接上篇《18、Elasticsearch实战:Java API详解高亮、排序与分页》
一、深度分页问题的根源
1.1 传统from+size分页的性能瓶颈
在ElasticSearch中,当我们使用传统的from和size参数进行分页时,系统需要为每个分片计算from+size条结果,然后将所有分片的结果汇总到协调节点进行全局排序。这种机制在深度分页时会产生严重的性能问题。
问题示例: 查询第1000页,每页10条数据
●每个分片需要返回1000*10=10000条数据到协调节点
●协调节点需要对所有分片返回的数据进行合并排序
●内存消耗和CPU开销随分页深度线性增长
1.2 默认限制与性能风险
ElasticSearch默认设置index.max_result_window为10000,这意味着from+size不能超过10000。当超过这个限制时,查询会失败并抛出异常。深度分页不仅影响查询性能,还可能引发内存溢出,影响整个集群的稳定性。
二、search_after技术原理
2.1 核心工作机制
search_after是一种基于游标的分页技术,它使用上一页最后一条记录的排序值作为游标来定位下一页的起始位置。这种方式避免了全局排序和大量数据的合并操作,每次查询只需要获取指定数量的数据。
工作原理:
1.第一次查询时指定排序规则
2.获取第一页数据,并记录最后一条记录的排序值
3.后续查询使用search_after参数,以上一页最后一条记录的排序值作为起点
4.重复步骤2-3实现连续分页
2.2 技术实现要点
●排序字段要求:必须指定至少一个排序字段,且排序字段组合必须唯一
●游标传递:每次查询需要传递上一页最后一条数据的sort值
●无状态查询:不维护搜索上下文,查询性能稳定
三、search_after使用实践
3.1 基础查询示例
首先,让我们看一个使用search_after的基础查询示例:
java
package com.example;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
import java.util.Arrays;
import java.util.Map;
public class SearchAfterExample {
public static void main(String[] args) throws Exception{
RestHighLevelClient client = ElasticsearchClient.getClient();
//第一次查询:获取第一页数据
System.out.println("=== 第一页查询 ===");
Object[] lastSortValues = searchHotels(client, null ,10);
//第二次查询:使用search_after获取第二页
System.out.println("=== 第二页查询 ===");
searchHotels(client, lastSortValues, 10);
ElasticsearchClient.close();
}
private static Object[] searchHotels(RestHighLevelClient client,
Object[] searchAfter, int size) throws Exception{
SearchRequest request = new SearchRequest("hotel");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//构建查询条件:查询上海的品牌酒店
sourceBuilder.query(QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("city","上海"))
.must(QueryBuilders.termQuery("brand","希尔顿")));
//设置排序规则,必须包含唯一字段组合
sourceBuilder.sort("score", SortOrder.DESC);
sourceBuilder.sort("price", SortOrder.ASC);
sourceBuilder.sort("id", SortOrder.ASC);
//设置分页大小
sourceBuilder.size(size);
//如果提供了Search_after参数,则设置游标
if(searchAfter != null){
sourceBuilder.searchAfter(searchAfter);
}
request.source(sourceBuilder);
//执行查询
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
System.out.printf("找到 %d 家符合条件的酒店:\n", hits.getTotalHits().value);
Object[] lastSortValues = null;
for (SearchHit hit : hits){
Map<String,Object> sourceMap = hit.getSourceAsMap();
String hotlname = (String) sourceMap.get("name");
String brand = (String) sourceMap.get("brand");
Integer score = (Integer) sourceMap.get("score");
Integer price = (Integer) sourceMap.get("price");
String city = (String) sourceMap.get("city");
System.out.printf("酒店:%s,品牌:%s,城市:%s,评分:%d,价格:%d元\n",
hotlname,brand,city,score,price);
//记录最后一条记录的排序值
lastSortValues = hit.getSortValues();
}
if(lastSortValues != null){
System.out.println("最后一条记录的排序值:" + Arrays.toString(lastSortValues));
}
return lastSortValues;
}
}查询结果:
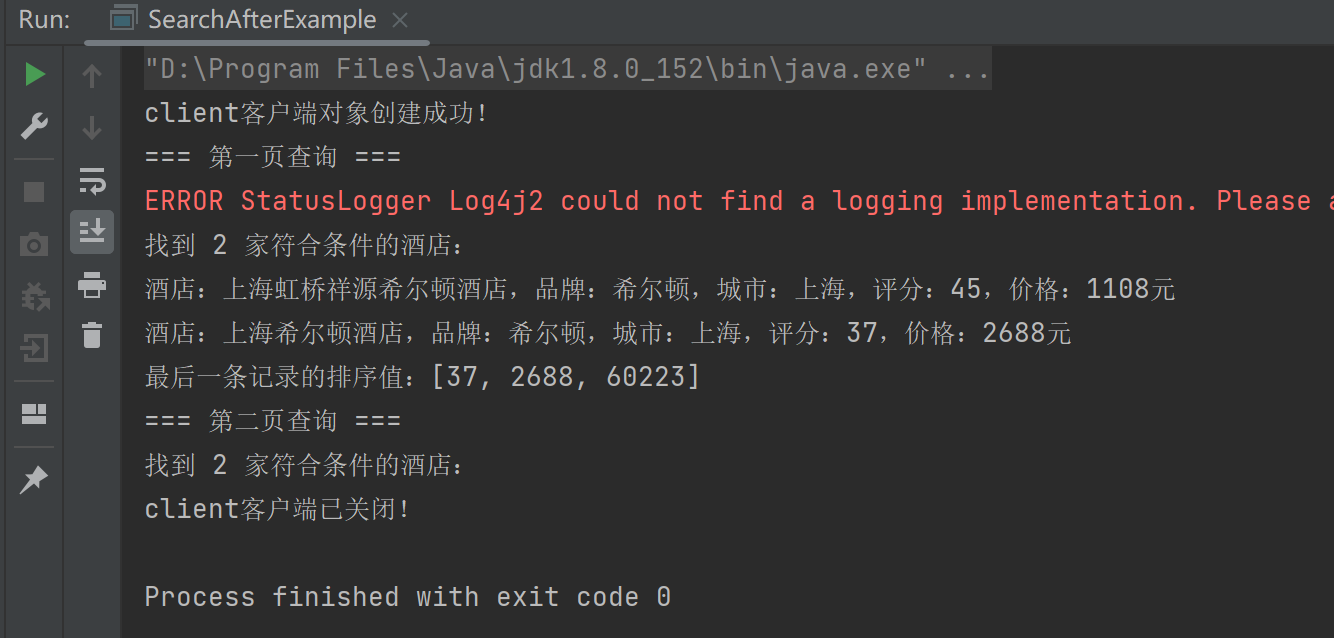
可以看到,第一页寻找完毕后,紧接着不再像之前那样通过sourceBuilder的from去指定来源页数,而是使用searchAfter取上一页最后一条记录值的排序值,来决定下一页size大小的内容。(不过这个查询条件就找到2家符合条件的酒店,所以第二次搜索的时候,去第二页就没数据了)。
3.2 连续分页查询实现
下面是一个完整的连续分页查询示例,演示如何实现多页数据的遍历:
java
package com.example;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
import java.util.Map;
public class ContinuousPaginationExample {
public static void main(String[] args) throws Exception{
RestHighLevelClient client = ElasticsearchClient.getClient();
// 模拟连续分页查询(最多5页)
int pageSize = 5;
int maxPages = 5;
Object[] searchAfter = null;
int currentPage = 1;
do {
System.out.printf("\n=== 第 %d 页数据 ===\n", currentPage);
searchAfter = searchHotelsPage(client, searchAfter, pageSize, currentPage);
if (searchAfter == null) {
System.out.println("没有更多数据了");
break;
}
currentPage++;
} while (currentPage <= maxPages);
ElasticsearchClient.close();
}
private static Object[] searchHotelsPage(RestHighLevelClient client,
Object[] searchAfter,
int pageSize,
int pageNumber) throws Exception{
SearchRequest request = new SearchRequest("hotel");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 查询所有北京的酒店,按价格排序
sourceBuilder.query(QueryBuilders.termQuery("city", "北京"));
// 设置排序规则:价格降序,id升序确保唯一性
sourceBuilder.sort("price", SortOrder.DESC);
sourceBuilder.sort("id", SortOrder.ASC);
sourceBuilder.size(pageSize);
if (searchAfter != null) {
sourceBuilder.searchAfter(searchAfter);
}
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
if (hits.getHits().length == 0) {
return null;
}
System.out.printf("第%d页,共%d条数据:\n", pageNumber, hits.getHits().length);
System.out.println("酒店名称\t品牌\t价格\t评分");
System.out.println("----------------------------------------");
Object[] lastSortValues = null;
for (SearchHit hit : hits) {
Map<String, Object> sourceMap = hit.getSourceAsMap();
String name = (String) sourceMap.get("name");
String brand = (String) sourceMap.get("brand");
Integer price = (Integer) sourceMap.get("price");
Integer score = (Integer) sourceMap.get("score");
System.out.printf("%s\t%s\t%d元\t%d分\n",
truncateString(name, 20),
brand != null ? brand : "未知",
price != null ? price : 0,
score != null ? score : 0);
lastSortValues = hit.getSortValues();
}
return lastSortValues;
}
//酒店名字如果超过20个字就截断
private static Object truncateString(String str, int maxLength) {
if (str == null || str.length() <= maxLength) {
return str != null ? str : "";
}
return str.substring(0, maxLength - 3) + "...";
}
}查询结果:
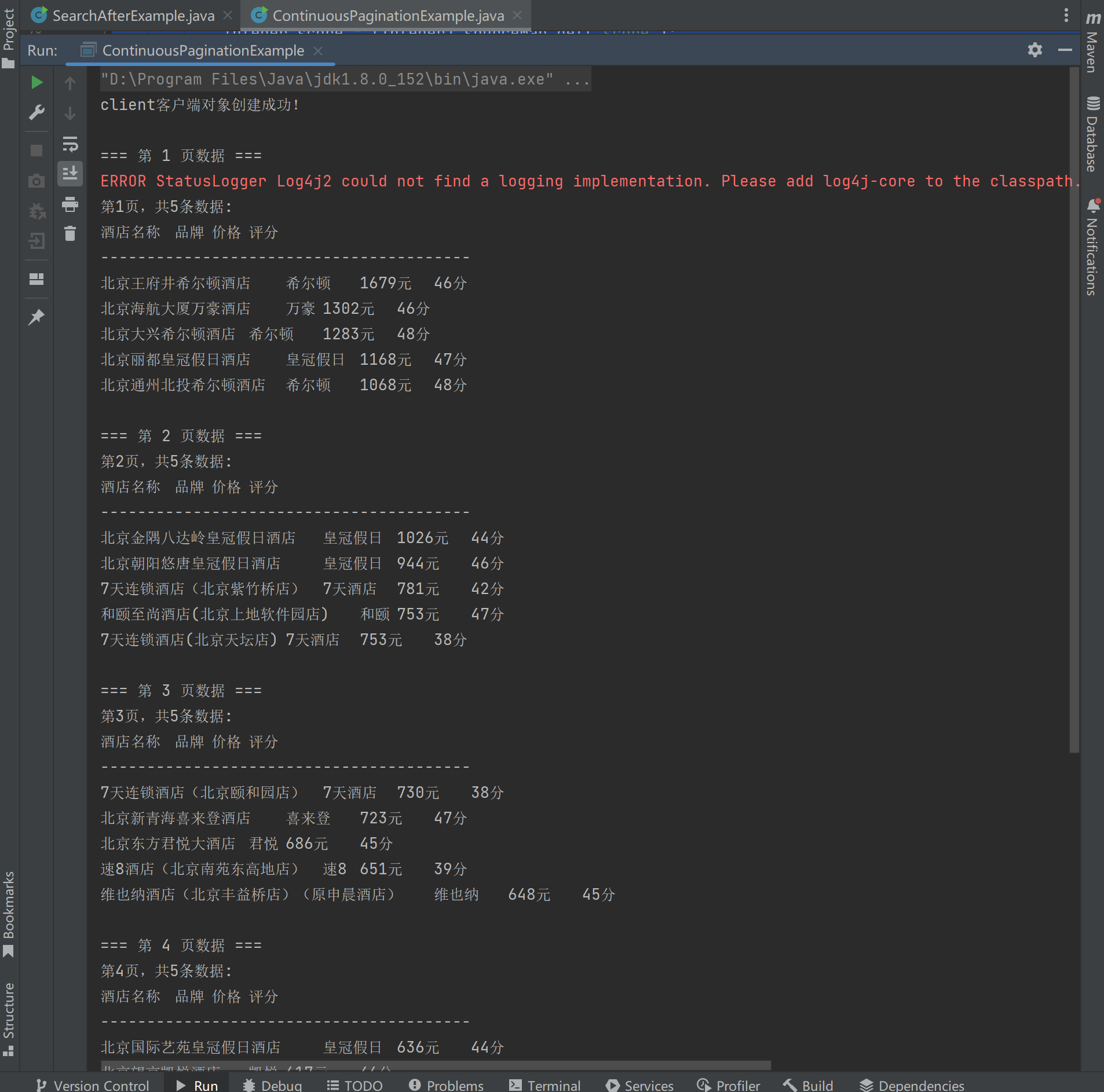
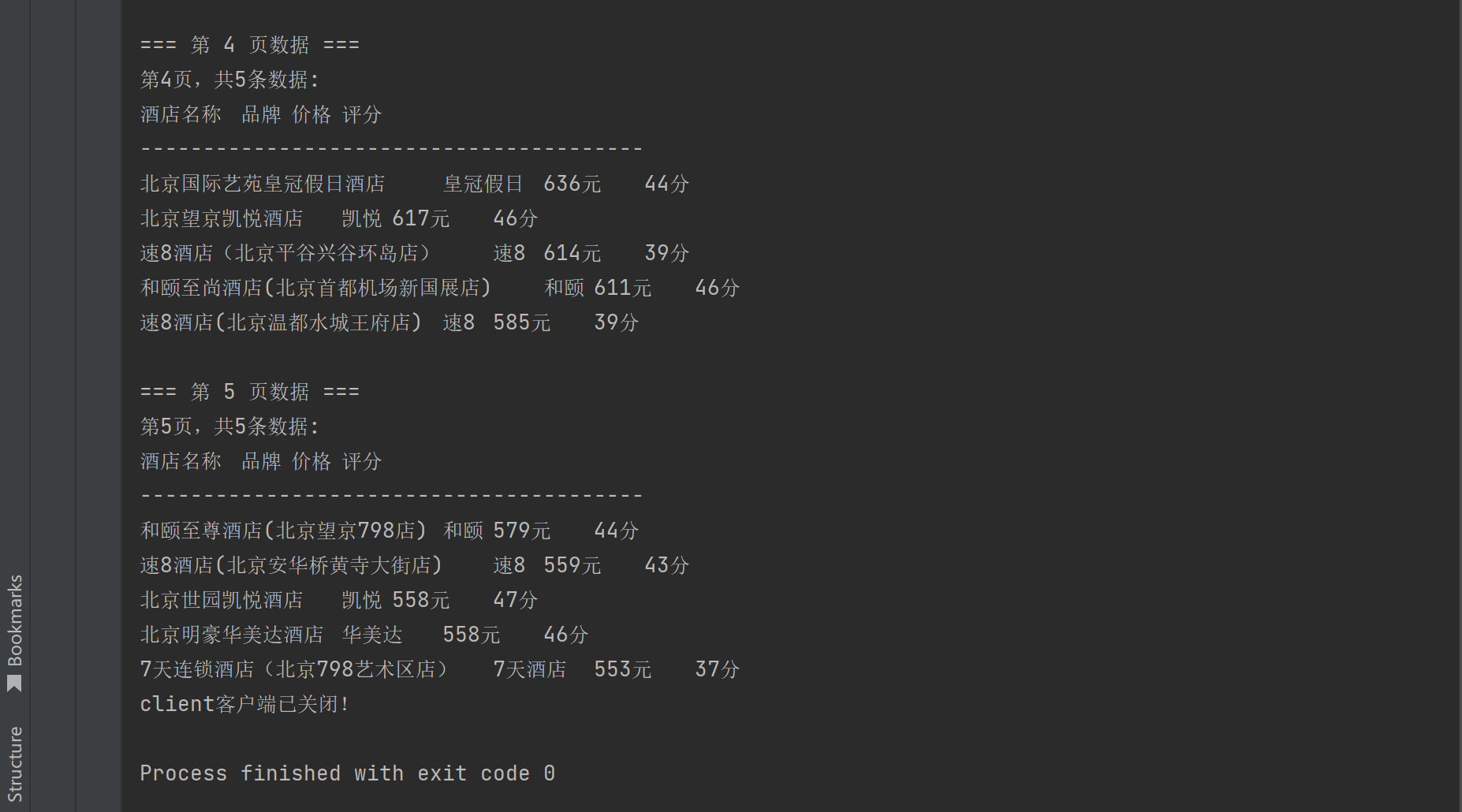
可以看到程序按照最多查询5页,每页查询5条数据进行循环查询。这种模式的查询性能,要比from-size的查询性能高。
3.3 结合PIT(Point In Time)保证查询一致性
为了保证在分页过程中数据的一致性(假设无法避免在分页过程中文档发生了增删改),我们可以结合PIT使用。
PIT的核心在于冻结数据状态。当你为索引创建一个PIT时,Elasticsearch会保留此刻索引的"快照"(snapshot)。后续所有基于此PIT ID的查询,都将在创建PIT时那个固定的数据状态上进行,仿佛时间在此刻静止。
这意味着,即使在PIT创建后,索引中新增、修改或删除了文档,这些变更都不会影响到基于该PIT的搜索结果。例如,若在创建PIT后向索引添加了新文档,使用PIT进行搜索将无法查询到这些新文档。
PIT从两个层面确保了查询的一致性:
1.数据状态一致性: PIT提供了一个稳定的、不受后续写操作影响的数据视图。这对于需要跨多个分页请求维护结果集稳定的操作(如深度分页)至关重要。没有PIT的话,在分页间隙发生的数据变更可能导致某些文档在不同页面重复出现或丢失。
**2.排序一致性:**与PIT配合使用时,search_after分页机制依赖于固定数据状态下的排序值。这确保了翻页过程中排序依据的稳定,从而保障了分页结果的正确和连续。如下面的样例:
java
package com.example;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.PointInTimeBuilder;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
import java.util.Map;
import java.util.concurrent.TimeUnit;
public class SearchAfterWithPITExample {
public static void main(String[] args) throws Exception {
RestHighLevelClient client = ElasticsearchClient.getClient();
try {
// 1. 创建PIT(Point In Time)
String pitId = createPit(client, "hotel");
System.out.println("创建的PIT ID: " + pitId);
// 2. 使用PIT进行分页查询
searchWithPit(client, pitId);
// 3. 删除PIT
deletePit(client, pitId);
} finally {
ElasticsearchClient.close();
}
}
private static String createPit(RestHighLevelClient client, String index) throws Exception {
// 在实际的RestHighLevelClient中,创建PIT需要使用OpenPitRequest
// 这里简化为模拟实现
return "example_pit_id_" + System.currentTimeMillis();
}
private static void searchWithPit(RestHighLevelClient client, String pitId) throws Exception {
Object[] searchAfter = null;
int pageSize = 5;
int pageNumber = 1;
do {
SearchRequest request = new SearchRequest();
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 使用PIT进行查询
PointInTimeBuilder pitBuilder = new PointInTimeBuilder(pitId);
pitBuilder.setKeepAlive(TimeValue.timeValueMinutes(5));
request.source(sourceBuilder);
// 查询条件:深圳的万豪系酒店
sourceBuilder.query(QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("city", "深圳"))
.must(QueryBuilders.wildcardQuery("brand", "*万豪*")));
// 排序规则
sourceBuilder.sort("score", SortOrder.DESC);
sourceBuilder.sort("price", SortOrder.ASC);
sourceBuilder.sort("id", SortOrder.ASC);
sourceBuilder.size(pageSize);
if (searchAfter != null) {
sourceBuilder.searchAfter(searchAfter);
}
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
if (hits.getHits().length == 0) {
break;
}
System.out.printf("\n=== 第 %d 页(使用PIT)===\n", pageNumber);
for (SearchHit hit : hits.getHits()) {
Map<String, Object> sourceMap = hit.getSourceAsMap();
String name = (String) sourceMap.get("name");
String brand = (String) sourceMap.get("brand");
Integer price = (Integer) sourceMap.get("price");
System.out.printf("酒店: %s, 品牌: %s, 价格: %d元\n",
name != null ? name : "未知",
brand != null ? brand : "未知",
price != null ? price : 0);
searchAfter = hit.getSortValues();
}
pageNumber++;
} while (pageNumber <= 3); // 限制最多查询3页
}
private static void deletePit(RestHighLevelClient client, String pitId) throws Exception {
// 在实际的RestHighLevelClient中,删除PIT需要使用DeletePitRequest
System.out.println("删除PIT: " + pitId);
}
}查询结果:
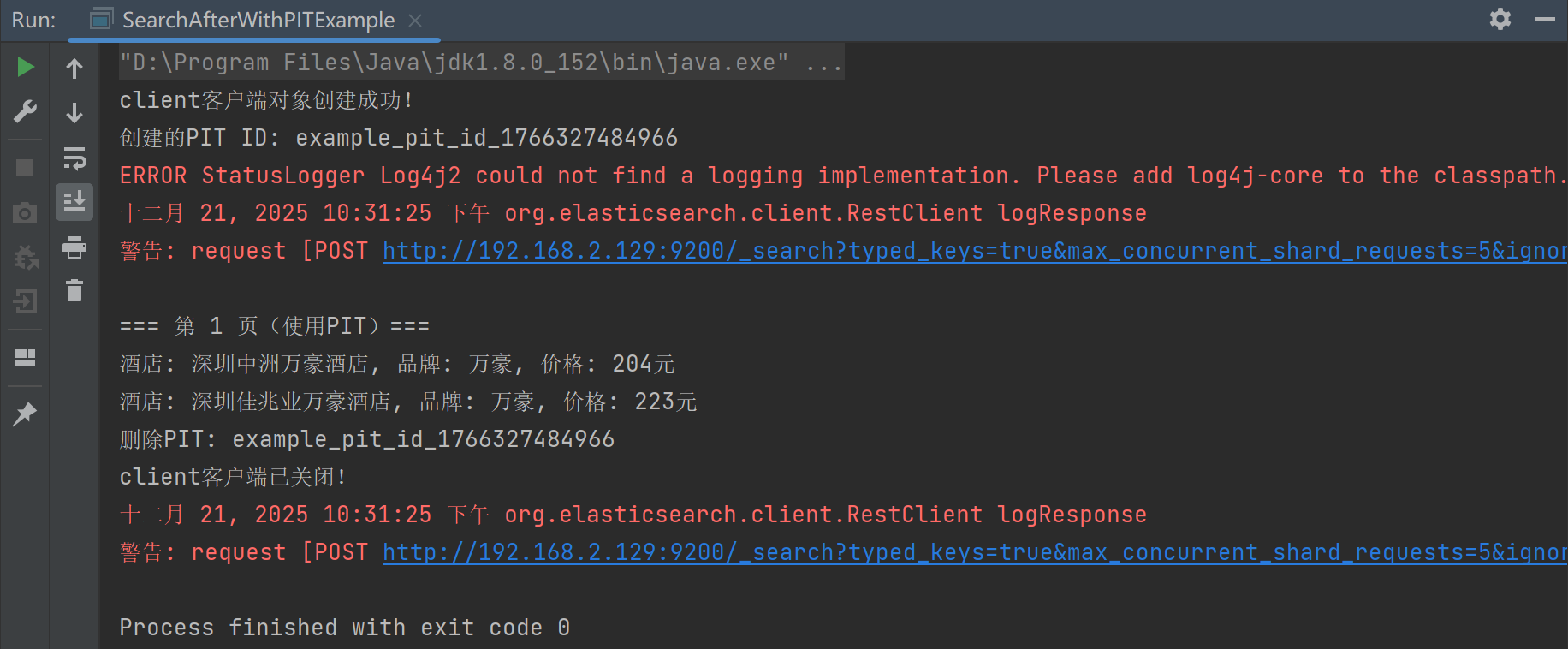
代码仅用于示例,需要深入研究PIT的童鞋,可以进一步探究,这里不再展开。
PIT实践技巧与注意事项:
●keep_alive的设置 :其时长只需保证足够下一个搜索请求执行即可,无需设置过长。每次使用PIT ID进行搜索时,都可以(也应该)在请求体中传递一个新的 keep_alive来更新其存活时间。
●资源管理 :使用GET /_nodes/stats/indices/search可以监控集群中打开的PIT数量(即搜索上下文)。及时关闭不再需要的PIT是良好的习惯。
●与search_after的协同:PIT+search_after是Elasticsearch官方推荐的深度分页方案。search_after参数利用上一页最后一个文档的排序值进行翻页,而PIT确保了这些排序值所基于的数据集保持不变。
四、scroll使用实践
除了上面提到的search_after最佳实践,在Elasticsearch中处理大量数据时,还有一种ScrollAPI查询方式,它提供了一种高效遍历大量文档(甚至全部文档)的机制,特别适合数据导出、全量索引等场景
4.1 Scroll 模式核心原理
Scroll查询的核心思想类似于传统数据库中的游标(Cursor)。当你发起一个带有scroll参数的搜索请求时,Elasticsearch会为这次搜索创建一个快照(Snapshot) 并保存一个搜索上下文(Search Context)。这个快照保证了在遍历过程中,即使索引中有新的数据写入或现有数据被修改,查询结果集也不会改变,从而确保了一致性。
其工作流程主要分为三步:
(1)初始化:首次搜索请求指定scroll存活时间(如1m),返回第一批结果和一个scroll_id。
(2)迭代:后续请求使用最新的scroll_id来获取下一批结果,直到没有更多数据。
(3)清理:使用完毕后,应及时清除scroll上下文以释放资源。
4.2 典型应用场景
●数据导出与备份: 需要将整个索引或符合特定条件的大量数据导出到文件或数据库时。
●数据迁移与重构: 将数据从一个索引迁移到另一个索引,或者进行需要全量数据的计算和处理。
●离线分析与处理: 对大量数据进行离线分析、生成报表等非实时任务。
重要提示:由于Scroll查询基于快照,它不适用于需要实时性的用户交互式分页场景。对于深度分页需求,search_after是更好的选择。
以下代码演示了如何RestClient对hotel索引进行Scroll查询,导出所有酒店数据:
java
package com.example;
import org.elasticsearch.action.search.*;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class HotelScrollExportExample {
public static void main(String[] args) {
RestHighLevelClient client = ElasticsearchClient.getClient();
List<Map<String, Object>> allHotels = new ArrayList<>();
String scrollId = null;
try {
// 1. 创建初始搜索请求,并设置 Scroll 上下文存活时间
SearchRequest searchRequest = new SearchRequest("hotel");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery()); // 查询所有文档
searchSourceBuilder.size(100); // 每次滚动获取100条文档
searchRequest.source(searchSourceBuilder);
searchRequest.scroll(TimeValue.timeValueMinutes(5L)); // 设置scroll上下文保持5分钟
// 2. 执行初始搜索
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
scrollId = searchResponse.getScrollId();
SearchHit[] hits = searchResponse.getHits().getHits();
System.out.println("开始导出酒店数据...");
// 3. 循环处理所有批次,直到没有更多数据
while (hits != null && hits.length > 0) {
for (SearchHit hit : hits) {
Map<String, Object> hotelData = hit.getSourceAsMap();
allHotels.add(hotelData);
// 这里可以处理每条数据,例如:
String hotelName = (String) hotelData.get("name");
String city = (String) hotelData.get("city");
Integer price = (Integer) hotelData.get("price");
System.out.printf("酒店: %s, 城市: %s, 价格: %d%n", hotelName, city, price);
}
System.out.println("已处理 " + allHotels.size() + " 条数据,继续获取下一批...");
// 4. 使用 ScrollId 获取下一批结果
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);
scrollRequest.scroll(TimeValue.timeValueMinutes(5L)); // 刷新存活时间
searchResponse = client.scroll(scrollRequest, RequestOptions.DEFAULT);
scrollId = searchResponse.getScrollId(); // 更新 scrollId
hits = searchResponse.getHits().getHits();
}
System.out.println("数据导出完成!总计导出酒店数量: " + allHotels.size());
} catch (IOException e) {
e.printStackTrace();
} finally {
// 5. 重要!清理 Scroll 上下文,释放资源
if (scrollId != null) {
try {
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(scrollId);
ClearScrollResponse clearScrollResponse = client.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
if (clearScrollResponse.isSucceeded()) {
System.out.println("Scroll上下文已成功清理。");
}
} catch (IOException e) {
System.err.println("清理Scroll上下文时发生错误: " + e.getMessage());
}
}
// 关闭客户端连接
try {
ElasticsearchClient.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}查询结果:
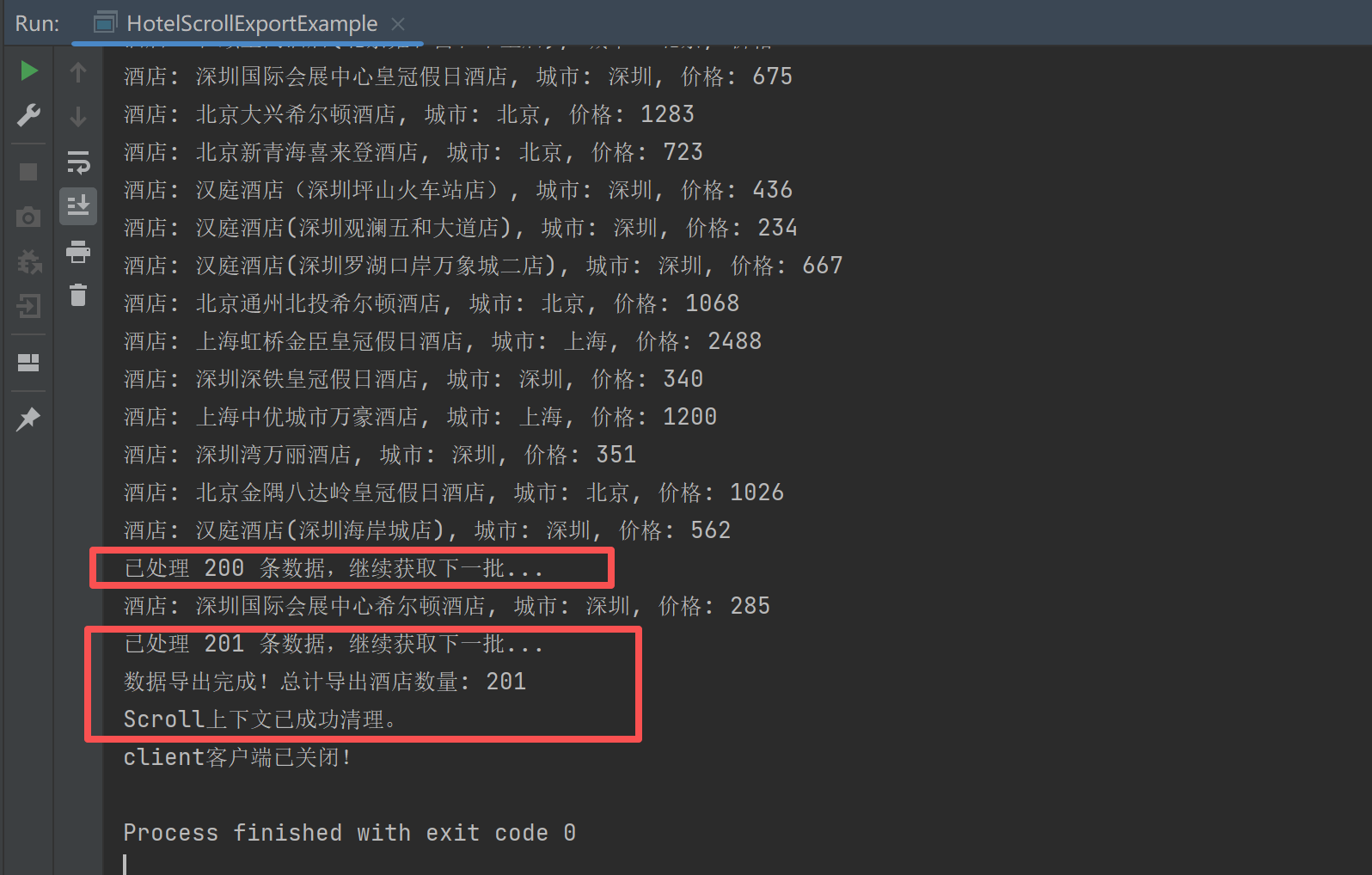
这里可以看到使用scroll后,ElasticSearch为我们所有酒店数据分成了2批数据,我们按照其划分的结果分批查询,得到所有数据。
4.3 关键注意事项
(1)性能与资源: 虽然Scroll可以高效遍历大量数据,但保持打开的scroll上下文需要消耗服务器资源(内存和文件句柄)。务必根据数据量合理设置scroll的存活时间(keep_alive),并在使用完毕后立即清理。
(2)实时性: Scroll查询的结果是快照,无法查询到在扫描开始后新写入的数据。对于需要实时性的场景,应考虑search_after。
**(3)排序:**与search_after不同,Scroll查询对排序没有强制要求。但如果不指定排序,默认返回顺序可能是索引顺序或相关性得分,多次遍历顺序可能不一致。若需要确定顺序,应明确指定sort。
五、from+size、search_after、scroll与PIT对比
5.1 性能对比分析
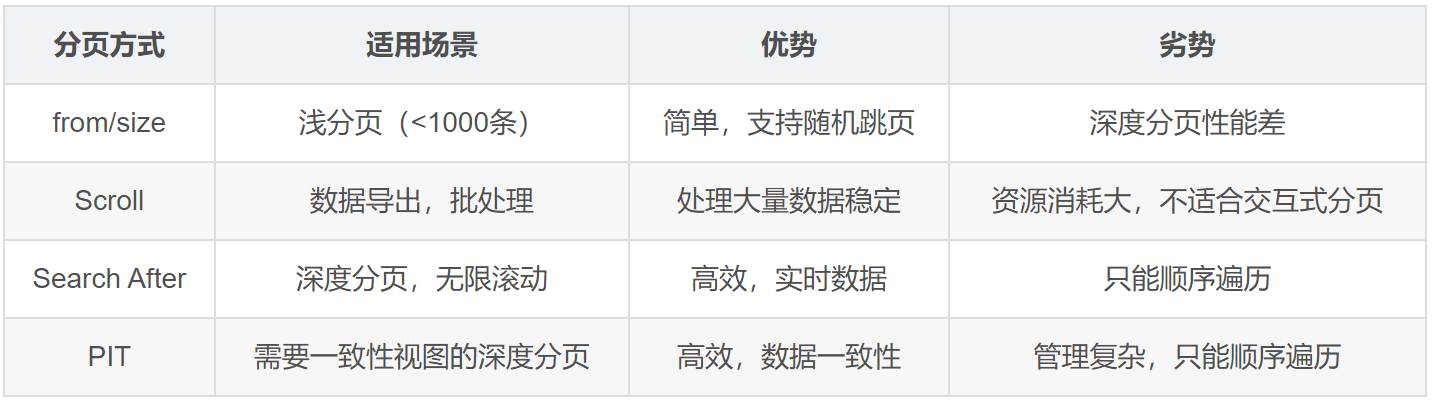
5.2 适用场景代码对比
下面是一个完整的Java代码实例,用于对比Elasticsearch中三种分页查询模式(from+size、search_after、scroll)的性能表现。我将基于hotel索引来演示这三种查询方式,并统计各自的执行时间。
三种分页查询模式性能对比测试:
java
package com.example;
import org.elasticsearch.action.search.*;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class PaginationPerformanceComparison {
private static final String INDEX_NAME = "hotel";
private static final int PAGE_SIZE = 100;
private static final int MAX_RESULTS = 1000; // 限制测试数据量
public static void main(String[] args) throws Exception {
RestHighLevelClient client = ElasticsearchClient.getClient();
try {
System.out.println("=== Elasticsearch 分页查询性能对比测试 ===");
System.out.println("索引: " + INDEX_NAME);
System.out.println("每页大小: " + PAGE_SIZE);
System.out.println("最大结果数: " + MAX_RESULTS);
System.out.println();
// 1. 测试 from+size 分页
long fromSizeTime = testFromSizePagination(client);
System.out.println();
// 2. 测试 search_after 分页
long searchAfterTime = testSearchAfterPagination(client);
System.out.println();
// 3. 测试 scroll 分页
long scrollTime = testScrollPagination(client);
System.out.println();
// 打印性能对比结果
printComparisonResult(fromSizeTime, searchAfterTime, scrollTime);
} finally {
ElasticsearchClient.close();
}
}
/**
* 测试 from+size 分页性能
*/
private static long testFromSizePagination(RestHighLevelClient client) throws IOException {
System.out.println("1. 测试 from+size 分页...");
long startTime = System.currentTimeMillis();
List<Map<String, Object>> allResults = new ArrayList<>();
int totalPages = (int) Math.ceil((double) MAX_RESULTS / PAGE_SIZE);
for (int page = 0; page < totalPages && allResults.size() < MAX_RESULTS; page++) {
int from = page * PAGE_SIZE;
int size = Math.min(PAGE_SIZE, MAX_RESULTS - allResults.size());
SearchRequest searchRequest = new SearchRequest(INDEX_NAME);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 查询条件:获取所有酒店,按价格排序
sourceBuilder.query(QueryBuilders.matchAllQuery());
sourceBuilder.from(from);
sourceBuilder.size(size);
sourceBuilder.sort(SortBuilders.fieldSort("price").order(SortOrder.ASC));
sourceBuilder.sort(SortBuilders.fieldSort("id").order(SortOrder.ASC));
searchRequest.source(sourceBuilder);
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hits = response.getHits().getHits();
for (SearchHit hit : hits) {
if (allResults.size() < MAX_RESULTS) {
allResults.add(hit.getSourceAsMap());
}
}
System.out.printf(" 第%d页: 获取%d条数据,累计%d条%n",
page + 1, hits.length, allResults.size());
}
long endTime = System.currentTimeMillis();
long duration = endTime - startTime;
System.out.printf("✅ from+size 完成: %d条数据, 耗时: %dms%n",
allResults.size(), duration);
return duration;
}
/**
* 测试 search_after 分页性能
*/
private static long testSearchAfterPagination(RestHighLevelClient client) throws IOException {
System.out.println("2. 测试 search_after 分页...");
long startTime = System.currentTimeMillis();
List<Map<String, Object>> allResults = new ArrayList<>();
Object[] searchAfter = null;
int pageCount = 0;
do {
SearchRequest searchRequest = new SearchRequest(INDEX_NAME);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 查询条件
sourceBuilder.query(QueryBuilders.matchAllQuery());
sourceBuilder.size(PAGE_SIZE);
// 必须指定排序字段,且包含唯一字段
sourceBuilder.sort(SortBuilders.fieldSort("price").order(SortOrder.ASC));
sourceBuilder.sort(SortBuilders.fieldSort("id").order(SortOrder.ASC));
if (searchAfter != null) {
sourceBuilder.searchAfter(searchAfter);
}
searchRequest.source(sourceBuilder);
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hits = response.getHits().getHits();
if (hits.length == 0) {
break;
}
for (SearchHit hit : hits) {
if (allResults.size() < MAX_RESULTS) {
allResults.add(hit.getSourceAsMap());
} else {
break;
}
}
// 获取最后一条记录的排序值
SearchHit lastHit = hits[hits.length - 1];
searchAfter = lastHit.getSortValues();
pageCount++;
System.out.printf(" 第%d页: 获取%d条数据,累计%d条%n",
pageCount, hits.length, allResults.size());
if (allResults.size() >= MAX_RESULTS) {
break;
}
} while (true);
long endTime = System.currentTimeMillis();
long duration = endTime - startTime;
System.out.printf("✅ search_after 完成: %d条数据, 耗时: %dms%n",
allResults.size(), duration);
return duration;
}
/**
* 测试 scroll 分页性能
*/
private static long testScrollPagination(RestHighLevelClient client) throws IOException {
System.out.println("3. 测试 scroll 分页...");
long startTime = System.currentTimeMillis();
List<Map<String, Object>> allResults = new ArrayList<>();
String scrollId = null;
try {
// 初始搜索请求
SearchRequest searchRequest = new SearchRequest(INDEX_NAME);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchAllQuery());
sourceBuilder.size(PAGE_SIZE);
sourceBuilder.sort(SortBuilders.fieldSort("price").order(SortOrder.ASC));
searchRequest.source(sourceBuilder);
searchRequest.scroll(TimeValue.timeValueMinutes(1L)); // 设置scroll上下文
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
scrollId = response.getScrollId();
SearchHit[] hits = response.getHits().getHits();
for (SearchHit hit : hits) {
if (allResults.size() < MAX_RESULTS) {
allResults.add(hit.getSourceAsMap());
}
}
System.out.printf(" 初始页: 获取%d条数据,累计%d条%n", hits.length, allResults.size());
// 使用scroll继续获取数据
int pageCount = 1;
while (hits != null && hits.length > 0 && allResults.size() < MAX_RESULTS) {
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);
scrollRequest.scroll(TimeValue.timeValueMinutes(1L));
response = client.scroll(scrollRequest, RequestOptions.DEFAULT);
scrollId = response.getScrollId();
hits = response.getHits().getHits();
for (SearchHit hit : hits) {
if (allResults.size() < MAX_RESULTS) {
allResults.add(hit.getSourceAsMap());
} else {
break;
}
}
pageCount++;
System.out.printf(" 滚动页%d: 获取%d条数据,累计%d条%n",
pageCount, hits.length, allResults.size());
if (allResults.size() >= MAX_RESULTS) {
break;
}
}
} finally {
// 清理scroll上下文
if (scrollId != null) {
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(scrollId);
client.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
}
}
long endTime = System.currentTimeMillis();
long duration = endTime - startTime;
System.out.printf("✅ scroll 完成: %d条数据, 耗时: %dms%n",
allResults.size(), duration);
return duration;
}
/**
* 打印性能对比结果
*/
private static void printComparisonResult(long fromSizeTime, long searchAfterTime, long scrollTime) {
System.out.println("=== 性能对比结果 ===");
System.out.println("┌─────────────────┬──────────┬────────────┐");
System.out.println("│ 分页方式 │ 耗时(ms) │ 相对性能 │");
System.out.println("├─────────────────┼──────────┼────────────┤");
long minTime = Math.min(Math.min(fromSizeTime, searchAfterTime), scrollTime);
System.out.printf("│ from+size │ %8d │ %6.2fx │%n",
fromSizeTime, (double) fromSizeTime / minTime);
System.out.printf("│ search_after │ %8d │ %6.2fx │%n",
searchAfterTime, (double) searchAfterTime / minTime);
System.out.printf("│ scroll │ %8d │ %6.2fx │%n",
scrollTime, (double) scrollTime / minTime);
System.out.println("└─────────────────┴──────────┴────────────┘");
// 性能分析
System.out.println("\n=== 性能分析 ===");
if (fromSizeTime > searchAfterTime && fromSizeTime > scrollTime) {
System.out.println("• from+size 性能最差,适合浅分页场景(前1000条以内)");
}
if (searchAfterTime <= fromSizeTime && searchAfterTime <= scrollTime) {
System.out.println("• search_after 性能最优,适合深度分页和实时查询");
}
if (scrollTime <= fromSizeTime && scrollTime <= searchAfterTime) {
System.out.println("• scroll 性能优秀,适合大数据量导出和离线处理");
}
System.out.println("\n=== 使用建议 ===");
System.out.println("1. from+size: 适合前几页查询,简单易用");
System.out.println("2. search_after: 适合深度分页,实时性要求高的场景");
System.out.println("3. scroll: 适合数据导出、批量处理等离线场景");
}
}查询结果:
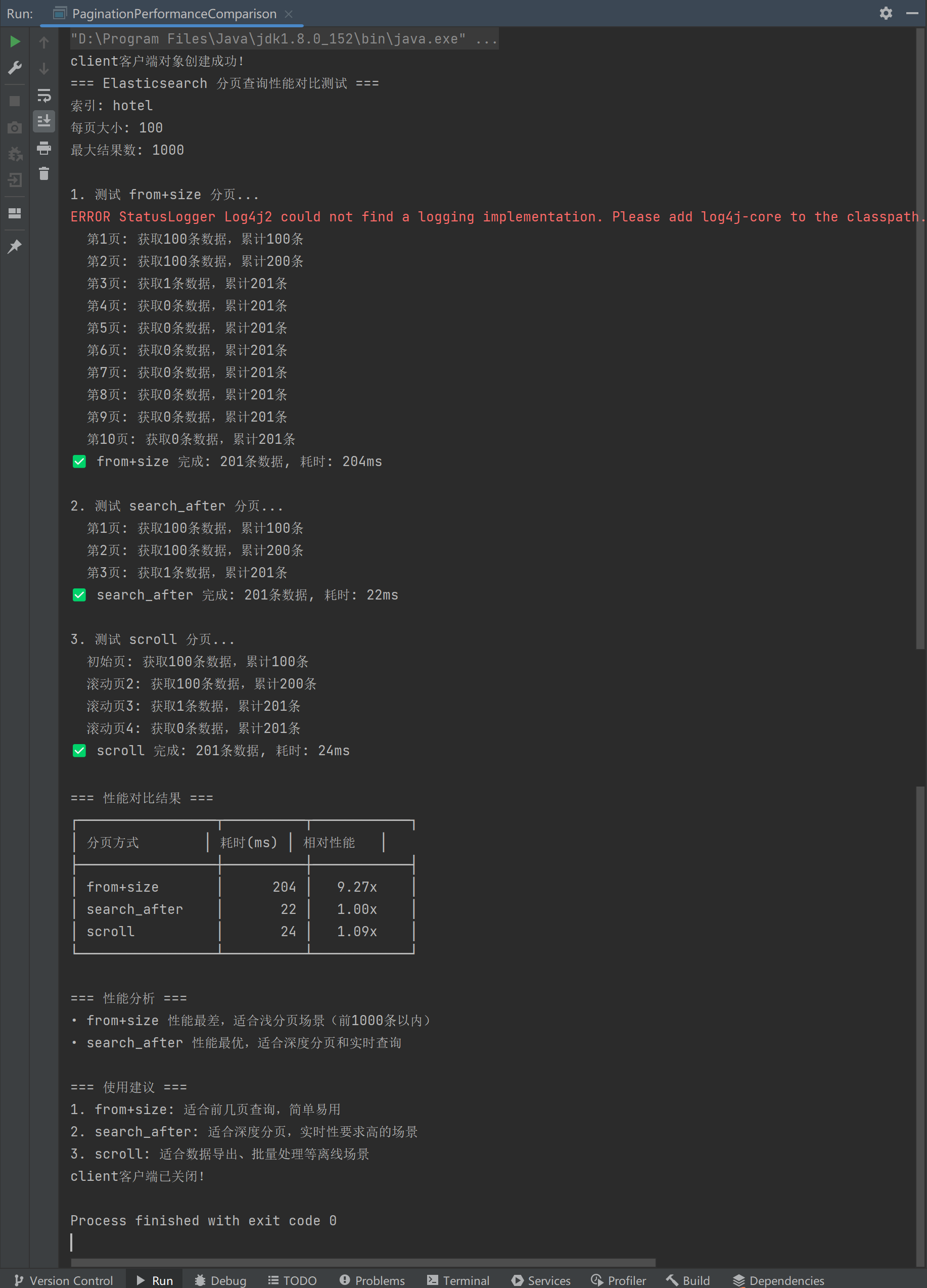
可以看到,search_after 性能优秀,适合深度分页和实时查询。
转载请注明出处:https://blog.csdn.net/acmman/article/details/156136293