目录
- 1.索引
-
- [1.1 索引的概念](#1.1 索引的概念)
- [1.2 索引需要使用什么数据结构来存储?](#1.2 索引需要使用什么数据结构来存储?)
- [1.3 页](#1.3 页)
-
- 1.为什么需要使用页这样的单位?
- [2. 页的介绍](#2. 页的介绍)
- 3.页的主体
- 4.页目录
- 5.数据页头
- [1.4 3层B+树可以存储的数据大小](#1.4 3层B+树可以存储的数据大小)
- [1.5 索引的使用](#1.5 索引的使用)
-
- [1 索引的创建](#1 索引的创建)
- [2 索引的查询](#2 索引的查询)
- [3 索引的删除](#3 索引的删除)
1.索引
1.1 索引的概念
索引在MySQL中是一种数据结构,可以帮助我们快速的定位数据库中需要查询,更新,删除的数据,更加高效的管理库中的数据。
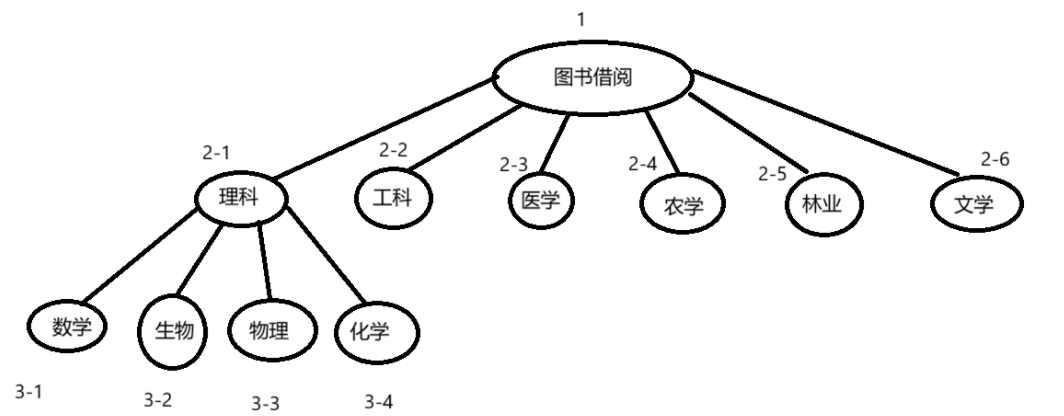
例如:在图书馆中的书籍借阅系统中,可以将书籍先划分为多个类别:理科,工科,医学,农学,林业,文学等,再将每一个类别再进行划分,例如理科:数学,物理,化学,地理,生物...由一个整体划分为多个部分,一直细化,在每一层的划分中就可以使用索引来进行标记,快速定位到需要查询的书籍。
1.2 索引需要使用什么数据结构来存储?
1.Hash表
索引的使用是为了查找时可以更加快速的获取到查询的信息,在数据结构中哈希表的查询可以达到O(1),但是在索引中需要查找大量的数据,并且需要支持范围查询,Hash表是通过键值对(key -val )来查找键值,并不支持范围查询,所以索引的数据结构并不是使用Hash表。
2.二叉搜索树
二叉搜索树的中序遍历是有序的,虽然在给定范围内可以查找到数据,但是存在几个问题:
(1)二叉索树在最坏情况下的时间复杂度是O(N)(退化退单枝)。
(2)二叉索树树的节点个数太多无法保证树的高度;二叉树搜索树某一个节点查询其子节点需要一次硬盘IO的读取,IO读取是性能的瓶颈,在最坏情况下读取n次,会导致性能下降,因此索引的数据结构不使用二叉搜索树。
3.N叉搜索树 & B+树
为了解决树高度问题引入N叉树,在相同节点下,N叉树的树高可以得到有效控制。
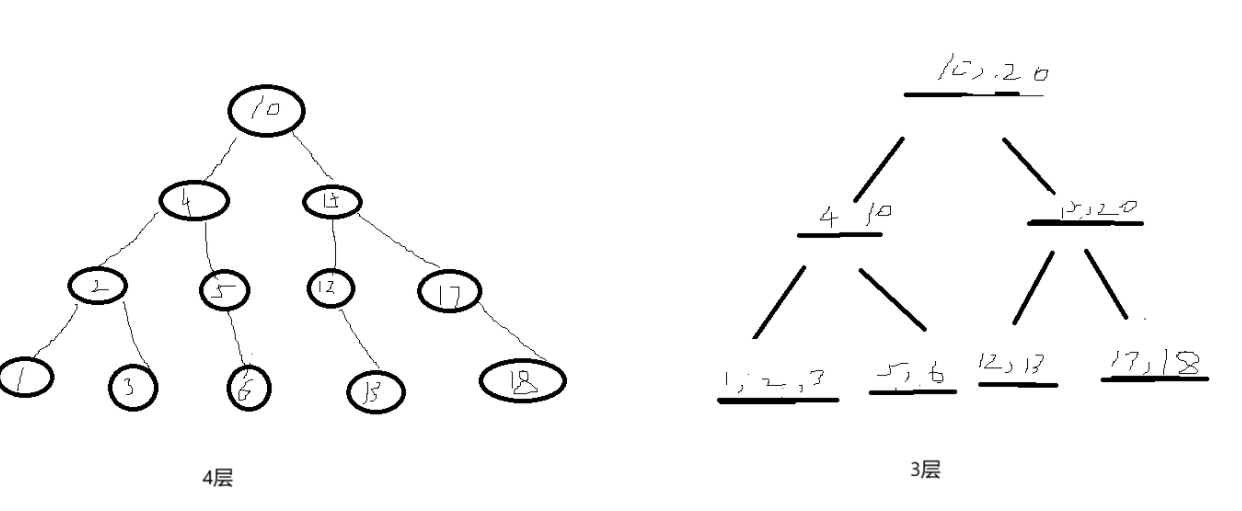
N叉树的每一个节点可以存储多个值,每一个值又可以划分为N个区间,可以支持范围查询。在N叉搜索树的基础上做进一步优化得到B+树。
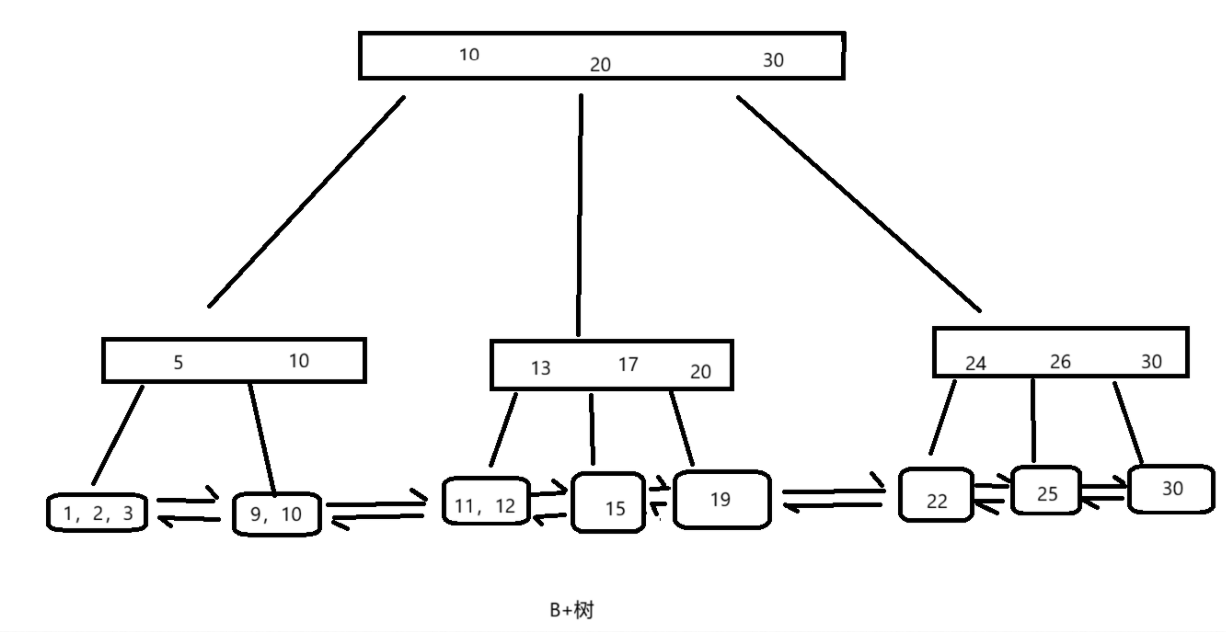
B+树有几个特点:
1)每一个节点都有N个节点值,每一个节点值又可以分支出N个分支;
2)父亲节点的节点值在子节点中以最大值的方式出现;
3)叶子节点使用链表连接;
4)非叶子节点存储索引列,叶子节点存储数据行。
B+树的优点:
1)B+树是一棵N叉搜索树,高度较低,查询时需要IO相对有限;
2)数据行都是存储在叶子节点,每一次查询读取的次数是固定的;
3)叶子节点使用链表连接,非常适合范围查询;
4)非叶子节点只需要存储"索引列''(id),占据的空间比较小,可以通过内存缓存,减少IO读取次数。
在MySQL中索引使用的数据结构是B+树,可以高效查询数据。
1.3 页
MySQL中的页是内存和硬盘交互的最小单位,默认大小是16Kb,可以使用以下语句查询。
sql
# 查询页大小变量 16kb = 163684 byte
show variables like 'innodb_page_size'; 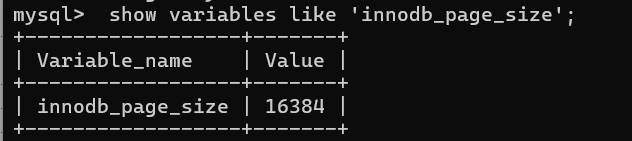
1.为什么需要使用页这样的单位?
根据局部性原理:当前正在查询的数据在下一时刻很有可能继续使用(时间局部性原理);当前正在访问的数据与下一次需要访问的数据的地址很可能是相邻的(空间局部性原理),所以为了在空间和时间上尽可能的利用,引入页的概念。
2. 页的介绍
在B+树中每一个节点都是一个页:非叶子节点为索引页 ,叶子节点为数据页 。MySQL创建的数据默认存储在以下路劲中:C:\ProgramData\MySQL\MySQL Server 8.0\Data(8.0是版本号,具体以使用的版本号为主),可以看到创建的数据库,打开数据库可以看到表的信息

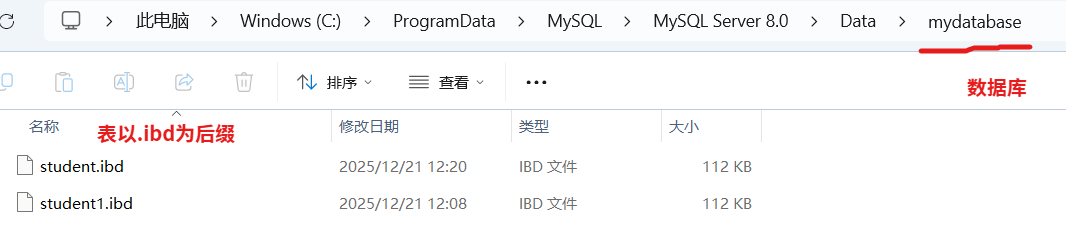
MySQL创建的表格数据都是以.idb为后缀的,每一个表中又包含多个页。
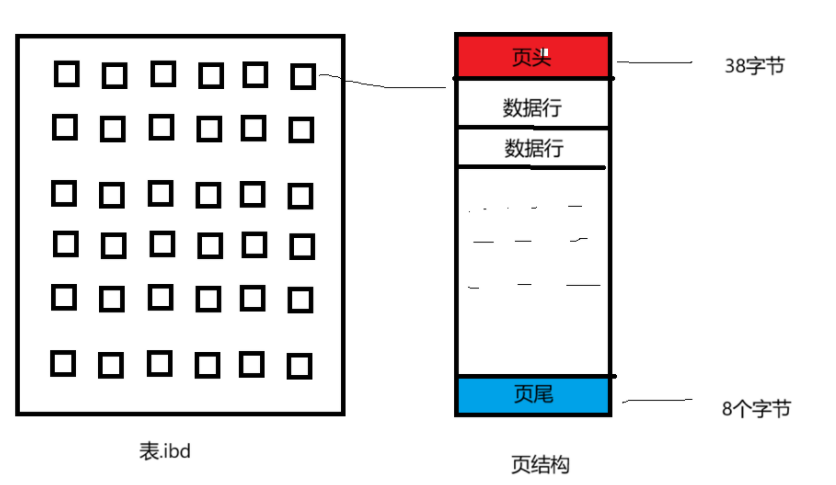
页头中包含上一页和下一页的页数,方便页数的起始计数。
3.页的主体
在创建页时会创建一行来记录最大行supermun和最小行infimun的信息,记录真实数据行的范围,数据行中有一个record_next,用来记录下一数据行的位置。数据行以单链表的形式组织,当新的数据行插入,与单链表的插入类似进行修改。
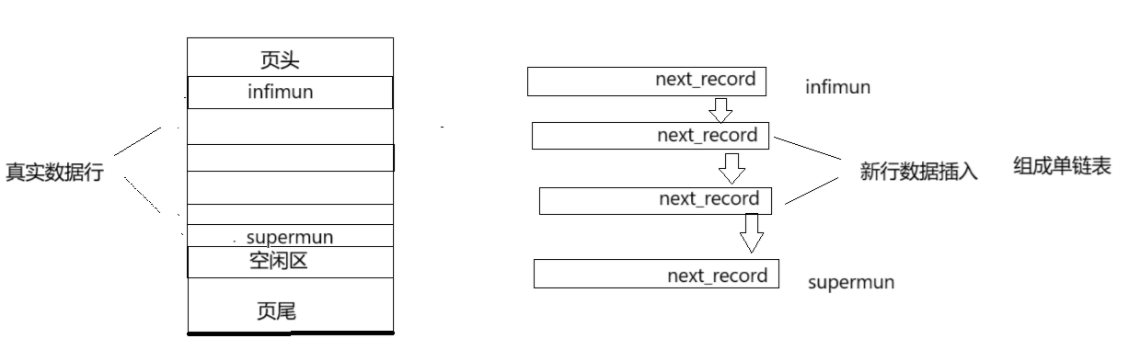
4.页目录
页中有一行用来存储目录信息,在数据行中每一行都有一个id,将这样id每8个为一组作为一个槽,每一个槽按照从小到大编号,存储目录信息的行对应存储的就是一个一个的槽,需要查找页中的某一条数据,可以先二分查找到对应的槽,再到槽中查找数据行id。
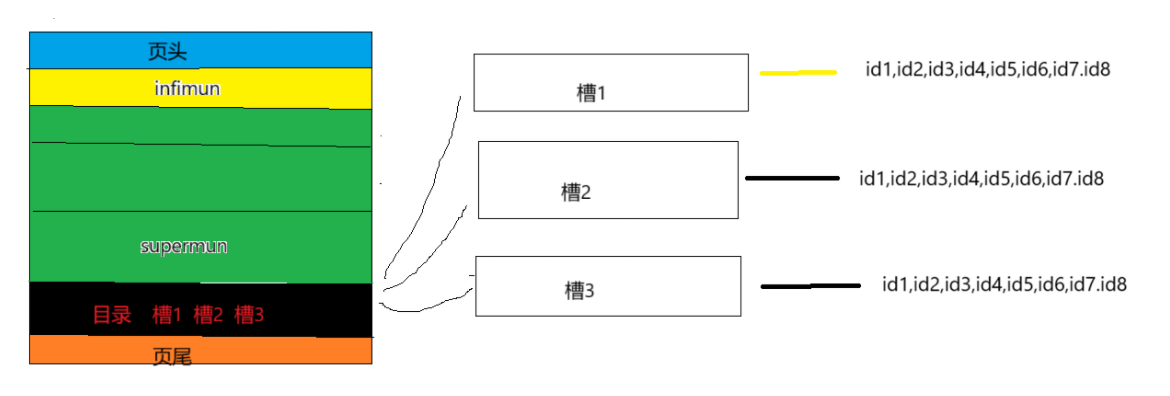
5.数据页头
数据页头中会记录一些,统计信息,事务信息,位置信息。最终页的结构大致如下。

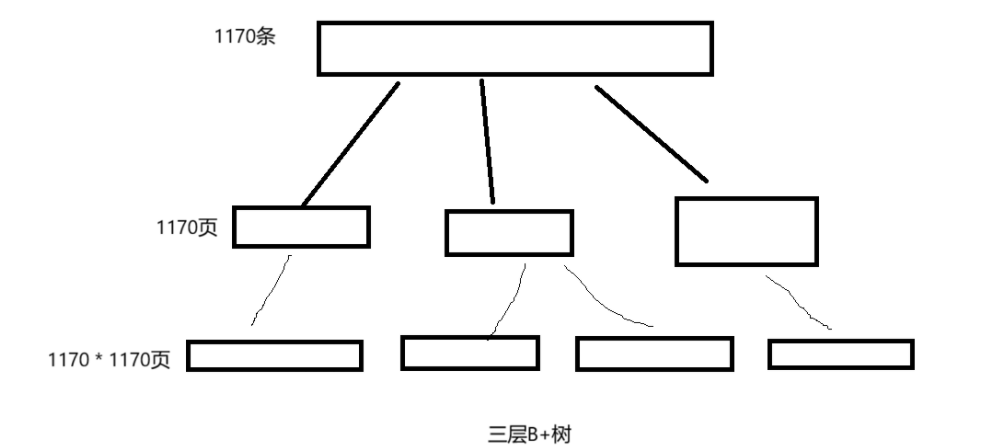
1.4 3层B+树可以存储的数据大小
通过以上页的基本介绍,可以了解到页有页头 + 页尾 + 数据页头 + (最大行 + 最小行)+ 数据行 +页目录组成,页的大小为16kb,为了简化计算,可以忽略页头和页尾的大小(38 + 8 = 46字节),其它行以 id + record_next构成计算,主键ID为8字节,record_next为6个字节,一行数据大小为14个字节。
1.索引页中可以存储的的行数为:16 * 1024 * 1024 / 14 = 1170(行)
一个索引页可以分为1170行,所以在第二层中可以分为1170页,依次类推,第三层中可以分为1170 * 1170页。
2.假设第三层数据行一条数据存储的大小为1kb,三层B+树可以存储的数据行为:1070 * 1070 * 16 = 21,902,400(条)
1.5 索引的使用
主键索引:被primary key修饰的列为主键索引,又称聚焦索引。
普通索引:没有被unique修饰的索引。
唯一索引:被unique修饰的索引。
全文索引:基于行文本(被char,varchar,text)修饰的列。
非聚焦索引:又称二级索引,包行主键索引和非聚集索引对应的列,查询时通过非聚焦索引先找到主键索引,有主键索引找到非聚焦索引对应的列,这一个过程又称回表查询;
索引覆盖:查找的索引是普通索引,返回普通索引查询的结果,不需要主键索引查询。
1 索引的创建
主键索引的创建
sql
# 方式一:
create table test1(
id int primary key AUTO_INCREMENT,## 手动创建
name char(20)
)
# 方式二:
create table test1(
id int,## 手动创建
name char(20),
primary key(id) # 指定创建
)
# 方式三:
create table test1(
id int,
name char(20)
)
alter table test1 add primary key(id); ## 表格创建后指定主键唯一索引的创建
sql
# 方式一:
create table test1(
id int unique,## 手动创建
name char(20)
)
# 方式二:
create table test1(
id int,
name char(20),
unique(id) # 指定创建
)
# 方式三:
create table test1(
id int,
name char(20)
)
alter table test1 add unique(id); ## 表格创建后指定唯一索引列普通索引的创建
sql
# 方式一:
create table test1(
id int,
name char(20),
index(id) # 增加普通索引
)
# 方式二:
create table test1(
id int,
name char(20)
)
alter table test1 add index(id); ## 表格创建后指定普通索引列
# 方式三:
create table test1(
id int,
name char(20)
)
create index index_id on test1(id); # 创建普通索引并命名2 索引的查询
sql
# 方式一
show index form table_name;
# 方式二
desc table_name;
sql
# 创建表
create table test2(
id int PRIMARY key,
name char(20 )unique,
age int
)
create index age_index on test2(age); # 指定普通索引使用方式一查询
sql
show index from test2;
使用方式二查询
sql
desc test2;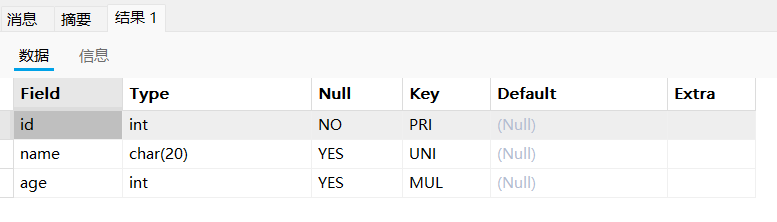
age字段对应的key为mul(multiple key),表示的是非唯一索引,即普通索引。
3 索引的删除
sql
create table test3(
id int primary key auto_increment, # 主键索引
name char(20) unique, # 唯一索引
a int,
index(a) # 普通索引
);删除主键索引
sql
# 删除主键
alter table test3 drop primary key;执行以上语句会出现报错,原因是因为自增主键索引不能直接删除

删除自增主键索引需要先将自增特性修改后才可删除。
sql
alter table test3 modify id int; # 修为int 原本为int auto_increment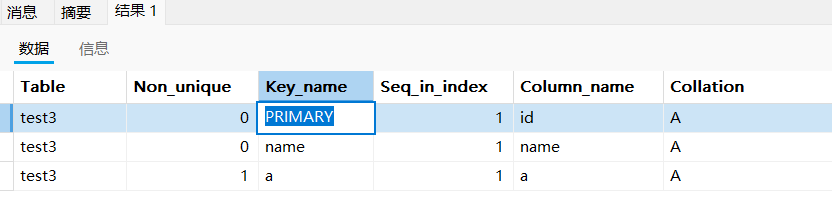
执行删除主键索引:主键索引被删除。
sql
alter table test3 drop primary key;
执行删除其它索引:
sql
# 删除唯一索引 和普通索引
alter table test3 drop index name;
alter table test3 drop index a;
# 错误删除
alter table test drop name; # 直接删除列删除后的表格索引:不存在索引。
以上就是有关M有SQL中索引的介绍,如果有相关疑问,欢迎留言讨论,我们下一篇文章,再见!