0. 概要
该文对基于DNN的俄语语音识别声学建模进行了研究。使用开源的Kaldi工具包对系统进行了训练和测试。我们创建了具有不同隐藏层数和不同隐藏单元数的tanhtanhtanh 和 p−normDNNsp - norm DNNsp−normDNNs。在超大词汇量连续俄语语音识别任务上进行了模型的测试。与基准模型GMM - HMM系统相比,我们获得了20 %的相对WER降低。
1. 引言
在声学建模领域,人工神经网络(ANNs)常通过混合法 (hybrid method) 与串联法(tandem method) 两种方式与隐马尔可夫模型(HMMs)结合使用。
- 在混合法中,人工神经网络被用于估计隐马尔可夫模型状态的后验概率;
- 在串联法中,人工神经网络的输出则被当作隐马尔可夫 - 高斯混合模型(HMM-GMM)系统的额外输入特征流。
Kaldi
Kaldi采用C++编写,基于OpenFST库,使用BLAS和LAPACK库进行线性代数运算。
在 Kaldi 中,深度神经网络(DNNs)有两种实现方式
- 第一种是 Kerel 实现方案:该方案支持受限玻尔兹曼机(RBM)预训练、基于图形处理器(GPU)的随机梯度训练,以及判别式训练。
- 第二种是 Dan 实现方案 :该方案不支持受限玻尔兹曼机预训练,而是采用了一种与 "贪心逐层监督训练 " 或 "逐层反向传播"相似的方法。
该研究选择了第二种 DNN 实现方案,原因是它支持在多个中央处理器(CPUs)上进行并行训练。
Dan 方案(贪心逐层监督训练)完整流程
- 基础准备(并行环境初始化)
- 数据与模型配置:输入特征(如 MFCC)+ 标注(音素 / 词级标签),固定输入 / 输出层维度,划分训练数据为多个 mini-batch(批大小适配 CPU 核心数)。
- 并行环境搭建(核心):
- 初始化 Kaldi 的多 CPU 并行框架(如 OpenMP/MPI),指定可用 CPU 核心数(如 8 核 / 16 核);
- 将数据 mini-batch 分配到不同 CPU 核心,每个核心负责一个批次的特征计算与梯度更新,避免单核心瓶颈。
-
首层训练(单层级并行)
-
网络结构:输入→隐藏 1→输出(单层 DNN)。
-
并行训练逻辑:
- 每个 CPU 核心独立加载一个数据 mini-batch,计算当前批次的监督损失(如交叉熵);
- 各核心并行计算梯度(仅针对隐藏 1 层 + 输出层参数),汇总梯度到主进程;
- 主进程更新权重后,同步到所有 CPU 核心,完成一轮迭代;
-
收尾:训练收敛后冻结隐藏 1 层,将隐藏 1 层的输出结果按 CPU 核心拆分存储(为下一层并行做准备)。
-
-
逐层堆叠(跨层级并行 + 单层级并行)
以新增隐藏 2 层为例(后续层逻辑一致):- 数据分发:将之前各 CPU 核心存储的隐藏 1 层输出,直接作为对应核心的输入数据(无需重新分发,减少数据传输耗时);
- 并行训练逻辑:
- 各 CPU 核心仅优化隐藏 2 层 + 输出层参数(隐藏 1 层已冻结,无梯度计算);
- 核心间无需交互(仅主进程汇总梯度),每层训练的计算任务完全并行;
- 收尾:冻结隐藏 2 层,拆分存储其输出,重复堆叠至目标层数(如隐藏 3/4 层),每一层均沿用该并行逻辑。
-
全局微调(可选,轻量级并行)
- 解冻所有层,降低学习率(避免参数震荡);
- 仍采用多 CPU 核心并行计算梯度,但因涉及所有层,主进程汇总梯度的耗时略增加(但远低于单 CPU 训练);
- 微调轮数远少于逐层训练,整体并行收益仍显著。
2. 相关著作
Context-dependent pre-trained deep neural networks for large vocabulary speech recognition. IEEE Trans. Audio Speech Lang. Process. 20(1), 30--42 (2012)
- 核心贡献是验证了 DBN 在大词汇量语音识别中的有效性,证明基于深度学习的混合架构(DNN-HMM)相比传统 GMM-HMM 有稳定性能增益;
Conversational speech transcription using context-dependent deep neural networks. In: INTERSPEECH-2011, pp. 437--440 (2011)
-
将基于人工神经网络(ANN)的隐马尔可夫模型、绑定状态三音子与深度信念网络(DBN)预训练这三项技术进行了融合
- 三音子(triphones):语音识别中常用的上下文建模单元,定义为 "左邻音素 - 当前音素 - 右邻音素" 的三元组,比如 /b/-/a/-/c/ 就是一个三音子。
- 绑定状态(tied-state):如果为每个三音子都单独训练一套模型参数,会导致参数爆炸(大词汇量下三音子数量可达百万级)。"状态绑定" 就是将声学特征相似的三音子状态共享同一套参数,在保证建模精度的同时,大幅降低模型复杂度。
Tandem acoustic modeling in large-vocabulary recognition. In: International Conference on Acoustics, Speech and Signal Processing ICASSP 2001, pp. 517--520 (2001)
-
提出了串联法(tandem approach)在声学建模中的应用,完整链路可总结为:
连续特征窗口输入→DNN训练(混合法流程)→提取高层特征→GMM−HMM训练(EM算法)→最终识别连续特征窗口输入→DNN训练(混合法流程)→提取高层特征→GMM-HMM训练(EM算法)→最终识别连续特征窗口输入→DNN训练(混合法流程)→提取高层特征→GMM−HMM训练(EM算法)→最终识别
- 连续特征向量窗口:指将相邻多帧的 MFCC/PLP 特征拼接成一个时序窗口输入 DNN,目的是让网络捕捉语音的短时上下文信息(比如相邻帧的声学变化趋势),这是比单帧特征更有效的输入形式。
- DNN 训练遵循混合法流程:这里的混合法流程,本质是让 DNN 学习特征的非线性变换,而非直接估计 HMM 状态后验概率 ------ 串联法的核心就是用 DNN 做特征增强,而非替代 GMM。
- EM 算法训练 GMM-HMM:EM 算法是训练 GMM 的标准方法,分为两步:
- E 步:根据当前 GMM 参数,计算每个样本属于各高斯分量的概率;
- M 步:更新高斯分量的均值、方差和权重,最大化样本的似然概率;反复迭代直至收敛,完成 GMM 对 DNN 提取特征的建模。
Probabilistic and bottle-neck features for LVCSR of meetings. In: ICASSP 2007, pp. 757--760 (2007)
- 对串联法的优化升级------ 该方法无需将神经网络的输出概率,转换为适用于高斯混合模型 - 隐马尔可夫模型(GMM-HMM)系统的特征形式。研究搭建了含瓶颈层(bottle-neck layer)的 5 层感知器并开展实验:在完成 DNN 的训练后,直接将瓶颈层的输出作为特征,输入至 GMM-HMM 语音识别系统中
- 瓶颈层是 DNN 中维度远低于前后层的隐藏层(比如前一层维度是 1024,瓶颈层维度是 64,后一层再恢复到 1024),形似 "瓶颈" 而得名
- 5 层结构属于中等深度的 DNN,兼顾了特征提取能力和训练效率:
- 输入层:接收连续语音特征窗口(如 MFCC 帧拼接);
- 隐藏层 1-2:逐层提取低层声学特征(如频谱、共振峰信息);
- 瓶颈层:压缩并提纯核心特征;
- 隐藏层 4-5:将瓶颈层特征映射回高维空间,辅助后续训练(但实验中未使用这两层的输出);
- 输出层:用于 DNN 的监督训练(如音素分类),训练完成后即不再使用。
System of speech recognition for Russian language, using deep neural networks and finite state transducers. Neurocomput. Dev. Appl. 10, 40--46 (2013). (in Russia)
3. 声学建模
图 1 展示了DNN-HMM 混合系统的通用架构。该深度神经网络(DNN)经训练后,能够根据给定的声学观测数据,预测每个上下文相关状态的后验概率。在解码阶段,将神经网络输出的概率除以各状态的先验概率,得到一种 "伪似然值",并以此替代隐马尔可夫模型(HMM)中原有的状态发射概率 。
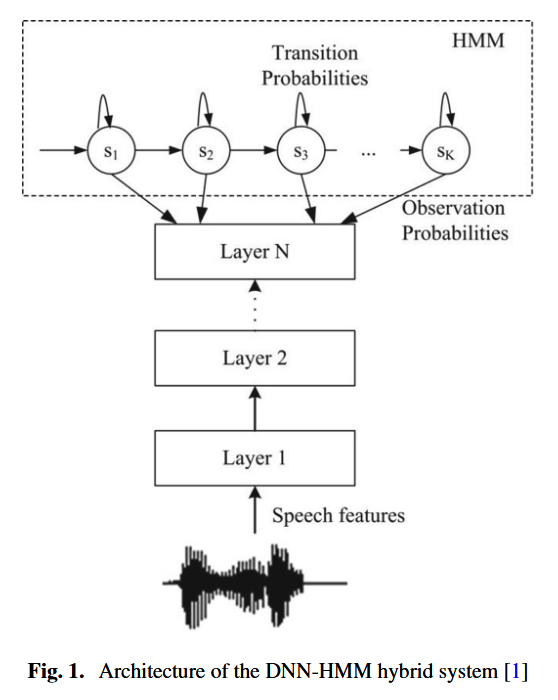
- Kaldi 中 DNN-HMM 声学建模的 "标准流水线",核心逻辑是 "用传统 GMM-HMM 模型完成初始化与状态对齐,再基于对齐结果训练 DNN",每一步都是为后续 DNN 训练铺垫更精准的声学建模基础。
- 整个 GMM-HMM 训练的核心目标:生成高质量的状态对齐,给 DNN 准备精准的监督标签
核心训练依赖:数据、决策树、对齐信息的来源
- 训练特征:DNN 输入的是 fMLLR 自适应后的声学特征
原因很直接 ------fMLLR 已经消除了不同说话人的音色、语速差异,用这种特征训练的 DNN 泛化能力更强,识别鲁棒性更高。 - 决策树:来自 SAT-fMLLR GMM 模型
决策树的作用是 对大量三音子状态进行聚类。因为三音子的数量会随词汇量指数级增长(比如英语可能有几十万种三音子组合),直接建模会导致参数爆炸;决策树通过声学相似性将三音子聚成有限的 "状态绑定类",减少 DNN 的输出节点数,降低训练难度。 - 状态对齐信息:同样来自 SAT-fMLLR GMM 模型
这就是我们之前提到的 DNN 训练的监督标签------SAT-fMLLR GMM 模型是 GMM 系列中性能最优的版本,它输出的 "特征帧→HMM 状态" 的对齐结果最精准,用它做监督信号,DNN 才能学到可靠的特征 - 状态映射关系。
非线性激活函数的选型:tanh vs p-norm
DNN 的核心能力来自非线性激活函数------ 它能打破线性模型的局限,让网络拟合声学特征和 HMM 状态之间的复杂映射关系
- tanh 函数:是传统 DNN 中常用的激活函数,输出范围在 -1,1,能将神经元的输出做非线性变换,同时缓解梯度消失问题(相比 sigmoid 更适合深层网络)
- p-norm 函数 :是一种广义的归一化激活函数,它的核心思想是对神经元的输入进行 p 阶范数归一化,再输出结果。
- 这种函数的优势是 对特征的尺度变化更鲁棒,能自适应不同说话人、不同环境下的特征波动,在语音识别任务中常能取得比 tanh 更优的性能。
- 通常 p-norm 的计算公式可以表示为:p-norm(xi)=xi(∑j∣xj∣p)1/p\text{p-norm}(x_i) = \frac{x_i}{\left(\sum_{j} |x_j|^p\right)^{1/p}}p-norm(xi)=(∑j∣xj∣p)1/pxi
- 其中 xix_ixi 是神经元的输入,p 是范数阶数(常见取值为 2 或 3)。
DNN 输出层
-
使用 Softmax 层,将 DNN 最后一层的原始输出(logits)转化为概率分布,每个输出节点对应一个 HMM 上下文相关状态的后验概率 P(s∣o)P(s|o)P(s∣o),所有节点的概率之和为 1。
-
输出维度:等于 HMM 上下文相关状态的总数,文中实验的维度是 1609。
这个数值由两部分决定:一是前面 SAT-fMLLR GMM 模型的决策树聚类结果,二是目标语言的音素上下文组合数量;1609 这个维度说明模型的状态划分足够精细,能精准表征不同的语音声学特征。
DNN 的训练超参数
-
再次明确输入是 fMLLR 自适应特征,保证模型的跨说话人泛化能力。
-
用 "衰减学习率 + 固定学习率" 的两阶段训练策略,这是深度学习中防止过拟合、稳定收敛的常用技巧:
- 第一阶段(15 个 epochs):学习率从 0.02 线性衰减到 0.004
- 初始较大的学习率可以让模型快速逼近最优解区域;
- 逐步衰减能避免后期参数震荡,让模型更平稳地收敛
- 第二阶段(5 个 epochs):固定学习率 0.004 继续训练
- 目的是在最优解区域内做精细微调,进一步提升模型精度。
- 第一阶段(15 个 epochs):学习率从 0.02 线性衰减到 0.004
-
学习率的衰减方式
-
"线性衰减" 是指每轮 epoch 的学习率按固定步长递减
-
学习率t=初始学习率−(初始学习率−最终学习率)衰减轮数×(t−1)\text{学习率}_t = \text{初始学习率} - \frac{(\text{初始学习率}-\text{最终学习率})}{\text{衰减轮数}} \times (t-1)学习率t=初始学习率−衰减轮数(初始学习率−最终学习率)×(t−1)
-
代入数值(初始 = 0.02,最终 = 0.004,衰减轮数 = 15)
-
4. 训练与测试
训练集
语料库
是 SPIIRAS(圣彼得堡信息学与自动化研究所)自建的语料库,属于机构内部的专属数据,而非公开通用数据集。
语料库的两部分构成
- 第一部分:EuroNounce 项目框架下的语音数据库
- 第二部分:补充的俄语母语者录音数据
总时长 超过 25 小时
测试集
训练 - 测试数据独立
测试集的核心设计原则:与训练集完全解耦;测试集的短语全部取自某份俄语在线报纸,且这份报纸的内容完全没有出现在训练数据中。
该实验的语音数据从采集到预处理都严格遵循高质量标准:专业设备 + 干净环境保证原始数据纯度,降采样和单文件存储适配模型训练需求,配套转录文本则为模型训练和评估提供了关键监督信息。
5. 实验
俄语语音识别(ASR)系统的语言模型(LM)和词汇层关键配置
n-gram 语言模型:约束识别结果的合理性
- 约束声学模型输出的词序列,避免出现语法或语义不通的结果(比如声学模型可能混淆发音相似的词,语言模型会通过 "哪个词组合更常见" 来修正)
平滑方法:Kneser-Ney 平滑
- 这是 n-gram 模型的核心优化手段。因为训练语料无法覆盖所有词组合,会出现 "未登录的 n-gram 序列",Kneser-Ney 平滑通过折扣概率 + 回退机制,为未见过的词组合分配合理概率,避免模型输出概率为 0 的情况,提升模型鲁棒性。
语言模型工具:SRI Language Modeling Toolkit (SRILM)
- SRILM 是语音识别领域经典的开源语言模型工具包,支持 n-gram 模型的训练、平滑、评估等全流程操作,被广泛用于学术研究和工业实践,选择该工具包保证了实验的可复现性。
词汇层配置:15 万词表 + 自动 G2P 转换
- G2P( grapheme-to-phoneme,字素转音素)规则
作用是自动为词表中的每个单词生成音素序列 :- 无需人工标注每个单词的发音,大幅降低标注成本;
- 保证音素转录的一致性,让声学模型的 "音素 - 特征" 映射学习更稳定;
- 对于俄语这类拼写和发音关联性较强的语言,基于规则的 G2P 就能达到较高的准确率。
G2P 管 "单词怎么拆成音素",状态对齐管 "语音帧怎么对应音素的声学状态",前者是词汇层的 "静态映射",后者是声学层的 "动态时序匹配"。
GMM-HMM 模型的优化
GMM-HMM 的实验结果汇总在表 1 中,表格包含核心指标 WER、不同模型变体(如单音子 / 三音子 / LDA+MLLT 版本)的对比数据

- 模型优化趋势:随着 GMM-HMM 模型的逐步升级(从基础三音子到 LDA/MLLT 特征优化,再到 fMLLR 说话人自适应),WER 持续降低,说明每一步的模型改进(特征增强、特征空间优化、说话人自适应)都有效提升了识别精度。
- 关键提升点:SAT_fMLLR 模型的 WER(25.32%)相比初始三音子模型(30.30%)降低了约 5 个百分点,体现了说话人自适应对模型泛化能力的显著改善,这也是后续 DNN-HMM 模型训练的关键基线。
网络结构对俄语语音识别性能的影响
- 实验的变量是 隐藏层的单元数(神经元数量),同时搭配了 3--5 层的隐藏层设计,属于典型的网络结构超参数搜索。
- 目的:找到 "层数 - 单元数" 的最优组合 ------ 层数和单元数过少会导致模型拟合能力不足,过多则会增加计算量并容易过拟合。
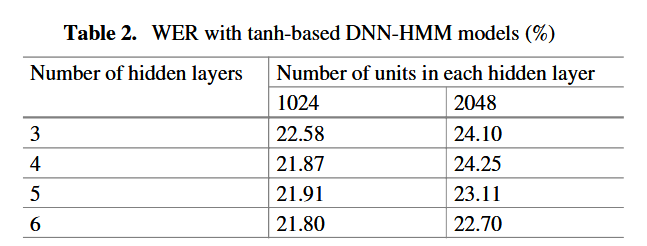
tanh 激活函数的 DNN 配置
- 激活函数:使用 tanh 函数
- 网络规模:
- 隐藏层层数:3~5 层,属于中等深度的神经网络(过深的网络在语音识别中容易出现梯度消失,且训练成本高)。
- 每层单元数:1024~2048 个,这个规模能保证模型有足够的拟合能力,同时适配俄语语音的声学特征复杂度。
-
在 3--5 层的基础上增加到 6 层时,模型性能没有出现明显波动,说明层数不是该实验中影响识别效果的关键因素。
-
适度增加层数(从 5 层到 6 层) + 适中的单元数(1024) 能达到最佳的拟合效果,既不会因模型过小导致欠拟合,也不会因模型过大增加训练负担。
-
当每层隐藏单元数从 1024 增加到 2048 时,词错误率(WER)反而上升。
- 核心原因:训练数据量不足。
- 更多的隐藏单元意味着模型的参数规模大幅增加,而有限的训练数据无法充分 "喂饱" 大模型,导致模型出现过拟合------ 在训练集上表现良好,但在测试集上的泛化能力下降,最终体现为 WER 升高。
p-norm DNN 模型的独特参数设计
-
传统 DNN(如 tanh-DNN)用 "隐藏层层数 + 每层单元数" 定义结构;而 p-norm DNN 抛弃了 "隐藏层维度" 的说法,改用 "p-norm 输入维度" 和 "p-norm 输出维度" 两个核心参数。
-
这是因为 p-norm 激活函数的计算逻辑是 对一组输入神经元进行归一化,再输出到下一层,其结构设计天然围绕 "输入组大小" 和 "输出组大小" 展开。
-
输入维度必须是输出维度的整数倍,目的是让输入神经元可以被均匀划分为若干小组,每个小组对应一个输出神经元的 p-norm 计算。
举个例子
- 输入层的特征维度:假设输入层是 40 维的声学特征(比如每帧 40 维 fMLLR 特征)。
- 第 1 隐藏层的输入 / 输出维度设计
- 我们希望第 1 隐藏层的神经元数量(即 p-norm 输出维度)是 200。
- 按 10:1 的比例约束,需要让输入维度 = 200×10=2000。
- 因此,输入层到第 1 隐藏层之间会加一个 "全连接变换":把输入层的 40 维特征,通过全连接层(40→2000 的权重矩阵)映射为 2000 维的信号 ------ 这个 2000 维信号就是第 1 隐藏层的 "p-norm 输入维度"。
- 第 1 隐藏层的 p-norm 计算:把 2000 维输入分成 200 组(每组 10 个),每组做 p-norm 得到 1 个输出,最终得到 200 维的结果(即第 1 隐藏层的输出,也是下一层的输入)。
这个升维的全连接层,属于 p-norm 隐藏层的一部分,不是独立的额外层。它和后续的 p-norm 计算,共同构成了 p-norm DNN 隐藏层的完整变换逻辑。
对比传统 tanh-DNN 的隐藏层:
-
传统 DNN 隐藏层 = 全连接线性变换 + tanh 非线性激活
-
p-norm DNN 隐藏层 = 全连接升维变换 + p-norm 非线性激活
实验选择 10:1 的经典比例,对比 2000/200 和 4000/400 两种配置
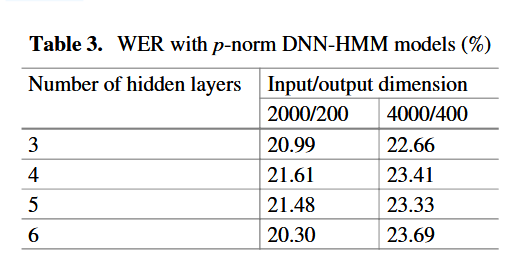
输入 / 输出维度的影响:相同层数下,2000/200 维度配置的 WER 均低于 4000/400 的情况,说明在训练数据量有限时,增大 p-norm 的输入 / 输出维度会导致模型过拟合,进而降低识别性能。
层数的影响:对于 2000/200 维度的模型,层数从 3 增加到 6 时,WER 先小幅上升后下降,最终 6 层配置取得了最低 WER(20.30%);而 4000/400 维度的模型,层数变化对 WER 的影响无明显规律,但整体性能较差。
最优结构:6 层隐藏层 + 2000/200 输入 / 输出维度的 p-norm DNN 模型,WER 低至 20.30%,是该实验中性能最优的 p-norm 配置。