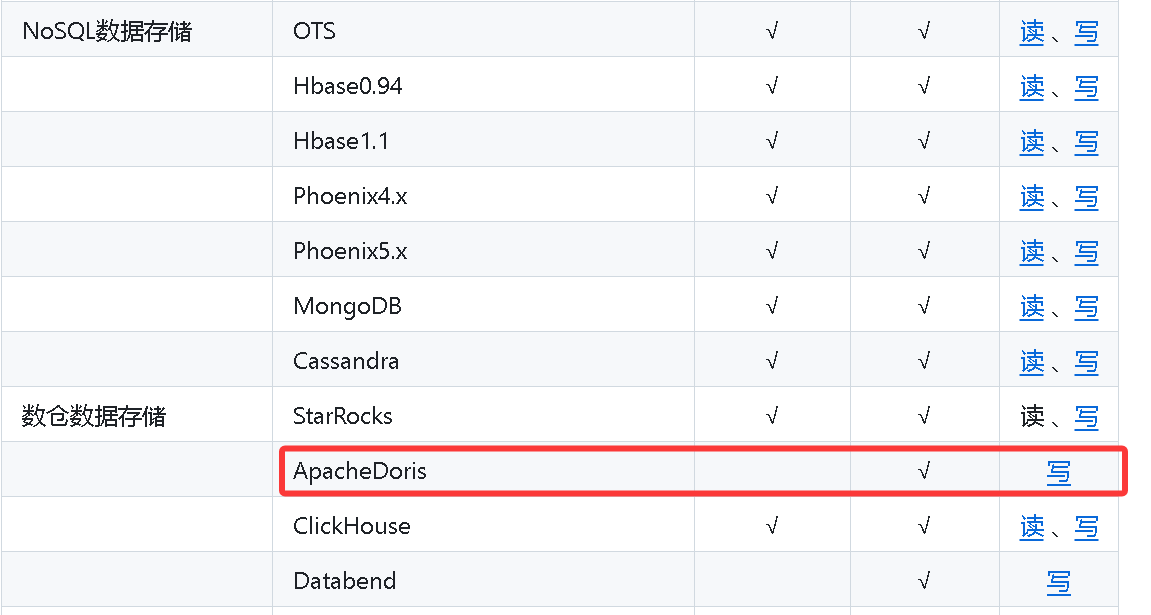
一、 物化视图
物化视图是既包含计算逻辑也包含数据的实体。它不同于视图,因为视图仅包含计算逻辑,本身不存储数据。
视图:创建一个视图,类似于临时表。mysql,oracle 都有这样的功能。
就是查询结果预先存储起来的特殊的表。物化视图的出现主要是为了满足用户既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询。
mysql 中视图:视图只保存查询的逻辑,不保存查询的结果。
举例:
create view as user_account_view
select * from user join account on user.xx = account.xx;
视图的使用:
select * from user_accout_view where id = xxx;
普通视图仅仅是减少了一些代码量,根本提高不了查询的效率。我们不用担心,基数表数据变更物化视图表中的数据是否会老,不会,因为会随之改变。
Doris 系统提供了一整套对物化视图的 DDL 语法,包括创建,査看,删除。DDL 的语法和 PostgreSQL, Oracle 都是一致的。
同步物化视图(学习的重点)
什么是同步物化视图
同步物化视图是将预先计算 (根据定义好的 SELECT 语句)的数据集,存储在 Doris 中的一个特殊的表。Doris 会自动维护同步物化视图的数据,无论是新增数据还是删除数据,都能保证基表(Base Table)和物化视图表的数据同步更新并保持一致,只有同步完成后,相关命令才会结束,无需任何额外的人工维护成本。查询时,Doris 会自动匹配到最优的物化视图,并直接从物化视图中读取数据。
使用物化视图
Doris 系统提供了一整套针对物化视图的 DDL 语法,包括创建、查看和删除。下面通过一个示例来展示如何使用物化视图加速聚合计算。假设用户有一张销售记录明细表,该表存储了每个交易的交易 ID、销售员、售卖门店、销售时间以及金额。建表语句和插入数据语句如下:
-- 创建一个 test_db
create database test_db;
use test_db;
-- 创建表
create table sales_records
(
record_id int,
seller_id int,
store_id int,
sale_date date,
sale_amt bigint
)
distributed by hash(record_id)
properties("replication_num" = "1");
-- 插入数据
insert into sales_records values(1,1,1,"2020-02-02",1), (1,1,1,"2020-02-02",2);创建物化视图
如果用户经常需要分析不同门店的销售量,则可以为 sales_records 表创建一个物化视图,该视图以售卖门店分组,并对相同售卖门店的销售额进行求和。创建语句如下:
mysql -uroot -p123456 -P9030 -hbigdata01
create materialized view store_amt as
select store_id, sum(sale_amt) from sales_records group by store_id;有些语句在 datagrip 中不支持,但是在黑窗口客户端支持。
检查物化视图是否创建完成
由于创建物化视图是一个异步操作,用户在提交创建物化视图任务后,可以通过命令异步地检查物化视图是否构建完成。命令如下:
show alter table materialized view from test_db;该命令的结果将显示该数据库的所有创建物化视图的任务。结果示例如下:
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+----------+------+----------+---------+
| JobId | TableName | CreateTime | FinishTime | BaseIndexName | RollupIndexName | RollupId | TransactionId | State | Msg | Progress | Timeout |
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+----------+------+----------+---------+
| 11238 | sales_records | 2025-08-06 20:20:55 | 2025-08-06 20:20:56 | sales_records | store_amt | 11239 | 157 | FINISHED | | NULL | 2592000 |
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+----------+------+----------+---------+其中,TableName 指的是物化视图的数据来源表,RollupIndexName 指的是物化视图的名称。比较重要的指标是 State。当创建物化视图任务的 State 变为 FINISHED 时,就说明这个物化视图已经创建成功了。这意味着,在执行查询时有可能自动匹配到这张物化视图。
取消创建物化视图
如果创建物化视图的后台异步任务还未结束,可以通过以下命令取消任务:
cancel alter table materialized view from test_db.sales_records;如果物化视图已经创建完毕,则无法通过该命令取消创建,但可以通过删除命令来删除物化视图。
查看物化视图的表结构
可以通过以下命令查看目标表上创建的所有物化视图及其表结构:
desc sales_records all;该命令的结果如下:
+---------------+---------------+---------------------+--------+--------------+------+-------+---------+-------+---------+------------+-------------+
| IndexName | IndexKeysType | Field | Type | InternalType | Null | Key | Default | Extra | Visible | DefineExpr | WhereClause |
+---------------+---------------+---------------------+--------+--------------+------+-------+---------+-------+---------+------------+-------------+
| sales_records | DUP_KEYS | record_id | INT | INT | Yes | true | NULL | | true | | |
| | | seller_id | INT | INT | Yes | true | NULL | | true | | |
| | | store_id | INT | INT | Yes | true | NULL | | true | | |
| | | sale_date | DATE | DATEV2 | Yes | false | NULL | NONE | true | | |
| | | sale_amt | BIGINT | BIGINT | Yes | false | NULL | NONE | true | | |
| | | | | | | | | | | | |
| store_amt | AGG_KEYS | mv_store_id | INT | INT | Yes | true | NULL | | true | `store_id` | |
| | | mva_SUM__`sale_amt` | BIGINT | BIGINT | Yes | false | NULL | SUM | true | `sale_amt` | |
+---------------+---------------+---------------------+--------+--------------+------+-------+---------+-------+---------+------------+-------------+可以看到,sales_records有一个名叫store_amt的物化视图,这个物化视图就是前面步骤创建的。
查询物化视图
当物化视图创建完成后,用户在查询不同门店的销售量时,Doris 会直接从刚才创建的物化视图store_amt中读取聚合好的数据,从而提升查询效率。用户的查询依旧指定查询sales_records表,比如:
select store_id, sum(sale_amt) from sales_records group by store_id;上面的查询就能自动匹配到store_amt。用户可以通过下面的命令,检验当前查询是否匹配到了合适的物化视图。
explain select store_id, sum(sale_amt) from sales_records group by store_id;结果如下:
+------------------------------------------------------------------------+
| Explain String(Nereids Planner) |
+------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| store_id[#11] |
| sum(sale_amt)[#12] |
| PARTITION: HASH_PARTITIONED: mv_store_id[#7] |
| |
| HAS_COLO_PLAN_NODE: true |
| |
| VRESULT SINK |
| MYSQL_PROTOCAL |
| |
| 3:VAGGREGATE (merge finalize)(384) |
| | output: sum(partial_sum(mva_SUM__`sale_amt`)[#8])[#10] |
| | group by: mv_store_id[#7] |
| | sortByGroupKey:false |
| | cardinality=1 |
| | final projections: mv_store_id[#9], sum(mva_SUM__`sale_amt`)[#10] |
| | final project output tuple id: 4 |
| | distribute expr lists: mv_store_id[#7] |
| | |
| 2:VEXCHANGE |
| offset: 0 |
| distribute expr lists: |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: record_id[#2] |
| |
| HAS_COLO_PLAN_NODE: false |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| HASH_PARTITIONED: mv_store_id[#7] |
| |
| 1:VAGGREGATE (update serialize)(374) |
| | STREAMING |
| | output: partial_sum(mva_SUM__`sale_amt`[#1])[#8] |
| | group by: mv_store_id[#0] |
| | sortByGroupKey:false |
| | cardinality=1 |
| | distribute expr lists: |
| | |
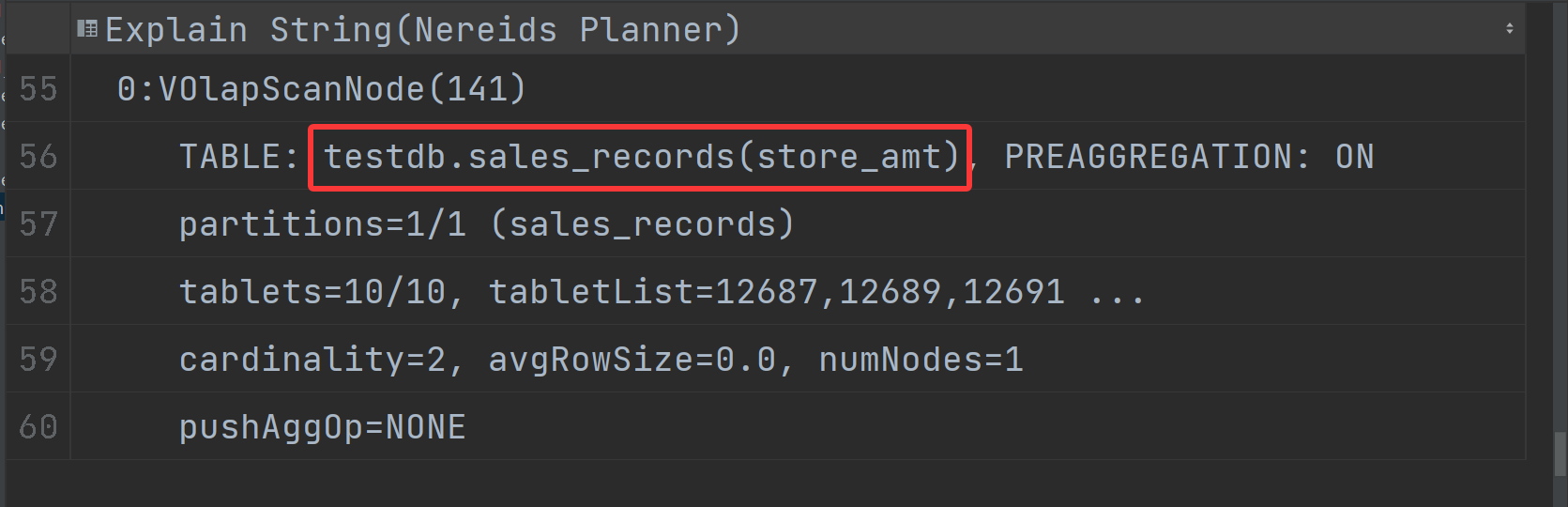
| 0:VOlapScanNode(369) |
| TABLE: test_db.sales_records(store_amt), PREAGGREGATION: ON |
| partitions=1/1 (sales_records) |
| tablets=10/10, tabletList=266568,266570,266572 ... |
| cardinality=1, avgRowSize=1805.0, numNodes=1 |
| pushAggOp=NONE |
| |
| |
| ========== MATERIALIZATIONS ========== |
| |
| MaterializedView |
| MaterializedViewRewriteSuccessAndChose: |
| internal.test_db.sales_records.store_amt chose, |
| |
| MaterializedViewRewriteSuccessButNotChose: |
| not chose: none, |
| |
| MaterializedViewRewriteFail: |
| |
| |
| ========== STATISTICS ========== |
| planed with unknown column statistics |
+------------------------------------------------------------------------+MaterializedViewRewriteSuccessAndChose 会展示被成功命中的物化视图,具体示例如下:
+------------------------------------------------------------------------+
| MaterializedViewRewriteSuccessAndChose: |
| internal.test_db.sales_records.store_amt chose, |
+------------------------------------------------------------------------+上述内容表明,查询成功命中了名为 store_amt 的物化视图。值得注意的是,若目标表中无任何数据,则可能不会触发对物化视图的命中。
关于 MATERIALIZATIONS 的详细说明:
- MaterializedViewRewriteSuccessAndChose:展示被成功选中并用于查询优化的物化视图。
- MaterializedViewRewriteSuccessButNotChose:展示匹配成功但未被选中的物化视图(优化器会基于物化视图的成本进行最优选择,这些匹配但未被选中的物化视图,表示它们并非最优选择)。
- MaterializedViewRewriteFail:展示未能匹配的物化视图,即原始 SQL 查询与现有物化视图无法匹配,因此无法使用物化视图进行优化。
以上是官方给出的是否使用到物化视图的解释,但经过演示,不是这个样子的,应该如下图所示,根本没有MATERIALIZATIONS 及以下的内容,那如何才能知道命中了物化视图呢?
命中的截图:

没有使用到物化视图的截图:

删除物化视图
drop materialized view store_amt on sales_records;使用示例
示例一:加速聚合查询
业务场景: 计算广告的 UV(独立访客数)和 PV(页面访问量)。
-
假设用户的原始广告点击数据存储在 Doris 中,那么针对广告 PV 和 UV 的查询就可以通过创建带有
bitmap_union的物化视图来提升查询速度。首先,创建一个存储广告点击数据明细的表,包含每条点击的点击时间、点击的广告、点击的渠道以及点击的用户。原始表创建语句如下:create table advertiser_view_record
(
click_time datetime,
advertiser varchar(10),
channel varchar(10),
user_id int
) distributed by hash(user_id) properties("replication_num" = "1");
insert into advertiser_view_record values("2020-02-02 02:02:02",'a','a',1), ("2020-02-02 02:02:02",'a','a',2); -
用户想要查询的是广告的 UV 值,也就是需要对相同广告的用户进行精确去重,查询语句一般为:
select
advertiser,
channel,
count(distinct user_id)
from
advertiser_view_record
group by
advertiser, channel; -
针对这种求 UV 的场景,可以创建一个带有
bitmap_union的物化视图,以达到预先精确去重的效果。在 Doris 中,count(distinct)聚合的结果和bitmap_union_count聚合的结果是完全一致的。因此,如果查询中涉及到count(distinct),则通过创建带有bitmap_union聚合的物化视图可以加快查询。根据当前的使用场景,可以创建一个根据广告和渠道分组,对user_id进行精确去重的物化视图。create materialized view advertiser_uv as
select
advertiser,
channel,
bitmap_union(to_bitmap(user_id))
from
advertiser_view_record
group by
advertiser, channel; -
当物化视图表创建完成后,查询广告 UV 时,Doris 就会自动从刚才创建好的物化视图
advertiser_uv中查询数据。如果执行之前的 SQL 查询:select
advertiser,
channel,
count(distinct user_id)
from
advertiser_view_record
group by
advertiser, channel; -
在选中物化视图后,实际的查询会转化为:
select
advertiser,
channel,
bitmap_union_count(to_bitmap(user_id))
from
advertiser_uv
group by
advertiser, channel;
为什么创建物化视图的时候,不使用count(distinct user_id) 方式,因为这样报错,需要更改为bitmap_union_count(to_bitmap(user_id)) ,具体查看示例三这个案例。
-
通过
explain命令检查查询是否匹配到了物化视图:explain select
advertiser,
channel,
count(distinct user_id)
from
advertiser_view_record
group by
advertiser, channel; -
输出结果如下:
+---------------------------------------------------------------------------------------------------------------------------------------------------------+
| Explain String(Nereids Planner) |
+---------------------------------------------------------------------------------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| advertiser[#13] |
| channel[#14] |
| count(DISTINCT user_id)[#15] |
| PARTITION: HASH_PARTITIONED: mv_advertiser[#7], mv_channel[#8] |
| |
| HAS_COLO_PLAN_NODE: true |
| |
| VRESULT SINK |
| MYSQL_PROTOCAL |
| |
| 3:VAGGREGATE (merge finalize)(440) |
| | output: bitmap_union_count(partial_bitmap_union_count(mva_BITMAP_UNION__to_bitmap_with_check(CAST(user_idAS bigint)))[#9])[#12] |
| | group by: mv_advertiser[#7], mv_channel[#8] |
| | sortByGroupKey:false |
| | cardinality=1 |
| | final projections: mv_advertiser[#10], mv_channel[#11], bitmap_union_count(mva_BITMAP_UNION__to_bitmap_with_check(CAST(user_idAS bigint)))[#12] |
| | final project output tuple id: 4 |
| | distribute expr lists: mv_advertiser[#7], mv_channel[#8] |
| | |
| 2:VEXCHANGE |
| offset: 0 |
| distribute expr lists: |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: user_id[#6] |
| |
| HAS_COLO_PLAN_NODE: false |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| HASH_PARTITIONED: mv_advertiser[#7], mv_channel[#8] |
| |
| 1:VAGGREGATE (update serialize)(430) |
| | STREAMING |
| | output: partial_bitmap_union_count(mva_BITMAP_UNION__to_bitmap_with_check(CAST(user_idAS bigint))[#2])[#9] |
| | group by: mv_advertiser[#0], mv_channel[#1] |
| | sortByGroupKey:false |
| | cardinality=1 |
| | distribute expr lists: |
| | |
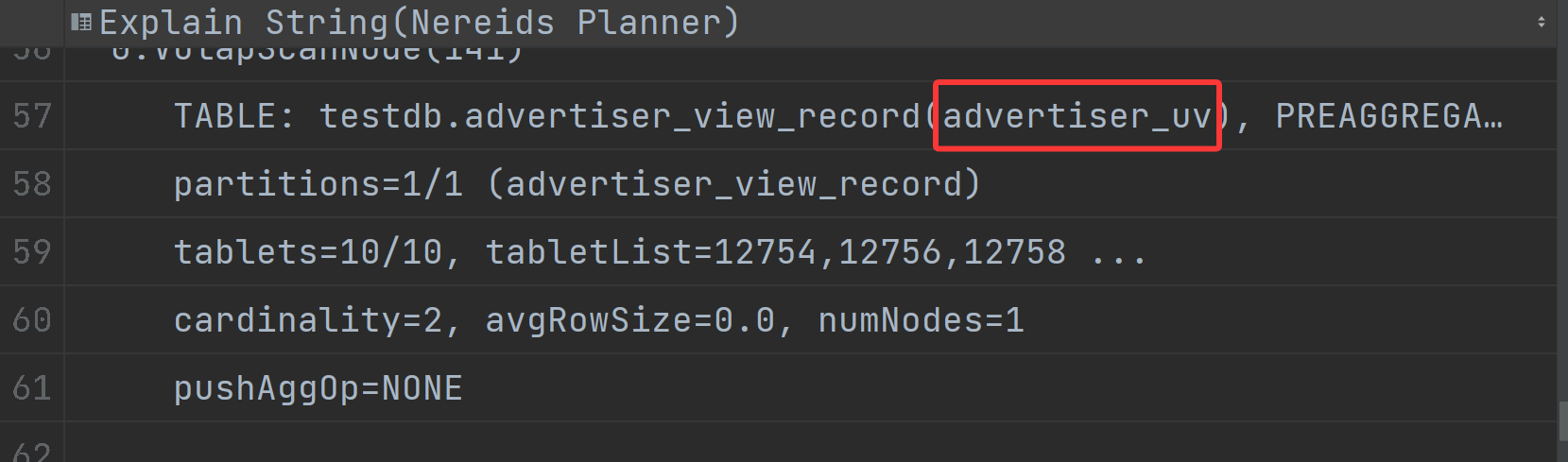
| 0:VOlapScanNode(425) |
| TABLE: test_db.advertiser_view_record(advertiser_uv), PREAGGREGATION: ON |
| partitions=1/1 (advertiser_view_record) |
| tablets=10/10, tabletList=266637,266639,266641 ... |
| cardinality=1, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
| |
| ========== MATERIALIZATIONS ========== |
| |
| MaterializedView |
| MaterializedViewRewriteSuccessAndChose: |
| internal.test_db.advertiser_view_record.advertiser_uv chose, |
| |
| MaterializedViewRewriteSuccessButNotChose: |
| not chose: none, |
| |
| MaterializedViewRewriteFail: |
| |
| |
| ========== STATISTICS ========== |
| planed with unknown column statistics |
+---------------------------------------------------------------------------------------------------------------------------------------------------------+ -
在
explain的结果中,可以看到internal.test_db.advertiser_view_record.advertiser_uv chose。也就是说,查询会直接扫描物化视图的数据,说明匹配成功。其次,对于user_id字段求count(distinct)被改写为求bitmap_union_count(to_bitmap),也就是通过 Bitmap 的方式来达到精确去重的效果。
示例二:是案例一的拓展
创建一个 Base 表:
用户有一张销售记录明细表,存储了每个交易的交易id,销售员,售卖门店,销售时间,以及金额
drop table sales_records;
create table sales_records(
record_id int,
seller_id int,
store_id int,
sale_date date,
sale_amt bigint)
duplicate key (record_id,seller_id,store_id,sale_date)
distributed by hash(record_id) buckets 2
properties("replication_num" = "1");
-- 插入数据
insert into sales_records values
(1,1,1,'2025-02-02',100),
(2,2,1,'2025-02-02',200),
(3,3,2,'2025-02-02',300),
(4,3,2,'2025-02-02',200),
(5,2,1,'2025-02-02',100),
(6,4,2,'2025-02-02',200),
(7,7,3,'2025-02-02',300),
(8,2,1,'2025-02-02',400),
(9,9,4,'2025-02-02',100);如果用户需要经常对不同门店的销售量进行统计
第一步:创建一个物化视图
-- 不同门店,看总销售额的一个场景
explain select store_id, sum(sale_amt)
from sales_records
group by store_id;
--针对上述场景做一个物化视图
create materialized view store_amt as
select store_id, sum(sale_amt) as sum_amount
from sales_records
group by store_id;
创建物化视图的sql语句在datagrip 中报错,没有办法创建(将来新的版本可能会支持),需要在黑窗口执行该命令创建。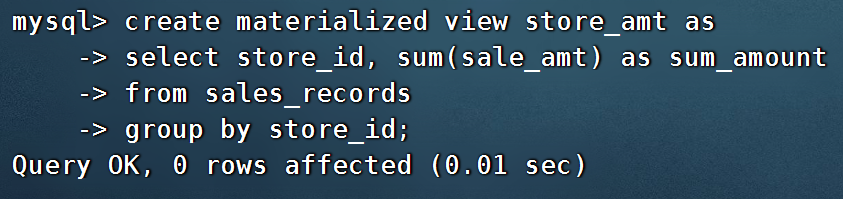
第二步:检查物化视图是否构建完成(物化视图的创建是个异步的过程)
show alter table materialized view from 库名 order by CreateTime desc limit 1;
show alter table materialized view from test_db order by CreateTime desc limit 1;
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+----------+------+----------+---------+
| JobId | TableName | CreateTime | FinishTime | BaseIndexName | RollupIndexName | RollupId | TransactionId | State | Msg | Progress | Timeout |
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+----------+------+----------+---------+
| 15093 | sales_records | 2022-11-25 10:32:33 | 2022-11-25 10:32:59 | sales_records | store_amt | 15094 | 3008 | FINISHED | | NULL | 86400 |
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+----------+------+----------+---------+
查看 Base 表的所有物化视图
desc sales_records all;
+---------------+---------------+-----------+--------+------+-------+---------+-------+---------+
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra | Visible |
+---------------+---------------+-----------+--------+------+-------+---------+-------+---------+
| sales_records | DUP_KEYS | record_id | INT | Yes | true | NULL | | true |
| | | seller_id | INT | Yes | true | NULL | | true |
| | | store_id | INT | Yes | true | NULL | | true |
| | | sale_date | DATE | Yes | true | NULL | | true |
| | | sale_amt | BIGINT | Yes | false | NULL | NONE | true |
| | | | | | | | | |
| store_amt | AGG_KEYS | store_id | INT | Yes | true | NULL | | true |
| | | sale_amt | BIGINT | Yes | false | NULL | SUM | true |
+---------------+---------------+-----------+--------+------+-------+---------+-------+---------+第三步:查询
看是否命中刚才我们建的物化视图
EXPLAIN SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
+------------------------------------------------------------------------------------+
| Explain String |
+------------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:<slot 2> `store_id` | <slot 3> sum(`sale_amt`) |
| PARTITION: UNPARTITIONED |
| |
| VRESULT SINK |
| |
| 4:VEXCHANGE |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: <slot 2> `store_id` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 04 |
| UNPARTITIONED |
| |
| 3:VAGGREGATE (merge finalize) |
| | output: sum(<slot 3> sum(`sale_amt`)) |
| | group by: <slot 2> `store_id` |
| | cardinality=-1 |
| | |
| 2:VEXCHANGE |
| |
| PLAN FRAGMENT 2 |
| |
| PARTITION: HASH_PARTITIONED: `default_cluster:study`.`sales_records`.`record_id` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| HASH_PARTITIONED: <slot 2> `store_id` |
| |
| 1:VAGGREGATE (update serialize) |
| | STREAMING |
| | output: sum(`sale_amt`) |
| | group by: `store_id` |
| | cardinality=-1 |
| | |
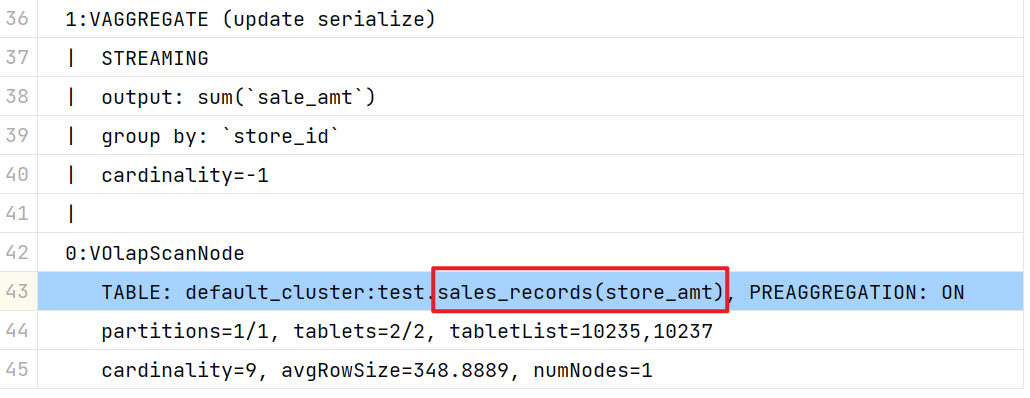
| 0:VOlapScanNode |
| TABLE: sales_records(store_amt), PREAGGREGATION: ON |
| partitions=1/1, tablets=10/10, tabletList=15095,15097,15099 ... |
| cardinality=7, avgRowSize=1560.0, numNodes=3 |
+------------------------------------------------------------------------------------+
测试一下没有添加物化视图的sql:
EXPLAIN
select seller_id, sum(sale_amt)
from sales_records
group by seller_id;删除物化视图语法
-- 语法:
DROP MATERIALIZED VIEW 物化视图名 on base_table_name;
--示例:
drop materialized view store_amt on sales_records;示例三:计算广告的 pv、uv
pv : 整个网站的网页访问量 p--> page
uv: 一个网站的访问人数 u --> user/unique
用户有一张点击广告的明细数据表
需求:针对用户点击计广告明细数据的表,算每天,每个页面,每个渠道的 pv,uv
pv:page view,页面浏览量或点击量
uv:unique view,通过互联网访问、浏览这个网页的自然人
drop table if exists ad_view_record;
create table ad_view_record(
dt date,
ad_page varchar(10),
channel varchar(10),
refer_page varchar(10),
user_id int
)
distributed by hash(dt)
properties("replication_num" = "1");插入数据
insert into ad_view_record values
('2025-02-02','a','app','/home',1),
('2025-02-02','a','web','/home',1),
('2025-02-02','a','app','/addbag',2),
('2025-02-02','b','app','/home',1),
('2025-02-02','b','web','/home',1),
('2025-02-02','b','app','/addbag',2),
('2025-02-02','b','app','/home',3),
('2025-02-02','b','web','/home',3),
('2025-02-02','c','app','/order',1),
('2025-02-02','c','app','/home',1),
('2025-02-03','c','web','/home',1),
('2025-02-03','c','app','/order',4),
('2025-02-03','c','app','/home',5),
('2025-02-03','c','web','/home',6),
('2025-02-03','d','app','/addbag',2),
('2025-02-03','d','app','/home',2),
('2025-02-03','d','web','/home',3),
('2025-02-03','d','app','/addbag',4),
('2025-02-03','d','app','/home',5),
('2025-02-03','d','web','/addbag',6),
('2025-02-03','d','app','/home',5),
('2025-02-03','d','web','/home',4);创建物化视图
-- 怎么去计算pv,uv
select
dt,ad_page,channel,
count(ad_page) as pv,
count(distinct user_id) as uv
from ad_view_record
group by dt,ad_page,channel;
-- 1.物化视图中,不能够使用两个相同的字段
-- 2.在增量聚合里面,不能够使用count(distinct) ==> bitmap_union
-- 3.count(字段)
create materialized view dpc_pv_uv as
select
dt,ad_page,channel,
-- refer_page 没有null的情况
count(refer_page) as pv,
-- doris的物化视图中,不支持count(distint) ==> bitmap_union
-- count(distinct user_id) as uv
bitmap_union(to_bitmap(user_id)) uv_bitmap
from ad_view_record
group by dt,ad_page,channel;
//1. count(必须加字段名) 不能写count(1)
//2.同一个字段在物化视图的sql逻辑中不能出现两次
//3. count(distinct) 不能使用。需要用bitmap_union来代替
create materialized view tpc_pv_uv as
select
dt,ad_page,channel,
count(refer_page) as pv,
-- refer_page 不能为null
-- count(user_id) as pv
-- count(1) as pv,
bitmap_union(to_bitmap(user_id)) as uv_bitmap
--count(distinct user_id) as uv
from ad_view_record
group by dt,ad_page,channel;
--结论:在doris的物化视图中,一个字段不能用两次,并且聚合函数后面必须跟字段名称
在 Doris 中,count(distinct) 聚合的结果和 bitmap_union_count 聚合的结果是完全一致的。而 bitmap_union_count 等于 bitmap_union 的结果求 count,所以如果查询中涉及到count(distinct) 则通过创建带 bitmap_union 聚合的物化视图方可加快查询。因为本身 user_id 是一个 INT 类型,所以在 Doris 中需要先将字段通过函数 to_bitmap 转换为 bitmap 类型然后才可以进行 bitmap_union 聚合。
查询自动匹配
explain
select
dt,ad_page,channel,
count(refer_page) as pv,
count(distinct user_id) as uv
from ad_view_record
group by dt,ad_page,channel;没有用到物化视图:

使用一下sql进行查询。
explain
select
dt,ad_page,channel,
count(1) as pv,
bitmap_union_count(to_bitmap(user_id)) as uv
from ad_view_record
group by dt,ad_page,channel;
这个sql用的是哪张表呢?
explain
select
dt,ad_page,
count(refer_page) as pv,
count(distinct user_id) as uv
from ad_view_record
group by dt,ad_page;
TABLE: ad_view_record_1(dpc_pv_uv), PREAGGREGATION: ON
-- 很显然命中的是tpc_pv_uv 这个物化视图
当然,我们还可以根据日期和页面的维度再去创建一张物化视图
create materialized view tp_pv_uv as
select
dt,ad_page,
count(refer_page) as pv,
bitmap_union(to_bitmap(user_id)) as uv
from ad_view_record
group by dt,ad_page;再去执行上面的sql,显然命中的就是tp_pv_uv这个物化视图
explain
select
dt,ad_page,
count(refer_page) as pv,
count(distinct user_id) as uv
from ad_view_record
group by dt,ad_page;
-- TABLE: ad_view_record_1(tp_pv_uv), PREAGGREGATION: ON
explain
select
dt,
count(refer_page) as pv,
count(distinct user_id) as uv
from ad_view_record
group by dt;总结:
- 在创建doris的物化视图中,同一个字段不能被使用两次,并且聚合函数后面必须跟字段名称(不能使用count(1)这样的聚合逻辑)
- doris在选择使用哪一个物化视图表的时候,按照维度上卷rollup的原则,选距离查询维度最接近,并且指标可以复用的物化视图.
河南
河南 郑州
河南 郑州 金水区
- 一张基表可以创建多个物化视图(计算资源占用比较多)
案例四:调整前缀索引
场景:用户的原始表有(k1, k2, k3)三列。其中 k1, k2 为前缀索引列。这时候如果用户查询条件中包含 where k1=1 and k2=2 就能通过索引加速查询。
但是有些情况下,用户的过滤条件无法匹配到前缀索引,比如 where k3=3。则无法通过索引提升查询速度。
跟 mysql 中的索引优化的最佳最前缀法则一样。
解决方法:
创建以 k3 作为第一列的物化视图就可以解决这个问题。
查询
desc sales_records all;
+---------------+---------------+-----------+--------+------+-------+---------+-------+---------+
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra | Visible |
+---------------+---------------+-----------+--------+------+-------+---------+-------+---------+
| sales_records | DUP_KEYS | record_id | INT | Yes | true | NULL | | true |
| | | seller_id | INT | Yes | true | NULL | | true |
| | | store_id | INT | Yes | true | NULL | | true |
| | | sale_date | DATE | Yes | true | NULL | | true |
| | | sale_amt | BIGINT | Yes | false | NULL | NONE | true |
+---------------+---------------+-----------+--------+------+-------+---------+-------+---------+
5 rows in set (0.00 sec)
--针对上面的前缀索引情况,执行下面的sql是无法利用前缀索引的
explain
select record_id,seller_id,store_id from sales_records
where store_id=3;创建物化视图
create materialized view sto_rec_sell as
select
store_id,
record_id,
seller_id,
sale_date,
sale_amt
from sales_records;通过上面语法创建完成后,物化视图中既保留了完整的明细数据,且物化视图的前缀索 引为 store_id 列。
3)查看表结构
desc sales_records all;
+---------------+---------------+-----------+--------+------+-------+---------+-------+---------+
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra | Visible |
+---------------+---------------+-----------+--------+------+-------+---------+-------+---------+
| sales_records | DUP_KEYS | record_id | INT | Yes | true | NULL | | true |
| | | seller_id | INT | Yes | true | NULL | | true |
| | | store_id | INT | Yes | true | NULL | | true |
| | | sale_date | DATE | Yes | true | NULL | | true |
| | | sale_amt | BIGINT | Yes | false | NULL | NONE | true |
| | | | | | | | | |
| sto_rec_sell | DUP_KEYS | store_id | INT | Yes | true | NULL | | true |
| | | record_id | INT | Yes | true | NULL | | true |
| | | seller_id | INT | Yes | true | NULL | | true |
| | | sale_date | DATE | Yes | false | NULL | NONE | true |
| | | sale_amt | BIGINT | Yes | false | NULL | NONE | true |
+---------------+---------------+-----------+--------+------+-------+---------+-------+---------+查询匹配
explain select record_id,seller_id,store_id from sales_records where store_id=3;
+------------------------------------------------------------------------------------+
| Explain String |
+------------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:`record_id` | `seller_id` | `store_id` |
| PARTITION: UNPARTITIONED |
| |
| VRESULT SINK |
| |
| 1:VEXCHANGE |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: `default_cluster:study`.`sales_records`.`record_id` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 01 |
| UNPARTITIONED |
| |
| 0:VOlapScanNode |
| TABLE: sales_records(sto_rec_sell), PREAGGREGATION: ON |
| PREDICATES: `store_id` = 3 |
| partitions=1/1, tablets=10/10, tabletList=15300,15302,15304 ... |
| cardinality=0, avgRowSize=12.0, numNodes=1 |
+------------------------------------------------------------------------------------+这时候查询就会直接从刚才创建的sto_rec_sell物化视图中读取数据。物化视图对 store_id是存在前缀索引的,查询效率也会提升。
异步物化视图概述
物化视图作为一种高效的解决方案,兼具了视图的灵活性和物理表的高性能优势。 它能够预先计算并存储查询的结果集,从而在查询请求到达时,直接从已存储的物化视图中快速获取结果,避免了重新执行复杂的查询语句所带来的开销。
使用限制
- 异步物化视图与基表数据一致性:异步物化视图与基表的数据最终会保持一致,但无法实时同步,即无法保持实时一致性。
- 窗口函数查询支持:当前,如果查询中包含了窗口函数,暂不支持将该查询透明地改写为利用物化视图的形式。
- 物化视图连接表多于查询表:如果物化视图所连接的表数量多于查询所涉及的表(例如,查询仅涉及 t1 和 t2,而物化视图则包含了 t1、t2 以及额外的 t3), 则系统目前不支持将该查询透明地改写为利用该物化视图的形式。
- 如果物化视图包含 UNION ALL 等集合操作,LIMIT,ORDER BY,CROSS JOIN,物化视图可以正常构建,但是不能用于透明改写。
原理介绍
在创建物化视图时,系统会同时注册一个刷新任务。此任务会在需要时运行,执行 INSERT OVERWRITE 语句,以将最新的数据写入物化视图中。
刷新机制 与同步物化视图所采用的实时增量刷新不同,异步物化视图提供了更为灵活的刷新选项
- 全量刷新 : 在此模式下,系统会重新计算物化视图定义 SQL 所涉及的所有数据,并将结果完整地写入物化视图。 此过程确保了物化视图中的数据与基表数据保持一致,但可能会消耗更多的计算资源和时间。
- 分区增量刷新 : 当物化视图的基表分区数据发生变化时,系统能够智能地识别出这些变化,并仅针对受影响的分区进行刷新。 这种机制显著降低了刷新物化视图所需的计算资源和时间,同时保证了数据的最终一致性。
透明改写 : 透明改写是数据库优化查询性能的一种重要手段。在处理用户查询时,系统能够自动对 SQL 进行优化和改写, 以提高查询的执行效率和降低计算成本。这一改写过程对用户而言是透明的,无需用户进行任何干预。
创建、查询与维护异步物化视图
物化视图创建
创建语法
CREATE MATERIALIZED VIEW
[ IF NOT EXISTS ] <materialized_view_name>
[ (<columns_definition>) ]
[ BUILD <build_mode> ]
[ REFRESH <refresh_method> [refresh_trigger]]
[ [DUPLICATE] KEY (<key_cols>) ]
[ COMMENT '<table_comment>' ]
[ PARTITION BY (
{ <partition_col>
| DATE_TRUNC(<partition_col>, <partition_unit>) }
)]
[ DISTRIBUTED BY { HASH (<distribute_cols>) | RANDOM }
[ BUCKETS { <bucket_count> | AUTO } ]
]
[ PROPERTIES (
-- Table property
<table_property>
-- Additional table properties
[ , ... ])
]
AS <query>刷新配置
build_mode 刷新时机
物化视图创建完成是否立即刷新。
- IMMEDIATE:立即刷新,默认方式。
- DEFERRED:延迟刷新。
refresh_method 刷新方式
- COMPLETE:刷新所有分区。
- AUTO:尽量增量刷新,只刷新自上次物化刷新后数据变化的分区,如果不能感知数据变化的分区,只能退化成全量刷新,刷新所有分区。
refresh_trigger 触发方式
- ON MANUAL****手动触发
用户通过 SQL 语句触发物化视图的刷新,策略如下
检测基表的分区数据自上次刷新后是否有变化,刷新数据变化的分区。
REFRESH MATERIALIZED VIEW mvName AUTO;提示
如果物化视图定义 SQL 使用的基表是 JDBC 表,Doris 无法感知表数据变化,刷新物化视图时需要指定 COMPLETE。 如果指定了 AUTO,会导致基表有数据,但是刷新后物化视图没数据。 刷新物化视图时,目前 Doris 只能感知内表和 Hive 数据源表数据变化,其他数据源逐步支持中。
不校验基表的分区数据自上次刷新后是否有变化,直接刷新物化视图的所有分区。
REFRESH MATERIALIZED VIEW mvName COMPLETE;只刷新指定的分区。
REFRESH MATERIALIZED VIEW mvName partitions(partitionName1,partitionName2);提示
partitionName 可以通过 SHOW PARTITIONS FROM mvName 获取。 从 2.1.3 版本开始支持 Hive 检测基表的分区数据自上次刷新后是否有变化,其他外表暂时还不支持。内表一直支持。
- ON SCHEDULE****定时触发
通过物化视图的创建语句指定间隔多久刷新一次数据,refreshUnit(刷新时间间隔单位)可以是 minute, hour,day,week 等。
如下,要求全量刷新 (REFRESH COMPLETE),物化视图每 10 小时刷新一次,并且刷新物化视图的所有分区。
CREATE MATERIALIZED VIEW mv_6
REFRESH COMPLETE ON SCHEDULE EVERY 10 hour
DISTRIBUTED BY RANDOM BUCKETS 2
AS
SELECT * FROM lineitem;如下,尽量增量刷新 (REFRESH AUTO),只刷新自上次物化刷新后数据变化的分区,如果不能增量刷新,就刷新所有分区,物化视图每 10 小时刷新一次(从 2.1.3 版本开始能自动计算 Hive 需要刷新的分区)。
CREATE MATERIALIZED VIEW mv_7
REFRESH AUTO ON SCHEDULE EVERY 10 hour
PARTITION by(l_shipdate)
DISTRIBUTED BY RANDOM BUCKETS 2
AS
SELECT * FROM lineitem;ON COMMIT****自动触发
- 提示
自 Apache Doris 2.1.4 版本起支持此功能。
基表数据发生变更后,自动触发相关物化视图刷新,刷新的分区范围与"定时触发"一致。
如果物化视图的创建语句如下,那么当 基表 lineitem 的 t1 分区数据发生变化时,会自动触发物化视图的对应分区刷新。
CREATE MATERIALIZED VIEW mv_8
REFRESH AUTO ON COMMIT
PARTITION by(l_shipdate)
DISTRIBUTED BY RANDOM BUCKETS 2
AS
SELECT * FROM lineitem;注意
如果基表的数据频繁变更,不太适合使用此种触发方式,因为会频繁构建物化刷新任务,消耗过多资源。
详情参考 REFRESH MATERIALIZED VIEW
示例如下
建表语句
CREATE TABLE IF NOT EXISTS lineitem (
l_orderkey integer not null,
l_partkey integer not null,
l_suppkey integer not null,
l_linenumber integer not null,
l_quantity decimalv3(15,2) not null,
l_extendedprice decimalv3(15,2) not null,
l_discount decimalv3(15,2) not null,
l_tax decimalv3(15,2) not null,
l_returnflag char(1) not null,
l_linestatus char(1) not null,
l_shipdate date not null,
l_commitdate date not null,
l_receiptdate date not null,
l_shipinstruct char(25) not null,
l_shipmode char(10) not null,
l_comment varchar(44) not null
)
DUPLICATE KEY(l_orderkey, l_partkey, l_suppkey, l_linenumber)
PARTITION BY RANGE(l_shipdate)
(FROM ('2023-10-17') TO ('2023-11-01') INTERVAL 1 DAY)
DISTRIBUTED BY HASH(l_orderkey) BUCKETS 3;
INSERT INTO lineitem VALUES
(1, 2, 3, 4, 5.5, 6.5, 7.5, 8.5, 'o', 'k', '2023-10-17', '2023-10-17', '2023-10-17', 'a', 'b', 'yyyyyyyyy'),
(2, 4, 3, 4, 5.5, 6.5, 7.5, 8.5, 'o', 'k', '2023-10-18', '2023-10-18', '2023-10-18', 'a', 'b', 'yyyyyyyyy'),
(3, 2, 4, 4, 5.5, 6.5, 7.5, 8.5, 'o', 'k', '2023-10-19', '2023-10-19', '2023-10-19', 'a', 'b', 'yyyyyyyyy');
CREATE TABLE IF NOT EXISTS orders (
o_orderkey integer not null,
o_custkey integer not null,
o_orderstatus char(1) not null,
o_totalprice decimalv3(15,2) not null,
o_orderdate date not null,
o_orderpriority char(15) not null,
o_clerk char(15) not null,
o_shippriority integer not null,
o_comment varchar(79) not null
)
DUPLICATE KEY(o_orderkey, o_custkey)
PARTITION BY RANGE(o_orderdate)(
FROM ('2023-10-17') TO ('2023-11-01') INTERVAL 1 DAY)
DISTRIBUTED BY HASH(o_orderkey) BUCKETS 3;
INSERT INTO orders VALUES
(1, 1, 'o', 9.5, '2023-10-17', 'a', 'b', 1, 'yy'),
(1, 1, 'o', 10.5, '2023-10-18', 'a', 'b', 1, 'yy'),
(2, 1, 'o', 11.5, '2023-10-19', 'a', 'b', 1, 'yy'),
(3, 1, 'o', 12.5, '2023-10-19', 'a', 'b', 1, 'yy');
CREATE TABLE IF NOT EXISTS partsupp (
ps_partkey INTEGER NOT NULL,
ps_suppkey INTEGER NOT NULL,
ps_availqty INTEGER NOT NULL,
ps_supplycost DECIMALV3(15,2) NOT NULL,
ps_comment VARCHAR(199) NOT NULL
)
DUPLICATE KEY(ps_partkey, ps_suppkey)
DISTRIBUTED BY HASH(ps_partkey) BUCKETS 3;
INSERT INTO partsupp VALUES
(2, 3, 9, 10.01, 'supply1'),
(4, 3, 10, 11.01, 'supply2'),
(2, 3, 10, 11.01, 'supply3');一口气创建多个分区:
PARTITION BY RANGE(l_shipdate)
(FROM ('2023-10-17') TO ('2023-11-01') INTERVAL 1 DAY)
从 2023-10-17 号,到 2024-11-01 ,每天创建一个日期分区
刷新机制示例一
如下,刷新时机是创建完立即刷新 BUILD IMMEDIATE,刷新方式尽量增量刷新 REFRESH AUTO, 只刷新自上次物化刷新后数据变化的分区,如果不能增量刷新,就刷新所有分区。 触发方式是手动 ON MANUAL。对于非分区全量物化视图,只有一个分区,如果基表数据发生变化,意味着要全量刷新。
CREATE MATERIALIZED VIEW mv_1_0
BUILD IMMEDIATE
REFRESH AUTO
ON MANUAL
DISTRIBUTED BY RANDOM BUCKETS 2
AS
SELECT
l_linestatus,
to_date(o_orderdate) as date_alias,
o_shippriority
FROM
orders
LEFT JOIN lineitem ON l_orderkey = o_orderkey;刷新机制示例二
如下,刷新时机是延迟刷新 BUILD DEFERRED,刷新方式是全量刷新 REFRESH COMPLETE, 触发时机是定时刷新 ON SCHEDULE,首次刷新时间是 2024-12-01 20:30:00, 并且每隔一天刷新一次。 如果 BUILD DEFERRED 指定为 BUILD IMMEDIATE,创建完物化视图会立即刷新一次。之后从 2024-12-01 20:30:00 每隔一天刷新一次。
提示
STARTS 的时间要晚于当前的时间
CREATE MATERIALIZED VIEW mv_1_1
BUILD DEFERRED
REFRESH COMPLETE
ON SCHEDULE EVERY 1 DAY STARTS '2025-12-22 20:30:00'
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES ('replication_num' = '1')
AS
SELECT
l_linestatus,
to_date(o_orderdate) as date_alias,
o_shippriority
FROM
orders
LEFT JOIN lineitem ON l_orderkey = o_orderkey;
ERROR 1105 (HY000): errCode = 2, detailMessage = errCode = 2, detailMessage = starts time must be greater than current time
这个错误的意思是:定制执行的时候,这个时间必须大于当前时间刷新机制示例三
如下,刷新时机是创建完立即刷新 BUILD IMMEDIATE,刷新方式是全量刷新 REFRESH COMPLETE, 触发方式是触发刷新 ON COMMIT,当 orders 或者 lineitem 表数据发生变化的时候,会自动触发物化视图的刷新。
CREATE MATERIALIZED VIEW mv_1_2
BUILD IMMEDIATE
REFRESH COMPLETE
ON COMMIT
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES ('replication_num' = '1')
AS
SELECT
l_linestatus,
to_date(o_orderdate) as date_alias,
o_shippriority
FROM
orders
LEFT JOIN lineitem ON l_orderkey = o_orderkey;分区配置
如下,创建分区物化视图时,需要指定 PARTITION BY,对于分区字段引用的表达式,仅允许使用 date_trunc 函数和标识符。 以下语句是符合要求的: 分区字段引用的列仅使用了 date_trunc 函数。分区物化视图的刷新方式一般是 AUTO,即尽量增量刷新,只刷新自上次物化刷新后数据变化的分区,如果不能增量刷新,就刷新所有分区。
date_trunc 是一个在许多数据库系统(如 PostgreSQL )中提供的函数,用于将日期或时间戳截断(truncate)到指定的精度级别 。简单来说,就是将时间值按照你指定的粒度进行"向下取整",去掉比该粒度更小的时间部分。
CREATE MATERIALIZED VIEW mv_2_0
BUILD IMMEDIATE
REFRESH AUTO
ON MANUAL
PARTITION BY (order_date_month)
DISTRIBUTED BY RANDOM BUCKETS 2
AS
SELECT
l_linestatus,
date_trunc(o_orderdate,'month') as order_date_month,
o_shippriority
FROM
orders
LEFT JOIN lineitem ON l_orderkey = o_orderkey;如下语句创建分区物化视图会失败,因为分区字段 order_date_month 使用了 date_add() 函数,报错 because column to check use invalid implicit expression, invalid expression is days_add(o_orderdate#4, 2)。
select date_trunc('month','2025-11-11');
等同于如下写法:
select date_trunc('2025-11-11','month');
select date_trunc('month','2025-12-25');
select date_trunc('minute','2025-12-25 12:13:56');
vb
`CREATE MATERIALIZED VIEW mv_2_1
BUILD IMMEDIATE
REFRESH AUTO
ON MANUAL
PARTITION BY (order_date_month)
DISTRIBUTED BY RANDOM BUCKETS 2
AS
SELECT
l_linestatus,
date_trunc(days_add(o_orderdate, 2 ), 'month') as order_date_month,
o_shippriority
FROM
orders
LEFT JOIN lineitem ON l_orderkey = o_orderkey;`以上物化视图会报错:
您使用的表达式 date_trunc(days_add(o_orderdate, 2), 'month')嵌套了 days_add函数。这种带有算术运算的复杂表达式,Doris 无法在元数据层面将其与基表的分区进行稳定、准确的映射,因此系统会报错,提示类似 "invalid implicit expression" 的信息
可以将这个计算去掉,再使用。
基表有多列分区
目前仅支持 Hive 外表有多列分区。Hive 外表有很多多级分区的情况,例如一级分区按照日期,二级分区按照区域。物化视图可以选择 Hive 的某一级分区列作为物化视图的分区列。
例如,Hive 的建表语句如下:
CREATE TABLE hive1 (
`k1` int)
PARTITIONED BY (
`year` int,
`region` string)
STORED AS ORC;
alter table hive1 add if not exists
partition(year=2020,region="bj")
partition(year=2020,region="sh")
partition(year=2021,region="bj")
partition(year=2021,region="sh")
partition(year=2022,region="bj")
partition(year=2022,region="sh")当物化视图的创建语句如下时,物化视图mv_hive将有三个分区:('2020'),('2021'),('2022')
CREATE MATERIALIZED VIEW mv_hive
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(`year`)
DISTRIBUTED BY RANDOM BUCKETS 2
AS
SELECT k1,year,region FROM hive1;当物化视图的建表语句如下时,那么物化视图mv_hive2将有如下两个分区:('bj'),('sh'):
CREATE MATERIALIZED VIEW mv_hive2
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(`region`)
DISTRIBUTED BY RANDOM BUCKETS 2
AS
SELECT k1,year,region FROM hive1;使用基表部分分区
有些基表有很多分区,但是物化视图只关注最近一段时间的"热"数据,那么可以使用此功能。
基表的建表语句如下:
CREATE TABLE t1 (
`k1` INT,
`k2` DATE NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`k1`)
COMMENT 'OLAP'
PARTITION BY range(`k2`)
(
PARTITION p26 VALUES [("2024-03-26"),("2024-03-27")),
PARTITION p27 VALUES [("2024-03-27"),("2024-03-28")),
PARTITION p28 VALUES [("2024-03-28"),("2024-03-29"))
)
DISTRIBUTED BY HASH(`k1`) BUCKETS 2;物化视图的创建语句如以下,代表物化视图只关注最近一天的数据。若当前时间为 2024-03-28 xx:xx:xx,这样物化视图会仅有一个分区 [("2024-03-28"),("2024-03-29")]:
CREATE MATERIALIZED VIEW mv1
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by(`k2`)
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES (
'partition_sync_limit'='1',
'partition_sync_time_unit'='DAY'
)
AS
SELECT * FROM t1;若时间又过了一天,当前时间为 2024-03-29 xx:xx:xx,t1则会新增一个分区 [("2024-03-29"),("2024-03-30")],若此时刷新物化视图,刷新完成后,物化视图会仅有一个分区 [("2024-03-29"),("2024-03-30")]。
此外,分区字段是字符串类型时,可以设置物化视图属性 partition_date_format,例如 %Y-%m-%d 。
分区上卷
提示
自 Doris 2.1.5 版本起支持 Range 分区
当基表数据经过聚合处理后,各分区的数据量可能会显著减少。在这种情况下,可以采用分区上卷策略,以降低物化视图的分区数量。
假设基表的建表语句如下:
CREATE TABLE `t1` (
`k1` LARGEINT NOT NULL,
`k2` DATE NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`k1`)
COMMENT 'OLAP'
PARTITION BY range(`k2`)
(
PARTITION p_20200101 VALUES [("2020-01-01"),("2020-01-02")),
PARTITION p_20200102 VALUES [("2020-01-02"),("2020-01-03")),
PARTITION p_20200201 VALUES [("2020-02-01"),("2020-02-02"))
)
DISTRIBUTED BY HASH(`k1`) BUCKETS 2;若物化视图的创建语句如下,则该物化视图将包含两个分区:[("2020-01-01","2020-02-01")] 和 [("2020-02-01","2020-03-01")]
CREATE MATERIALIZED VIEW mv_3
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by (date_trunc(`k2`,'month'))
DISTRIBUTED BY RANDOM BUCKETS 2
AS
SELECT * FROM t1;若物化视图的创建语句如下,则该物化视图将只包含一个分区:[("2020-01-01","2021-01-01")]
CREATE MATERIALIZED VIEW mv_4
BUILD DEFERRED REFRESH AUTO ON MANUAL
partition by (date_trunc(`k2`,'year'))
DISTRIBUTED BY RANDOM BUCKETS 2
AS
SELECT * FROM t1;SQL 定义
异步物化视图 SQL 定义没有限制。
直查物化视图
物化视图可以看作是表,可以对物化视图添加过滤条件和聚合等,进行直接查询。
物化视图的定义:
CREATE MATERIALIZED VIEW mv_5
BUILD IMMEDIATE
REFRESH AUTO
ON SCHEDULE EVERY 1 hour
DISTRIBUTED BY RANDOM BUCKETS 3
AS
SELECT t1.l_linenumber,
o_custkey,
o_orderdate
FROM (SELECT * FROM lineitem WHERE l_linenumber > 1) t1
LEFT OUTER JOIN orders
ON l_orderkey = o_orderkey;原查询如下
SELECT t1.l_linenumber,
o_custkey,
o_orderdate
FROM (SELECT * FROM lineitem WHERE l_linenumber > 1) t1
LEFT OUTER JOIN orders
ON l_orderkey = o_orderkey
WHERE o_orderdate = '2023-10-18';等价的直查物化语句如下,用户需要手动修改查询
SELECT
l_linenumber,
o_custkey
FROM mv_5
WHERE l_linenumber > 1 and o_orderdate = '2023-10-18';二、 索引
数据库索引是用于查询加速的,为了加速不同的查询场景,Apache Doris 支持了多种丰富的索引。
索引分类和原理
从加速的查询和原理来看,Apache Doris 的索引分为点查索引和跳数索引两大类。
- 点查索引 :常用于加速点查,原理是通过索引定位到满足 WHERE 条件的有哪些行,直接读取那些行。点查索引在满足条件的行比较少时效果很好 。Apache Doris 的点查索引包括前缀索引和倒排索引。
-
- 前缀索引:Apache Doris 按照排序键以有序的方式存储数据,并每隔 1024 行数据创建一个稀疏前缀索引。索引中的 Key 是当前 1024 行中第一行中排序列的值。如果查询涉及已排序列,系统将找到相关 1024 行组的第一行并从那里开始扫描。
前缀索引采用的是稀疏索引,每隔 1024 行,创建一条索引。
-
- 倒排索引:对创建了倒排索引的列,建立每个值到对应行号集合的倒排表。对于等值查询,先从倒排表中查到行号集合,然后直接读取对应行的数据,而不用逐行扫描匹配数据,从而减少 I/O 加速查询。倒排索引还能加速范围过滤、文本关键词匹配,算法更加复杂但是基本原理类似。(备注:之前的 BITMAP 索引已经被更强的倒排索引取代)
倒排索引也是非常有名的索引,比如 ElaticSearch 采用的就是倒排索引。
- 跳数索引 :常用于加速分析,原理是通过索引确定不满足 WHERE 条件的数据块,跳过这些不满足条件的数据块,只读取可能满足条件的数据块并再进行一次逐行过滤,最终得到满足条件的行。跳数索引在满足条件的行比较多时效果较好。Apache Doris 的跳数索引包括 ZoneMap 索引、BloomFilter 索引、NGram BloomFilter 索引。
-
- ZoneMap 索引:自动维护每一列的统计信息,为每一个数据文件(Segment)和数据块(Page)记录最大值、最小值、是否有 NULL。对于等值查询、范围查询、IS NULL,可以通过最大值、最小值、是否有 NULL 来判断数据文件和数据块是否可以包含满足条件的数据,如果没有则跳过不读对应的文件或数据块减少 I/O 加速查询。
- BloomFilter 索引:将索引对应列的可能取值存入 BloomFilter 数据结构中,它可以快速判断一个值是否在 BloomFilter 里面,并且 BloomFilter 存储空间占用很低。对于等值查询,如果判断这个值不在 BloomFilter 里面,就可以跳过对应的数据文件或者数据块减少 I/O 加速查询。
- NGram BloomFilter 索引:用于加速文本 LIKE 查询,基本原理与 BloomFilter 索引类似,只是存入 BloomFilter 的不是原始文本的值,而是对文本进行 NGram 分词,每个词作为值存入 BloomFilter。对于 LIKE 查询,将 LIKE 的 pattern 也进行 NGram 分词,判断每个词是否在 BloomFilter 中,如果某个词不在则对应的数据文件或者数据块就不满足 LIKE 条件,可以跳过这部分数据减少 I/O 加速查询。
上述索引中,前缀索引和 ZoneMap 索引是 Apache Doris 自动维护的内建智能索引,无需用户管理,而倒排索引、BloomFilter 索引、NGram BloomFilter 索引则需要用户自己根据场景选择,手动创建、删除。
索引设计指南
数据库表的索引设计和优化跟数据特点和查询很相关,需要根据实际场景测试和优化。虽然没有 "银弹",Apache Doris 仍然不断努力降低用户使用索引的难度,用户可以根据下面的简单建议原则进行索引选择和测试。
- 最频繁使用的过滤条件指定为 Key 自动建前缀索引,因为它的过滤效果最好,但是一个表只能有一个前缀索引,因此要用在最频繁的过滤条件上
- 对非 Key字段如有过滤加速需求,首选建倒排索引,因为它的适用面广,可以多条件组合,次选下面两种索引:
- 有字符串 LIKE 匹配需求,再加一个 NGram BloomFilter 索引
- 对索引存储空间很敏感,将倒排索引换成 BloomFilter 索引
前缀索引与排序键
前缀索引是自动加的,最多 36 位
索引原理
Doris 的数据存储在类似 SSTable(Sorted String Table)的数据结构中。该结构是一种有序的数据结构,可以按照指定的一个或多个列进行排序存储。在这种数据结构上,以排序列的全部或者前面几个作为条件进行查找,会非常的高效。
在 Aggregate、Unique 和 Duplicate 三种数据模型中。底层的数据存储,是按照各自建表语句中,Aggregate Key、Unique Key 和 Duplicate Key 中指定的列进行排序存储的。这些 Key,称为排序键(Sort Key)。借助排序键,在查询时,通过给排序列指定条件,Doris 不需要扫描全表即可快速找到需要处理的数据,降低搜索的复杂度,从而加速查询。
在排序键的基础上,又引入了前缀索引(Prefix Index)。前缀索引是一种稀疏索引。表中按照相应的行数的数据构成一个逻辑数据块 (Data Block)。每个逻辑数据块在前缀索引表中存储一个索引项,索引项的长度不超过 36 字节,其内容为数据块中第一行数据的排序列组成的前缀,在查找前缀索引表时可以帮助确定该行数据所在逻辑数据块的起始行号。由于前缀索引比较小,所以,可以全量在内存缓存,快速定位数据块,大大提升了查询效率。
提示
数据块一行数据的前 36 个字节作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断。如果第一列即为 VARCHAR,那么即使没有达到 36 字节,也会直接截断,后面的列不再加入前缀索引。
使用场景
前缀索引可以加速等值查询和范围查询。
管理索引
前缀索引没有专门的语法去定义,建表时自动取表的 Key 的前 36 字节作为前缀索引。
前缀索引选择建议
提示
因为一个表的 Key 定义是唯一的,所以一个表只有一组前缀索引,因此设计表结构时选择合适的前缀索引很重要,可以参考下面的建议:
- 选择查询中最常用于 WHERE 过滤条件的字段作为 Key。
- 约常用的字段越放在前面,因为前缀索引只对 WHERE 条件中字段在 Key 的前缀中才有效。
使用其他不能命中前缀索引的列作为条件进行的查询来说,效率上可能无法满足需求,有两种解决方案:
- 对需要加速查询的条件列创建倒排索引,由于一个表的倒排索引可以有很多个。
- 对于 Duplicate 表可以通过创建相应的调整了列顺序的单表强一致物化视图来间接实现多种前缀索引,详情可参考查询加速/物化视图。
使用索引
前缀索引用于加速 WHERE 条件中的等值和范围查询,能加速时自动生效,没有特殊语法。
可以通过 Query Profile 中的下面几个指标分析前缀索引的加速效果。
- RowsKeyRangeFiltered 前缀索引过滤掉的行数,可以与其他几个 Rows 值对比分析索引过滤效果
使用示例
- 假如表的排序列为如下 5 列,那么前缀索引为:user_id(8 Bytes) + age(4 Bytes) + message(prefix 20 Bytes)。

|----------------|--------------|
| ColumnName | Type |
| user_id | BIGINT |
| age | INT |
| message | VARCHAR(100) |
| max_dwell_time | DATETIME |
| min_dwell_time | DATETIME |
- 假如表的排序列为如下 5 列,则前缀索引为 user_name(20 Bytes)。即使没有达到 36 个字节,因为遇到 VARCHAR,所以直接截断,不再往后继续。
|----------------|--------------|
| ColumnName | Type |
| user_name | VARCHAR(20) |
| age | INT |
| message | VARCHAR(100) |
| max_dwell_time | DATETIME |
| min_dwell_time | DATETIME |
-
当我们的查询条件,是前缀索引的前缀时,可以极大地加快查询速度。比如在第一个例子中,执行如下查询:
SELECT * FROM table WHERE user_id=1829239 and age=20;
该查询的效率会远高于如下查询:
SELECT * FROM table WHERE age=20;所以在建表时,正确选择列顺序,能够极大地提高查询效率。
倒排索引
索引原理
倒排索引,是信息检索领域常用的索引技术,将文本分成一个个词,构建 词 -> 文档编号 的索引,可以快速查找一个词在哪些文档出现。
从 2.0.0 版本开始,Doris 支持倒排索引,可以用来进行文本类型的全文检索、普通数值日期类型的等值范围查询,快速从海量数据中过滤出满足条件的行。
在 Doris 的倒排索引实现中,Table 的一行对应一个文档、一列对应文档中的一个字段,因此利用倒排索引可以根据关键词快速定位包含它的行,达到 WHERE 子句加速的目的
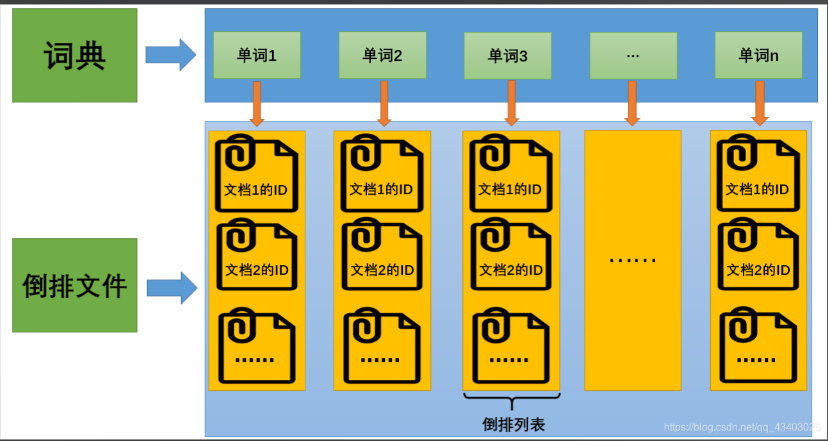
一、正排索引(不是倒排索引)------就像「书的目录」
- •正排索引 ,简单来说就是:通过某个东西(比如书的编号、文档ID),找到这个东西的详细内容。
🔍 类比:
- •图书馆里每本书都有一个编号,比如「书号001」「书号002」......
- •正排索引就像是一张表,写着:
-
- •书号001 → 《西游记》,作者吴承恩,放在第3层A架
- •书号002 → 《红楼梦》,作者曹雪芹,放在第2层B架
- •你通过"书号"能找到这本书的信息和位置。
二、倒排索引 ------ 就像「关键词找书」
- •倒排索引 就是反过来:不是通过书去找信息,而是通过某个关键字(比如"孙悟空"),找到哪些书提到了它。
🔍 类比:
- •假如我们为图书馆建立了一个「关键词索引表」,记录每个词出现在哪些书里:
-
- •"孙悟空" → 出现在书号001(《西游记》)、书号045(某本改编小说)
- •"林黛玉" → 出现在书号002(《红楼梦》)
- •你直接通过关键词(比如"孙悟空"),就能立刻知道哪些书提到了它,不用一本本翻!
建表时定义倒排索引
在建表语句中 COLUMN 的定义之后是索引定义:
CREATE TABLE table_name
(
column_name1 TYPE1,
column_name2 TYPE2,
column_name3 TYPE3,
INDEX idx_name1(column_name1) USING INVERTED [PROPERTIES(...)] [COMMENT 'your comment'],
INDEX idx_name2(column_name2) USING INVERTED [PROPERTIES(...)] [COMMENT 'your comment']
)
table_properties;语法说明如下:
1. idx_column_name(column_name)是必须的, **column_name**是建索引的列名,必须是前面列定义中出现过的, idx_column_name****是索引名字,必须表级别唯一,建议命名规范:列名前面加前缀 idx_
2. USING INVERTED****是必须的,用于指定索引类型是倒排索引
3、 PROPERTIES****是可选的,用于指定倒排索引的额外属性
用分词函数验证分词效果
python 的 jieba ,java 中 ik 分词器 效果是一样的
如果想检查分词实际效果或者对一段文本进行分词行为,可以使用 TOKENIZE 函数进行验证。
TOKENIZE 函数的第一个参数是待分词的文本,第二个参数是创建索引指定的分词参数。
SELECT TOKENIZE('武汉长江大桥','"parser"="chinese","parser_mode"="fine_grained"');
+-----------------------------------------------------------------------------------+
| tokenize('武汉长江大桥', '"parser"="chinese","parser_mode"="fine_grained"') |
+-----------------------------------------------------------------------------------+
| ["武汉", "武汉长江大桥", "长江", "长江大桥", "大桥"] |
+-----------------------------------------------------------------------------------+
SELECT TOKENIZE('武汉市长江大桥','"parser"="chinese","parser_mode"="fine_grained"');
+--------------------------------------------------------------------------------------+
| tokenize('武汉市长江大桥', '"parser"="chinese","parser_mode"="fine_grained"') |
+--------------------------------------------------------------------------------------+
| ["武汉", "武汉市", "市长", "长江", "长江大桥", "大桥"] |
+--------------------------------------------------------------------------------------+
SELECT TOKENIZE('武汉市长江大桥','"parser"="chinese","parser_mode"="coarse_grained"');
+----------------------------------------------------------------------------------------+
| tokenize('武汉市长江大桥', '"parser"="chinese","parser_mode"="coarse_grained"') |
+----------------------------------------------------------------------------------------+
| ["武汉市", "长江大桥"] |
+----------------------------------------------------------------------------------------+
SELECT TOKENIZE('I love Doris','"parser"="english"');
+------------------------------------------------+
| tokenize('I love Doris', '"parser"="english"') |
+------------------------------------------------+
| ["i", "love", "doris"] |
+------------------------------------------------+
SELECT TOKENIZE('I love CHINA 我爱我的祖国','"parser"="unicode"');
+-------------------------------------------------------------------+
| tokenize('I love CHINA 我爱我的祖国', '"parser"="unicode"') |
+-------------------------------------------------------------------+
| ["i", "love", "china", "我", "爱", "我", "的", "祖", "国"] |
+-------------------------------------------------------------------+使用示例
用 HackerNews 100 万条数据展示倒排索引的创建、全文检索、普通查询,包括跟无索引的查询性能进行简单对比。
支持关键词检索,包括同时匹配多个关键字 MATCH_ALL、匹配任意一个关键字 MATCH_ANY
建表
CREATE DATABASE test_inverted_index;
USE test_inverted_index;
-- 创建表的同时创建了 comment 的倒排索引 idx_comment
-- USING INVERTED 指定索引类型是倒排索引
-- PROPERTIES("parser" = "english") 指定采用 "english" 分词,还支持 "chinese" 中文分词和 "unicode" 中英文多语言混合分词,如果不指定 "parser" 参数表示不分词
CREATE TABLE hackernews_1m
(
`id` BIGINT,
`deleted` TINYINT,
`type` String,
`author` String,
`timestamp` DateTimeV2,
`comment` String,
`dead` TINYINT,
`parent` BIGINT,
`poll` BIGINT,
`children` Array<BIGINT>,
`url` String,
`score` INT,
`title` String,
`parts` Array<INT>,
`descendants` INT,
INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");导入数据
通过 Stream Load 导入数据
wget https://qa-build.oss-cn-beijing.aliyuncs.com/regression/index/hacknernews_1m.csv.gz
curl --location-trusted -u root:123456 -H "compress_type:gz" -T hacknernews_1m.csv.gz http://127.0.0.1:8030/api/test_inverted_index/hackernews_1m/_stream_load
导入成功后的报告如下:
{
"TxnId": 2,
"Label": "a8a3e802-2329-49e8-912b-04c800a461a6",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 1000000,
"NumberLoadedRows": 1000000,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 130618406,
"LoadTimeMs": 8988,
"BeginTxnTimeMs": 23,
"StreamLoadPutTimeMs": 113,
"ReadDataTimeMs": 4788,
"WriteDataTimeMs": 8811,
"CommitAndPublishTimeMs": 38
}SQL 运行 count() 确认导入数据成功
SELECT count(1) FROM hackernews_1m;
+---------+
| count() |
+---------+
| 1000000 |
+---------+查询
01 全文检索
-
用
LIKE匹配计算 comment 中含有 'OLAP' 的行数,耗时 0.18sSELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%';
+---------+
| count() |
+---------+
| 34 |
+---------+ -
用基于倒排索引的全文检索
MATCH_ANY计算 comment 中含有'OLAP'的行数,耗时 0.02s,加速 9 倍,在更大的数据集上效果会更加明显
这里结果条数的差异,是因为倒排索引 对 comment 分词后,还会对词进行进行统一成小写等归一化处理,因此 MATCH_ANY 比 LIKE 的结果多一些
SELECT count() FROM hackernews_1m WHERE comment MATCH_ANY 'OLAP';
+---------+
| count() |
+---------+
| 35 |
+---------+-
同样的对比统计 'OLTP' 出现次数的性能,0.07s vs 0.01s,由于缓存的原因
LIKE和MATCH_ANY都有提升,倒排索引仍然有7 倍加速SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 48 |
+---------+SELECT count() FROM hackernews_1m WHERE comment MATCH_ANY 'OLTP';
+---------+
| count() |
+---------+
| 51 |
+---------+ -
同时出现 'OLAP' 和 'OLTP' 两个词,0.13s vs 0.01s,13 倍加速
要求多个词同时出现时(AND 关系)使用 MATCH_ALL 'keyword1 keyword2 ...'
SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 14 |
+---------+
SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+- 任意出现 'OLAP' 和 'OLTP' 其中一个词,0.12s vs 0.01s,12 倍加速
只要求多个词任意一个或多个出现时(OR 关系)使用 MATCH_ANY 'keyword1 keyword2 ...'
SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' OR comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 68 |
+---------+
SELECT count() FROM hackernews_1m WHERE comment MATCH_ANY 'OLAP OLTP';
+---------+
| count() |
+---------+
| 71 |
+---------+BloomFilter 索引
索引原理
BloomFilter 索引是基于 BloomFilter 的一种跳数索引。它的原理是利用 BloomFilter 跳过等值查询指定条件不满足的数据块,达到减少 I/O 查询加速的目的。
BloomFilter 是由 Bloom 在 1970 年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求 100% 正确的场合,BloomFilter 有以下特点:
- 空间效率高的概率型数据结构,用来检查一个元素是否在一个集合中。
- 对于一个元素检测是否存在的调用,BloomFilter 会告诉调用者两个结果之一:可能存在或者一定不存在。
BloomFilter 是由一个超长的二进制位数组和一系列的哈希函数组成。二进制位数组初始全部为 0,当给定一个待查询的元素时,这个元素会被一系列哈希函数计算映射出一系列的值,所有的值在位数组的偏移量处置为 1。
下图所示出一个 m=18, k=3(m 是该 Bit 数组 的大小,k 是 Hash 函数的个数)的 BloomFilter 示例。集合中的 x、y、z 三个元素通过 3 个不同的哈希函数散列到位数组中。当查询元素 w 时,通过 Hash 函数计算之后只要有一个位为 0,因此 w 不在该集合中。但是反过来全部都是 1 只能说明可能在集合中、不能肯定一定在集合中,因为 Hash 函数可能出现 Hash 碰撞。
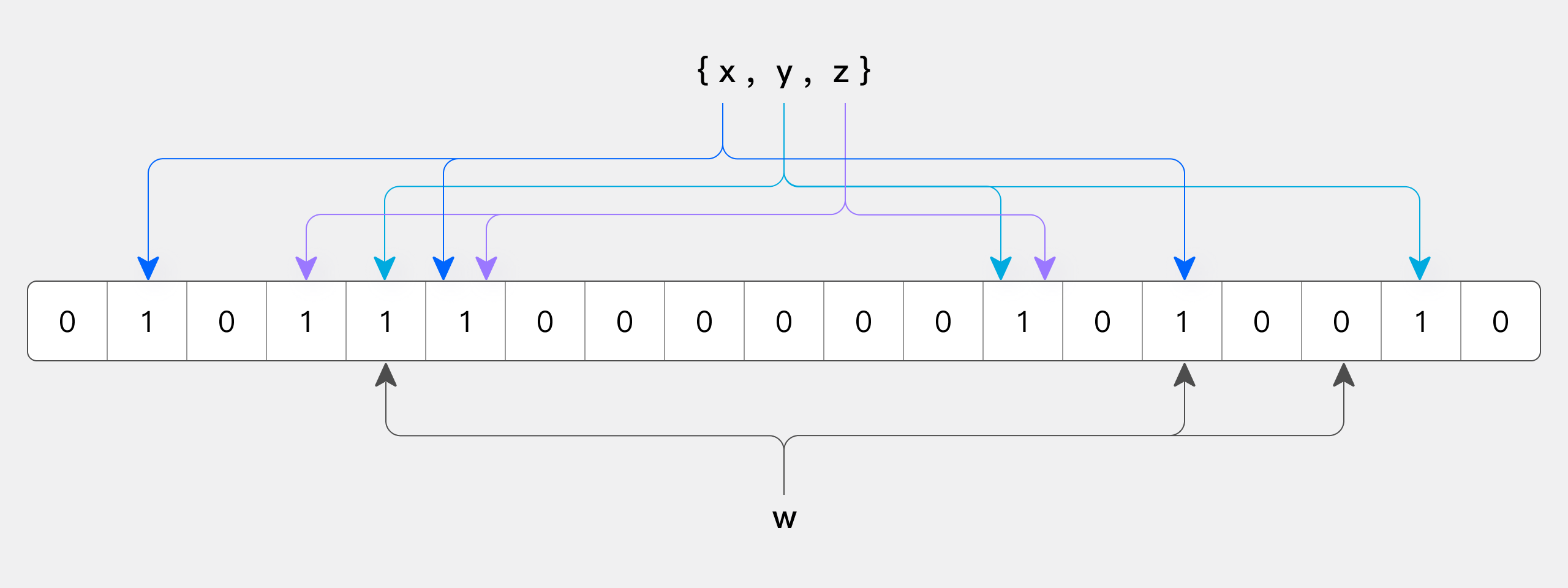
反过来如果某个元素经过哈希函数计算后得到所有的偏移位置,若这些位置全都为 1,只能说明可能在集合中、不能肯定一定在集合中,因为 Hash 函数可能出现 Hash 碰撞。这就是 BloomFilter"假阳性",因此基于 BloomFilter 的索引只能跳过不满足条件的数据,不能精确定位满足条件的数据。
Doris BloomFilter 索引以数据块(page)为单位构建,每个数据块存储一个 BloomFilter。写入时,对于数据块中的每个值,经过 Hash 存入数据块对应的 BloomFilter。查询时,根据等值条件的值,判断每个数据块对应的 BloomFilter 是否包含这个值,不包含则跳过对应的数据块不读取,达到减少 I/O 查询加速的目的。
使用场景
BloomFilter 索引能够对等值查询(包括 = 和 IN)加速 ,对高基数字段效果较好,比如 userid 等唯一 ID 字段。
提示
BloomFilter 的使用有下面一些限制:
- 对 IN 和 = 之外的查询没有效果,比如 !=, NOT IN, >, < 等
- 不支持对 Tinyint、Float、Double 类型的列建 BloomFilter 索引。
- 对低基数字段的加速效果很有限,比如"性别"字段仅有两种值,几乎每个数据块都会包含所有取值,导致 BloomFilter 索引失去意义。
如果要查看某个查询 BloomFilter 索引效果,可以通过 Query Profile 中的相关指标进行分析。
- BlockConditionsFilteredBloomFilterTime 是 BloomFilter 索引消耗的时间
- RowsBloomFilterFiltered 是 BloomFilter 过滤掉的行数,可以与其他几个 Rows 值对比分析 BloomFilter 索引过滤效果
管理索引
建表时创建 BloomFilter 索引
由于历史原因,BloomFilter 索引定义的语法与倒排索引等通用 INDEX 语法不一样。BloomFilter 索引通过表的 PROPERTIES "bloom_filter_columns" 指定哪些字段建 BloomFilter 索引,可以指定一个或者多个字段。
PROPERTIES (
"bloom_filter_columns" = "column_name1,column_name2"
);查看 BloomFilter 索引
SHOW CREATE TABLE table_name;已有表增加、删除 BloomFilter 索引
通过 ALTER TABLE 修改表的 bloom_filter_columns 属性来完成。
为 column_name3 增加 BloomFilter 索引
ALTER TABLE table_name SET ("bloom_filter_columns" = "column_name1,column_name2,column_name3");删除 column_name1 的 BloomFilter 索引
ALTER TABLE table_name SET ("bloom_filter_columns" = "column_name2,column_name3");使用索引
BloomFilter 索引用于加速 WHERE 条件中的等值查询,能加速时自动生效,没有特殊语法。
可以通过 Query Profile 中的下面几个指标分析 BloomFilter 索引的加速效果。
- RowsBloomFilterFiltered BloomFilter 索引过滤掉的行数,可以与其他几个 Rows 值对比分析索引过滤效果
- BlockConditionsFilteredBloomFilterTime BloomFilter 倒排索引消耗的时间
使用示例
下面通过实例来看看 Doris 怎么创建 BloomFilter 索引。
Doris BloomFilter 索引的创建是通过在建表语句的 PROPERTIES 里加上 "bloom_filter_columns"="k1,k2,k3", 这个属性,k1,k2,k3 是要创建的 BloomFilter 索引的 Key 列名称,例如下面对表里的 saler_id,category_id 创建了 BloomFilter 索引。
CREATE TABLE IF NOT EXISTS sale_detail_bloom (
sale_date date NOT NULL COMMENT "销售时间",
customer_id int NOT NULL COMMENT "客户编号",
saler_id int NOT NULL COMMENT "销售员",
sku_id int NOT NULL COMMENT "商品编号",
category_id int NOT NULL COMMENT "商品分类",
sale_count int NOT NULL COMMENT "销售数量",
sale_price DECIMAL(12,2) NOT NULL COMMENT "单价",
sale_amt DECIMAL(20,2) COMMENT "销售总金额"
)
Duplicate KEY(sale_date, customer_id,saler_id,sku_id,category_id)
DISTRIBUTED BY HASH(saler_id) BUCKETS 10
PROPERTIES (
"replication_num" = "1",
"bloom_filter_columns"="saler_id,category_id"
);
select * from sale_detail_bloom where saler_id='xxxxxx';三、 doris中join的优化原理
https://doris.apache.org/zh-CN/docs/query-data/join
Hive中都有哪些Join?
1、map join
2、smb join (分桶表Join)
3、shuffle join (reduce Join )

Shuffle Join(Partitioned Join)
和mr中的shuffle过程是一样的,针对每个节点上的数据进行shuffle,相同数据分发到下游的节点上的join方式叫shuffle join
订单明细表:
CREATE TABLE test.order_info_shuffle
(
`order_id` varchar(20) COMMENT "订单id",
`user_id` varchar(20) COMMENT "用户id",
`goods_id` VARCHAR(20) COMMENT "商品id",
`goods_num` Int COMMENT "商品数量",
`price` double COMMENT "商品价格"
)
duplicate KEY(`order_id`)
DISTRIBUTED BY HASH(`order_id`) BUCKETS 5
properties("replication_num" = "1");
导入数据:
insert into test.order_info_shuffle values
('o001','u001','g001',1,9.9 ),
('o001','u001','g002',2,19.9),
('o001','u001','g003',2,39.9),
('o002','u002','g001',3,9.9 ),
('o002','u002','g002',1,19.9),
('o003','u002','g003',1,39.9),
('o003','u002','g002',2,19.9),
('o003','u002','g004',3,99.9),
('o003','u002','g005',1,99.9),
('o004','u003','g001',2,9.9 ),
('o004','u003','g002',1,19.9),
('o004','u003','g003',4,39.9),
('o004','u003','g004',1,99.9),
('o004','u003','g005',4,89.9);商品表:
CREATE TABLE test.goods_shuffle
(
`goods_id` VARCHAR(20) COMMENT "商品id",
`goods_name` VARCHAR(20) COMMENT "商品名称",
`category_id` VARCHAR(20) COMMENT "商品品类id"
)
duplicate KEY(`goods_id`)
DISTRIBUTED BY HASH(`goods_id`) BUCKETS 5
properties("replication_num" = "1")
;
导入数据:
insert into test.goods_shuffle values
('g001','iphon13','c001'),
('g002','ipad','c002'),
('g003','xiaomi12','c001'),
('g004','huaweip40','c001'),
('g005','headset','c003');Sql示例:
EXPLAIN
select
oi.order_id,
oi.user_id,
oi.goods_id,
gs.goods_name,
gs.category_id,
oi.goods_num,
oi.price
from order_info_shuffle as oi
-- 我们可以不指定哪一种join方式,doris会自己根据数据的实际情况帮我们选择
JOIN [shuffle] goods_shuffle as gs
on oi.goods_id = gs.goods_id;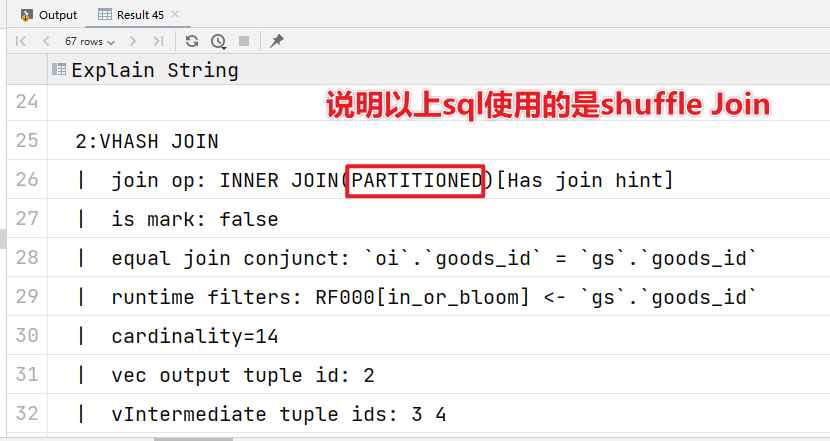
适用场景:不管数据量,不管是大表join大表还是大表join小表都可以用
优点:通用
缺点:需要shuffle内存和网络开销比较大,效率不高
Broadcast Join
当一个大表join小表 的时候,将小表广播到每一个大表所在的每一个节点上(以hash表的形式放在内存中)这样的方式叫做Broadcast Join,类似于mr里面的一个map端join 【map join】
订单明细表:
CREATE TABLE test.order_info_broadcast
(
`order_id` varchar(20) COMMENT "订单id",
`user_id` varchar(20) COMMENT "用户id",
`goods_id` VARCHAR(20) COMMENT "商品id",
`goods_num` Int COMMENT "商品数量",
`price` double COMMENT "商品价格"
)
duplicate KEY(`order_id`)
DISTRIBUTED BY HASH(`goods_id`) BUCKETS 5;
insert into test.order_info_broadcast values
('o001','u001','g001',1,9.9 ),
('o001','u001','g002',2,19.9),
('o001','u001','g003',2,39.9),
('o002','u002','g001',3,9.9 ),
('o002','u002','g002',1,19.9),
('o003','u002','g003',1,39.9),
('o003','u002','g002',2,19.9),
('o003','u002','g004',3,99.9),
('o003','u002','g005',1,99.9),
('o004','u003','g001',2,9.9 ),
('o004','u003','g002',1,19.9),
('o004','u003','g003',4,39.9),
('o004','u003','g004',1,99.9),
('o004','u003','g005',4,89.9);商品表:
CREATE TABLE test.goods_broadcast
(
`goods_id` VARCHAR(20) COMMENT "商品id",
`goods_name` VARCHAR(20) COMMENT "商品名称",
`category_id` VARCHAR(20) COMMENT "商品品类id"
)
duplicate KEY(`goods_id`)
DISTRIBUTED BY HASH(`goods_id`) BUCKETS 5;
insert into test.goods_broadcast values
('g001','iphon13','c001'),
('g002','ipad','c002'),
('g003','xiaomi12','c001'),
('g004','huaweip40','c001'),
('g005','headset','c003');-
显式使用 Broadcast Join:
EXPLAIN
select
oi.order_id,
oi.user_id,
oi.goods_id,
gs.goods_name,
gs.category_id,
oi.goods_num,
oi.price
from order_info_broadcast as oi
JOIN [broadcast] goods_broadcast as gs
on oi.goods_id = gs.goods_id;
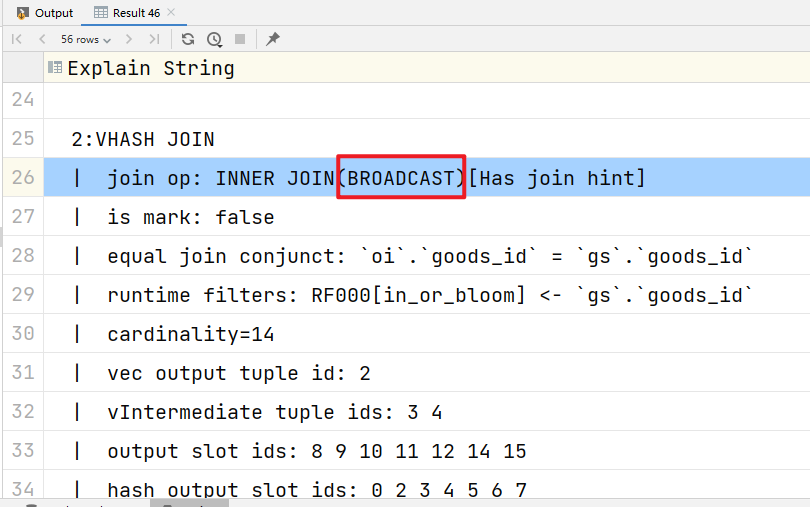
他一般用在什么场景下:左表join右表,要求左表的数据量相对来说比较大,右表数据量比较小
优点:避免了shuffle,提高了运算效率
缺点:有限制,必须右表数据量比较小
Bucket Shuffle Join (有点类似smb join)
利用建表时候分桶的特性 ,当join的时候,join的条件和左表的分桶字段一样的时候 ,将右表按照左表分桶的规则 进行shuffle操作,使右表中需要join的数据落在左表中需要join数据的BE节点上的join方式叫做Bucket Shuffle Join。
使用
从 0.14 版本开始默认为 true,新版本可以不用设置这个参数了!
show variables like '%bucket_shuffle_join%';
set enable_bucket_shuffle_join = true;订单明细表:
CREATE TABLE test.order_info_bucket
(
`order_id` varchar(20) COMMENT "订单id",
`user_id` varchar(20) COMMENT "用户id",
`goods_id` VARCHAR(20) COMMENT "商品id",
`goods_num` Int COMMENT "商品数量",
`price` double COMMENT "商品价格"
)
duplicate KEY(`order_id`)
DISTRIBUTED BY HASH(`goods_id`) BUCKETS 5
properties("replication_num" = "1");
导入数据:
insert into test.order_info_bucket values
('o001','u001','g001',1,9.9 ),
('o001','u001','g002',2,19.9),
('o001','u001','g003',2,39.9),
('o002','u002','g001',3,9.9 ),
('o002','u002','g002',1,19.9),
('o003','u002','g003',1,39.9),
('o003','u002','g002',2,19.9),
('o003','u002','g004',3,99.9),
('o003','u002','g005',1,99.9),
('o004','u003','g001',2,9.9 ),
('o004','u003','g002',1,19.9),
('o004','u003','g003',4,39.9),
('o004','u003','g004',1,99.9),
('o004','u003','g005',4,89.9);商品表:
CREATE TABLE test.goods_bucket
(
`goods_id` VARCHAR(20) COMMENT "商品id",
`goods_name` VARCHAR(20) COMMENT "商品名称",
`category_id` VARCHAR(20) COMMENT "商品品类id"
)
duplicate KEY(`goods_id`)
DISTRIBUTED BY HASH(`goods_id`) BUCKETS 3
properties("replication_num" = "1");
导入数据:
insert into test.goods_bucket values
('g001','iphon13','c001'),
('g002','ipad','c002'),
('g003','xiaomi12','c001'),
('g004','huaweip40','c001'),
('g005','headset','c003');通过 explain 查看 join 类型
选择的顺序:Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join。
EXPLAIN
select
oi.order_id,
oi.user_id,
oi.goods_id,
gs.goods_name,
gs.category_id,
oi.goods_num,
oi.price
from goods_bucket as gs
-- 目前 Bucket Shuffle Join不能像Shuffle Join那样可以显示指定Join方式,
-- 只能让执行引擎自动选择,
-- 选择的顺序:Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join。
JOIN order_info_bucket as oi
where oi.goods_id = gs.goods_id;
注意事项
- Bucket Shuffle Join 只生效于Join 条件为等值的场景
- Bucket Shuffle Join 要求左表的分桶列的类型与右表等值 join 列的类型需要保持一致,否则无法进行对应的规划。
- Bucket Shuffle Join 只作用于 Doris 原生的 OLAP 表,对于 ODBC,MySQL,ES 等外表,当其作为左表时是无法规划生效的。
- Bucket Shuffle Join只能保证左表为单分区时生效。所以在 SQL 执行之中,需要尽量使用 where 条件使分区裁剪的策略能够生效。
Colocation托管 Join
中文意思叫位置协同分组join,指需要join的两份数据都在同一个BE节点 上,这样在join的时候,直接本地 join计算即可,不需要进行shuffle。
1 名词解释
- Colocation Group(位置协同组CG):在同一个 CG内的 Table 有着相同的 Colocation Group Schema,并且有着相同的数据分片分布 (满足三个条件**)**。
- Colocation Group Schema(CGS):用于描述一个 CG 中的 Table,和 Colocation 相关的通用 Schema 信息。包括分桶列类型,分桶数以及分区的副本数等。
2 使用限制
- 建表时两张表的分桶列的类型和数量需要完全一致 ,并且桶数一致,才能保证多张表的数据分片能够一一对应的进行分布控制。
- 同一个 CG 内所有表的所有分区(Partition)的副本数必须一致。如果不一致,可能出现某一个Tablet 的某一个副本,在同一个 BE 上没有其他的表分片的副本对应
- 同一个 CG 内的表,分区的个数、范围以及分区列的类型不要求一致。
3 使用案例
建两张表,分桶列都为 int 类型,且桶的个数都是 5 个。副本数都为默认副本数。
CREATE TABLE test.order_info_colocation
(
`order_id` varchar(20) COMMENT "订单id",
`user_id` varchar(20) COMMENT "用户id",
`goods_id` VARCHAR(20) COMMENT "商品id",
`goods_num` Int COMMENT "商品数量",
`price` double COMMENT "商品价格"
)
duplicate KEY(`order_id`)
DISTRIBUTED BY HASH(`goods_id`) BUCKETS 5
--指定组的定义
PROPERTIES (
"replication_num" = "1",
"colocate_with" = "group1"
);
导入数据:
insert into test.order_info_colocation values
('o001','u001','g001',1,9.9 ),
('o001','u001','g002',2,19.9),
('o001','u001','g003',2,39.9),
('o002','u002','g001',3,9.9 ),
('o002','u002','g002',1,19.9),
('o003','u002','g003',1,39.9),
('o003','u002','g002',2,19.9),
('o003','u002','g004',3,99.9),
('o003','u002','g005',1,99.9),
('o004','u003','g001',2,9.9 ),
('o004','u003','g002',1,19.9),
('o004','u003','g003',4,39.9),
('o004','u003','g004',1,99.9),
('o004','u003','g005',4,89.9);
-- 创建商品表
drop table test.goods_colocation ;
CREATE TABLE test.goods_colocation
(
`goods_id` VARCHAR(20) COMMENT "商品id",
`goods_name` VARCHAR(20) COMMENT "商品名称",
`category_id` VARCHAR(20) COMMENT "商品品类id"
)
duplicate KEY(`goods_id`)
DISTRIBUTED BY HASH(`goods_id`) BUCKETS 5
PROPERTIES (
"replication_num" = "1",
"colocate_with" = "group1"
);
导入数据:
insert into test.goods_colocation values
('g001','iphon13','c001'),
('g002','ipad','c002'),
('g003','xiaomi12','c001'),
('g004','huaweip40','c001'),
('g005','headset','c003');编写查询语句,并查看执行计划
EXPLAIN
select
oi.order_id,
oi.user_id,
oi.goods_id,
gs.goods_name,
gs.category_id,
oi.goods_num,
oi.price
from order_info_colocation as oi
-- 目前 Colocation Join不能像Shuffle Join那样可以显示指定Join方式,
-- 只能让执行引擎自动选择,
-- 选择的顺序:Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join。
JOIN goods_colocation as gs
on oi.goods_id = gs.goods_id ;
查看 Group
SHOW PROC '/colocation_group';当 Group 中最后一张表彻底删除后(彻底删除是指从回收站中删除。通常,一张表通过DROP TABLE 命令删除后,会在回收站默认停留一天的时间后,再删除),该 Group 也会被自动删除。
修改表 Colocate Group 属性
ALTER TABLE tbl SET ("colocate_with" = "group2");如果被修改的表原来有group,那么会直接将原来的group删除后创建新的group
如果原来没有组,就直接创建
删除表的 Colocation 属性
ALTER TABLE tbl SET ("colocate_with" = "");当对一个具有 Colocation 属性的表进行增加分区(ADD PARTITION)、修改副本数时,Doris 会检查修改是否会违反 Colocation Group Schema,如果违反则会拒绝。
Doris的端口号和Yarn有冲突,解决方案
https://blog.csdn.net/w65er5/article/details/128504084
在hadoop下修改yarn-site.xml文件,如果是高可用,带上.rm1
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop11:8035</value> <!-- 这里只修改端口号 8030 -> 8035 -->
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop12:8035</value> <!-- 这里只修改端口号 8030 -> 8035 -->
</property>
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>hadoop11:8046</value> <!-- 这里只修改端口号 8040 -> 8046 -->
</property>Yarn 和 Doris 中的一些服务端口有冲突,一般选择 yarn 妥协,修改端口。
四、Doris 和其他技术的整合
7.1 和 DataX 的整合
以将 mysql 导入 doris 为例:
关于 datax 的源码编译:
https://www.yuque.com/yxiansheng-njx6f/uizabi/yi8lg6oipqg1fdom
重新安装 datax:
mv datax _datax
cd /opt/modules/
tar -zxvf datax.tar.gz -C /opt/installs/
cd /opt/installs/datax/bin/
chmod 777 datax.pyMysql 数据库准备
下面是我数据库的建表脚本(mysql 8):
CREATE TABLE `order_analysis` (
`date` varchar(19) DEFAULT NULL,
`user_src` varchar(9) DEFAULT NULL,
`order_src` varchar(11) DEFAULT NULL,
`order_location` varchar(2) DEFAULT NULL,
`new_order` int DEFAULT NULL,
`payed_order` int DEFAULT NULL,
`pending_order` int DEFAULT NULL,
`cancel_order` int DEFAULT NULL,
`reject_order` int DEFAULT NULL,
`good_order` int DEFAULT NULL,
`report_order` int DEFAULT NULL
)示例数据:
INSERT INTO `order_analysis` (`date`, `user_src`, `order_src`, `order_location`, `new_order`, `payed_order`, `pending_order`, `cancel_order`, `reject_order`, `good_order`, `report_order`) VALUES ('2015-10-12 00:00:00', '广告二维码', 'Android APP', '上海', 15253, 13210, 684, 1247, 1000, 10824, 862);
INSERT INTO `order_analysis` (`date`, `user_src`, `order_src`, `order_location`, `new_order`, `payed_order`, `pending_order`, `cancel_order`, `reject_order`, `good_order`, `report_order`) VALUES ('2015-10-14 00:00:00', '微信朋友圈H5页面', 'iOS APP', '广州', 17134, 11270, 549, 204, 224, 10234, 773);
INSERT INTO `order_analysis` (`date`, `user_src`, `order_src`, `order_location`, `new_order`, `payed_order`, `pending_order`, `cancel_order`, `reject_order`, `good_order`, `report_order`) VALUES ('2015-10-17 00:00:00', '地推二维码扫描', 'iOS APP', '北京', 16061, 9418, 1220, 1247, 458, 13877, 749);
INSERT INTO `order_analysis` (`date`, `user_src`, `order_src`, `order_location`, `new_order`, `payed_order`, `pending_order`, `cancel_order`, `reject_order`, `good_order`, `report_order`) VALUES ('2015-10-17 00:00:00', '微信朋友圈H5页面', '微信公众号', '武汉', 12749, 11127, 1773, 6, 5, 9874, 678);
INSERT INTO `order_analysis` (`date`, `user_src`, `order_src`, `order_location`, `new_order`, `payed_order`, `pending_order`, `cancel_order`, `reject_order`, `good_order`, `report_order`) VALUES ('2015-10-18 00:00:00', '地推二维码扫描', 'iOS APP', '上海', 13086, 15882, 1727, 1764, 1429, 12501, 625);
INSERT INTO `order_analysis` (`date`, `user_src`, `order_src`, `order_location`, `new_order`, `payed_order`, `pending_order`, `cancel_order`, `reject_order`, `good_order`, `report_order`) VALUES ('2015-10-18 00:00:00', '微信朋友圈H5页面', 'iOS APP', '武汉', 15129, 15598, 1204, 1295, 1831, 11500, 320);
INSERT INTO `order_analysis` (`date`, `user_src`, `order_src`, `order_location`, `new_order`, `payed_order`, `pending_order`, `cancel_order`, `reject_order`, `good_order`, `report_order`) VALUES ('2015-10-19 00:00:00', '地推二维码扫描', 'Android APP', '杭州', 20687, 18526, 1398, 550, 213, 12911, 185);
INSERT INTO `order_analysis` (`date`, `user_src`, `order_src`, `order_location`, `new_order`, `payed_order`, `pending_order`, `cancel_order`, `reject_order`, `good_order`, `report_order`) VALUES ('2015-10-19 00:00:00', '应用商店', '微信公众号', '武汉', 12388, 11422, 702, 106, 158, 5820, 474);
INSERT INTO `order_analysis` (`date`, `user_src`, `order_src`, `order_location`, `new_order`, `payed_order`, `pending_order`, `cancel_order`, `reject_order`, `good_order`, `report_order`) VALUES ('2015-10-20 00:00:00', '微信朋友圈H5页面', '微信公众号', '上海', 14298, 11682, 1880, 582, 154, 7348, 354);
INSERT INTO `order_analysis` (`date`, `user_src`, `order_src`, `order_location`, `new_order`, `payed_order`, `pending_order`, `cancel_order`, `reject_order`, `good_order`, `report_order`) VALUES ('2015-10-21 00:00:00', '地推二维码扫描', 'Android APP', '深圳', 22079, 14333, 5565, 1742, 439, 8246, 211);
INSERT INTO `order_analysis` (`date`, `user_src`, `order_src`, `order_location`, `new_order`, `payed_order`, `pending_order`, `cancel_order`, `reject_order`, `good_order`, `report_order`) VALUES ('2015-10-22 00:00:00', 'UC浏览器引流', 'iOS APP', '上海', 28968, 18151, 7212, 2373, 1232, 10739, 578);doris数据库准备
下面是我上面数据表在doris对应的建表脚本
CREATE TABLE `order_analysis` (
`date` datetime DEFAULT NULL,
`user_src` varchar(30) DEFAULT NULL,
`order_src` varchar(50) DEFAULT NULL,
`order_location` varchar(10) DEFAULT NULL,
`new_order` int DEFAULT NULL,
`payed_order` int DEFAULT NULL,
`pending_order` int DEFAULT NULL,
`cancel_order` int DEFAULT NULL,
`reject_order` int DEFAULT NULL,
`good_order` int DEFAULT NULL,
`report_order` int DEFAULT NULL
) ENGINE=OLAP
DUPLICATE KEY(`date`,user_src)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`user_src`) BUCKETS 1
PROPERTIES (
"replication_num" = "3",
"in_memory" = "false",
"storage_format" = "V2"
);Datax Job JSON文件
创建并编辑datax job任务json文件,并保存到指定目录
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["date","user_src","order_src","order_location","new_order","payed_order"," pending_order"," cancel_order"," reject_order"," good_order"," report_order" ],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://bigdata01:3306/testabc"],
"table": ["order_analysis"]
}
],
"username": "root",
"password": "123456",
"where": ""
}
},
"writer": {
"name": "doriswriter",
"parameter": {
"loadUrl": ["bigdata01:8030"],
"column": ["date","user_src","order_src","order_location","new_order","payed_order"," pending_order"," cancel_order"," reject_order"," good_order"," report_order"],
"username": "root",
"password": "123456",
"postSql": ["select count(1) from order_analysis"],
"preSql": [],
"flushInterval":30000,
"connection": [
{
"jdbcUrl": "jdbc:mysql://bigdata01:9030/test",
"selectedDatabase": "test",
"table": ["order_analysis"]
}
]
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
datax.py doris.json假如没有使用新版的 datax,就不带 doriswriter 插件,会报如下错误!

7.2 代码操作 Doris
https://doris.apache.org/zh-CN/docs/db-connect/database-connect
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bigdata</groupId>
<artifactId>DorisDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<arrow.version>17.0.0</arrow.version>
</properties>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.30</version>
</dependency>
<dependency>
<groupId>org.apache.arrow</groupId>
<artifactId>flight-sql-jdbc-core</artifactId>
<version>${arrow.version}</version>
</dependency>
</dependencies>
</project>1) 通过 mysql 协议连接
package com.bigdata;
import java.sql.*;
public class Demo01 {
public static void main(String[] args) {
String user = "root";
String password = "123456";
String newUrl = "jdbc:mysql://node01:9030/testdb?useUnicode=true&characterEncoding=utf8&useTimezone=true&serverTimezone=Asia/Shanghai&useSSL=false&allowPublicKeyRetrieval=true";
try {
Connection myCon = DriverManager.getConnection(newUrl, user, password);
Statement stmt = myCon.createStatement();
ResultSet result = stmt.executeQuery("show databases");
ResultSetMetaData metaData = result.getMetaData();
int columnCount = metaData.getColumnCount();
while (result.next()) {
for (int i = 1; i <= columnCount; i++) {
System.out.println(result.getObject(i));
}
}
} catch (SQLException e) {
System.out.println(e);
}
}
}2) 基于 Arrow Flight SQL 的高速数据传输链路

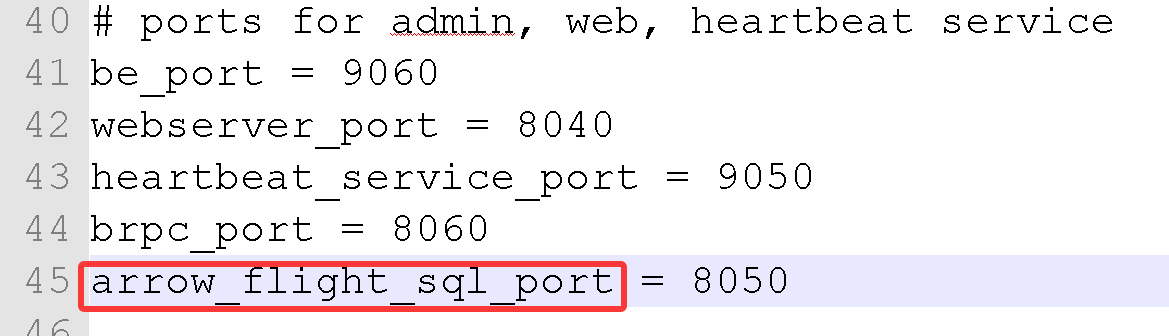
自 Doris 2.1 版本后,基于 Arrow Flight SQL 协议实现了高速数据链路,支持多种语言使用 SQL 从 Doris 高速读取大批量数据。Arrow Flight SQL 还提供了通用的 JDBC 驱动,支持与同样遵循 Arrow Flight SQL 协议的数据库无缝交互。部分场景相比 MySQL Client 或 JDBC/ODBC 驱动数据传输方案,性能提升百倍。
jdbc 方式使用 arrow flight sql
注意:需要将 pom 文件中的 mysql 的驱动包注释或者删除,否则报错!!!!
<properties>
<arrow.version>17.0.0</arrow.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.arrow</groupId>
<artifactId>flight-sql-jdbc-core</artifactId>
<version>${arrow.version}</version>
</dependency>
</dependencies>新建 doris 中的表:
package com.bigdata;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class Demo02 {
public static void main(String[] args) throws Exception{
Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");
String DB_URL = "jdbc:arrow-flight-sql://bigdata01:8070?useServerPrepStmts=false"
+ "&cachePrepStmts=true&useSSL=false&useEncryption=false";
String USER = "root";
String PASS = "123456";
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("select * from test.order_analysis;");
while (resultSet.next()) {
System.out.println(resultSet.toString());
System.out.println(resultSet.getString("user_src"));
}
resultSet.close();
stmt.close();
conn.close();
}
}除了使用 JDBC,与 Python 类似,Java 也可以创建 Driver 读取 Doris 并返回 Arrow 格式的数据,下面分别是使用 AdbcDriver 和 JdbcDriver 连接 Doris Arrow Flight Server。
<properties>
<adbc.version>0.15.0</adbc.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.arrow.adbc</groupId>
<artifactId>adbc-driver-jdbc</artifactId>
<version>${adbc.version}</version>
</dependency>
<dependency>
<groupId>org.apache.arrow.adbc</groupId>
<artifactId>adbc-core</artifactId>
<version>${adbc.version}</version>
</dependency>
<dependency>
<groupId>org.apache.arrow.adbc</groupId>
<artifactId>adbc-driver-manager</artifactId>
<version>${adbc.version}</version>
</dependency>
<dependency>
<groupId>org.apache.arrow.adbc</groupId>
<artifactId>adbc-sql</artifactId>
<version>${adbc.version}</version>
</dependency>
<dependency>
<groupId>org.apache.arrow.adbc</groupId>
<artifactId>adbc-driver-flight-sql</artifactId>
<version>${adbc.version}</version>
</dependency>
</dependencies>
package com.bigdata;
import org.apache.arrow.adbc.core.*;
import org.apache.arrow.adbc.driver.flightsql.FlightSqlDriver;
import org.apache.arrow.flight.Location;
import org.apache.arrow.memory.BufferAllocator;
import org.apache.arrow.memory.RootAllocator;
import org.apache.arrow.vector.VectorSchemaRoot;
import org.apache.arrow.vector.ipc.ArrowReader;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class Demo03 {
public static void main(String[] args) throws Exception {
// 1. new driver
final BufferAllocator allocator = new RootAllocator();
FlightSqlDriver driver = new FlightSqlDriver(allocator);
Map<String, Object> parameters = new HashMap<>();
AdbcDriver.PARAM_URI.set(parameters, Location.forGrpcInsecure("node01", 8070).getUri().toString());
AdbcDriver.PARAM_USERNAME.set(parameters, "root");
AdbcDriver.PARAM_PASSWORD.set(parameters, "123456");
AdbcDatabase adbcDatabase = driver.open(parameters);
// 2. new connection
AdbcConnection connection = adbcDatabase.connect();
AdbcStatement stmt = connection.createStatement();
// 3. execute query
stmt.setSqlQuery("select * from information_schema.tables;");
AdbcStatement.QueryResult queryResult = stmt.executeQuery();
ArrowReader reader = queryResult.getReader();
// 4. load result
List<String> result = new ArrayList<>();
while (reader.loadNextBatch()) {
VectorSchemaRoot root = reader.getVectorSchemaRoot();
String tsvString = root.contentToTSVString();
result.add(tsvString);
}
System.out.printf("batchs %d\n", result.size());
// 5. close
reader.close();
queryResult.close();
stmt.close();
connection.close();
}
}代码会报 java 版本问题,jdk 需要切换为 jdk11。
java: 无法访问org.apache.arrow.adbc.driver.flightsql.FlightSqlDriver
错误的类文件: /D:/repository/org/apache/arrow/adbc/adbc-driver-flight-sql/0.15.0/adbc-driver-flight-sql-0.15.0.jar!/org/apache/arrow/adbc/driver/flightsql/FlightSqlDriver.class
类文件具有错误的版本 55.0, 应为 52.0
请删除该文件或确保该文件位于正确的类路径子目录中。