一、引言
在服务器重启或宕机时,内存中的数据会瞬间消失。Redis作为一款高性能的内存数据库,Redis通过持久化机制保证数据安全不丢失的。
Redis提供了两种主流的持久化方案:
- RDB:定期保存Redis内存数据
- AOF:记录每次增删查改的操作
本文将深入探讨RDB持久化的原理、配置、优缺点以及应用场景,下文将详细讲解AOF持久化
二、RDB持久化:数据快照
1. 工作原理
RDB通过创建某个时间点的数据快照来实现持久化。它就像给数据库拍了一张照片,将当前内存中的所有数据保存到磁盘上的一个二进制文件中。
核心机制:
内存数据(时刻T) → 生成快照 → 保存为dump.rdb文件
2. 触发方式
RDB提供了三种触发保存快照的方式:
方式一:配置文件自动触发(最常用)
redis.conf的配置文件在etc/redis/下
# redis.conf 配置示例
save 900 1 # 900秒内至少有1个key被修改,则触发保存
save 300 10 # 300秒内至少有10个key被修改,则触发保存
save 60 10000 # 60秒内至少有10000个key被修改,则触发保存
# 其他相关配置
dbfilename dump.rdb # RDB文件名
dir ./ # 保存目录
rdbcompression yes # 是否压缩(LZF算法)
rdbchecksum yes # 是否进行CRC64校验
stop-writes-on-bgsave-error yes # bgsave出错时停止写入方式二:手动执行SAVE命令(不推荐)
重要警告:SAVE命令会阻塞所有客户端请求!
SAVE命令会让当前Redis服务器进入备份操作,期间所有客户端的请求全部阻塞。慎重使用SAVE命令!
可能导致的严重后果:
- 应用程序无法从Redis获取数据
- 大量请求转向MySQL数据库
- MySQL服务器压力激增,可能导致宕机
- 整个系统服务不可用
- 年终奖可能就泡汤了!

方式三:手动执行BGSAVE命令(推荐)
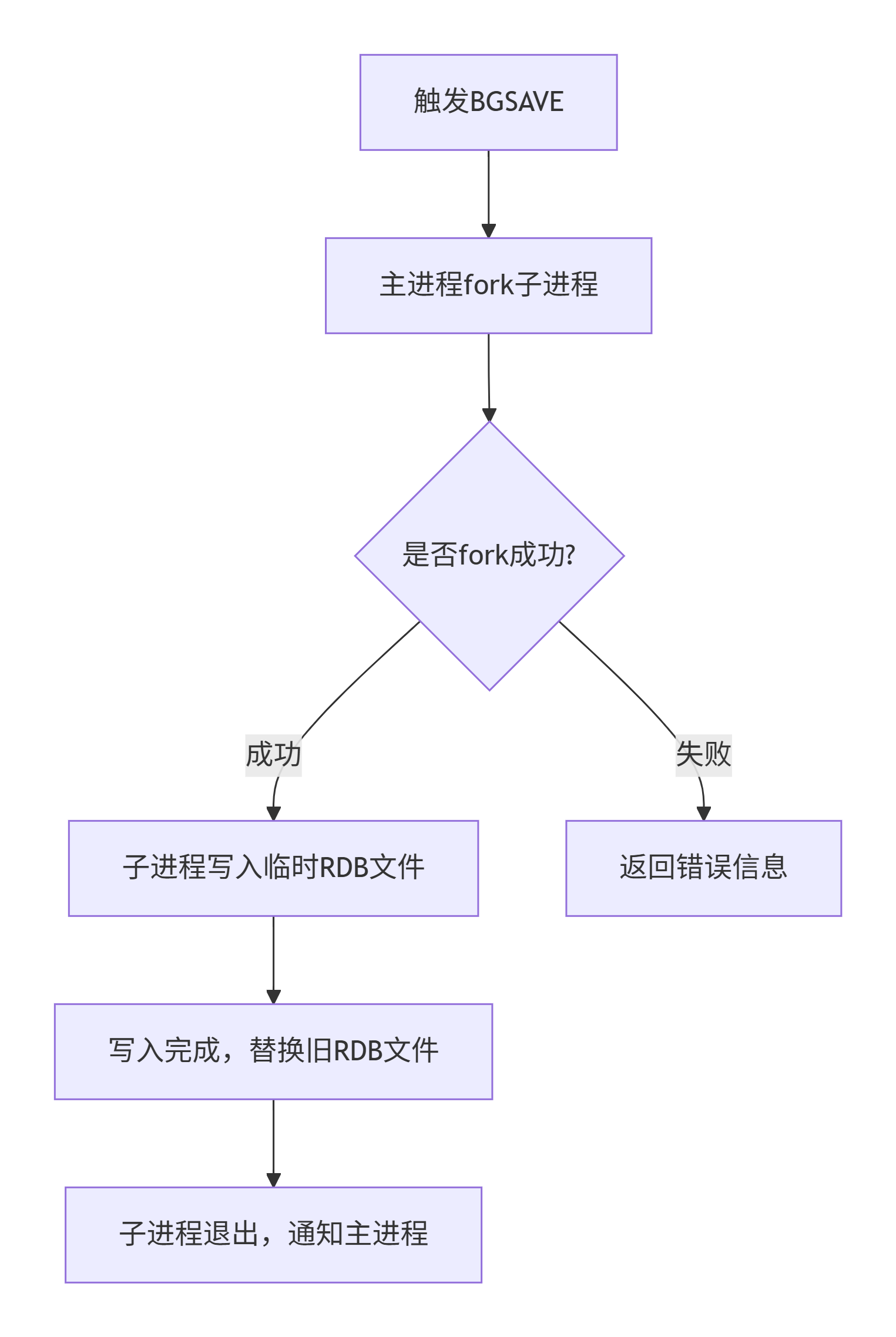
- 接收命令 :Redis主进程接收到 bgsave命令。
- 检查前置条件 :主进程先检查是否已有正在运行的bgsave 子进程,若有则直接返回失败(避免重复写 RDB 文件);若没有则继续。
- 创建子进程 :主进程调用 fork() 系统调用创建一个子进程,此时会发生写时拷贝。
- 主进程恢复服务 :fork 完成后,主进程返回Background saving started, 继续处理客户端请求,无阻塞。
- 子进程写 RDB 文件:子进程遍历 fork 时刻的内存数据,将其序列化后写入临时 RDB 文件
- 替换旧 RDB 文件:子进程写完临时文件后,用临时文件替换掉旧的 RDB 文件。
- 通知主进程完成 :子进程退出,并通过信号告知主进程持久化完成;主进程更新持久化状态(如记录日志等)。

3. RDB执行流程
4. 优缺点分析
优点:
- 性能高:恢复大数据集时速度比AOF快
- 文件紧凑:二进制格式,适合备份和灾难恢复
- 最大化Redis性能:父进程无需磁盘I/O操作
缺点:
- 可能丢失数据:两次快照之间的数据无法恢复
- fork可能阻塞:数据量过大时,fork子进程可能耗时较长
- 版本兼容性:不同版本的RDB文件格式可能不兼容
三、应用场景
适合使用RDB的场景:
- 数据备份:定期全量备份,便于灾难恢复
- 快速重启恢复:大数据集需要快速恢复服务
- 主从复制:初始化从节点时使用RDB文件
- 允许数据丢失:缓存场景,数据可以从源头重建
四、总结
RDB持久化是Redis提供的一种简单高效的数据持久化方案。它通过快照机制在特定时间点保存完整的数据集到磁盘,具有恢复速度快、文件紧凑、对性能影响小等优点。
关键要点:
- 三种触发方式:自动配置、SAVE(阻塞)、BGSAVE(非阻塞)
- 核心机制:fork子进程 + 写时复制
- 适用场景:允许少量数据丢失,追求快速恢复
- 注意事项:大数据集时fork可能阻塞,写操作多时可能有内存压力
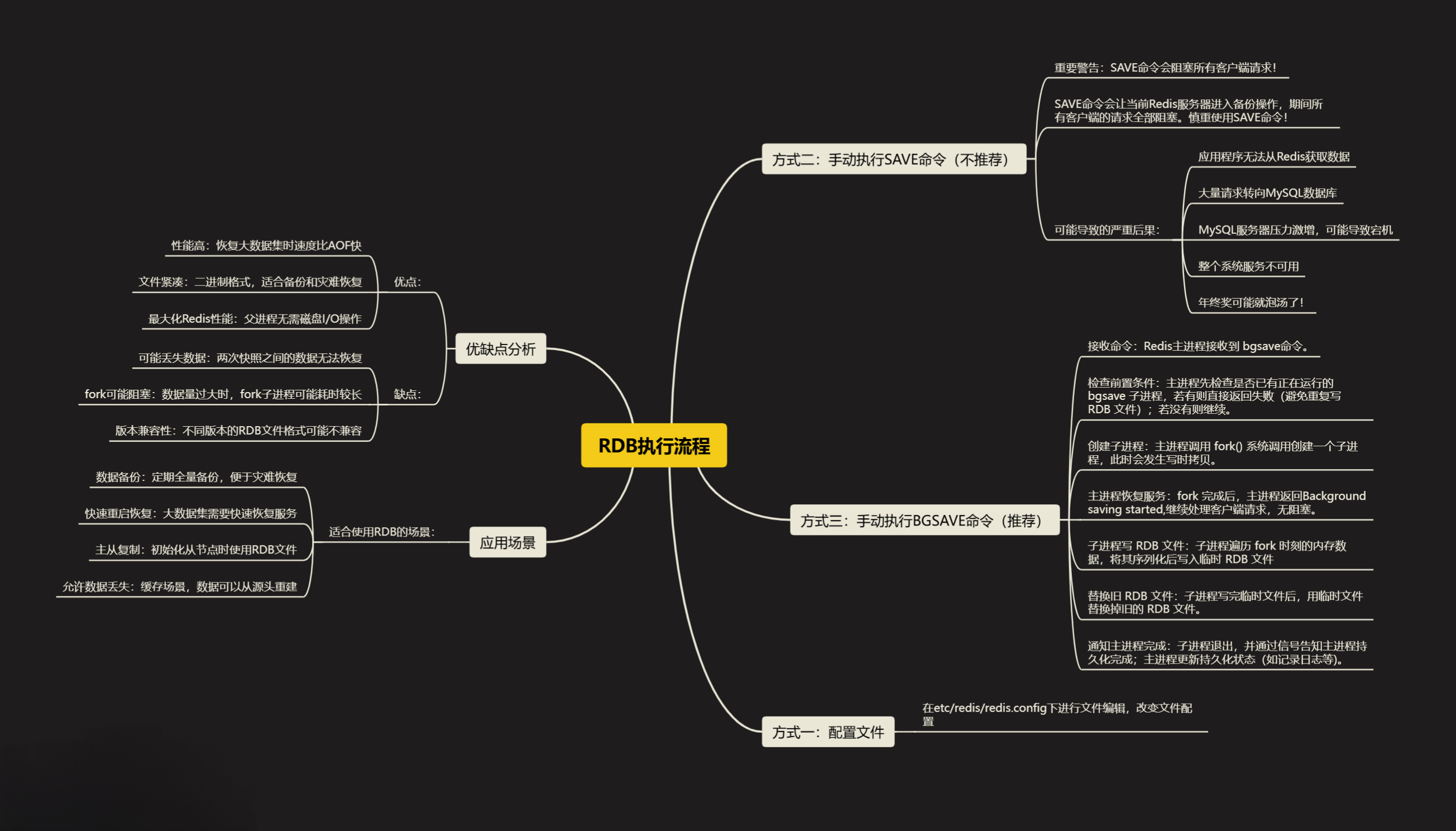
下面是我的思维导图,仅供参考:
结语:
以上就是我分享的C++四大类型转换关键字的全部内容了,希望对大家有些帮助,也希望与一样喜欢编程的朋友们共进步
谢谢观看
如果觉得还阔以的话,三连一下,以后会持续更新的,我会加油的
祝大家早安午安晚安