文章目录
- 摘要
- Abstract
- 一、发票关键字提取系统
-
- [1. 系统核心功能](#1. 系统核心功能)
- [2. 核心功能模块分析](#2. 核心功能模块分析)
-
- [2.1 PDF Converter](#2.1 PDF Converter)
- [2.2 Preprocessing](#2.2 Preprocessing)
- [2.3 OCR Engine](#2.3 OCR Engine)
- [2.4 Extractor](#2.4 Extractor)
- [2.5 Visualizer](#2.5 Visualizer)
- [3. main.py - 批量处理脚本](#3. main.py - 批量处理脚本)
-
- [3.1 主要作用](#3.1 主要作用)
- [3.2 准备工作](#3.2 准备工作)
- [3.3 核心步骤](#3.3 核心步骤)
- 总结
摘要
本周主要完成Github上发票关键字提取系统的学习,了解系统的核心功能,并对相应模块做出解读。
Abstract
This week, I mainly completed the learning of the invoice keyword extraction system on GitHub. I understood the core functions of the system and interpreted its corresponding modules in detail.
一、发票关键字提取系统
源项目地址:【invoice-ocr】
1. 系统核心功能
系统主要功能:
从发票PDF中提取关键信息(发票号、日期、总金额等)
核心工作:
- PDF Converter: 将pdf转为图片
- Preprocessing:图像预处理 灰度化,阈值化(二值化实现分割背景)
- OCR Engine: Tesseract OCR 提取文本和文本框信息
- Extractor: 使用正则表达式和规则从原始文本中识别发票字段
- Visualizer: 绘制文本框在文本边缘
- Streamlit UI: 加载pdf以及转换后的结果
问题1:为什么要将pdf转为图片?
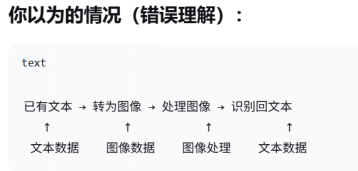

1,前提:原始数据pdf并不知"文本数据",对于计算机而言pdf为图像数据

2,OCR处理的对象就是"视觉信息"而非"文本信息"
问题2:为什么pdf作为图像数据,项目中还需要将pdf转为图片呢?
1,pdf存在两种类型:图像类和文本类
2,OCR引擎(Tesseract)只能处理图像
3,PDF不是像素矩阵,而是:矢量图形指令(画线、填充、文本渲染),压缩的图像数据(JPEG/PNG嵌入),字体和布局信息
问题2:为什么需要使用正则化?
正则化作用:防止过拟合,添加约束,数据增强,
OCR中批归一化也是一种正则化;有正则化的权重小而集中
问题3:Tesseract的具体任务?

2. 核心功能模块分析
2.1 PDF Converter
powershell
import os
from pdf2image import convert_from_path
def convert_pdfs_to_images(pdf_dir, image_dir, dpi=300, poppler_path=None):
os.makedirs(image_dir, exist_ok=True)
#read the pdf file list from pdf directory
pdf_files = [f for f in os.listdir(pdf_dir) if f.lower().endswith(".pdf")]
all_image_paths = []
for pdf_file in pdf_files:
pdf_path = os.path.join(pdf_dir, pdf_file)
images = convert_from_path(pdf_path, dpi=dpi, poppler_path=poppler_path)
base_name = os.path.splitext(pdf_file)[0]
for i, img in enumerate(images):
output_filename = f"{base_name}_page{i+1}.jpg"
output_path = os.path.join(image_dir, output_filename)
img.save(output_path, "JPEG")
all_image_paths.append(output_path)
return all_image_paths1,images = convert_from_path(pdf_path, dpi=dpi, poppler_path=poppler_path)
作用:将一个pdf文档转为一张张图片
说明:
convert_from_path():pdf2image库的核心函数
pdf_path:要转换的PDF文件路径
dpi:设置输出图像的分辨率(默认300)
poppler_path:指定poppler工具路径。Poppler是开源PDF渲染库,用于解析和渲染PDF文件。
返回值:images是一个PIL.Image对象的列表,每个元素对应PDF的一页
技术细节:实际调用了Poppler的pdftoppm工具将PDF渲染为图像
2, base_name = os.path.splitext(pdf_file)0
作用:取出pdf文档名称
说明:
os.path.splitext():分割文件名和扩展名,即"invoice.pdf" → ("invoice", ".pdf")
0:取第一个元素(基础名"invoice")
3,for循环遍历图片
作用:按照pdf文件名以及图片对应文档内的页面确定图片文件名,并在相应位置保存需要的格式的图片。
4,返回所有pdf文件生成的图片。
项目中存在raw文件夹下
2.2 Preprocessing
powershell
import cv2
def preprocess_image(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5, 5), 0)
thresh = cv2.adaptiveThreshold(
blur, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY, 11, 2
)
return thresh主要工作:首先进行灰度化处理,再使用5×5的高斯核进行高斯滤波,最后阈值化处理
1,thresh = cv2.adaptiveThreshold( blur, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2 )
说明:
函数原型:cv2.adaptiveThreshold(src, maxValue, adaptiveMethod, thresholdType, blockSize, C)
cv2.ADAPTIVE_THRESH_GAUSSIAN_C :自适应方法
使用邻域的高斯加权和作为阈值; 抗噪声更好,更平滑;适合光照不均的图像(如发票扫描件)
cv2.THRESH_BINARY :阈值类型
二值化规则:如果 像素值 > 阈值: 设为maxValue (255),否则: 设为0
11 :邻域大小。
2:常数。作用:从计算出的阈值中减去的常数# 用于微调阈值水平
问题1:自适应方法有什么用?
核心问题:光照不均。
传统阈值化方法:像素值>阈值,变成白色,否则变成黑色。
传统阈值化方法结果:
1,亮的地方:全变白,文字消失
2,暗的地方:全变黑,文字被淹没
综合上述结果,需要使用自适应方法,为每个区域计算不同的阈值,使得每个区域都能正确区分文字和背景
问题2:邻域什么意思?为什么需要?
邻域:以当前像素点为中心的n×n矩阵。
作用:为了获取局部信息,而不是只看单个像素

邻域大小的选择原则:
1,大小适中
太小(如3×3):对噪声敏感,容易把噪点当文字,文字可能断裂。适合:清晰文档,小字体。
中等(如11×11):平衡细节和平滑,抗噪声较好,保持文字完整。适合:大多数OCR场景。
太大(如31×31):过度平滑,小文字可能消失,边缘模糊。适合:大文字,强噪声。
2,奇数
要有明确的中心点。如果为偶数,中心点上下,左右难以均衡。
问题3:阈值化有什么用?
阈值化 = 把灰度世界变成黑白分明的世界。灰度化------>二值化。
2.3 OCR Engine
powershell
import pytesseract
from pytesseract import Output
def run_ocr(img):
return pytesseract.image_to_data(img, output_type=Output.DICT)
def get_full_text(ocr_dict):
return " ".join(ocr_dict['text'])主要工作:使用Tesseract引擎从图像中提取文字信息,并以结构化格式返回。
1,from pytesseract import Output
Output:是pytesseract定义的一个特殊类(本质是枚举)
作用:指定OCR输出的数据格式类型

2,pytesseract.image_to_data()
作用:核心OCR函数,执行文字识别。不只是提取文本,而是获取所有识别数据。

问题1:为什么要用Output.DICT而不是直接获取文本?
直接获取文本会丢失位置、置信度等关键信息;
获取字典数据可以保留所有信息:过滤低置信度文字;按位置提取特定区域;分析文本布局;可视化边界框。
2.4 Extractor
1,re模块:Python的正则表达式模块。作用:提供模式匹配功能,用于在文本中查找特定模式
2,为什么先replace('.', '')?
因为千分位点(.)和小数点(.)符号相同,需要区分处理,先去掉所有点,再把逗号换成点
由此可知方法的处理顺序由左至右(无嵌套情况)
3,try...except的作用:
尝试转换,如果转换失败(比如输入不是有效数字)时返回None,而不是程序崩溃
4,正则表达式提取发票信息:号码,日期,支付详情以及总金额,保存在字典变量results里面:

金额的特殊提取:由于extract_field提取为字符串,因此先将金额的字符串提取,再转为数字。如果没有提取到金额的字符就返回none。
补充:
正则表达式:
捕获多个符号:
- 捕获0-n个空格:\s*
- 捕获0-n个:或 空格::\\s*
可选符号:符号?

捕获数字:
- 捕获>=a个数字:(\d{a,})
- 捕获b个数字:\\d{b})
- 捕获数字和点的组合:\\d.
捕获日期:(\\d{2}.\\d{2}.\\d{4})

5,文本匹配方法re.findall():
re.IGNORECASE:忽略大小写
pattern:正则表达式模式
疑问:通用文本匹配的返回值为什么取第一个匹配项match0?
假设文本中有多个发票号,只取第一个(通常是最相关的)
.strip()表示去掉首尾空白字符
2.5 Visualizer
powershell
import cv2
def draw_boxes(img, ocr_result):
img_copy = img.copy()
n_boxes = len(ocr_result['level'])
for i in range(n_boxes):
(x, y, w, h) = (ocr_result['left'][i], ocr_result['top'][i],
ocr_result['width'][i], ocr_result['height'][i])
text = ocr_result['text'][i]
#Only information is available, and the frames are drawn
if len(text.strip()) > 1:
cv2.rectangle(img_copy, (x, y), (x + w, y + h), (0, 255, 0), 2)
return img_copy可视化OCR结果,给pdf中所有信息添加边界框
1,为什么需要复制图片
目的:保留原始图像不被修改,便于对比
2,ocr_result为识别结果的字典
ocr_result'level':Tesseract返回的层级列表
len():获取列表长度,即总边界框数量
补充:
ocr_result返回字典格式

ocr_result'level':

具体举例如下:对于文本"Hello World"的识别


2,绘制矩形框

说明:
- 需要注意Open CV默认颜色格式为BGR。根据BGR参数可知,绘制绿色线框。
- 线框宽度:如果为负数或cv2.FILLED,则填充整个矩形
3. main.py - 批量处理脚本
powershell
import os
import cv2
import pytesseract
import argparse
import logging
import pandas as pd
import matplotlib.pyplot as plt
from src.pdf_converter import convert_pdfs_to_images
from src.preprocess import preprocess_image
from src.ocr_engine import run_ocr, get_full_text
from src.extractor import extract_fields
from src.visualize import draw_boxes
# --- Set up logging ---
logging.basicConfig(
level=logging.INFO, # 日志级别:INFO及以上(INFO, WARNING, ERROR, CRITICAL)
format='[%(asctime)s] %(levelname)s - %(message)s', # 日志格式
datefmt='%Y-%m-%d %H:%M:%S' # 时间格式
)
# --- CLI Args ---
parser = argparse.ArgumentParser(description="Invoice OCR pipeline")
parser.add_argument("--headless", action="store_true", help="Run without showing plots")
args = parser.parse_args()
# --- Paths ---
# 获取脚本所在目录的绝对路径
script_dir = os.path.dirname(os.path.abspath(__file__))
# save files to the paths
pdf_dir = os.path.join(script_dir, "data", "pdf")
image_dir = os.path.join(script_dir, "data", "raw")
visual_dir = os.path.join(script_dir, "data", "visuals")
output_dir = os.path.join(script_dir, "data", "processed")
poppler_bin_path = os.path.join(script_dir, "poppler-24.08.0", "Library","bin")
pytesseract.pytesseract.tesseract_cmd = r"D:\SOFT\Tesseract\tesseract.exe"
os.makedirs(image_dir, exist_ok=True)
os.makedirs(output_dir, exist_ok=True)
os.makedirs(visual_dir, exist_ok=True)
# --- Step 1: Convert all PDFs to images ---
logging.info("Converting PDFs to images...")
convert_pdfs_to_images(pdf_dir=pdf_dir, image_dir=image_dir, dpi=300, poppler_path=poppler_bin_path)
# --- Step 2: Process images ---
summary = [] # 用于存储所有文件的提取结果
for filename in os.listdir(image_dir):
if not filename.lower().endswith((".jpg", ".jpeg", ".png")):
continue
img_path = os.path.join(image_dir, filename)
logging.info(f"Processing: {filename}")
img = cv2.imread(img_path)
if img is None:
logging.warning(f"Failed to load image: {filename}")
continue
# Preprocess + OCR
preprocessed = preprocess_image(img)
ocr_result = run_ocr(preprocessed)
full_text = get_full_text(ocr_result)
# Extract fields
fields = extract_fields(full_text)
fields["source_file"] = filename
summary.append(fields)
# Draw and save visualization
boxed_img = draw_boxes(cv2.cvtColor(img, cv2.COLOR_BGR2RGB), ocr_result)
visual_path = os.path.join(visual_dir, f"{os.path.splitext(filename)[0]}_boxed.jpg")
plt.imsave(visual_path, boxed_img)
# Show plot only if not headless
if not args.headless:
plt.imshow(boxed_img)
plt.axis('off')
plt.title(f"OCR: {filename}")
plt.show()
# --- Step 3: Save output ---
df = pd.DataFrame(summary)
csv_path = os.path.join(output_dir, "invoice_summary.csv")
df.to_csv(csv_path, index=False)
logging.info(f"✅ Done. Output saved to: {csv_path}")3.1 主要作用
- 完全自动化,无需人工干预
- 支持批量处理大量文件
- 适合后台运行和定时任务
- 日志记录详细的处理过程
3.2 准备工作
1,配置日志系统
powershell
format='[%(asctime)s] %(levelname)s - %(message)s', # 日志格式
powershell
# 所有可用变量:
变量名 说明
────────────── ──────────────────────────────────────────
%(name)s Logger的名称(默认是'root')
%(levelno)s 数字形式的日志级别(DEBUG=10, INFO=20等)
%(levelname)s 文本形式的日志级别('DEBUG', 'INFO'等)
%(pathname)s 调用日志记录函数的源文件的完整路径
%(filename)s 文件名部分
%(module)s 模块名(文件名去掉.py)
%(lineno)d 调用日志记录函数的源代码行号
%(funcName)s 调用日志记录函数的函数名
%(created)f 日志创建时间(time.time()返回值)
%(asctime)s 可读的时间字符串
%(msecs)d 毫秒部分
%(relativeCreated)d 相对于Logger创建时间的毫秒数
%(thread)d 线程ID
%(threadName)s 线程名
%(process)d 进程ID
%(message)s 日志消息2,命令行参数解析
powershell
parser = argparse.ArgumentParser(description="Invoice OCR pipeline")
parser.add_argument("--headless", action="store_true", help="Run without showing plots")
args = parser.parse_args()3,路径配置
4,创建必要的目录:
os.makedirs(image_dir, exist_ok=True)
作用:确保输出目录存在,避免保存文件时出错
exist_ok=True:目录已存在时不报错
3.3 核心步骤
步骤一:pdf转图像
1,convert_pdfs_to_images(pdf_dir=pdf_dir, image_dir=image_dir, dpi=300, poppler_path=poppler_bin_path)
参数说明:
pdf_dir:源文件地址
image_dir:目的文件地址
dpi=300:高分辨率转换(OCR推荐)
poppler_path:指定poppler工具位置(Windows必需)
步骤二:处理每张图像
1,summary列表:收集所有发票的提取结果
2,if not filename.lower().endswith((".jpg", ".jpeg", ".png"))
文件过滤:只处理图像文件,跳过其他文件
3,预处理和OCR
preprocess_image(img):图像预处理(灰度化、去噪、二值化等)
run_ocr(preprocessed):执行OCR,返回结构化结果
get_full_text(ocr_result):从OCR结果中提取完整文本
4,字段提取
fields = extract_fields(full_text)
提取业务字段:从OCR文本中提取发票号、日期、金额等
fields"source_file" = filename
添加源文件信息:记录当前处理的文件名
summary.append(fields)
收集结果:将字段字典添加到汇总列表
5,可视化
boxed_img = draw_boxes(cv2.cvtColor(img, cv2.COLOR_BGR2RGB), ocr_result)
转换颜色空间:OpenCV是BGR,matplotlib需要RGB
绘制识别框:在图像上绘制OCR识别的文字边界框
visual_path = os.path.join(visual_dir, f"{os.path.splitext(filename)0}_boxed.jpg")
保存可视化结果:保存为原始名_boxed.jpg
条件显示:根据--headless参数决定是否弹出显示窗口
步骤三:保存输出
df = pd.DataFrame(summary)
转换为DataFrame:将字典列表转换为pandas表格
csv_path = os.path.join(output_dir, "invoice_summary.csv")
df.to_csv(csv_path, index=False)
保存CSV:保存所有发票的提取结果
总结
对于pdf文件中内容的提取,首先是将文件转换为图片,对图片进行预处理后再进行文本的提取。主要受以下两个方面影响:pdf文件类型以及OCR处理的对象就是"视觉信息"。同时,需要对图片进行灰度化,去噪以及二值化处理以增加文字识别的准确率。