1.Doris 简介
官网:
https://doris.apache.org/zh-CN/docs/gettingStarted/what-is-apache-doris
Doris 2.1.10 版本 存算一体架构 (不需要依赖任何的别的技术)
Doris3 存算分离 算(doris 的计算引擎) 存(可以使用第三方比如 hdfs s3 的)也当然支持存算一体
Doris4 假如了 AI 功能
1.1 Doris 概述
Apache Doris 简介
Apache Doris 是一款基于 MPP 架构的高性能、实时分析型数据库 。它以高效、简单和统一的特性著称,能够在亚秒级的时间内返回海量数据的查询结果。Doris 既能支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。
基于这些优势,Apache Doris 非常适合用于报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等场景。用户可以基于 Doris 构建大屏看板、用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
发展历程
Apache Doris 最初是百度 广告报表业务的 Palo 项目。2017 年正式对外开源,2018 年 7 月由百度捐赠给 Apache 基金会进行孵化。在 Apache 导师的指导下,由孵化器项目管理委员会成员进行孵化和运营。2022 年 6 月,Apache Doris 成功从 Apache 孵化器毕业,正式成为 Apache 顶级项目(Top-Level Project,TLP)。
目前,Apache Doris 社区已经聚集了来自不同行业数百家企业的 600 余位贡献者,并且每月活跃贡献者人数超过 120 位。
应用现状
Apache Doris 在中国乃至全球范围内拥有广泛的用户群体。截至目前,Apache Doris 已经在全球超过 5000 家中大型企业的生产环境中得到应用。在中国市值或估值排行前 50 的互联网公司中,有超过 80% 长期使用 Apache Doris,包括百度、美团、小米、京东、字节跳动、阿里巴巴、腾讯、网易、快手、微博等。同时,在金融、消费、电信、工业制造、能源、医疗、政务等传统行业也有着丰富的应用。
在中国,几乎所有的云厂商,如阿里云、华为云、天翼云、腾讯云、百度云、火山引擎等,都在提供托管的 Apache Doris 云服务。
使用场景
数据源经过各种数据集成和加工处理后,通常会进入实时数据仓库 Doris和离线湖仓(如 Hive、Iceberg 和 Hudi),广泛应用于 OLAP 分析场景,如下图所示:Lake
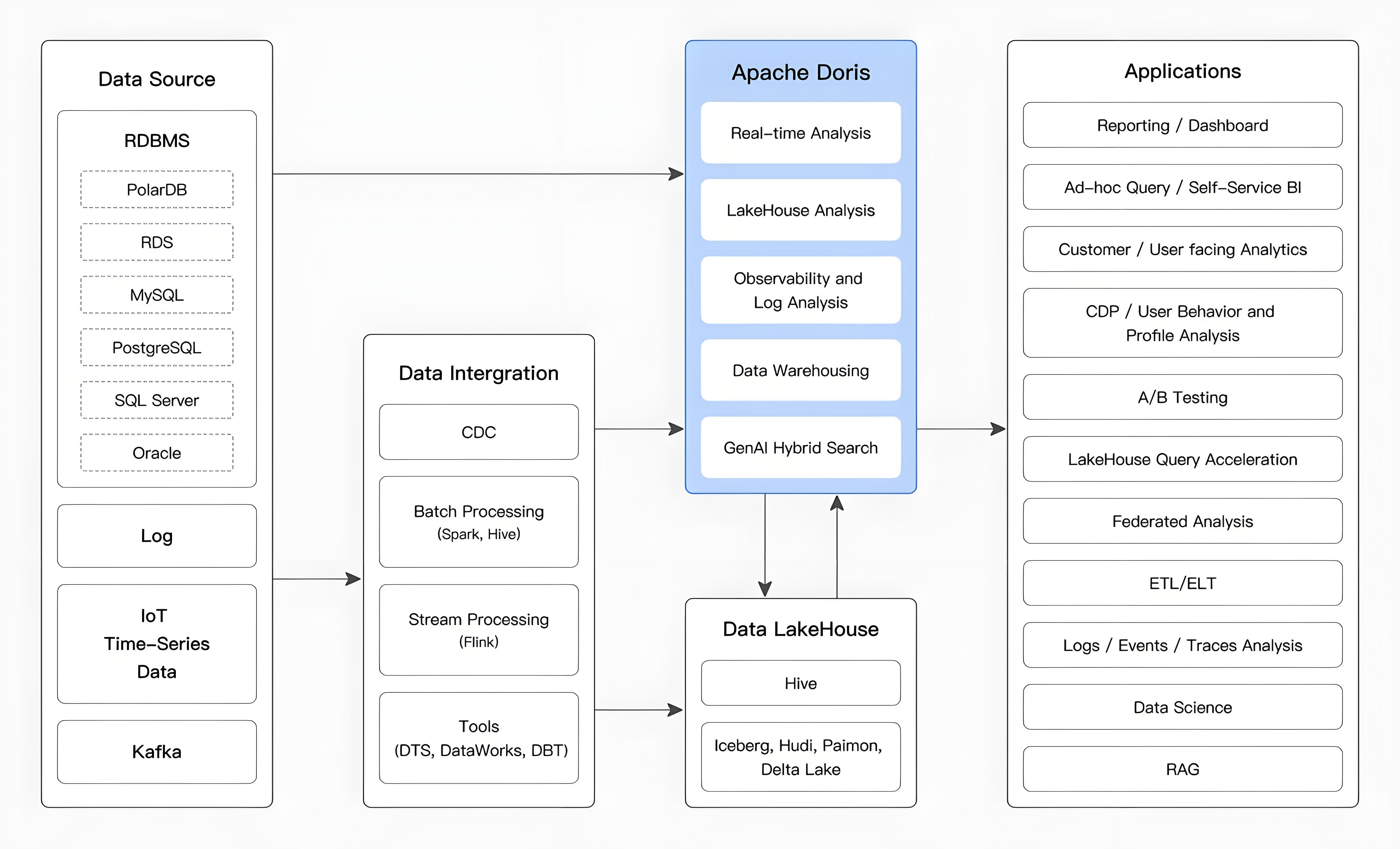
Intergration: 集成的意思
Apache Doris 主要应用于以下场景:
- 实时数据分析:
-
- 实时报表与实时决策: 为企业内外部提供实时更新的报表和仪表盘,支持自动化流程中的实时决策需求。
- 交互式探索分析: 提供多维数据分析能力,支持对数据进行快速的商业智能分析和即席查询(Ad Hoc),帮助用户在复杂数据中快速发现洞察。
- 用户行为与画像分析: 分析用户参与、留存、转化等行为,支持人群洞察和人群圈选等画像分析场景。
- 湖仓融合分析:
-
- 湖仓查询加速: 通过高效的查询引擎加速湖仓数据的查询。
- 多源联邦分析: 支持跨多个数据源的联邦查询,简化架构并消除数据孤岛。
- 实时数据处理: 结合实时数据流和批量数据的处理能力,满足高并发和低延迟的复杂业务需求。
- 半结构化数据分析:
-
- 日志与事件分析: 对分布式系统中的日志和事件数据进行实时或批量分析,帮助定位问题和优化性能
整体架构
Apache Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL。用户可以通过各类客户端工具访问 Apache Doris,并支持与 BI 工具无缝集成。
存算一体架构
Apache Doris 存算一体架构精简且易于维护。它包含以下两种类型的进程:
- Frontend (FE): 主要负责接收用户请求、查询解析和规划、元数据管理以及节点管理。
- Backend (BE): 主要负责数据存储和查询计划的执行。数据会被切分成数据分片(Shard),在 BE 中以多副本方式存储。
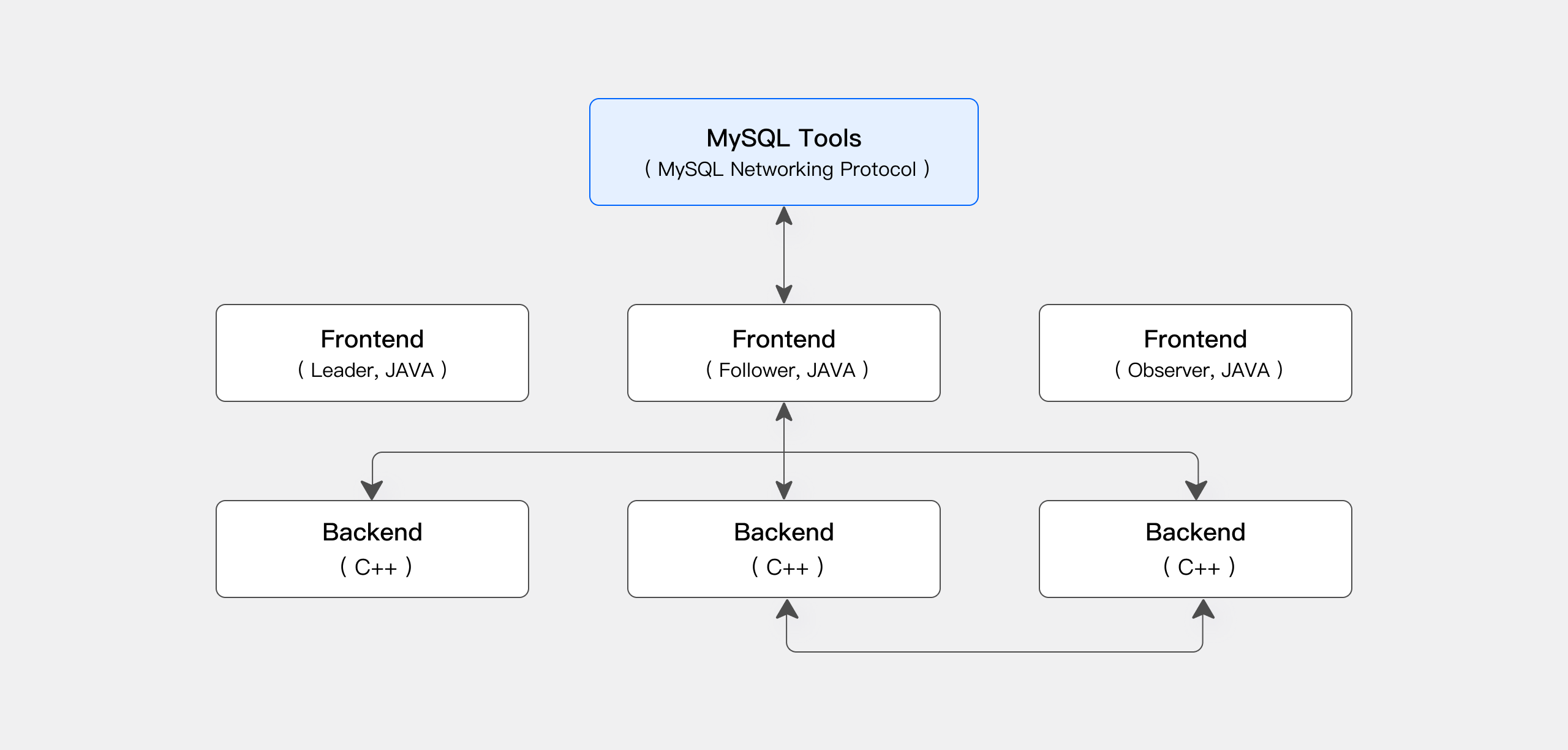
在生产环境中,可以部署多个 FE 节点以实现容灾备份。每个 FE 节点都会维护完整的元数据副本。FE 节点分为以下三种角色:
|----------|------------------------------------------------------------------------------------|
| 角色 | 功能 |
| Master | FE Master 节点负责元数据的读写。当 Master 节点的元数据发生变更后,会通过 BDB JE 协议同步给 Follower 或 Observer 节点。 |
| Follower | Follower 节点负责读取元数据。当 Master 节点发生故障时,可以选取一个 Follower 节点作为新的 Master 节点。 |
| Observer | Observer 节点负责读取元数据,主要目的是增加集群的查询并发能力。Observer 节点不参与集群的选主过程。 |
FE 和 BE 进程都可以横向扩展。单个集群可以支持数百台机器和数十 PB 的存储容量。FE 和 BE 进程通过一致性协议来保证服务的高可用性和数据的高可靠性。存算一体架构高度集成,大幅降低了分布式系统的运维成本。
技术特点
Doris 提供了高效的 SQL 接口,并完全兼容 MySQL 协议。其查询引擎基于 MPP(大规模并行处理)架构,能够高效执行复杂的分析查询,并实现低延迟的实时查询。通过列式存储技术对数据进行编码与压缩,显著优化了查询性能和存储压缩比。
使用接口
Apache Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL。用户可以通过各类客户端工具访问 Apache Doris,并支持与 BI 工具无缝集成。Apache Doris 当前支持多种主流的 BI 产品,包括 Smartbi、DataEase、FineBI、Tableau、Power BI、Apache Superset 等。只要支持 MySQL 协议的 BI 工具,Apache Doris 就可以作为数据源提供查询支持。
存储引擎
在存储引擎方面,Apache Doris 采用列式存储(Hbase 也是列式存储的),按列进行数据的编码、压缩和读取,能够实现极高的压缩比,同时减少大量非相关数据的扫描,从而更有效地利用 IO 和 CPU 资源。
Apache Doris 也支持多种索引结构,以减少数据的扫描:
- Sorted Compound Key Index: 最多可以指定三个列组成复合排序键。通过该索引,能够有效进行数据裁剪,从而更好地支持高并发的报表场景。
- Min/Max Index: 有效过滤数值类型的等值和范围查询。
- BloomFilter Index: 对高基数列的等值过滤裁剪非常有效。
- Inverted Index: 能够对任意字段实现快速检索。
在存储模型方面,Apache Doris 支持多种存储模型,针对不同的场景做了针对性的优化:
- 明细模型(Duplicate Key Model): 适用于事实表的明细数据存储。
- 主键模型(Unique Key Model): 保证 Key 的唯一性,相同 Key 的数据会被覆盖,从而实现行级别数据更新。
- 聚合模型(Aggregate Key Model): 相同 Key 的 Value 列会被合并,通过提前聚合大幅提升性能。
Apache Doris 也支持强一致的单表物化视图和异步刷新的多表物化视图。单表物化视图在系统中自动刷新和维护,无需用户手动选择。多表物化视图可以借助集群内的调度或集群外的调度工具定时刷新,从而降低数据建模的复杂性。
查询引擎
Apache Doris 采用大规模并行处理(MPP)架构 ,支持节点间和节点内并行执行,以及多个大型表的分布式 Shuffle Join,从而更好地应对复杂查询。
Doris的查询引擎采用MPP(大规模并行处理)架构,结合向量化执行技术,能够实现节点间和节点内的并行执行。该引擎支持多个大表的分布式Shuffle Join,能够高效处理复杂查询场景。
Doris查询引擎的核心特性包括:
1. 向量化执行引擎
所有内存结构按照列式布局,大幅减少虚函数调用、提升Cache命中率,并高效利用SIMD指令。在宽表聚合场景下,性能是非向量化引擎的5-10倍。
2. 自适应查询执行
采用Adaptive Query Execution技术,根据运行时统计信息动态调整执行计划。通过Runtime Filter技术,能够在运行时生成过滤器并推送到Probe侧,大幅减少数据扫描量,加速Join性能。支持In/Min/Max/Bloom Filter等多种过滤器类型。
3. Pipeline执行模型
将查询分解为多个子任务并行执行,充分利用多核CPU能力,同时通过限制查询线程数解决线程膨胀问题。Pipeline执行引擎减少数据拷贝和共享,优化排序和聚合操作,显著提高查询效率和吞吐量。
4. 优化器策略
采用CBO(基于代价优化)、RBO(基于规则优化)和HBO(基于历史优化)相结合的优化策略。RBO支持常量折叠、子查询重写和谓词下推等优化,CBO支持Join Reorder等优化,HBO能够基于历史查询信息推荐最优执行计划。
5. 分布式执行流程
查询执行采用"集中调度+分布式计算"模式:FE(Frontend)负责SQL解析、优化和计划生成,BE(Backend)节点负责数据扫描、计算和聚合操作。通过数据分片(Tablet)机制实现并行扫描,BE间通过Pipeline模式并行执行任务,必要时进行数据Shuffle。
这种架构设计使得Doris能够在大规模数据场景下保持毫秒级到秒级的查询响应,广泛应用于实时报表分析、即席查询等高并发场景。
MPP数据库(大规模并行处理数据库)是一种分布式数据库架构,通过将数据分散到多个节点并行处理,实现高性能分析查询。核心特点:无共享架构、节点独立计算、线性扩展能力,适合海量数据分析场景。典型代表:Greenplum、Vertica、ClickHouse。
MPP数据库如何工作:
- 数据分片:交易数据按时间或客户ID分散到10个服务器节点(如2020年数据在节点1,2021年在节点2...)。
- 并行计算:每个节点独立扫描本地数据(如节点1只计算2020年的交易),最后汇总结果。
- 高速返回:10个节点同时工作,比单机快10倍以上,几分钟完成分析。
默认端口
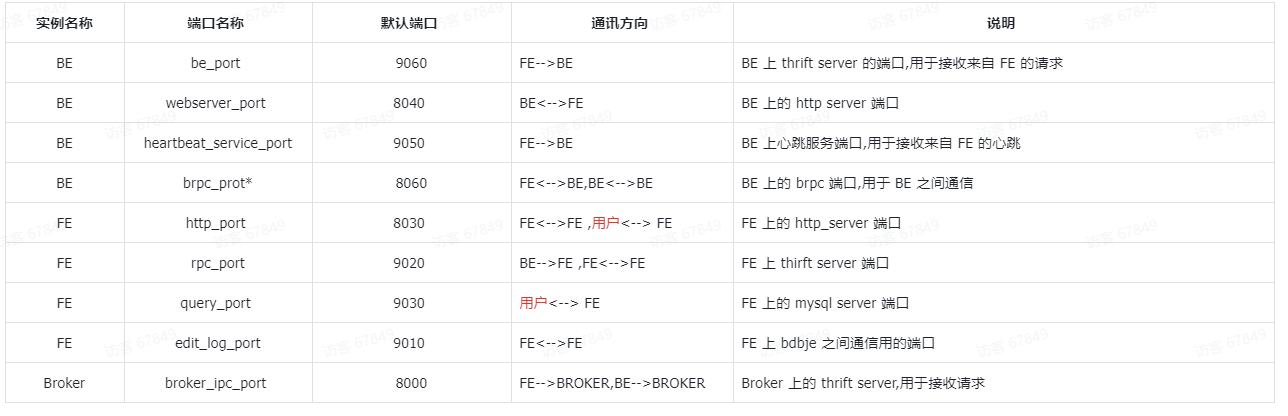
我们的理解:doris 数据库是一个 mpp 数据库,支持海量数据的存储以及查询分析极快(达到亚秒级),支持分布式部署,有两部分组成 FE 和 BE,而且无需任何大数据技术的支持!
目前来讲:数据量达到一定级别,doris 性能就跟不上了。

2.安装
Apache Doris 2.1.10 版本已于 2025 年 05 月 17 日正式发布
官方安装文档:
下载:

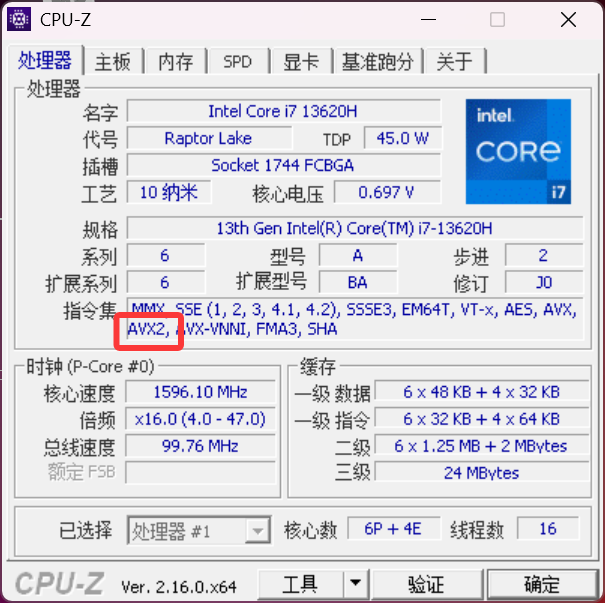
可以使用 cpu 工具查看,cpu 知否支持 avx2 指令集:
2.1 安装前的准备工作
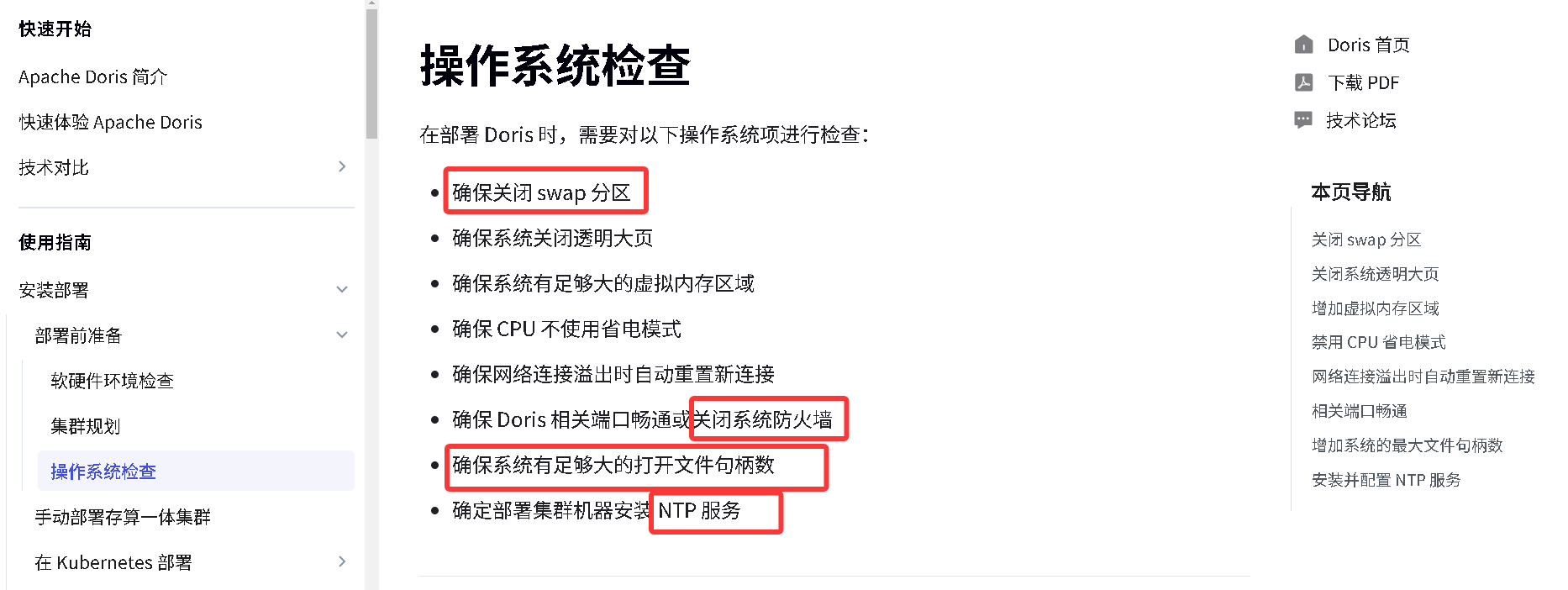

设置系统最大文件打开句柄数
1.打开文件
vi /etc/security/limits.conf
2.在文件最后添加下面几行信息(注意* 也要复制进去)
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536
ulimit -n 65536 临时生效
修改完文件后需要重新启动虚拟机
重启永久生效,也可以用
如果不修改这个句柄数大于等于60000,回头启动doris的be节点的时候就会报如下的错
如果报错:Please set the maximum number of open file descriptors to be 65536 using 'ulimit -n 65536'.
代表句柄数没有生效,需要临时设置或者重启电脑
第一次启动的时候可能会报错
Please set vm.max_map_count to be 2000000 under root using 'sysctl -w vm.max_map_count=2000000'.
解决方案:
命令行输入:sysctl -w vm.max_map_count=2000000记得将该文件分发到不同的服务器上。
xsync.sh /etc/security/limits.conf
设置文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量
临时生效:
sysctl -w vm.max_map_count=2000000
永久生效
vim /etc/sysctl.conf
在文件最后一行添加
vm.max_map_count=2000000
让他永久生效
sysctl -p
检查是否生效
sysctl -a|grep vm.max_map_count时钟同步
Doris 的元数据要求时间精度要小于5000ms,所以所有集群所有机器要进行时钟同步,避免因为时钟问题引发的元数据不一致导致服务出现异常。
systemctl restart chronyd
这个命令写完之后需要等一会儿才会变为新日期。
xcall.sh ntpdate time1.aliyun.com关闭交换分区(swap)
交换分区是linux用来当做虚拟内存用的磁盘分区;
linux可以把一块磁盘分区当做内存来使用(虚拟内存、交换分区);
Linux使用交换分区会给Doris带来很严重的性能问题,建议在安装之前禁用交换分区;
1、查看 Linux 当前 Swap 分区
free -m
2、关闭 Swap 分区 (临时关闭)
swapoff -a
[root@hadoop11 app]# free -m
total used free shared buff/cache available
Mem: 5840 997 4176 9 666 4604
Swap: 6015 0 6015
[root@hadoop11 app]# swapoff -a
3.验证是否关闭成功
[root@hadoop11 app]# free -m
total used free shared buff/cache available
Mem: 5840 933 4235 9 671 4667
Swap: 0 0 0
记得三台都需要关闭:
xcall.sh swapoff -a如果想永久关闭,需要修改配置文件:
vi /etc/fstab可以按照如下方式进行操作:
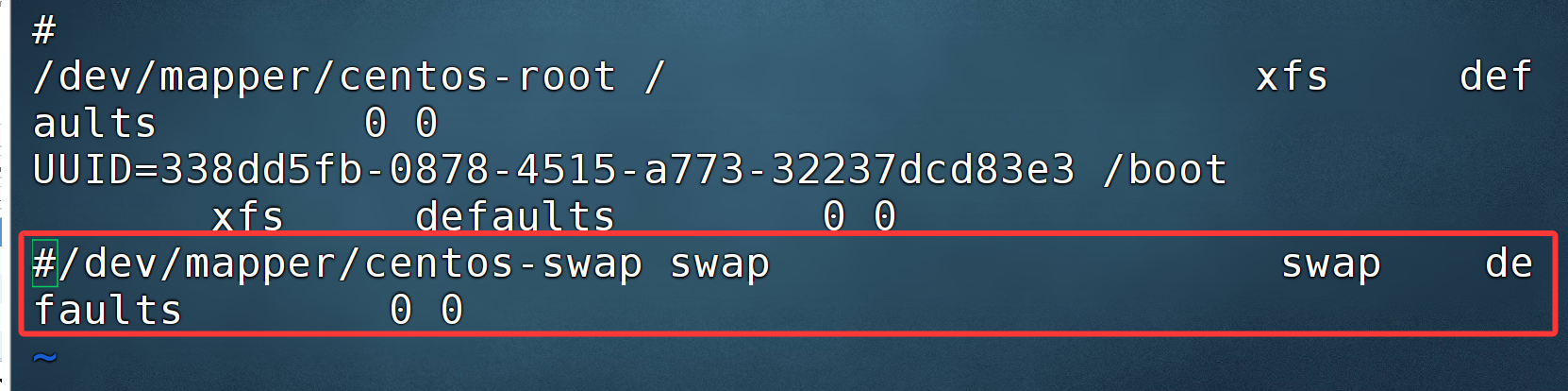
千万不要粘贴官方给的配置文件,以供参考
假如你粘贴了官网这个配置,重启后报如下错误:(输入 root 的密码可以进入,在将其文件改回来)

所以解决方案有两种:
方案一:将 swap 注释取消,每次重启使用swapoff -a 关闭
方案二:检查你是否粘贴了官方文档中的 内容,如果是删除掉,仅仅注释这行 swap 即可。
分发一下:
xsync.sh /etc/fstab注意事项:
- FE 的磁盘空间主要用于存储元数据,包括日志和 image。通常从几百 MB 到几个GB 不等。
- BE 的磁盘空间主要用于存放用户数据,总磁盘空间按用户总数据量* 3(3 副本)计算,然后再预留额外 40%的空间用作后台 compaction 以及一些中间数据的存放。
- 一台机器上可以部署多个 BE 实例,但是只能部署一个 FE(FE 可以部署三台用于自动容灾)。如果需要 3 副本数据,那么至少需要 3 台机器各部署一个 BE 实例(而不是 1 台机器部署 3 个 BE 实例)。多 个 FE 所在服务器的时钟必须保持一致(允许最多 5 秒的时钟偏差)
- 测试环境也可以仅适用一个 BE 进行测试。实际生产环境,BE 实例数量直接决定了整体查询延迟。
- 所有部署节点关闭 Swap。
- FE 节点数据至少为 1(1 个 Follower)。当部署 1 个 Follower 和 1 个 Observer 时,可以实现读高可用。当部署 3 个 Follower 时,可以实现读写高可用(HA)。
- Follower 的数量必须为奇数,Observer 数量随意。
- 根据以往经验,当集群可用性要求很高时(比如提供在线业务),可以部署 3 个Follower 和 1-3 个 Observer。如果是离线业务,建议部署 1 个 Follower 和 1-3 个 Observer。
- Broker 是用于访问外部数据源(如 HDFS)的进程。通常,在每台机器上部署一个 broker 实例即可。
将三台虚拟机重新启动,可以使用 reboot 命令。
2.2安装FE
官方手动安装手册:
-
上传apache-doris-2.1.10-bin-x64.tar.gz到linux
-
解压
cd /opt/modules/
tar -zxvf apache-doris-2.1.10-bin-x64.tar.gz -C /opt/installs/
mv apache-doris-2.1.10-bin-x64/ dorisdoris1.x 没有doris-meta文件夹,doris2.x已经有这个文件夹了,但是不建议直接使用
-
修改配置文件
-- fe.conf文件:位于fe安装目录下的conf目录
vi /opt/installs/doris/fe/conf/fe.confJAVA_OPTS="-Xmx16384m -XX:+UseMembar -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xloggc:DORIS_HOME/log/fe.gc.log.DATE"
priority_networks = 192.168.233.133/24
lower_case_table_names = 1
JAVA_HOME = /opt/installs/jdk
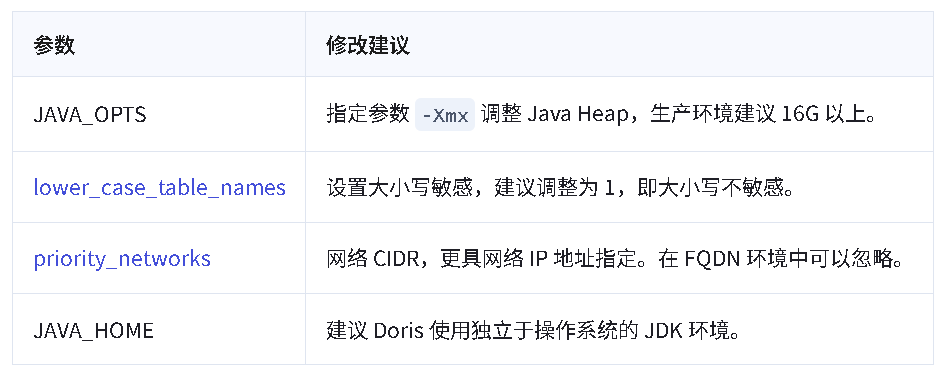
4、环境变量配置
export DORIS_HOME=/opt/installs/doris
export PATH=$PATH:$DORIS_HOME/fe/bin:$DORIS_HOME/be/bin
xsync.sh /etc/profile
source /etc/profile5、 分发集群(如果是伪分布的不需要分发)
xsync.sh /opt/installs/doris为了以后将来可能会启动多台 fe,最好将 bigdata02 和 03 上的 fe.conf 中的 ip 修改为对应节点上的 ip
我们此处只需要一台 Fe,所以不修改
6、 启动
进入到fe的bin目录下执行
[root@hadoop11 bin]# start_fe.sh --daemon生产环境强烈建议单独指定目录不要放在 Doris 安装目录下,最好是单独的磁盘(如果有 SSD 【固态】 最好)。 如果机器有多个 ip, 比如内网外网, 虚拟机 docker 等, 需要进行 ip 绑定,才能正确识别。 JAVA_OPTS 默认 java 最大堆内存为 4GB,建议生产环境调整至 16G 以上。

如果 FE 启动失败,可以查看对应的 log 日志
E 进程将在后台启动,日志默认保存在 log/ 目录。如果启动失败,可通过查看 log/fe.log 或 log/fe.out 文件获取错误信息。
com.sleepycat.je.rep.ReplicaWriteException: (JE 18.3.12) Problem closing transaction 27. The current state is:UNKNOWN. The node transitioned to this state at:Thu Dec 19 16:44:14 CST 2024
如果遇到这个错误,一般是你的磁盘空间,不够 6G,可以通过删除一些无用的安装包或者日志。
然后删除元数据后重启启动,否则会报这个错误:
2024-12-19 16:48:25,483 ERROR (stateListener|67) Env.checkCurrentNodeExist():1540 current node 192.168.177.128:9010 is not added to the cluster, will exit. Your FE IP maybe changed, please set 'priority_networks' config in fe.conf properly.
检查 FE 启动状态
通过 MySQL 客户端连接 Doris 集群,初始化用户为 root,默认密码为空。
mysql -uroot -P<fe_query_port> -h<fe_ip_address>
mysql -uroot -P9030 -h127.0.0.1 -e "show frontends;"启动 fe 需要 一点时间,如果连接不成功,稍微等一会儿。
打印混乱,可以通过粘贴到 nodepad++等工具中展示完全:

链接到 Doris 集群后,可以通过 show frontends 命令查看 FE 的状态,通常要确认以下几项
-
- Alive 为
true表示节点存活; - Join 为
true表示节点加入到集群中,但不代表当前还在集群内(可能已失联); - IsMaster 为 true 表示当前节点为 Master 节点。
- Alive 为
查看 web 界面
http://bigdata01:8030/ 账号 root,密码是空
通过 MySQL 客户端连接 Doris 集群,初始化用户为 root,默认密码为空。
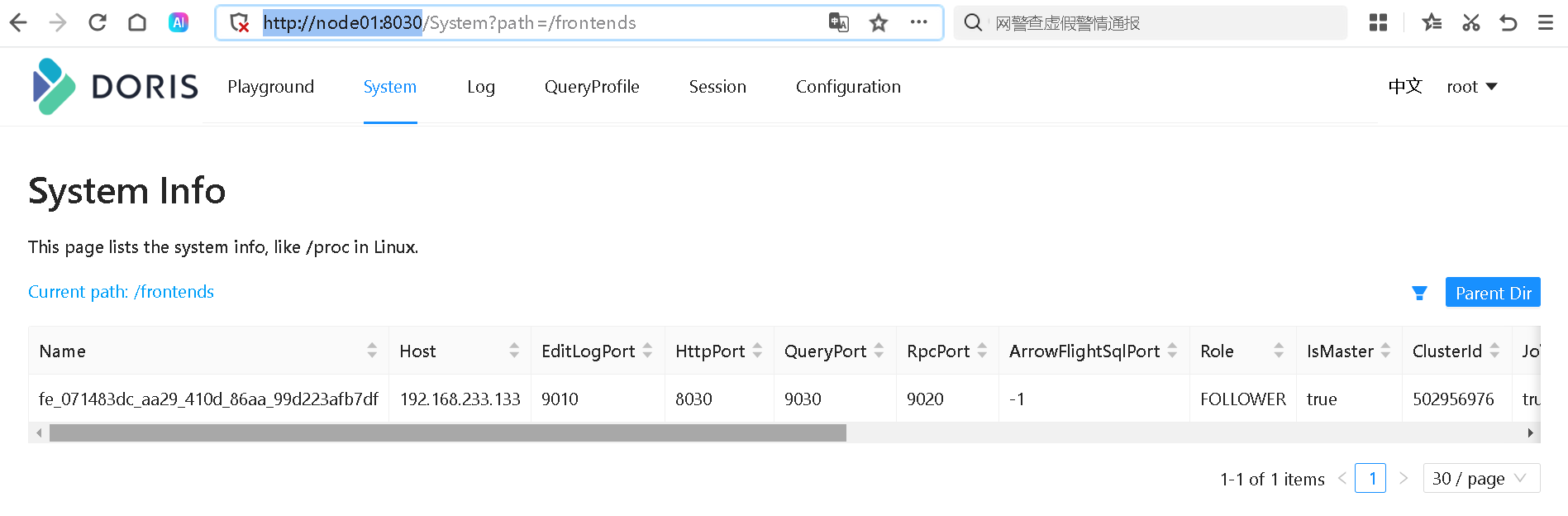
可能引发的一个问题:
当我启动 ResourceManager 的时候,会报 8030 端口被占用了。原因是 doris 启动会占用该端口,解决办法:要么使用哪个启动哪个,要么修改 doris 的端口。8030 端口属于 FE 的端口。
解决步骤:
查看端口使用情况:
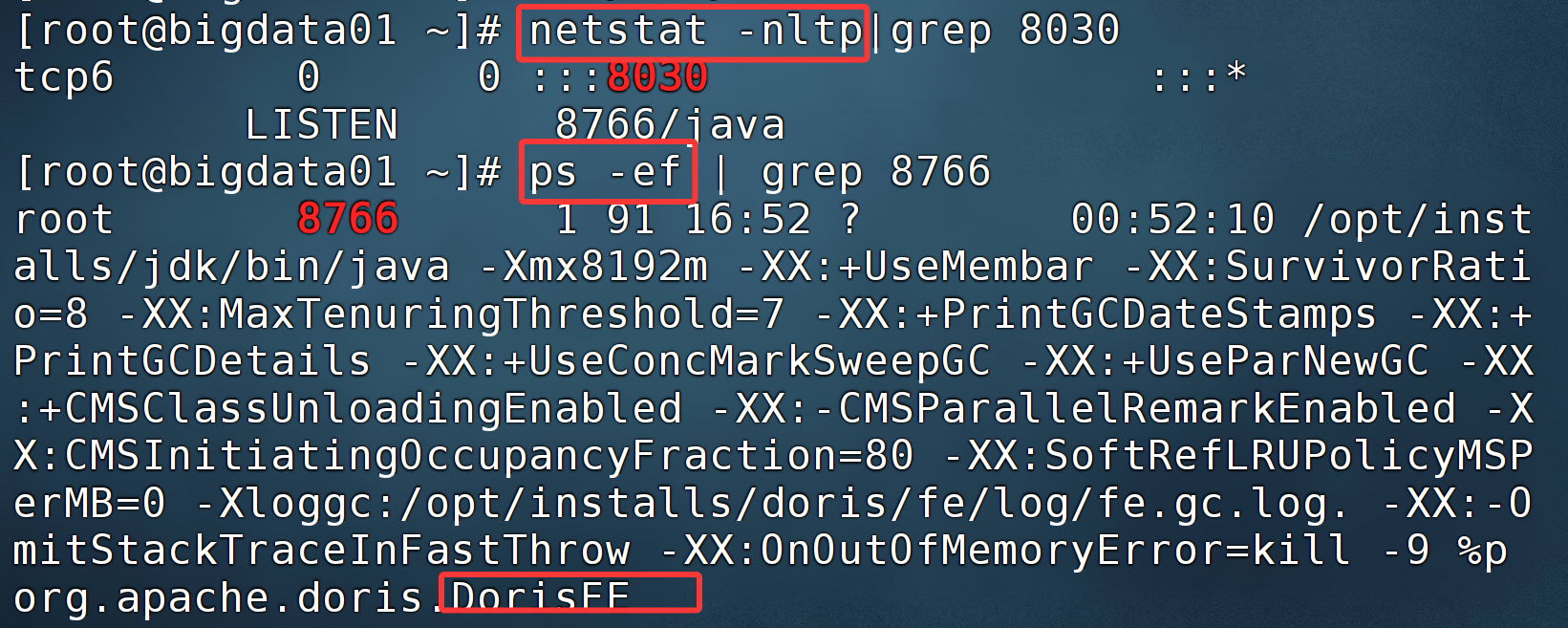
还有一个问题:为什么启动后,FE 显示角色为 Follwer?

2.3安装BE
创建 BE 数据存放目录(每个节点)
mkdir /opt/installs/doris/doris-storage1
mkdir /opt/installs/doris/doris-storage2进入到be的conf目录下修改配置文件
vim /opt/installs/doris/be/conf/be.conf
storage_root_path=/opt/installs/doris/doris-storage1;/opt/installs/doris/doris-storage2
priority_networks = 192.168.233.128/24
JAVA_HOME = /opt/installs/jdk
cd /opt/installs/doris/be/conf
xsync.sh be.conf
记得修改bigdata02和03的IP地址
第一次启动的时候可能会报错
Please set vm.max_map_count to be 2000000 under root using 'sysctl -w vm.max_map_count=2000000'.
解决方案:
命令行输入:sysctl -w vm.max_map_count=2000000
如果报错:Please set the maximum number of open file descriptors to be 65536 using 'ulimit -n 65536'.注意事项:
storage_root_path 默认在 be/storage 下,需要手动创建该目录。多个路径之间使用英文状态的分号;分隔(最后一个目录后不要加)。
可以通过路径区别存储目录的介质,HDD 或 SSD。可以添加容量限制在每个路径的末尾,通过英文状态逗号,隔开,如:
storage_root_path=/home/disk1/doris.HDD,50;/home/disk2/doris.SSD,10;/home/disk2/doris
说明:
/home/disk1/doris.HDD,50,表示存储限制为 50GB,HDD;
/home/disk2/doris.SSD,10,存储限制为 10GB,SSD;
/home/disk2/doris,存储限制为磁盘最大容量,默认为 HDD
公司只有一台服务器,这台服务器上有一个 mysql,这个 mysql 满了(磁盘满了)
他想把这个服务器再加一个磁盘,然后把 mysql 的数据都移动到这个磁盘,不敢动?
他的想法跟你一样天真:把 mysql 的数据文件拷贝到新磁盘,然后,修改哪个配置文件,就可以搞定。
思路:
1、删点别的东西呗
2、删除点无用的数据
3、最笨的方法:将 mysql 中每一个表的数据导出成 sql 文件 ,然后备份
4、假如有第二台服务器的话,做个 mysql 的主从复制 主 --> 从 ,通过从节点起到备份的作用
5、查询 mysql 是否支持 指定多个存储盘,进行存储
6、是否可以将以前的数据拷贝到新的硬盘上,然后修改配置文件的指向,指向新的盘符 (没试过)
7、现在本地的 linux 虚拟机上找一个新的数据库,写入一些数据,然后将以上思路实施一下,如果可以,再在服务器上进行
这样就好了嘛?不是哦
be可以先不启动,因为启动也没啥用。
因为FE和BE两个都是单独的个体,所以他俩相互间还不认识,就需要我们通过mysql的客户端将他们建立起联系
如果没有装mysql的,记得先装mysql
使用 MySQL Client 连接 FE
mysql -h bigdata01 -P 9030 -uroot
第一次没有密码可以进入。查看 BE 状态
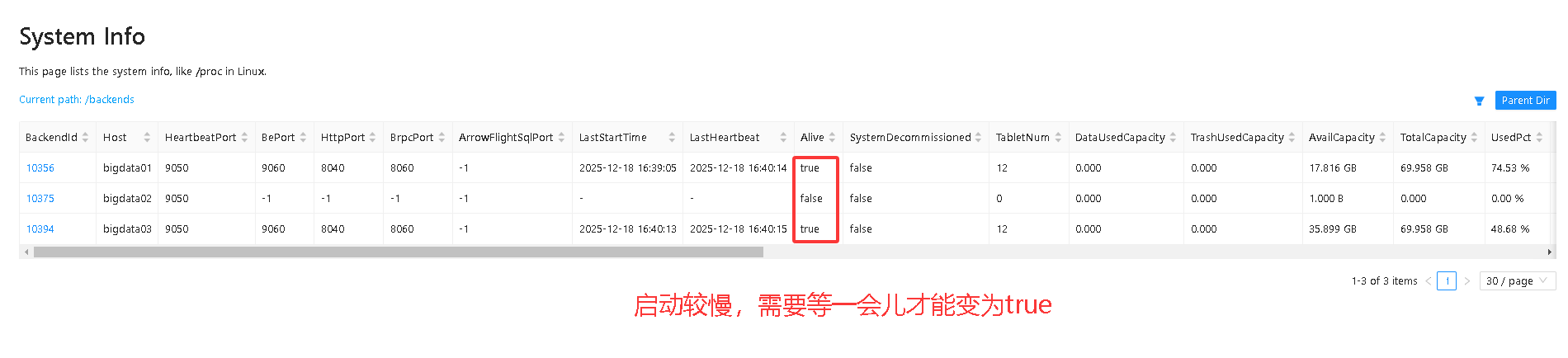
SHOW PROC '/backends'\G;
Alive 为 false 表示该 BE 节点还是死的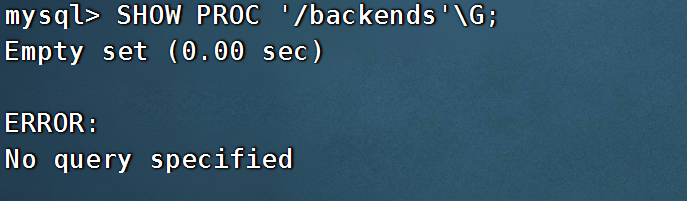
添加BE
mysql> ALTER SYSTEM ADD BACKEND "bigdata01:9050";
如果是全分布的,需要输入三个命令
mysql> ALTER SYSTEM ADD BACKEND "bigdata02:9050";
mysql> ALTER SYSTEM ADD BACKEND "bigdata03:9050";启动BE
启动 BE(每个节点)
start_be.sh --daemon
启动后再次查看BE的节点
mysql -h bigdata01 -P 9030 -uroot -p123456
SHOW PROC '/backends'\G;
Alive 为 true 表示该 BE 节点存活。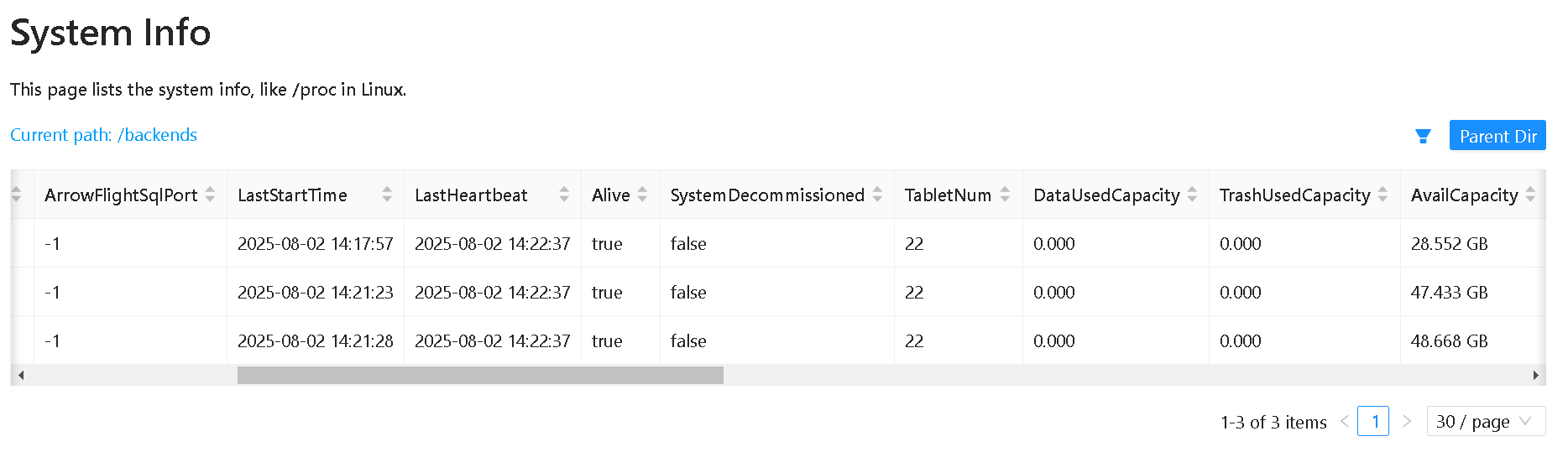
2.5 验证集群正确性
-- create a test database
create database testdb;
-- create a test table
CREATE TABLE testdb.table_hash
(
k1 TINYINT,
k2 DECIMAL(10, 2) DEFAULT "10.5",
k3 VARCHAR(10) COMMENT "string column",
k4 INT NOT NULL DEFAULT "1" COMMENT "int column"
)
COMMENT "my first table"
DISTRIBUTED BY HASH(k1) BUCKETS 32;DISTRIBUTED BY HASH(k1) BUCKETS 32包含以下几个关键信息:
- 数据分布方式:
HASH(k1)表示数据将按照k1列的哈希值进行分布
-
- 相同k1值的数据会被分配到同一个数据分片(Tablet)中
- 这种分布方式有利于基于k1的等值查询和join操作
- 分片数量:
BUCKETS 32表示将表数据划分为32个分片(Tablet)
-
- 每个分片是数据存储和计算的基本单元
- 分片数量影响查询并行度和数据均衡性
2.6 修改 Doris 集群密码
在创建 Doris 集群时,系统会自动创建一个名为 root 的用户,并默认设置其密码为空。为了提高安全性,建议在集群创建后立即为 root 用户设置一个新密码
SET PASSWORD = PASSWORD('123456');
2.7 使用DataGrip连接doris
3.数据表设计
3.1字段类型
https://doris.apache.org/zh-CN/docs/table-design/data-type
|-------------------------------|--------------|--------------------------------------------------------------------------------------------------------------------------------|
| TINYINT | 1 字节 | 范围:-2^7 + 1 ~ 2^7 - 1 |
| SMALLINT | 2 字节 | 范围:-2^15 + 1 ~ 2^15 - 1 |
| INT | 4 字节 | 范围:-2^31 + 1 ~ 2^31 - 1 |
| BIGINT | 8 字节 | 范围:-2^63 + 1 ~ 2^63 - 1 |
| LARGEINT | 16 字节 | 范围:-2^127 + 1 ~ 2^127 - 1 |
| FLOAT | 4 字节 | 支持科学计数法 |
| DOUBLE | 12 字节 | 支持科学计数法 |
| DECIMAL(precision, scale) | 16 字节 | 保证精度的小数类型。默认是DECIMAL(10, 0) ,precision: 1 ~ 27 ,scale: 0 ~ 9,其中整数部分为 1 ~ 18,不支持科学计数法 |
| DATE | 3 字节 | 范围:0000-01-01 ~ 9999-12-31 |
| DATETIME | 8 字节 | 范围:0000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| CHAR(length) | | 定长字符串。长度范围:1 ~ 255。默认为 1 |
| VARCHAR(length) | | 变长字符串。长度范围:1 ~ 65533 |
| BOOLEAN | | 与 TINYINT 一样,0 代表 false,1 代表 true |
| HLL | 1~16385 个字节 | hll 列类型,不需要指定长度和默认值,长度根据数据的聚合程度系统内控制,并且 HLL 列只能通过 配套的hll_union_agg、Hll_cardinality、hll_hash 进行查询或使用 |
| BITMAP | | bitmap 列类型,不需要指定长度和默认值。表示整型的集合,元素最大支持到 2^64 - 1 |
| STRING | | 变长字符串,0.15 版本支持,最大支持 2147483643 字节(2GB-4),长度还受 be 配置`string_type_soft_limit`, 实际能存储的最大长度取两者最小值。只能用在 value 列,不能用在 key列和分区、分桶列 |
此处有 varchar 和 string, string 单个字段都可以插入高达 2G 的数据,并且是弹性的。
结论:我们使用 string 比较多。

3.2 表的基本概念
创建表
使用 CREATE TABLE 语句在 Doris 中创建一个表,也可以使用 CREATE TABKE LIKE 或 CREATE TABLE AS 子句从另一个表派生表定义。
表名
Doris 中表名默认是大小写敏感的,可以在第一次初始化集群时配置lower_case_table_names为大小写不敏感的。默认的表名最大长度为 64 字节,可以通过配置table_name_length_limit更改,不建议配置过大。创建表的语法请参考CREATE TABLE。
3.2.1 Row & Column
一张表包括行(Row)和列(Column);
Row 即用户的一行数据。Column 用于描述一行数据中不同的字段。
doris中的列分为两类: key列和value列
key列在doris中有两种作用:
聚合表模型中,key是聚合和排序的依据
其他表模型中,key是排序依据
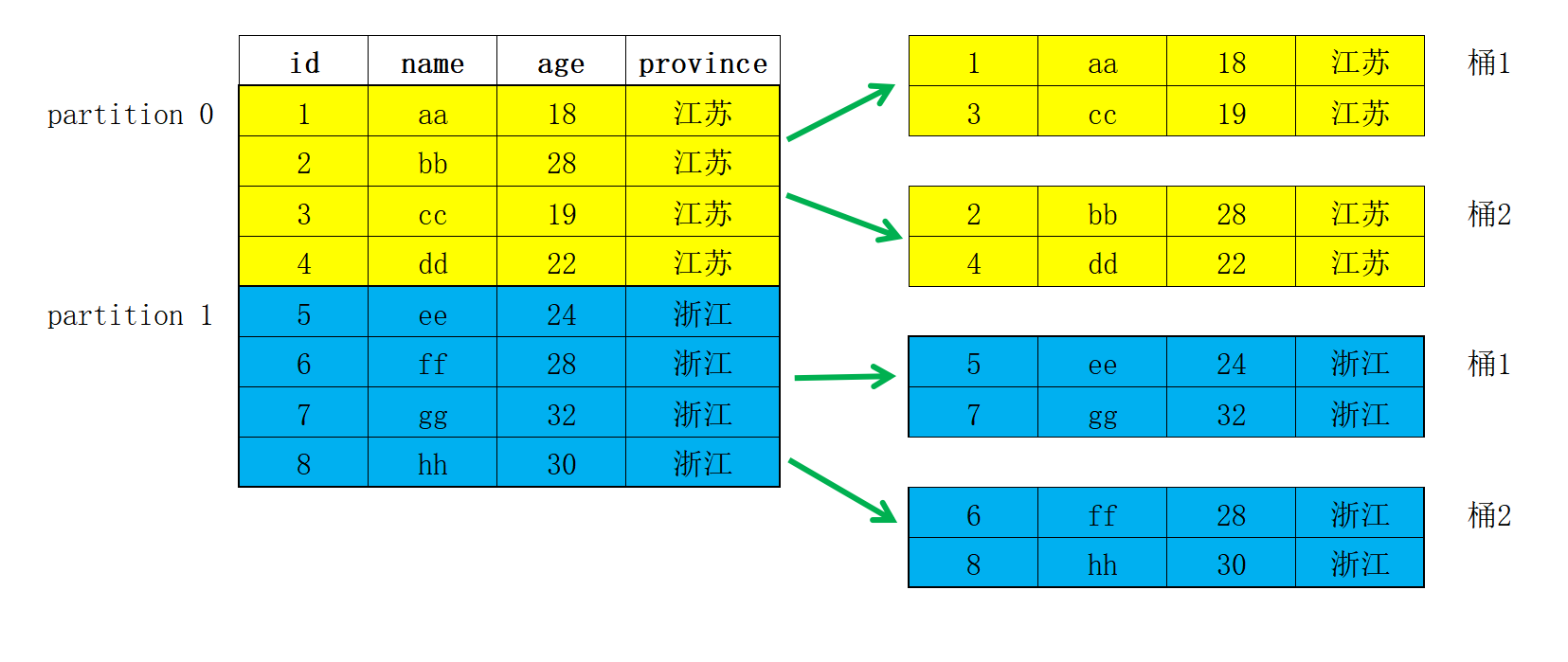
3.2.2 分区与分桶
- partition(分区):是在 逻辑上 将一张表按行(横向)划分
- tablet(又叫bucket,分桶):在 物理上 对一个分区再按行(横向)划分
3.2.2.1 Partition
- Partition 列可以指定一列或多列,在聚合模型中,分区列必须为 KEY 列。
- 不论分区列是什么类型,在写分区值时,都需要加双引号。
- 分区数量理论上没有上限。
- 当不使用 Partition 建表时,系统会自动生成一个和表名同名的,全值范围的 Partition。该 Partition 对用户不可见,并且不可删改。
- 创建分区时不可添加范围重叠的分区。

手动分区
1)Range 分区
range分区创建语法
建表语句中的 key,不是主键的意思,是什么意思具体需要看是什么表模型。
假如是DUPLICATE(明细类型),此处的 key 只有两个作用,第一个作用是分区 ,分桶字段必须是 key 键字段,第二个作用主要用于排序使用。
假如是 AGGREGATE(聚合类型),此处的 key 主要用于分组聚合使用。
select class,sum(score) from a group by class;
假如是 UNIQUE 类型(主键类型),这个的 key 主要用于区分是否唯一。
create database test;
CREATE TABLE IF NOT EXISTS test.example_range_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别"
)
ENGINE=OLAP
DUPLICATE KEY(`user_id`, `date`) -- 表模型
-- 分区的语法
PARTITION BY RANGE(`date`) -- 指定分区类型和分区列
(
PARTITION `p202201` VALUES LESS THAN("2022-02-01"),
PARTITION `p202202` VALUES LESS THAN("2022-03-01"),
PARTITION `p202203` VALUES LESS THAN("2022-04-01"),
PARTITION `p202204` VALUES LESS THAN("2022-05-01"),
PARTITION `p202205` VALUES LESS THAN("2022-06-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 2
PROPERTIES
(
"replication_num" = "1"
);
副本是1 ,因为我们搭建的doris 只有一台,如果有三台,副本数可以是3
alter table test.example_range_tbl add partition `p202206-07` values less than ('2022-08-01')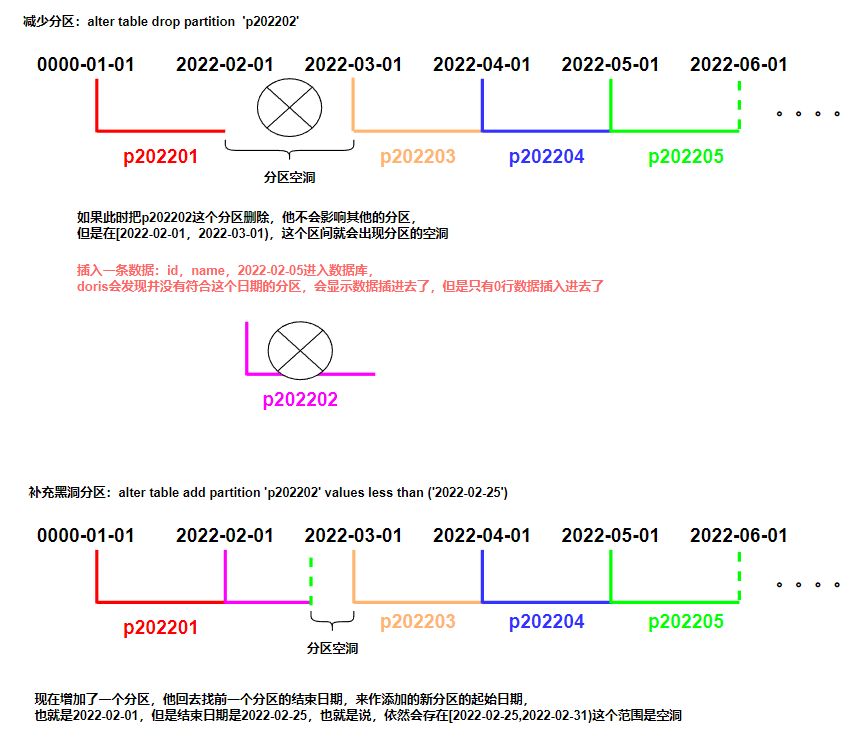
alter table test.example_range_tbl drop partition `p202202`- 分区列通常为时间列,以方便的管理新旧数据。
- Partition 支持通过 VALUES LESS THAN (...) 仅指定上界,系统会将前一个分区的上界作为该分区的下界,生成一个左闭右开的区间。同时,也支持通过 VALUES [...) 指定上下界,生成一个左闭右开的区间。
- 通过 VALUES [...) 同时指定上下界比较容易理解。这里举例说明,当使用 VALUES LESS THAN (...) 语句进行分区的增删操作时,分区范围的变化情况:
如上 example_range_tbl 得建表语句中可以看到,当建表完成后,会自动生成如下 5 个分区:
-- 查看表中分区得情况
mysql> SHOW PARTITIONS FROM test.example_range_tbl \G
\G 是将查询结果竖着显示,一般我们都是横着显示的,这个只有在黑窗口才起作用。
SHOW PARTITIONS FROM test.example_range_tbl;
insert into test.example_range_tbl
values(1,'2022-03-05', '2022-03-05 00:00:00', '北京', 10, 1);
插入2月的数据会报错,插入3月不会,因为2月被删除了。综上,分区的删除不会改变已存在分区的范围。删除分区可能出现 空洞 。通过 VALUES LESS THAN 语句增加分区时,分区的下界紧接上一个分区的上界。
2)List 分区
- 分区列支持 BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR 数据类型,分区值为枚举值。只有当数据为目标分区枚举值其中之一时,才可以命中分区。
- Partition 支持通过 VALUES IN (...) 来指定每个分区包含的枚举值。
- 下面通过示例说明,进行分区的增删操作时,分区的变化。
List分区创建语法
-- List Partition
CREATE TABLE IF NOT EXISTS test.example_list_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) NOT NULL COMMENT "用户所在城市",
`age` SMALLINT NOT NULL COMMENT "用户年龄",
`sex` TINYINT NOT NULL COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY LIST(`city`)
(
PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),
PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),
PARTITION `p_jp` VALUES IN ("Tokyo")
)
-- 指定分桶的语法
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES
(
"replication_num" = "1"
);
select `user_id`, `date`, `timestamp`, `city`, `age`, `sex` ,
sum(cost) cost,
last_value(time) last_visit_date
from a
group by `user_id`, `date`, `timestamp`, `city`, `age`, `sex`如上 example_list_tbl 示例,当建表完成后,会自动生成如下3个分区:
p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_jp: ("Tokyo")当我们增加一个分区 p_uk VALUES IN ("London"),分区结果如下:
p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_jp: ("Tokyo")
p_uk: ("London")
alter table test.example_list_tbl add partition `p_uk` values in("London");当我们删除分区 p_jp,分区结果如下:
p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_uk: ("London")
insert into test.example_list_tbl
values(
1,'2022-03-05', '2022-03-05 00:00:00',
'Beijing', 10, 1, '2022-03-05 00:00:00', 100, 10, 1000);
insert into test.example_list_tbl
values(
1,'2022-03-05', '2022-03-05 00:00:00',
'Beijing', 10, 1, '2022-03-06 00:00:00', 200, 5, 900);实验,插入一个不存在的分区,比如 zhengzhou:
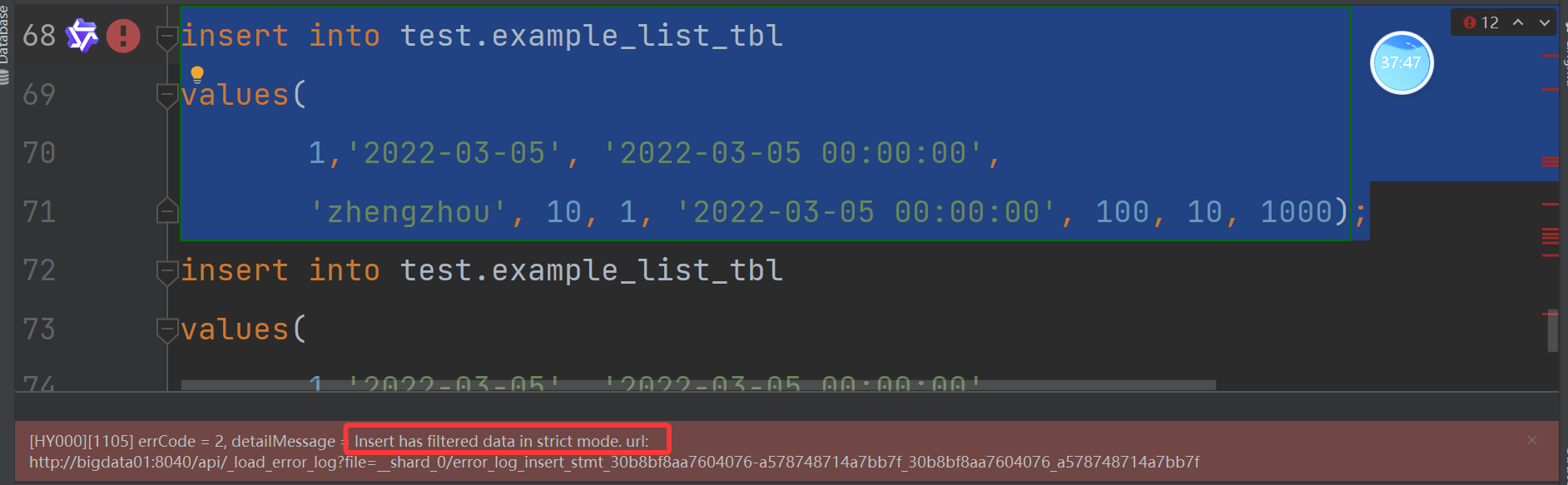
以上如果真要插入,将其修改为非严格模式:
SET enable_insert_strict = false;
显示插入成功,但是查询不出来!!动态分区(新特性)
动态分区会按照设定的规则,滚动添加、删除分区,从而实现对表分区的生命周期管理(TTL),减少数据存储压力。在日志管理,时序数据管理等场景,通常可以使用动态分区能力滚动删除过期的数据。
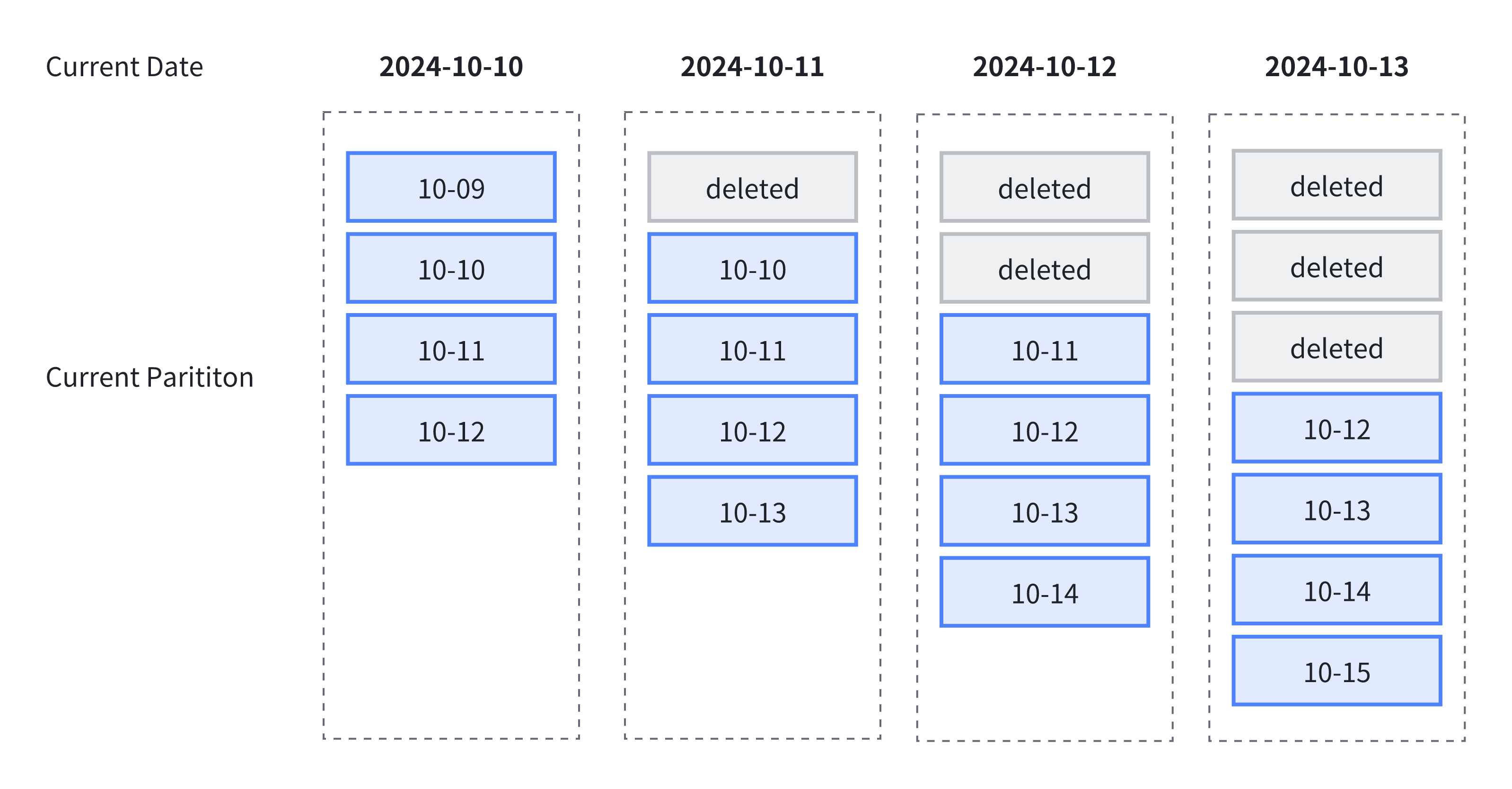
下图中展示了使用动态分区进行生命周期管理,其中指定了以下规则:
- 动态分区调度单位
dynamic_partition.time_unit为 DAY,按天组织分区; - 动态分区起始偏移量
dynamic_partition.start设置为 -1,保留一天前分区; - 动态分区结束偏移量
dynamic_partition.end设置为 2,保留未来两天分区
依据以上规则,随着时间推移,总会保留 4 个分区,即过去一天分区,当天分区与未来两天分区:
使用的场景:
老板说:咱们这个数据库中的数据,只保留最近两年的就可以了。
你是不是要创建分区,按照时间划分,如果是天的话,那就是 720 个分区左右,如果是按照月分区的话,24 个分区左右。
time_unit =Day
start = -720
end = 1
创建动态分区
在建表时,通过指定 dynamic_partition 属性,可以创建动态分区表。
CREATE TABLE test_dynamic_partition(
order_id BIGINT,
create_dt DATE,
username VARCHAR(20)
)
DUPLICATE KEY(order_id)
PARTITION BY RANGE(create_dt) ()
DISTRIBUTED BY HASH(order_id) BUCKETS 10
PROPERTIES(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-1",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "p",
"dynamic_partition.create_history_partition" = "true"
);管理动态分区
修改动态分区属性
提示:
在使用 ALTER TABLE 语句修改动态分区时,不会立即生效。会以 dynamic_partition_check_interval_seconds 参数指定的时间间隔轮训检查 dynamic partition 分区,完成需要的分区创建与删除操作。
下例中通过 ALTER TABLE 语句,将非动态分区表修改为动态分区:
CREATE TABLE test_dynamic_partition(
order_id BIGINT,
create_dt DATE,
username VARCHAR(20)
)
DUPLICATE KEY(order_id)
DISTRIBUTED BY HASH(order_id) BUCKETS 10;运行这个报错:
ALTER TABLE test_dynamic_partition SET (
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-1",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "p",
"dynamic_partition.create_history_partition" = "true"
);
HY000][1105] errCode = 2, detailMessage = Table testabc.test_dynamic_partition is not a dynamic partition table. Use command `HELP ALTER TABLE` to see how to change a normal table to a dynamic partition table.错误原因是说我这个表不是分区表,所以要么创建的时候是分区表,要么修改为分区表:
CREATE TABLE test_dynamic_partition(
order_id BIGINT,
create_dt DATE,
username VARCHAR(20)
)
DUPLICATE KEY(order_id)
PARTITION BY RANGE(create_dt) ()
DISTRIBUTED BY HASH(order_id) BUCKETS 10;查看动态分区调度情况 查看所有的动态分区表
通过 SHOW-DYNAMIC-PARTITION 可以查看当前数据库下,所有动态分区表的调度情况:
SHOW DYNAMIC PARTITION TABLES;
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
| TableName | Enable | TimeUnit | Start | End | Prefix | Buckets | StartOf | LastUpdateTime | LastSchedulerTime | State | LastCreatePartitionMsg | LastDropPartitionMsg | ReservedHistoryPeriods |
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
| d3 | true | WEEK | -3 | 3 | p | 1 | MONDAY | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | [2021-12-01,2021-12-31] |
| d5 | true | DAY | -7 | 3 | p | 32 | N/A | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d4 | true | WEEK | -3 | 3 | p | 1 | WEDNESDAY | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d6 | true | MONTH | -2147483648 | 2 | p | 8 | 3rd | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d2 | true | DAY | -3 | 3 | p | 32 | N/A | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d7 | true | MONTH | -2147483648 | 5 | p | 8 | 24th | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
7 rows in set (0.02 sec)历史分区管理
在使用 start 与 end 属性指定动态分区数量时,为了避免一次性创建所有的分区造成等待时间过长,不会创建历史分区,只会创建当前时间以后的分区。如果需要一次性创建所有分区,需要开启 create_history_partition 参数。
例如当前日期为 2024-10-11,指定 start = -2,end = 2:
- 如果指定了
create_history_partition = true,立即创建所有分区,即 10-09, 10-13 五个分区; - 如果指定了
create_history_partition = false,只创建包含 10-11 以后的分区,即 10-11, 10-13 三个分区。
动态分区最佳实践
示例 1:按天分区,只保留过去 7 天的及当天分区,并且预先创建未来 3 天的分区。
CREATE TABLE tbl1 (
order_id BIGINT,
create_dt DATE,
username VARCHAR(20)
)
PARTITION BY RANGE(create_dt) ()
DISTRIBUTED BY HASH(create_dt)
PROPERTIES (
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-7",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "32"
);示例 2:按月分区,不删除历史分区,并且预先创建未来 2 个月的分区。同时设定以每月 3 号为起始日。
CREATE TABLE tbl1 (
order_id BIGINT,
create_dt DATE,
username VARCHAR(20)
)
PARTITION BY RANGE(create_dt) ()
DISTRIBUTED BY HASH(create_dt)
PROPERTIES (
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "MONTH",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "8",
"dynamic_partition.start_day_of_month" = "3"
);示例 3:按天分区,保留过去 10 天及未来 10 天分区,并且保留 2020-06-01,2020-06-20 及 2020-10-31,2020-11-15 期间的历史数据。
CREATE TABLE tbl1 (
order_id BIGINT,
create_dt DATE,
username VARCHAR(20)
)
PARTITION BY RANGE(create_dt) ()
DISTRIBUTED BY HASH(create_dt)
PROPERTIES (
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-10",
"dynamic_partition.end" = "10",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "8",
"dynamic_partition.reserved_history_periods"="[2020-06-01,2020-06-20],[2020-10-31,2020-11-15]"
);3.2.2.2 数据分桶Bucket
一个分区可以根据业务需求进一步划分为多个数据分桶(bucket)。每个分桶都作为一个物理数据分片(tablet)存储。合理的分桶策略可以有效降低查询时的数据扫描量,提升查询性能并增加并发处理能力。
分桶方式
Doris 支持两种分桶方式:Hash 分桶与 Random 分桶。
Hash 分桶
在创建表或新增分区时,用户需选择一列或多列作为分桶列,并明确指定分桶的数量。在同一分区内,系统会根据分桶键和分桶数量进行哈希计算。哈希值相同的数据会被分配到同一个分桶中。例如,在下图中,p250102 分区根据 region 列被划分为 3 个分桶,哈希值相同的行被归入同一个分桶。
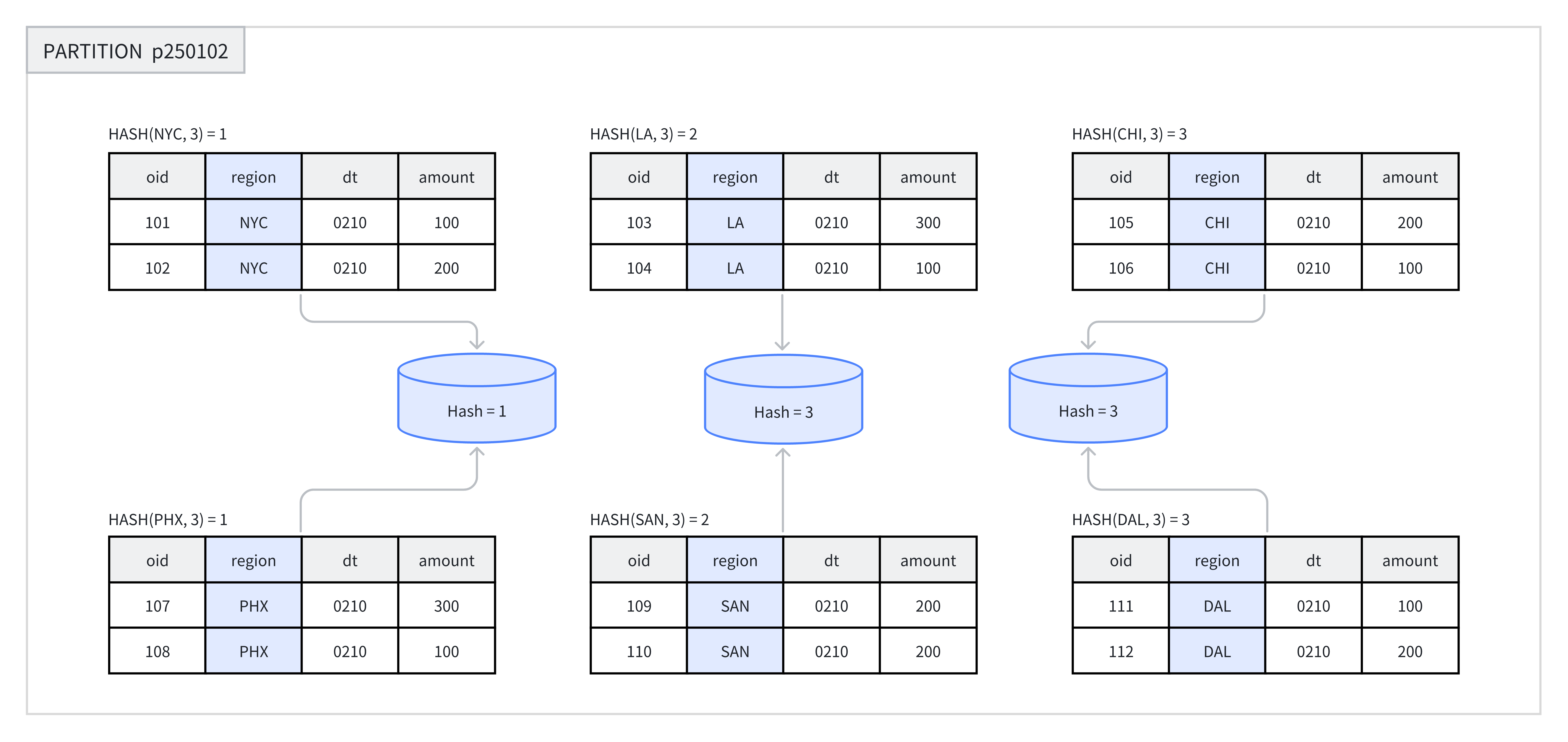
以上图 2 应该是 Hash=2 ,图画错了。
推荐在以下场景中使用 Hash 分桶:
- 业务需求频繁基于某个字段进行过滤时,可将该字段作为分桶键,利用 Hash 分桶提高查询效率。
- 当表中的数据分布较为均匀时,Hash 分桶同样是一种有效的选择。
以下示例展示了如何创建带有 Hash 分桶的表。详细语法请参考 CREATE TABLE 语句。
CREATE TABLE hash_bucket_tbl(
oid BIGINT,
dt DATE,
region VARCHAR(10),
amount INT
)
DUPLICATE KEY(oid)
PARTITION BY RANGE(dt) (
PARTITION p250101 VALUES LESS THAN("2025-01-01"),
PARTITION p250102 VALUES LESS THAN("2025-01-02")
)
DISTRIBUTED BY HASH(region) BUCKETS 8;
insert into hash_bucket_tbl
values(5, "2025-01-01 12:30:00", "HA", 100);
验证的结果:在明细表类型中,假如key=oid ,oid相同的数据可以插入成功。
插入时,分区一定要存在,分区不存在,插入失败。示例中,通过 DISTRIBUTED BY HASH(region) 指定了创建 Hash 分桶,并选择 region 列作为分桶键。同时,通过 BUCKETS 8 指定了创建 8 个分桶。
Random 分桶
在每个分区中,使用 Random 分桶会随机地将数据分散到各个分桶中,不依赖于某个字段的 Hash 值进行数据划分。Random 分桶能够确保数据均匀分散,从而避免由于分桶键选择不当而引发的数据倾斜问题。
在导入数据时,单次导入作业的每个批次会被随机写入到一个 tablet 中,以此保证数据的均匀分布。例如,在一次操作中,8 个批次的数据被随机分配到 p250102 分区下的 3 个分桶中。
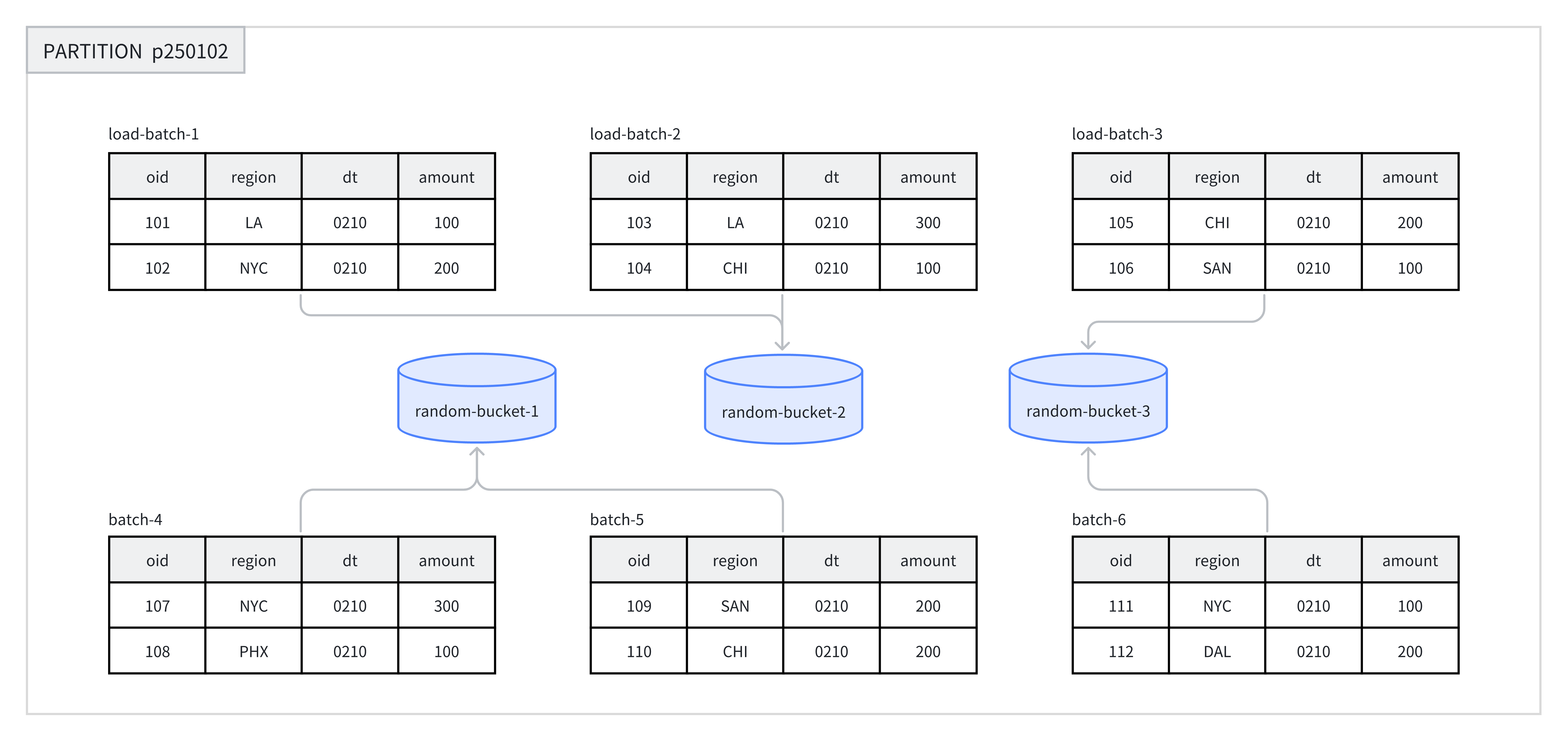
在使用 Random 分桶时,可以启用单分片导入模式(通过设置 load_to_single_tablet 为 true)。这样,在大规模数据导入过程中,单个批次的数据仅写入一个数据分片,能够提高数据导入的并发度和吞吐量,减少因数据导入和压缩(Compaction)操作造成的写放大问题,从而确保集群稳定性。
在以下场景中,建议使用 Random 分桶:
- 在任意维度分析的场景中,业务没有特别针对某一列频繁进行过滤或关联查询时,可以选择 Random 分桶;
- 当经常查询的列或组合列数据分布极其不均匀时,使用 Random 分桶可以避免数据倾斜。
- Random 分桶无法根据分桶键进行剪裁,会扫描命中分区的所有数据,不建议在点查场景下使用;
- 只有 DUPLICATE 表可以使用 Random 分区,UNIQUE 与 AGGREGATE 表无法使用 Random 分桶;
以下示例展示了如何创建带有 Random 分桶的表。详细语法请参考 CREATE TABLE 语句:
CREATE TABLE random_bucket_tbl(
oid BIGINT,
dt DATE,
region VARCHAR(10),
amount INT
)
DUPLICATE KEY(oid)
PARTITION BY RANGE(dt) (
PARTITION p250101 VALUES LESS THAN("2025-01-01"),
PARTITION p250102 VALUES LESS THAN("2025-01-02")
)
DISTRIBUTED BY RANDOM BUCKETS 8;示例中,通过 DISTRIBUTED BY RANDOM 语句指定了使用 Random 分桶,创建 Random 分桶无需选择分桶键,通过 BUCKETS 8 语句指定创建 8 个分桶。
选择分桶键
提示
只有 Hash 分桶需要选择分桶键,Random 分桶不需要选择分桶键。
分桶键可以是一列或者多列。如果是 DUPLICATE 表,任何 Key 列与 Value 列都可以作为分桶键。如果是 AGGREGATE 或 UNIQUE 表,为了保证逐渐的聚合性,分桶列必须是 Key 列。
选择分桶数量
在 Doris 中,一个 bucket 会被存储为一个物理文件(tablet)。一个表的 Tablet 数量等于 partition_num(分区数)乘以 bucket_num(分桶数)。一旦指定 Partition 的数量,便不可更改。
在确定 bucket 数量时,需预先考虑机器扩容情况。自 2.0 版本起,Doris 支持根据机器资源和集群信息自动设置分区中的分桶数。
手动设置分桶数
通过 DISTRIBUTED 语句可以指定分桶数量:
-- Set hash bucket num to 8
DISTRIBUTED BY HASH(region) BUCKETS 8
-- Set random bucket num to 8
DISTRIBUTED BY RANDOM BUCKETS 8在决定分桶数量时,通常遵循数量与大小两个原则 ,当发生冲突时,优先考虑大小原则:
- 大小原则 :建议一个 tablet 的大小在1-10G 范围内。过小的 tablet 可能导致聚合效果不佳,增加元数据管理压力;过大的 tablet 则不利于副本迁移、补齐,且会增加 Schema Change 操作的失败重试代价;
- 数量原则 :在不考虑扩容的情况下,一个表的 tablet 数量建议略多于整个集群的磁盘数量。
例如,假设有 10 台 BE 机器,每个 BE 一块磁盘,可以按照以下建议进行数据分桶:
|----------|-------------------------------|
| 单表大小 | 建议分桶数量 |
| 500MB | 4-8 个分桶 |
| 5GB | 6-16 个分桶 |
| 50GB | 32 个分桶 |
| 500GB | 建议分区,每个分区 50GB,每个分区 16-32 个分桶 |
| 5TB | 建议分区,每个分区 50GB,每个分桶 16-32 个分桶 |
提示
表的数据量可以通过 SHOW DATA 命令查看。结果需要除以副本数,及表的数据量。
自动设置分桶数
自动推算分桶数功能会根据过去一段时间的分区大小,自动预测未来的分区大小,并据此确定分桶数量。
-- Set hash bucket auto
DISTRIBUTED BY HASH(region) BUCKETS AUTO
properties("estimate_partition_size" = "20G")
-- Set random bucket auto
DISTRIBUTED BY Random BUCKETS AUTO
properties("estimate_partition_size" = "20G")在创建分桶时,可以通过 estimate_partition_size 属性来调整前期估算的分区大小。此参数为可选设置,若未给出,Doris 将默认取值为 10GB。请注意,该参数与后期系统通过历史分区数据推算出的未来分区大小无关。
维护数据分桶
提示
目前,Doris 仅支持修改新增分区的分桶数量,对于以下操作暂不支持:
- 不支持修改分桶类型
- 不支持修改分桶键
- 不支持修改已创建的分桶的分桶数量
在建表时,已通过 DISTRIBUTED 语句统一指定了每个分区的数量。为了应对数据增长或减少的情况,在动态增加分区时,可以单独指定新分区的分桶数量。以下示例展示了如何通过 ALTER TABLE 命令来修改新增分区的分桶数:
-- Modify hash bucket table
ALTER TABLE demo.hash_bucket_tbl
ADD PARTITION p250103 VALUES LESS THAN("2025-01-03")
DISTRIBUTED BY HASH(region) BUCKETS 16;
-- Modify random bucket table
ALTER TABLE demo.random_bucket_tbl
ADD PARTITION p250103 VALUES LESS THAN("2025-01-03")
DISTRIBUTED BY RANDOM BUCKETS 16;
-- Modify dynamic partition table
ALTER TABLE demo.dynamic_partition_tbl
SET ("dynamic_partition.buckets"="16");在修改分桶数量后,可以通过 SHOW PARTITION 命令查看修改后的分桶数量。
3.2.3 PROPERTIES
在建表语句的最后,可以用 PROPERTIES 关键字来设置一些表的属性参数(参数有很多)
PROPERTIES(
"参数名" = "参数值"
)下文挑选了3个比较重要的参数进行示例;
3.2.3.1 分片副本数
- replication_num
每个 Tablet 的副本数量。默认为 3,建议保持默认即可。在建表语句中,所有 Partition中的 Tablet 副本数量统一指定。而在增加新分区时,可以单独指定新分区中 Tablet 的副本数量。
副本数量可以在运行时修改。强烈建议保持 奇数 。
最大副本数量取决于集群中独立 IP 的数量 (注意不是 BE 数量)。Doris 中副本分布的原则是,不允许同一个 Tablet 的副本分布在同一台物理机上,而识别物理机即通过 IP。所以,即使在同一台物理机上部署了 3 个或更多 BE 实例,如果这些 BE 的 IP 相同,则依然只能设置副本数为 1。对于一些小,并且更新不频繁的维度表,可以考虑设置更多的副本数。这样在 Join 查询时,可以有更大的概率进行本地数据 Join。
3.2.3.2 存储介质 和 热数据冷却时间
- storage_medium
- storage_cooldown_time
建表时,可以统一指定所有 Partition 初始存储的介质及热数据的冷却时间,如:
"storage_medium" = "SSD"
"storage_cooldown_time" = "2023-04-20 00:00:00" 要在当前时间之后,并且是一个datetime类型默认初始存储介质可通过 fe 的配置文件 fe.conf 中指定 default_storage_medium=xxx,如果没有指定,则默认为 HDD 。如果指定为 SSD,则数据初始 存放在 SSD 上。没设storage_cooldown_time,则默认 30 天后,数据会从 SSD自动迁移到 HDD上。如果指定了 storage_cooldown_time,则在到达 storage_cooldown_time 时间后,数据才会迁移。
注意,当指定 storage_medium 时,如果 FE 参数 enable_strict_storage_medium_check 为False 该参数只是一个"尽力而为"的设置。即使集群内没有设置 SSD 存储介质,也不会报错,而是自动存储在可用的数据目录中。 同样,如果 SSD 介质不可访问、空间不足,都可能导致数据初始直接存储在其他可用介质上。而数据到期迁移到 HDD 时,如果 HDD 介质不 可 访 问 、 空 间 不 足 , 也 可 能 迁 移 失 败 ( 但 是 会 不 断 尝 试 ) 。 如 果 FE 参 数enable_strict_storage_medium_check 为 True 则当集群内没有设置 SSD 存储介质时,会报错Failed to find enough host in all backends with storage medium is SSD。
SSD: 固态硬盘
HDD:机械硬盘