据悉,昇思MindSpore开源社区将于 2025 年 12 月 25日在杭州举办昇思人工智能框架峰会。本次峰会的昇思人工智能框架技术发展与行业实践论坛将讨论到昇思MindSpore大模型训练技术进展与实践,MindSpore Parallel Training System SIG的核心贡献者将在昇思开发者动手实践workshop设立开发者动手实践体验,带领开发者体验使用昇思MindSpore大模型训练技术。本文对MindSpore 大模型训练技术进行了深入解读,就业界关热度较高的MoE性能优化技术,介绍MindSpore方案。
混合专家模型(Mixture of Experts, MoE)因其在计算效率与模型容量之间巧妙的平衡作用,能有效缓解解决大模型参数指数增长带来的计算压力的关键技术之一,正成为构建超大规模神经网络的核心架构。然而,MoE模型引入的复杂路由机制,导致通信开销显著增长,特别是token dispatch和combine阶段,AlltoAll类密集的跨机大数据量通信,成为系统性能的主要瓶颈。针对这一瓶颈,昇思MindSpore面向大模型训练实践,提出了一套MoE性能优化方案。
昇思MindSpore MoE性能优化方案主要包含机间通信合并、零冗余通信、AlltoAllV收发异构复用3项关键技术。这些技术协同作用,系统性地解决了MoE架构在大规模分布式训练中面临的通信开销大、断流频率高、显存占用高等核心瓶颈。
机间通信合并特性
当前的流行MoE架构存在着专家数多、单个专家计算量小的特点。如DeepSeek V3每个层的路由专家个数高达256个,在训练实践中为了减小显存压力往往开启专家并行(EP),将专家切分到不同的卡上。然而,当EP数大于单个节点的的NPU/GPU数量时,专家会被切分到不同节点上,在token dispatch和combine阶段,需要进行AlltoAll的机间通信。因机间带宽远小于机内带宽,此时,机间通信不可避免地成为通信性能的瓶颈。
昇思MindSpore团队针对这一问题,采用跨机AllGather通信与机内AlltoAll通信相结合的方式,解决AlltoAll机间通信性能差的问题。首先将所需的tokens通过跨机AllGather同步到机间,然后在机间进行tokens的排序与AlltoAll通信。基于这种分层的通信方式降低了跨机通信数据量,有效地提升了整体通信性能。经过在DeepSeek V3 671B实训测试,在EP=16时端到端吞吐性能提升15%。机间通信合并与原始通信方案的示意如图1。
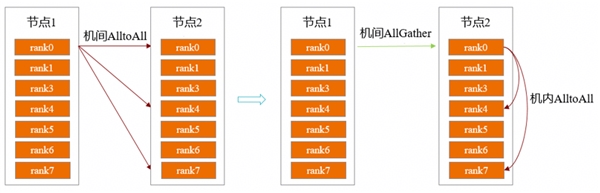
图1. 机间通信合并与原始通信方案的示意图
AlltoAllV收发异构复用特性
在MoE的token dispatch 以及 token combine阶段各需要执行一次AlltoAllV的通信计算。在下发AlltoAllV算子时需要send_list/receive_list的参数信息,而这两个参数内存在device侧,需要对其进行一次device to host操作将其搬运至Host侧内存。因此在正向token dispatch及token combine阶段各存在1次因device to host引发的下发断流(即,下发流程需要等待device to host操作完成后,才能下发其余算子)。如果考虑反向计算,断流次数就变成4次,对性能造成严重影响。
为此,昇思MindSpore采用AlltoAllV收发异构复用技术来减少断流次数,其核心思想在于在提前对token dispatch的send_list/receive_list进行device to host,将其缓存在Host,然后基于缓存的send_list/receive_list实现提前下发token combine阶段的AlltoAllV,其原理如图2所示。
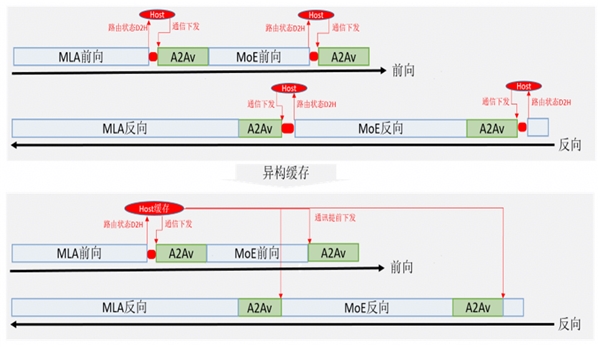
图2. AlltoAllV收发异构复用
昇思MindSpore通过其异构能力实现AlltoAllV收发send_list/receive_list的异构复用,将断流次数从4次降低到1次。在DeepSeek V3 671B实训测试,端到端性能提升5%。
昇思MindSpore针对MoE性能提升的业界难题,成体系地采用优化技术,包括但不限于上述2项技术,构筑了昇思MindSpore面向超大规模MoE训练的高效通信底座,更多的技术介绍与交流,请关注昇思人工智能框架峰会。
本次在杭州举办的昇思人工智能框架峰会,将会邀请思想领袖、专家学者、企业领军人物及明星开发者等产学研用代表,共探技术发展趋势、分享创新成果与实践经验。欢迎各界精英共赴前沿之约,携手打造开放、协同、可持续的人工智能框架新生态!