目录
[5.好友申请 II :谁有最多的好友(union+窗口函数+子查询)](#5.好友申请 II :谁有最多的好友(union+窗口函数+子查询))
题目来源:高频 SQL 50 题(基础版) - 学习计划 - 力扣(LeetCode)全球极客挚爱的技术成长平台
1.上级经理已离职的公司员工
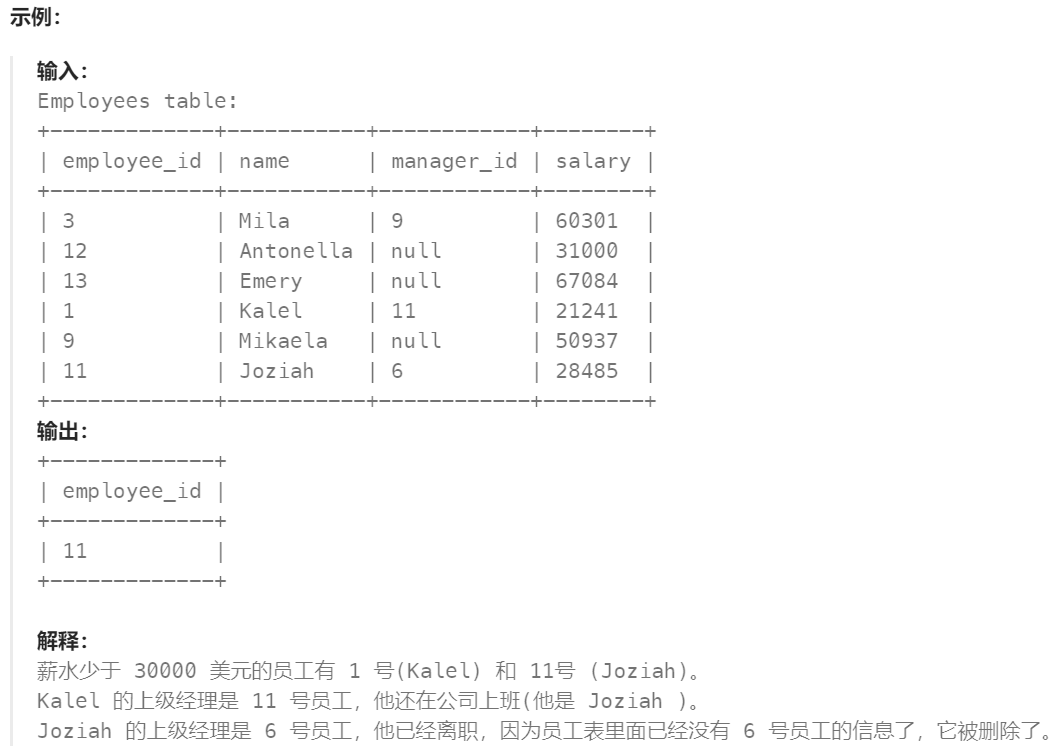
题目:

查找这些员工的id,他们的薪水严格少于$30000 并且他们的上级经理已离职。当一个经理离开公司时,他们的信息需要从员工表中删除掉,但是表中的员工的manager_id 这一列还是设置的离职经理的id 。
返回的结果按照employee_id 从小到大排序。
查询结果如下所示:
思路:
这道题要求薪资小于30000的且上司已经离职的员工
第一个条件很简单,第二个条件如果正向找已经离职的员工会麻烦点,我们使用not in语句来反向寻找目前还未离职的员工,最后排个序即可。
代码:
sql
# 子查询+排序
select employee_id
from Employees
where salary<30000
and manager_id not in (
select employee_id
from Employees
)
order by employee_id2.换座位
题目:

编写解决方案来交换每两个连续的学生的座位号。如果学生的数量是奇数,则最后一个学生的id不交换。
按 id 升序 返回结果表。
查询结果格式如下所示。

思路:
这题要求的是将相邻的两行的id进行位置交换,最后跟据id进行排序。
这题的难点在于如何将两行的id进行交换,其他字段不变,可以使用窗口函数实现,完整流程:
-
FROM seat:从seat表读取数据
-
计算IF表达式:对每行的id进行奇偶判断和转换
-
窗口函数排序:按照转换后的值排序
-
RANK()分配排名:为排序后的行分配连续排名(1,2,3...)(因为排名从1开始,需重新分配)
-
SELECT输出:显示新的id列和原student列
转换过程示例:
| 原ID | 学生 | 转换值 | 新ID |
|---|---|---|---|
| 1 | Alice | 1 | 1 |
| 2 | Bob | 0 | 2 |
| 3 | Charlie | 3 | 3 |
| 4 | David | 2 | 4 |
| 5 | Eve | 5 | 5 |
结合流程和表进行理解
代码:
sql
# 窗口函数+排序
select rank() over (order by if(id%2=0,id-2,id)) id, student
from Seat3.电影评分
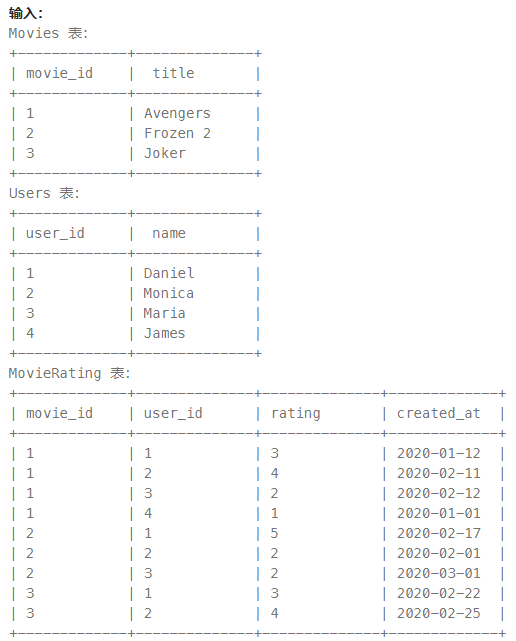
题目:

请你编写一个解决方案:
- 查找评论电影数量最多的用户名。如果出现平局,返回字典序较小的用户名。
- 查找在
February 2020平均评分最高 的电影名称。如果出现平局,返回字典序较小的电影名称。
字典序 ,即按字母在字典中出现顺序对字符串排序,字典序较小则意味着排序靠前。
返回结果格式如下例所示。

思路:
这题本质就是两道题,第一个要求的是评论电影最多的人,第二个要求的是2020年2月内的电影平均分最高的电影,两个毫不相干的问题,最后都塞进同一个字段,只能使用写两个select然后使用union拼接起来。
之所以用union all而不是union,是因为有一个例子出现了电影名跟人名同名的情况,直接union会把其中一个覆盖掉,必须使用union all
代码:
sql
# union
(select u.name results
from MovieRating mr
left join Users u on mr.user_id=u.user_id
group by mr.user_id
order by count(*) desc, name
limit 1
)
union all
(select m.title results
from MovieRating mr
left join Movies m on mr.movie_id=m.movie_id
where date_format(created_at,'%Y%m')='202002'
group by mr.movie_id
order by avg(rating) desc, m.title
limit 1
) 4.餐馆营业额变化增长(窗口+子查询)
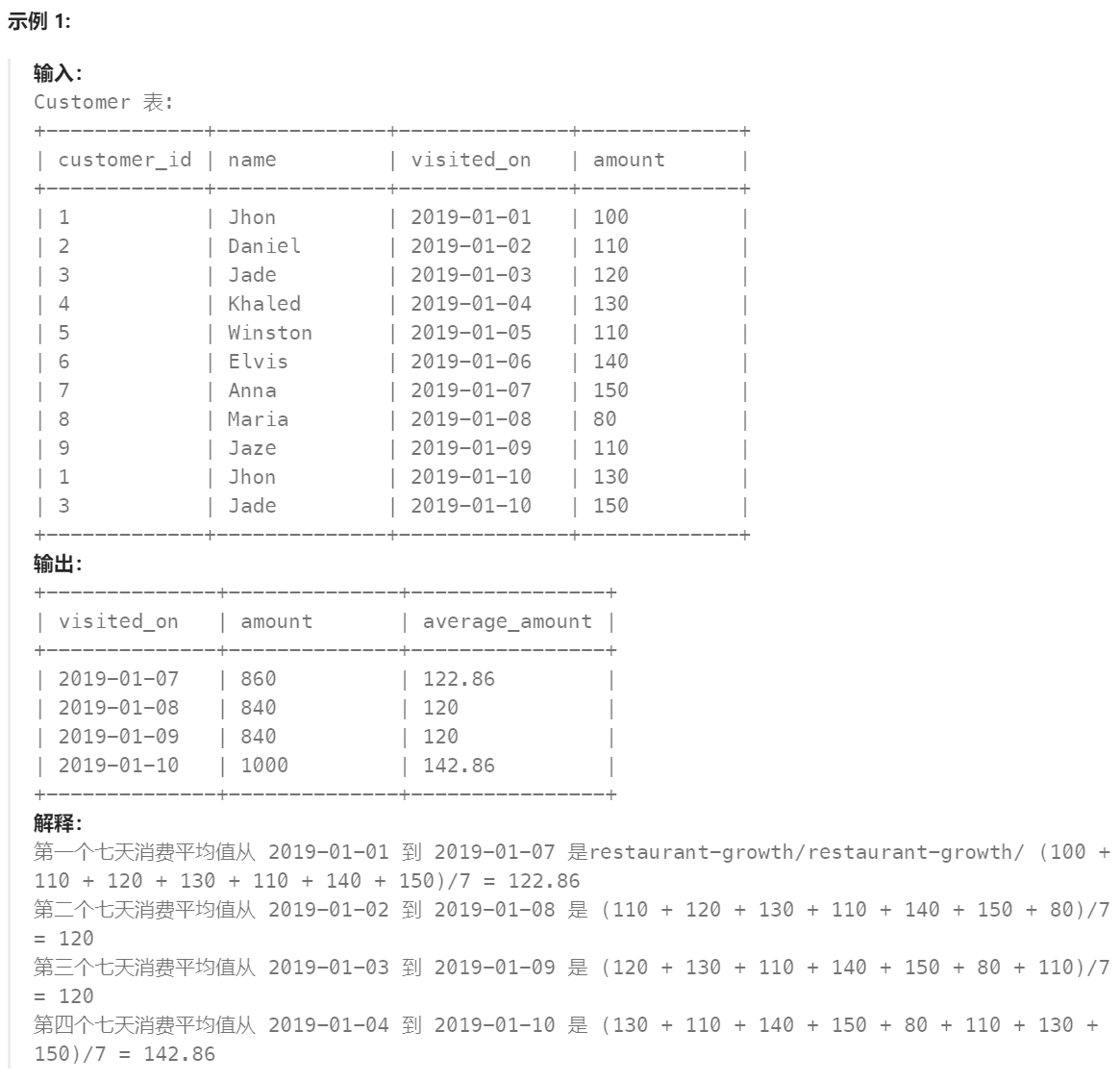
题目:

你是餐馆的老板,现在你想分析一下可能的营业额变化增长(每天至少有一位顾客)。
计算以 7 天(某日期 + 该日期前的 6 天)为一个时间段的顾客消费平均值。average_amount 要 保留两位小数。
结果按 visited_on 升序排序。
返回结果格式的例子如下。
思路:
这道题要求对每个日期的前七天的营业额的平均值,且该日期的前七天要存在,不能少一天,这就是为什么输出结果从7号开始。
因为原表出现重复的日期(如10号),思路是先对原来的表进行重新去重查询,同时使用窗口函数计算每个日期的前七天营业总额,这样就得到一个新表temp。这里要注意的是,对于去重distinct和窗口函数的优先级 ,是先对每条数据执行完所有窗口函数的代码,然后才进行去重,也就是说,就算有两个10号,也会先把所有10号的营业额算进去,这两个10号的营业总额都是一样的,然后再去重多余的10号
最后最外层的查询的where语句要筛选出从第7天开始 的数据,使用 datediff(date1, date2):计算两个日期的天数差,这个date2可以使用子查询 (select min(visited_on) from Customer):找到最早的访问日期(也就是1号),这个日期差>=6即可满足条件
最后再回到最外层的查询字段,对于第三个字段,只要使用round((amount/7),2)求平均值然后保留2位小数即可,注意不能使用avg()
代码:
sql
#窗口函数+子查询
select visited_on, amount, round((amount/7),2) average_amount
from (
select distinct visited_on,
sum(amount) over(order by visited_on range interval 6 day preceding) amount
from Customer
) temp
where datediff(visited_on, (
select min(visited_on)
from Customer
)) >=65.好友申请 II :谁有最多的好友(union+窗口函数+子查询)
题目:
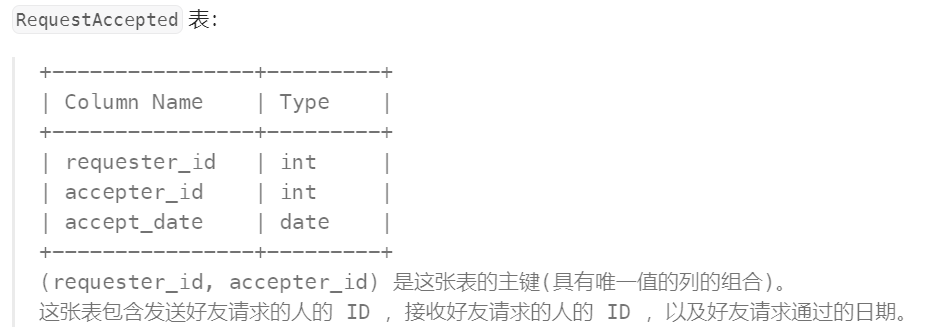
编写解决方案,找出拥有最多的好友的人和他拥有的好友数目。
生成的测试用例保证拥有最多好友数目的只有 1 个人。
查询结果格式如下例所示。

思路:
这道题主要是求拥有好友数量最多的人,也就是第一列出现的id加上第二列出现的id的值最大的用户,因为一个是添加别人,一个是被别人添加,都是属于好友数+1
因为在一行数据中,每个id只要出现一次,就算这个id的好友数+1,因此根本目的就是找出出现次数最多的id。
那么我们只要统计两列的id数然后相加再排个序即可,但是这样直接算会比较麻烦,我们可以使用union all语句进行优化,第一个select,先求出第一列的所有id,第二个select求出第二列的所有id,然后合并(注意union会去除重复行, 而union all会保留所有行),这样我们就做到了将两列的id全部加起来了,之所以要保留所有行,就是防止第二列的id漏算。然后就是按照id进行分组排序取第一即可。
代码:
sql
# union
select id, count(*) num
from (
select requester_id id from RequestAccepted
union all
select accepter_id id from RequestAccepted
) temp
group by id
order by num desc
limit 1进阶:
使用窗口函数
sql
# union+窗口函数+子查询
WITH friend_counts AS (
SELECT id, COUNT(*) as num
FROM (
SELECT requester_id as id FROM RequestAccepted
UNION ALL
SELECT accepter_id as id FROM RequestAccepted
) temp
GROUP BY id
)
SELECT id, num
FROM friend_counts
WHERE num = (SELECT MAX(num) FROM friend_counts)
ORDER BY num DESC;6.2016年的投资(子查询)
题目:
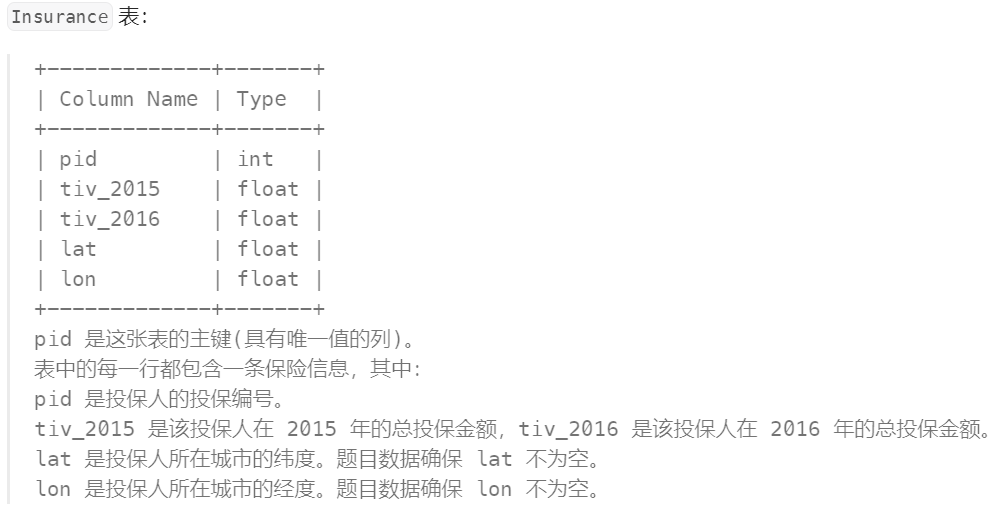
编写解决方案报告 2016 年 (tiv_2016) 所有满足下述条件的投保人的投保金额之和:
- 他在 2015 年的投保额 (
tiv_2015) 至少跟一个其他投保人在 2015 年的投保额相同。 - 他所在的城市必须与其他投保人都不同(也就是说 (
lat, lon) 不能跟其他任何一个投保人完全相同)。
tiv_2016 四舍五入的 两位小数 。
查询结果格式如下例所示。
思路:
这道题求的是满足条件的所有投保人的2016年的投保金额总额,也就是要先筛选出满足上面说的两个条件的人再求和
我们可以使用从正面进行求解,先使用一个where求出满足第一个条件的人,子查询的内容是先按tiv_2015分组,然后having找出行数>1的组,意思就是有至少两个人的2015的投保额一样,使用in确定这个范围即可;然后使用and求出满足第二个条件的人,子查询的内容是同时对lat和lon进行分组,然后找出行数>1的组,意思是这个组的经纬度一样,一定不满足第二个条件,然后使用not in排除掉这组数据即可;
代码:
sql
# 子查询
select round(sum(tiv_2016),2) tiv_2016
from Insurance
where tiv_2015 in (
select tiv_2015
from Insurance
group by tiv_2015
having count(*)>1
)
and (lat, lon) not in (
select lat, lon
from Insurance
group by lat, lon
having count(*)>1
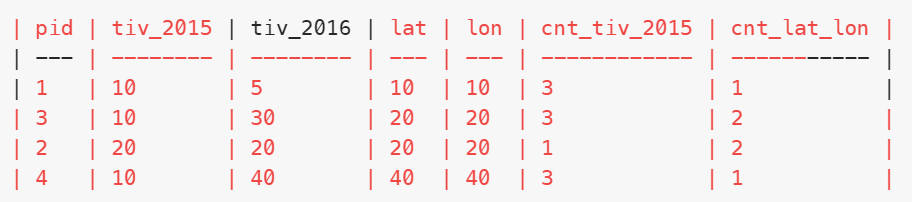
)也可以使用窗口函数:
思路就是先对原表的每一行数据后面都开两个窗,统计当前id的2015投资额有多少组和经纬度有多少组
sql
#窗口函数
select round(sum(tiv_2016),2) tiv_2016
from (
select *,
count(*) over (partition by tiv_2015) cnt_tiv_2015,
count(*) over (partition by lat, lon) cnt_lat_lon
from Insurance
) temp
where cnt_tiv_2015>1
and cnt_lat_lon =1窗口查询结果示例:
7.部门工资前三高的所有员工(左连接)
题目:

公司的主管们感兴趣的是公司每个部门中谁赚的钱最多。一个部门的 高收入者 是指一个员工的工资在该部门的 不同 工资中 排名前三 。
编写解决方案,找出每个部门中 收入高的员工 。
以 任意顺序 返回结果表。
返回结果格式如下所示。

思路:
这题主要求每个部门的工资排名前三的员工(包括重复/并排的),比较麻烦的是如何将重复的也找出来
我们可以先直接使用两次左连接来找出排名前三的员工,第一个左连接先Employee自己跟自己链接,要求是departmentId必须相等且工资必须比左边的高,第二个左连接是跟Department链接,要求是departmentId相等,代码如下:
sql
select *
from employee e1
left join employee e2 on e1.departmentId = e2.departmentId and e1.salary < e2.salary
left join department d on e1.departmentId = d.id查询结果如下:
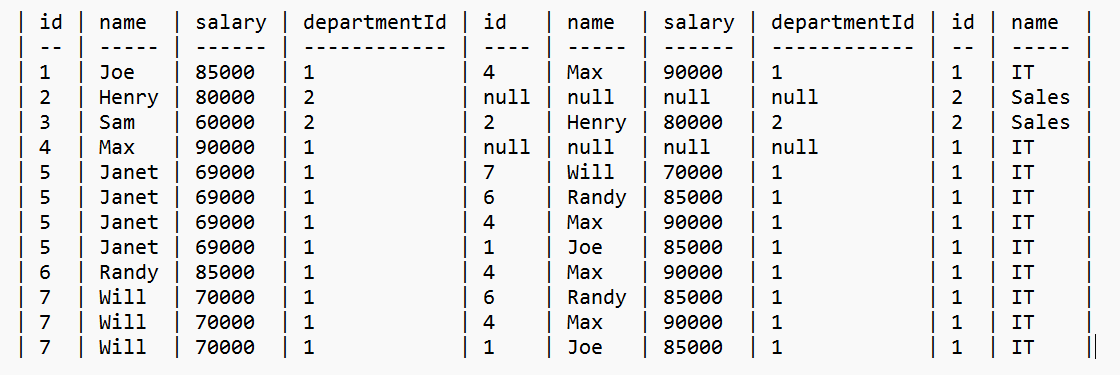
可以看出在IT组Will就是第三名,则可以排除Janet,我们可以继续按e1.id进行分组,条件是count(distinct e2.salary) <=2,即先对e2的工资进行去重然后再统计行数,行数即代表实际e1.id的排名+1,Joe和Randy并排第二
sql
group by e1.id
having count(distinct e2.salary) <=2
最后可以再进行一个排序即可,排序是对e1.departmentId, e1.salary进行排序,因为返回的数据没有要求,所以排不排都无所谓,我这里选择排一下(不排更快一点)
代码:
sql
#左连接
select d.name Department, e1.name Employee, e1.salary Salary
from employee e1
left join employee e2 on e1.departmentId = e2.departmentId and e1.salary < e2.salary
left join department d on e1.departmentId = d.id
group by e1.id
having count(distinct e2.salary) <=2
order by e1.departmentId, e1.salary desc本篇文章到此结束,如果对你有帮助可以点个赞吗~
个人主页有很多个人总结的 Java、MySQL 等相关的知识,欢迎关注~