介绍
MySQL8 的事务性数据字典是相比 MySQL 5.7 的核心改进之一,彻底改变了元数据(如表结构、视图、索引等)的存储和管理方式。
数据库的元数据包含表结构、视图、索引等等数据,在MySQL 5.7之前,元数据存储在文件系统中,这样的存储方式会导致DDL操作不支持事务,即无法做到批量的DDL操作要么完全执行,要么完全不执行。
MySQL 8.0 将默认字符集从 MySQL 5.7 的 latin1 更改为 utf8mb4,并将默认排序规则从 latin1_swedish_ci 更改为 utf8mb4_0900_ai_ci。这一变化显著提升了字符集支持的范围和排序精度。
utf8mb4 是 MySQL 对 UTF-8 的实现,支持完整的 Unicode 字符集,适合存储多语言文本、Emoji 和特殊符号。包括多国语言和补充语言,如 Emoji 和罕见汉字。而latin1仅支持 256 个字符,无法存储 Emoji 或汉字。
而uft8的排序规则utf8mb4_0900_ai_ci 基于 Unicode 9.0 标准,取代了 MySQL 5.7 中的uft8排序规则utf8_general_ci,提供更精确的 Unicode 排序,比较和排序更符合语言习惯(如中文拼音、笔画排序)。
MySQL 5.7也可以设置使用字符集
utf8mb4,只不过默认字符集是latin1,但它的utf8排序规则只能是utf8_general_ci,不能使用MySQL 8.0的utf8mb4_0900_ai_ci
在实际开发过程中,我们有时会修改数据库版本,或者将别人的数据库内容导入自己的MySQL中。如果我们导出的数据库版本是MySQL8,现在要将数据导入MySQL5.7当中,往往会出现导入异常。
这大概率就是由于MySQL5.7和MySQL8.0的字符集排序规则和源数据存储方式不同,我们需要打开SQL文件,将建表语句中的字符集和排序规则变成MySQL5.7的规则:
- 将
COLLATE utf8mb4_0900_ai_ci替换为COLLATE utf8mb4_general_ci。 - 将
ENGINE = InnoDB替换为ENGINE = MyISAM - 去掉表定义末尾的
AUTO_INCREMENT = 1
窗口函数
窗口函数 也叫分析函数 ,用于将查询的结果进行较为复杂的统计分析,MySQL从8.0开始支持窗口函数。
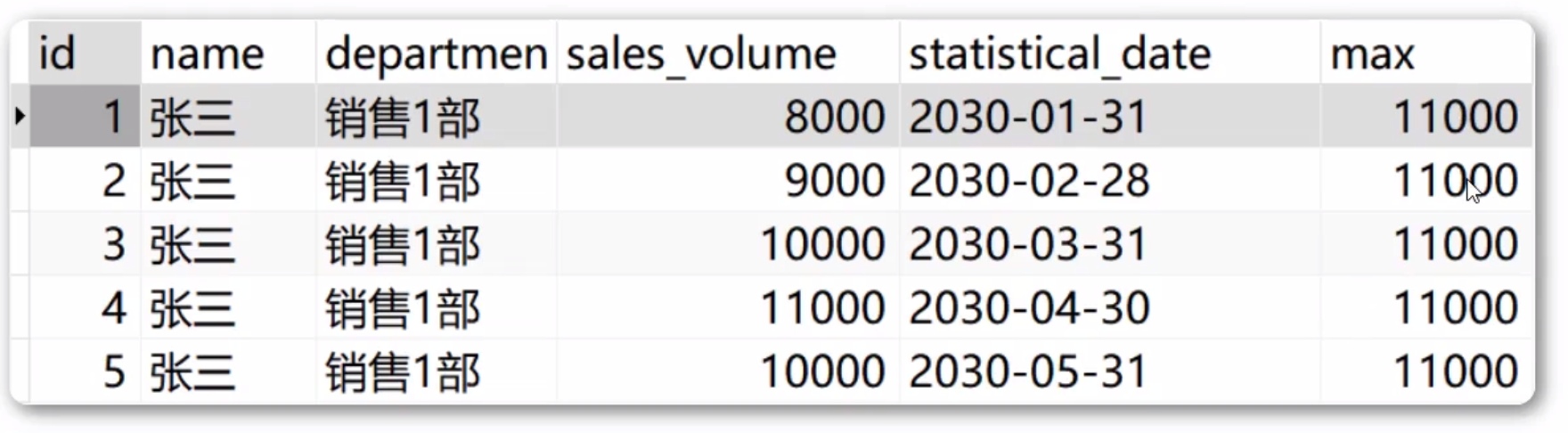
假设我现在有这样一张表:
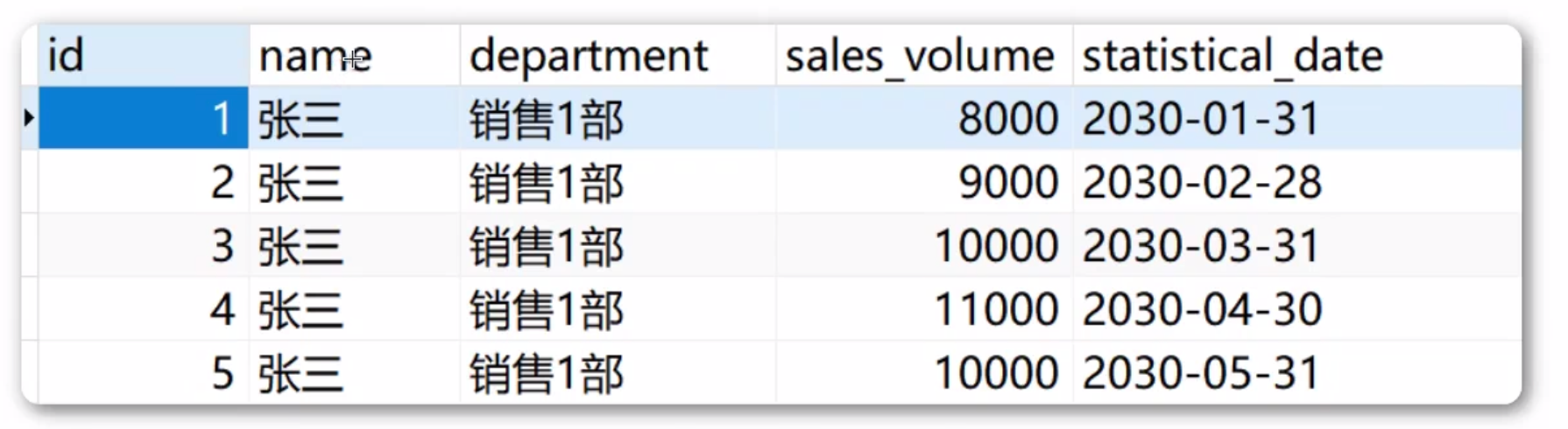
我想要每个月都统计张三今年的销售总额。也就是这样的一个效果:
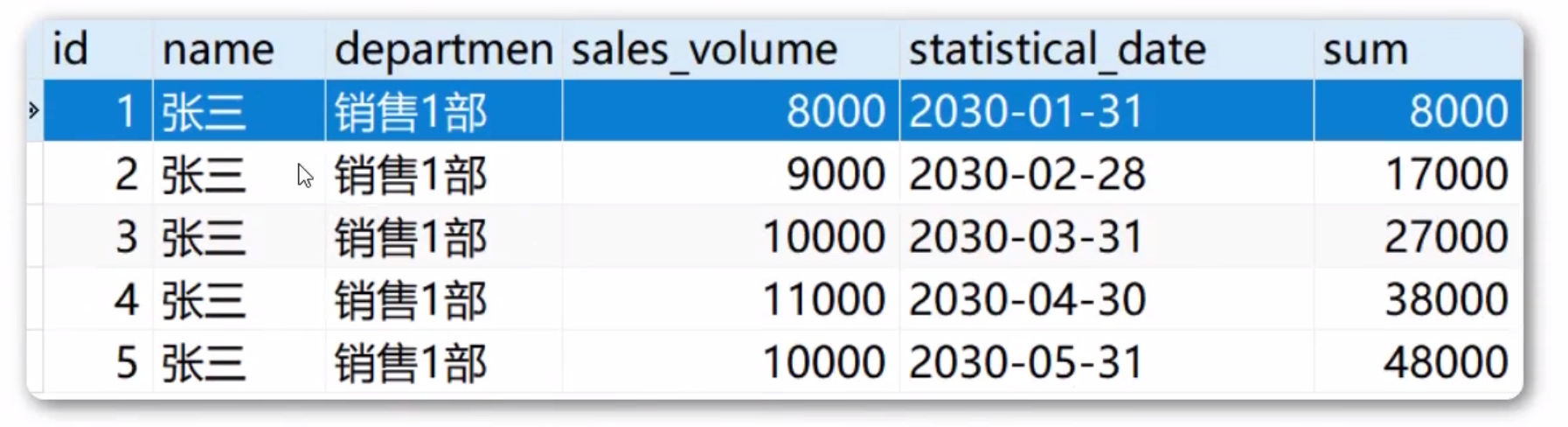
此时使用原来的SQL语句,是非常难做到这样的效果的,而要想对查询结果 进行复杂的分析处理,最好的方式就是使用窗口函数。
窗口函数中引入了一个窗口 的概念,窗口类似于窗户,限定一个空间范围,或者可以理解为查询结果的自定义集合。而窗口函数可以在处理查询结果的时候,每条结果 都可以结合不同的窗口 ,从而输出相应的数据分析结果。对窗口内数据不同的处理方法 ,可以使用不同的窗口函数。 例如:我们可以查询张三所有月份中最高的销售额
格式:

窗口函数不能过滤查询结果,只能对查询结果进行分析并输出。所以窗口函数是写在SELECT之后,而不是写在WHERE之后。即:
SELECT 窗口函数 where 条件而窗口函数的基本格式如下:
函数名(字段) over(子句)
其中over是关键字,用来指定函数执行的窗口范围,包含三个分析子句:分组(partition by)子句,排序(order by)子句,窗口(rows)子句,如果后面括号中什么都不写,则意味着窗口包含所有的查询结果,窗口函数的完整格式如下:
函数名(字段) over(
partition by <要分组的字段>
order by <排序的字段>
rows <窗口范围>
)举个例子:
-
向MySQL8数据库中导入销售额表
-
查询每个人的销售额,并统计每个月末,每个人的销售总额。
SELECT
*,
sum( sales.sales_volume ) over ( -- 计算sales_volume字段的和
PARTITION BY name -- 根据名字分组
ORDER BY YEAR(sales.statistical_date),MONTH(sales.statistical_date) -- 根据月份排序
rows between unbounded preceding and current row -- 窗口范围从之前的所有行到当前行
) sum
FROM
sales
接下来我们具体介绍一下rows子句的关键字和写法:
- preceding:前面行
- following:后面行
- current row:当前行
- unbounded:所有行
例如:
- rows between 2 preceding and current row :窗口取前面两行到当前行
- rows between unbounded preceding and current row :窗口取之前所有行到当前行
- rows between current row and unbounded following: 窗口当前行到之后所有行
- rows between 3 preceding and 1 following:窗口取当前行的前面三行到后面一行,总共五行
如果子句中只有partition by没有order by和rows,窗口规范默认是所有行
如果子句中有order by没有rows,窗口规范默认是取之前所有行到当前行
所以之前的例子也可以这么写:
SELECT
*,
sum( sales.sales_volume ) over ( -- 计算sales_volume字段的和
PARTITION BY name -- 根据名字分组
ORDER BY YEAR(sales.statistical_date),MONTH(sales.statistical_date) -- 根据月份排序
) sum
FROM
sales 聚合函数
窗口函数中的聚合函数,负责在窗口内执行聚合计算,支持窗口内累计或统计。常见的聚合函数有这几种:
- SUM():计算窗口内值的总和
- AVG():计算窗口内值的平均值
- COUNT():计算窗口内的行数
- MIN() :找出窗口内的最小值
- MAX():找出窗口内的最大值
接下来我们用查询语句举例聚合函数的使用:
-- 计算每个销售人员的累计销售额
SELECT
*,
SUM(sales_volume) OVER(PARTITION BY name ORDER BY statistical_date) AS running_total
FROM sales;
-- 计算每个部门的平均销售额
SELECT
*,
AVG(sales_volume) OVER(PARTITION BY department) AS dept_avg_sales
FROM sales;
-- 计算每个销售人员的销售记录数量
SELECT
*,
COUNT(*) OVER(PARTITION BY name) AS sales_count
FROM sales;
-- 找出每个销售人员的最低单月销售额
SELECT
*,
MIN(sales_volume) OVER(PARTITION BY name) AS min_sales
FROM sales;
-- 找出每个销售人员的最高单月销售额
SELECT
*,
MAX(sales_volume) OVER(PARTITION BY name) AS max_sales
FROM sales;SQL中聚合函数,与窗口函数中聚合函数有什么区别:
我们以同样的需求举例:
-- 找出每个销售人员的最高单月销售额
SELECT
*,
MAX(sales_volume) OVER(PARTITION BY name) AS max_sales
FROM sales;
-- 找出每个销售人员的最高单月销售额
SELECT name,SUM(sales_volume) FROM sales GROUP BY name;- 普通场景下的聚合函数基于GROUP BY子句定义的组进行计算,将多条记录聚合为一条,只能展示分组字段和聚合函数字段;
- 窗口函数是基于窗口定义进行计算,每条记录都会执行,而且针对于不同的记录可以设置不同的窗口范围,有几条记录执行完还是几条。
排名函数
排名函数可以为数据集中的行分配排名或序号,常用于排序和比较场景。常见的排名函数有这几种:
- ROW_NUMBER():为结果集中的每一行分配唯一的连续序号(1, 2, 3...),即使值相同也会分配不同序号
- RANK():为行分配排名,相同值获得相同排名,但会跳过后续排名(如1,1,3)
- DENSE_RANK():类似RANK()但不跳过排名数字(如1,1,2)
接下来我们用查询语句举例排名函数的使用:
-- 计算3月销售额排名
SELECT
*,
ROW_NUMBER() OVER(ORDER BY sales_volume DESC) AS rn,
RANK() OVER(ORDER BY sales_volume DESC) AS r,
DENSE_RANK() OVER(ORDER BY sales_volume DESC) AS dr
FROM sales
WHERE MONTH(statistical_date) = 3;
分析函数
分析函数用于访问窗口内其他行的数据。常见的分析函数有这几种:
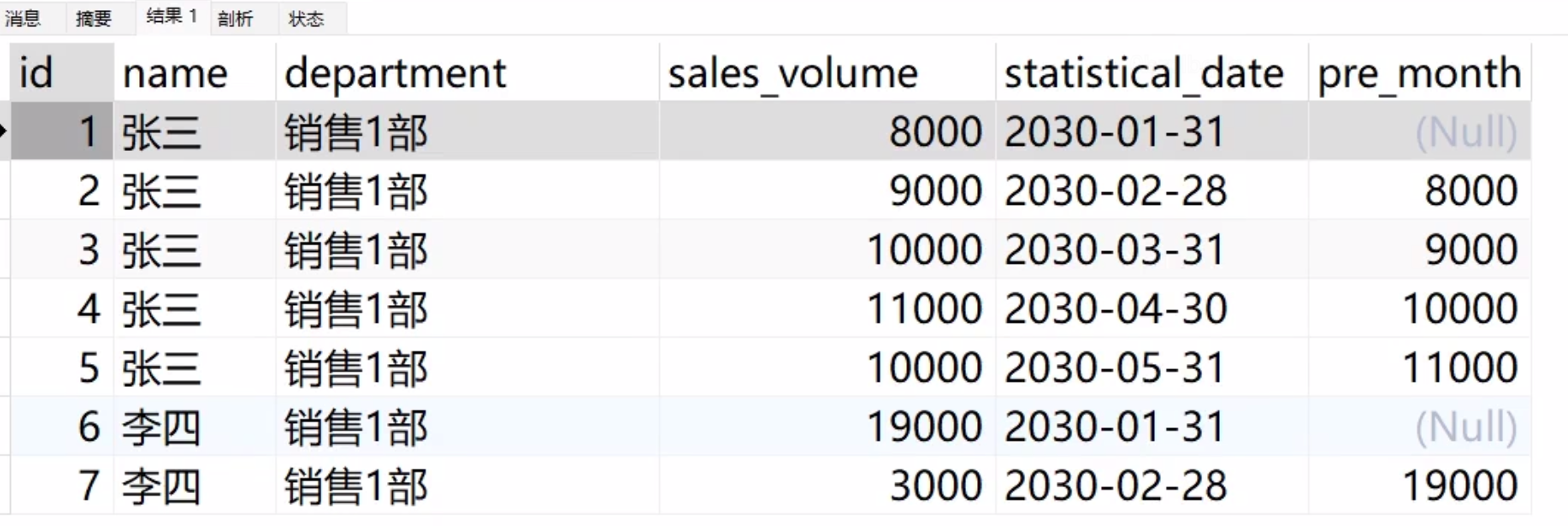
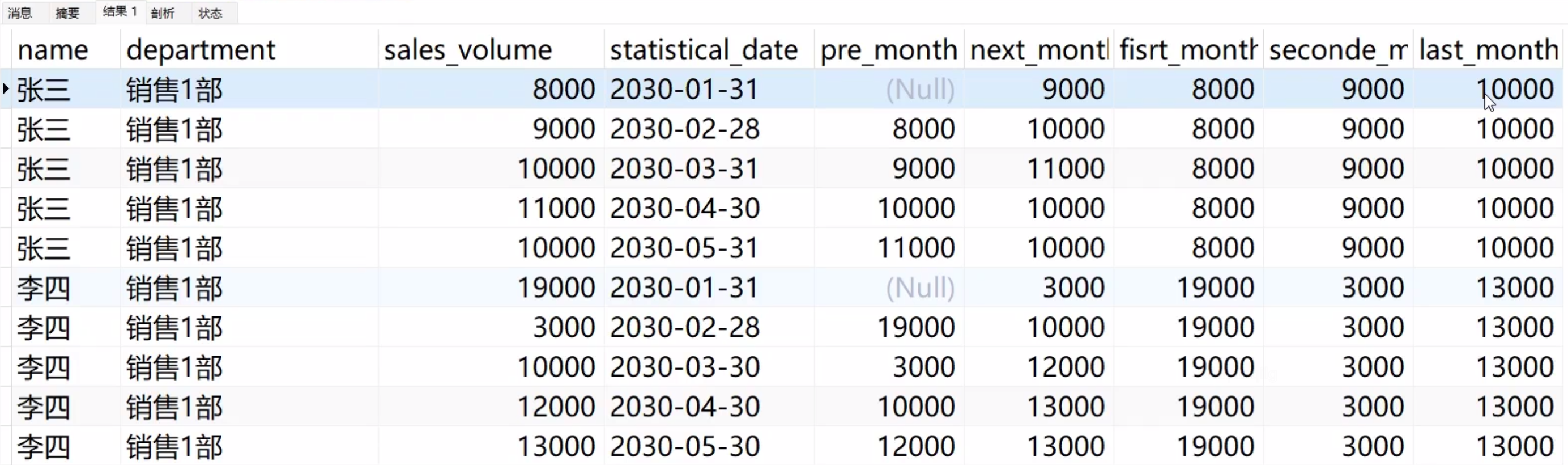
- LAG(column, n, default):返回当前行前 n 行的 column 列的值,若没有则返回当前行中default列的值。
- LEAD(column, n, default):返回当前行后 n 行的 column 值,若没有则返回当前行中default列的值。
- FIRST_VALUE(column):返回窗口内第一行的 column 值。
- LAST_VALUE(column):返回窗口内最后一行的 column 值。
- NTH_VALUE(column, n):返回窗口内第 n 行的 column 值。
接下来我们举例分析函数的使用:
-- 显示每个销售人员上个月的销售额
-- 显示每个销售人员下个月的销售额
-- 显示每个销售人员第一个月的销售额
-- 显示每个销售人员第二个月的销售额
-- 显示每个销售人员最后一个月的销售额
SELECT
*,
LAG(sales_volume, 1) OVER(
PARTITION BY name
ORDER BY statistical_date
rows BETWEEN unbounded preceding AND unbounded following
) AS prev_month_sales,
LEAD(sales_volume, 1 , sales_volume) OVER(
PARTITION BY name
ORDER BY statistical_date
rows BETWEEN unbounded preceding AND unbounded following
) AS next_month_sales,
FIRST_VALUE(sales_volume) OVER(
PARTITION BY name
ORDER BY statistical_date
rows BETWEEN unbounded preceding AND unbounded following
) AS first_month_sales,
NTH_VALUE(sales_volume,2) OVER(
PARTITION BY name
ORDER BY statistical_date
rows BETWEEN unbounded preceding AND unbounded following
) AS second_month_sales,
LAST_VALUE(sales_volume) OVER(
PARTITION BY name
ORDER BY statistical_date
rows BETWEEN unbounded preceding AND unbounded following
) AS last_month_sales
FROM sales;