动态字符串SDS
动态字符串源码实现
Redis是C语言实现的,其中SDS是一个结构体,源码如下:
c
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* buf已保存的字符串字节数,不包含结束标示*/
uint8_t alloc; /* buf申请的总的字节数,不包含结束标示*/
unsigned char flags; /* 不同SDS的头类型,用来控制SDS的头大小
char buf[];
};其中 __attribute__表示Clang编译器的扩展属性,给结构体附加编译特性。((__packed__))是 __attribute__的具体属性,表示:取消结构体成员的自动内存对齐,让成员按照实际字节紧密排列 。其中结构体的钱三个属性代表了头,也就是对应的当前字符串长度,当前申请的字节数,当前的类型。
类型:就是名称中对应的也就是表示对应的不同长度的可变动态数组。也就是对应的len取值的不同。
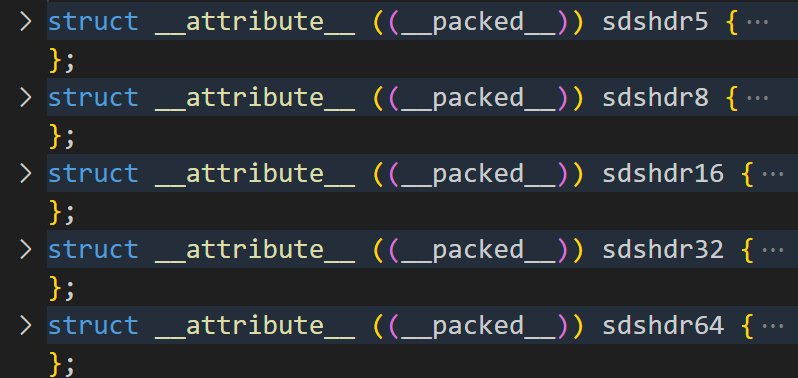
对应的类型:不同的类型代表长度上限不同的字符串。
c
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4动态字符串内存预分配(扩容)
动态字符串其具有动态扩容能力,如果需要申请新的内存空间:
如果字符串小于1MB,那么新空间为扩展后的字符串长度的两倍+1
如果字符串大于1MB,那么新空间为扩展后的字符串长度的+1MB+1,成为内存预分配。
动态字符串的优势
获取字符串长度的时间复杂度为O(1)
支持动态扩容
减少内存分配次数
二进制安全
整数集合IntSet
IntSet底层原理
IntSet是Redis中set集合的一种实现方式,基于整数数组来实现,并且具备长度可变、有序等特征。
c
typedef struct intset {
uint32_t encoding; /* 编码方式,支持存放16位、32位、64位整数*/
uint32_t length; /* 元素个数 */
int8_t contents[]; /* 整数数组,保存集合数据*/
} intset;
/* Note that these encodings are ordered, so:
* INTSET_ENC_INT16 < INTSET_ENC_INT32 < INTSET_ENC_INT64. */
#define INTSET_ENC_INT16 (sizeof(int16_t)) /* 2字节整数,范围类似java的short*/
#define INTSET_ENC_INT32 (sizeof(int32_t)) /* 4字节整数,范围类似java的int */
#define INTSET_ENC_INT64 (sizeof(int64_t)) /* 8字节整数,范围类似java的long */contents数组存储的并不是实际存储内容,而是存储的指向了数组的第一个地址,八字节无符号整数就是对应的地址。但是为了方便对于数据的查找。下图中黑框中表示的寻址公式。

如果对应的存储的数据超出了当前的编码方式,那么就会对数组进行扩容。
现在,假设有一个intset,元素为{5,10,20},采用的编码是INTSET_ENC_INT16,则每个整数占2字节:
我们向该其中添加一个数字:50000,这个数字超出了int16_t的范围,intset会自动升级编码方式到合适的大小。
以当前案例来说流程如下:
① 升级编码为INTSET_ENC_INT32, 每个整数占4字节,并按照新的编码方式及元素个数扩容数组
② 倒序依次将数组中的元素拷贝到扩容后的正确位置
③ 将待添加的元素放入数组末尾
④ 最后,将inset的encoding属性改为INTSET_ENC_INT32,将length属性改为4
新增元素流程:
c
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
uint8_t valenc = _intsetValueEncoding(value);// 获取当前值编码
uint32_t pos; // 要插入的位置
if (success) *success = 1;
// 判断编码是不是超过了当前intset的编码
if (valenc > intrev32ifbe(is->encoding)) {
// 超出编码,需要升级
return intsetUpgradeAndAdd(is,value);
} else {
// 在当前intset中查找值与value一样的元素的角标pos
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0; //如果找到了,则无需插入,直接结束并返回失败
return is;
}
// 数组扩容
is = intsetResize(is,intrev32ifbe(is->length)+1);
// 移动数组中pos之后的元素到pos+1,给新元素腾出空间
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);
}
// 插入新元素
_intsetSet(is,pos,value);
// 重置元素长度
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}如果当前插入的数会导致数组的属性扩容,那么插入的数要么是一个正数比当前所有的数据都要大,要么是一个负数比当前所有数据都更小。由于集合中所有的数据都是排序的所以扩容后插入的数,只会插入到集合的头部 或者是集合的尾部。
编码升级流程:
c
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
// 获取当前intset编码
uint8_t curenc = intrev32ifbe(is->encoding);
// 获取新编码
uint8_t newenc = _intsetValueEncoding(value);
// 获取元素个数
int length = intrev32ifbe(is->length);
// 判断新元素是大于0还是小于0 ,小于0插入队首、大于0插入队尾
int prepend = value < 0 ? 1 : 0;
// 重置编码为新编码
is->encoding = intrev32ifbe(newenc);
// 重置数组大小
is = intsetResize(is,intrev32ifbe(is->length)+1);
// 倒序遍历,逐个搬运元素到新的位置,_intsetGetEncoded按照旧编码方式查找旧元素
while(length--) // _intsetSet按照新编码方式插入新元素
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));
/* 插入新元素,prepend决定是队首还是队尾*/
if (prepend)
_intsetSet(is,0,value);
else
_intsetSet(is,intrev32ifbe(is->length),value);
// 修改数组长度
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}查找目标值:使用二分查找,因为当前的IntSet是有序的。
c
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;
int64_t cur = -1;
/* The value can never be found when the set is empty */
if (intrev32ifbe(is->length) == 0) {
if (pos) *pos = 0;
return 0;
} else {
/* Check for the case where we know we cannot find the value,
* but do know the insert position. */
if (value > _intsetGet(is,max)) {
if (pos) *pos = intrev32ifbe(is->length);
return 0;
} else if (value < _intsetGet(is,0)) {
if (pos) *pos = 0;
return 0;
}
}
while(max >= min) {
mid = ((unsigned int)min + (unsigned int)max) >> 1;
cur = _intsetGet(is,mid);
if (value > cur) {
min = mid+1;
} else if (value < cur) {
max = mid-1;
} else {
break;
}
}
if (value == cur) {
if (pos) *pos = mid;
return 1;
} else {
if (pos) *pos = min;
return 0;
}
}IntSet扩容
从源码中可以看出,IntSet的扩容,是每次插入一个便会扩容一次,并且每次扩容的长度仅为原长度+1。这与很多可变数组类的扩容思想很不相似。我们以Java中的ArrayList为例做对比,ArrayList每次触发扩容为旧容量的1.5倍, int newCapacity = oldCapacity + (oldCapacity >> 1);,这样做可以避免插入时频繁扩容。但ArrayList中数据是无序的,也就是插入的数据并不需要按照插入的内容做排序,但是IntSet不同,IntSet是按照数据内容做排序的,也就是只要插入的数据,都涉及到对应数据的复制移动。
对比两者我们会发现,ArrayList增加数据的开销主要集中在扩容上,因为扩容会造成原数组的复制,那么只需要为期分配一个大一些的空间就可以避免频繁扩容带来的性能下降。
IntSet增加数据的开销集中在插入数据后维护整体数据的有序性,那么这种情况下为其分配一个更大的空间并不能解决其问题,反而会造成内存空间的浪费。并且还需要引入容量变量和真实长度变量,并且每次需要维护这两个值,这反而又额外增加了开销。
从上述对比中可以看出,IntSet设计之初并不是为了适应频繁插入删除元素,而是使用二分查找快速查找某一元素,这就说明其场景应该是多内容查询,少增删 。
而ArrayList由于底层是数组实现,相比链表其同样使用的场景为多查询少增删,但更侧重多索引查询,少增删。
IntSet总结
适合数据量不多的查询。
Intset可以看做是特殊的整数数组,具备一些特点:
Redis会确保Intset中的元素唯一、有序
具备类型升级机制,可以节省内存空间
底层采用二分查找方式来查询
字典Dict
Redis是一个键值型(Key-Value Pair)的数据库,我们可以根据键实现快速的增删改查。而键与值的映射关系正是通过Dict来实现的。
Dict由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)
c
typedef struct dictht {
// entry数组
// 数组中保存的是指向entry的指针
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小的掩码,总等于size - 1
unsigned long sizemask;
// entry个数
unsigned long used;
} dictht;在当前的源码中可以看出,在Hash冲突时使用的是拉链法。
c
typedef struct dictEntry {
void *key; // 键
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; // 值
// 下一个Entry的指针
struct dictEntry *next;
} dictEntry;当我们向Dict添加键值对时,Redis首先根据key计算出hash值(h),然后利用 h & sizemask来计算元素应该存储到数组中的哪个索引位置。
这里的 h & sizemask 对当前的 table 数组长度取余。所以这里也需要保证数组的长度必须是2的次幂。
哈希冲突时采用头插法:

dict源码:为什么使用这个结构体,主要是为了Hash扩容。
c
typedef struct dict {
dictType *type; // dict类型,内置不同的hash函数
void *privdata; // 私有数据,在做特殊hash运算时用
dictht ht[2]; // 一个Dict包含两个哈希表,其中一个是当前数据,另一个一般是空,rehash时使用
long rehashidx; // rehash的进度,-1表示未进行
int16_t pauserehash; // rehash是否暂停,1则暂停,0则继续
} dict;Dict的扩容
Dict在每次新增键值对时都会检查负载因子(LoadFactor = used/size) ,满足以下两种情况时会触发哈希表扩容:
这里扩容会检查后台进程:
哈希表的 LoadFactor >= 1,并且服务器没有执行 BGSAVE 或者 BGREWRITEAOF 等后台进程;
哈希表的 LoadFactor > 5 ;
c
static unsigned int dict_force_resize_ratio = 5;
static int _dictExpandIfNeeded(dict *d)
{
//如果正在进行rehash就返回
if (dictIsRehashing(d)) return DICT_OK;
// 如果Hash表为空,则初始化哈希表的默认大小:4
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
// 如果used : size >= 1,那么就扩容
// 如果大于5,强制扩容
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio) &&
dictTypeExpandAllowed(d))
{
//如果扩容,就找下一个最接近 used+1 的 2^n
return dictExpand(d, d->ht[0].used + 1);
}
return DICT_OK;
}Dict收缩
Dict除了扩容以外,每次删除元素时,也会对负载因子做检查,当LoadFactor < 0.1 时,会做哈希表收缩:
c
// server.c 文件
int htNeedsResize(dict *dict) {
long long size, used;
// 哈希表大小
size = dictSlots(dict);
// entry数量
used = dictSize(dict);
// size > 4(哈希表初识大小)并且 负载因子低于0.1
return (size > DICT_HT_INITIAL_SIZE && (used*100/size < HASHTABLE_MIN_FILL));
}Dict的Rehash
Rehash相当于重新建了一张Hash表,之后将旧Hash表中的数据迁移到新Hash表中。
对于数据量较小的情况下,迁移的过程感知并不明显。但是如果数据量太大,一次rehash就可能导致主线程阻塞,所以Redis采用的是渐进式rehash,也就是迁移的过程是分多次的渐进式的来完成的。
- rehashidx 就标志着rehash的进度,也就是当前迁移到哪个Hash桶了。代码中默认是每次会迁移一个桶。也就是每次执行新增、查询、修改、删除操作时,都检查一下dict.rehashidx是否大于-1,如果是则将dict.ht0.tablerehashidx的entry链表rehash到dict.ht1,并且将rehashidx++。直至dict.ht0的所有数据都rehash到dict.ht1。
- 注意:在rehash过程中,新增操作,则直接写入ht1,查询、修改和删除则会在dict.ht0和dict.ht1依次查找并执行。这样可以确保ht0的数据只减不增,随着rehash最终为空。
Dict总结
Dict的结构:
类似java的HashTable,底层是数组加链表来解决哈希冲突
Dict包含两个哈希表,ht0平常用,ht1用来rehash
Dict的伸缩:
当LoadFactor大于5或者LoadFactor大于1并且没有子进程任务时,Dict扩容
当LoadFactor小于0.1时,Dict收缩
扩容大小为第一个大于等于used + 1的2^n
收缩大小为第一个大于等于used 的2^n
Dict采用渐进式rehash,每次访问Dict时执行一次rehash
rehash时ht0只减不增,新增操作只在ht1执行,其它操作在两个哈希表。
压缩列表 ZipList
压缩列表可以理解为数组实现的双端链表。
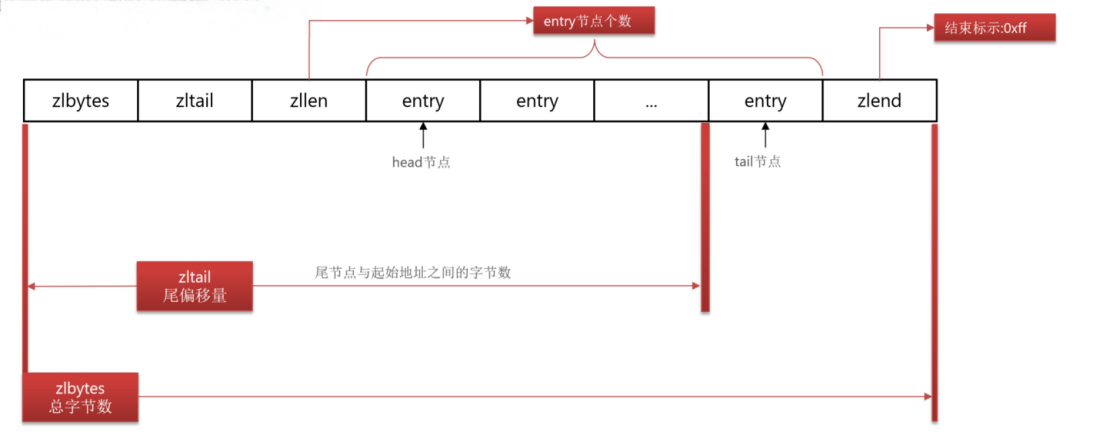
单个key,必要存储过多的数据,避免BigKey。
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
zlbytes |
uint32_t |
4B | 整个压缩列表占用的字节数,可快速释放整个内存 |
zltail |
uint32_t |
4B | 表尾节点距起始地址的偏移量(字节) |
zllen |
uint16_t |
2B | 节点数量(最大 65534;若为 65535 需遍历计算) |
entry |
可变 | 不定 | 实际数据节点,长度由内容决定 |
zlend |
uint8_t |
1B | 结束标记(固定值 0xFF) |
ZipList中的每一个Entry结构如下所示:
| previous_entry_length | encoding | content |
|---|
previous_entry_length:前一节点的长度,占1个或5个字节。ZipList是逆序遍历。
如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据
encoding:编码属性,记录content的数据类型(字符串还是整数)以及长度,占用1个、2个或5个字节
contents:负责保存节点的数据,可以是字符串或整数
注:ZipList中所有存储长度的数值均采用小端字节序,即低位字节在前,高位字节在后。例如:数值0x1234,采用小端字节序后实际存储值为:0x3412,也就是按照字节倒序存储。
字符串:如果encoding是以"00"、"01"或者"10"开头,则证明content是字符串
| 编码 | 编码长度 | 字符串大小 |
|---|---|---|
| |00pppppp| | 1 byte | ≤ 63 bytes |
| |01pppppp|qqqqqqqq| | 2 bytes | ≤ 16383 bytes |
| |10000000|qqqqqqqq|rrrrrrr|ssssssss|ttttttt| | 5 bytes | ≤ 4294967295 bytes |
整数:如果encoding是以"11"开始,则证明content是整数,且encoding固定只占用1个字节
| 编码 | 编码长度 | 整数类型 |
|---|---|---|
11000000 |
1 byte | int16_t(2 bytes) |
11010000 |
1 byte | int32_t(4 bytes) |
11100000 |
1 byte | int64_t(8 bytes) |
11110000 |
1 byte | 24位有符号整数(3 bytes) |
11111110 |
1 byte | 8位有符号整数(1 byte) |
1111xxxx |
1 byte | 直接在 xxxx 位置保存数值,范围从 0001~1101,减1后结果为实际值 |
示例:保存字符串
由于Entry中大部分都是一个字节的数据,所以当前的例子看不出小端存储。
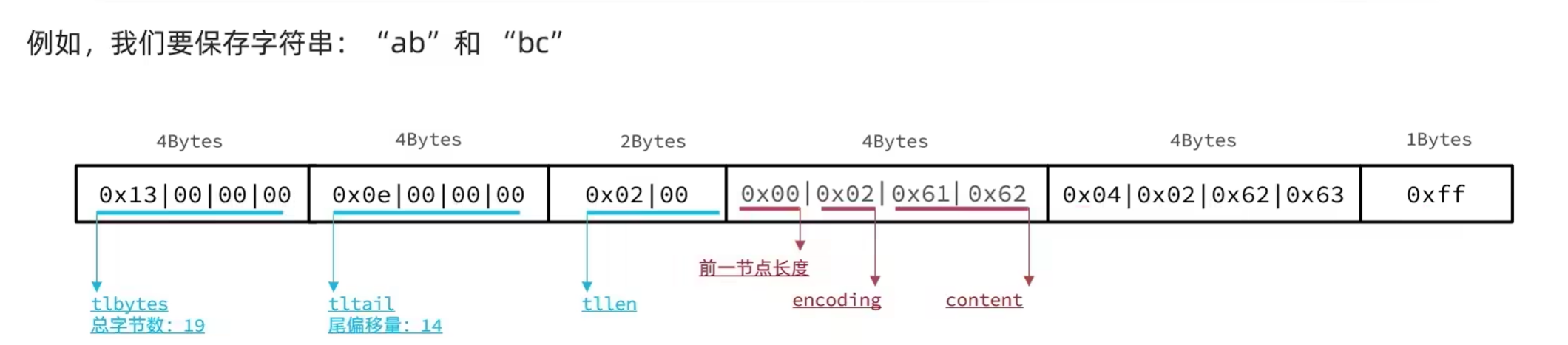
ZipList连锁更新问题
ZipList的每个Entry都包含previous_entry_length来记录上一个节点的大小,长度是1个或5个字节:
如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
如果前一节点的长度大于等于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据
现在,假设我们有N个连续的、长度为250~253字节之间的entry,因此entry的previous_entry_length属性用1个字节即可表示,如图所示:

变为

内存的增加和销毁会涉及到内核态和用户态的切换,那么带来的开销就会更大。
如果此时插入一个254字节的Entry,那么后续的各个Entry都因为前一数据的变大而更新。这种特殊情况下会产生连续多次的空间扩展称为连续更新,新增和删除都可能导致连续更新的发生。
解决:新结构ListPack(紧凑列表)
ZipList总结
ZipList特性:
压缩列表的可以看做一种连续内存空间的"双向链表"
列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较低
如果列表数据过多,导致链表过长,可能影响查询性能
增或删较大数据时有可能发生连续更新问题
QuickList
问题1:ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低。怎么办?
为了缓解这个问题,我们必须限制ZipList的长度和entry大小。
问题2:但是我们要存储大量数据,超出了ZipList最佳的上限该怎么办?
我们可以创建多个ZipList来分片存储数据。
问题3:数据拆分后比较分散,不方便管理和查找,这多个ZipList如何建立联系?
Redis在3.2版本引入了新的数据结构QuickList,它是一个双端链表,只不过链表中的每个节点都是一个ZipList。
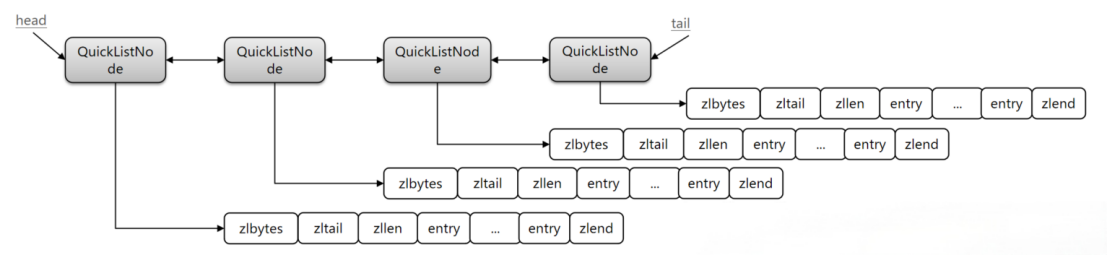
也就是相当于QuickList通过再引入一个双端链表将各个ZipList连接在一块。其中的每一个QuickListNode都存有一个ZipList。但如果ZipList中存储的数据太多势必会影响QuickList的查询性能,所有QuickList中提供了一个配置项list-max-ziplist-size来限制每个ZipList中Entry过多。
QuickList配置项
限制ZipList的Entry节点
Redis提供了一个配置项:list-max-ziplist-size来限制。
- 如果值为正,则代表ZipList允许的entry个数的最大值
- 如果值为负,则代表ZipList的最大内存大小,分5种情况:
① -1:每个ZipList的内存占用不能超过4kb
② -2:每个ZipList的内存占用不能超过8kb
③ -3:每个ZipList的内存占用不能超过16kb
④ -4:每个ZipList的内存占用不能超过32kb
⑤ -5:每个ZipList的内存占用不能超过64kb
默认值为 -2 ,也就是内存不超过 8kb。
ZipList压缩
配置项list-compress-depth
0:特殊值,代表不压缩
1:标示QuickList的首尾各有1个节点不压缩,中间节点压缩
2:标示QuickList的首尾各有2个节点不压缩,中间节点压缩
以此类推
压缩采用的是 lzf 算法
源码
QuickList源码:
c
typedef struct quicklist {
// 头节点指针
quicklistNode *head;
// 尾节点指针
quicklistNode *tail;
// 所有ziplist的entry的数量
unsigned long count;
// ziplists总数量
unsigned long len;
// ziplist的entry上限,默认值 -2
int fill : QL_FILL_BITS; // 首尾不压缩的节点数量
unsigned int compress : QL_COMP_BITS;
// 内存重分配时的书签数量及数组,一般用不到
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;QuickListNode源码
c
typedef struct quicklistNode {
// 前一个节点指针
struct quicklistNode *prev;
// 下一个节点指针
struct quicklistNode *next;
// 当前节点的ZipList指针
unsigned char *zl;
// 当前节点的ZipList的字节大小
unsigned int sz;
// 当前节点的ZipList的entry个数
unsigned int count : 16;
// 编码方式:1,ZipList; 2,lzf压缩模式
unsigned int encoding : 2;
// 数据容器类型(预留):1,其它;2,ZipList
unsigned int container : 2;
// 是否被解压缩。1:则说明被解压了,将来要重新压缩
unsigned int recompress : 1;
unsigned int attempted_compress : 1; //测试用
unsigned int extra : 10; /*预留字段*/
} quicklistNode;QuickList图示
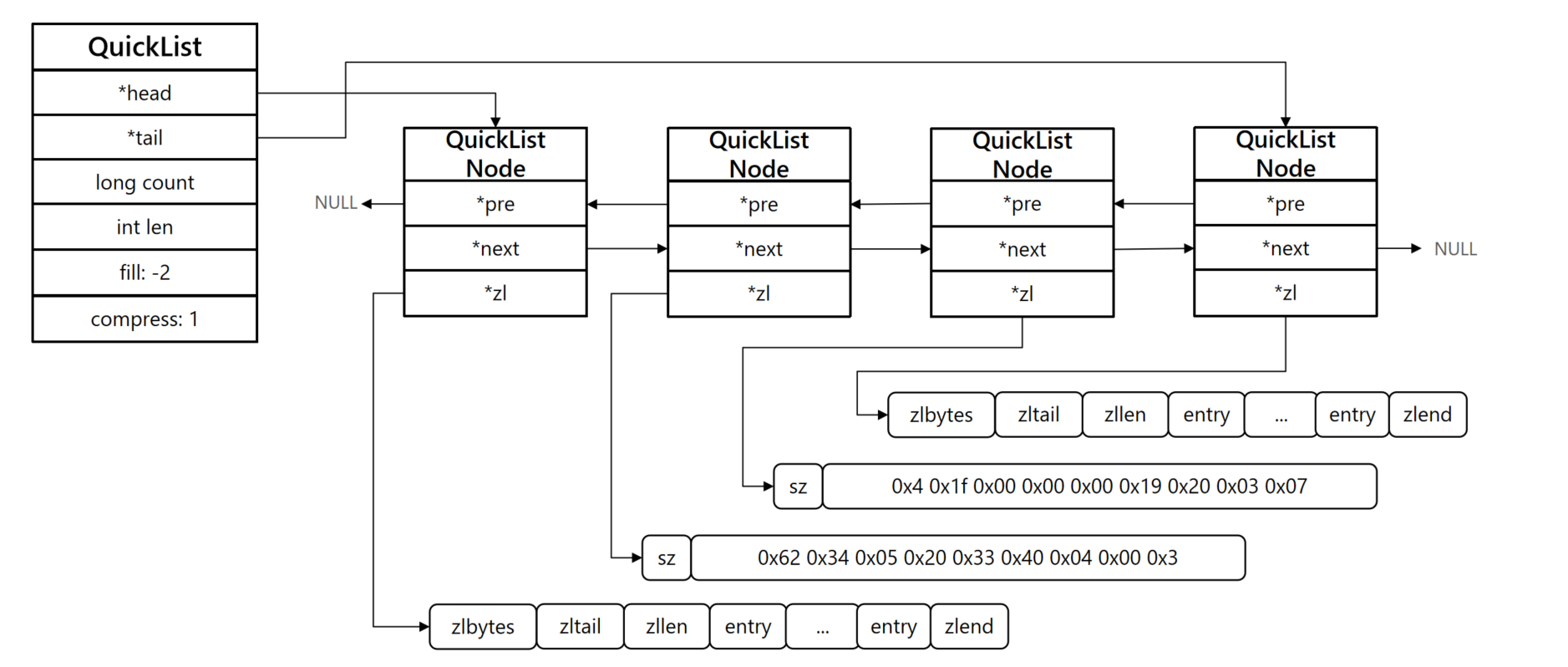
总结
是一个节点为ZipList的双向链表
节点采用ZipList,解决了传统链表的内存占用问题
控制了ZipList大小,解决连续内存空间申请效率问题
中间节点可以压缩,进一步节省了内存
SkipList
跳表是链表,但是和传统的链表相比有差异:
- 元素按照升序排序存储
- 节点可能包含多个指针,指针跨度不同
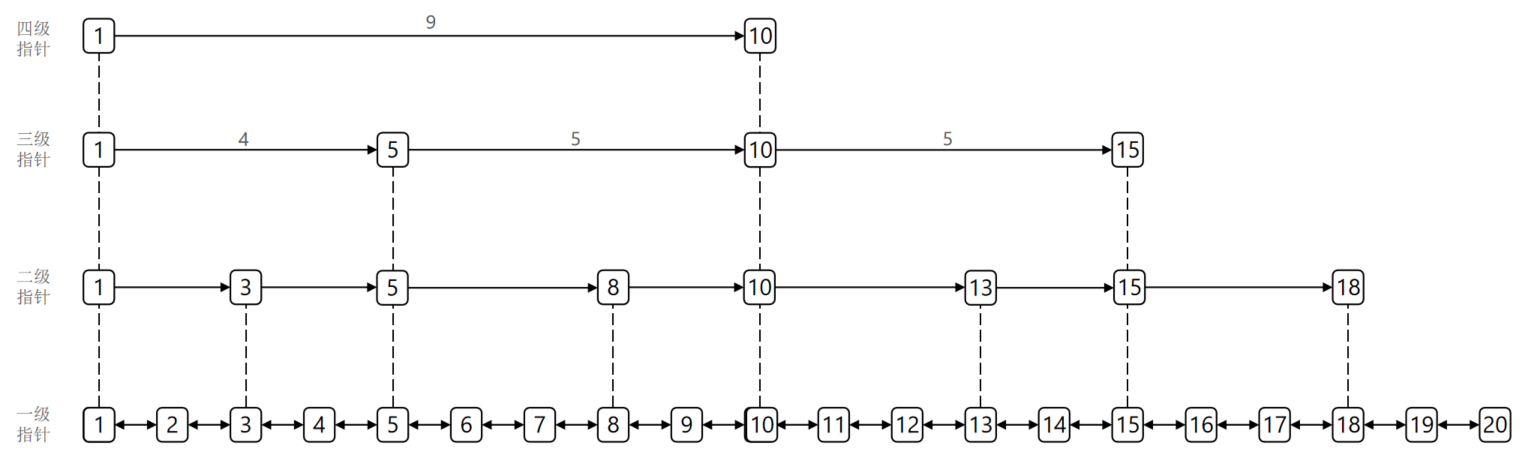
跳表源码
zskiplist 跳表
c
// t_zset.c
typedef struct zskiplist {
// 头尾节点指针
struct zskiplistNode *header, *tail;
// 节点数量
unsigned long length;
// 最大的索引层级,默认是1
int level;
} zskiplist;zskiplistNode 跳表结点
c
// t_zset.c
typedef struct zskiplistNode {
sds ele; // 节点存储的值
double score;// 节点分数,排序、查找用
struct zskiplistNode *backward; // 前一个节点指针
struct zskiplistLevel {
struct zskiplistNode *forward; // 下一个节点指针
unsigned long span; // 索引跨度
} level[]; // 多级索引数组
} zskiplistNode;实现图如下:
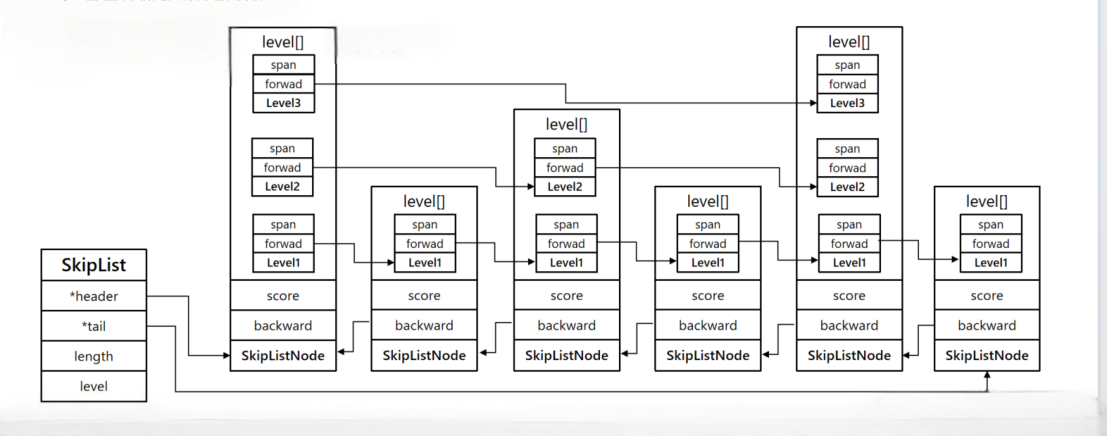
跳表总结
跳跃表是一个双向链表,每个节点都包含score和ele值
节点按照score值排序,score值一样则按照ele字典排序
每个节点都可以包含多层指针,层数是1到32之间的随机数(level)
不同层指针到下一个节点的跨度不同,层级越高,跨度越大
增删改查效率与红黑树基本一致,实现却更简单
RedisObject
Redis中的任意数据类型的键和值都会被封装为一个RedisObject
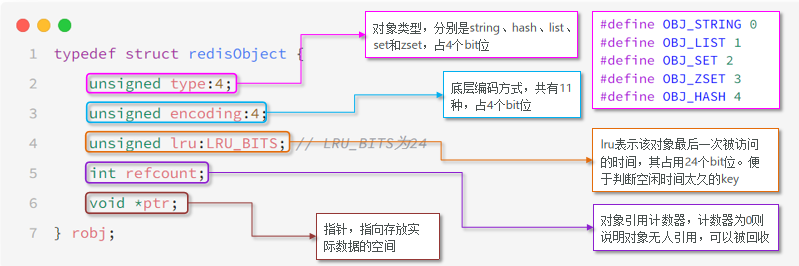
类型有五种:分别对应的这String、hash、list、set、zset
编码有11种:标注底层编码
LRU(最近最少使用算法):记录当前最近一次访问是什么时候
refcount:引用计数器,类似于Java中的内存回收
*ptr:指向存放实际数据的空间
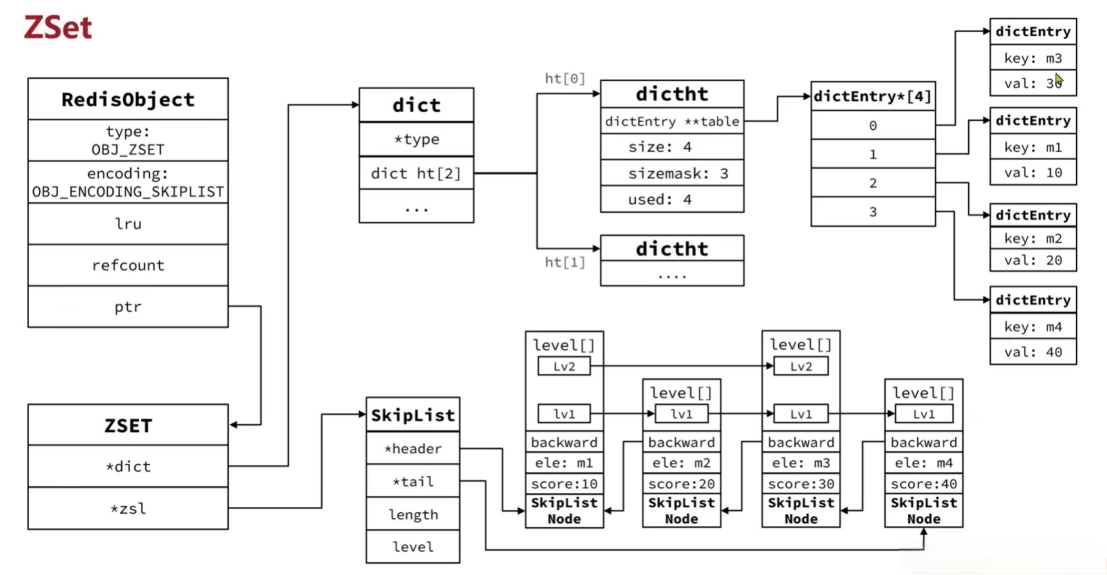
ZSet
Zset也就是SortedSet(有序集合),其中每一个元素都需要指定一个Score值和member值,可以根据Score值排序,member必须唯一,但是Score可以重复,当score相同时,Redis会按照member的字典序来排序这些元素。member相同时,Redis会将新的Score值覆盖旧的Score值。可以根据member查询分数。
所以Zset的特征:键值存储、键必须唯一、可排序。
SkipList:其可以排序,并且可以存储 Score 和 ele值。但是只能根据Score查询ele,并不能实现通过ele查询Score。
HashTable:Dict,可以键值存储,并且可以根据key找value。
底层代码如下:
c
// zset结构
typedef struct zset {
// Dict指针
dict *dict;
// SkipList指针
zskiplist *zsl;
} zset;对与ZsetObject的编码:虽然使用了两者的结合,但是仅写了一种:OBJ_ENCODING_SKIPLIST
c
robj *createZsetObject(void) {
zset *zs = zmalloc(sizeof(*zs));
robj *o;
// 创建Dict
zs->dict = dictCreate(&zsetDictType,NULL);
// 创建SkipList
zs->zsl = zslCreate();
o = createObject(OBJ_ZSET,zs);
o->encoding = OBJ_ENCODING_SKIPLIST;
return o;
}Zset内存示意图:
与B+树对比
MySQL(磁盘数据库)使用 B+ 树,而 Redis(内存数据库) 使用跳表 + Dict 的原因主要是:
首先其两者的不同在于:
① 存储介质:MySQL的存储介质为磁盘,I/O成本更高;而 Redis 使用的是内存。
② 设计目标:所有MySQL在设计时,需要减少I/O次数,让一次I/O尽可能读取更多的数据。而Redis并不考虑这些,其在设计时追求的是极致的读写性能。
③ 数据规模:磁盘数据库的数据规模一般为TB级,远超内存数据库,并且其依赖分页和缓存,但是内存数据库的数据一般为GB级,无分页开销。
所以:MySQL使用 B+ 树是为了磁盘I/O优化设计的;
B+树的非叶子节点只存储"索引键+指针",叶子节点存储完整数据并按照双向链表连接。通常单个磁盘块(4KB)可容纳更多的索引项,百万级数据也需要3-4层,也就是一次查询最多会有3-4次磁盘I/O。
这里区分几个概念:
扇区:硬件设备在出厂时定义了物理扇区大小,常见的为 512字节,现代设备多为4KB的物理扇区。
逻辑块/簇:操作系统中的文件系统会定义自身逻辑块大小,通常为扇区的整数倍,以提高I/O效率。
数据库页:数据库页是数据库管理系统中用于管理磁盘和内存之间数据传输的最小I/O单位。数据库用页来管理自己的数据存储。当数据库需要访问一行数据时,它会将包含该行的整个页从磁盘加载到内容中,修改数据时,也是先修改内存中的页再异步写回到磁盘。
Zset优化点
两种编码格式
当元素数量不多时,HT和SkipList的优势不明显,而且更耗内存。因此zset还会采用ZipList 结构来节省内存,不过需要同时满足两个条件:
1> 元素数量小于zset_max_ziplist_entries,默认值128
2> 每个元素都小于zset_max_ziplist_value字节,默认值64
使用config get 命令来检查对应的默认值,并且可以使用config set来对这两个值进行设置。
c
/* Lookup the key and create the sorted set if does not exist. */
zobj = lookupKeyWrite(c->db,key);
if (checkType(c,zobj,OBJ_ZSET)) goto cleanup;
if (zobj == NULL) {
if (xx) goto reply_to_client; /* No key + XX option: nothing to do. */
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr))
{
zobj = createZsetObject();
} else {
zobj = createZsetZiplistObject();
}
dbAdd(c->db,key,zobj);
}上述代码中,可以看到,如果禁用zset_max_ziplist_entries或者value的大小超过了zset_max_ziplist_value ,那么就createZsetObject();也就是使用HT+SkipList。否则就采用createZsetZiplistObject();去创建一个ZipList。
c
robj *createZsetObject(void) {
zset *zs = zmalloc(sizeof(*zs));
robj *o;
zs->dict = dictCreate(&zsetDictType,NULL);
zs->zsl = zslCreate();
o = createObject(OBJ_ZSET,zs);
o->encoding = OBJ_ENCODING_SKIPLIST;
return o;
}
robj *createZsetZiplistObject(void) {
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_ZSET,zl);
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}编码转换:
由于涉及到两种编码,所以Redis在添加元素的时候要进行编码转换。
源码如下:
c
int zsetAdd(robj *zobj, double score, sds ele, int in_flags, int *out_flags, double *newscore) {
/* Turn options into simple to check vars. */
int incr = (in_flags & ZADD_IN_INCR) != 0;
int nx = (in_flags & ZADD_IN_NX) != 0;
int xx = (in_flags & ZADD_IN_XX) != 0;
int gt = (in_flags & ZADD_IN_GT) != 0;
int lt = (in_flags & ZADD_IN_LT) != 0;
*out_flags = 0; /* We'll return our response flags. */
double curscore;
/* NaN as input is an error regardless of all the other parameters. */
if (isnan(score)) {
*out_flags = ZADD_OUT_NAN;
return 0;
}
/* Update the sorted set according to its encoding. */
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *eptr;
if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {
/* NX? Return, same element already exists. */
if (nx) {
*out_flags |= ZADD_OUT_NOP;
return 1;
}
/* Prepare the score for the increment if needed. */
if (incr) {
score += curscore;
if (isnan(score)) {
*out_flags |= ZADD_OUT_NAN;
return 0;
}
}
/* GT/LT? Only update if score is greater/less than current. */
if ((lt && score >= curscore) || (gt && score <= curscore)) {
*out_flags |= ZADD_OUT_NOP;
return 1;
}
if (newscore) *newscore = score;
/* Remove and re-insert when score changed. */
if (score != curscore) {
zobj->ptr = zzlDelete(zobj->ptr,eptr);
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
*out_flags |= ZADD_OUT_UPDATED;
}
return 1;
} else if (!xx) {
/* check if the element is too large or the list
* becomes too long *before* executing zzlInsert. */
if (zzlLength(zobj->ptr)+1 > server.zset_max_ziplist_entries ||
sdslen(ele) > server.zset_max_ziplist_value ||
!ziplistSafeToAdd(zobj->ptr, sdslen(ele)))
{
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
} else {
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
if (newscore) *newscore = score;
*out_flags |= ZADD_OUT_ADDED;
return 1;
}
} else {
*out_flags |= ZADD_OUT_NOP;
return 1;
}
}
/* Note that the above block handling ziplist would have either returned or
* converted the key to skiplist. */
if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
zset *zs = zobj->ptr;
zskiplistNode *znode;
dictEntry *de;
de = dictFind(zs->dict,ele);
if (de != NULL) {
/* NX? Return, same element already exists. */
if (nx) {
*out_flags |= ZADD_OUT_NOP;
return 1;
}
curscore = *(double*)dictGetVal(de);
/* Prepare the score for the increment if needed. */
if (incr) {
score += curscore;
if (isnan(score)) {
*out_flags |= ZADD_OUT_NAN;
return 0;
}
}
/* GT/LT? Only update if score is greater/less than current. */
if ((lt && score >= curscore) || (gt && score <= curscore)) {
*out_flags |= ZADD_OUT_NOP;
return 1;
}
if (newscore) *newscore = score;
/* Remove and re-insert when score changes. */
if (score != curscore) {
znode = zslUpdateScore(zs->zsl,curscore,ele,score);
/* Note that we did not removed the original element from
* the hash table representing the sorted set, so we just
* update the score. */
dictGetVal(de) = &znode->score; /* Update score ptr. */
*out_flags |= ZADD_OUT_UPDATED;
}
return 1;
} else if (!xx) {
ele = sdsdup(ele);
znode = zslInsert(zs->zsl,score,ele);
serverAssert(dictAdd(zs->dict,ele,&znode->score) == DICT_OK);
*out_flags |= ZADD_OUT_ADDED;
if (newscore) *newscore = score;
return 1;
} else {
*out_flags |= ZADD_OUT_NOP;
return 1;
}
} else {
serverPanic("Unknown sorted set encoding");
}
return 0; /* Never reached. */
}
虽然源码较多,但是可以从最初始的if来判断编码转化的逻辑。if (zobj->encoding == OBJ_ENCODING_ZIPLIST)如果当前的编码为ZIPList才设计到编码转换,也就是需要判断: if (zzlLength(zobj->ptr)+1 > server.zset_max_ziplist_entries || sdslen(ele) > server.zset_max_ziplist_value || !ziplistSafeToAdd(zobj->ptr, sdslen(ele)))三种情况,从前到后分别是添加元素后,对应的元素个数超出了zset_max_ziplist_entries的限制,添加的元素的字节大小超出了zset_max_ziplist_value的限制,总体的数量超出了ZipList的限制。具体ziplistSafeToAdd()判断函数如下:
c
/* Don't let ziplists grow over 1GB in any case, don't wanna risk overflow in
* zlbytes*/
#define ZIPLIST_MAX_SAFETY_SIZE (1<<30)
int ziplistSafeToAdd(unsigned char* zl, size_t add) {
size_t len = zl? ziplistBlobLen(zl): 0;
if (len + add > ZIPLIST_MAX_SAFETY_SIZE)
return 0;
return 1;
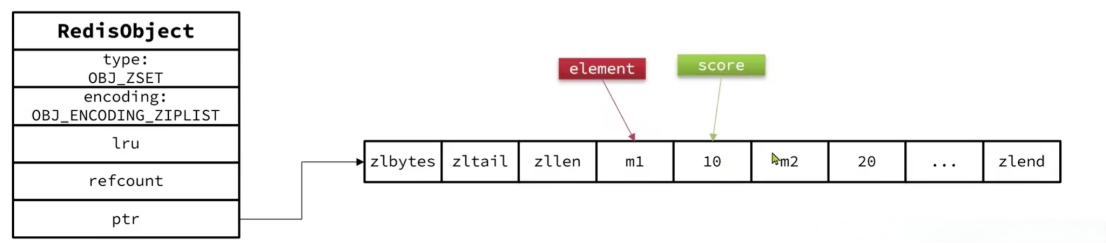
}ZipList实现Zset功能
ziplist本身没有排序功能,因此score和element是紧挨在一起的两个Entry,element在前,score在后。
score越小越接近队首,score越大越接近队尾,按照score值升序排列。
根据键找值,那么直接对ZIPList进行遍历。
Hash
hash结构与Redis中的zset非常类似。
类似点如下:
1> 都是键值对存储
2> 都需要根据键获取值
3> 键都需要唯一
不同点如下:
1> zset 中根据score排序,并且可以通过 element 找值,键是member/element,值是value/score,并且是按照score排序的,score必须为数值型。而hash是field找value,键是field,值是value,Hash是无序的。
基于类似点,所以Hash底层采用的编码与Zset大致相同,不过由于Hash并不需要做排序,所以不需要维护SkipList,所以对应的编码修改为 OBJ_ENCODING_HT。所以与Zset相同Hash结构默认采用ZipList编码,以节省内存。ZipList中的两个Entry分别保存field和value,当数据量较大的时候,Hash结构会转化为HT编码,对应Dict,对应决定的变量为:
ZipList中的元素数量超过了hash-max-ziplist-entries(默认512)
ZipList中的任意entry大小超过了hash-max-ziplist-value(默认64字节)
以及隐含条件ZipList不能超过1GB,这与Zset都是类似的。
c
// hset user1 name Jack age 21
void hsetCommand(client *c) {
int i, created = 0;
robj *o;
if ((c->argc % 2) == 1) {
addReplyErrorFormat(c,"wrong number of arguments for '%s' command",c->cmd->name);
return;
}
//这里的c->argv[1])就是对应的key,也就是命令中的user1
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
//把输入的starth和end传入,查看是否要将ZIPLIST转为HT
// 这里的2表示的就是name,agrc-1就是最后的21
hashTypeTryConversion(o,c->argv,2,c->argc-1);
// 循环将命令中的值使用hset添加到hash中
for (i = 2; i < c->argc; i += 2)
created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);
/* HMSET (deprecated) and HSET return value is different. */
char *cmdname = c->argv[0]->ptr;
if (cmdname[1] == 's' || cmdname[1] == 'S') {
/* HSET */
addReplyLongLong(c, created);
} else {
/* HMSET */
addReply(c, shared.ok);
}
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_HASH,"hset",c->argv[1],c->db->id);
server.dirty += (c->argc - 2)/2;
}注:本文以黑马程序员的Redis课程为模板进行总结。对应视频链接:
黑马程序员Redis入门到实战教程