大家好, 我是印刻君. 今天我们来看看像 ChatGPT、DeepSeek 这样的大模型, 是如何一步步生成出连贯的句子和答案的.
答案就在一篇 AI 经典论文《Attention is All You Need》中, 这篇论文提出的 Transformer 架构, 奠定了当前大模型的技术基础.
接下来, 我们不纠结复杂数学公式和运算细节, 仅用具体实例串联起整个生成流程, 让你看懂论文, 对 Transformer 有一个感性认知.
此前 AI 主流是循环神经网络 (RNN), 存在两个核心缺陷:
- 看不懂上下文, 随着文本变长, 早期词的信息会不断衰减, 导致模型记不住前文;
- 计算效率低, 无法并行计算, 必须逐词迭代处理.
而 Transformer 架构恰好精准解决了这两个痛点.
零、Transformer 的核心框架: 编码器与解码器
Transformer 架构的核心示意图如下, 整个结构分为左右两部分: 左侧是编码器 (Encoder), 右侧是解码器 (Decoder).
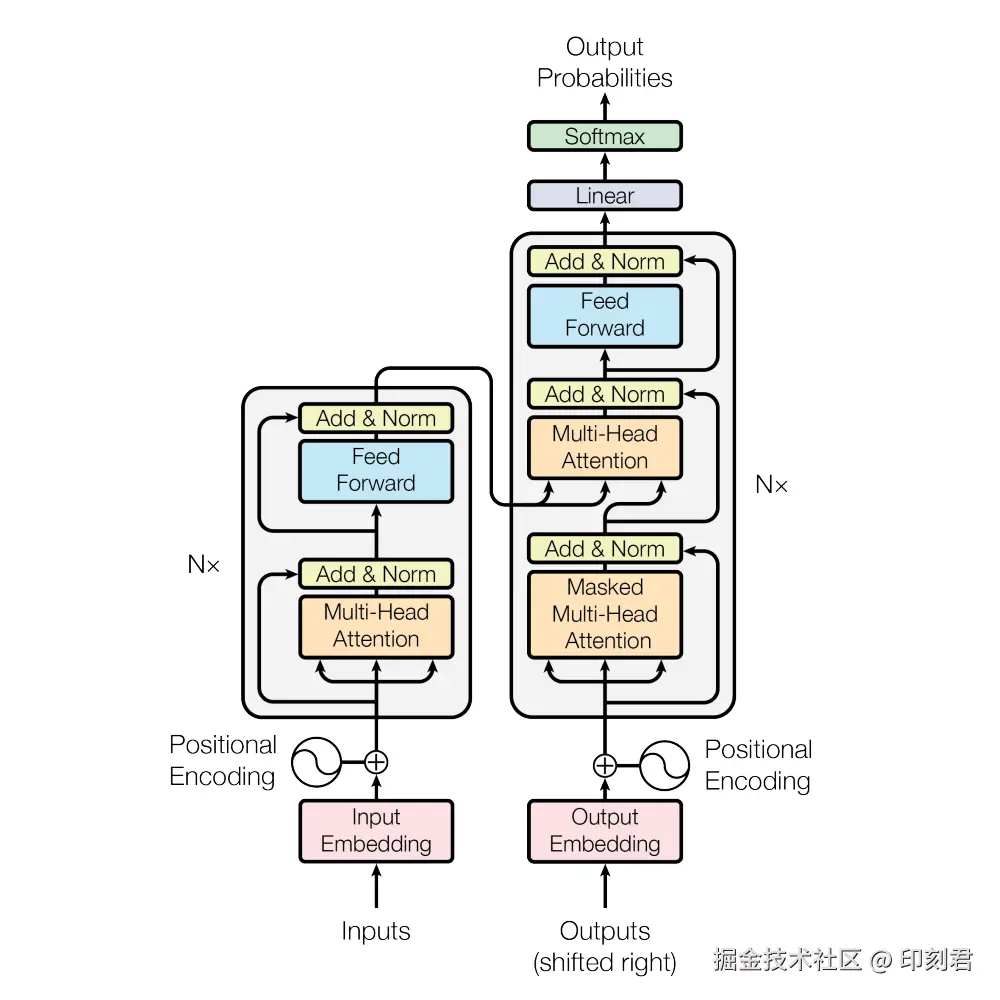
两者的分工很明确:
- 编码器: 核心作用是 "语义理解". 它会完整解析输入文本, 把文字转化为包含上下文信息的语义向量. 让模型明白 "用户在说什么";
- 解码器: 核心作用是 "生成预测". 它基于编码器的理解结果, 逐步生成符合语境的文本. 确保生成的贴合需求.
需要注意的是, 我们日常使用的 ChatGPT、DeepSeek 等生成式大模型, 并没有用到完整的 Transformer 架构, 而是只保留了右侧的解码器. 这种设计被称为 "Decoder Only 架构".
这种设计把 "理解输入" 和 "生成输出" 的任务全部交给了解码器. 当你输入问题时, 解码器通过自我迭代, 既完成了对问题的理解, 又逐步生成回答.
接下来的拆解, 我们将聚焦于 Decoder Only 架构的核心流程. 单独看解码器的结构.
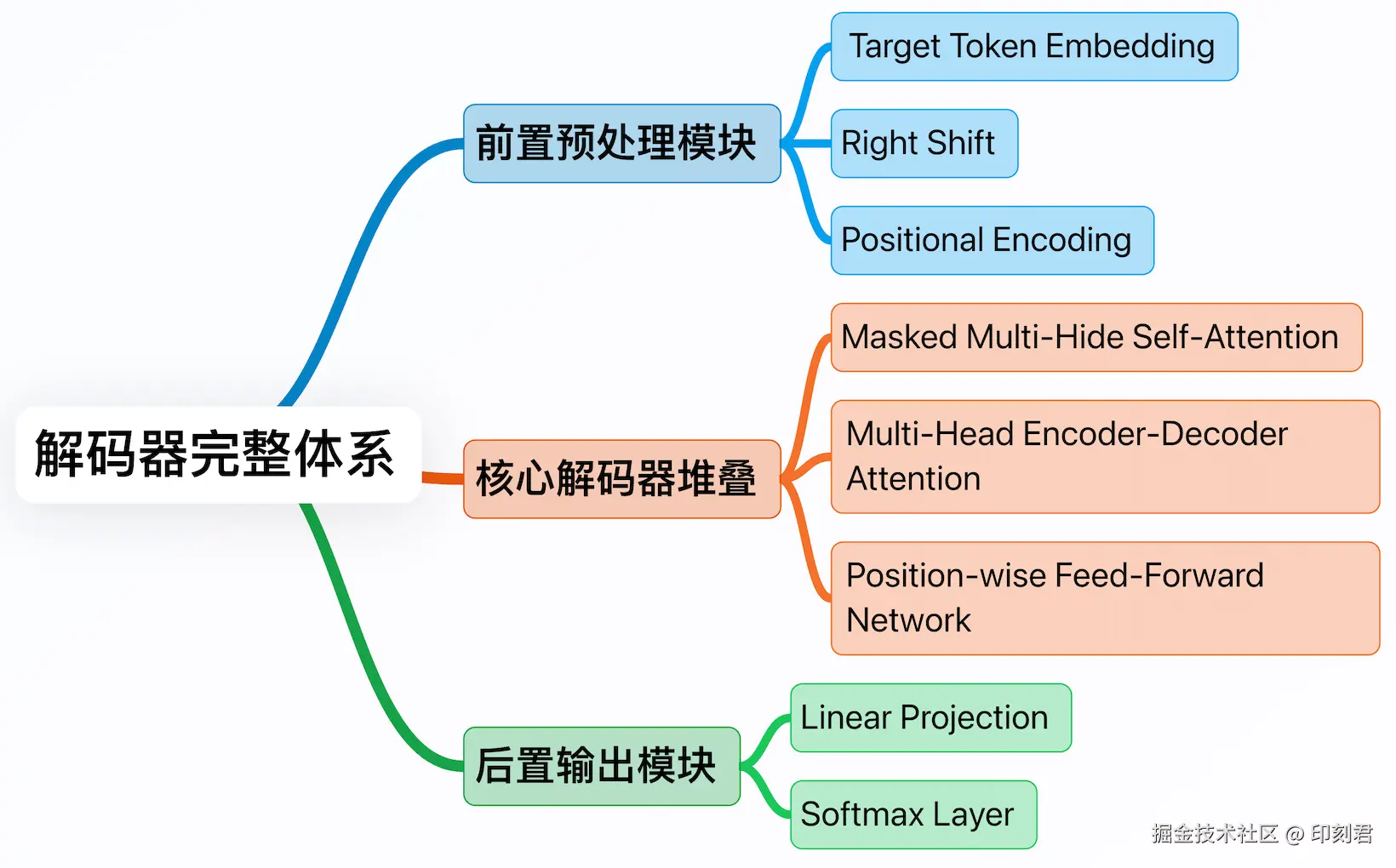
解码器的结构, 就像一条三层的"文本生产流水线", 每个环节各司其职:
- 前置预处理模块: 准备好需要加工的"原料"(Token 序列), 并为原料补充 "语义" 和 "位置信息" 两大关键辅助信息;
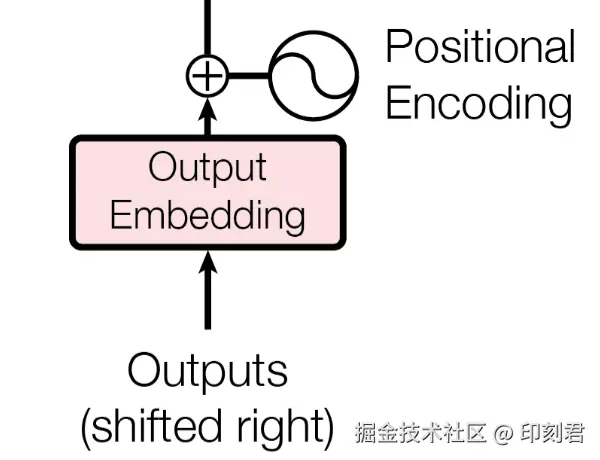
- 核心解码器堆叠: 流水线的核心加工环节, 通过 "注意力机制" 梳理词与词的关联, 把 "原料" 加工成包含完整语义逻辑的"半成品";
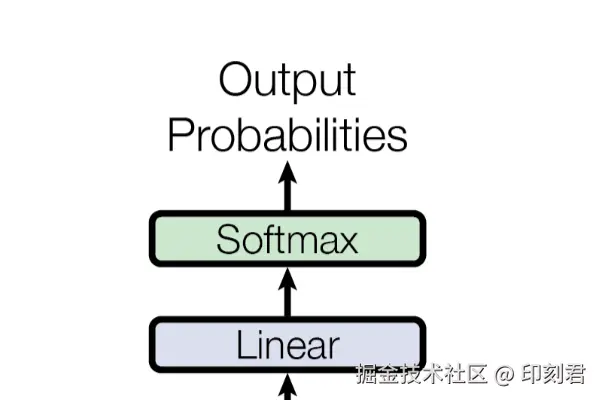
- 后置输出模块: 把 "半成品" 转换成人类能理解的文字, 完成最终生成.
三层模块的逻辑关系可参考下图:
下面我们就沿着这条"流水线", 一步步拆解每个环节的具体工作, 搞懂大模型生成的底层逻辑.
一、前置预处理模块: 给文字赋予语义和位置信息, 做好生成准备
大模型生成答案是"逐字逐句"的(专业叫"自回归").
比如生成 "我爱吃苹果":
- 输出 "我", 再基于我生成 "爱";
- 接着基于 "我爱" 生成 "吃";
- 最后基于 "我爱吃" 生成 "苹果";
- 直到生成表示结束的特殊符号 (如
</s>).
预处理模块的核心任务, 就是把每一步的词准备好, 为后续的语义提供合格的 "原料". 它包含三个关键操作:
1 Token 嵌入 (Token Embedding)
计算机不能直接理解文字符号, 必须把文字转化成数值形式, 这就是嵌入 (Embedding) 的核心目的. 具体来说, 就是把每个子词 (Token) 转换成一个固定的向量, 这个向量就是 "词向量".
2 Right Shift(序列右移)
这是一个简单却重要的技术操作: 把整个 Token 序列向右移动一个位置, 并在最开头补一个特殊的起始符号 (如 <s>), 同时舍弃最后一个 Token.
为什么要做这个操作? 主要是为了配合后续的掩码机制, 模拟逐词生成的真实场景. 从数据结构上为 "防作弊" 做好准备.
3. 添加位置编码(Positional Encoding)
词向量解决了 "每个词是什么意思", 但没有解决 "词在句子中的位置在哪里", 而词序恰恰是语义的关键, 例如 "我爱吃苹果" 和 "苹果词爱我" 的词完全一样, 但语义天差地别.
位置编码的作用, 就是给每个词向量补充 "位置信息", 相当于给每个词贴一张唯一的 "座位号".
从数学逻辑上看, 位置编码是一个和词向量维度相同的向量, 通过 "相加" 的方式与词向量融合. 原始论文中, 位置编码采用正弦和余弦函数生成.
现在的大模型 (如 GPT) 大多采用更高效的 "旋转位置编码 (RoPE)", 但核心目的相同: 让模型同时掌握词的 "语义信息" 和 "位置信息", 为后续的上下文理解打下基础.
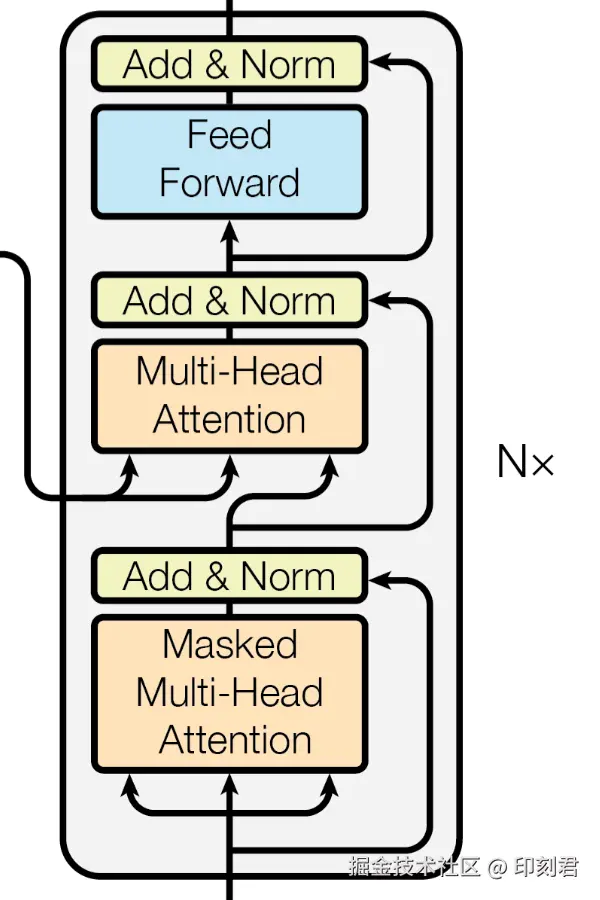
二、核心解码器堆叠: 用注意力机制梳理语义, 深化语境理解
经过预处理后, 每个 Token 都变成 "词向量 + 位置编码" 的融合向量, 这些向量会进入核心加工区. 由多个完全相同的 "解码器层" 堆叠而成. (原始论文用了 6 层, 现代大模型则更多, GPT-3 175B 用了 96 层)
你可以把每一层看作一个 "语义提炼车间".
- 语义进入第一层, 被初步梳理词与词的关联;
- 再进入第二层, 在第一层的基础上深化理解;
- 经过多层迭代后, 模型对当前语境的理解会越来越精准, 生成的语义向量也会越来越贴合 "下一步该说什么" 的需求.
介绍解码器层的核心前, 我们再了解两个保证架构稳定的工具, 它们会在每个核心操作后生效.
- 残差连接 (Residual Connection): 相当于一条信息"备用通道". 它把加工前的原始信息直接传到加工后, 与加工结果相加. 这能防止核心语义被弱化. 因为在深层堆叠网络中, 原始信息在多轮加工后容易被 "稀释";
- 层归一化 (Layer Normalization): 相当于一个"稳定器". 它把每一层的输入输出都进行标准化处理, 确保下一层接收的数据在一个稳定范围内. 这能避免因为数值过大或过小, 导致模型训练过程停滞不前.
做好了这些准备, 我们来看每个解码器层内部的三个核心操作:
1. 掩码多头自注意力(Masked Multi-Head Self-Attention)
这是整个 Transformer 架构的"灵魂", 也是大模型能理解上下文的核心原因. 我们把它拆解成 "自注意力"、"掩码"、"多头" 三个部分, 用实例讲解:
自注意力 (Self-Attention)
先看 "自注意力 (Self-Attention)", 它的核心作用是梳理当前序列中词与词的关联, 比如 "我爱吃苹果". 自注意力会计算每个词与其他词的关联程度 (专业上叫 "注意力分数"), 然后根据分数加权求和, 得到词的上下文向量.
以 "我爱吃苹果" 为例:
- "我" 会重点关联 "爱" (谁在做动作);
- "爱" 会重点关联 "我" 和 "吃" (动作的主体和对象);
- "吃" 会重点关联 "苹果" (动作的对象).
通过这种方式, 每个词都能融合上下文的语境信息, 不在是孤立的存在.
从向量角度理解, 注意力分数的计算, 本质上是向量的内积运算, 两个词向量的内积越大, 说明它们的语义关联度越高, 注意力分数也就越高.
掩码 (Masked)
再看 "掩码 (Masked)": 结合我们前面说的 "自回归" 模式, 模型在生成第 i 个词时, 只能看到前 i - 1 个词, 不能 "偷看" 后面的词.
掩码的作用就是 "屏蔽未来信息", 它会给未来位置的注意力分数, 加上一个极大的负数, 让这些分数在后续的 Softmax 运算中趋近于 0, 相当于让模型 "看不见" 未来的词, 从机制上杜绝了 "作弊"
多头 (Multi-Head)
可以理解为 "多个语义分析专家组同时工作". 每个 "头" 都有独立的参数, 负责从不同维度分析词与词的关联.
比如一个头专门分析 "主谓宾" 关系 (谁对谁做了什么), 一个头专门分析 "修饰关系" (形容词修饰哪个名词), 一个头专门分析 "逻辑关系" (因果、转折等).
所有的头的分析结果会通过矩阵拼接和转换融合, 最终得到更全面、更精准的上下文向量. 这种 "多视角融合" 的设计, 让模型对语义的理解更深刻, 避免单一视角的片面性.
2. 编码器-解码器注意力(Encoder-Decoder Attention)
在完整的 Transformer 中, 这一步作用是 "让解码器关注编码器的理解结果". 比如翻译任务中, 解码器生成英文时, 会通过这一步回看编码器对于中文输入的语义理解, 确保翻译准确
但在我们聚焦的 Decoder Only 模型(如 ChatGPT)中, 由于没有独立的编码器, 这一步的作用发生了转变, 变成了 "解码器自关注": 让模型再深度审视已经生成的全部序列, 强化对整个上下文的理解
换句话说, 这一步相当于让模型回头, 再读一遍自己已经写的内容, 检查是否有语义矛盾、逻辑断裂的地方, 确保接下来要生成的词, 与整个上下文保持连贯, 不跑题.
3. 前馈网络(Position-wise Feed-Forward Network)
经过前两步的注意力机制处理, 词与词之间的关联已经梳理清晰. 相当于解决了 "词与词如何配合" 的问题.
前馈网络的核心任务, 是对每个词的语义向量, 进行独立的精细化加工, 相当于解决了 "每个词在当前语境下具体是什么意思" 的问题.
从结构上看, 前馈网络是一个两层的神经网络, 它会对每个词的向量进行独立处理.
举个例子, 在 "我爱吃苹果" 的语境下, 前馈网络会强化 "苹果" 向量中 "可食用水果" 的特征维度, 同时弱化 "苹果公司"、"苹果肌" 等与当前语境无关的特殊维度;
而在 "我会用苹果手机" 的语境下, 它会反过来强化 "科技产品" 的特征维度, 通过这种精细化的调整, 让每个词的语义在当前语境下更精准.
三、后置输出模块: 把语义向量 "翻译" 成人类能懂的文字
经过多个解码器层的深度加工, 我们得到了一个代表 "下一步最想说什么" 的语义向量. 这个向量是数值形式, 人类无法直接理解. 所以我们需要后置输出模块, 把这个语义向量翻译成具体的文字, 完成最终的生成. 它包含两个关键步骤:
1. 线性投射(Linear Projection)
大模型内部有一个"词表", 包含了它认识的所有 Token (可能有几万个). 线性投射的本质, 是一个简单的线性变换, 是将几百维的语义向量, 转换成一个长度与词表相同的分数向量.
这相当于给词表中的每个词, 打一个 "匹配分", 分数越高, 说明这个词越符合当前语义向量要表达的意思.
举个例子, 如果当前语义向量要表达的是 "苹果" 相关的意思, 那么线性投射后:
- "苹果" 对应的分数可能是9.5;
- "香蕉" 是 8.0;
- "桌子"是 0.5;
- "跑步" 是 0.3.
通过分数清晰区分不同词的匹配程度.
2. Softmax 归一化(Softmax Layer)
线性投射得到的分数是任意实数, 无法直接作为"选择依据".
Softmax 的作用就是把这些分数转换成"概率", 让每个词对应的数值都落在 0 到 1 之间, 且所有词的概率之和为 1. 概率越高, 说明模型认为这个词是"下一步最应该生成的词".
比如前面例子中:"
- "苹果" 的分数 9.5 经过 Softmax 后, 概率可能达到 70%;
- "香蕉" 的分数 8.0 可能变成 28%;
- "桌子"、"跑步" 的低分则会变成 1% 以下.
最终, 模型会选择概率最高的那个词作为下一步生成的词. 这个词会被立即添加到已生成序列的末尾, 整个"预处理→核心加工→输出"的流程会重新执行, 直到模型生成表示结束的特殊符号(如 </s>), 一条完整的回答就诞生了.
总结
《Attention is All You Need》这篇论文的核心贡献, 就是用 "编码器解码器+注意力机制" 的 Trasnfromer 架构, 解决了之前语言模型 "看不懂上下文、计算效率低" 的问题.
现在的生成式大模型(Decoder Only 架构), 本质上是 Transformer 基础上做 "放大" 和 "优化". 比如增加解码器层数(从 6 层增加到几十层)、扩大词表规模、用更多数据训练, 但核心的生成逻辑, 依然是我们前面拆解的 "预处理→核心语义加工→输出转换" 的流水线流程.
现在回顾一下整体流程, 大模型生成内容, 就是:
- 把文字转换成 Token 向量, 补充位置信息;
- 通过多层注意力机制梳理 Token 关联、优化语义特征;
- 把优化后的向量转换成概率, 选择概率最高的词逐一生成, 直到完成整个答案.
我是印刻君, 一位探索 AI 的前端程序员, 关注我, 让 AI 知识有温度, 技术落地有深度.