《声音克隆与情感合成:IndexTTS2让AI语音会"演戏"》中,已经在本地部署了模型,可以通过它提供的web页面使用语音合成。
本小节让 Dify 接入 IndexTTS2, 将 IndexTTS2 集成到Dify应用中。

1.Dify环境
本次环境使用 Dify 1.10.0, RockyLinux 操作系统,使用 Docker 安装部署。
http://http://192.168.1.20
2.IndexTTS2服务
《声音克隆与情感合成:IndexTTS2让AI语音会"演戏"》中详细介绍了如何本地部署 IndexTTS2服务,如需本地部署,请参考文章。
shell
# 如果系统中安装了conda,需要退出conda环境
conda deactivate
# 进入 IndexTTS2源码目录
cd index-tts
# 配置环境变量,指定Haggingface镜像网站。因为启动的时候,如果需要模型权重文件,将会到 Haggingface上下载
export HF_ENDPOINT="https://hf-mirror.com"
# 启动服务, 服务会开启 7860 端口
uv run webui.pyhttp://http://192.168.6.133:7860/
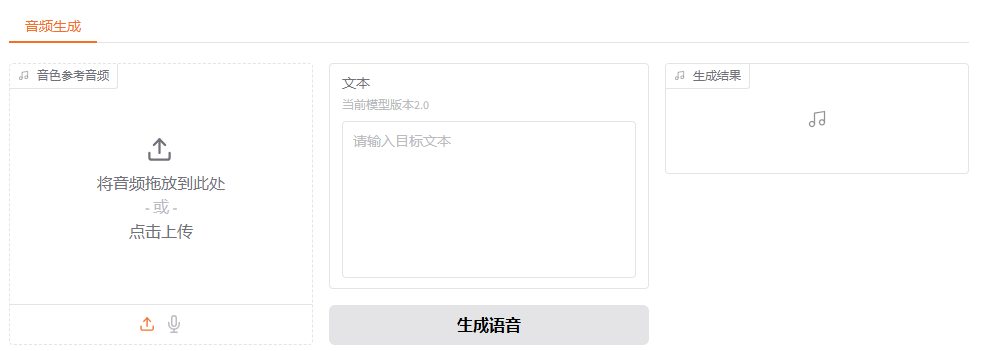
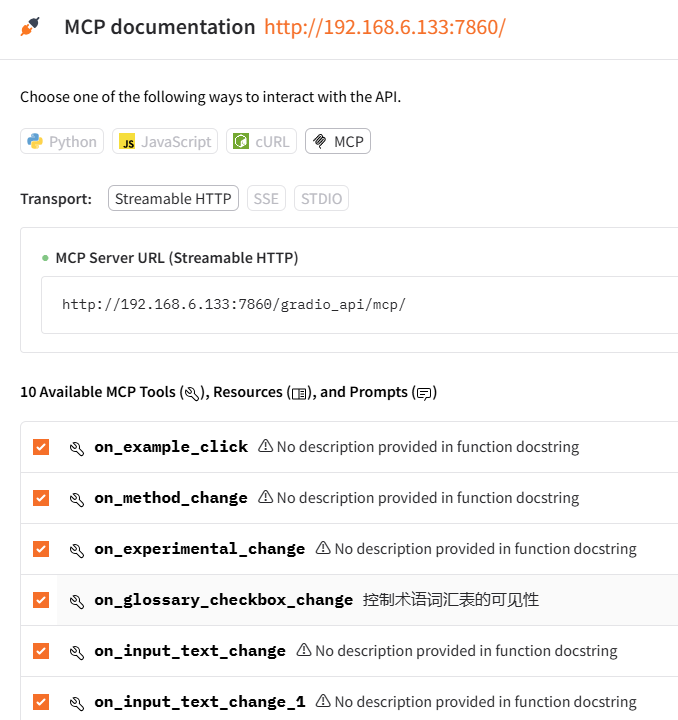
在页面的最底部,会出现 "通过API使用" 的链接:

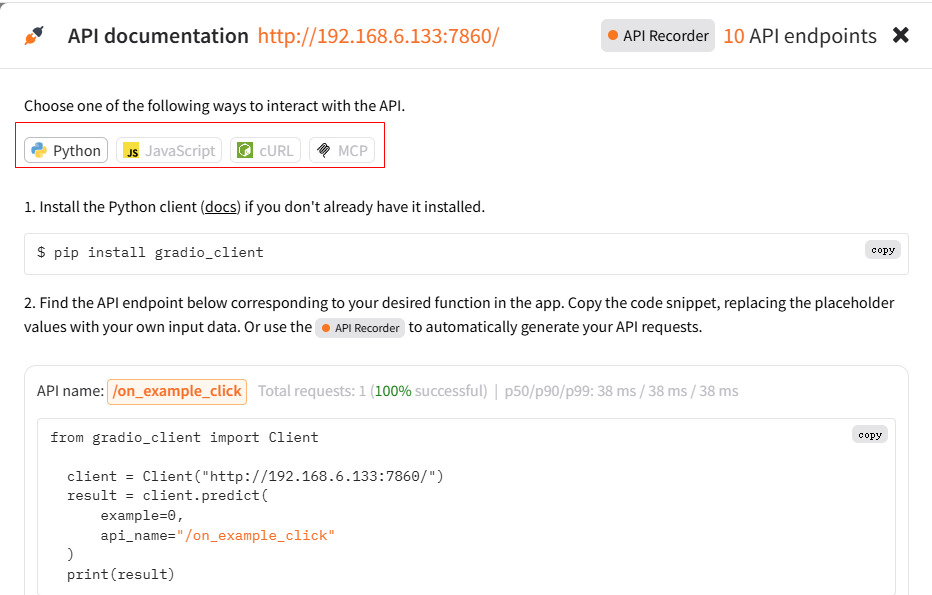
3.IndexTTS2 API接口
点击上面的链接后,出现页面,可以看到,它提供了4中接口嗲用方式:
- Python: 通过Python代码进行调用
- JavaScript: 通过JS代码进行接口调用
- cURL : 通过HTTP方式进行调用
- MCP: 如果IndexTTS2服务启动的时候,指定了启动参数或者添加了环境变脸,那它就可以作为一个MCP服务启动,应用中可以直接集成这个MCP服务

4.Dify中如何集成
要想在Dify中集成 IndexTTS2服务,有两种途径:
- 在工作流中添加 HTTP请求节点,使用HTTP方式调用 IndexTTS2服务
- 使用MCP。IndexTTS2提供了MCP服务,Dify中接入MCP服务即可。
4.1 使用MCP
首先安装依赖:
shell
uv pip install gradio[mcp]编辑 webui.py 最后一行:
python
# 修改前
demo.launch(server_name=cmd_args.host, server_port=cmd_args.port)
# 修改后
demo.launch(server_name=cmd_args.host, server_port=cmd_args.port,mcp_server=True)启动服务后:
4.2 使用Python发送 HTTP请求
API 文档中有说明:
latex
Find the API endpoint below corresponding to your desired function in the app. Copy the code snippet, replacing the placeholder values with your own input data. Or use the
API Recorder
to automatically generate your API requests.
Making a prediction and getting a result requires 2 requests: a POST and a GET request. The POST request returns an EVENT_ID, which is used in the second GET request to fetch the results. In these snippets, we've used awk and read to parse the results, combining these two requests into one command for ease of use. See curl docs.大概意思是: 首先会发送异步的请求,比如语音合成API 的URL:POSThttp://192.168.6.133:7860/gradio_api/call/gen_single ,返回$EVENT_ID,然后在使用 GEThttp://192.168.6.133:7860/gradio_api/call/gen_single/ E V E N T I D ( h t t p : / / 192.168.6.133 : 7860 / g r a d i o a p i / c a l l / g e n s i n g l e / EVENT_ID](http://192.168.6.133:7860/gradio_api/call/gen_single/ EVENTID](http://192.168.6.133:7860/gradioapi/call/gensingle/EVENT_ID) 来获取最终生成的音频文件
因为第二个请求,也就是那个 GET请求,服务端响应的是 SSE 流,所以我们使用 sseclient这个库来解析返回内容。
shell
pip install requests sseclient-py
python
# 使用示例
if __name__ == "__main__":
# 替换为你的服务器地址
SERVER_URL = "http://192.168.6.133:7860"
# 生成语音
sound_url = simple_tts(
server_url=SERVER_URL,
text="Translate for me, what is a surprise!"
)
if sound_url!=None:
print("语音合成成功!")
print(sound_url)
else:
print("语音合成失败!")
python
def simple_tts(server_url, text):
"""
简化版TTS调用函数
Args:
server_url: 服务器地址,如 "http://192.168.6.133:7860"
text: 要合成的文本
"""
api_url = f"{server_url.rstrip('/')}/gradio_api/call/gen_single"
# 构建请求数据
request_data = {
"data": [
"与音色参考音频相同", # 0:情感控制方式
{ # 1: 音色参考音频
"path": "/tmp/gradio/bbf6da2c239d53e761a6e2ab173c9db011f3e1c8e4e04566c73fc61a77e6925d/voice_01.wav",
"meta": {"_type": "gradio.FileData"}
},
text, # 2: 要转换的文本
None, # 3:
1, # 4: 情感权重
0, 0, 0, 0, 0, 0, 0, 0, # 情感值:5:喜、6:怒、7:哀、8:惧、9:厌恶、10:低落、11:惊喜、12:平静
"", # 13: 情感描述文本
False, # 14: 情感随机采样
120, # 15: 分句最大Token数
True, # 16: do_sample
0.8, 30, 0.8, 0, 3, 10, 1500 # 其他参数
]
}
try:
# 第一步:发送POST请求
print(f"正在生成语音: {text}")
response = requests.post(api_url, json=request_data)
response.raise_for_status()
# 获取EVENT_ID
result = response.json()
event_id = result.get("event_id")
if not event_id and "data" in result:
event_id = result["data"][0]
if not event_id:
print("无法获取EVENT_ID")
return False
# 第二步:获取结果
result_url = f"{api_url}/{event_id}"
response = requests.get(result_url, stream=True)
client = sseclient.SSEClient(response)
sound_url = None
try:
for event in client.events():
print(f"事件类型: {event.event}")
print(f"事件数据: {event.data}")
datas=json.loads(event.data) # 转换为JSON对象
if len(datas)>0:
data=datas[0]
print(data['visible'])
if data['visible']:
sound_url=data['value']['url']
return sound_url
except Exception as e:
print(f"读取流时发生错误: {e}")
finally:
client.close()
print("客户端已关闭")
return sound_url
except Exception as e:
print(f"发生错误: {str(e)}")
return None注意:第一个参数是上传的音色文件,这个path ,传递的是服务器端的路径。
这个path可以通过调用
/on_example_click这个接口来获取。 相当于点击了UI页面中,最下面的Example 中的音色参考行,这样就能得到内置的参考音频路径如果要使用自己的参考音频,就需要调用
/update_prompt_audio这个接口来获取上传到服务器上的文件路径。
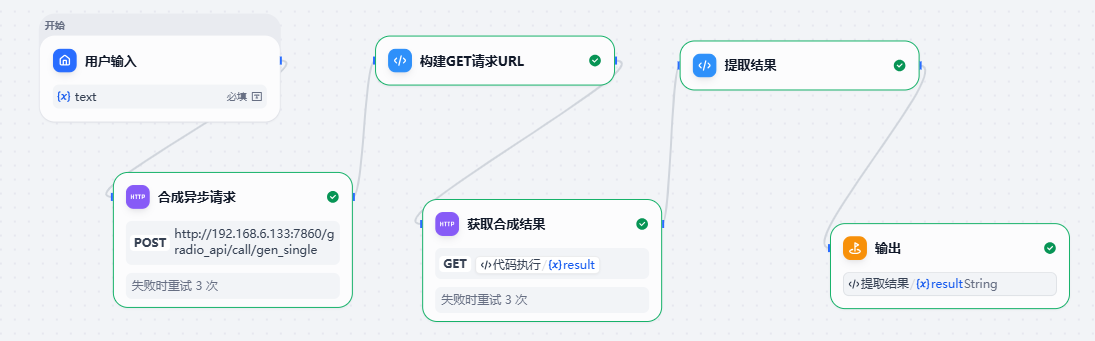
4.3 Dify发送 HTTP请求
新建一个工作流,在开始节点后面添加HTTP请求节点:
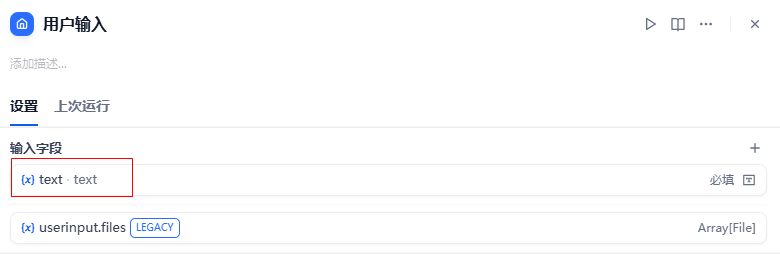
4.3.1 用户输入节点
在这个节点上,添加一个变量,名称为: text,用于保存用户输入的要合成语音的文本。
4.3.2 添加HTTP请求节点
HTTP请求节点向服务器发送HTTP请求,这个请求会返回一个 event_id
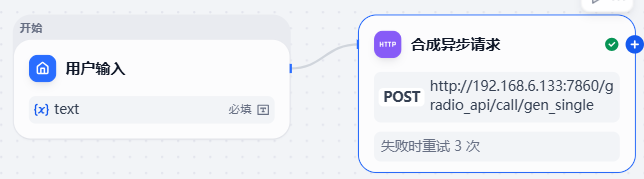
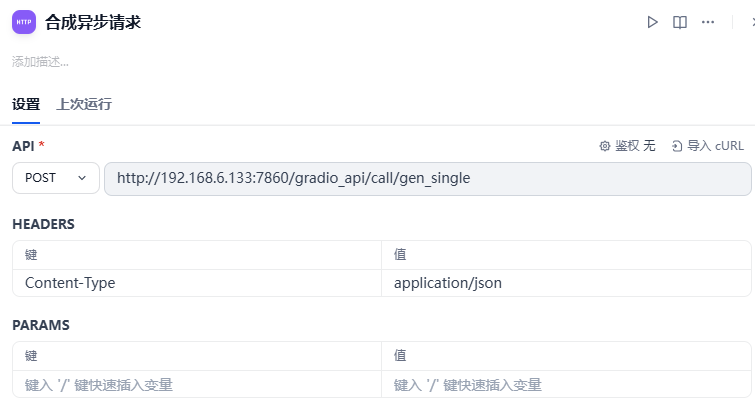
请求Body:注意path 得写服务器上的文件路径
json
{
"data": [
"与音色参考音频相同",
{
"path": "/tmp/gradio/bbf6da2c239d53e761a6e2ab173c9db011f3e1c8e4e04566c73fc61a77e6925d/voice_01.wav",
"meta":{"_type":"gradio.FileData"}
},
"{{#1766126193865.text#}}",
null,
1,
0, 0, 0, 0, 0, 0, 0, 0,
"",
false,
120,
true,
0.8, 30, 0.8, 0, 3, 10, 1500
]
}如果报文不知道怎么写,可以在页面上录制操作生成 body
在http://192.168.6.133:7860/ 上,打开 API Recorder 按钮,然后再页面上进行操作:
- 选一个音色文件
- 输入要转换的文本
- 生成语音
然后结束录制。此时就可以在页面上看到 curl代码:
4.3.3 解析返回的数据
添加一个 代码执行节点,它会执行一段代码,提取上个http请求返回的 event_id,生成GET请求的URL保存到变量中
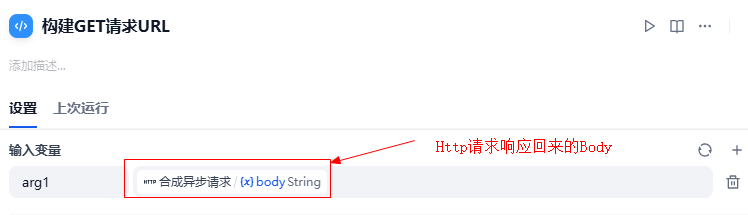
要执行的python代码,它是一个函数,返回值必须是一个字典,key默认为 result
python
def main(arg1: str):
import json
data=json.loads(arg1)
event_id=data['event_id']
url=f'http://192.168.6.133:7860/gradio_api/call/gen_single/{event_id}'
return {
"result": url,
}4.3.4 添加HTTP请求节点发出GET请求
这个HTTP节点发出GET请求,请求的地址是上一步构建出来的URL
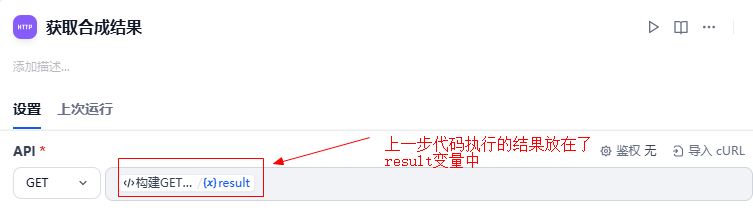
4.3.5 添加代码执行节点获取合成结果
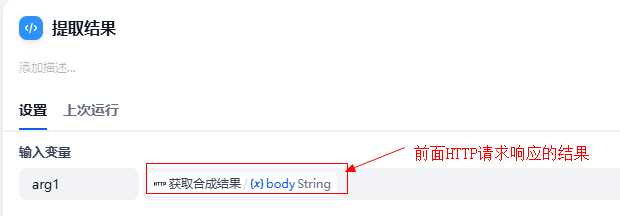
python
import json
import re
def main(arg1: str):
# 初始化返回结果
result_url = None
try:
# 1. 获取 body 内容
body_text = arg1
# 2. 使用正则表达式查找 data: 开头的行,并提取后面的数据部分
# 匹配 'data: ' 后面直到行尾的所有内容
data_match = re.search(r'data:\s*(.+)', body_text, re.IGNORECASE)
if data_match:
json_str = data_match.group(1).strip()
# 3. 解析 JSON 字符串
# 注意:这里解析出来的是一个列表
data_list = json.loads(json_str)
# 4. 提取第一个元素中的 url
# 结构: [{ "value": { "url": "实际链接" } }]
if len(data_list) > 0:
result_url = data_list[0].get("value", {}).get("url")
except Exception as e:
# 如果出错,返回错误信息(调试时很有用)
return {
"result": f"Error parsing response: {str(e)}"
}
# 5. 按照 Dify 规范返回字典
# 这里的 "result" 键是 Dify 默认读取的输出变量名
return {
"result": result_url
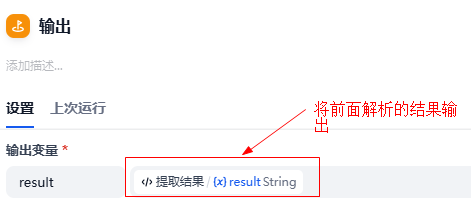
}4.3.6 输出结果
添加输出节点
4.3.7 整体流程