证与融合,输出最优映射。
- 工作流程:Msea⇒Msel⇒Malg⇒MrefM_{sea} \Rightarrow M_{sel} \Rightarrow M_{alg} \Rightarrow M_{ref}Msea⇒Msel⇒Malg⇒Mref(数据库搜索→候选筛选→匹配计算→结果优化)。
- 工具:
- 混合数据库搜索(Hybrid Database Search):作为数据库接口,为后续匹配工具提供数据访问支持。
- 元数据匹配器(Metadata Matcher):基于实体类型(类/属性)筛选候选,确保匹配类型一致性。
- 句法+词汇+语义匹配器(Syntactic & Lexical & Semantic Matcher):通过余弦相似度计算,检索向量数据库中相似的实体信息。
- 匹配汇总器(Matching Summariser):用RRF( reciprocal rank fusion)算法融合三类匹配结果,生成候选排序。
- 匹配验证器(Matching Validator):通过二元问题("实体A与实体B是否等价?")校验候选,减轻LLM幻觉。
- 匹配融合器(Matching Merger):合并"源→目标"和"目标→源"双向匹配结果,仅保留双向确认的映射。
共享内存-memory
关系数据库 + 向量数据库的混合存储组成。通过唯一实体ID关联两个数据库,实现"精确筛选+模糊匹配"的协同。
- 关系数据库:存储实体元数据(实体ID、类别、类型),支持精确查询。
- 向量数据库:存储实体的句法/词汇/语义嵌入向量,支持高效相似度搜索。