📚 项目推荐:notes-on-llms
我在系统整理大语言模型(LLM)相关知识的过程中,长期维护了一个公开文档仓库 notes-on-llms。
这个项目不是零散的论文笔记或 Prompt 技巧合集,而是从 模型原理 → 训练范式 → 推理优化 → Agent 架构 → 安全与对齐 → 多模态,系统性拆解 LLM 技术栈,构建一份 结构化的认知地图。
如果你已经接触过 LLM,希望从"会用模型"进阶到"理解模型系统",这个仓库会更有参考价值。
🔗 项目地址:
https://likebeans.github.io/notes-on-llms/
⭐ 欢迎 Star / Follow,后续会持续更新。
摘要本报告旨在为人工智能领域的研究人员与高级工程师提供一份关于大语言模型(LLM)技术栈的详尽综述。报告跨越了从底层数学原理到大规模分布式系统工程的完整技术图谱,深入剖析了 Transformer 架构的现代变体(如 RoPE、ALiBi、GQA)、万亿级参数模型的训练基础设施(Megatron-LM、DeepSpeed、FlashAttention)、高效微调范式(PEFT、LoRA)、人类价值观对齐算法(RLHF、DPO)以及生产级推理优化技术(PagedAttention、Speculative Decoding)。
1. 架构演进:Transformer 的现代化重构
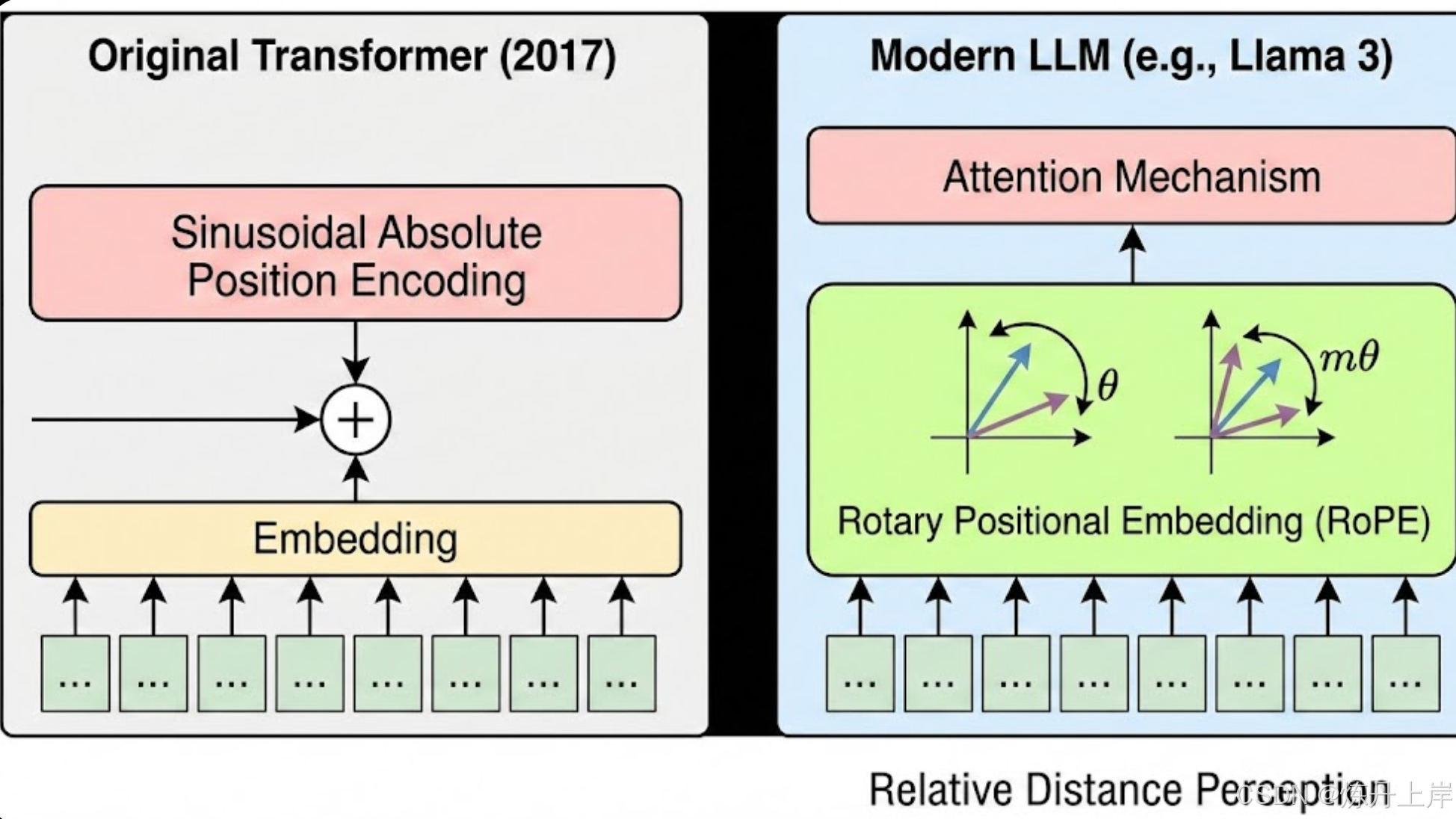
尽管 Google 在 2017 年提出的 Transformer 架构奠定了基础,但现代主流 LLM(如 Llama 3、PaLM、Gemini)运行的是一套经过深度改良的"现代 Transformer"架构,主要解决了外推性差、训练不稳定和显存效率低等问题。
1.1 位置编码的革命:从绝对位置到相对位置
早期的正弦波绝对位置编码在处理超过训练长度的序列时,外推性(Extrapolation)表现极差。
1.1.1 旋转位置编码 (Rotary Positional Embedding, RoPE)
目前被 Llama、PaLM 和 Qwen 等广泛采用。
- 数学原理:RoPE 将 维的 Query 和 Key 向量视为 个二维复数向量的组合。对于位置 的输入向量 ,通过旋转矩阵 进行变换(对应旋转角度 )。
- 相对距离特性:注意力分数 仅依赖于 。机制不再感知绝对位置,只感知 Token 间的相对距离。
- 工程优势 :保持计算复杂度的同时,实现了优异的长度外推能力(无需重新训练即可处理更长序列)。
1.1.2 ALiBi (Attention with Linear Biases)
- 实现机制:放弃 Embedding 层的位置向量,直接在 Attention Softmax 前添加一个与 Query-Key 距离成正比的静态线性偏置项(Penalty)。
- 外推性能:ALiBi 在外推性上优于 RoPE,如 BLOOM 模型能够平滑处理数倍于训练窗口的序列,且提升了训练初期稳定性。
1.2 注意力机制的效率优化
针对全注意力机制 的复杂度瓶颈,业界引入了稀疏化和分组策略。
- Multi-Query Attention (MQA):所有 Query 头共享同一对 Key 和 Value 头。显存占用降低 倍,推理极快,但可能导致模型表达能力下降。
- Grouped-Query Attention (GQA):Llama 2/3 的标配。将 Query 头分成 组,每组共享一对 K、V 头。
- 性能权衡:达到接近 MQA 的速度和效率,同时保持与 MHA 相当的质量。
1.3 归一化与激活函数的重选
- Pre-Norm 结构 :将归一化置于残差主路径之外(
x + Sublayer(LayerNorm(x))),解决了深层网络的梯度消失/爆炸问题,提升训练稳定性。 - RMSNorm:去除了 LayerNorm 中的中心化操作,仅保留均方根缩放。在 GPU 内核层面减少同步开销,显著提升大规模集群的训练效率。
- SwiGLU 激活函数:PaLM 和 Llama 摒弃了 ReLU/GELU,利用门控机制提供更强的非线性表达能力,在同等计算预算下获得更低的困惑度(Perplexity)。
1.4 下一代架构:MoE 与 Mamba
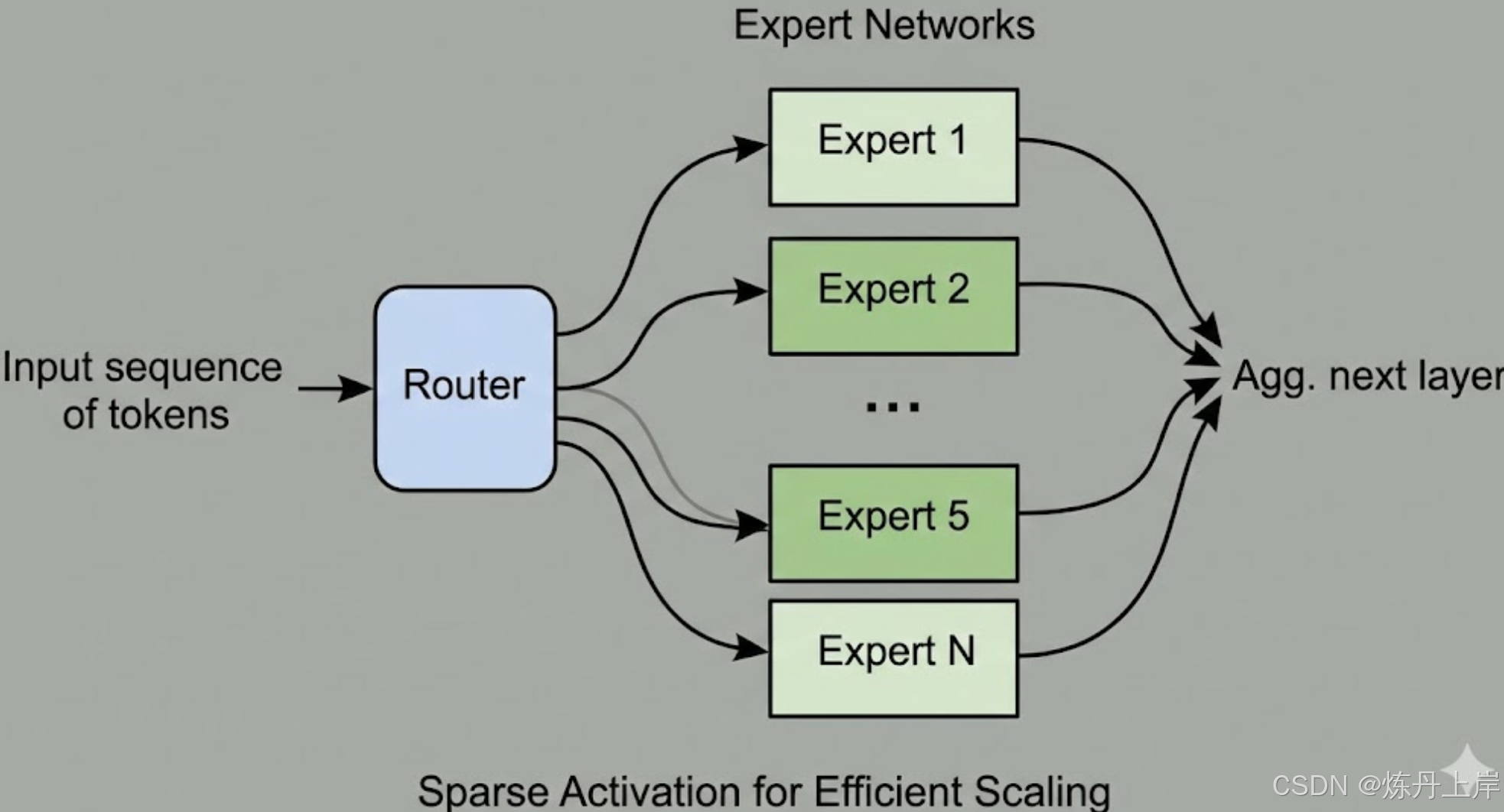
1.4.1 混合专家模型 (Mixture of Experts, MoE)
- 稀疏激活原理:将 FFN 替换为一组专家网络。对于每个 Token,Router 仅激活 Top-k(通常为 1 或 2)个专家。
- 负载均衡:通过辅助损失(Auxiliary Loss)防止"专家坍塌",强制 Router 均匀分配 Token。
- 优势:实现了"训练万亿参数,推理百亿计算"。
1.4.2 状态空间模型 (SSM) - Mamba
- 核心突破:基于选择性状态空间模型,推理时实现 状态更新,达到 线性时间复杂度。
- 性能对比:在长序列任务中,吞吐量和显存占用优于 Transformer。Mamba-2 引入状态空间对偶性(SSD)进一步优化了并行训练。
2. 数据工程:构建万亿 Token 的知识库
2.1 数据处理流水线 (Pipeline)
现代数据工程(如 Dolma, RefinedWeb)的标准流程如下:
| 步骤 | 技术细节 | 目的 |
|---|---|---|
| URL 过滤 | 基于黑名单 | 阻断成人、暴力、垃圾网站等低质内容 |
| 文本提取 | Trafilatura 或自定义解析器 | 去除导航栏、广告、HTML 标签噪声 |
| 语言识别 | FastText 模型 (如 CCNet) | 过滤非目标语言 |
| 文档质量过滤 | 启发式规则 + BERT-based 分类器 | 剔除机器生成文本、乱码及低流利度文本 |
| 敏感信息去除 | 正则表达式匹配 | 移除 Email, IP, 电话号码等 PII 信息 |
| 去重 | MinHash LSH (模糊) + Exact Match | 防止基准测试数据泄漏,提升泛化能力 |
深度解析:去重的重要性
模糊去重(Fuzzy Deduplication)通过 MinHash 算法识别细微差异的重复文档(如转载新闻),对提升模型的 Zero-shot 能力至关重要。
2.2 Tokenization 策略
- Byte-Pair Encoding (BPE):GPT-4 和 Llama 3 采用直接在 UTF-8 字节层面操作的 BPE,无需预分词,支持多语言、代码和 Emoji。
- 词表大小:较大的词表(如 128k)提高编码效率,但增加参数量和计算延迟。
3. 分布式训练基础设施:驯服算力巨兽
训练千亿参数模型依赖 3D/4D 并行策略。
3.1 多维并行策略
- 数据并行 (DP):基础策略,瓶颈在于梯度 All-Reduce。
- 张量并行 (TP):Megatron-LM 方案。利用矩阵乘法结合律切分权重(),通常限于节点内(NVLink)使用。
- 流水线并行 (PP):层间切分。使用 GPipe 或 1F1B 调度,将 Batch 切分为 Micro-batches 以减少设备空闲(Bubble)。
- 序列并行 (SP) / DeepSpeed Ulysses:针对超长上下文(100k+)。在序列维度切分输入,通过 All-to-All 通信计算局部 Attention,极大降低单卡显存峰值。
3.2 显存优化:ZeRO 与 Checkpointing
-
ZeRO (Zero Redundancy Optimizer):消除数据并行中的冗余。
-
Stage 1:切分优化器状态(省 4x 显存)。
-
Stage 2:切分梯度(省 8x 显存)。
-
Stage 3:切分模型参数(支持万亿参数,通信开销大)。
-
激活重算 (Activation Checkpointing):不保存中间激活值,反向传播时重算。以 30% 计算开销换取 5-10 倍显存节省。
3.3 训练稳定性:Loss Spikes
- 成因:AdamW 二阶矩估计在训练后期遇到"坏数据"导致梯度突增。
- 解决方案:
- AdaGC:自适应梯度裁剪。
- Checkpoint 回滚:跳过导致 Spike 的数据。
- QK-Norm:防止 Attention Score 过大。
4. 参数高效微调 (PEFT):低成本适配
4.1 LoRA (Low-Rank Adaptation)
- 原理:冻结 ,注入低秩矩阵 ,使得 。
- 优势 :显存占用极低,且推理时可合并权重实现零推理延迟。
4.2 QLoRA
- 技术细节 :结合 NormalFloat4 (NF4) 量化加载基座模型,使用双重量化和分页优化器。实现在单张 48GB 显卡上微调 65B 模型。
5. 对齐技术:赋予模型价值观
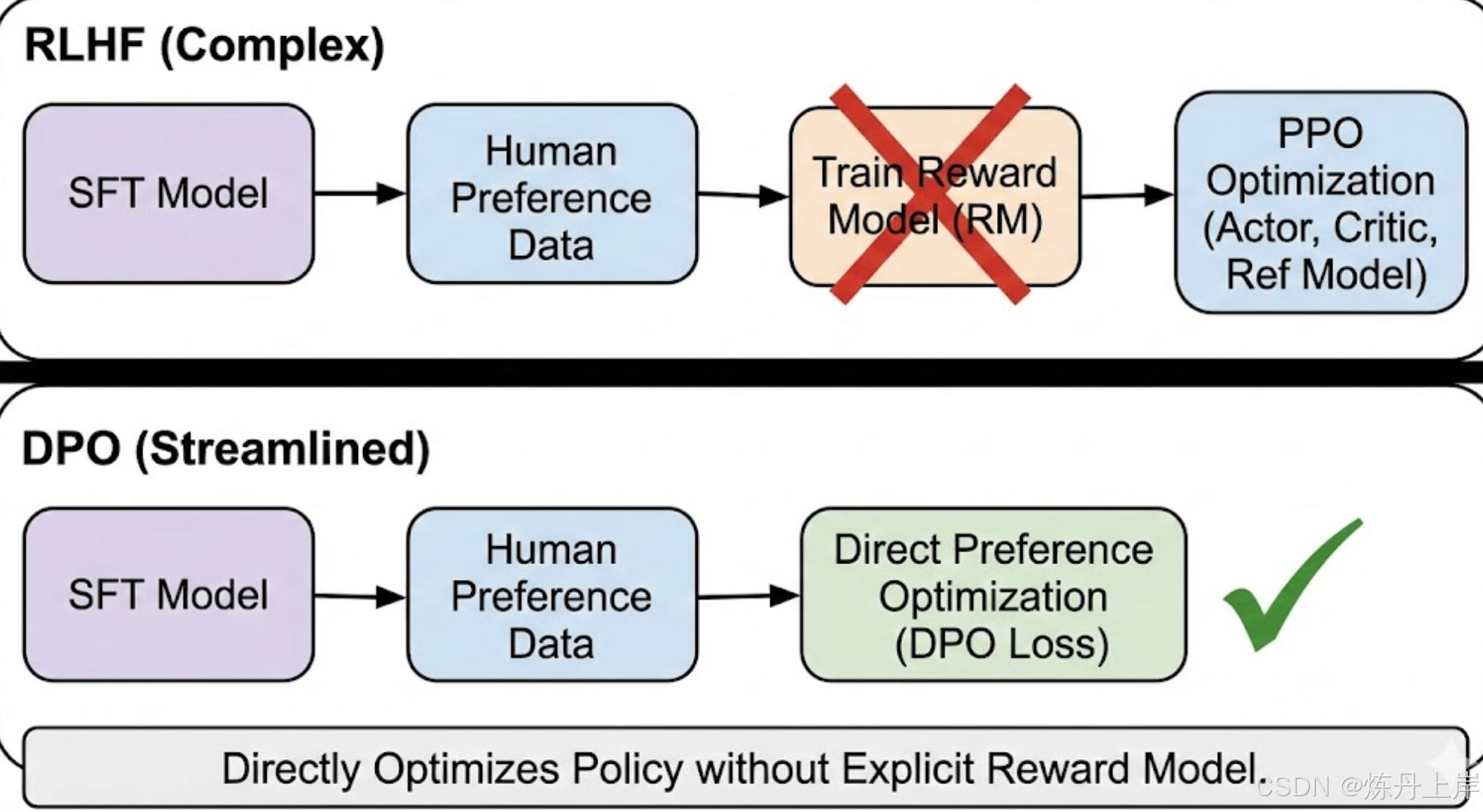
5.1 RLHF (Reinforcement Learning from Human Feedback)
ChatGPT 的核心技术,流程包含:SFT Reward Modeling (RM) PPO。
- 痛点:涉及 4 个模型协同训练,超参数敏感,极不稳定。
5.2 DPO (Direct Preference Optimization)
-
原理:推导出最优策略与奖励函数的解析映射,直接在偏好数据上优化策略,无需显式 RM。
-
损失函数:
-
优势:训练稳定,显存节省(无需 Critic/Reward 模型),效果通常优于 PPO。
6. 推理优化:极致的速度与吞吐
6.1 内核级优化:FlashAttention
- 核心:解决内存带宽瓶颈(Memory Bound)。通过 Tiling 和 Recomputation 将计算保留在 SRAM,避免 矩阵写入 HBM。
- 效果:推理速度提升 2-4 倍,支持超长序列。
6.2 显存管理:PagedAttention 与 vLLM
- PagedAttention:借鉴操作系统虚拟内存分页思想,通过页表将逻辑连续 Token 映射到不连续显存块。
- vLLM:基于此构建,实现显存零浪费,吞吐量比 HuggingFace TGI 高 2-4 倍。
6.3 投机采样 (Speculative Decoding)
- 原理:利用小模型(Draft Model)快速生成候选 Token,大模型并行验证。
- 效果:利用访存密集型特性,实现 2-3 倍延迟降低,且保证结果数学一致性。