文章目录
- 1.BERT模型微调
-
- [1.首先设置huggingface 环境变量](#1.首先设置huggingface 环境变量)
- [2. 本次demo用到的模型和数据集](#2. 本次demo用到的模型和数据集)
- [3. 代码](#3. 代码)
- 4.sentiment_model本地训练模型和bert对比
1.BERT模型微调
1.首先设置huggingface 环境变量
这样存储的模型和数据集会下载到指定路径
bash
setx HF_HOME D:\langChain\huggingface 2. 本次demo用到的模型和数据集
(1)需要下载bert-base-chinese模型和lansinuote/ChnSentiCorp数据集
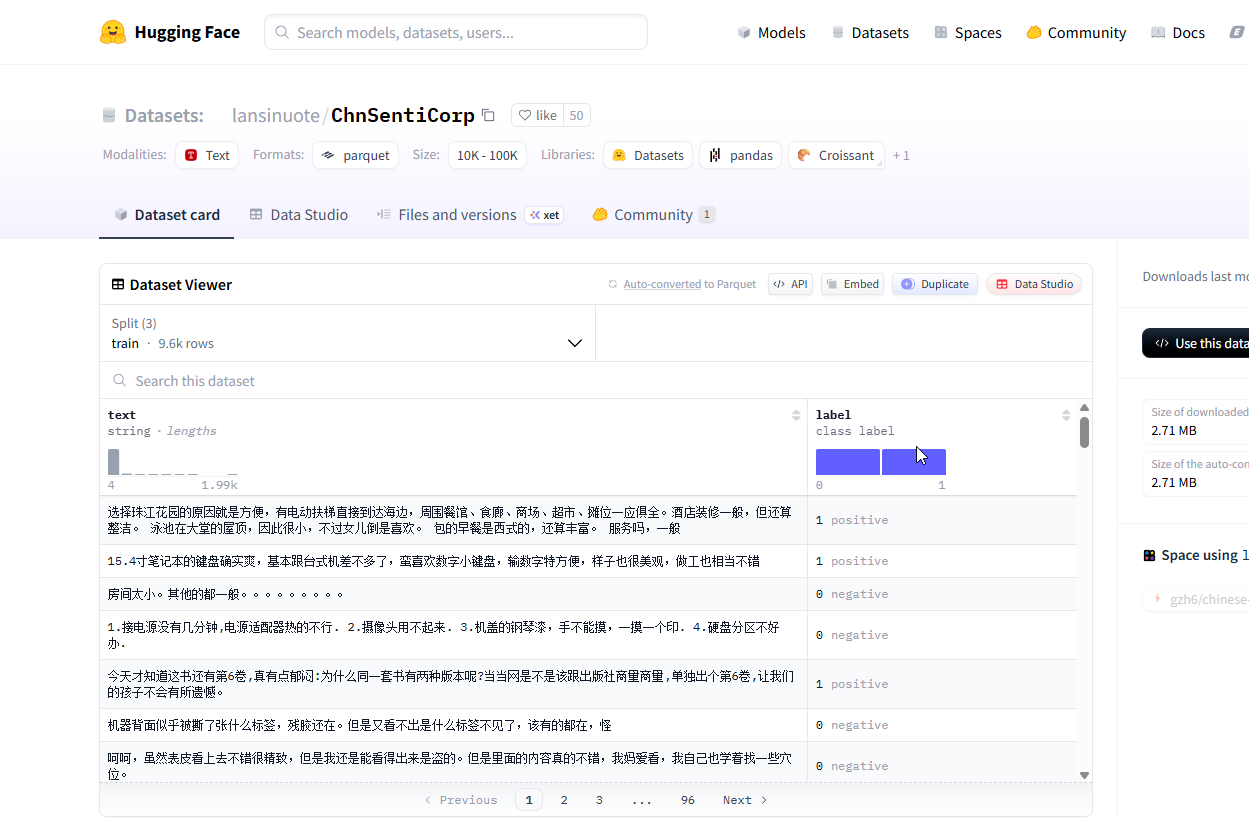
(2)模型和数据集下载行为
- bert-base-chinese 模型: 会自动下载到本地缓存目录
- lansinuote/ChnSentiCorp 数据集: 也会下载到本地缓存目录
- 缓存机制
- Hugging Face 缓存:
- 模型默认缓存路径(已经指定D盘): ~/.cache/huggingface/transformers/
- 数据集默认缓存路径(已经指定D盘): ~/.cache/huggingface/datasets/
- 下次运行时的行为:
- 优先使用本地缓存的文件
- 如果本地存在缓存,则不会重新从远程下载
- 只有在缓存不存在或损坏时才重新下载
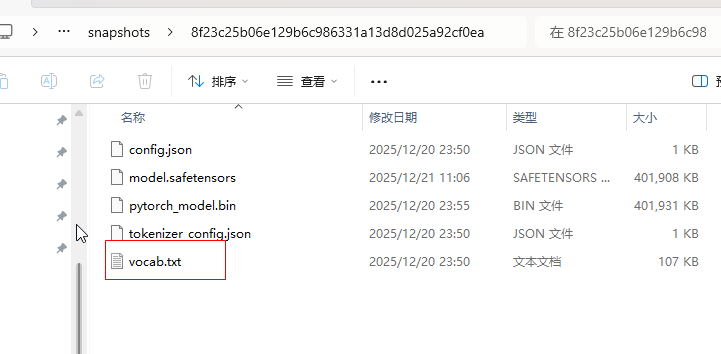
(3) bert-base-chinese 模型
模型主要是将文本转换成向量坐标,这样才能被识别,主要依赖于vocab.txt还有分词器文件tokenizer.json文件,这里新版本没有
- Hugging Face 缓存:
3. 代码
这种bert模型是开源的,不需要apikey秘钥
python
##步骤 1:环境准备
# pip install torch transformers datasets scikit-learn
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
os.environ['HF_HUB_TIMEOUT'] = '60'
from transformers import BertTokenizer, BertForSequenceClassification
##步骤 2:加载中文 BERT 预训练模型
# 加载 BERT 中文预训练模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertForSequenceClassification.from_pretrained(
'bert-base-chinese',
num_labels=3
)
##步骤 3:加载 CnnSentiCorp 数据集并进行清洗
from datasets import load_dataset
# 加载 CnnSentiCorp 数据集
# 数据集地址:https://huggingface.co/datasets/lansinuote/CnnSentiCorp
# 验证数据集是否存在
try:
dataset = load_dataset("lansinuote/ChnSentiCorp")
except Exception as e:
print(f"数据集加载失败: {e}")
# 使用备用数据集或本地数据
import re
# 定义数据清洗函数
def clean_text(text):
text = re.sub(r'[^\w\s]', '', text) # 去除标点符号
text = text.strip() # 去除前后空格
return text
# 对数据集中的文本进行清洗
dataset = dataset.map(lambda x: {'text': clean_text(x['text'])})
# 步骤 4:数据预处理
def tokenize_function(examples):
return tokenizer(examples['text'], padding='max_length', truncation=True, max_length=128)
# 对数据集进行分词和编码
encoded_dataset = dataset.map(tokenize_function, batched=True)
# 步骤 5:训练模型
from transformers import Trainer, TrainingArguments
# 定义训练参数
# 定义训练参数,创建一个TrainingArguments对象
training_args = TrainingArguments(
output_dir='D:\\langChain\\data\\results', # 指定训练输出的目录,用于保存模型和其他输出文件
num_train_epochs=1, # 设置训练的轮数,这里设置为1轮
per_device_train_batch_size=1, # 每个设备(如GPU)上的训练批次大小,这里设置为1
per_device_eval_batch_size=1, # 每个设备上的评估批次大小,这里设置为1
evaluation_strategy="epoch", # 设置评估策略为每个epoch结束后进行评估
logging_dir='D:\\langChain\\logs', # 指定日志保存的目录,用于记录训练过程中的日志信息
)
# 使用 Trainer 进行训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=encoded_dataset['train'],
eval_dataset=encoded_dataset['validation'],
)
# 开始训练
trainer.train()
#{'loss': 0.7493, 'grad_norm': 31.590713500976562, 'learning_rate': 1.35416666666666666-05, 'epoch': 0.73}
# 步骤 6:评估模型性能
from sklearn.metrics import accuracy_score
# 定义评估函数
def compute_metrics(p):
preds = p.predictions.argmax(-1)
return {'accuracy': accuracy_score(p.label_ids, preds)}
# 在测试集上评估模型
trainer.evaluate(encoded_dataset['test'], metric_key_prefix="eval")
# {'eval_loss': 0.2, 'eval_accuracy': 0.85}
# eval_loss: 0.2: 这是模型在测试集上的损失值。
# 损失值是一个衡量模型预测与实际标签之间差异的指标。
# 较低的损失值通常表示模型的预测更接近于真实标签。
# eval_accuracy: 0.85: 这是模型在测试集上的准确率。
# 准确率是指模型正确预测的样本数量占总体本数量的比例。
# 在这个例子中,准确率为 0.85,意味着模型在测试集上有 85% 的样本被正确分类。
# 步骤 7: 导出模型
# 保存模型和分词器
model.save_pretrained('D:\\langChain\\data\\sentiment_model')
tokenizer.save_pretrained('D:\\langChain\\data\\sentiment_model')output_dir='D:\\langChain\\data\\results', # 指定训练输出的目录,用于保存模型和其他输出文件
用CPU训练了一下午,有条件直接上GPU
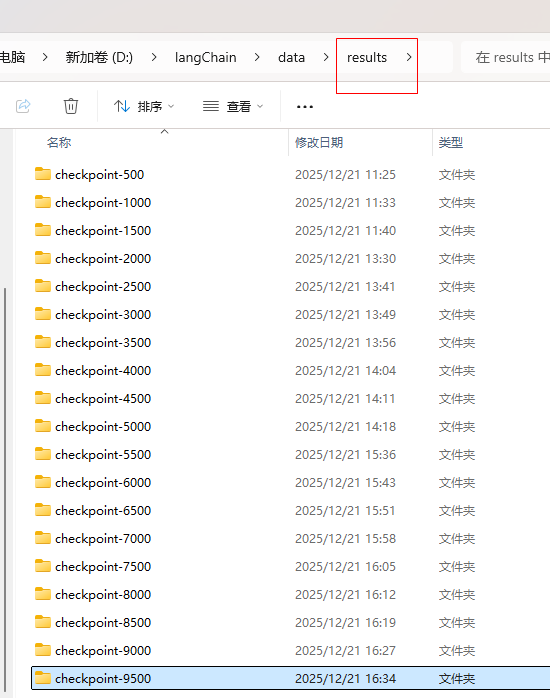
运行完代码就会生成本地的model训练模型,存储在sentiment_model目录,这个模型结构和下载的bert模型结构一样,如果训练次数越多,那么本地的sentiment_model模型性能应该会比bert模型强
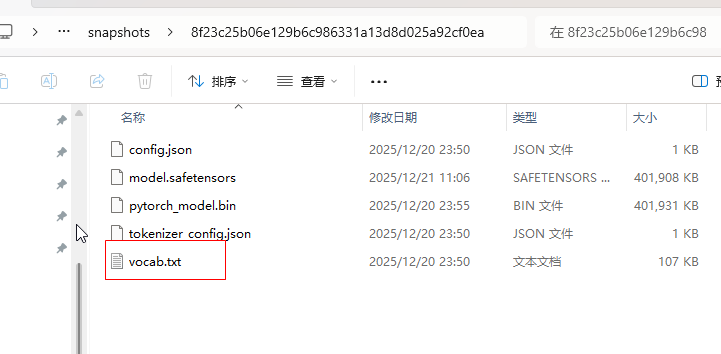
(1)bert模型结构
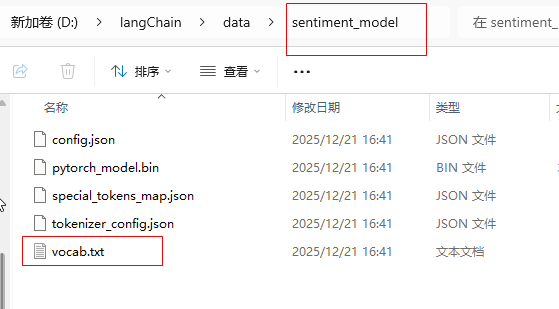
(2)sentiment_model本地模型
4.sentiment_model本地训练模型和bert对比
python
from transformers import AutoModelForSequenceClassification, AutoTokenizer, pipeline
# 设置具体包含 config.json 的目录
#官方模型
#model_dir = r"D:\langChain\huggingface\hub\models--bert-base-chinese\snapshots\8f23c25b06e129b6c986331a13d8d025a92cf0ea"
#本地训练模型
model_dir = r"D:\langChain\data\sentiment_model"
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForSequenceClassification.from_pretrained(model_dir)
# 创建文本分类管道
classifier = pipeline("text-classification", model=model, tokenizer=tokenizer)
# 测试示例
result = classifier("这个电影非常好看,我很喜欢!")
print(result)
# LABEL_0:在二分类情感分析任务中,0 通常表示"负面"情感。
# LABEL_1:相应地,1 通常表示"正面"情感。
output = classifier("我今天心情很好")
print(output)
# [{'label': 'LABEL_1', 'score': 0.5915976762771606}]
output = classifier("你好,我是AI助手")
print(output)
# [{'label': 'LABEL_1', 'score': 0.5109264254570007}]
output = classifier("我今天很生气")
print(output)
# [{'label': 'LABEL_1', 'score': 0.6152875423431396}]本地模型结果
[{'label': 'LABEL_0', 'score': 0.579810619354248}]
[{'label': 'LABEL_0', 'score': 0.5798107981681824}]
[{'label': 'LABEL_0', 'score': 0.5798106789588928}]
[{'label': 'LABEL_0', 'score': 0.5798109173774719}]bert模型结果
[{'label': 'LABEL_1', 'score': 0.7983449697494507}]
[{'label': 'LABEL_1', 'score': 0.7800017595291138}]
[{'label': 'LABEL_1', 'score': 0.8223720788955688}]
[{'label': 'LABEL_1', 'score': 0.7756355404853821}]